
Aquí está el primer libro originalmente en ruso en el que los secretos de la vida real del procesamiento de Big Data en las nubes se examinan con ejemplos reales.
La atención se centra en las soluciones de Microsoft Azure y AWS. Se consideran todas las etapas del trabajo: obtener datos preparados para el procesamiento en la nube, usar almacenamiento en la nube, herramientas de análisis de datos en la nube. Se presta especial atención a los servicios SAAS, se demuestran las ventajas de las tecnologías en la nube en comparación con las soluciones implementadas en servidores dedicados o máquinas virtuales.
El libro está diseñado para una amplia audiencia y servirá como un excelente recurso para el desarrollo de Azure, Docker y otras tecnologías indispensables, sin las cuales la empresa moderna es impensable.
Te invitamos a leer el pasaje "Descarga directa de datos de transmisión"
10.1 Arquitectura general
En el capítulo anterior, examinamos la situación en la que muchas aplicaciones cliente deben enviar una gran cantidad de mensajes que deben procesarse dinámicamente, colocarse en el repositorio y luego procesarse nuevamente en él. Al mismo tiempo, es necesario poder cambiar la lógica del procesamiento de datos y el flujo de almacenamiento sin tener que recurrir a cambiar el código del cliente. Y, por último, desde el punto de vista de las razones de seguridad, los clientes deberían tener el derecho de hacer una sola cosa: enviar mensajes o recibirlos, pero de ninguna manera leer datos o eliminar bases de datos, y no deberían tener derechos directos para escribir estos datos.
Dichas tareas son muy comunes en sistemas que trabajan con dispositivos IoT conectados a través de una conexión a Internet, así como en sistemas de análisis de registros en línea. Además de los requisitos enumerados anteriormente para nuestro servicio dedicado, hay dos requisitos más relacionados con los detalles de la "Internet de las cosas" y para garantizar el procesamiento confiable de mensajes. En primer lugar, el protocolo de interacción entre el cliente y el receptor del servicio debe ser muy simple para que pueda implementarse en un dispositivo con capacidades informáticas limitadas y memoria muy limitada (por ejemplo, Arduino, Intel Edison, STM32 Discovery y otras plataformas "inapropiadas", como como antes RaspberryPi). El siguiente requisito es la entrega confiable de mensajes independientemente de las posibles fallas en los servicios de procesamiento. Este es un requisito más fuerte que el requisito de alta confiabilidad. De hecho, para garantizar la confiabilidad general de todo el sistema, es necesario que la confiabilidad de todos sus componentes sea lo suficientemente alta y la adición de un nuevo componente no conduzca a un aumento notable en el número de fallas. Además de la falla en la infraestructura de la nube, puede ocurrir un error en el servicio creado por el usuario. E incluso entonces, el mensaje debe procesarse tan pronto como se restablezca el servicio del usuario. Para hacer esto, el servicio de recepción de flujo de mensajes debe almacenar de manera confiable el mensaje hasta que se procese o hasta que expire su vida útil (esto es necesario para evitar el desbordamiento de memoria durante un flujo continuo de mensajes). Un servicio con estas propiedades se llama Event Hub. Para los dispositivos IoT hay centros especializados (IoT Hub), que tienen una serie de otras propiedades que son muy importantes para usar en conjunto con los dispositivos de Internet de las cosas (por ejemplo, comunicación bidireccional desde un punto, enrutamiento de mensajes incorporado, "dobles digitales" del dispositivo y una serie de otros) Sin embargo, estos servicios aún están especializados y no los consideraremos en detalle.
Antes de pasar al concepto de concentración de mensajes, pasemos a las ideas subyacentes.
Supongamos que tenemos una fuente de mensajes (por ejemplo, solicitudes de un cliente) y un servicio que debería manejarlos. El procesamiento de una sola solicitud lleva tiempo y requiere recursos computacionales (CPU, memoria, IOPS). Además, durante el procesamiento de una solicitud, las solicitudes restantes no se pueden procesar. Para que las aplicaciones cliente no se congelen mientras esperan que se lance un servicio, es necesario separarlas con la ayuda de un servicio adicional que se encargará de almacenar los mensajes mientras esperan el procesamiento mientras están en la cola. Esta separación también es necesaria para aumentar la confiabilidad general del sistema. De hecho, el cliente envía un mensaje al sistema, pero el servicio de procesamiento puede "caerse", pero el mensaje no debe perderse, debe almacenarse en un servicio que sea más confiable que el servicio de procesamiento. La versión más simple de dicho servicio se llama cola (Fig. 10.1).
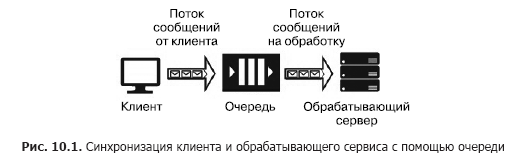
El servicio de cola funciona de la siguiente manera: el cliente conoce la URL de la cola y tiene claves de acceso. Usando el SDK o API de la cola, el cliente coloca un mensaje que contiene la marca de tiempo, el identificador y el cuerpo del mensaje con una carga útil en formato JSON, XML o binario.
El código del programa del servicio incluye un ciclo que "escucha" la cola, recuperando el siguiente mensaje en cada paso, y si hay un mensaje en la cola, se extrae y procesa. Si el servicio procesa con éxito el mensaje, se elimina de la cola. Si se produce un error durante el procesamiento, no se elimina y puede procesarse nuevamente cuando se inicia una nueva versión del servicio, con el código corregido. La cola está diseñada para sincronizar un cliente (o un grupo de clientes similares) y exactamente un servicio de procesamiento (aunque este último puede ubicarse en un clúster de servidores o en una granja de servidores). Los servicios de Cloud Queuing incluyen Azure Storage Queue, Azure Service Bus Queue y AWS SQS. Los servicios alojados en máquinas virtuales incluyen RabbitMQ, ZeroMQ, MSMQ, IBM MQ, etc.
Los diferentes servicios de cola garantizan diferentes tipos de entrega de mensajes:
- Entrega de mensajes al menos una vez
- estrictamente entrega de una sola vez;
- entrega de mensajes mientras se mantiene el orden;
- entrega de mensajes sin mantener el orden.
La cola proporciona una entrega confiable de mensajes de una fuente a un servicio de procesamiento, es decir, interacción uno a uno. Pero, ¿qué sucede si es necesario enviar mensajes a varios servicios? En este caso, debe usar un servicio llamado "tema" (tema) (Fig. 10.2).
Un elemento importante de esta arquitectura son las "suscripciones". Esta es la ruta registrada en la sección a lo largo de la cual se envía el mensaje. Los mensajes son publicados en el tema por el cliente y transferidos a una de las suscripciones, de donde los extrae uno de los servicios y los procesa. Los temas proporcionan una arquitectura de interacción de servicio al cliente de uno a muchos. Ejemplos de tales servicios incluyen el tema del Bus de servicio de Azure y AWS SNS.
Ahora suponga que hay una gran cantidad de clientes heterogéneos que necesitan enviar muchos mensajes a varios servicios, es decir, necesitamos construir un sistema de interacción de muchos a muchos. Por supuesto, dicha arquitectura se puede construir utilizando varias secciones, pero dicha construcción no es escalable y requiere un esfuerzo de administración y monitoreo. Sin embargo, hay servicios separados: concentradores de mensajes (Fig. 10.3).
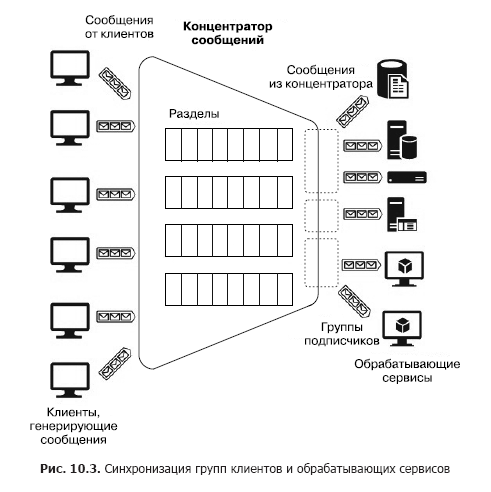
El centro acepta mensajes de muchos clientes. Todos los clientes pueden enviar mensajes a un punto final de servicio común o conectarse por separado a diferentes puntos finales a través de teclas especiales. Estas teclas le permiten administrar clientes de manera flexible: desconecte algunos, conecte otros nuevos, etc. Dentro del concentrador también hay particiones. Pero en este caso, se pueden distribuir entre todos los clientes para aumentar la productividad (round robin - "con adición cíclica") o el cliente puede publicar mensajes en una de las secciones. Por otro lado, los servicios de procesamiento se combinan en grupos de consumidores. Uno o varios servicios se pueden conectar a un grupo. Por lo tanto, un concentrador de mensajes es el servicio más flexible que se puede configurar como una cola, sección o grupo de colas, o un conjunto de secciones. En general, un concentrador de mensajes proporciona una relación de muchos a muchos entre clientes y servicios. Estos centros incluyen Apache Kafka, Azure Event Hub y AWS Kinesis Stream.
Antes de mirar los servicios de PaaS basados en la nube, prestaremos atención a un servicio muy poderoso y conocido: Apache Kafka. En entornos de nube, se puede acceder como una distribución implementada directamente en un clúster de máquinas virtuales o utilizando el servicio HDInsight. Entonces, Apache Kafka es un servicio que proporciona las siguientes características:
- Publicar y suscribirse a un flujo de mensajes
- almacenamiento confiable de mensajes;
- Aplicación de servicios de procesamiento de mensajes de transmisión de terceros.
Físicamente, Kafka se ejecuta en un clúster de uno o más servidores. Kafka proporciona una API para interactuar con clientes externos (Fig. 10.4).
Considere estas API en orden.
- Las API de proveedores permiten que las aplicaciones cliente publiquen flujos de mensajes en uno o más temas de Kafka.
- Las API del consumidor brindan a las aplicaciones del cliente la capacidad de suscribirse a uno o más temas y procesar los flujos de mensajes entregados por los temas a los clientes.
- Las API del procesador de transmisión permiten que las aplicaciones interactúen con el clúster Kafka como procesador de transmisión. Las fuentes para un procesador pueden ser uno o más temas. En este caso, los mensajes procesados también se colocan en uno o más temas.
- Las API de conector ayudan a conectar fuentes de datos externas (por ejemplo, RDB) como fuentes de mensajes (por ejemplo, es posible interceptar eventos de cambio de datos en la base de datos) y como receptores.
En Kafka, la interacción entre los clientes y el clúster se realiza a través de TCP, que se ve facilitada por los SDK existentes para varios lenguajes de programación, incluido .Net. Pero los lenguajes básicos del SDK son Java y Scala.
En un clúster, el almacenamiento de flujos de mensajes (en la terminología de Kafka también denominada entradas) se produce lógicamente en objetos llamados temas (Fig. 10.5). Cada registro consta de una clave, un valor y una marca de tiempo. En esencia, un tema es una secuencia de registros (mensajes) que han sido publicados por los clientes. Los temas de Kafka admiten de 0 a varios suscriptores. Cada tema se representa físicamente como un registro particionado. Cada sección es una secuencia ordenada de registros, a los que se agregan constantemente nuevos que llegan a la entrada de Kafka.
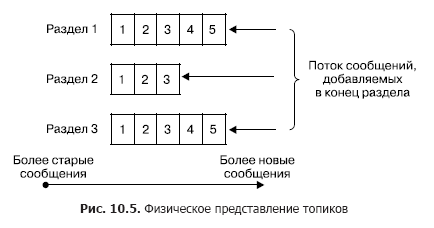
Cada entrada en la sección corresponde a un número en la secuencia, también llamado desplazamiento, que identifica de manera única este mensaje en la secuencia. A diferencia de la cola, Kafka elimina el mensaje no después de procesar el servicio, sino después de la vida útil de los mensajes. Esta es una propiedad muy importante, ya que brinda la capacidad de leer un tema a diferentes consumidores. Además, se asocia un sesgo con cada consumidor (Fig. 10.6). Y cada acto de lectura solo conduce a un aumento en el valor para cada cliente individualmente y es determinado precisamente por el cliente.
En el caso normal, este desplazamiento aumenta en uno después de leer con éxito un mensaje del tema. Pero si es necesario, el cliente puede cambiar este desplazamiento y repetir la operación de lectura.
Usar el concepto de secciones tiene los siguientes objetivos.
En primer lugar, las secciones proporcionan la capacidad de escalar temas cuando un tema no cabe dentro del mismo nodo. Al mismo tiempo, cada sección tiene un nodo principal (no lo confunda con el nodo principal de todo el clúster) y cero o varios nodos seguidores. El nodo principal es responsable del procesamiento de las operaciones de lectura / escritura, mientras que los seguidores son sus copias pasivas. Si el nodo maestro falla, uno de los nodos sucesores se convertirá automáticamente en el nodo principal. Cada nodo del clúster es el líder de algunas secciones y un seguidor de otras. En segundo lugar, dicha replicación aumenta el rendimiento de lectura debido a la posibilidad de operaciones de lectura paralelas.
El productor puede colocar el mensaje en cualquier tema de su elección explícitamente o en modo round robin implícitamente (es decir, con relleno uniforme). Los consumidores están unidos en los llamados grupos de consumidores, y cada mensaje publicado en el tema se entrega a un cliente en cada grupo de consumidores. Los clientes en este caso pueden alojarse físicamente en uno o más servidores / máquinas virtuales. Con más detalle, la entrega del mensaje es la siguiente. Para todos los clientes que pertenecen al mismo grupo de consumidores, los mensajes se pueden distribuir entre los clientes para optimizar la carga. Si los clientes pertenecen a diferentes grupos de consumidores, cada mensaje se enviará a cada grupo. La separación de mensajes de secciones por diferentes grupos de consumidores se muestra en la Fig. 10.7
Ahora describiré brevemente los principales parámetros de entrega y almacenamiento de mensajes garantizados por Kafka.
- Los mensajes enviados por el fabricante a un tema específico se agregarán estrictamente en el orden en que fueron enviados.
- El cliente ve el orden de los mensajes en el tema que se recibió cuando se guardaron los mensajes. Como resultado, los mensajes se entregan del productor al consumidor estrictamente en el orden en que se reciben.
- La replicación N-fold del tema garantiza la estabilidad del tema ante el fallo de los nodos N-1 sin pérdida de rendimiento.
Por lo tanto, el servicio Apache Kafka se puede usar en los siguientes modos.
- Servicio: agente de mensajes (cola) o servicio de publicación: suscripción de mensajes (tema). De hecho, Kafka se basa en un grupo de temas que se pueden convertir en una cola con un suscriptor. (Debe recordarse: en contraste con los servicios habituales de intermediario de mensajes, basados en el principio de las colas, en Kafka los mensajes se eliminan solo después de que su vida haya expirado, mientras que los intermediarios implementan el principio Peek-Delete, es decir, recuperación y eliminación después de un procesamiento exitoso. ) El principio de grupos de consumidores resume estos dos conceptos, y la capacidad de publicar mensajes en todos los temas con la distribución de round robin hace de Kafka un agente de mensajes universal multimodo.
- Servicio de análisis de mensajes en streaming. Esto es posible gracias a la API para procesadores de transmisión incluidos en Kafka, que le permite construir sistemas complejos, creados sobre la base de Event Driven, con servicios que filtran mensajes o responden a ellos, así como servicios que agregan mensajes.
Todas estas propiedades permiten utilizar Kafka como un componente clave de una plataforma que funciona con la transmisión de datos y tiene grandes capacidades para construir sistemas complejos de procesamiento de mensajes. Pero al mismo tiempo, Kafka es bastante complicado en términos de implementación y configuración de un clúster de varios nodos, lo que requiere un esfuerzo administrativo significativo. Pero, por otro lado, dado que las ideas subyacentes a Kafka son muy adecuadas para construir sistemas, transmitir mensajes y recibir mensajes, los proveedores de la nube brindan servicios de PaaS que implementan estas ideas y ocultan todas las dificultades de construir y administrar un clúster de Kafka. Pero dado que estos servicios tienen una serie de restricciones en términos de personalización y expansión más allá de los límites asignados para los servicios, los proveedores de la nube proporcionan servicios especiales IaaS / PaaS para el despliegue físico de Kafka en un clúster de máquinas virtuales. En este caso, el usuario tiene una libertad casi completa de configuración y expansión. Estos servicios incluyen Azure HDInsight. Ya se ha mencionado anteriormente. Fue creado para, por un lado, proporcionar al usuario servicios del ecosistema Hadoop por su cuenta, sin envoltorios externos y, por otro lado, para aliviar las dificultades derivadas de la instalación, administración y configuración directa de IaaS. El alojamiento Docker está un poco apartado. Dado que este es un tema extremadamente importante, lo consideraremos, pero primero nos familiarizaremos con los servicios de PaaS implementados utilizando los conceptos básicos de Kafka.
10.2 Centro de eventos de Azure
Considere el servicio de concentrador de mensajes de Azure Event Hub. Es un servicio basado en el modelo PaaS. Varios grupos de clientes pueden actuar como orígenes de mensajes para Azure Event Hub (Figura 10.8). En primer lugar, este es un grupo muy grande de servicios en la nube cuyas salidas o disparadores se pueden configurar para enviar mensajes directamente al Event Hub. Estos pueden ser Stream Analytics Job, Event Grid y un grupo significativo de servicios que redirigen eventos: registros en Event Hub (creados principalmente con AppService: aplicación Api, aplicación web, aplicación móvil y aplicación de función).
Los mensajes entregados al concentrador pueden capturarse directamente y almacenarse en Blob Storage o Data Lake Store.
El siguiente grupo de fuentes son los clientes o dispositivos de software externos para los cuales no hay SDK de Azure Event Hub y que no pueden integrarse directamente con los servicios de Azure. Estos clientes incluyen principalmente dispositivos IoT. Pueden enviar mensajes al Event Hub a través de HTTPS o AMQP. La consideración de cómo conectar estos dispositivos está más allá del alcance de nuestro libro.
Finalmente, los clientes de software que generan mensajes y los envían a Event Hub mediante el SDK de Azure Event Hub. Este grupo incluye Azure PowerShell y la CLI de Azure.
Como receptores de mensajes (consumidores - "consumidores") del Event Hub, Stream Analytics Job o el servicio de integración Event Grid se pueden utilizar. Además, es posible recibir mensajes de clientes de software mediante el SDK de Azure Event Hub. Los consumidores se conectan al Event Hub utilizando el protocolo AMQP 1.0.
Considere los conceptos básicos de Azure Event Hub necesarios para comprender cómo usarlo y configurarlo. Cualquier fuente (también llamada editor en la documentación) que envíe un mensaje al concentrador debe usar el protocolo HTTPS o AMQP 1.0. La elección de un protocolo está determinada por el tipo de cliente, la red de comunicación y los requisitos de velocidad de mensajes. AMQP requiere una conexión permanente entre dos sockets TCP bidireccionales. Está protegido mediante el uso del protocolo de cifrado de la capa de transporte TLS o SSL / TLS. , , AMQP , HTTPS, . HTTPS.
, SAS (Shared Access Signature) tokens. SAS- SAS . SAS-, ( ).
256 . , .
, Event Hub. , , , -. EventHub (partitions). EventHub — , « — » (FIFO) (. 10.9).
— Event Hub. Event Hub 2 32 , Event Hub. , .
( ) , ( , — . ), (retention period), . . . , Azure Event Hub (offset). — , , , , . . Azure Event Hub SDK , , . -, .
, , , , . Azure Event Hub SDK , . , Storage Account. Azure, Event Hub, .
Event Hub (partition key), . — . , ( ) . , (round robin).
. , (consumer group) (. 10.11). . (view) ( ) , , . , . — 20, , .
. , . , (throughput unit). :
. , . . . Ten cuidado , , , Event Hub.
(namespace) (. 10.12).
»Se puede encontrar más información sobre el libro en
el sitio web del editor»
Contenidos»
ExtractoCupón de 20% de descuento para
vendedores ambulantes -
BigData