Síntesis y edición de imágenes controladas utilizando el nuevo TL-GAN Ejemplo de síntesis controlada en mi modelo TL-GAN (GAN de espacio latente transparente, red de contenido generativo con espacio oculto transparente)
Ejemplo de síntesis controlada en mi modelo TL-GAN (GAN de espacio latente transparente, red de contenido generativo con espacio oculto transparente)Todos los códigos y demostraciones en línea están disponibles en
la página del proyecto .
Entrenamos la computadora para tomar fotos como se describe
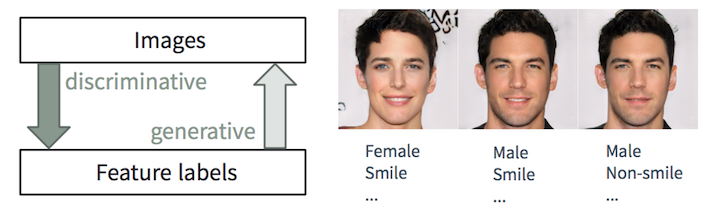 Tareas discriminatorias y generativas
Tareas discriminatorias y generativasEs fácil para una persona
describir una imagen, aprendemos a hacerlo desde una edad muy temprana. En el aprendizaje automático, esta es la tarea de clasificación / regresión
discriminante , es decir predicción de características a partir de imágenes de entrada. Los avances recientes en los métodos de ML / AI, especialmente en los modelos de aprendizaje profundo, comienzan a sobresalir en estas tareas, a veces alcanzando o superando las habilidades humanas, como se muestra en tareas como el reconocimiento de objetos visuales (por ejemplo, de AlexNet a ResNet según la clasificación de ImageNet) y detección / segmentación objetos (por ejemplo, de RCNN a YOLO en el conjunto de datos COCO), etc.
Sin embargo, la tarea inversa de
crear imágenes realistas a partir de la descripción es mucho más complicada y requiere muchos años de capacitación en diseño gráfico. En el aprendizaje automático, esta es una tarea
generativa , que es mucho más compleja que las tareas discriminatorias, ya que el modelo generativo debe generar mucha más información (por ejemplo, una imagen completa con cierto nivel de detalle y variación) basada en datos iniciales más pequeños.
A pesar de la complejidad de crear tales aplicaciones, los
modelos generativos (con cierto control) son extremadamente útiles en muchos casos:
- Creación de contenido : imagine que una empresa de publicidad crea automáticamente imágenes atractivas que coinciden con el contenido y el estilo de la página web donde se insertan estas imágenes. El diseñador busca inspiración, ordenando el algoritmo para generar 20 patrones de calzado asociados con los signos "descanso", "verano" y "apasionado". El nuevo juego te permite generar avatares realistas a partir de una simple descripción.
- Edición inteligente basada en el contenido : el fotógrafo cambia la expresión facial, la cantidad de arrugas y el peinado de la foto en unos pocos clics. Un artista en un estudio de Hollywood convierte las tomas tomadas en una tarde nublada, como si fueran tomadas en una mañana brillante, con luz solar en el lado izquierdo de la pantalla.
- Aumento de datos : un desarrollador de drones puede sintetizar videos realistas para un escenario de accidente específico con el fin de aumentar el conjunto de datos de entrenamiento. Un banco puede sintetizar ciertos tipos de datos de fraude mal presentados en el conjunto de datos existente para mejorar el sistema antifraude.
En este artículo, hablaremos sobre nuestro trabajo reciente llamado
Transparent Latent-space GAN (TL-GAN) , que amplía la funcionalidad de los modelos más modernos y proporciona una nueva interfaz. Actualmente estamos trabajando en un documento que tendrá más detalles técnicos.
Resumen de modelos generativos
La comunidad de aprendizaje profundo está mejorando rápidamente los modelos generativos. Se pueden distinguir tres tipos prometedores entre ellos:
modelos autorregresivos ,
autoencoders variacionales (VAE) y
redes adversas generativas (GAN) , que se muestran en la figura a continuación. Si está interesado en los detalles, lea el excelente
artículo del blog OpenAI.
 Comparación de redes generativas. Imagen del curso STAT946F17 en la Universidad de Waterloo
Comparación de redes generativas. Imagen del curso STAT946F17 en la Universidad de WaterlooPor el momento, las redes GAN generan imágenes de la
más alta calidad (fotorrealistas y diversas, con detalles convincentes en alta resolución). Eche un vistazo a la impresionante red pg-GAN (
GAN en crecimiento progresivo ) de Nvidia. Por lo tanto, en este artículo nos centraremos en los modelos GAN.
 Pg-GAN sintético generado por Nvidia. Ninguna de las imágenes está relacionada con la realidad.
Pg-GAN sintético generado por Nvidia. Ninguna de las imágenes está relacionada con la realidad.Gestión de problemas del modelo GAN
 Generación de imágenes aleatorias y controladas.La versión original de GAN
Generación de imágenes aleatorias y controladas.La versión original de GAN y muchos modelos populares basados en él (como
DC-GAN y
pg-GAN ) son modelos de enseñanza
sin un maestro . Después del entrenamiento, la red neuronal generativa toma ruido aleatorio como entrada y crea una imagen fotorrealista que apenas se distingue del conjunto de datos de entrenamiento. Sin embargo, no podemos controlar adicionalmente las características de las imágenes generadas. En la mayoría de las aplicaciones (por ejemplo, en los escenarios descritos en la primera sección), a los usuarios les gustaría crear patrones con
atributos arbitrarios (por ejemplo, edad, color de cabello, expresión facial, etc.) Idealmente, configure suavemente cada función.
Se han creado numerosas variantes de GAN para dicha síntesis controlada. Se pueden dividir condicionalmente en dos tipos: redes de transferencia de estilo y generadores condicionales.
Redes de transferencia de estilo
Las redes de transferencia de estilo
CycleGAN y
pix2pix están capacitadas para transferir una imagen de un área (dominio) a otra: por ejemplo, de un caballo a una cebra, de un boceto a imágenes en color. Como resultado, no podemos cambiar suavemente un signo específico entre dos estados discretos (por ejemplo, agregar un poco de barba en la cara). Además, una red está diseñada para un tipo de transmisión, por lo que se necesitarán diez redes neuronales diferentes para configurar diez funciones.
Generadores de condición
Los generadores
condicionales -
GAN condicional ,
AC-GAN y Stack-GAN - en el proceso de capacitación, estudian simultáneamente imágenes y etiquetas de objetos, lo que le permite generar imágenes con la configuración de atributos. Cuando desee agregar nuevas funciones al proceso de generación, debe volver a capacitar todo el modelo GAN, lo que requiere enormes recursos computacionales y tiempo (por ejemplo, de varios días a semanas en la misma GPU K80 con el conjunto ideal de hiperparámetros). Además, para completar la capacitación, es necesario confiar en un conjunto de datos que contenga todas las etiquetas de objeto definidas por el usuario, y no usar diferentes etiquetas de varios conjuntos de datos.
Nuestra red generativa competitiva con espacio oculto transparente (
Transparent Latent-space GAN , TL-GAN) utiliza un enfoque diferente para la generación controlada, y resuelve estos problemas. Ofrece la capacidad de
configurar sin problemas una o más funciones usando una sola red . Además, puede agregar efectivamente nuevas características personalizadas en menos de una hora.
TL-GAN: un enfoque nuevo y efectivo para la síntesis y edición controladas
Haciendo este misterioso espacio oculto transparente
Tome el modelo pvGAN de Nvidia, que genera imágenes fotorrealistas de caras de alta resolución, como se muestra en la sección anterior. Todas las características de la imagen generada de 1024 × 1024px están determinadas exclusivamente por el vector de ruido de 512 dimensiones en el espacio oculto (como una representación de baja dimensión del contenido de la imagen). Por lo tanto,
si entendemos qué constituye un espacio oculto (es decir, hacerlo transparente), entonces podemos controlar completamente el proceso de generación .
 Motivación TL-GAN: comprensión del espacio oculto para gestionar el proceso de generación
Motivación TL-GAN: comprensión del espacio oculto para gestionar el proceso de generaciónExperimentando con la red pre-entrenada pg-GAN, descubrí que el espacio oculto en realidad tiene dos buenas propiedades:
- Está bien lleno, es decir, la mayoría de los puntos en el espacio generan imágenes razonables.
- Es bastante continuo, es decir, la interpolación entre dos puntos en un espacio oculto generalmente conduce a una transición suave de las imágenes correspondientes.
La intuición dice que en el espacio oculto hay direcciones que predicen los atributos que necesitamos (por ejemplo, un hombre / mujer). Si es así, los vectores unitarios de estas direcciones se convertirán en ejes para controlar el proceso de generación (cara más masculina o más femenina).
Enfoque: expansión del eje de características
Para encontrar estos ejes de atributos en un espacio oculto,
construimos una conexión entre el vector oculto y etiquetas de etiquetas utilizando la formación del profesorado en parejas
. Ahora el problema es cómo obtener estos pares, ya que los conjuntos de datos existentes contienen solo imágenes
y etiquetas de objeto correspondientes
.
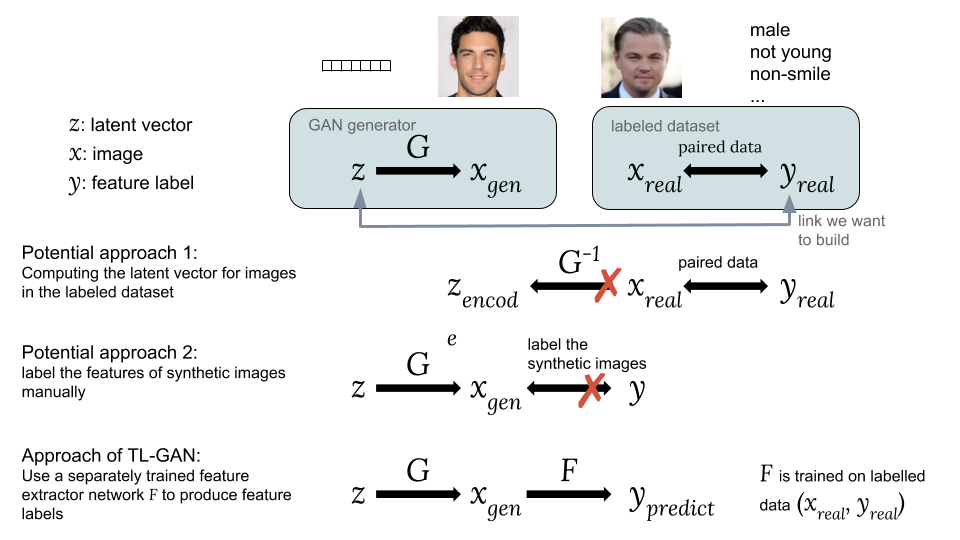 Formas de asociar un vector oculto z con una etiqueta de etiqueta yPosibles enfoques:Una opción es calcular los vectores ocultos correspondientes imágenes de un conjunto de datos existente con etiquetas de interés para nosotros . Sin embargo, la GAN no proporciona una manera fácil de calcular , lo que dificulta la implementación de esta idea.
Formas de asociar un vector oculto z con una etiqueta de etiqueta yPosibles enfoques:Una opción es calcular los vectores ocultos correspondientes imágenes de un conjunto de datos existente con etiquetas de interés para nosotros . Sin embargo, la GAN no proporciona una manera fácil de calcular , lo que dificulta la implementación de esta idea.
La segunda opción es generar imágenes sintéticas. usando una GAN de un vector oculto al azar como . El problema es que las imágenes sintéticas no están etiquetadas, por lo que es difícil usar un conjunto accesible de datos etiquetados.La principal innovación de nuestro modelo TL-GAN es la
capacitación de un extractor separado (clasificador para etiquetas discretas o regresor para continuo) con el modelo
utilizando un conjunto existente de datos etiquetados (
,
), y luego lanzar en un grupo de generadores de GAN entrenados
con red de extracción de características
. Esto le permite predecir etiquetas de características.
imágenes sintéticas
utilizando una red de extracción de características capacitada (extractor). Por lo tanto, a través de imágenes sintéticas, se establece una conexión entre
y
como
y
.
Ahora tenemos un vector oculto emparejado y características. Puedes entrenar al modelo regresor
para abrir todos los ejes de las funciones para controlar el proceso de generación de imágenes.
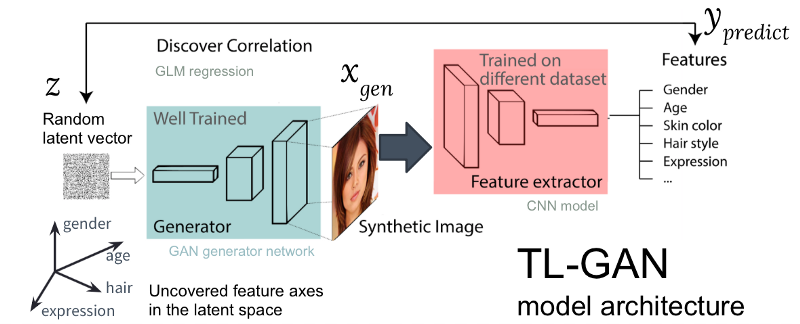 Figura: La arquitectura de nuestro modelo TL-GAN
Figura: La arquitectura de nuestro modelo TL-GANLa figura anterior muestra la arquitectura del modelo TL-GAN, que contiene cinco pasos:
- El estudio de la distribución . Seleccionamos un modelo GAN bien entrenado y una red generativa. Tomé el pg-GAN bien entrenado (de Nvidia), que proporciona la generación de rostros de mejor calidad.
- Clasificación Seleccionamos un modelo previamente entrenado para extraer atributos (el extractor puede ser una red neuronal convolucional u otros modelos de visión por computadora) o capacitar a nuestro propio extractor utilizando un conjunto de datos etiquetados. Entrené una red neuronal convolucional simple usando el kit CelebA (más de 30,000 caras con 40 etiquetas).
- Generación Creamos varios vectores ocultos al azar, pasamos a través del generador de GAN entrenado para crear imágenes sintéticas, luego usamos el extractor de funciones entrenado para generar características en cada imagen.
- Correlación Usamos el modelo lineal generalizado (GLM) para implementar la regresión entre vectores ocultos y características. La pendiente de la línea de regresión se convierte en el eje de los rasgos .
- Investigación . Comenzamos con un vector oculto, lo movemos a lo largo de uno o varios ejes de los signos y estudiamos cómo esto afecta la generación de imágenes.
He optimizado enormemente el proceso: en un modelo de GAN pre-entrenado, identificar ejes de características
lleva solo una hora en una máquina con una GPU. Esto se logra a través de varios trucos de ingeniería, incluida la transferencia de capacitación, la reducción del tamaño de las imágenes, el almacenamiento en caché preliminar de imágenes sintéticas, etc.
Resultados
Veamos cómo funciona esta simple idea.
Mover un vector oculto a lo largo de los ejes de los objetos.
Primero, verifiqué si los ejes de características detectadas se pueden usar para controlar la característica correspondiente de la imagen generada. Para hacer esto, cree un vector aleatorio
en el espacio oculto de la GAN y generar una imagen sintética
pasándolo a través de una red generativa
. Luego movemos el vector oculto a lo largo de un eje de características
(un vector unitario en el espacio oculto, por ejemplo, correspondiente al género de la cara) a distancia
a una nueva posición
y generar una nueva imagen
. Idealmente, la característica correspondiente de la nueva imagen debería cambiar en la dirección esperada.
A continuación se presentan los resultados de mover un vector a lo largo de varios ejes de atributos (género, edad, etc.). ¡Funciona sorprendentemente bien! Puede
transformar suavemente la imagen entre un hombre / mujer, un hombre joven / viejo, etc.
 Los primeros resultados de mover un vector oculto a lo largo de ejes de entidades enredados
Los primeros resultados de mover un vector oculto a lo largo de ejes de entidades enredadosDesentrañar los ejes de características correlacionados
En los ejemplos anteriores, la desventaja del método original es visible, es decir, el eje confuso de los atributos. Por ejemplo, cuando necesita reducir el vello facial, las caras generadas se vuelven más femeninas, lo cual no es el resultado esperado. El problema es que el género y la barba están inherentemente
correlacionados . Un cambio en un rasgo conduce a un cambio en otro. Cosas similares ocurrieron con otras características, como el cabello y el cabello rizado. Como se muestra en la figura siguiente, el eje original del atributo "barba" en el espacio oculto no es perpendicular al eje "piso".
Para resolver el problema, utilicé las técnicas de álgebra lineal simple. En particular, proyectó el eje de la barba en una nueva dirección, ortogonal al eje del piso, lo que elimina efectivamente su correlación y, por lo tanto, puede desentrañar estos dos signos en las caras generadas.
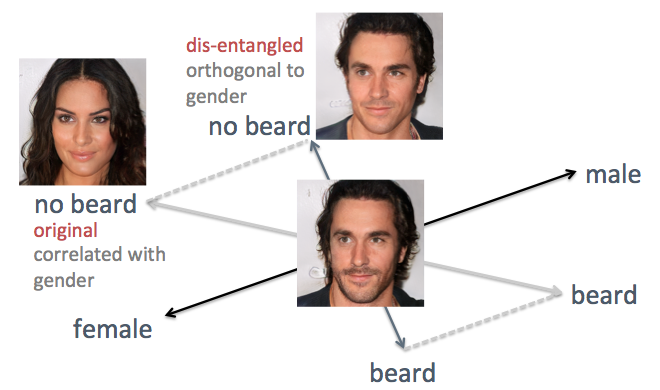 Desentrañar los ejes de características correlacionados con técnicas de álgebra lineal
Desentrañar los ejes de características correlacionados con técnicas de álgebra linealApliqué este método a la misma persona. Esta vez, los ejes de género y edad se eligen como de apoyo, proyectando todos los demás ejes para que se vuelvan ortogonales al género y la edad. Las caras se generan moviendo el vector oculto a lo largo de los ejes de entidades recién generados (que se muestran en la figura a continuación). Como era de esperar, ahora los signos como peinados y barbas no afectan el piso.
 Resultado mejorado de mover un vector oculto a lo largo de ejes de entidades desenredados
Resultado mejorado de mover un vector oculto a lo largo de ejes de entidades desenredadosEdición interactiva flexible
Para ver cuán flexiblemente nuestro modelo TL-GAN es capaz de controlar el proceso de generación de imágenes, creé una interfaz gráfica interactiva con un cambio suave en los valores de los objetos a lo largo de diferentes ejes, como se muestra a continuación.
Edición interactiva con TL-GAN¡Y de nuevo, el modelo funciona sorprendentemente bien si cambia la imagen a lo largo del eje de los signos!
Resumen
Este proyecto demuestra un nuevo método para administrar un modelo generativo sin un maestro, como la GAN (red generativa de confrontación). Usando un generador de GAN pre-entrenado (pg-GAN de Nvidia), hice que su espacio oculto sea transparente al mostrar los ejes de características significativas. Cuando un vector se mueve a lo largo de dicho eje en un espacio oculto, la imagen correspondiente se transforma a lo largo de esta característica, proporcionando síntesis y edición controladas.
Este método tiene claras ventajas:
- Eficiencia: para agregar un nuevo sintonizador de funciones para el generador, no es necesario volver a entrenar el modelo GAN, por lo que agregar sintonizadores para 40 funciones lleva menos de una hora.
- Flexibilidad: puede usar cualquier extractor de funciones capacitado en cualquier conjunto de datos, agregando más funciones a una GAN bien capacitada.
Algunas palabras sobre ética
Este trabajo le permite controlar la generación de imágenes en detalle, pero aún depende en gran medida de las características del conjunto de datos. La capacitación en fotos de estrellas de Hollywood significa que la modelo generará muy bien fotos de personas en su mayoría blancas y atractivas. Esto conducirá al hecho de que los usuarios podrán crear caras que representen solo una pequeña parte de la humanidad. Si implementa este servicio como una aplicación real, es recomendable expandir el conjunto de datos original para tener en cuenta la diversidad de nuestros usuarios.
Aunque la herramienta puede ser de gran ayuda en el proceso creativo, debe recordar las posibilidades de usarla para fines indecorosos. Si creamos caras realistas de cualquier tipo, ¿hasta qué punto podemos confiar en la persona que vemos en la pantalla? Hoy es importante discutir temas de este tipo. Como vimos en ejemplos recientes de la tecnología
Deepfake , la IA está progresando rápidamente, por lo que es vital para la humanidad comenzar una discusión sobre cómo implementar mejor estas aplicaciones.
Demostración en línea y código
Todo el código y las demostraciones en línea para este trabajo están disponibles en
la página de GitHub .
Si quieres jugar con el modelo en el navegador
No necesita descargar código, modelo o datos. Simplemente siga las instrucciones en
esta sección Léame. Puede cambiar las caras en el navegador como se muestra en el video.
Si quieres probar el código
Simplemente vaya a la página Léame del repositorio de GitHub. Código compilado en Anaconda Python 3.6 con Tensorflow y Keras.
Si quieres contribuir
Bienvenido No dude en enviar una solicitud de grupo o informar un problema en GitHub.
Acerca de mi
Recientemente recibí un doctorado en neurobiología computacional y cognitiva de la Universidad de Brown y una maestría en ciencias de la computación, con especialización en aprendizaje automático. En el pasado, estudié cómo las neuronas en el cerebro procesan información colectivamente para lograr funciones de alto nivel, como la percepción visual. Me gusta el enfoque algorítmico para el análisis, la simulación y la implementación de inteligencia, así como el uso de IA para resolver problemas complejos del mundo real. Estoy buscando activamente un trabajo como investigador de ML / AI en la industria de la tecnología.
Agradecimientos
Este trabajo se realizó en tres semanas como un proyecto para
el programa de becas InSight AI . Agradezco al director del programa
Emmanuel Amaisen y
Matt Rubashkin por el liderazgo general, especialmente a Emmanuel por sus sugerencias y la edición del artículo. También agradezco a todos los empleados de Insight por el excelente entorno de aprendizaje y otros participantes del programa Insight AI de quienes aprendí mucho.
Un agradecimiento especial a Rubin Xia por los muchos consejos e inspiración cuando decidí en qué dirección desarrollar el proyecto, y por la enorme ayuda para estructurar y editar este artículo.