
En la Conferencia de IA,
Vladimir Ivanov vivanov879 , Sr. , hablará sobre el uso del aprendizaje reforzado
Ingeniero de aprendizaje profundo en Nvidia . El experto se dedica al aprendizaje automático en el departamento de pruebas: “Analizo los datos que recopilamos durante las pruebas de videojuegos y hardware. Para esto utilizo el aprendizaje automático y la visión por computadora. La parte principal del trabajo es el análisis de imágenes, la limpieza de datos antes de la capacitación, el marcado de datos y la visualización de las soluciones obtenidas ".
En el artículo de hoy, Vladimir explica por qué el aprendizaje reforzado se usa en automóviles autónomos y habla sobre cómo un agente está capacitado para actuar en un entorno cambiante, utilizando ejemplos de videojuegos.
En los últimos años, la humanidad ha acumulado una gran cantidad de datos. Algunos conjuntos de datos se comparten y se presentan manualmente. Por ejemplo, el conjunto de datos CIFAR, donde se firma cada imagen, a qué clase pertenece.
Hay conjuntos de datos en los que debe asignar una clase no solo a la imagen en su conjunto, sino a cada píxel de la imagen. Como, por ejemplo, en CityScapes.

Lo que une estas tareas es que una red neuronal de aprendizaje solo necesita recordar los patrones en los datos. Por lo tanto, con cantidades suficientemente grandes de datos, y en el caso de CIFAR son 80 millones de imágenes, la red neuronal está aprendiendo a generalizar. Como resultado, se las arregla bien con la clasificación de imágenes que nunca había visto antes.
Pero actuando dentro del marco de la técnica de enseñanza con el maestro, que funciona para marcar imágenes, es imposible resolver problemas donde no queremos predecir la marca, sino tomar decisiones. Como, por ejemplo, en el caso de la conducción autónoma, donde la tarea es llegar de manera segura y confiable al punto final de la ruta.
En los problemas de clasificación, utilizamos la técnica de enseñanza con el maestro, cuando a cada imagen se le asigna una clase específica. Pero, ¿qué pasa si no tenemos ese marcado, pero hay un agente y un entorno en el que puede realizar ciertas acciones? Por ejemplo, que sea un videojuego, podemos hacer clic en las flechas de control.

Este tipo de problema debe resolverse con entrenamiento de refuerzo. En el enunciado general del problema, queremos aprender a realizar la secuencia correcta de acciones. Es fundamental que el agente tenga la capacidad de realizar acciones una y otra vez, explorando así el entorno en el que se encuentra. Y en lugar de la respuesta correcta, qué hacer en una situación particular, recibe una recompensa por una tarea completada correctamente. Por ejemplo, en el caso de un taxi autónomo, el conductor recibirá una bonificación por cada viaje realizado.
Volvamos a un ejemplo simple: un videojuego. Tome algo simple, como el juego de tenis de mesa Atari.
Controlaremos la tableta a la izquierda. Jugaremos contra el jugador de la computadora programado en las reglas de la derecha. Dado que estamos trabajando con una imagen, y las redes neuronales son las más exitosas en extraer información de las imágenes, apliquemos una imagen a la entrada de una red neuronal de tres capas con un tamaño de núcleo de 3x3. A la salida, tendrá que elegir una de dos acciones: mover el tablero hacia arriba o hacia abajo.
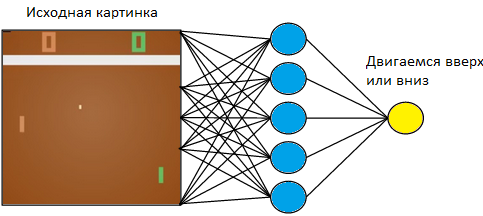
Entrenamos la red neuronal para realizar acciones que conduzcan a la victoria. La técnica de entrenamiento es la siguiente. Dejamos que la red neuronal juegue algunas rondas de tenis de mesa. Luego comenzamos a ordenar los juegos jugados. En los juegos en los que ganó, marcamos las imágenes con la etiqueta "Arriba" donde levantó la raqueta y "Abajo" donde la bajó. En los juegos perdidos, hacemos lo contrario. Marcamos esas imágenes donde bajó el tablero con la etiqueta "Arriba", y donde lo levantó, "Abajo". Por lo tanto, reducimos el problema al enfoque que ya conocemos: capacitación con un maestro. Tenemos un conjunto de imágenes con etiquetas.
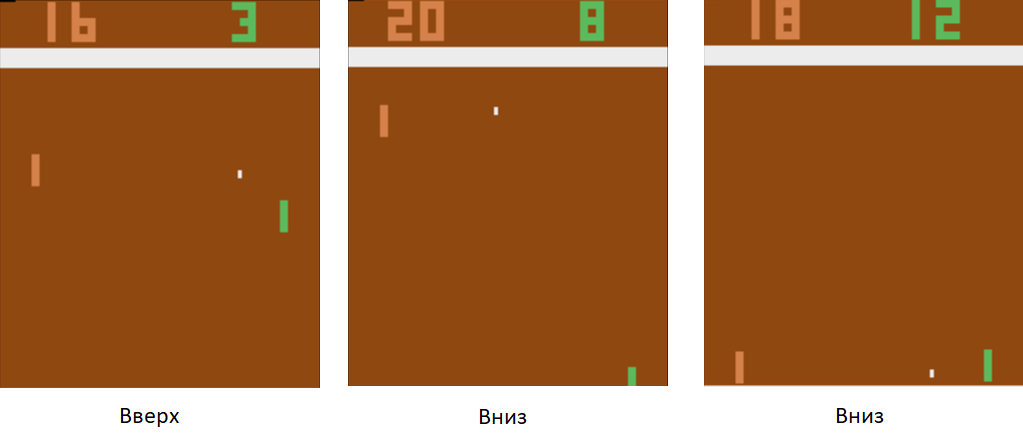
Usando esta técnica de entrenamiento, en un par de horas, nuestro agente aprenderá a vencer a un jugador de computadora programado en las reglas.
¿Qué hacer con la conducción autónoma? El hecho es que el tenis de mesa es un juego muy simple. Y puede producir miles de cuadros por segundo. En nuestra red ahora solo hay 3 capas. Por lo tanto, el proceso de aprendizaje es muy rápido. El juego genera una gran cantidad de datos y los procesamos instantáneamente. En el caso de la conducción autónoma, la recopilación de datos es mucho más larga y costosa. Los autos son caros, y con un solo automóvil recibiremos solo 60 cuadros por segundo. Además, aumenta el precio del error. En un videojuego, podríamos permitirnos jugar juego tras juego al comienzo del entrenamiento. Pero no podemos permitirnos estropear el auto.
En este caso, ayudemos a la red neuronal al comienzo del entrenamiento. Arreglamos la cámara en el automóvil, colocamos un conductor experimentado y grabaremos fotos de la cámara. Para cada imagen, suscribimos el ángulo de dirección del automóvil. Entrenaremos la red neuronal para copiar el comportamiento de un conductor experimentado. Por lo tanto, nuevamente redujimos la tarea a la enseñanza ya conocida con un maestro.
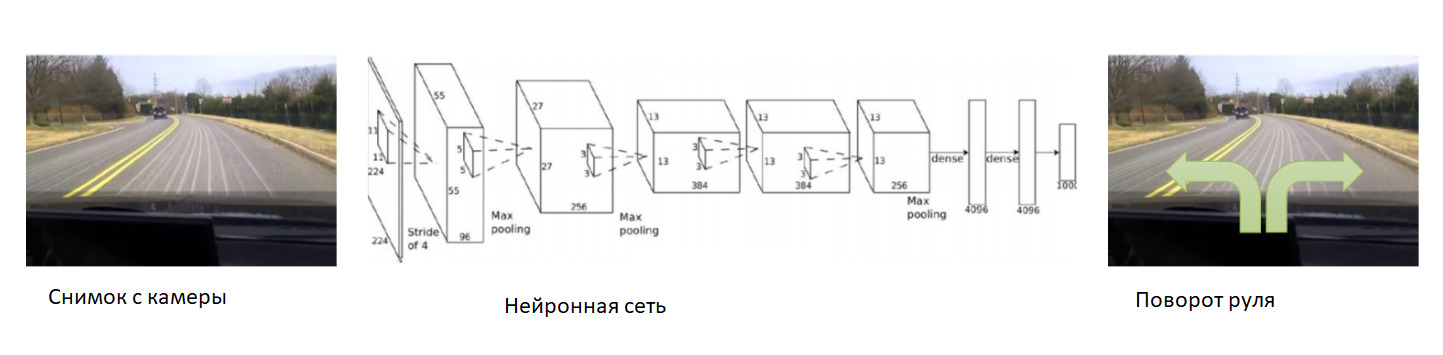
Con un conjunto de datos lo suficientemente grande y diverso, que incluirá diferentes paisajes, estaciones y condiciones climáticas, la red neuronal aprenderá a controlar con precisión el automóvil.
Sin embargo, hubo un problema con los datos. Son muy largos y caros de recolectar. Usemos un simulador en el que se implementará toda la física del movimiento del automóvil, por ejemplo, DeepDrive. Podemos aprenderlo sin temor a perder un automóvil.

En este simulador, tenemos acceso a todos los indicadores del automóvil y del mundo. Además, todas las personas, automóviles, sus velocidades y distancias a ellos están marcados alrededor.

Desde el punto de vista del ingeniero, en dicho simulador, puede probar con seguridad nuevas técnicas de entrenamiento. ¿Qué debe hacer un investigador? Por ejemplo, estudiar diferentes opciones para el descenso de gradiente en problemas de aprendizaje con refuerzo. Para probar una hipótesis simple, no quiero disparar gorriones desde un cañón y ejecutar un agente en un mundo virtual complejo, y luego esperar días a la vez para obtener los resultados de la simulación. En este caso, usemos nuestra potencia informática de manera más eficiente. Deje que los agentes sean más simples. Tomemos, por ejemplo, un modelo de araña de cuatro patas. En el simulador de Mujoco, se ve así:

Le asignamos la tarea de correr a la mayor velocidad posible en una dirección determinada, por ejemplo, a la derecha. El número de parámetros observados para una araña es un vector de 39 dimensiones, que registra la posición y la velocidad de todas sus extremidades. A diferencia de la red neuronal para el tenis de mesa, donde solo había una neurona en la salida, hay ocho en la salida (ya que la araña en este modelo tiene 8 articulaciones).
En tales modelos simples, se pueden probar varias hipótesis sobre la técnica de enseñanza. Por ejemplo, comparemos la velocidad de aprendizaje para correr, según el tipo de red neuronal. Sea una red neuronal de una capa, una red neuronal de tres capas, una red convolucional y una red recurrente:
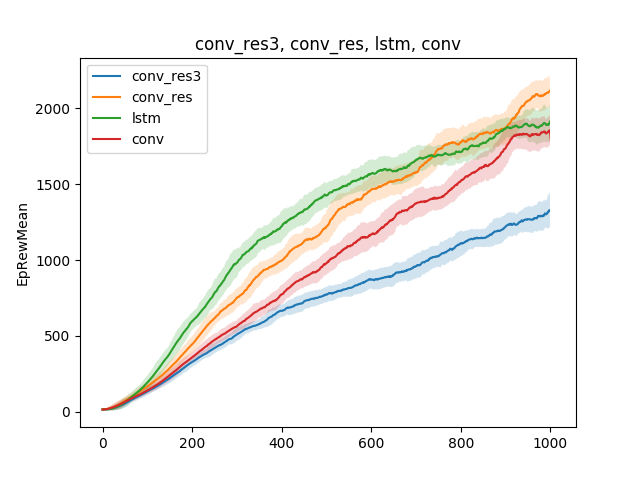
La conclusión se puede extraer de la siguiente manera: dado que el modelo de araña y la tarea son bastante simples, los resultados de la capacitación son aproximadamente los mismos para diferentes modelos. Una red de tres capas es demasiado compleja y, por lo tanto, aprende peor.
A pesar del hecho de que el simulador funciona con un modelo de araña simple, dependiendo de la tarea planteada a la araña, el entrenamiento puede durar días. En este caso, animemos varios cientos de arañas en una superficie al mismo tiempo en lugar de una y aprendamos de los datos que recibiremos de todos. Así que aceleraremos el entrenamiento varios cientos de veces. Aquí hay un ejemplo del motor Flex.
Lo único que ha cambiado en términos de optimización de redes neuronales es la recopilación de datos. Cuando solo ejecutamos una araña, recibimos datos secuencialmente. Una carrera tras otra.

Ahora puede suceder que algunas arañas recién estén comenzando la carrera, mientras que otras han estado corriendo durante mucho tiempo.
Tendremos esto en cuenta durante la optimización de la red neuronal. De lo contrario, todo sigue igual. Como resultado, obtenemos aceleración en el entrenamiento cientos de veces, de acuerdo con la cantidad de arañas que están simultáneamente en la pantalla.
Como tenemos un simulador efectivo, tratemos de resolver problemas más complejos. Por ejemplo, correr sobre terreno accidentado.

Dado que el entorno en este caso se ha vuelto más agresivo, cambiemos y compliquemos las tareas durante el entrenamiento. Es difícil de aprender, pero fácil en la batalla. Por ejemplo, cada pocos minutos para cambiar el terreno. Además, dirijamos los agentes externos al agente. Por ejemplo, vamos a lanzarle bolas y encender y apagar el viento. Luego, el agente aprende a correr incluso en superficies que nunca ha conocido. Por ejemplo, suba escaleras.

Como hemos aprendido tan efectivamente a correr en simulaciones, verifiquemos las técnicas de entrenamiento de refuerzo en disciplinas competitivas. Por ejemplo, en juegos de disparos. La plataforma VizDoom ofrece un mundo en el que puedes disparar, recoger armas y reponer salud. En este juego también usaremos una red neuronal. Solo que ahora tendrá cinco salidas: cuatro para movimiento y una para disparar.
Para que el entrenamiento sea efectivo, vamos a tomarlo gradualmente. De simple a complejo. En la entrada, la red neuronal recibe una imagen, y antes de comenzar a hacer algo consciente, debe aprender a comprender en qué consiste el mundo. Al estudiar en escenarios simples, aprenderá a comprender qué objetos habitan el mundo y cómo interactuar con ellos. Comencemos con el guión:
Una vez que domine este escenario, el agente comprenderá que hay enemigos, y que deberían ser disparados, porque obtienes puntos por ellos. Luego lo entrenaremos en un escenario donde la salud está disminuyendo constantemente y usted necesita reponerla.

Aquí aprenderá que tiene salud y necesita reponerse, porque en caso de muerte, el agente recibe una recompensa negativa. Además, aprenderá que si te mueves hacia el tema, puedes recogerlo. En el primer escenario, el agente no podía moverse.
Y en el tercer escenario final, dejemos que dispare con los robots programados en las reglas del juego para que pueda perfeccionar sus habilidades.

Durante el entrenamiento en este escenario, la selección correcta de las recompensas que recibe el agente es muy importante. Por ejemplo, si otorga una recompensa solo por los rivales derrotados, la señal será muy rara: si hay pocos jugadores alrededor, entonces recibiremos puntos cada pocos minutos. Por lo tanto, usemos la combinación de recompensas que existían antes. El agente recibirá una recompensa por cada acción útil, ya sea mejorar la salud, seleccionar cartuchos o golpear a un oponente.
Como resultado, un agente entrenado con recompensas bien elegidas es más fuerte que sus oponentes más exigentes computacionalmente. En 2016, dicho sistema ganó la competencia VizDoom con un margen de más de la mitad de los puntos anotados desde el segundo lugar. El segundo equipo también utilizó una red neuronal, solo con una gran cantidad de capas e información adicional del motor del juego durante el entrenamiento. Por ejemplo, información sobre si hay enemigos en el campo de visión del agente.
Hemos examinado enfoques para resolver problemas, donde es importante tomar decisiones. Pero muchas tareas con este enfoque permanecerán sin resolver. Por ejemplo, el juego de búsqueda Montezuma Revenge.
Aquí debe buscar las llaves para abrir las puertas de las habitaciones vecinas. Raramente recibimos llaves, y abrimos habitaciones incluso con menos frecuencia. También es importante no distraerse con objetos extraños. Si entrena el sistema como lo hicimos en las tareas anteriores y da recompensas por enemigos vencidos, simplemente noqueará el cráneo rodante una y otra vez y no examinará el mapa. Si está interesado, puedo hablar sobre cómo resolver estos problemas en un artículo separado.
Puedes escuchar el discurso de Vladimir Ivanov en la Conferencia de AI el 22 de noviembre . Un programa detallado y entradas están disponibles en el
sitio web oficial del evento.
Lea la entrevista con Vladimir
aquí .