Lo primero que encontramos cuando hablamos de optimización proactiva es que no se sabe qué necesita ser optimizado. "Haz eso, no sé qué".
- No hay un algoritmo clásico.
- El problema aún no ha surgido (desconocido), y uno solo puede adivinar dónde podría estar.
- Necesitamos encontrar algunos puntos débiles potenciales en el sistema.
- Intente optimizar el rendimiento de la consulta en estos lugares.
Los objetivos principales de la optimización proactiva
Las tareas principales de la optimización proactiva difieren de las tareas de optimización reactiva y son las siguientes:
- deshacerse de los cuellos de botella en la base de datos;
- disminución en el consumo de recursos de la base de datos.
El último momento es el más fundamental. En el caso de la optimización reactiva, no tenemos la tarea de reducir el consumo de recursos en su conjunto, sino solo la tarea de llevar el tiempo de respuesta de la funcionalidad a límites aceptables.
Si trabaja con servidores de batalla, tiene una buena idea de lo que significan los incidentes de rendimiento. Debe dejar todo y resolver rápidamente el problema. RNKO Payment Center LLC trabaja con muchos agentes y es muy importante que tengan el menor número de problemas posible. Alexander Makarov en HighLoad ++ Siberia contó lo que se hizo para reducir significativamente el número de incidentes de rendimiento. La optimización proactiva vino al rescate. Y por qué y cómo se produce en un servidor de combate, lea a continuación.
 Acerca del orador:
Acerca del orador: Alexander Makarov (
AL_IG_Makarov ), Administrador principal del Centro de pagos RNCO de Oracle Database, LLC. A pesar de la posición, hay muy poca administración como tal, las tareas principales están relacionadas con el mantenimiento del complejo y su desarrollo, en particular, para resolver problemas de rendimiento.
¿Es la optimización en una base de datos de combate proactiva?
Primero, trataremos los términos a los que este informe se refiere como "optimización proactiva del rendimiento". A veces puede cumplir con el punto de vista de que la optimización proactiva es cuando el análisis de las áreas problemáticas se lleva a cabo antes de que se inicie la aplicación. Por ejemplo, descubrimos que algunas consultas no funcionan de manera óptima, ya que no hay suficiente índice o la consulta utiliza un algoritmo ineficiente, y este trabajo se realiza en servidores de prueba.
Sin embargo, nosotros en RNCO hicimos este proyecto
en servidores de batalla . Muchas veces escuché: “¿Cómo es eso? Lo haces en un servidor de combate, ¡eso significa que no es una optimización proactiva del rendimiento! Aquí necesitamos recordar el enfoque que se cultiva en ITIL. Desde el punto de vista de ITIL, tenemos:
- los incidentes de rendimiento son lo que ya sucedió;
- Las medidas que tomamos para evitar que ocurran incidentes de rendimiento.
En este sentido, nuestras acciones son proactivas. A pesar del hecho de que estamos resolviendo el problema en un servidor de combate, el problema en sí aún no ha surgido: el incidente no ocurrió, no corrimos y no intentamos resolver este problema en poco tiempo.
Entonces, en este informe, la proactividad se entiende como
proactividad en el sentido de ITIL , resolvemos el problema antes de que ocurra un incidente de rendimiento.
Punto de referencia
El "Centro de pagos" de RNKO sirve 2 sistemas grandes:
- RBS-Retail Bank;
- CFT Bank.
La naturaleza de la carga en estos sistemas es mixta (DSS + OLTP): hay algo que funciona muy rápidamente, hay informes, hay cargas medias.
Nos enfrentamos al hecho de que no muy a menudo, pero con cierta frecuencia, se produjeron incidentes de rendimiento. Quienes trabajan con servidores de batalla imaginan lo que es. Esto significa que debe abandonar todo y resolver rápidamente el problema, porque en este momento el cliente no puede recibir el servicio, algo no funciona o funciona muy lentamente.
Dado que muchos agentes y clientes están vinculados a nuestra organización, esto es muy importante para nosotros. Si no podemos resolver rápidamente los incidentes de rendimiento, nuestros clientes sufrirán de una forma u otra. Por ejemplo, no podrán reponer una tarjeta o hacer una transferencia. Por lo tanto, nos preguntamos qué se podría hacer para eliminar incluso estos incidentes de rendimiento poco frecuentes. Para trabajar en un modo cuando necesita soltar todo y resolver un problema, esto no es del todo correcto. Usamos sprints y elaboramos un plan de trabajo de sprint. La presencia de incidentes de rendimiento también es una desviación del plan de trabajo.
¡Algo debe hacerse con esto!
Enfoques de optimización
Pensamos y llegamos a comprender la tecnología de optimización proactiva. Pero antes de hablar sobre la optimización proactiva, debo decir algunas palabras sobre la optimización reactiva clásica.
Optimización reactiva
El escenario es simple, hay un servidor de combate en el que sucedió algo: lanzaron un informe, los clientes reciben declaraciones, en este momento hay actividad continua en la base de datos, y de repente alguien decidió actualizar algún tipo de directorio voluminoso. El sistema comienza a ralentizarse. En este momento, el cliente llega y dice: "No puedo hacer esto o aquello". Necesitamos encontrar una razón por la que no pueda hacer esto.
Algoritmo de acción clásico:- Reproduce el problema.
- Localice el lugar del problema.
- Optimizar el lugar del problema.
Dentro del marco del enfoque reactivo, la tarea principal no es tanto encontrar la causa raíz en sí misma y eliminarla, sino hacer que el sistema funcione normalmente. La eliminación de la causa raíz puede tratarse más adelante. Lo principal es restaurar rápidamente el servidor para que el cliente pueda recibir el servicio.
Los principales objetivos de la optimización reactiva.
En la optimización reactiva, se pueden distinguir dos objetivos principales:
1.
Disminución del tiempo de respuesta .
Una acción, por ejemplo, recibir un informe, extracto, transacción, debe realizarse durante un tiempo programado. Es necesario asegurarse de que el tiempo de recepción del servicio vuelva a los límites aceptables para el cliente. Tal vez el servicio funciona un poco más lento de lo habitual, pero para el cliente esto es aceptable. Luego creemos que el incidente de rendimiento ha sido eliminado y comenzamos a trabajar en la causa raíz.
2.
Un aumento en el número de objetos procesados por unidad de tiempo durante el procesamiento por lotes .
Cuando el procesamiento por lotes de transacciones está en progreso, es necesario reducir el tiempo de procesamiento de un objeto de un lote.
Ventajas de un enfoque reactivo:●
Una variedad de herramientas y técnicas es la principal ventaja de un enfoque reactivo.
Usando herramientas de monitoreo, podemos entender cuál es el problema directamente: no hay suficiente CPU, subprocesos, memoria o el sistema de disco se ha deslizado o los registros se están procesando lentamente. Existen muchas herramientas y técnicas para estudiar el problema de rendimiento actual en la base de datos Oracle.
●
El tiempo de respuesta deseado es otra ventaja.
En el proceso de dicho trabajo, llevamos la situación a un tiempo de respuesta aceptable, es decir, no intentamos reducirla al valor mínimo, pero alcanzamos un cierto valor y después de esta acción terminamos, porque creemos que hemos alcanzado límites aceptables.
Contras del enfoque reactivo:- Los incidentes de rendimiento permanecen : este es el mayor inconveniente del enfoque reactivo, porque no siempre podemos llegar a la causa raíz. Ella podría quedarse en algún lugar alejado y acostarse en algún lugar más profundo, a pesar del hecho de que logramos un rendimiento aceptable.
¿Y cómo lidiar con incidentes de rendimiento si aún no han sucedido? Tratemos de formular cómo se puede llevar a cabo una optimización proactiva para evitar tales situaciones.
Optimización proactiva
Lo primero que encontramos es que no se sabe qué debe optimizarse. "Haz eso, no sé qué".
- No hay un algoritmo clásico.
- El problema aún no ha surgido (desconocido), y uno solo puede adivinar dónde podría estar.
- Necesitamos encontrar algunos puntos débiles potenciales en el sistema.
- Intente optimizar el rendimiento de la consulta en estos lugares.
Los objetivos principales de la optimización proactiva
Las tareas principales de la optimización proactiva difieren de las tareas de optimización reactiva y son las siguientes:
- deshacerse de los cuellos de botella en la base de datos;
- disminución en el consumo de recursos de la base de datos.
El último momento es el más fundamental. En el caso de la optimización reactiva, no tenemos la tarea de reducir el consumo de recursos en su conjunto, sino solo la tarea de llevar el tiempo de respuesta de la funcionalidad a límites aceptables.
¿Cómo encontrar cuellos de botella en la base de datos?
Cuando comenzamos a pensar en este problema, surgen muchas subtareas inmediatamente. Es necesario realizar:
- Prueba de CPU
- prueba de carga en lecturas / registros;
- pruebas de estrés por el número de sesiones activas;
- prueba de carga en ... etc.
Si intentamos simular estos problemas en un complejo de prueba, podemos encontrar el hecho de que el problema que surgió en el servidor de prueba no tiene nada que ver con el de combate. Hay muchas razones para esto, comenzando por el hecho de que los servidores de prueba suelen ser más débiles. Es bueno si es posible hacer que el servidor de prueba sea una copia exacta del combate, pero esto no garantiza que la carga se reproduzca de la misma manera, porque necesita reproducir con precisión la actividad del usuario y muchos más factores diferentes que afectan la carga final. Si intentas simular esta situación, entonces, en general, nadie garantiza que sucederá exactamente lo mismo que sucederá en el servidor de batalla.
Si en un caso el problema surgió debido a la llegada de un nuevo registro, en el otro podría surgir porque el usuario lanzó un gran informe haciendo una gran selección, por lo que el espacio de tabla temporal se llenó y Como resultado, el sistema comenzó a disminuir. Es decir, los motivos pueden ser diferentes y no siempre es posible predecirlos. Por
lo tanto,
abandonamos los intentos de buscar cuellos de botella en los servidores de prueba casi desde el principio. Solo confiamos en el servidor de combate y lo que estaba sucediendo en él.
¿Qué hacer en este caso? Tratemos de entender qué recursos es más probable que falten en primer lugar.
Disminución del consumo de recursos de la base de datos
En función de los complejos industriales que tenemos a nuestra disposición, la
falta de recursos más frecuente se observa en las lecturas de disco y las CPU . Por lo tanto, en primer lugar, buscaremos debilidades precisamente en estas áreas.
La segunda pregunta importante: ¿cómo buscar algo?
La pregunta es muy no trivial. Utilizamos Oracle Enterprise Edition con la opción de Paquete de diagnóstico y para nosotros encontramos una herramienta de este tipo:
informes AWR (en otras ediciones de Oracle puede usar
informes STATSPACK ). En PostgreSQL hay un análogo - pgstatspack, hay
pg_profile de Andrey Zubkov. El último producto, según tengo entendido, apareció y comenzó a desarrollarse solo el año pasado. Para MySQL, no pude encontrar herramientas similares, pero no soy un experto en MySQL.
El enfoque en sí no está vinculado a ningún tipo particular de base de datos. Si es posible obtener información sobre la carga del sistema de algún informe, entonces, utilizando la técnica de la que hablaré ahora, puede realizar un trabajo de optimización proactiva
en cualquier base .
Optimización de las 5 operaciones principales
La tecnología de optimización proactiva que hemos desarrollado y estamos utilizando en el Centro de pagos RNCO consta de cuatro etapas.
Etapa 1. Recibimos el informe de AWR para el mayor período posible.Se necesita el mayor tiempo posible para promediar la carga en diferentes días de la semana, ya que a veces es muy diferente. Por ejemplo, los registros de la semana pasada llegan al RBS-Retail Bank el martes, comienzan a procesarse, y durante todo el día tenemos una carga que está por encima del promedio entre 2 y 3 veces. En otros días, la carga es menor.
Si sabe que el sistema tiene algunos detalles específicos: en algunos días la carga es mayor, en algunos días, menos, entonces necesita recibir informes para estos períodos por separado y trabajar con ellos por separado si queremos optimizar intervalos de tiempo específicos . Si necesita optimizar la situación general del servidor, puede obtener un gran informe del mes y ver qué consumen realmente los recursos del servidor.
A veces se presentan situaciones muy inesperadas. Por ejemplo, en el caso de CFT Bank, una solicitud que verifica la cola del servidor de informes puede estar en el top 10. Además, esta solicitud es oficial y no ejecuta ninguna lógica de negocios, sino que solo verifica si hay un informe de ejecución o no.
Etapa 2. Buscamos secciones:- SQL ordenado por tiempo transcurrido: consultas SQL ordenadas por tiempo de ejecución;
- SQL ordenado por tiempo de CPU - para uso de CPU;
- SQL ordenado por Gets - por lecturas lógicas;
- SQL ordenado por lecturas - para lecturas físicas.
Las secciones restantes de SQL ordenadas por se estudian según sea necesario.
Etapa 3. Determinamos las operaciones principales y las solicitudes que dependen de ellas.El informe de AWR tiene secciones separadas donde, según la versión de Oracle, se muestran 15 o más consultas principales en cada una de estas secciones. Pero estas consultas de Oracle en el informe de AWR muestran un desastre.
Por ejemplo, hay una operación principal, dentro de ella puede haber 3 consultas principales. Oracle en el informe de AWR mostrará tanto la operación principal como todas estas 3 consultas. Por lo tanto, debe hacer un análisis de esta lista y ver a qué operaciones se refieren las solicitudes específicas, agruparlas.
Etapa 4. Optimizamos las 5 principales operaciones.Después de dicha agrupación, el resultado es una lista de operaciones de las que puede seleccionar las más difíciles. Estamos limitados a 5 operaciones (no solicitudes, es decir, operaciones). Si el sistema es más complejo, puede tomar más.
Errores comunes de diseño de consultas
Durante la aplicación de esta técnica, hemos compilado una pequeña lista de errores de diseño típicos. Algunos errores son tan simples que parece que no pueden serlo.
●
Falta de índice → Escaneo completoHay casos muy incidentales, por ejemplo, con la ausencia de un índice en el esquema de combate. Tuvimos un ejemplo concreto en el que una consulta durante mucho tiempo funcionó rápidamente sin un índice. Pero hubo un escaneo completo, y a medida que el tamaño de la tabla creció gradualmente, la consulta comenzó a funcionar más lentamente, y de un trimestre a otro tardó un poco más. Al final, le prestamos atención y resultó que el índice no está allí.
●
Amplia selección → Escaneo completoEl segundo error común es una muestra de datos de gran tamaño: el caso clásico de una exploración completa. Todo el mundo sabe que un análisis completo solo debe usarse cuando esté realmente justificado. A veces hay momentos en que se produce un análisis completo en el que podría prescindir de él, por ejemplo, si transfiere las condiciones de filtrado del código pl / sql a la consulta.
●
Índice ineficaz → ESCANEO DE RANGO DE ÍNDICE largoTal vez este sea incluso el error más común, por lo que por alguna razón dicen muy poco: el llamado índice ineficiente (exploración de índice larga, exploración de RANGO DE ÍNDICE larga). Por ejemplo, tenemos una tabla para registros. En la solicitud, tratamos de encontrar todos los registros de este agente y, en última instancia, agregamos algún tipo de condición de filtrado, por ejemplo, durante un período determinado, o con un número específico o un cliente específico. En tales situaciones, el índice generalmente se crea solo en el campo "agente" por razones de universalidad de uso. El resultado es la siguiente imagen: en el primer año de trabajo, por ejemplo, el agente tenía 100 entradas en esta tabla, el próximo año ya 1,000, en otro año puede haber 10,000 entradas. Con el tiempo, estos registros se convierten en 100,000. Obviamente, la solicitud comienza a funcionar lentamente, porque en la solicitud debe agregar no solo el identificador del agente en sí, sino también algún filtro adicional, en este caso por fecha. De lo contrario, resultará que el tamaño de la muestra aumentará de año en año, a medida que aumenta el número de registros para este agente. Este problema debe abordarse a nivel de índice. Si hay demasiados datos, entonces ya deberíamos pensar en la dirección de la partición.
●
Ramas de código de distribución innecesariasEste también es un caso curioso, pero, sin embargo, sucede. Observamos las consultas principales, y vemos algunas consultas extrañas allí. Acudimos a los desarrolladores y les decimos: "Encontramos algunas solicitudes, resolvamos y veamos qué se puede hacer al respecto". El desarrollador piensa, luego llega un momento y dice: “Esta rama de código no debería estar en su sistema. No utilizas esta funcionalidad ". Luego, el desarrollador recomienda que active alguna configuración especial para evitar esta sección del código.
Estudios de caso
Ahora me gustaría considerar dos ejemplos de nuestra práctica real. Cuando tratamos las principales consultas, por supuesto, primero pensamos en el hecho de que debería haber algo mega pesado, no trivial, con operaciones complejas. De hecho, este no es siempre el caso. A veces hay casos en que las consultas muy simples caen en las operaciones principales.
Ejemplo 1
select * from (select o.* from rnko_dep_reestr_in_oper o where o.type_oper = 'proc' and o.ean_rnko in (select l.ean_rnko from rnko_dep_link l where l.s_rnko = :1) order by o.date_oper_bnk desc, o.date_reg desc) where ROWNUM = 1
En este ejemplo, una consulta consta de solo dos tablas, y estas no son tablas pesadas, solo unos pocos millones de registros. Parecería más fácil? Sin embargo, la solicitud llegó a la cima.
Tratemos de descubrir qué le pasa.
A continuación se muestra una imagen de Enterprise Manager Cloud Control: datos sobre las estadísticas de esta solicitud (Oracle tiene una herramienta de este tipo). Se puede ver que hay una carga regular en esta solicitud (gráfico superior). El número 1 en el lateral indica que, en promedio, no se está ejecutando más de una sesión. El diagrama verde muestra que la
solicitud usa solo la CPU , lo cual es doblemente interesante.

Tratemos de descubrir qué está pasando aquí.

Arriba hay una tabla con estadísticas a pedido. Casi 700 mil lanzamientos, esto no sorprenderá a nadie. Pero el intervalo de tiempo desde el primer tiempo de carga el 15 de diciembre hasta el último tiempo de carga el 22 de diciembre (ver la imagen anterior) es de una semana. Si cuenta el número de inicios por segundo, resulta que la
consulta se ejecuta en promedio cada segundo .
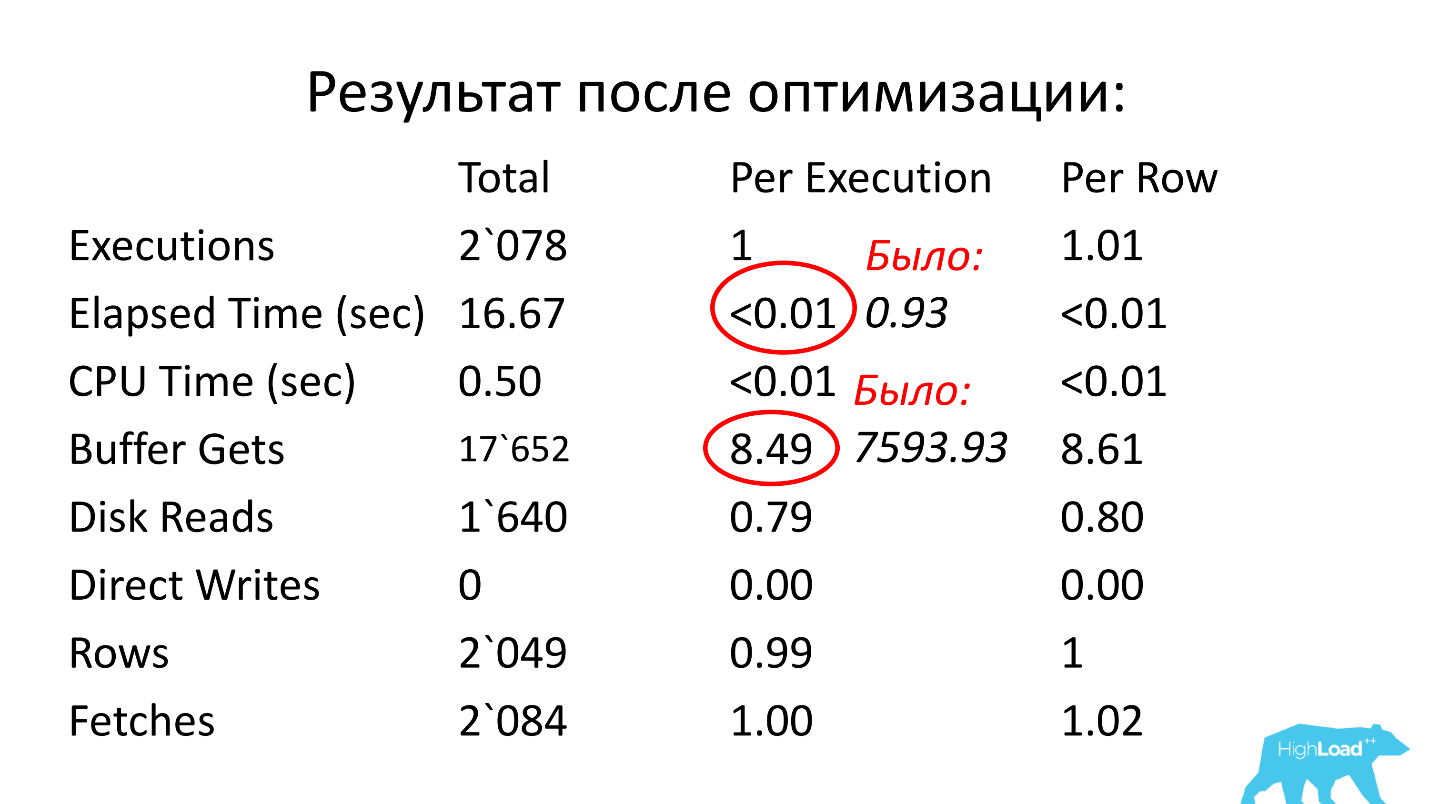
Nosotros miramos más allá. El tiempo de ejecución de la consulta es de 0,93 segundos, es decir. menos de un segundo, eso es genial. Podemos alegrarnos: la solicitud no es pesada. Sin embargo, llegó a la cima, lo que significa que consume muchos recursos. ¿Dónde consume muchos recursos?
La tabla tiene una línea para lecturas lógicas. Vemos que para un lanzamiento necesita casi 8 mil bloques (generalmente 1 bloque es 8 KB). Resulta que la solicitud, que funciona una vez por segundo, carga aproximadamente 64 MB de datos de la memoria. Algo está mal aquí, debemos entenderlo.
Veamos el plan: hay un escaneo completo. Bueno, sigamos adelante.
Plan hash value: 634977963
En la tabla rnko_dep_reestr_in_oper, solo hay 5 millones de filas y su longitud promedio es de 150 bytes. Pero resultó que no hay suficiente índice para el campo que se está conectando: ¡la subconsulta está conectada a la solicitud a través del campo ean_rnko, para el que no hay índice!
Además, incluso si aparece, de hecho, la situación no será muy buena. Se producirá esa exploración de índice larga (exploración de RANGO DE ÍNDICE larga). ean_rnko es el identificador interno del agente. Se acumularán registros de agentes, y cada año aumentará la cantidad de datos que seleccionará esta solicitud, y la solicitud se ralentizará.
Solución: cree un índice para los campos ean_rnko y date_reg, solicite a los desarrolladores que limiten la profundidad de escaneo por fecha en esta solicitud. Entonces, al menos en cierta medida, puede garantizar que el rendimiento de la consulta se mantendrá aproximadamente en los mismos límites, ya que el tamaño de la muestra se limitará a un intervalo de tiempo fijo y no será necesario leer toda la tabla. Este es un punto muy importante, mira lo que pasó.
Después de la optimización, el tiempo de operación se convirtió en menos de una centésima de segundo (fue 0.93), el número de bloques se convirtió en un promedio de 8.5 - 1000 veces menos que antes.
Ejemplo 2
select count(1) from loy$barcodes t where t.id_processing = :b1 and t.id_rec_out is null and not t.barcode is null and t.status = 'u' and not t.id_card is null
Comencé la historia diciendo que generalmente se espera algo complicado en la parte superior de la consulta. Arriba hay un ejemplo de una consulta "compleja" que va a una tabla (!), Y también entró en las consultas principales :) ¡Hay un índice en el campo ID_PROCESSING!
Hay 3 condiciones IS NULL en esta consulta y, como sabemos, dichas condiciones no están indexadas (no puede usar el índice en este caso). Además, solo hay dos condiciones del tipo de igualdad (por ID_PROCESSING y STATUS).
Probablemente, el desarrollador que miraría esta consulta, en primer lugar, sugeriría hacer un índice en ID_PROCESSING y STATUS. Pero dada la cantidad de datos que se elegirán (habrá muchos), esta solución no funciona.
Sin embargo, la solicitud consume muchos recursos, lo que significa que hay que hacer algo para que funcione más rápido. Intentemos descubrir las razones.

Las estadísticas anteriores son para 1 día, a partir del cual se puede ver que la solicitud se inicia cada 5 minutos. El principal consumo de recursos es la CPU y la lectura del disco. A continuación, en el gráfico con estadísticas del número de inicios de consultas, se puede ver que todo está en orden, el número de inicios casi no cambia con el tiempo, una situación bastante estable.

Y si mira más allá, puede ver que el tiempo de consulta a veces varía bastante, varias veces, lo que ya es significativo.
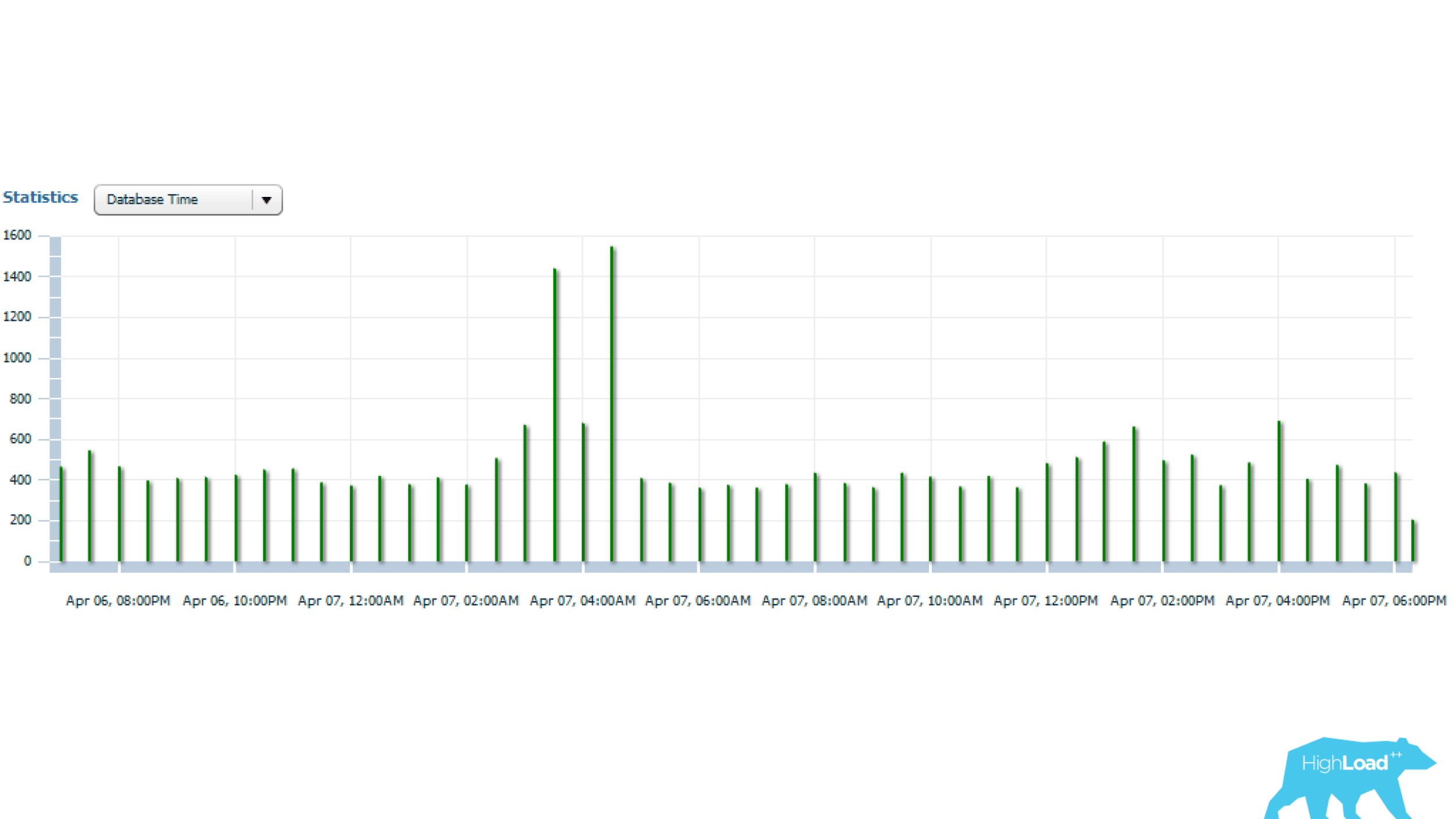
Vamos a resolverlo a continuación.
Oracle Enterprise Manager tiene una utilidad de monitoreo de SQL. Con esta utilidad puede ver en tiempo real el consumo de recursos a pedido.

Informe anterior para solicitud problemática. En primer lugar, deberíamos estar interesados en el hecho de que el ESCANEO DE RANGO DE ÍNDICE (línea inferior) en la columna Filas reales muestra 17 millones de líneas. Probablemente vale la pena considerarlo.
Si observamos más a fondo el plan de implementación, resulta que después del siguiente elemento del plan, de estos 17 millones de líneas, solo quedan 1705. La pregunta es, ¿por qué se eligieron 17 millones? Alrededor del 0.01% permaneció en la muestra final, es decir
, obviamente ineficiente, se realizó un trabajo innecesario . Además, este trabajo se realiza cada 5 minutos. ¡Aquí está el problema! Por lo tanto, esta solicitud llegó a las principales consultas.
Intentemos resolver este problema no trivial. El índice que se pide en primer lugar es ineficiente, por lo que debe encontrar algo complicado y vencer las condiciones IS NULL.
Nuevo índice
Consultamos con los desarrolladores, pensamos y llegamos a esta decisión: hicimos un índice funcional en el que hay una columna ID_PROCESSING, que tenía la condición de igualdad en la solicitud, e incluimos todos los demás campos como argumentos de esta función:
create index gc.loy$barcod_unload_i on gc.loy$barcodes (gc.loy_barcodes_ic_unload(id_rec_out, barcode, id_card, status), id_processing); function loy_barcodes_ic_unload( pIdRecOut in loy$barcodes.id_rec_out%type, pBarcode in loy$barcodes.barcode%type, pIdCard in loy$barcodes.id_card%type, pStatus in loy$barcodes.status%type) return varchar2 deterministic is vRes varchar2(1) := ''; begin if pIdRecOut is null and pBarcode is not null and pIdCard is not null and pStatus = 'U' then vRes := pStatus; end if; return vRes; end loy_barcodes_ic_unload;
Esta función es de tipo determinista, es decir, en el mismo conjunto de parámetros siempre da la misma respuesta. Nos aseguramos de que esta función siempre devolviera un valor, en este caso "U". Cuando se cumplen todas estas condiciones, se emite "U", cuando no se cumple: NULL. Tal índice funcional hace posible filtrar efectivamente los datos.
La aplicación de este índice condujo al siguiente resultado:
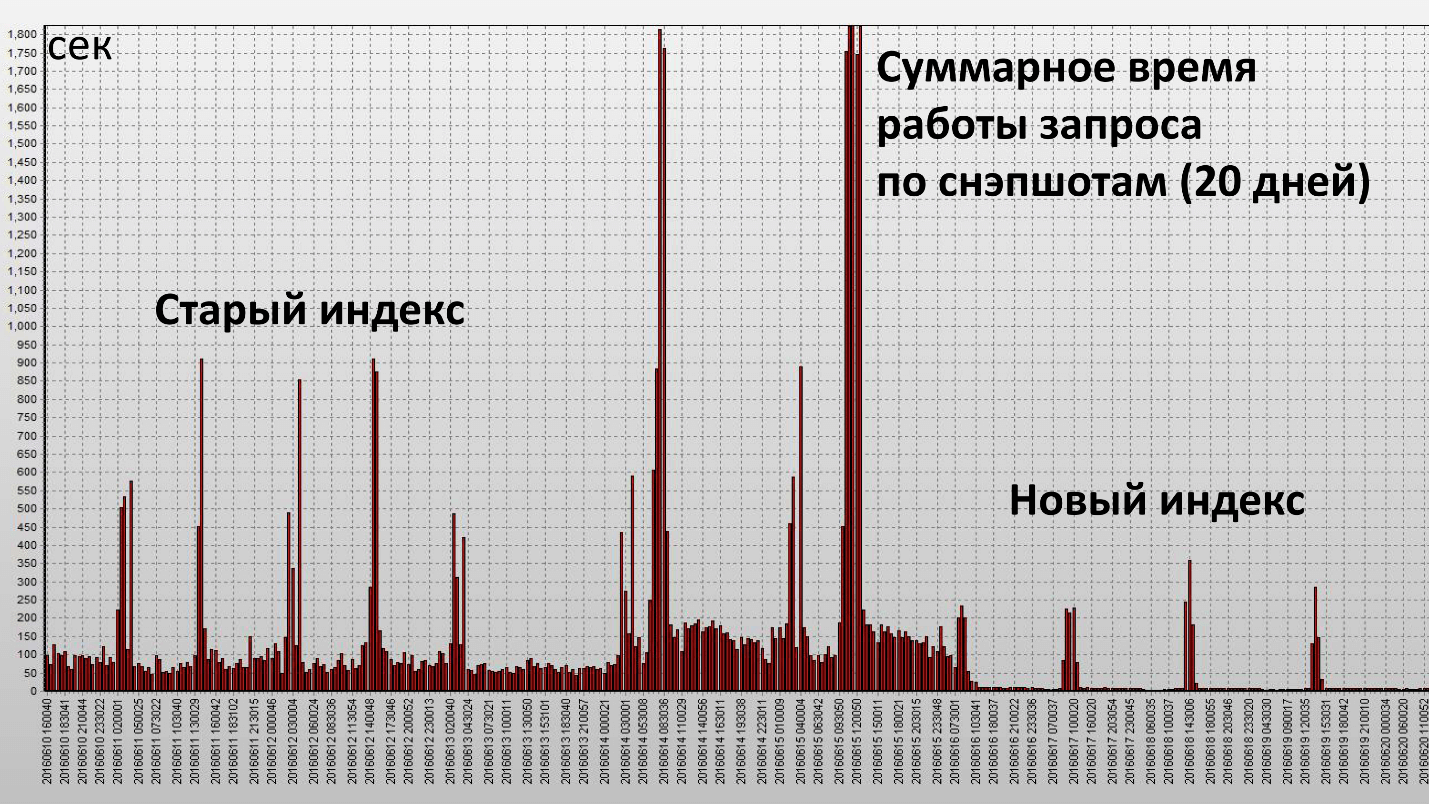
Aquí, una columna es una instantánea, se realizan cada media hora de la base de datos. Hemos logrado nuestro objetivo y este índice ha sido realmente efectivo. Veamos las características cuantitativas:
Estadísticas de solicitud promedio
|
| Antes
| DESPUÉS
|
Tiempo transcurrido, seg.
| 143,21
| 60,7
|
Tiempo de CPU, seg.
| 33,23
| 45,38
|
Buffer Gets Block
| 6`288`237.67
| 1`589`836
|
Bloque de lecturas de disco
| 266`600.33
| 2`680
|
El tiempo de operación disminuyó en 2.5 veces, y el consumo de recursos (Buffer Gets) - en aproximadamente 4. El número de bloques de datos leídos del disco disminuyó significativamente.
Resultados de optimización proactiva
Hemos recibido:
- reduciendo la carga en la base de datos;
- mejorando la estabilidad de la base de datos;
- Una reducción significativa en el número de incidentes de rendimiento del software.
Los incidentes de rendimiento disminuyeron 10 veces . Esta es una cantidad subjetiva, antes de que ocurrieran los incidentes en el complejo RBS-Retail Bank 1-2 veces al mes, pero ahora prácticamente nos hemos olvidado de ellos.
Esto plantea la pregunta: ¿qué pasa con los incidentes de rendimiento del software? ¿No tratamos con ellos directamente?
De vuelta al último horario. Si recuerdas, hubo un escaneo completo, fue necesario para almacenar una gran cantidad de bloques en la memoria. Como la solicitud se ejecutó regularmente, todos estos bloques se almacenaron en el caché de Oracle. Resulta que si en este momento se produce una alta carga en la base de datos, por ejemplo, alguien comienza a usar la memoria de forma activa, necesitará un caché para almacenar bloques de datos. Por lo tanto, parte de los datos de nuestra solicitud se eliminarán, lo que significa que tendremos que hacer lecturas físicas. Si realiza lecturas físicas, el tiempo de ejecución de la consulta aumentará enormemente de inmediato.
La lectura lógica funciona con la memoria, ocurre rápidamente y cualquier acceso al disco es lento (si observa la hora, milisegundos). Si tiene suerte, y existen estos datos en la memoria caché del sistema operativo o en la memoria caché de la matriz, aún serán decenas de microsegundos. Leer desde el caché de Oracle es mucho más rápido.
Cuando nos deshicimos de la exploración completa, desapareció la necesidad de almacenar una cantidad tan grande de bloques en el caché (Buffer Cache). Cuando hay escasez de estos recursos, la solicitud es más o menos estable. Ya no hay picos tan grandes que estaban con el índice anterior.
Resumen de optimización proactiva:- La optimización de la consulta inicial debe llevarse a cabo en servidores de prueba, para ver cómo funcionan las consultas y su lógica de negocios, para no hacer nada superfluo. Estas obras permanecen.
- Pero periódicamente, una vez cada pocos meses, tiene sentido eliminar informes del servidor a plena carga, hacer una búsqueda de las principales consultas y operaciones en la base de datos y optimizarlas.
Existen muchas herramientas para obtener estadísticas en una base de datos Oracle:- Informe de AWR (DBMS_WORKLOAD_REPOSITORY.awr_report_html);
- Enterprise Manager Cloud Control 12c (Detalles de SQL);
- Informe activo de detalles de SQL (DBMS_PERF.report_sql);
- Monitoreo SQL (pestaña en EMCC);
- Informe de supervisión de SQL (DBMS_SQLTUNE.report_sql_monitor *).
Algunas de estas herramientas funcionan en la consola, es decir, no están vinculadas al Enterprise Manager.
Ejemplos de herramientas de Oracle para recopilar estadísticas Bonificación: los especialistas del "Centro de pagos" de RNCO y CFT estaban bien preparados para la conferencia en Novosibirsk, hicieron algunos informes útiles y también organizaron una verdadera radio de salida. Durante dos días, expertos, oradores y organizadores lograron visitar la radio CFT. Puede regresar al verano siberiano incluyendo entradas, aquí están los enlaces a los bloques:
Kubernetes: pros y contras ;
Ciencia de datos y aprendizaje automático ;
DevOps .
En HighLoad ++ en Moscú, que ya es el 8 y 9 de noviembre, habrá cosas aún más interesantes. El programa incluye informes sobre todos los aspectos del trabajo en proyectos altamente cargados, clases magistrales, reuniones y eventos de socios que compartirán consejos de expertos y encontrarán algo para sorprender. Asegúrese de escribir sobre lo más interesante y notifíquelo en el boletín , ¡conéctese!