43 segundos fatales, que causaron la degradación diaria del servicioLa semana pasada ocurrió un
incidente en GitHub que degradó el servicio durante 24 horas y 11 minutos. El incidente no afectó a toda la plataforma, sino solo a unos pocos sistemas internos, lo que llevó a la visualización de información obsoleta e inconsistente. Finalmente, los datos del usuario no se perdieron, pero la reconciliación manual de varios segundos de escritura en la base de datos todavía está en progreso. Durante la mayor parte del bloqueo, GitHub tampoco pudo manejar webhooks, crear y publicar páginas de GitHub.
A todos en GitHub nos gustaría disculparnos sinceramente por los problemas que todos ustedes han encontrado. Conocemos su confianza en GitHub y estamos orgullosos de crear sistemas sostenibles que respaldan la alta disponibilidad de nuestra plataforma. Lo hemos decepcionado con este incidente y lo lamentamos profundamente. Aunque no podemos solucionar los problemas debido a la degradación de la plataforma GitHub durante mucho tiempo, podemos explicar las razones de lo que sucedió, hablar sobre las lecciones aprendidas y las medidas que permitirán a la compañía protegerse mejor de tales fallas en el futuro.
Antecedentes
La mayoría de los servicios de usuario de GitHub funcionan en nuestros propios
centros de datos . La topología del centro de datos está diseñada para proporcionar una red fronteriza confiable y expandible frente a varios centros de datos regionales que proporcionan el trabajo de los sistemas informáticos y de almacenamiento de datos. A pesar de los niveles de redundancia incorporados en los componentes físicos y lógicos del proyecto, todavía es posible que los sitios no puedan interactuar entre sí durante algún tiempo.
El 21 de octubre, a las 10:52 p.m. UTC, los trabajos de reparación programados para reemplazar el equipo óptico defectuoso de 100G resultaron en una pérdida de comunicación entre el nodo de red en la costa este (costa este de los EE. UU.) Y el principal centro de datos en la costa este. La conexión entre ellos se restableció después de 43 segundos, pero esta corta desconexión provocó una cadena de eventos que condujo a la degradación del servicio durante 24 horas y 11 minutos.
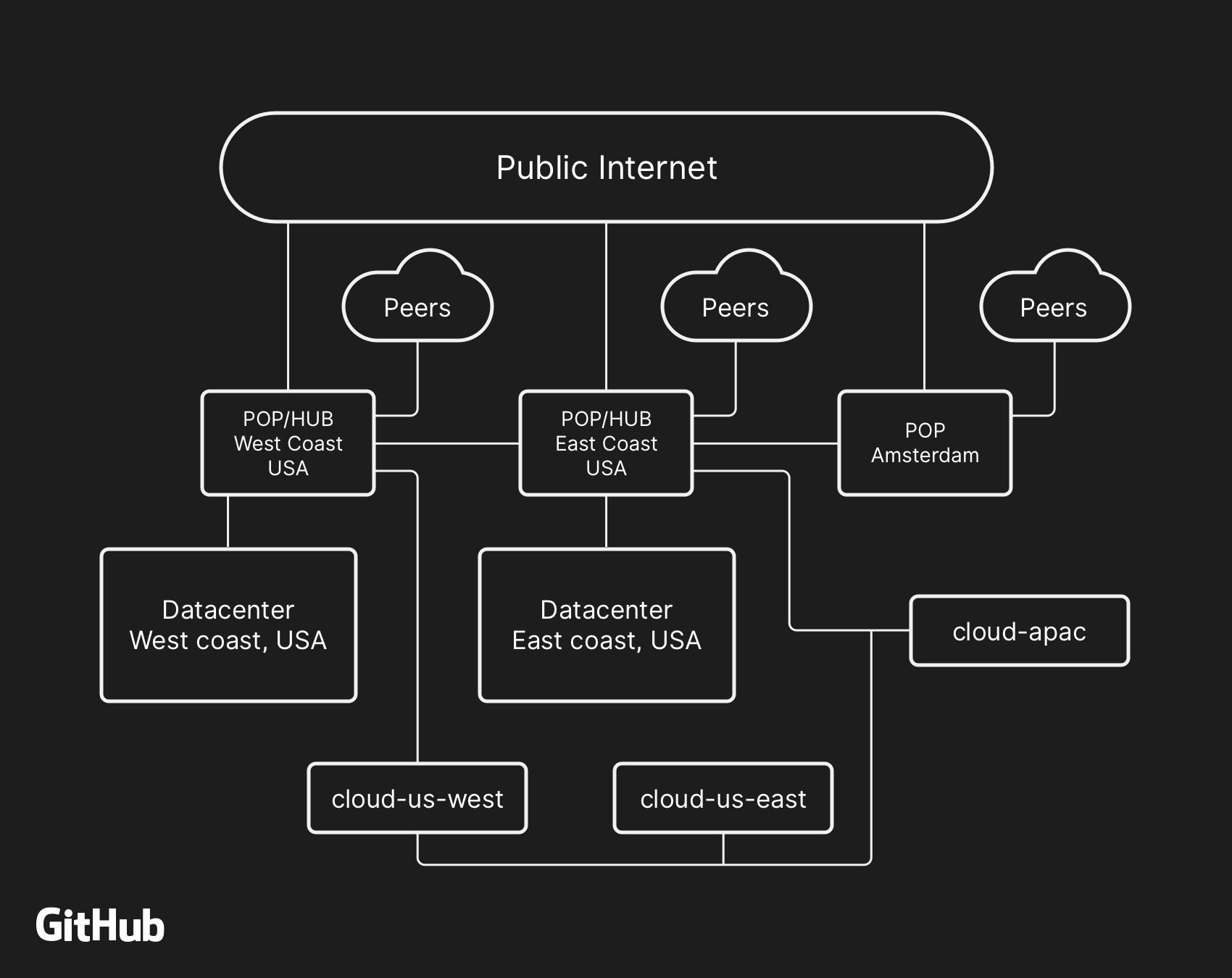 La arquitectura de red de alto nivel de GitHub, que incluye dos centros de datos físicos, 3 POP y almacenamiento en la nube en varias regiones, conectados a través del emparejamiento
La arquitectura de red de alto nivel de GitHub, que incluye dos centros de datos físicos, 3 POP y almacenamiento en la nube en varias regiones, conectados a través del emparejamientoEn el pasado, discutimos cómo usamos
MySQL para almacenar metadatos de GitHub , así como nuestro enfoque para proporcionar
alta disponibilidad para MySQL . GitHub gestiona varios clústeres MySQL que varían en tamaño desde cientos de gigabytes hasta casi cinco terabytes. Cada clúster tiene docenas de réplicas de lectura para almacenar metadatos que no sean Git, por lo que nuestras aplicaciones proporcionan solicitudes de grupo, problemas, autenticación, procesamiento en segundo plano y características adicionales fuera del repositorio de objetos Git. Diferentes datos en diferentes partes de la aplicación se almacenan en diferentes grupos utilizando segmentación funcional.
Para mejorar el rendimiento a gran escala, las aplicaciones escriben directamente en el servidor primario apropiado para cada clúster, pero en la gran mayoría de los casos delegan solicitudes de lectura a un subconjunto de servidores de réplica. Usamos
Orchestrator para administrar topologías de clúster MySQL y conmutar por error automáticamente. Durante este proceso, Orchestrator tiene en cuenta una serie de variables y se ensambla en la parte superior de
Raft para
mantener la coherencia. Orchestrator puede implementar potencialmente topologías que las aplicaciones no admiten, por lo que debe asegurarse de que su configuración de Orchestrator cumpla con las expectativas de nivel de aplicación.
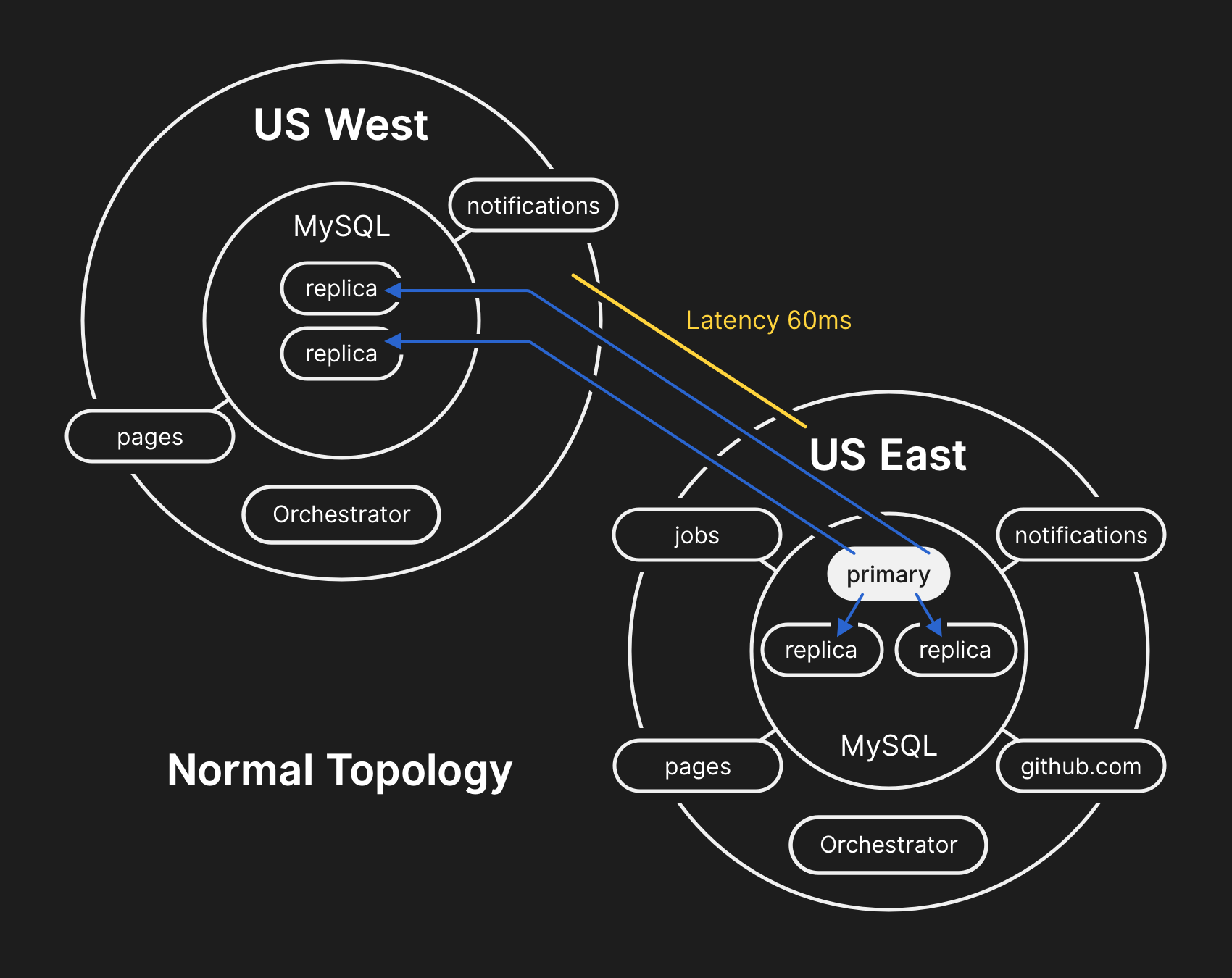 En una topología típica, todas las aplicaciones leen localmente con baja latencia.
En una topología típica, todas las aplicaciones leen localmente con baja latencia.Crónica del incidente.
10.21.2018, 22:52 UTC
Durante la separación de red mencionada anteriormente, Orchestrator en el centro de datos principal comenzó el proceso de deseleccionar el liderazgo de acuerdo con el algoritmo de consenso Raft. El centro de datos de la costa oeste y los nodos de la nube pública Orchestrator en la costa este lograron llegar a un consenso, y comenzaron a resolver las fallas de los clústeres para enviar registros al centro de datos occidental. Orchestrator comenzó a crear una topología de clúster de base de datos en Occidente. Después de reconectarse, las aplicaciones enviaron inmediatamente tráfico de escritura a los nuevos servidores primarios en el oeste de los EE. UU.
En los servidores de bases de datos en el centro de datos del este, hubo registros por un período corto que no se replicaron en el centro de datos del oeste. Dado que los grupos de bases de datos en ambos centros de datos ahora contenían registros que no estaban en el otro centro de datos, no pudimos devolver de manera segura el servidor primario al centro de datos oriental.
10.21.2018, 22:54 UTC
Nuestros sistemas de monitoreo interno comenzaron a generar alertas que indicaban numerosas fallas en el sistema. En este momento, varios ingenieros respondieron y trabajaron en ordenar las notificaciones entrantes. A las 23:02, los ingenieros del primer grupo de respuesta determinaron que las topologías para numerosos grupos de bases de datos estaban en un estado inesperado. Al consultar la API de Orchestrator, se mostraba la topología de replicación de la base de datos, que contenía solo servidores del centro de datos occidental.
10.21.2018, 23:07 UTC
En este punto, el equipo de respuesta decidió bloquear manualmente las herramientas de implementación internas para evitar cambios adicionales. A las 23:09, el grupo estableció el sitio en
amarillo . Esta acción asignó automáticamente a la situación el estado de un incidente activo y envió una advertencia al coordinador del incidente. A las 23:11, el coordinador se unió al trabajo y dos minutos después decidió
cambiar el estado a rojo .
10.21.2018, 23:13 UTC
En ese momento, estaba claro que el problema afectaba a varios grupos de bases de datos. Desarrolladores adicionales del grupo de ingeniería de la base de datos estuvieron involucrados en el trabajo. Comenzaron a examinar el estado actual para determinar qué acciones debían tomarse para configurar manualmente la base de datos de la costa este de los EE. UU. Como primaria para cada grupo y reconstruir la topología de replicación. Esto no fue fácil, porque en este punto el clúster de la base de datos occidental había estado recibiendo registros del nivel de aplicación durante casi 40 minutos. Además, en el grupo oriental, hubo varios segundos de registros que no se replicaron hacia el oeste y no permitieron la replicación de nuevos registros hacia el este.
Proteger la privacidad e integridad de los datos del usuario es la principal prioridad de GitHub. Por lo tanto, decidimos que más de 30 minutos de datos registrados en el centro de datos occidental nos dejan con una sola solución a la situación para guardar estos datos: transferir hacia adelante (fallar hacia adelante). Sin embargo, las aplicaciones en el este, que dependen de escribir información en el clúster MySQL occidental, actualmente no pueden manejar el retraso adicional debido a la transferencia de la mayoría de sus llamadas a la base de datos de un lado a otro. Esta decisión conducirá al hecho de que nuestro servicio será inadecuado para muchos usuarios. Creemos que la degradación a largo plazo de la calidad del servicio valió la pena garantizar la consistencia de los datos de nuestros usuarios.
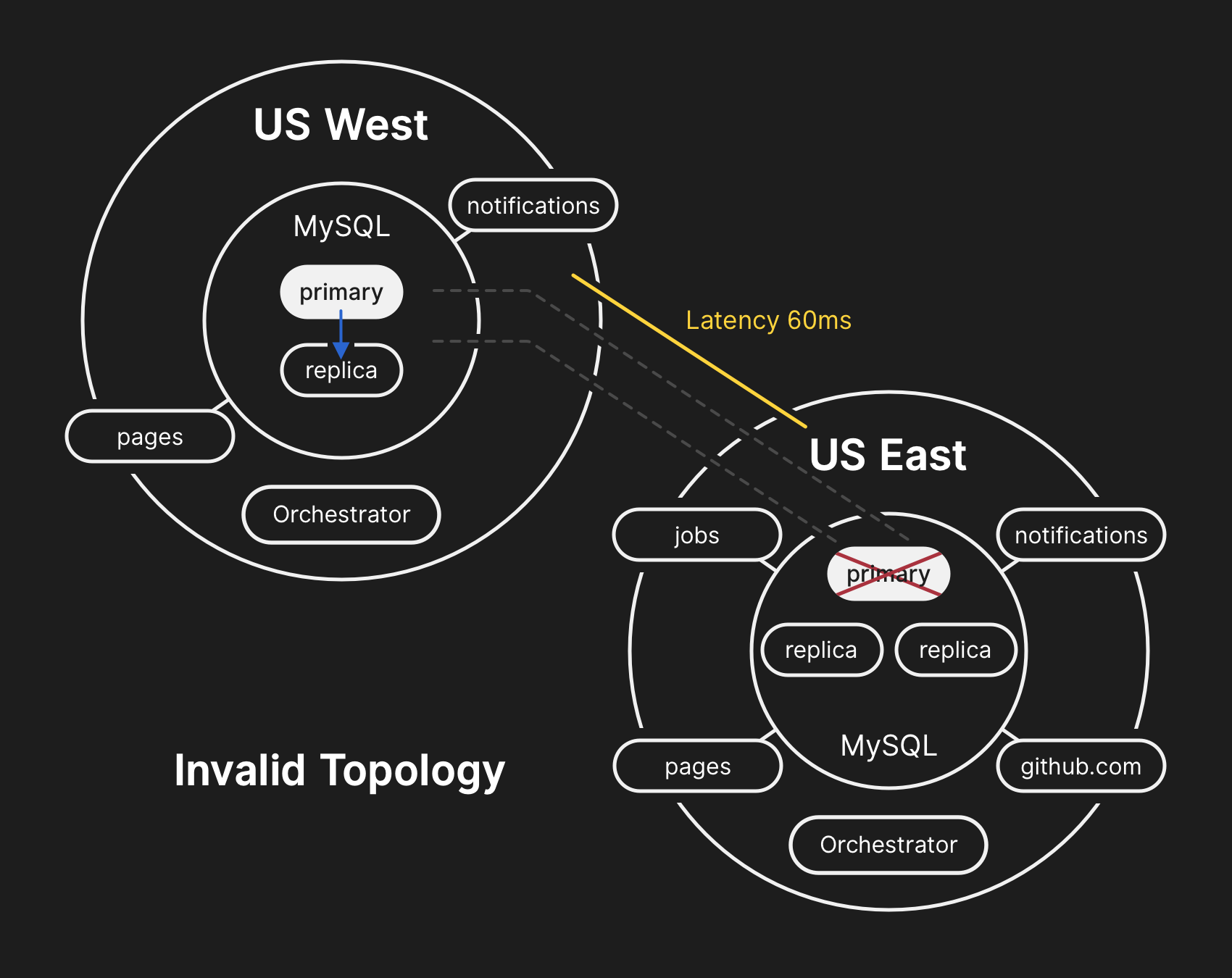 En la topología incorrecta, se viola la replicación de oeste a este, y las aplicaciones no pueden leer los datos de las réplicas actuales, porque dependen de una baja latencia para mantener el rendimiento de la transacción.
En la topología incorrecta, se viola la replicación de oeste a este, y las aplicaciones no pueden leer los datos de las réplicas actuales, porque dependen de una baja latencia para mantener el rendimiento de la transacción.10.21.2018, 23:19 UTC
Las consultas sobre el estado de los clústeres de bases de datos mostraron que es necesario detener la ejecución de tareas que escriben metadatos, como solicitudes push. Hicimos una elección y deliberadamente fuimos a una degradación parcial del servicio, suspendiendo los webhooks y el ensamblaje de las páginas de GitHub, para no comprometer los datos que ya recibimos de los usuarios. En otras palabras, la estrategia era priorizar: la integridad de los datos en lugar de la usabilidad del sitio y la recuperación rápida.
22/10/2018, 00:05 UTC
Los ingenieros del equipo de respuesta comenzaron a desarrollar un plan para resolver inconsistencias de datos y lanzaron procedimientos de conmutación por error para MySQL. El plan consistía en restaurar los archivos de la copia de seguridad, sincronizar las réplicas en ambos sitios, volver a una topología de servicio estable y luego reanudar los trabajos de procesamiento en la cola. Actualizamos el estado para informar a los usuarios que vamos a realizar una conmutación por error administrada del sistema de almacenamiento interno.
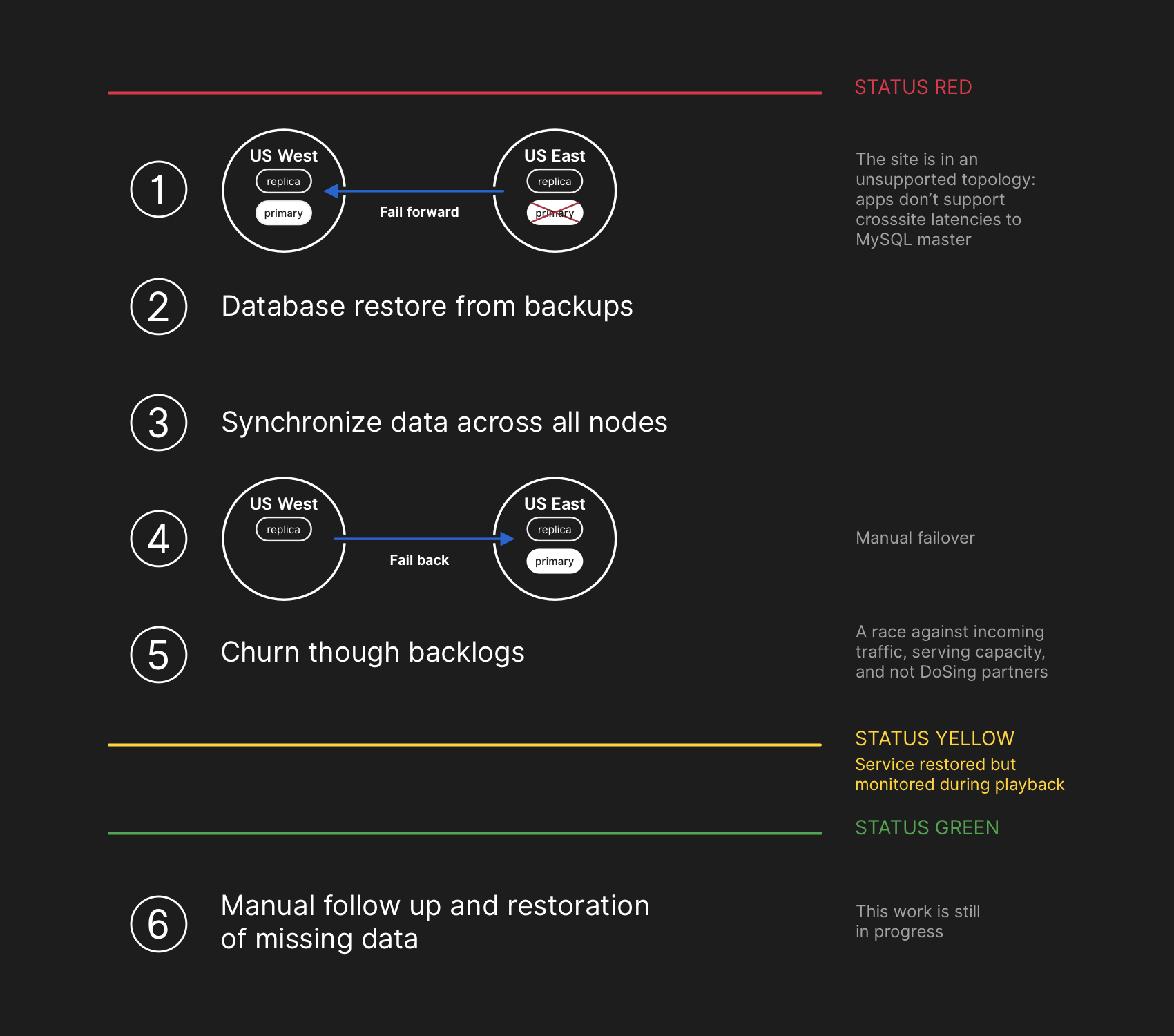 El plan de recuperación implicaba avanzar, restaurar desde las copias de seguridad, sincronizar, retroceder y solucionar el retraso antes de volver al estado verde
El plan de recuperación implicaba avanzar, restaurar desde las copias de seguridad, sincronizar, retroceder y solucionar el retraso antes de volver al estado verdeAunque las copias de seguridad de MySQL se realizan cada cuatro horas y se almacenan durante muchos años, se encuentran en un almacenamiento remoto en la nube de objetos blob. La recuperación de varios terabytes de una copia de seguridad tomó varias horas. La transferencia de datos desde el servicio de copia de seguridad remota llevó mucho tiempo. La mayor parte del tiempo se dedicó a desempaquetar, verificar la suma de verificación, preparar y cargar grandes archivos de respaldo en servidores MySQL recién preparados. Este procedimiento se prueba a diario, por lo que todos tenían una buena idea de cuánto tiempo tomaría la recuperación. Sin embargo, antes de este incidente, nunca tuvimos que reconstruir completamente el clúster completo a partir de una copia de seguridad. Otras estrategias siempre han funcionado, como las réplicas diferidas.
22/10/2018, 00:41 UTC
En este momento, se había iniciado un proceso de copia de seguridad para todos los clústeres MySQL afectados, y los ingenieros siguieron el progreso. Al mismo tiempo, varios grupos de ingenieros estudiaron formas de acelerar la transferencia y la recuperación sin una mayor degradación del sitio o el riesgo de corrupción de datos.
22/10/2018, 06:51 UTC
Varios grupos en el centro de datos del este completaron la recuperación de las copias de seguridad y comenzaron a replicar nuevos datos de la costa oeste. Esto condujo a una desaceleración en la carga de páginas que realizaron una operación de escritura en todo el país, pero leer páginas de estos grupos de bases de datos arrojó resultados reales si la solicitud de lectura caía en una réplica recién restaurada. Otros grupos de bases de datos más grandes continuaron recuperándose.
Nuestros equipos han identificado un método de recuperación directamente desde la costa oeste para superar las limitaciones de ancho de banda causadas por el arranque desde el almacenamiento externo. Se hizo casi 100% claro que la recuperación se completará con éxito, y el tiempo para crear una topología de replicación saludable depende de la cantidad de replicación de recuperación. Esta estimación se interpoló linealmente en función de la replicación de telemetría disponible, y la página de estado se
actualizó para establecer la espera de dos horas como el tiempo de recuperación estimado.
22/10/2018, 07:46 UTC
GitHub publicó una
publicación informativa en el blog . Nosotros mismos utilizamos las páginas de GitHub, y todas las asambleas se detuvieron hace unas horas, por lo que la publicación requirió un esfuerzo adicional. Pedimos disculpas por el retraso. Tenemos la intención de enviar este mensaje mucho antes y en el futuro proporcionaremos la publicación de actualizaciones en las condiciones de dichas restricciones.
22/10/2018, 11:12 UTC
Todas las bases de datos primarias se transfieren nuevamente al Este. Esto llevó al sitio a ser mucho más receptivo, ya que los registros ahora se enrutaron a un servidor de base de datos ubicado en el mismo centro de datos físicos que nuestra capa de aplicación. Aunque esto mejoró significativamente el rendimiento, todavía había docenas de réplicas de lectura de la base de datos que estaban varias horas detrás de la copia principal. Estas réplicas retrasadas han llevado a los usuarios a ver datos inconsistentes al interactuar con nuestros servicios. Distribuimos la carga de lectura en un gran conjunto de réplicas de lectura, y cada solicitud a nuestros servicios tiene buenas posibilidades de ingresar a la réplica de lectura con un retraso de varias horas.
De hecho, el tiempo de recuperación de una réplica retrasada se reduce exponencialmente, no linealmente. Cuando los usuarios en los EE. UU. Y Europa se despertaron, debido al aumento de la carga en los registros en los grupos de bases de datos, el proceso de recuperación tomó más tiempo de lo previsto.
22/10/2018, 13:15 UTC
Nos estábamos acercando a la carga máxima en GitHub.com. El equipo de respuesta discutió los siguientes pasos. Estaba claro que el retraso de la replicación a un estado constante está aumentando, no disminuyendo. Anteriormente, comenzamos a preparar réplicas de lectura MySQL adicionales en la nube pública de la costa este. Una vez que estuvieron disponibles, se hizo más fácil distribuir el flujo de solicitudes de lectura entre varios servidores. La reducción de la carga promedio en las réplicas de lectura aceleró la recuperación de la replicación.
22/10/2018, 16:24 UTC
Después de sincronizar las réplicas, volvimos a la topología original, eliminando los problemas de demora y disponibilidad. Como parte de una decisión consciente sobre la prioridad de la integridad de los datos sobre una corrección rápida de la situación,
mantuvimos el estado rojo del sitio cuando comenzamos a procesar los datos acumulados.
22/10/2018, 16:45 UTC
En la etapa de recuperación, era necesario equilibrar el aumento de la carga asociada con el trabajo atrasado, sobrecargando potencialmente a nuestros socios del ecosistema con notificaciones y volviendo a la eficiencia al cien por cien lo más rápido posible. Más de cinco millones de eventos de gancho y 80 mil solicitudes para crear páginas web permanecieron en la cola.
Cuando volvimos a habilitar el procesamiento de estos datos, procesamos alrededor de 200,000 tareas útiles con webhooks que excedieron el TTL interno y se eliminaron. Al enterarnos de esto, dejamos de procesar y comenzamos a aumentar el TTL.
Para evitar una disminución adicional en la confiabilidad de nuestras actualizaciones de estado, dejamos el estado de degradación hasta que terminemos de procesar toda la cantidad acumulada de datos y nos aseguremos de que los servicios hayan regresado claramente al nivel normal de rendimiento.
22/10/2018, 11:03 p.m. UTC
Se procesan todos los eventos de webhook incompletos y los ensambles de páginas, y se confirma la integridad y el funcionamiento correcto de todos los sistemas. El estado del sitio se ha
actualizado a verde .
Otras acciones
Resolviendo el desajuste de datos
Durante la recuperación, arreglamos registros binarios de MySQL con entradas principalmente del centro de datos, que no se replicaron en el occidental. El número total de tales entradas es relativamente pequeño. Por ejemplo, en uno de los grupos más activos, solo hay 954 registros en estos segundos. Actualmente estamos analizando estos registros y determinando qué entradas se pueden conciliar automáticamente y cuáles requieren asistencia del usuario. Varios equipos participan en este trabajo, y nuestro análisis ya ha determinado la categoría de registros que el usuario repitió, y se guardaron con éxito. Como se indicó en este análisis, nuestro objetivo principal es mantener la integridad y la precisión de los datos que almacena en GitHub.
Comunicación
Intentando transmitirle información importante durante el incidente, realizamos varias estimaciones públicas del tiempo de recuperación en función de la velocidad de procesamiento de los datos acumulados. Mirando hacia atrás, nuestras estimaciones no tuvieron en cuenta todas las variables. Pedimos disculpas por la confusión y nos esforzaremos por proporcionar información más precisa en el futuro.
Medidas técnicas
En el curso de este análisis, se identificaron varias medidas técnicas. El análisis continúa, la lista se puede complementar.
- Ajuste la configuración de Orchestrator para evitar que las bases de datos primarias se muevan fuera de la región. Orchestrator funcionaba de acuerdo con la configuración, aunque la capa de aplicación no admitía dicho cambio de topología. Elegir un líder dentro de una región generalmente es seguro, pero la aparición repentina de un retraso debido al flujo de tráfico en todo el continente se ha convertido en la causa principal de este incidente. Este es un comportamiento emergente y nuevo del sistema, porque antes no encontramos la sección interna de la red de esta magnitud.
- Hemos acelerado la migración al nuevo sistema de informes de estado, que proporcionará una plataforma más adecuada para discutir incidentes activos con formulaciones más precisas y claras. Aunque muchas partes de GitHub estuvieron disponibles durante todo el incidente, solo pudimos seleccionar los estados verde, amarillo y rojo para todo el sitio. Admitimos que esto no da una imagen precisa: qué funciona y qué no. El nuevo sistema mostrará los diversos componentes de la plataforma para que conozca el estado de cada servicio.
- Unas semanas antes de este incidente, lanzamos una iniciativa de ingeniería a nivel corporativo para respaldar el servicio del tráfico de GitHub desde múltiples centros de datos utilizando la arquitectura activa / activa / activa. El objetivo de este proyecto es soportar la redundancia N + 1 a nivel del centro de datos para resistir la falla de un centro de datos sin interferencia externa. Esto es mucho trabajo y llevará algún tiempo, pero creemos que varios centros de datos bien conectados en diferentes regiones proporcionarán un buen compromiso. El último incidente impulsó esta iniciativa aún más.
- Tomaremos una posición más activa al verificar nuestras suposiciones. GitHub está creciendo rápidamente y ha acumulado una considerable cantidad de complejidad durante la última década. Cada vez es más difícil capturar y transmitir a la nueva generación de empleados el contexto histórico de compromisos y decisiones tomadas.
Medidas organizativas
Este incidente influyó mucho en nuestra comprensión de la fiabilidad del sitio. Aprendimos que ajustar el control operativo o mejorar los tiempos de respuesta no son garantías suficientes de confiabilidad en un sistema de servicios tan complejo como el nuestro. Para respaldar estos esfuerzos, también comenzaremos una práctica sistemática de probar escenarios de fallas antes de que realmente ocurran. Este trabajo incluye la resolución de problemas deliberada y el uso de herramientas de ingeniería del caos.
Conclusión
Sabemos cómo confía en GitHub en sus proyectos y negocios. Nos preocupamos más que nadie por la disponibilidad de nuestro servicio y la seguridad de sus datos.
El análisis de este incidente continuará encontrando una oportunidad para servirle mejor y justificar su confianza.