El aprendizaje automático se está volviendo más accesible, hay más oportunidades para aplicar esta tecnología utilizando "componentes estándar". Por ejemplo, Transfer Learning le permite utilizar la experiencia adquirida en la resolución de un problema para resolver otro problema similar. La red neuronal se entrena primero en una gran cantidad de datos, luego en el conjunto objetivo.

En este artículo, le diré cómo usar el método Transfer Learning utilizando el ejemplo de reconocimiento de imágenes con alimentos. Hablaré sobre otras herramientas de aprendizaje automático en
el taller de
Aprendizaje automático y Redes neuronales para desarrolladores .
Si nos enfrentamos a la tarea de reconocimiento de imágenes, puede utilizar el servicio listo para usar. Sin embargo, si necesita entrenar el modelo en su propio conjunto de datos, deberá hacerlo usted mismo.
Para tareas típicas como la clasificación de imágenes, puede usar la arquitectura preparada (AlexNet, VGG, Inception, ResNet, etc.) y entrenar la red neuronal en sus datos. Ya existen implementaciones de tales redes que usan varios marcos, por lo que en esta etapa puede usar una de ellas como una caja negra, sin profundizar en el principio de su funcionamiento.
Sin embargo, las redes neuronales profundas exigen grandes cantidades de datos para la convergencia del aprendizaje. Y a menudo en nuestra tarea particular no hay suficientes datos para entrenar adecuadamente todas las capas de la red neuronal. Transferir aprendizaje resuelve este problema.
Transferir el aprendizaje para la clasificación de imágenes
Las redes neuronales que se usan para la clasificación generalmente contienen
N neuronas de salida en la última capa, donde
N es el número de clases. Tal vector de salida se trata como un conjunto de probabilidades de pertenecer a una clase. En nuestra tarea de reconocer imágenes de alimentos, la cantidad de clases puede diferir de la del conjunto de datos original. En este caso, tendremos que tirar por completo esta última capa y poner una nueva, con el número correcto de neuronas de salida
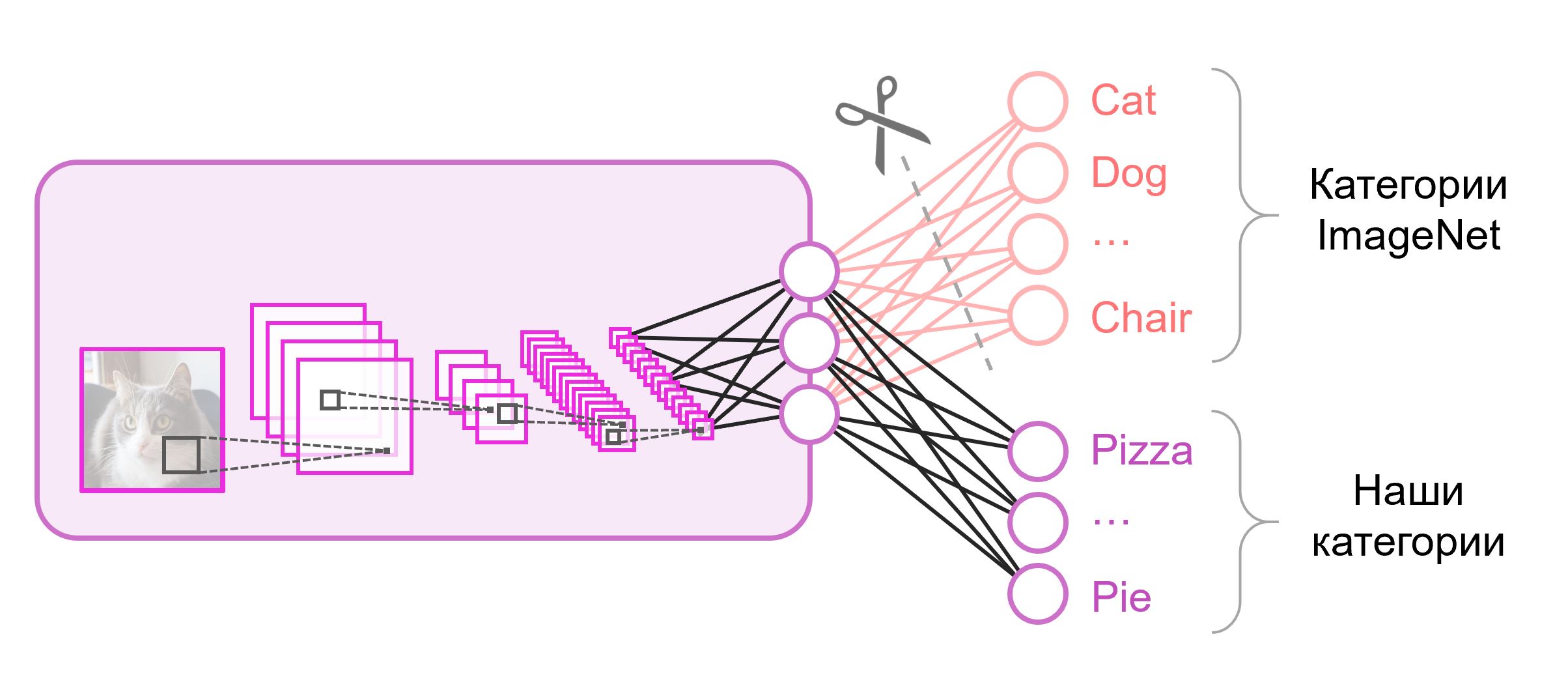
A menudo, al final de las redes de clasificación, se utiliza una capa totalmente conectada. Como reemplazamos esta capa, el uso de pesos pre-entrenados para ella no funcionará. Tendrás que entrenarlo desde cero, inicializando sus pesos con valores aleatorios. Cargamos pesos para todas las demás capas desde una instantánea pre-entrenada.
Hay varias estrategias para seguir entrenando el modelo. Usaremos lo siguiente: entrenaremos a toda la red de extremo a extremo (de
extremo a extremo ), y no fijaremos pesos pre-entrenados para permitir que se ajusten un poco y se ajusten a nuestros datos. Este proceso se llama
ajuste fino .
Componentes estructurales
Para resolver el problema, necesitamos los siguientes componentes:
- Descripción del modelo de red neuronal.
- Canal de aprendizaje
- Tubería de interferencia
- Pesas pre-entrenadas para este modelo
- Datos para entrenamiento y validación
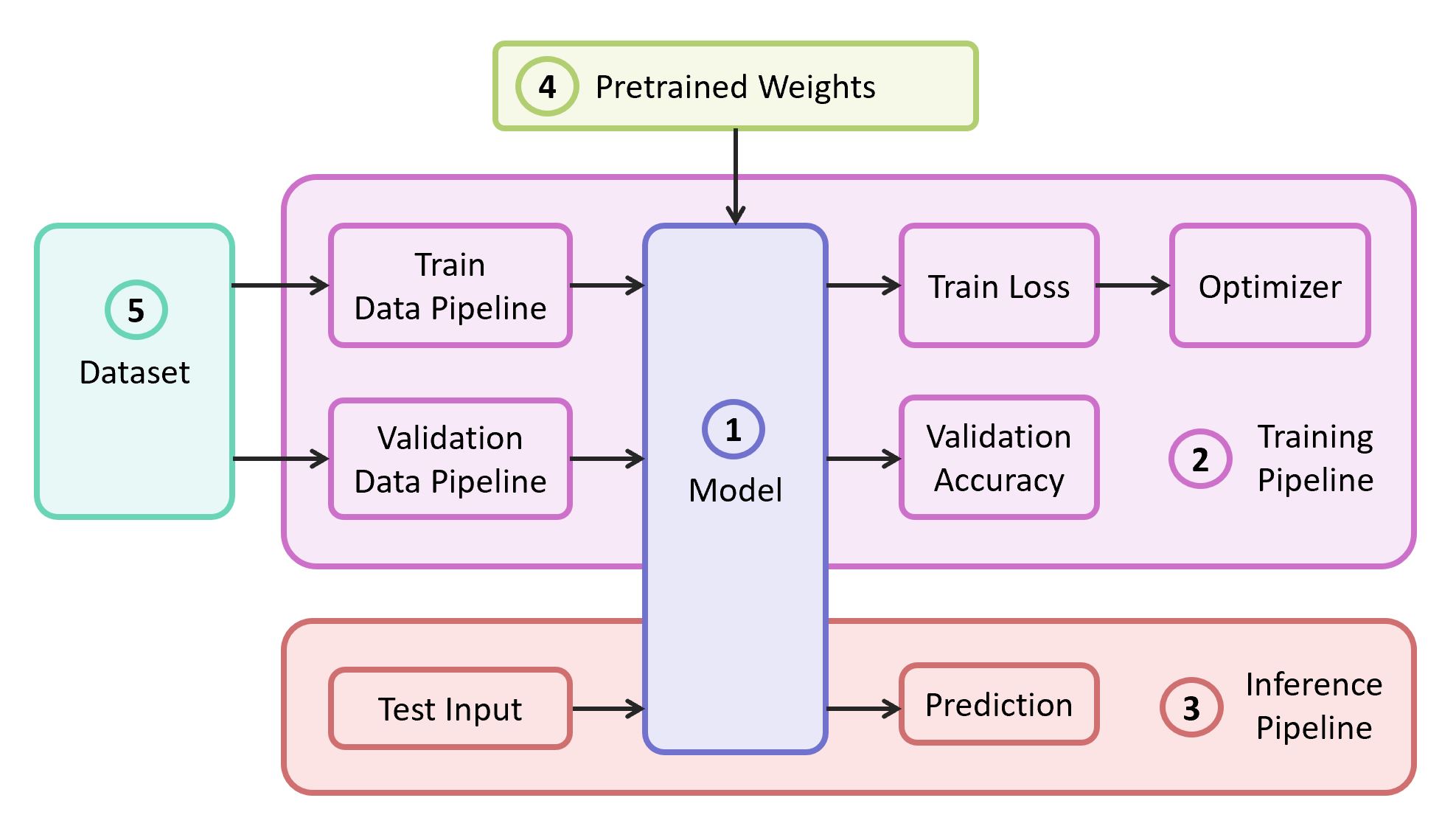
En nuestro ejemplo, tomaré los componentes (1), (2) y (3) de
mi propio repositorio , que contiene el código más liviano; puede resolverlo fácilmente si lo desea. Nuestro ejemplo se implementará en el popular marco
TensorFlow . Los pesos pre-entrenados (4) adecuados para el marco seleccionado se pueden encontrar si corresponden a una de las arquitecturas clásicas. Como conjunto de datos (5) para demostración, tomaré
Food-101 .
Modelo
Como modelo, utilizamos la clásica red neuronal
VGG (más precisamente,
VGG19 ). A pesar de algunas desventajas, este modelo demuestra una calidad bastante alta. Además, es fácil de analizar. En TensorFlow Slim, la descripción del modelo parece bastante compacta:
import tensorflow as tf import tensorflow.contrib.slim as slim def vgg_19(inputs, num_classes, is_training, scope='vgg_19', weight_decay=0.0005): with slim.arg_scope([slim.conv2d], activation_fn=tf.nn.relu, weights_regularizer=slim.l2_regularizer(weight_decay), biases_initializer=tf.zeros_initializer(), padding='SAME'): with tf.variable_scope(scope, 'vgg_19', [inputs]): net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1') net = slim.max_pool2d(net, [2, 2], scope='pool1') net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2') net = slim.max_pool2d(net, [2, 2], scope='pool2') net = slim.repeat(net, 4, slim.conv2d, 256, [3, 3], scope='conv3') net = slim.max_pool2d(net, [2, 2], scope='pool3') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv4') net = slim.max_pool2d(net, [2, 2], scope='pool4') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv5') net = slim.max_pool2d(net, [2, 2], scope='pool5')
Los pesos para VGG19, entrenados en ImageNet y compatibles con TensorFlow, se descargan del repositorio en GitHub desde la sección
Modelos pre-entrenados .
mkdir data && cd data wget http://download.tensorflow.org/models/vgg_19_2016_08_28.tar.gz tar -xzf vgg_19_2016_08_28.tar.gz
Datacet
Como muestra de capacitación y validación, utilizaremos el conjunto de datos público
Food-101 , que contiene más de 100 mil imágenes de alimentos, divididas en 101 categorías.

Descargue y descomprima el conjunto de datos:
cd data wget http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz tar -xzf food-101.tar.gz
La canalización de datos en nuestra capacitación está diseñada para que del conjunto de datos necesitemos analizar lo siguiente:
- Lista de clases (categorías)
- Tutorial: una lista de rutas a imágenes y una lista de respuestas correctas
- Conjunto de validación: lista de rutas a imágenes y lista de respuestas correctas
Si es su conjunto de datos, entonces para el
entrenamiento y la
validación necesita romper los conjuntos usted mismo. Food-101 ya tiene esa partición, y esta información se almacena en el
meta directorio.
DATASET_ROOT = 'data/food-101/' train_data, val_data, classes = data.food101(DATASET_ROOT) num_classes = len(classes)
Todas las funciones auxiliares responsables del procesamiento de datos se mueven a un archivo
data.py separado:
data.py from os.path import join as opj import tensorflow as tf def parse_ds_subset(img_root, list_fpath, classes): ''' Parse a meta file with image paths and labels -> img_root: path to the root of image folders -> list_fpath: path to the file with the list (eg train.txt) -> classes: list of class names <- (list_of_img_paths, integer_labels) ''' fpaths = [] labels = [] with open(list_fpath, 'r') as f: for line in f: class_name, image_id = line.strip().split('/') fpaths.append(opj(img_root, class_name, image_id+'.jpg')) labels.append(classes.index(class_name)) return fpaths, labels def food101(dataset_root): ''' Get lists of train and validation examples for Food-101 dataset -> dataset_root: root of the Food-101 dataset <- ((train_fpaths, train_labels), (val_fpaths, val_labels), classes) ''' img_root = opj(dataset_root, 'images') train_list_fpath = opj(dataset_root, 'meta', 'train.txt') test_list_fpath = opj(dataset_root, 'meta', 'test.txt') classes_list_fpath = opj(dataset_root, 'meta', 'classes.txt') with open(classes_list_fpath, 'r') as f: classes = [line.strip() for line in f] train_data = parse_ds_subset(img_root, train_list_fpath, classes) val_data = parse_ds_subset(img_root, test_list_fpath, classes) return train_data, val_data, classes def imread_and_crop(fpath, inp_size, margin=0, random_crop=False): ''' Construct TF graph for image preparation: Read the file, crop and resize -> fpath: path to the JPEG image file (TF node) -> inp_size: size of the network input (eg 224) -> margin: cropping margin -> random_crop: perform random crop or central crop <- prepared image (TF node) ''' data = tf.read_file(fpath) img = tf.image.decode_jpeg(data, channels=3) img = tf.image.convert_image_dtype(img, dtype=tf.float32) shape = tf.shape(img) crop_size = tf.minimum(shape[0], shape[1]) - 2 * margin if random_crop: img = tf.random_crop(img, (crop_size, crop_size, 3)) else:
Entrenamiento modelo
El código de entrenamiento modelo consta de los siguientes pasos:
- Construcción de tuberías de datos de validación / tren
- Construcción de trenes / gráficos de validación (redes)
- Adjunto de la función de clasificación de pérdidas ( pérdida de entropía cruzada ) sobre el gráfico del tren
- El código necesario para calcular la precisión de las predicciones en la muestra de validación durante el entrenamiento
- Lógica para cargar escalas pre-entrenadas desde una instantánea
- Creación de diversas estructuras para la formación.
- El ciclo de aprendizaje en sí (optimización iterativa)
La última capa del gráfico se construye con el número requerido de neuronas y se excluye de la lista de parámetros cargados de la instantánea pre-entrenada.
Código de entrenamiento modelo import numpy as np import tensorflow as tf import tensorflow.contrib.slim as slim tf.logging.set_verbosity(tf.logging.INFO) import model import data
Después de comenzar el entrenamiento, puede ver su progreso utilizando la utilidad TensorBoard, que viene incluida con TensorFlow y sirve para visualizar varias métricas y otros parámetros.
tensorboard --logdir checkpoints/
Al final del entrenamiento en TensorBoard, vemos una imagen casi perfecta: una disminución en
la pérdida de trenes y un aumento en la
precisión de validación
Como resultado, obtenemos la instantánea guardada en
checkpoints/vgg19_food de
checkpoints/vgg19_food , que usaremos durante la prueba de nuestro modelo (
inferencia ).
Prueba de modelo
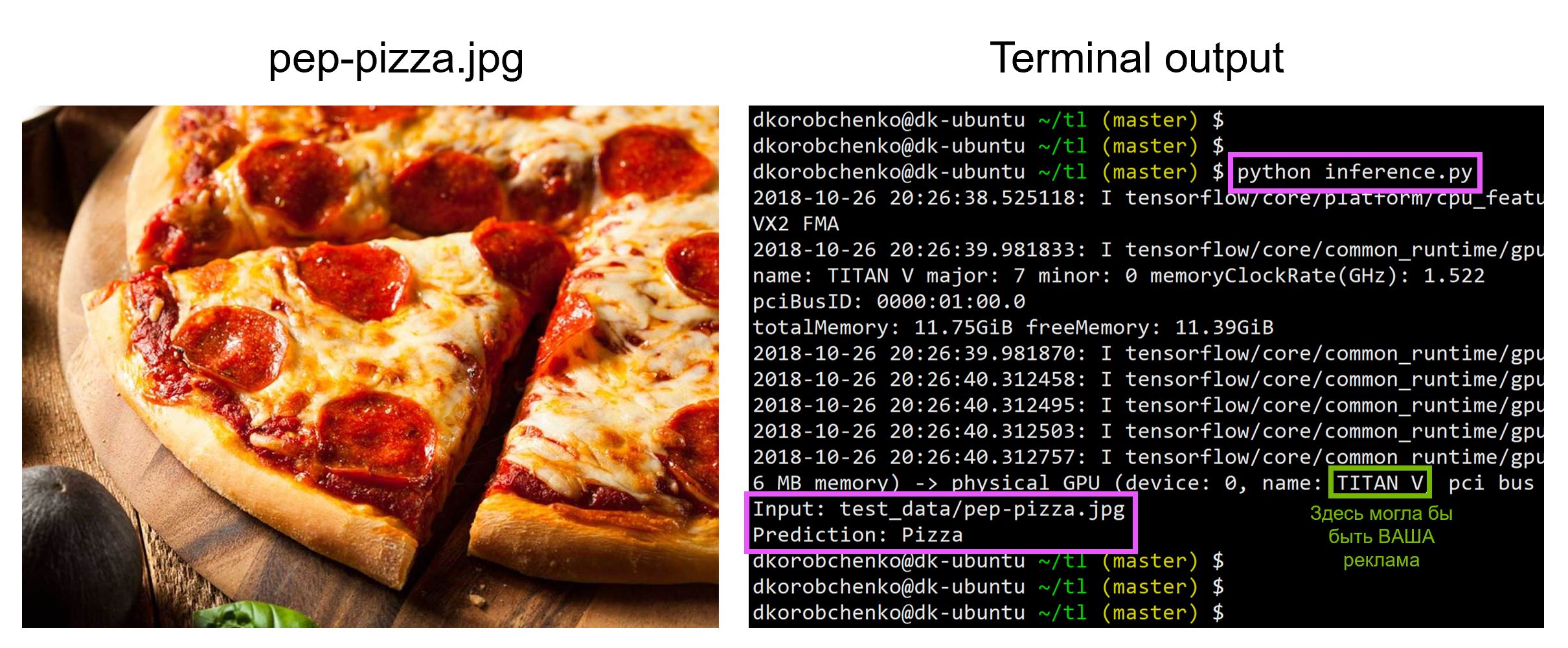
Ahora prueba nuestro modelo. Para hacer esto:
- Construimos un nuevo gráfico diseñado específicamente para inferencia (
is_training=False ) - Cargue pesas entrenadas desde una instantánea
- Descargue y procese previamente la imagen de prueba de entrada.
- Conduzcamos la imagen a través de la red neuronal y obtengamos la predicción
inferencia.py import sys import numpy as np import imageio from skimage.transform import resize import tensorflow as tf import model
Todo el código, incluidos los recursos para crear y ejecutar un contenedor Docker con todas las versiones necesarias de las bibliotecas, se encuentra en
este repositorio ; en el momento de leer el artículo, el código en el repositorio puede tener actualizaciones.
En el taller
"Aprendizaje automático y redes neuronales para desarrolladores" analizaré otras tareas del aprendizaje automático y los estudiantes presentarán sus proyectos al final de la sesión intensiva.