Nota perev. R: El artículo original fue escrito por representantes de BlueData, una compañía fundada por personas de VMware. Se especializa en hacer que sea más fácil (más fácil, más rápido, más barato) implementar soluciones para análisis de Big Data y aprendizaje automático en diversos entornos. La reciente iniciativa de la compañía llamada BlueK8s , en la que los autores desean reunir una galaxia de herramientas de código abierto "para implementar aplicaciones con estado y administrarlas en Kubernetes", también debe contribuir a esto. El artículo está dedicado al primero de ellos: KubeDirector, que, según los autores, ayuda a un entusiasta en el campo de Big Data, que no tiene capacitación especial en Kubernetes, a implementar aplicaciones como Spark, Cassandra o Hadoop en K8. En el artículo se proporcionan breves instrucciones sobre cómo hacerlo. Sin embargo, tenga en cuenta que el proyecto tiene un estado de preparación inicial: pre-alfa.
KubeDirector es un proyecto de código abierto diseñado para simplificar el lanzamiento de clústeres desde aplicaciones complejas con estado escalables en Kubernetes. KubeDirector se implementa utilizando el marco de
definición de recursos personalizados (CRD), utiliza las capacidades de extensión de API nativas de Kubernetes y se basa en su filosofía. Este enfoque proporciona una integración transparente con la gestión de usuarios y recursos en Kubernetes, así como con los clientes y utilidades existentes.
El proyecto KubeDirector
recientemente anunciado es parte de una iniciativa de código abierto más grande para Kubernetes llamada BlueK8s. Ahora me complace anunciar la disponibilidad del código
KubeDirector temprano (pre-alfa). Esta publicación mostrará cómo funciona.
KubeDirector ofrece las siguientes características:
- No es necesario modificar el código para ejecutar aplicaciones con estado que no sean nativas de la nube de Kubernetes. En otras palabras, no es necesario descomponer las aplicaciones existentes para que coincidan con el patrón de arquitectura del microservicio.
- Soporte nativo para almacenar la configuración y el estado específicos de la aplicación.
- Patrón de implementación independiente de la aplicación que minimiza el tiempo de inicio de nuevas aplicaciones con estado en Kubernetes.
KubeDirector permite a los científicos de datos, acostumbrados a aplicaciones distribuidas con procesamiento de datos intensivo, como Hadoop, Spark, Cassandra, TensorFlow, Caffe2, etc., ejecutarlas en Kubernetes con una curva de aprendizaje mínima y sin la necesidad de escribir código en Go. Cuando estas aplicaciones son controladas por KubeDirector, se definen mediante metadatos simples y el conjunto de configuraciones asociado. Los metadatos de la aplicación se definen como un recurso
KubeDirectorApp .
Para comprender los componentes de KubeDirector, clone el repositorio en
GitHub con un comando como el siguiente:
git clone http://<userid>@github.com/bluek8s/kubedirector.
La definición de
KubeDirectorApp para la aplicación Spark 2.2.1 se encuentra en el
kubedirector/deploy/example_catalog/cr-app-spark221e2.json :
~> cat kubedirector/deploy/example_catalog/cr-app-spark221e2.json
{ "apiVersion": "kubedirector.bluedata.io/v1alpha1", "kind": "KubeDirectorApp", "metadata": { "name" : "spark221e2" }, "spec" : { "systemctlMounts": true, "config": { "node_services": [ { "service_ids": [ "ssh", "spark", "spark_master", "spark_worker" ], …
La configuración del clúster de aplicaciones se define como un recurso
KubeDirectorCluster .
La definición de
KubeDirectorCluster para el ejemplo de clúster Spark 2.2.1 está disponible en
kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml :
~> cat kubedirector/deploy/example_clusters/cr-cluster-spark221.e1.yaml
apiVersion: "kubedirector.bluedata.io/v1alpha1" kind: "KubeDirectorCluster" metadata: name: "spark221e2" spec: app: spark221e2 roles: - name: controller replicas: 1 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: worker replicas: 2 resources: requests: memory: "4Gi" cpu: "2" limits: memory: "4Gi" cpu: "2" - name: jupyter …
Inicie Spark en Kubernetes con KubeDirector
Iniciar grupos de Spark en Kubernetes con KubeDirector es fácil.
Primero, asegúrese de que Kubernetes se esté ejecutando (versión 1.9 o superior) con el
kubectl version :
~> kubectl version Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T18:02:47Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Implemente el servicio KubeDirector y
KubeDirectorApp las
KubeDirectorApp recursos de
KubeDirectorApp utilizando los siguientes comandos:
cd kubedirector make deploy
Como resultado, comenzará con KubeDirector:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-qd9hb 1/1 Running 0 1m
Vea la lista de aplicaciones instaladas en KubeDirector ejecutando
kubectl get KubeDirectorApp :
~> kubectl get KubeDirectorApp NAME AGE cassandra311 30m spark211up 30m spark221e2 30m
Ahora puede iniciar el clúster Spark 2.2.1 utilizando el archivo de muestra para
KubeDirectorCluster y el
kubectl create -f deploy/example_clusters/cr-cluster-spark211up.yaml . Comprueba que ha comenzado:
~> kubectl get pods NAME READY STATUS RESTARTS AGE kubedirector-58cf59869-djdwl 1/1 Running 0 19m spark221e2-controller-zbg4d-0 1/1 Running 0 23m spark221e2-jupyter-2km7q-0 1/1 Running 0 23m spark221e2-worker-4gzbz-0 1/1 Running 0 23m spark221e2-worker-4gzbz-1 1/1 Running 0 23m
Spark también apareció en la lista de servicios en ejecución:
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 21s svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 20s svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 20s svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 20s svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 20s
Si accede al puerto 31533 en su navegador, puede ver la IU de Spark Master:
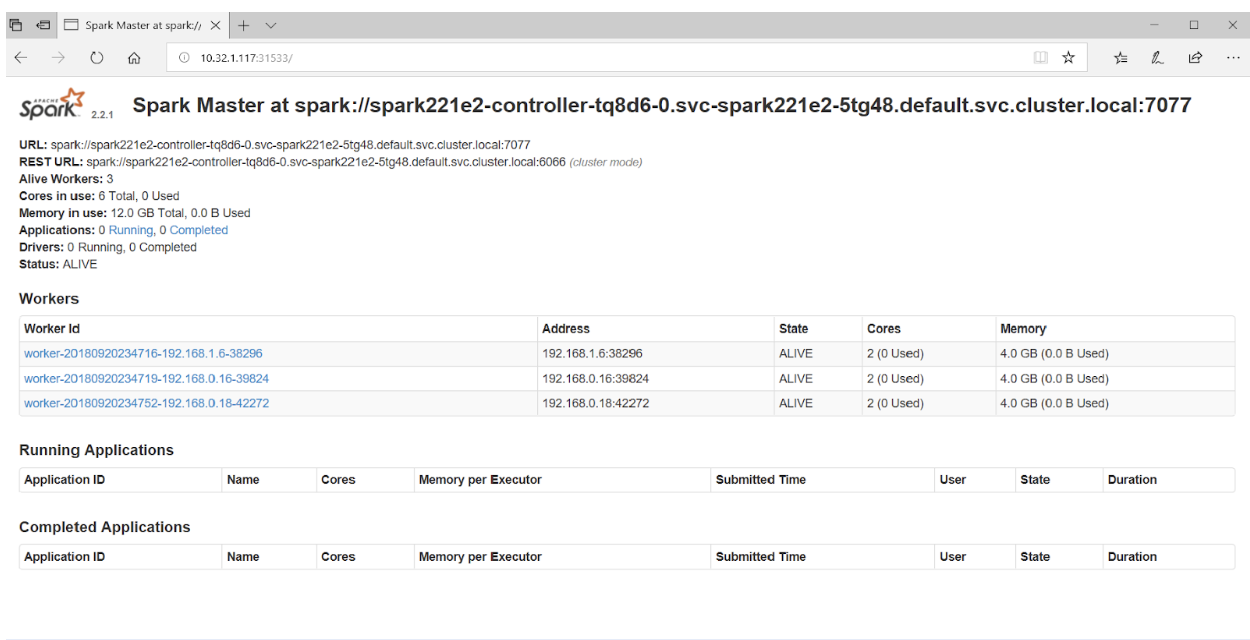
Eso es todo! En el ejemplo anterior, además del clúster Spark, también implementamos el
Jupyter Notebook .
Para iniciar otra aplicación (por ejemplo, Cassandra) simplemente especifique otro archivo con
KubeDirectorApp :
kubectl create -f deploy/example_clusters/cr-cluster-cassandra311.yaml
Verifique que el clúster Cassandra ha comenzado:
~> kubectl get pods NAME READY STATUS RESTARTS AGE cassandra311-seed-v24r6-0 1/1 Running 0 1m cassandra311-seed-v24r6-1 1/1 Running 0 1m cassandra311-worker-rqrhl-0 1/1 Running 0 1m cassandra311-worker-rqrhl-1 1/1 Running 0 1m kubedirector-58cf59869-djdwl 1/1 Running 0 1d spark221e2-controller-tq8d6-0 1/1 Running 0 22m spark221e2-jupyter-6989v-0 1/1 Running 0 22m spark221e2-worker-d9892-0 1/1 Running 0 22m spark221e2-worker-d9892-1 1/1 Running 0 22m
Kubernetes ahora ejecuta el clúster Spark (con Jupyter Notebook) y el clúster Cassandra. La lista de servicios se puede ver con el
kubectl get service :
~> kubectl get service NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubedirector ClusterIP 10.98.234.194 <none> 60000/TCP 1d kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d svc-cassandra311-seed-v24r6-0 NodePort 10.96.94.204 <none> 22:31131/TCP,9042:30739/TCP 3m svc-cassandra311-seed-v24r6-1 NodePort 10.106.144.52 <none> 22:30373/TCP,9042:32662/TCP 3m svc-cassandra311-vhh29 ClusterIP None <none> 8888/TCP 3m svc-cassandra311-worker-rqrhl-0 NodePort 10.109.61.194 <none> 22:31832/TCP,9042:31962/TCP 3m svc-cassandra311-worker-rqrhl-1 NodePort 10.97.147.131 <none> 22:31454/TCP,9042:31170/TCP 3m svc-spark221e2-5tg48 ClusterIP None <none> 8888/TCP 24m svc-spark221e2-controller-tq8d6-0 NodePort 10.104.181.123 <none> 22:30534/TCP,8080:31533/TCP,7077:32506/TCP,8081:32099/TCP 24m svc-spark221e2-jupyter-6989v-0 NodePort 10.105.227.249 <none> 22:30632/TCP,8888:30355/TCP 24m svc-spark221e2-worker-d9892-0 NodePort 10.107.131.165 <none> 22:30358/TCP,8081:32144/TCP 24m svc-spark221e2-worker-d9892-1 NodePort 10.110.88.221 <none> 22:30294/TCP,8081:31436/TCP 24m
PD del traductor
Si está interesado en el proyecto KubeDirector, también debe prestar atención a
su wiki . Desafortunadamente, no fue posible encontrar una hoja de ruta pública, sin embargo, los
problemas en GitHub arrojan luz sobre el progreso del proyecto y las opiniones de sus principales desarrolladores. Además, para aquellos interesados en KubeDirector, los autores proporcionan enlaces a
Slack chat y
Twitter .
Lea también en nuestro blog: