En los comentarios
de nuestro último artículo , hubo muchas preguntas sobre las tecnologías que utilizamos. En este artículo, yo, Igor Mosyagin, desarrollador de I + D de Lamoda, les contaré sobre ellos. Debajo del corte, encontrará una lista exhaustiva de idiomas, herramientas, plataformas y tecnologías que han pasado por nuestras manos. El frontend, el backend, la base de datos, los corredores de mensajes, las memorias caché y el monitoreo, el desarrollo y el equilibrio son una descripción detallada de lo que usamos hoy y lo que hemos abandonado.
Mis colegas y yo estamos listos para discutir en los comentarios o en el stand de la compañía en HighLoad ++ 2018.
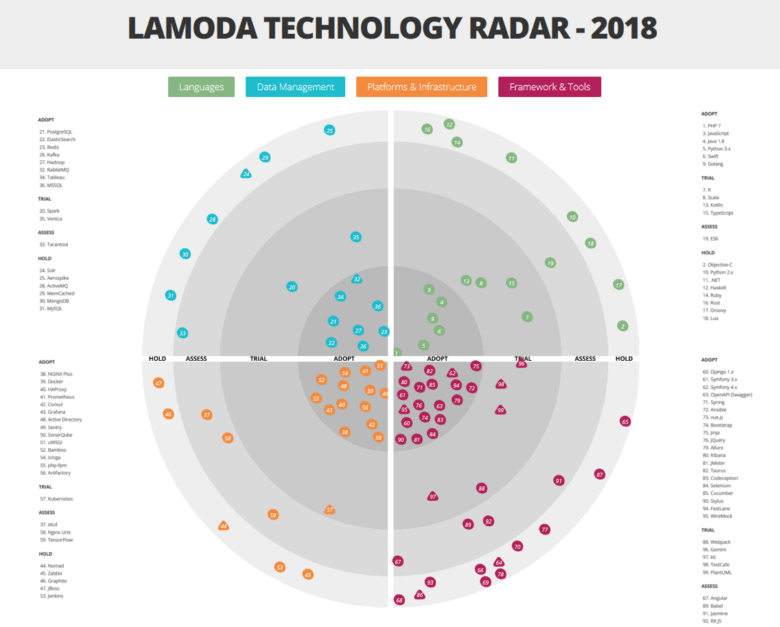
Ver el radar en grande y detallado aquí.Como ya dijimos, una gran cantidad de tecnologías y herramientas diferentes están involucradas en Lamoda. Y esto no es casualidad. De lo contrario, no podemos hacer frente a la carga! Tenemos un gran almacén automatizado. Nuestro centro de atención telefónica cuenta con 500 empleados, y los procesos que hemos creado nos permiten volver a llamar al cliente dentro de los 5 minutos posteriores a la realización del pedido. Nuestro servicio de entrega opera a intervalos de 15 minutos. Pero además de nuestros propios sistemas, tenemos integración B2B con otras tiendas en línea. Con una variedad de tareas y los requisitos de un negocio tan dinámico como el comercio electrónico, el crecimiento de la pila técnica es inevitable, porque queremos resolver cada problema con las tecnologías más adecuadas. La diversidad es inevitable. Hablaremos sobre los principales representantes de nuestra pila a continuación. Pero comencemos con los mecanismos que nos permiten no perdernos en esta variedad.
Esenciales de arquitectura
Estamos avanzando activamente hacia la arquitectura de microservicios. La mayoría de los sistemas ya se han construido de acuerdo con esta ideología: hace dos años pasamos por una etapa de transición con nuestros problemas y sus soluciones. Pero no nos detendremos en los detalles de este proceso: un informe de Andrey Evsyukov "
Características de los microservicios en el ejemplo de una plataforma e-Com " dirá mucho más sobre esto.
Para no agravar la diversidad tecnológica, hemos introducido una "dictadura de prácticas comprobadas", según la cual se recomienda a los creadores de nuevos chips que utilicen aquellas tecnologías y herramientas que ya se utilizan en algún lugar de la empresa. La mayoría de los servicios se comunican entre sí a través de la API (utilizamos nuestra modificación de la segunda versión del estándar JSONRPC), pero cuando la lógica de negocios lo permite, también utilizamos el bus de datos para la interacción.
El uso de otras tecnologías no está prohibido. Sin embargo, cualquier idea nueva debe probarse en un comité de arquitectura especialmente creado, que incluya líderes de las áreas principales.
Considerando la próxima propuesta, el comité da luz verde al experimento u ofrece algún tipo de reemplazo de la pila existente. Por cierto, esta decisión depende en gran medida de las circunstancias actuales del negocio. Por ejemplo, si un equipo llega la víspera de la venta del Black Friday y anuncia que introducirá tecnología en la producción de la que el comité nunca antes había oído hablar, lo más probable es que sea rechazada. Por otro lado, se puede dar luz verde al mismo experimento si se introduce una nueva tecnología o herramienta en circunstancias comerciales menos críticas, y la implementación comenzará con pruebas fuera de la producción.
El Comité de Arquitectura también es responsable de mantener el radar de Tecnología, haciendo los cambios necesarios cada 2-3 meses. Uno de los propósitos de este recurso es dar a los equipos una idea de qué tipo de experiencia ya tiene la empresa.
Pero pasemos a lo más interesante: al análisis de los sectores de nuestro radar.
Vale la pena señalar que utilizamos una interpretación ligeramente no estándar de las categorías de adopción de tecnología:
- ADOPTAR - tecnologías y herramientas que se implementan y utilizan activamente;
- PRUEBA: tecnologías y herramientas que ya han pasado la etapa de prueba y se están preparando para trabajar con la producción (o incluso que ya trabajan allí);
- EVALUACIÓN: herramientas de prueba que se están evaluando actualmente y que aún no afectan la producción. Con su participación, solo se implementan proyectos de prueba;
- HOLD: en esta categoría tenemos experiencia, pero las herramientas mencionadas solo se utilizan con el apoyo de los sistemas existentes; no se lanzan nuevos proyectos en ellas.
Desarrollo
PHP - Python - Ir
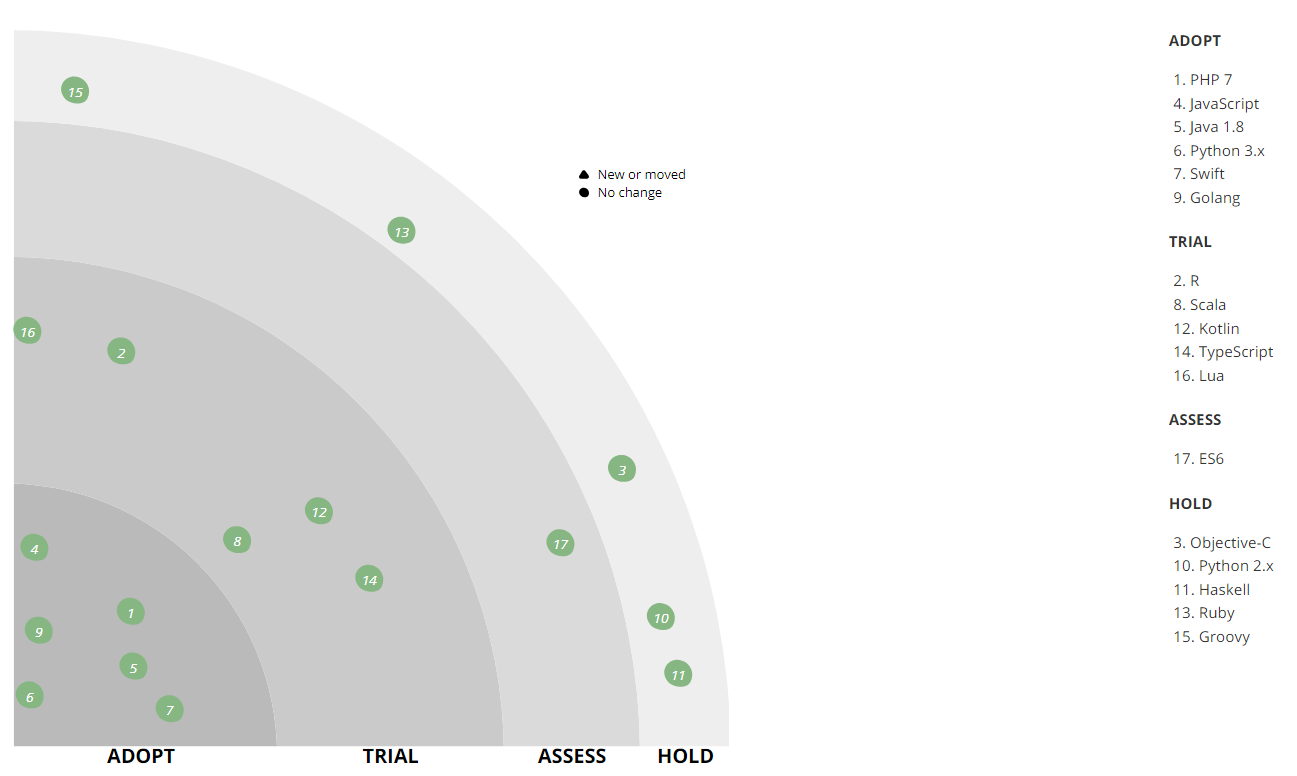
El primer lenguaje en el que queremos detenernos es PHP. Hoy resuelve solo una parte de las tareas de back-end de la tienda, e inicialmente todo el back-end trabajó en PHP. A medida que el negocio se expandió en el front-end, se notó una falta de velocidad y productividad: en aquel entonces utilizamos PHP 5, por lo que Python lo reemplazó (primero 2.x, y luego 3.x). Sin embargo, PHP le permite escribir modelos de negocios ricos, por lo que este lenguaje se ha mantenido en la oficina administrativa para automatizar diversos procesos operativos, en particular, la integración con tiendas en línea de terceros o servicios de entrega, así como la automatización de un estudio de contenido que elabora tarjetas de productos. Ahora ya estamos usando PHP 7. En PHP hemos escrito muchas bibliotecas para uso interno: integración y envoltorios sobre nuestra infraestructura, capa de integración entre servicios, varios ayudantes reutilizados. El primer lote de bibliotecas ya se ha llevado a código abierto en
nuestro github.com , y el resto, el más "maduro", llegará pronto. Uno de los primeros fue una máquina de estado, que, presente en casi todas las aplicaciones, se asegura de que con el pedido antes de enviar todas las acciones necesarias.
Con el tiempo, Python también se ha vuelto insuficiente para el backend de una tienda. Ahora preferimos un Go más productivo y liviano.
Quizás la transición a Go fue un cambio importante, ya que ahorró una gran cantidad de hardware y recursos humanos; la eficiencia ha aumentado significativamente. Los primeros que hicieron los primeros proyectos en Go fueron RnD, no querían lidiar con las limitaciones técnicas de Python. Luego, en el equipo de desarrollo móvil, había personas que estaban familiarizadas con él y lo promovieron a la producción. Desde su presentación, realizamos pruebas y quedamos más que satisfechos con el resultado. En casos separados, después de que parte del proyecto fue reescrito desde Python to Go, la carga de los nodos del clúster disminuyó significativamente. Por ejemplo, reescribir el motor de cálculo de descuentos para la canasta de Python to Go nos permitió procesar 8 veces más solicitudes con las mismas capacidades de hardware, y el tiempo promedio de respuesta API se redujo en 25 veces. Es decir Ir resultó ser más eficiente que Python (si lo escribe correctamente), incluso si no es tan conveniente para el desarrollador.
Dado que el desarrollo móvil tuvo que interactuar con docenas de API internas, se creó un generador de código que, de acuerdo con la descripción del servicio API (de acuerdo con la especificación Swagger), un cliente puede generar en Go. Así que On Go comenzó a corresponder gradualmente con los servicios y herramientas existentes, especialmente aquellos que crearon el "cuello de botella" para la carga. Además de facilitar la vida del desarrollador de backend móvil, hemos simplificado las siguientes convenciones internas sobre cómo desarrollar API, cómo nombrar métodos, cómo pasar parámetros y cosas similares. Esta estandarización ha facilitado el desarrollo y la implementación de nuevos servicios para todos los equipos.
Hoy, Go ya se usa en casi todas partes, en todas las interacciones en tiempo real con los usuarios, en el back-end del sitio y las aplicaciones móviles, así como en los servicios con los que están asociados. Y donde no hay necesidad de un procesamiento y una respuesta rápidos, por ejemplo, en las tareas de interacción con el almacén de datos, Python permanece, ya que no tiene igual para las tareas de procesamiento de datos (aunque aquí hay penetración de Go).
Como puede ver en el radar, tenemos Java en el activo. Se utiliza en el Sistema de gestión de almacenes (WMS), lo que ayuda a recoger rápidamente los pedidos. Hasta ahora, tenemos una pila bastante antigua allí y un modelo de arquitectura antiguo: un monolito que gira en Wildfly 10 y 8 Java Hotspot, y también hay un cliente remoto y Rich en la
plataforma de aplicaciones Netbeans (ahora esta funcionalidad se transfiere a la web). Aquí, en nuestro arsenal, tenemos almacenamientos estándar para la empresa e incluso nuestro propio monitoreo. Desafortunadamente, no encontramos una herramienta que pueda visualizar bien el funcionamiento del almacén y los procesos importantes en él (cuando una sección está sobrecargada, por ejemplo), y la hicimos nosotros mismos.
Utilizamos Python como el lenguaje principal para el aprendizaje automático: creamos sistemas de recomendación y clasificamos el catálogo, corregimos errores tipográficos en las consultas de búsqueda y también resolvemos otros problemas en conjunto con Spark en un clúster Hadoop (PySpark). Python nos ayuda a automatizar el cálculo de métricas internas y pruebas AB.
Desarrollo frontend y móvil
La interfaz de la tienda en línea de escritorio, así como los sitios móviles, está escrita en JavaScript. Ahora la interfaz se está moviendo gradualmente a la especificación ES6, creando nuevos proyectos de acuerdo con ella. Usamos vue.js como marco principal, pero nos detendremos en él con más detalle en la sección de herramientas.
El desarrollo de aplicaciones para plataformas móviles es una unidad separada en la compañía, que incluye grupos de back-end, así como aplicaciones de Android e iOS con sus propias herramientas y pilas de tecnología, que, debido a las diferencias de plataforma, no siempre es posible unificar en toda la unidad.
Durante dos años, todo el nuevo desarrollo de Android ha estado en marcha en Kotlin, lo que nos permite escribir código más conciso y comprensible. Entre las características más utilizadas, nuestros desarrolladores llaman: Smartcast, clases selladas, funciones de extensión, constructores de tipo seguro (DSL), funcionalidad stdlib.
El desarrollo de iOS está en marcha en Swift, que reemplazó a Objective-C.
Idiomas especiales
La gama de tareas de Lamoda no se limita al desarrollo de un "escaparate" para diferentes plataformas, respectivamente, tenemos una serie de idiomas que solo se utilizan dentro de sus sistemas, funcionan bien allí, pero no se implementarán en otras partes de la infraestructura:
- R: utilizado para el procesamiento de datos y las secuencias de comandos de informes en el marco de Business Intelligence (BI). No está en producción y ya no se usa para nuevas tareas, pero aún tenemos una serie de dichos scripts. Al resolver problemas con R, nos dimos cuenta de que este lenguaje no es para aplicaciones altamente cargadas. En nuevas tareas, usamos Python y otras tecnologías que son incompatibles con R.
- Scala: utilizado por la oficina de desarrollo en Vilnius para desarrollar un sistema de automatización de call center. Inicialmente, este sistema se escribió en PHP, pero durante la transición a una arquitectura de microservicio, se reescribieron varios componentes en Scala. También en él, el equipo de Ingeniería de Datos escribe trabajos de Spark.
- TypeScript que estamos viendo. La entrega ya está implementada con su ayuda, y en el futuro usaremos TypeScript + vue.js en la interfaz.
- Lua se usa para configurar nginx (a través de la API nginx), en otros proyectos no lo es y nunca lo será.
- Somos una empresa de moda y seguimos la moda para la programación funcional. Por ejemplo, un emulador de dispositivo de clasificación en uno de nuestros almacenes está escrito en Haskell.
Gestión de datos
DBMS, búsqueda y análisis de datos
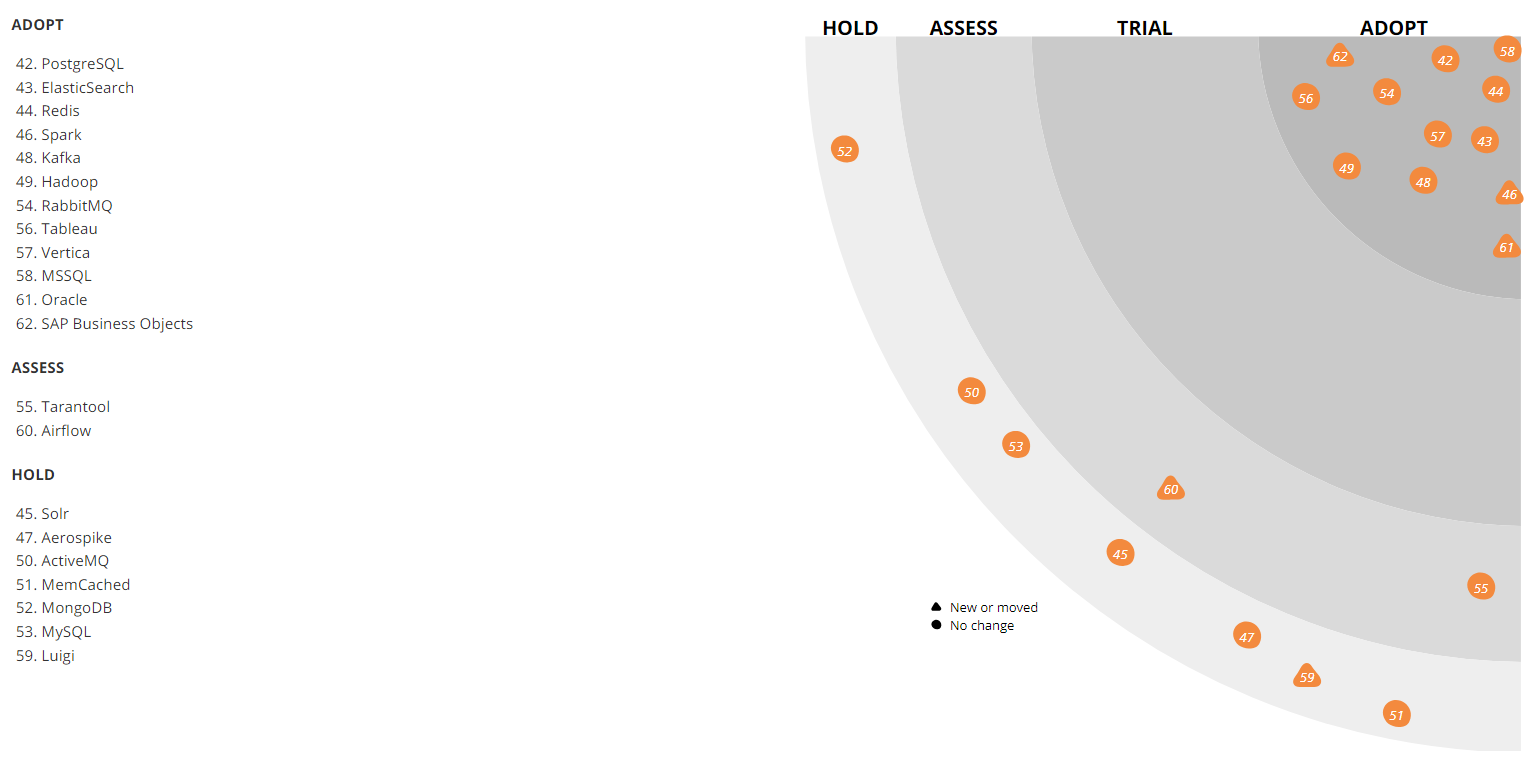
Como muchas de las bases de datos más diversas que hemos implementado en PostgreSQL, se usa donde se necesitan bases de datos relacionales, por ejemplo, para almacenar un directorio. Es bastante fácil encontrar especialistas en esta tecnología, además, hay muchos servicios diferentes disponibles.
Por supuesto, PostgreSQL no es el único DBMS que se puede encontrar en nuestra infraestructura de TI. En algunos sistemas más antiguos, por ejemplo, se usa MySQL, mientras que WMS tiene un poco de MongoDB. Sin embargo, para cargas elevadas y escalado (teniendo en cuenta el resto de nuestra pila de tecnología), no los usamos para nuevos proyectos. En general, PostgreSQL es nuestro todo.
El Aerospike también es visible en el radar. Lo usamos bastante activamente, pero luego el acuerdo de licencia cambió para el producto, por lo que la versión "nuestra" resultó ser un poco corta. Sin embargo, ahora lo miramos de nuevo. Quizás reconsideremos nuestra actitud hacia el instrumento y lo usaremos más activamente. Ahora Aerospike se utiliza en el servicio de agregación de eventos de visualización de páginas y el trabajo del usuario con la cesta, así como en el servicio de prueba social ("5 personas agregaron este producto a favoritos esta semana"). Ahora estamos haciendo recomendaciones aún más pronunciadas al respecto.
Apache Solr se utiliza para buscar datos de producción. Paralelamente, también utilizamos ElasticSearch. Ambas soluciones son de código abierto, pero si antes, cuando estábamos implementando la búsqueda, Apache Solr ya tenía la tercera o cuarta versión y se estaba desarrollando activamente, y ElasticSearch ni siquiera tenía la primera versión estable: era demasiado pronto para usarla en producción. Ahora los roles han cambiado: es mucho más fácil encontrar soluciones para ElasticSearch, y nos han llegado nuevas personas que son buenas para prepararlo. Sin embargo, en la producción tenemos Solr, y no pasaremos a otra solución al menos hasta el Black Friday 2018.
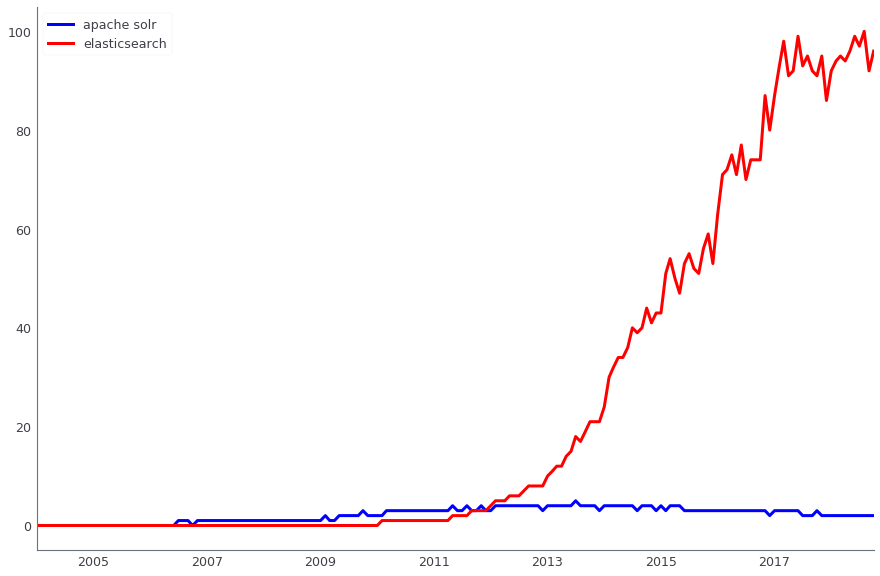 Comparación de la dinámica de las consultas de búsqueda Apache Solr (azul) y ElasticSearch (rojo), según Google Trends
Comparación de la dinámica de las consultas de búsqueda Apache Solr (azul) y ElasticSearch (rojo), según Google TrendsEl análisis de datos se produce en varios sistemas, en particular, utilizamos activamente Apache Hadoop. Al mismo tiempo, la columna Vertica DBMS se usa para almacenar marts de datos (con un volumen total de aproximadamente 4 TB). Sobre estas vitrinas, se construyen informes financieros, operativos y comerciales. Para muchas de nuestras tareas ETL, anteriormente utilizamos Luigi, pero ahora nos estamos moviendo a Apache Airflow. También utilizamos Pentaho para el almacenamiento relacional, en el que hay alrededor de mil tareas regulares de ETL.
Parte del análisis y preparación de datos para otros sistemas se lleva a cabo en Spark. En algunos lugares, esta no es solo una herramienta de análisis, sino también parte de nuestra arquitectura lambda.
Los sistemas ERP juegan un papel importante en la infraestructura de TI: Microsoft Dynamics AX y 1C. Como DBMS, se utiliza Microsoft SQL Server. Y para los informes, sus componentes, como los servicios de análisis y los servicios de informes.
Almacenamiento en caché
Para el almacenamiento en caché usamos Redis. Anteriormente, esta tarea fue realizada por MemCached, no podía usarse como almacenamiento de valor clave con un volcado periódico en el disco, por lo que la abandonamos.
Colas de mensajes
Como agente de eventos, utilizamos dos herramientas a la vez: Apache Kafka y RabbitMQ.
Apache Kafka es una herramienta que nos permite procesar decenas de miles de mensajes en varios sistemas donde se necesitan mensajes. Se implementan clústeres de Kafka separados para algunas partes altamente cargadas del sistema, por ejemplo, para eventos de usuario o registro (tuvimos un buen
informe sobre el registro en Highload ++ 2017 ). Kafka le permite hacer frente a 6000 mil mensajes masivos por segundo con un uso mínimo de hierro.
En sistemas internos, utilizamos RabbitMQ para acciones diferidas.
Plataformas e Infraestructura

Entrega continua
Para la implementación, se usa Kubernetes, que reemplazó el paquete Nomad + Consul de Hashicorp. La pila anterior funcionó muy mal con las actualizaciones de hardware. Cuando nuestro equipo de operaciones cambió los servidores físicos en los que giraban los nodos y se almacenaron los contenedores, se rompió y se bloqueó periódicamente, no queriendo elevarse. No había una versión estable en ese momento. Además, no utilizamos lo último en ese momento: 0.5.6, que todavía necesitaba actualizarse. La actualización a la última versión beta requirió algo de trabajo. Por lo tanto, se decidió abandonarlo y cambiar a los Kubernetes más populares.
Ahora Nomad y Cónsul todavía se usan en QA, pero en el futuro también debería mudarse a Kubernetes.
Para implementar la entrega continua, se utilizan contenedores Docker, a los que migramos hace dos años. Para nuestros servicios altamente cargados (cesta, catálogo, sitio web, sistema de gestión de pedidos), la capacidad de recoger rápidamente algunos contenedores adicionales de un servicio es importante, por lo que tenemos contenedores en todas partes. Y Docker es uno de los métodos de contenedorización más populares, por lo que su presencia en el radar es bastante lógica.
Como servidor de compilación e integración continua, Bamboo se implementa, se utiliza junto con Jira y Bitbucket (pila estándar).
Jenkins también se menciona en el radar. Experimentamos con él, pero no lo arrastraremos a nuevos proyectos. Es una gran herramienta, pero simplemente no cabe en nuestra pila porque ya tenemos Bamboo.
Recolectados con Bamboo docker-container se almacenan en el repositorio bajo el control de Artifactory.
Gestión de procesos y balanceo
Usamos NGINX Plus, pero no en términos de equilibrio, porque sus métricas no son suficientes para nuestras tareas. No puede decir, por ejemplo, qué solicitud se enruta o congela con mayor frecuencia. Por lo tanto, HAProxy se usa para equilibrar la carga. Puede funcionar de manera rápida y eficiente junto con nginx, sin cargar el procesador y la memoria. Además, las métricas que necesitamos están listas para usar: HAproxy puede mostrar estadísticas por nodos, por la cantidad de conexiones en este momento, por lo ocupado que está el ancho de banda y mucho más.
UWSGI se usa para ejecutar aplicaciones de Python sincrónicas. Php-fpm se utilizó como administrador de procesos en todos los servicios PHP.
Monitoreo
Utilizamos Prometheus para recopilar métricas de nuestras aplicaciones y máquinas host (máquinas virtuales), así como de la
base de datos de series temporales para la aplicación . Recopilamos registros, para esto usamos la pila ELK, como sistema de alerta usamos Icinga, que está configurado tanto para ELK como para Prometheus. Ella envía alertas por correo y SMS. El servicio de soporte 6911 recibe las mismas alertas y decide atraer ingenieros de servicio.
Prometheus está involucrado en casi todas partes, y para esto tenemos bibliotecas para todos los idiomas, que permiten usar solo un par de líneas de código para conectar sus métricas al proyecto. Por ejemplo, una biblioteca para PHP
está disponible en código abierto ).
Para mostrar visualmente los resultados del monitoreo en forma de hermosos paneles, se utiliza Grafana. Básicamente, recopilamos todos los paneles de Prometheus, aunque a veces otros sistemas también pueden servir como fuentes.
Para detectar y agregar errores automáticamente, utilizamos Sentry, que está integrado con Jira y facilita el inicio de un rastreador de tareas para cada uno de los problemas de producción. Él sabe cómo capturar el error con algo de retroceso e información adicional, por lo que es conveniente debutar.
Las estadísticas sobre el código de las solicitudes de extracción creadas se recopilan mediante SonarQube.
Marcos y herramientas

Durante el desarrollo de la infraestructura de TI de Lamoda, experimentamos con casi tres docenas de herramientas diferentes, por lo que esta categoría es la más "a gran escala" en nuestro radar. Hasta la fecha, se utilizan activamente:
- Symfony 3.xy más recientemente, Symfony 4.x, para desarrollo en PHP;
- Django y el motor de plantillas Jinja para el desarrollo de Python. Por cierto, Jinja se usa, incluso, para la configuración en Ansible;
- Frasco: para servicios internos (junto con Django), pero en producción no lo arrastramos;
- Spring - en desarrollo Java;
- Bootstrap: para una variedad de herramientas internas en el desarrollo web (panel de administración, tableros caseros, etc.);
- jQuery: para el desarrollo de js;
- OpenAPI (Swagger): para la documentación de todos los servicios API, incluidos que se utilizan para la generación de código anterior en Go;
- Webpack: para empaquetar JS y minimizar CSS;
- Selenio: para probar la interfaz;
- WireMock, JMeter, Allure y otros también se utilizan en las pruebas;
- Ansible: para la gestión de la configuración;
- Kibana: para visualizar resultados de búsqueda en ElasticSearch.
Me gustaría hablar sobre el desarrollo de JavaScript por separado. Nosotros, como muchos, tenemos todo un campo de experimentos. JavaScript . — Angular, ReactJS, vue.js. « », , vue.js, , .
, GO, PHP, Java, JavaScript, PostgreSQL, Docker Kubernetes.
, . , , . -, . , , , .