 Este artículo es parte de Chronicle of Software Architecture , una serie de artículos sobre arquitectura de software. En ellos escribo sobre lo que aprendí sobre la arquitectura de software, lo que pienso al respecto y cómo uso el conocimiento. El contenido de este artículo puede tener más sentido si lee los artículos anteriores de la serie.
Este artículo es parte de Chronicle of Software Architecture , una serie de artículos sobre arquitectura de software. En ellos escribo sobre lo que aprendí sobre la arquitectura de software, lo que pienso al respecto y cómo uso el conocimiento. El contenido de este artículo puede tener más sentido si lee los artículos anteriores de la serie.En un
artículo anterior de la serie, publiqué un mapa conceptual que muestra las relaciones entre los tipos de código.
Pero siempre me pareció que no todo está muy bien reflejado allí, simplemente no sabía cómo hacerlo mejor. Se trata de un núcleo común.
Además, han surgido algunas ideas más que esbozaré en este breve artículo.
En la infografía del último artículo de esta serie, en el centro del diagrama, vemos el núcleo común. Parece estar ubicado dentro de la capa de dominio y encima de las secciones cónicas, que son contextos limitados.

A pesar de su ubicación, no quise decir que el núcleo común depende del resto del código o que el núcleo común es otra capa dentro del nivel de dominio.
¿Qué es un núcleo común?
El núcleo común, según lo definido por Eric Evans, el
padre de DDD, es el código que el equipo de desarrollo decide dividir entre varios contextos limitados:
[...] un subconjunto del modelo de dominio que los dos equipos acordaron usar juntos. Por supuesto, junto con este subconjunto del modelo, el núcleo común incluye un subconjunto del código o la arquitectura de la base de datos asociada con esta parte del modelo. Este material claramente general tiene un estado especial y no debe cambiarse sin consultar a otro equipo.
- "Kernel común" , DDD Wiki de Ward Cunningham
Por lo tanto, puede ser cualquier tipo de código: código de nivel de dominio, código de nivel de aplicación, bibliotecas ... lo que sea.

Sin embargo, en el contexto de nuestro mapa conceptual, lo presento como un subconjunto, como un tipo específico de código. En mi mapa conceptual, el núcleo común contiene código para el dominio y los niveles de aplicación, que se comparte en contextos limitados para que sea posible la comunicación entre contextos restringidos.
Por ejemplo, esto significa que los eventos se disparan en uno o más contextos restringidos y se escuchan en otros contextos restringidos. Junto con estos eventos, necesitamos compartir todos los tipos de datos que utilizan estos eventos, por ejemplo: identificadores de entidad, objetos de valor, enumeraciones, etc. Los objetos complejos como las entidades no deben usarse directamente por eventos, ya que pueden ser difíciles serializar / deserializar hacia / desde la cola, por lo que el código genérico no debe distribuirse ampliamente.
Por supuesto, si tenemos un sistema multilingüe de microservicios, entonces el núcleo común debe ser descriptivo, en JSON, XML, YAML, etc., para que todos los microservicios puedan entenderlo.
Como resultado, este núcleo común está completamente separado del resto de la base de código, de los componentes. Esto es genial, porque los componentes, aunque están conectados con el núcleo común, están separados entre sí. El código genérico se identifica explícitamente y se recupera fácilmente en una biblioteca separada.
También es muy conveniente si decidimos extraer uno de los contextos limitados en un microservicio, separado del monolito. Sabemos con certeza qué es común y simplemente podemos extraer el núcleo común en la biblioteca, que se instalará tanto en el monolito como en el microservicio.
Entonces, para resumir, en mi mapa conceptual, el núcleo de la aplicación depende de un núcleo común que contiene código del dominio y los niveles de aplicación que se comparten entre contextos limitados.
Cuando el lenguaje no es suficiente ...
Entonces, tenemos el código de la aplicación con todas las capas concéntricas, y el núcleo de la aplicación depende del núcleo común, que está debajo de todo este código.
También podemos decir que todo este código depende de los lenguajes de programación utilizados, pero es un hecho tan obvio que tendemos a ignorarlo por completo.
Sin embargo, surge la pregunta: "¿Qué pasa si las construcciones del lenguaje no son suficientes?" Bueno, obviamente, creamos estas construcciones de lenguaje nosotros mismos y, por lo tanto, compensamos los defectos del lenguaje. Pero tengo importantes preguntas de seguimiento: “¿Cómo y dónde justificar la existencia de este código? ¿Cómo se puede indicar claramente cuándo y cómo usarlo?
Lo que vi e hice yo mismo fue un paquete llamado Utils o Commons, donde se encuentra este código. Pero al final, terminamos tirando todo el código allí, ¡que no sabemos dónde poner! Todo tipo de código para diferentes propósitos y facilidad de uso (envuelto en un adaptador utilizado directamente ...) finalmente se arroja allí. El paquete no tiene significado conceptual, ni coherencia, ni coherencia, ni claridad, ni muchas ambigüedades.
¡Quiero abandonar los paquetes de Utils y Commons!
¡Todos los paquetes deben tener cohesión conceptual! ¡Debe quedar claro cuándo y cómo usar el paquete! ¡Sin ambigüedad!
Por ejemplo, si una aplicación interactúa con la interfaz de línea de comandos de alguna manera especial, en lugar de colocar 'Acme / Util / SpecialCli' en el espacio de nombres, puede colocarla en 'Acme / App / Infrastructure / Cli / SpecialCli'. Esto dice que este paquete está asociado con la CLI, es parte de la infraestructura de la aplicación Acme App. La afiliación con la infraestructura de la aplicación también dice que hay un puerto en el núcleo de la aplicación al que corresponde este paquete.
Alternativamente, si vemos este paquete como algo que le falta al lenguaje en sí, podemos ponerlo en el espacio de nombres apropiado, por ejemplo, 'Acme / PhpExtension / SpecialCli'. Esto muestra que este paquete debe considerarse como parte del lenguaje en sí mismo y, por lo tanto, su código debe usarse directamente en la base del código como cualquier construcción de lenguaje. Por supuesto, si otra compañía depende de este paquete, puede ser razonable que no dependan directamente de él, pero es más seguro crear un puerto / adaptador para que puedan cambiarlo por otra cosa. Pero si poseemos el paquete, podemos considerarlo como parte del lenguaje, ya que el riesgo de tener que reemplazarlo por otra alternativa no es tan grande. El compromiso es siempre la cosa.
Otro ejemplo de lo que se puede considerar como parte del lenguaje son los UUID únicos en PHP. Es bastante posible imaginarlos fuera del lenguaje, porque cada vez hay una nueva versión y es una pesadilla con el soporte de código, pero este es un concepto muy general, un concepto amplio y lo suficientemente consistente como para ser parte del lenguaje.
Entonces, ¿por qué no crear una implementación UUID y usarla como parte del PHP mismo? ¿Cómo usamos un objeto DateTime? Mientras controlamos la implementación, no veo fallas.
¿Qué pasa con el Doctrine Query Language (DQL)? (Doctrine es el puerto de Hibernate en PHP) ¿podemos ver DQL como si fuera SQL, Elasticsearch QL o Mongo QL?
Conclusión
Entonces, a nivel macro, veo cuatro tipos básicos de código y creo que es importante mostrarlos claramente en la organización de la base del código, para no terminar con mucha suciedad.
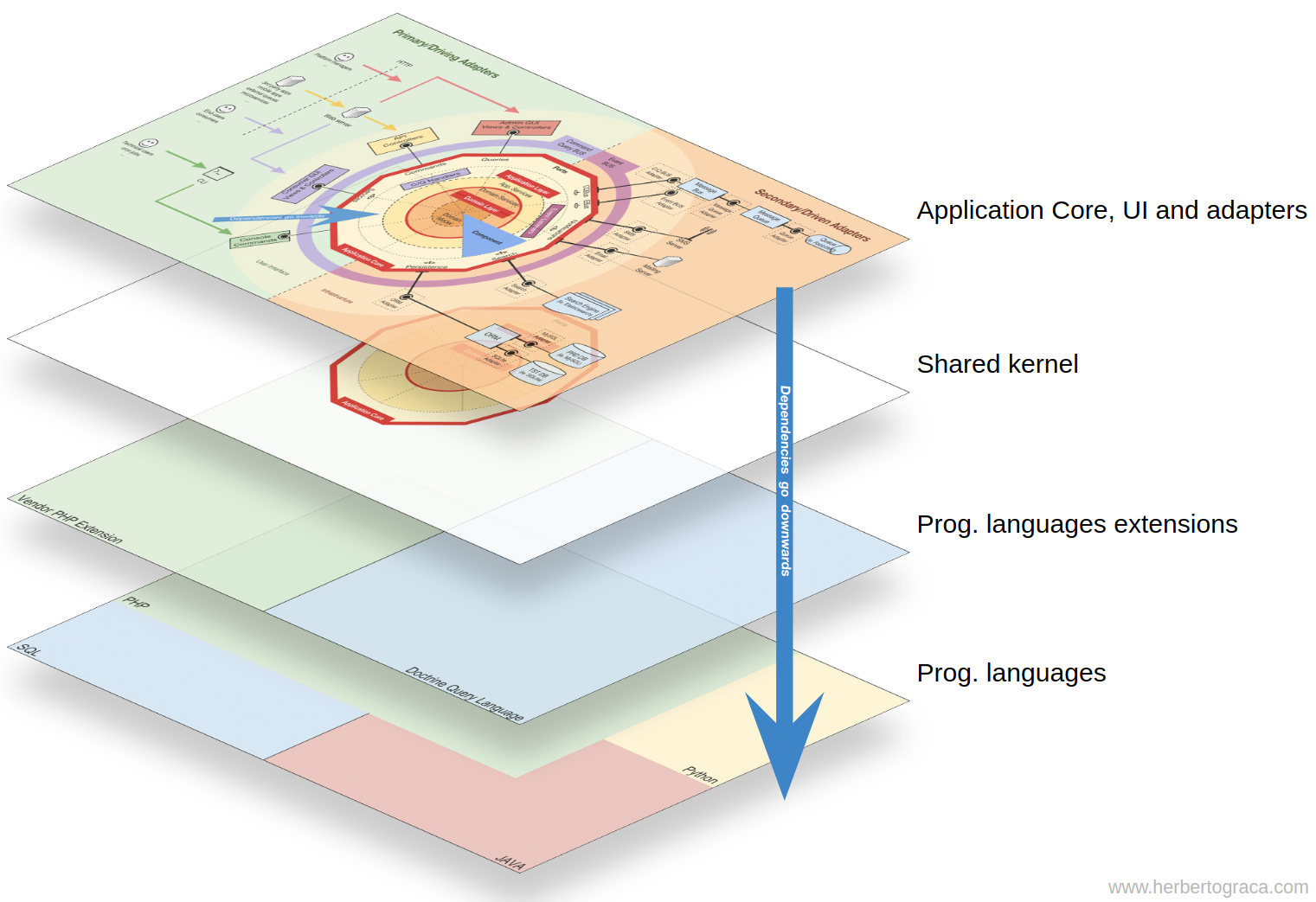
Para mí, la verdad innegable es que la
arquitectura siempre existe, ¡la única pregunta es si la controlamos o no?Así que
organicemos claramente el código de acuerdo con la arquitectura , en su totalidad o en parte, en un mapa conceptual: el mío u otro. Lo principal es organizar el código para que el proyecto informe explícitamente sobre su arquitectura a través de la estructura y organización del código.