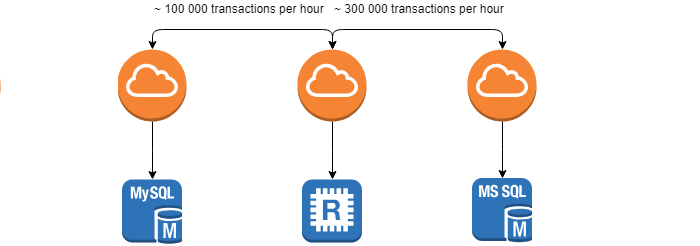
Al desarrollar y utilizar sistemas distribuidos, nos enfrentamos a la tarea de monitorear la integridad e identidad de los datos entre sistemas, la tarea de la reconciliación .
Los requisitos que establece el cliente son el tiempo mínimo para esta operación, ya que cuanto antes se encuentre la discrepancia, más fácil será eliminar sus consecuencias. La tarea es notablemente complicada por el hecho de que los sistemas están en constante movimiento (~ 100,000 transacciones por hora) y no se puede lograr el 0% de las discrepancias.
Idea principal
La idea principal de la solución se puede describir en el siguiente diagrama.
Consideramos cada uno de los elementos por separado.
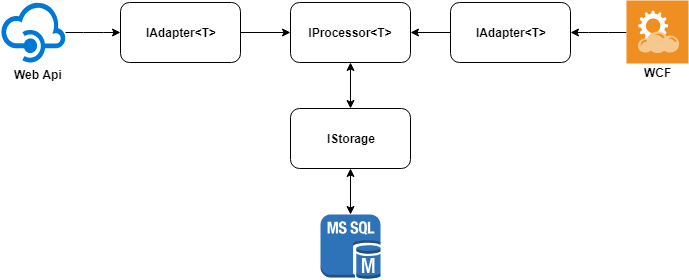
Adaptadores de datos
Cada uno de los sistemas está diseñado para su propia área temática y, como consecuencia, las descripciones de los objetos pueden variar significativamente. Necesitamos comparar solo un cierto conjunto de campos de estos objetos.
Para simplificar el procedimiento de comparación, llevamos los objetos a un formato único escribiendo un adaptador para cada fuente de datos. Traer los objetos a un solo formato puede reducir significativamente la cantidad de memoria utilizada, ya que solo almacenaremos los campos que se comparan.
Debajo del capó, el adaptador puede tener cualquier fuente de datos: HttpClient , SqlClient , DynamoDbClient , etc.
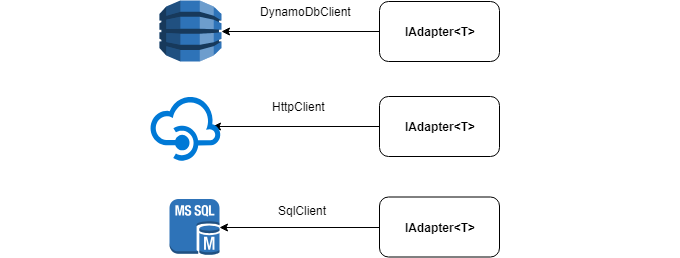
La siguiente es la interfaz IAdapter que desea implementar:
public interface IAdapter<T> where T : IModel { int Id { get; } Task<IEnumerable<T>> GetItemsAsync(ISearchModel searchModel); } public interface IModel { Guid Id { get; } int GetHash(); }
Almacenamiento
La conciliación de datos solo puede comenzar después de que se hayan leído todos los datos, ya que los adaptadores pueden devolverlos en orden aleatorio.
En este caso, la cantidad de RAM puede no ser suficiente, especialmente si ejecuta varias conciliaciones al mismo tiempo, lo que indica grandes intervalos de tiempo.
Considere la interfaz IStorage
public interface IStorage { int SourceAdapterId { get; } int TargetAdapterId { get; } int MaxWriteCapacity { get; } Task InitializeAsync(); Task<int> WriteItemsAsync(IEnumerable<IModel> items, int adapterId); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); } public interface ISearchDifferenceModel { int Offset { get; } int Limit { get; } }
Repositorio. Implementación basada en MS SQL
Implementamos IStorage usando MS SQL, lo que nos permitió realizar la comparación completamente en el lado del servidor Db.
Para almacenar los valores que se solicitan, simplemente cree la siguiente tabla:
CREATE TABLE [dbo].[Storage_1540747667] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [qty] INT NOT NULL, [price] INT NOT NULL, CONSTRAINT [PK_Storage_1540747667] PRIMARY KEY ([id], [adapterid]) )
Cada entrada contiene campos del sistema ( [id] , [adapterId] ) y campos para comparación ( [qty] , [price] ). Algunas palabras sobre los campos del sistema:
[id] : identificador único de la entrada, igual en ambos sistemas
[ID del adaptador ] : identificador del adaptador a través del cual se recibió el registro
Dado que los procesos de reconciliación pueden iniciarse en paralelo y tener intervalos de intersección, creamos una tabla con un nombre único para cada uno de ellos. Si la conciliación fue exitosa, esta tabla se elimina; de lo contrario, se envía un informe con una lista de registros en los que existen discrepancias.
Repositorio. Comparación de valor
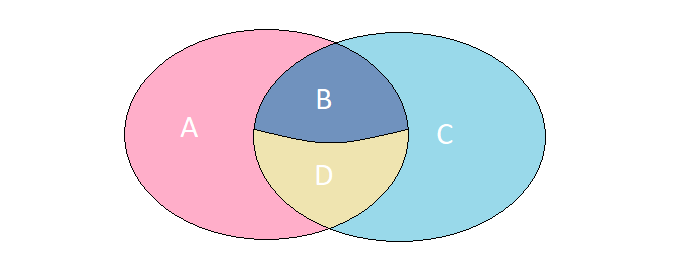
Imagine que tenemos 2 conjuntos cuyos elementos tienen un conjunto de campos absolutamente idéntico. Considere 4 casos posibles de su intersección:
A. Los elementos están presentes solo en el conjunto izquierdo.
B. Los elementos están presentes en ambos conjuntos, pero tienen diferentes significados.
S Los elementos están presentes solo en el conjunto correcto.
D Los elementos están presentes en ambos conjuntos y tienen el mismo significado.
En un problema específico, necesitamos encontrar los elementos descritos en los casos A, B, C. Puede obtener el resultado deseado en una consulta a MS SQL mediante FULL OUTER JOIN :
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[qty] = [s1].[qty] and [s2].[price] = [s1].[price] where [s2].[id] is nul
El resultado de esta solicitud puede contener 4 tipos de registros que cumplen con los requisitos iniciales
| # # | id | adaptador | comentar |
|---|
| 1 | guid1 | adp1 | El registro está presente solo en el conjunto izquierdo. Caso A |
| 2 | guid2 | adp2 | El registro está presente solo en el conjunto correcto. Caso C |
| 3 | guid3 | adp1 | Los registros están presentes en ambos conjuntos, pero tienen diferentes significados. Caso B |
| 4 4 | guid3 | adp2 | Los registros están presentes en ambos conjuntos, pero tienen diferentes significados. Caso B |
Repositorio. Hashing
Usando hashing en objetos comparados, puede reducir significativamente el costo de escribir y comparar operaciones. Especialmente cuando se trata de comparar docenas de campos.
El método más universal de cifrar una representación serializada de un objeto resultó ser.
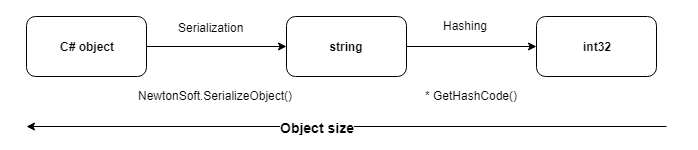
1. Para el hash, utilizamos el método estándar GetHashCode () , que devuelve int32 y se anula para todos los tipos primitivos.
2. En este caso, la probabilidad de colisiones es poco probable, ya que solo se comparan los registros con los mismos identificadores.
Considere la estructura de la tabla utilizada en esta optimización:
CREATE TABLE [dbo].[Storage_1540758006] ( [id] UNIQUEIDENTIFIER NOT NULL, [adapterid] INT NOT NULL, [hash] INT NOT NULL, CONSTRAINT [PK_Storage_1540758006] PRIMARY KEY ([id], [adapterid], [hash]) )
La ventaja de dicha estructura es el costo constante de almacenar un registro (24 bytes), que no dependerá del número de campos comparados.
Naturalmente, el procedimiento de comparación sufre sus cambios y se vuelve mucho más simple.
select [s1].[id], [s1].[adapterid] from [dbo].[Storage_1540758006] as [s1] full outer join [dbo].[Storage_1540758006] as [s2] on [s2].[id] = [s1].[id] and [s2].[adapterid] != [s1].[adapterid] and [s2].[hash] = [s1].[hash] where [s2].[id] is null
CPU
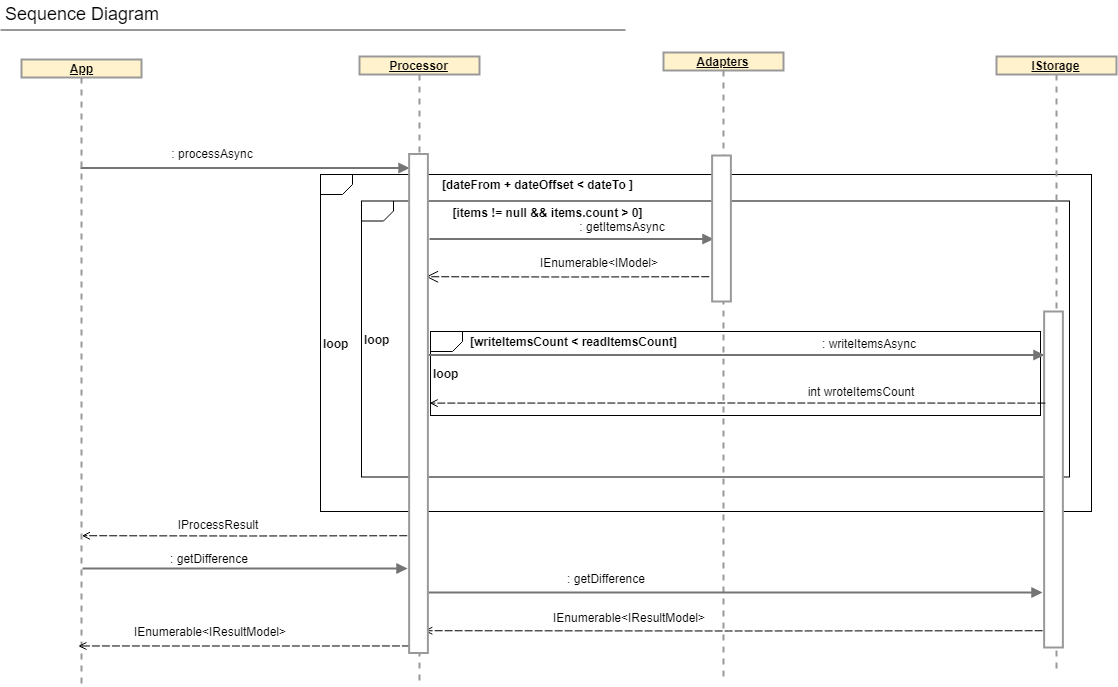
En esta sección, hablaremos sobre una clase que contiene toda la lógica empresarial de la reconciliación, a saber:
1. lectura paralela de datos de adaptadores
2. hashing de datos
3. registro de valores almacenados en la base de datos
4. entrega de resultados
Se puede obtener una descripción más completa del proceso de reconciliación mirando el diagrama de secuencia y la interfaz del procesador IP .
public interface IProcessor<T> where T : IModel { IAdapter<T> SourceAdapter { get; } IAdapter<T> TargetAdapter { get; } IStorage Storage { get; } Task<IProcessResult> ProcessAsync(); Task<IEnumerable<IResultModel>> GetDifferenceAsync(ISearchDifferenceModel model); }
Agradecimientos
Muchas gracias a mis colegas del Grupo MySale por sus comentarios: AntonStrakhov , Nesstory , Barlog_5 , Kostya Krivtsun y VeterManve , el autor de la idea.