¿Qué es el lenguaje de consulta GraphQL? ¿Qué ventajas ofrece esta tecnología y qué problemas enfrentarán los desarrolladores al usarla? ¿Cómo usar GraphQL de manera efectiva? Sobre todo esto bajo el corte.

El artículo se basa en el informe de nivel introductorio de
Vladimir Tsukur (
volodymyrtsukur ) de la conferencia
Joker 2017 .
Mi nombre es Vladimir, lidero el desarrollo de uno de los departamentos de WIX. Más de cien millones de usuarios de WIX crean sitios web de varias direcciones, desde sitios y tiendas de tarjetas de presentación hasta complejas aplicaciones web donde puede escribir código y lógica arbitraria. Como ejemplo vivo de un proyecto en WIX, me gustaría mostrarle la exitosa tienda del sitio
unicornadoptions.com , que ofrece la oportunidad de comprar un kit para domesticar un unicornio, un gran regalo para un niño.

Un visitante de este sitio puede elegir un kit que le guste para domar a un unicornio, decir rosa, luego ver qué hay exactamente en este kit: juguete, certificado, insignia. Además, el comprador tiene la oportunidad de agregar productos a la cesta, ver su contenido y realizar un pedido. Este es un ejemplo simple de un sitio de tienda, y tenemos muchos, cientos de miles de dichos sitios. Todos ellos están construidos en la misma plataforma, con un backend, con un conjunto de clientes que admitimos usando la API para esto. Se trata de la API que se discutirá más a fondo.
API simple y sus problemas
Imaginemos qué API de uso general (es decir, una API para todas las tiendas en la parte superior de la plataforma) podríamos crear para proporcionar la funcionalidad de la tienda. Concentrémonos únicamente en la obtención de datos.
Para una página de producto en dicho sitio, se debe devolver el nombre del producto, el precio, las imágenes, la descripción, la información adicional y mucho más. En una solución completa para tiendas en WIX, hay más de dos docenas de dichos campos de datos. La solución estándar para dicha tarea sobre la API HTTP es describir el recurso
/products/:id , que devuelve los datos del producto en la solicitud
GET . El siguiente es un ejemplo de datos de respuesta:
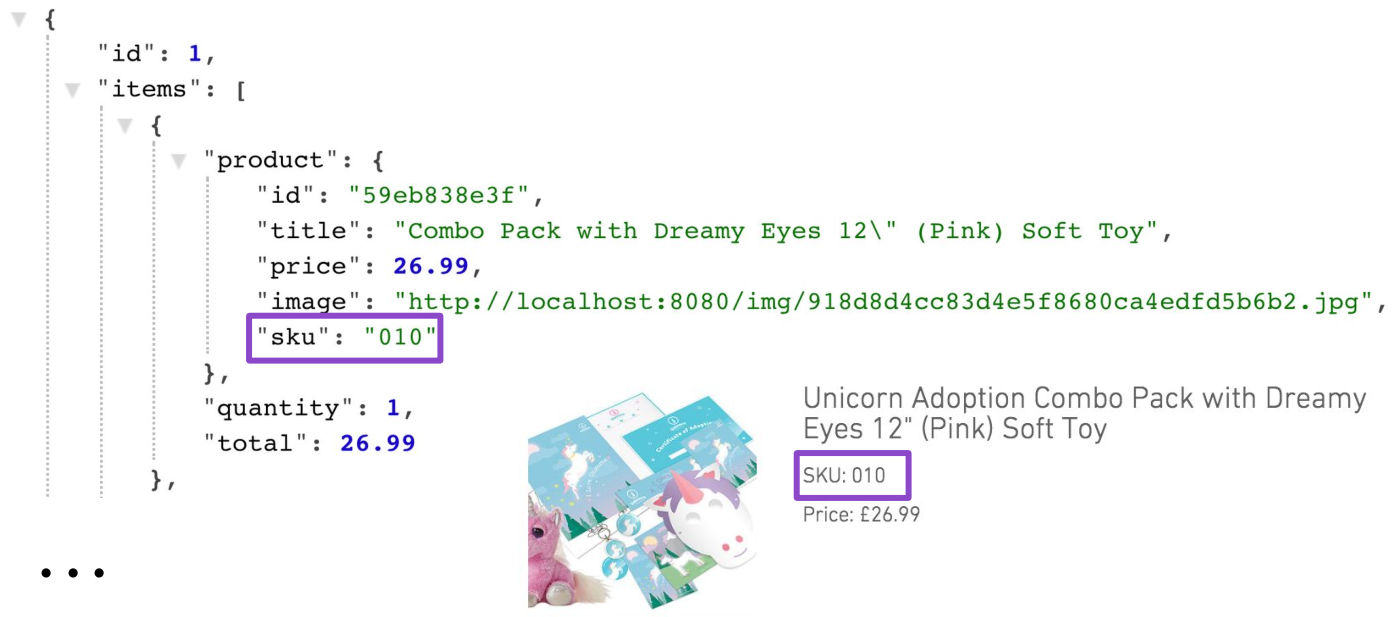
{ "id": "59eb83c0040fa80b29938e3f", "title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy", "price": 26.99, "description": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt today!", "sku":"010", "images": [ "http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg", "http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg", "http://localhost:8080/img/dd55129473e04f489806db0dc6468dd9.jpg", "http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg", "http://localhost:8080/img/5727549e9131440dbb3cd707dce45d0f.jpg", "http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg" ] }

Veamos la página del catálogo de productos ahora. Para esta página, necesita la colección de recursos
/ productos . Pero solo al mostrar la colección de productos en la página del catálogo, no se necesitan todos los datos del producto, sino solo el precio, el nombre y la imagen principal. Por ejemplo, la descripción, información adicional, imágenes de fondo, etc. no nos interesan.

Supongamos, por simplicidad, que decidimos usar el mismo modelo de datos del producto para los recursos
/products y
/products/:id . En el caso de una colección de tales productos, potencialmente habrá varios. El esquema de respuesta se puede representar de la siguiente manera:
GET /products [ { title price images description info ... } ]
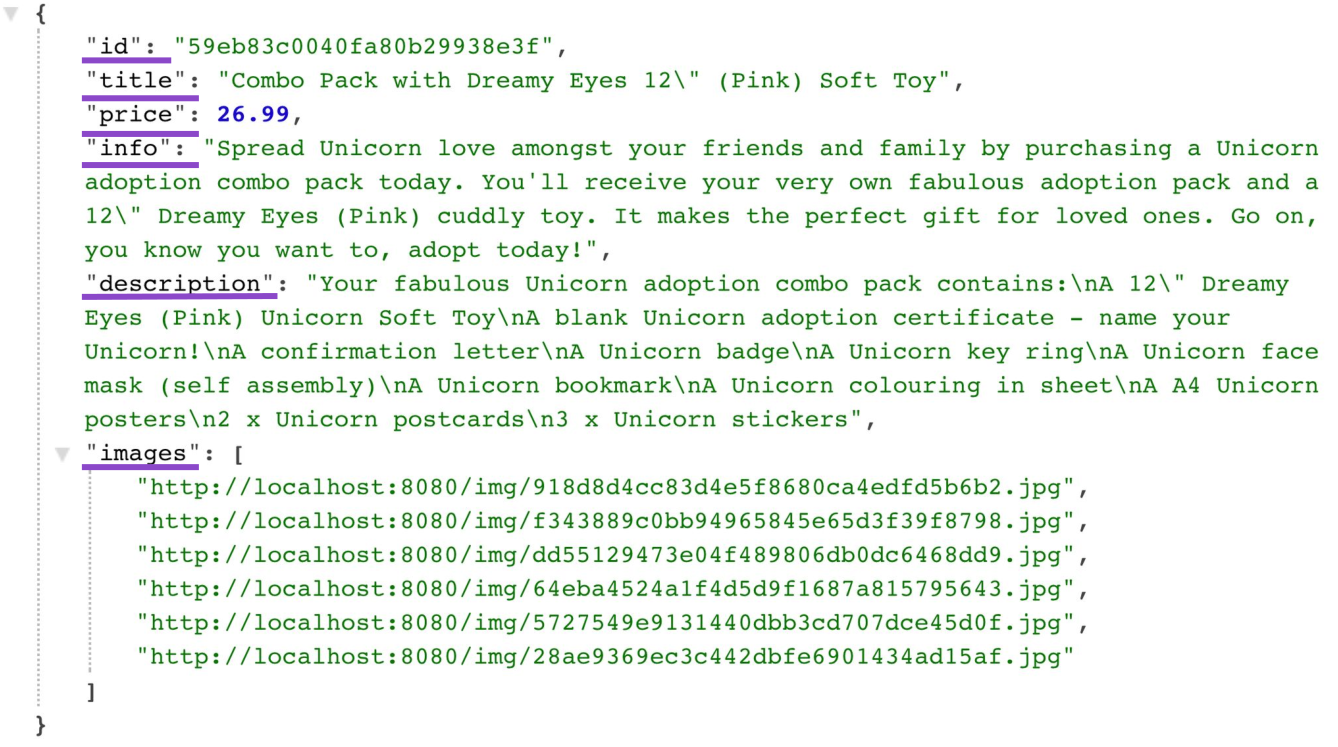
Ahora veamos la "carga útil" de la respuesta del servidor para la colección de productos. Esto es lo que realmente utiliza el cliente entre más de dos docenas de campos:
{
"id": "59eb83c0040fa80b29938e3f",
"title": "Combo Pack with Dreamy Eyes 12\" (Pink) Soft Toy",
"price": 26.99,
"info": "Spread Unicorn love amongst your friends and family by purchasing a Unicorn adoption combo pack today. You'll receive your very own fabulous adoption pack and a 12\" Dreamy Eyes (Pink) cuddly toy. It makes the perfect gift for loved ones. Go on, you know you want to, adopt todayl",
" description": "Your fabulous Unicorn adoption combo pack contains:\nA 12\" Dreamy Eyes (Pink) Unicorn Soft Toy\nA blank Unicorn adoption certificate — name your Unicorn!\nA confirmation letter\nA Unicorn badge\nA Unicorn key ring\nA Unicorn face mask (self assembly)\nA Unicorn bookmark\nA Unicorn colouring in sheet\nA A4 Unicorn posters\n2 x Unicorn postcards\n3 x Unicorn stickers",
"images": [
"http://localhost:8080/img/918d8d4cc83d4e5f8680ca4edfd5b6b2.jpg",
"http://localhost:8080/img/f343889c0bb94965845e65d3f39f8798.jpg",
"http://localhost:8080/img/dd55129473604f489806db0dC6468dd9.jpg",
"http://localhost:8080/img/64eba4524a1f4d5d9f1687a815795643.jpg",
"http://localhost:8080/img/5727549e9l3l440dbb3cd707dce45d0f.jpg",
"http://localhost:8080/img/28ae9369ec3c442dbfe6901434ad15af.jpg"
],
...
}Obviamente, si quiero mantener el modelo del producto simple devolviendo los mismos datos, entonces termino con un problema de sobrecarga, obteniendo en algunos casos más datos de los que necesito. En este caso, esto apareció en la página del catálogo de productos, pero en general, cualquier pantalla de interfaz de usuario que de alguna manera esté conectada con el producto requerirá de ella potencialmente solo una parte (y no todos) de los datos.
Miremos la página del carrito ahora. En la cesta, además de los productos en sí, también hay su cantidad (en esta cesta), el precio y el costo total de todo el pedido:

Si continuamos con el enfoque de modelado simple de la API HTTP, la canasta se puede representar a través de resource
/ carts /: id , cuya presentación se refiere a los recursos de los productos agregados a esta canasta:
{ "id": 1, "items": [ { "product": "/products/59eb83c0040fa80b29938e3f", "quantity": 1, "total": 26.99 }, { "product": "/products/59eb83c0040fa80b29938e40", "quantity": 2, "total": 25.98 }, { "product": "/products/59eb88bd040fa8125aa9c400", "quantity": 1, "total": 26.99 } ], "subTotal": 79.96 }
Ahora, por ejemplo, para dibujar una canasta con tres productos en la parte frontal, debe realizar cuatro solicitudes: una para cargar la canasta y tres solicitudes para cargar los datos del producto (nombre, precio y número de SKU).
El segundo problema que tuvimos fue una recuperación insuficiente. La diferenciación de responsabilidades entre la canasta y los recursos del producto ha llevado a la necesidad de realizar solicitudes adicionales. Obviamente, hay una serie de inconvenientes aquí: debido
a una mayor cantidad de solicitudes, aterrizamos la batería del teléfono móvil más rápido y obtenemos la respuesta completa más lentamente. Y la escalabilidad de nuestra solución también plantea preguntas.
Por supuesto, esta solución no es adecuada para la producción. Una forma de deshacerse del problema es agregar soporte de proyección para la canasta. Una de esas proyecciones podría, además de los datos de la canasta misma, devolver datos sobre productos. Además, esta proyección será muy específica, ya que es en la página de la cesta donde necesita el número de inventario (SKU) del producto. En ningún otro lugar se necesitaba SKU en ningún otro lugar.
GET /carts/1?projection=with-products
Tal "ajuste" de recursos para una IU específica generalmente no termina, y comenzamos a generar otras proyecciones: información breve sobre la canasta, la proyección de la canasta para la web móvil y luego la proyección de los unicornios.

(En general, en el Diseñador WIX, usted como usuario puede configurar qué datos del producto desea mostrar en la página del producto y qué datos mostrar en la cesta)
Y aquí nos esperan dificultades: estamos enmarcando el jardín y buscando soluciones complejas. Existen pocas soluciones estándar desde el punto de vista de la API para dicha tarea, y generalmente dependen en gran medida del marco o la biblioteca de descripción de recursos HTTP.
Lo que es aún más importante, ahora se está volviendo más difícil trabajar, porque cuando los requisitos del lado del cliente cambian, el backend debe "ponerse al día" constantemente y satisfacerlos.
Como "guinda del pastel", veamos otro tema importante. En el caso de una API HTTP simple, el desarrollador del servidor no tiene idea de qué tipo de datos está utilizando el cliente. ¿Se usa el precio? Descripción? ¿Una o todas las imágenes?
En consecuencia, surgen varias preguntas. ¿Cómo trabajar con datos obsoletos / obsoletos? ¿Cómo sé qué datos ya no se usan? ¿Cómo es relativamente seguro eliminar datos de la respuesta sin romper la mayoría de los clientes? No hay respuesta a estas preguntas con la API HTTP habitual. A pesar de que somos optimistas y la API parece ser simple, la situación no parece tan buena. Este rango de problemas de API no es exclusivo de WIX. Un gran número de empresas tuvieron que tratar con ellos. Ahora es interesante ver una posible solución.
GraphQL. Inicio
En 2012, en el proceso de desarrollo de una aplicación móvil, Facebook enfrentó un problema similar. Los ingenieros querían lograr el número mínimo de llamadas de aplicaciones móviles al servidor, mientras que en cada paso recibían solo los datos necesarios y nada más que ellos. El resultado de sus esfuerzos fue GraphQL, presentado en la conferencia React Conf 2015. GraphQL es un lenguaje de descripción de consultas, así como un entorno de tiempo de ejecución para estas consultas.

Considere un enfoque típico para trabajar con servidores GraphQL.
Describimos el esquema
El esquema de datos en GraphQL define los tipos y las relaciones entre ellos y lo hace de una manera fuertemente tipada. Por ejemplo, imagine un modelo simple de una red social.
User sabe sobre amigos
friends . Los usuarios viven en la ciudad, y la ciudad conoce a sus habitantes a través del campo de los
citizens . Esto es lo que es un gráfico de dicho modelo en GraphQL:
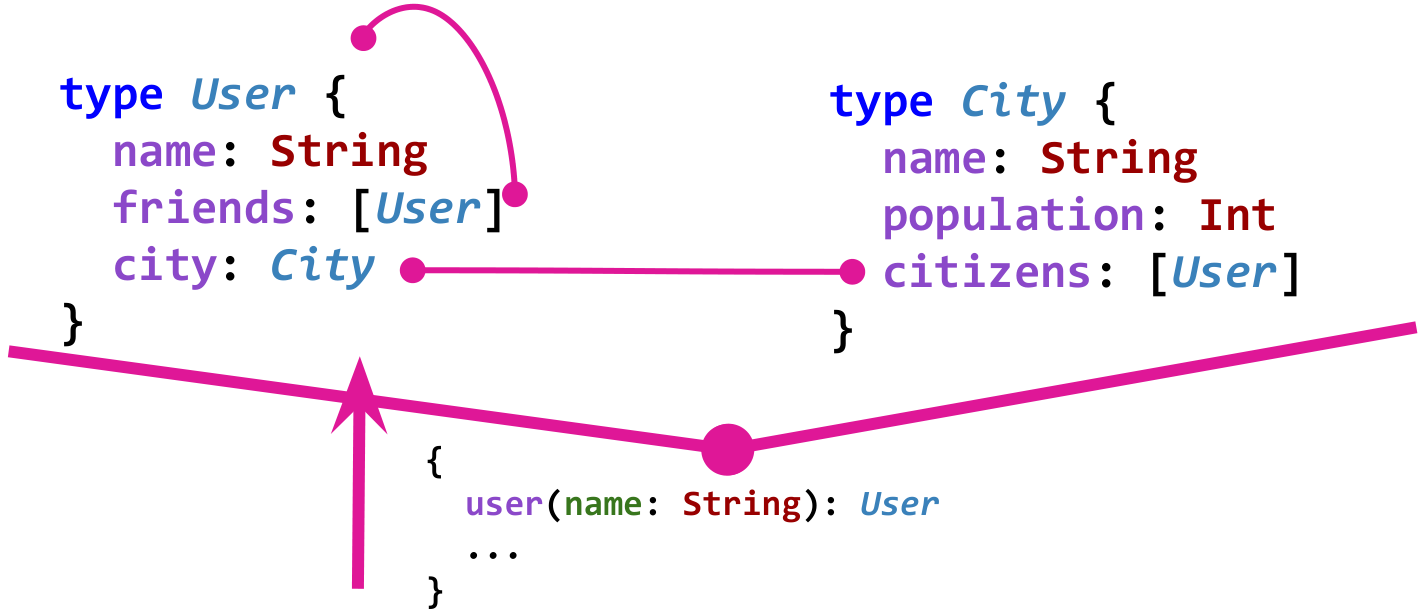
Por supuesto, para que el gráfico sea útil, también se necesitan los llamados "puntos de entrada". Por ejemplo, dicho punto de entrada podría ser obtener un usuario por su nombre.
Solicitar datos
Veamos cuál es la esencia del lenguaje de consulta GraphQL. Vamos a traducir esta pregunta a este idioma:
"Para un usuario llamado Vanya Unicorn, quiero saber los nombres de sus amigos, así como el nombre y la población de la ciudad en la que vive Vanya" :
{ user(name: "Vanya Unicorn") { friends { name } city { name population } } }
Y aquí viene la respuesta del servidor GraphQL:
{ "data": { "user": { "friends": [ { "name": "Lena" }, { "name": "Stas" } ] "city": { "name": "Kyiv", "population": 2928087 } } } }
Observe cómo el formulario de solicitud es "consonante" con el formulario de respuesta. Existe la sensación de que este lenguaje de consulta fue creado para JSON. Con mecanografía fuerte. Y todo esto se hace en una solicitud HTTP POST: no es necesario realizar varias llamadas al servidor.
Veamos cómo se ve en la práctica. Abramos la consola estándar para el servidor GraphQL, que se llama Graph
i QL ("gráfico"). Para solicitar una cesta, cumpliré la siguiente solicitud:
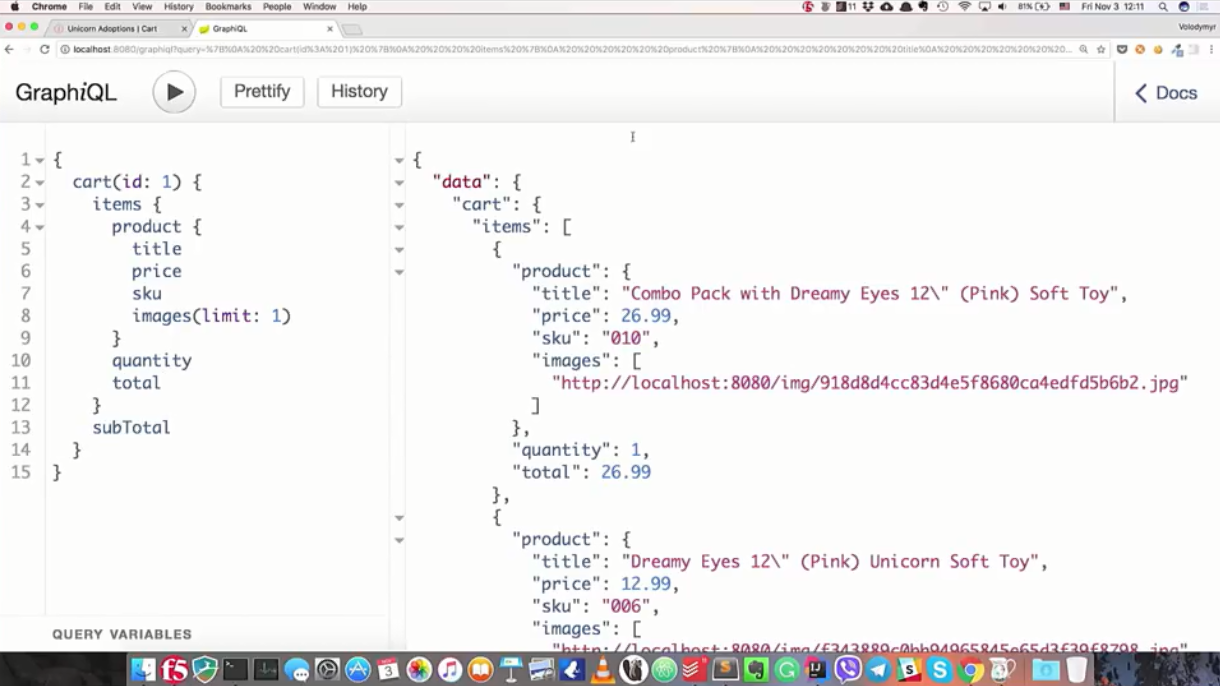
"Quiero obtener una cesta por el identificador 1, estoy interesado en todas las posiciones de esta cesta e información del producto. De la información, el nombre, el precio, el número de inventario y las imágenes son importantes (y solo el primero). También me interesa la cantidad de estos productos, cuál es su precio y el costo total en la cesta " .
{ cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
Después de completar con éxito la solicitud, obtenemos exactamente lo que se pidió:
Beneficios clave
- Muestreo flexible. El cliente puede realizar una solicitud de acuerdo con sus requisitos específicos.
- Muestreo efectivo. La respuesta devuelve solo los datos solicitados.
- Desarrollo más rápido. Muchos cambios en el cliente pueden ocurrir sin la necesidad de cambiar nada en el lado del servidor. Por ejemplo, según nuestro ejemplo, puede mostrar fácilmente una vista diferente de la cesta para web móvil.
- Análisis útiles Como el cliente debe indicar los campos explícitamente en la solicitud, el servidor sabe exactamente qué campos son realmente necesarios. Y esta es información importante para la política de desaprobación.
- Funciona sobre cualquier fuente de datos y transporte. Es importante que GraphQL le permita trabajar sobre cualquier fuente de datos y cualquier transporte. En este caso, HTTP no es una panacea, GraphQL también puede funcionar a través de WebSocket, y tocaremos este punto un poco más adelante.
Hoy, un servidor GraphQL se puede hacer en casi cualquier idioma. La versión más completa del servidor
GraphQL es
GraphQL.js para la plataforma Node. En la comunidad Java, la implementación de referencia es
GraphQL Java .
Crea la API GraphQL
Veamos cómo crear un servidor GraphQL en un ejemplo de vida concreta.
Considere una versión simplificada de una tienda en línea basada en una arquitectura de microservicio con dos componentes:
- Servicio de carro que proporciona trabajo con una canasta personalizada. Almacena datos en una base de datos relacional y usa SQL para acceder a los datos. Servicio muy simple, sin demasiada magia :)
- Servicio de productos que proporciona acceso al catálogo de productos, desde el cual, de hecho, se llena la cesta. Proporciona una API HTTP para acceder a los datos del producto.
Ambos servicios se implementan sobre el clásico Spring Boot y ya contienen toda la lógica básica.
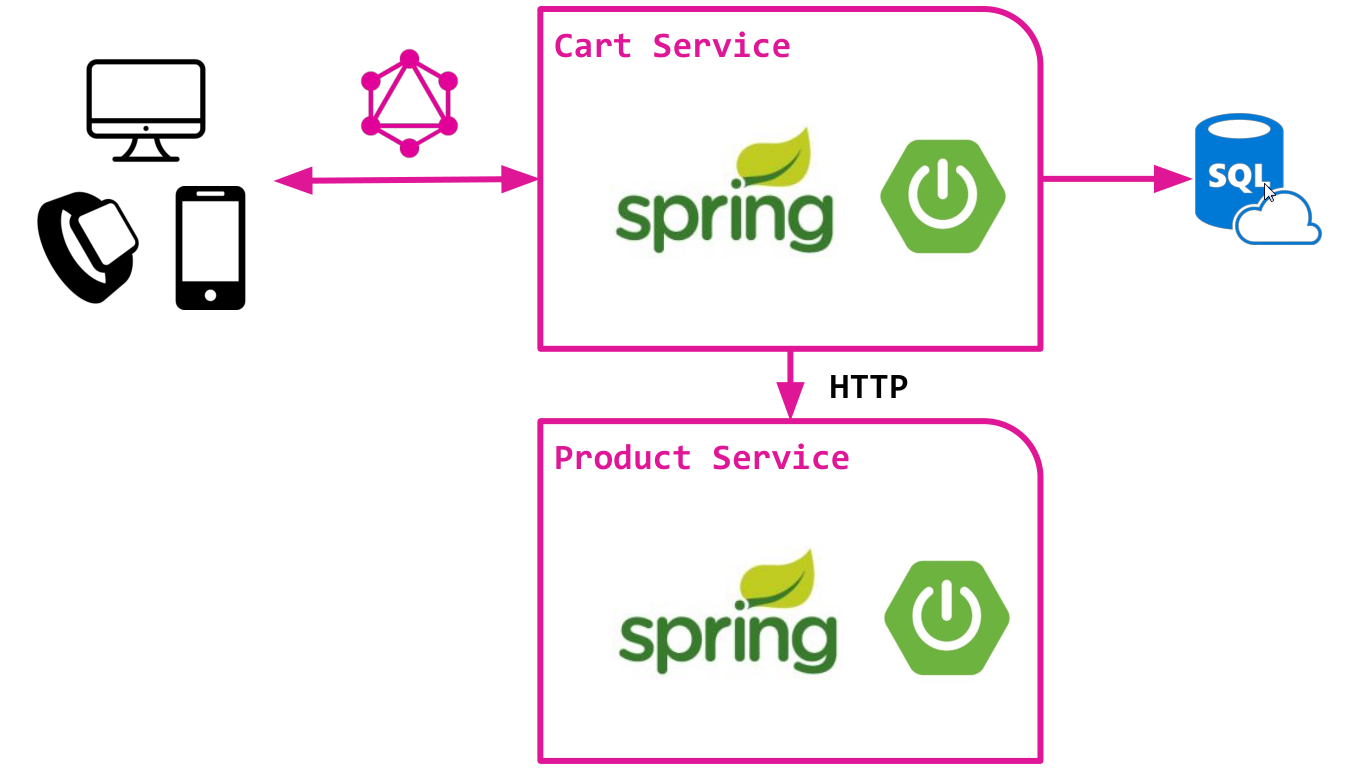
Tenemos la intención de crear la API GraphQL sobre el servicio Cart. Esta API está diseñada para proporcionar acceso a los datos de la cesta y los productos que se le agregan.
Primera versión
La implementación de referencia GraphQL para el ecosistema Java, que mencionamos anteriormente, GraphQL Java, nos ayudará.
Agregue algunas dependencias a
pom.xml: <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java</artifactId> <version>9.3</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-java-tools</artifactId> <version>5.2.4</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency> <dependency> <groupId>com.graphql-java</groupId> <artifactId>graphiql-spring-boot-starter</artifactId> <version>5.0.2</version> </dependency>
Además de
graphql-java mencionado anteriormente
graphql-java necesitaremos una biblioteca de
graphql-java-tools, así como "iniciadores" Spring Boot para GraphQL, lo que simplificará en gran medida los primeros pasos para crear un servidor GraphQL:
- graphql-spring-boot-starter proporciona un mecanismo para conectar rápidamente GraphQL Java a Spring Boot;
- graphiql-spring-boot-starter agrega una consola web interactiva Graph i QL para ejecutar consultas GraphQL.
El siguiente paso importante es determinar el esquema de servicio graphQL, nuestro gráfico. Los nodos de este gráfico se describen con
tipos y los bordes con
campos . Una definición de gráfico vacía se ve así:
schema { }
En este mismo esquema, como recordará, hay "puntos de entrada" o consultas de nivel superior. Se definen a través del campo de
consulta en el esquema. Llame a nuestro tipo para
obtener puntos de entrada
EntryPoints :
schema { query: EntryPoints }
Definimos en él una búsqueda de cesta por identificador como el primer punto de entrada:
type EntryPoints { cart(id: Long!): Cart }
Cart no es más que un
campo en términos de GraphQL.
id es un parámetro de este campo con el tipo escalar
Long . Signo de exclamación
! después de especificar el tipo significa que se requiere el parámetro.
Es hora de identificar y escribir
Cart :
type Cart { id: Long! items: [CartItem!]! subTotal: BigDecimal! }
Además de la
id estándar, la cesta incluye los elementos de sus artículos y la cantidad de todos los productos
subTotal . Tenga en cuenta que los
elementos se definen como una lista, como se indica entre corchetes
[] . Los elementos de esta lista son tipos
CartItem . ¡La presencia de un signo de exclamación después del nombre del tipo de campo
! indica que el campo es obligatorio. Esto significa que el servidor acepta devolver un valor no vacío para este campo, si se solicitó uno.
Queda por ver la definición del tipo
CartItem , que incluye un enlace al producto (
productId ), cuántas veces se agrega a la cesta (
quantity ) y la cantidad del producto, calculada sobre el número (
total ):
type CartItem { productId: String! quantity: Int! total: BigDecimal! }
Aquí todo es simple: todos los campos de tipos escalares son obligatorios.
Este esquema no fue elegido por casualidad. El servicio de Carrito ya ha definido la cesta del Carrito y sus elementos
CartItem con exactamente los mismos nombres y tipos de campo que en el esquema GraphQL. El modelo de carrito utiliza la biblioteca de Lombok para generar / obtener, establecer y construir automáticamente, y otros métodos. JPA se utiliza para la persistencia en la base de datos.
Clase de
Cart :
import lombok.Data; import javax.persistence.*; import java.math.BigDecimal; import java.util.ArrayList; import java.util.List; @Entity @Data public class Cart { @Id @GeneratedValue private Long id; @ElementCollection(fetch = FetchType.EAGER) private List<CartItem> items = new ArrayList<>(); public BigDecimal getSubTotal() { return getItems().stream() .map(Item::getTotal) .reduce(BigDecimal.ZERO, BigDecimal::add); } }
Clase
CartItem :
import lombok.AllArgsConstructor; import lombok.Data; import javax.persistence.Column; import javax.persistence.Embeddable; import java.math.BigDecimal; @Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
Por lo tanto, la cesta (
Cart ) y los elementos de la cesta (
CartItem ) se describen tanto en el diagrama GraphQL como en el código, y son "compatibles" entre sí según el conjunto de campos y sus tipos. Pero esto todavía no es suficiente para que nuestro servicio funcione.
Necesitamos aclarar exactamente cómo funcionará el punto de entrada "
cart(id: Long!): Cart ". Para hacer esto, cree una configuración Java extremadamente simple para Spring con un bean de tipo GraphQLQueryResolver. GraphQLQueryResolver solo describe los "puntos de entrada" en el esquema. Definimos un método con un nombre idéntico al campo en el punto de entrada (
cart ), lo hacemos compatible por tipo de parámetros y usamos
cartService para encontrar el mismo carrito por identificador:
@Bean public GraphQLQueryResolver queryResolver() { return new GraphQLQueryResolver () { public Cart cart(Long id) { return cartService.findCart(id); } } }
Estos cambios son suficientes para que podamos obtener una aplicación que funcione. Después de reiniciar el servicio Cart en la consola GraphiQL, la siguiente consulta comenzará a ejecutarse correctamente:
{ cart(id: 1) { items { productId quantity total } subTotal } }
Nota
- Utilizamos los tipos escalares
Long y String como identificadores únicos para la cesta y el producto. GraphQL tiene un tipo especial para tales propósitos: ID . Semánticamente, esta es una mejor opción para una API real. Los valores de ID de tipo se pueden usar como clave para el almacenamiento en caché.
- En esta etapa del desarrollo de nuestra aplicación, los modelos de dominio interno y externo son completamente idénticos. Estamos hablando de las
CartItem Cart y CartItem y su uso directo en los solucionadores GraphQL. En aplicaciones de combate, se recomienda separar estos modelos. Para los resolvers de GraphQL, debe existir un modelo separado del área temática interna.
Hacer que la API sea útil
Entonces obtuvimos el primer resultado, y esto es maravilloso. Pero ahora nuestra API es demasiado primitiva. Por ejemplo, hasta ahora no hay forma de solicitar datos útiles sobre un producto, como su nombre, precio, artículo, imágenes, etc. En cambio, solo hay un
productId . Hagamos que la API sea realmente útil y agreguemos soporte completo para el concepto del producto. Así es como se ve su definición en el diagrama:
type Product { id: String! title: String! price: BigDecimal! description: String sku: String! images: [String!]! }
Agregue el campo requerido a
CartItem y
productId campo productId como obsoleto:
type Item { quantity: Int! product: Product! productId: String! @deprecated(reason: "don't use it!") total: BigDecimal! }
Descubrimos el esquema. Y ahora es el momento de describir cómo funcionará la selección para el campo del
product . Anteriormente confiamos en getters en las
CartItem Cart y
CartItem , lo que permitió a GraphQL Java enlazar automáticamente los valores. Pero aquí debe recordarse que solo la propiedad del
product en la clase
CartItem no
CartItem :
@Embeddable @Data @AllArgsConstructor public class CartItem { @Column(nullable = false) private String productId; @Column(nullable = false) private int quantity; @Column(nullable = false) private BigDecimal total; }
Tenemos una opción:
- Agregue la propiedad del producto a CartItem y "enséñele" cómo recibir datos del producto;
- Determine cómo obtener el producto sin cambiar la clase CartItem .
La segunda forma es preferible, porque el modelo de la descripción del dominio interno (clase
CartItem ) en este caso no se cubrirá con detalles de la implementación de la API Graph
i QL.
Para lograr este objetivo, la interfaz de marcador GraphQLResolver ayudará. Al implementarlo, puede determinar (o anular) cómo obtener los valores de campo para el tipo
T Así es como se ve el bean correspondiente en la configuración de Spring:
@Bean public GraphQLResolver<CartItem> cartItemResolver() { return new GraphQLResolver<CartItem>() { public Product product(CartItem item) { return http.getForObject("http://localhost:9090/products/{id}", Product.class, item.getProductId()); } }; }
El nombre del método del
product no fue elegido por casualidad. GraphQL Java está buscando métodos de descarga de datos por nombre de campo, ¡y solo necesitábamos definir un cargador para el campo del
product ! Un objeto de tipo
CartItem pasado como parámetro define el contexto en el que se selecciona el producto. Lo siguiente es una cuestión de tecnología. Usando un cliente
http como
RestTemplate realizamos una solicitud GET al servicio del Producto y convertimos el resultado a
Product , que se ve así:
@Data public class Product { private String id; private String title; private BigDecimal price; private String description; private String sku; private List<String> images; }
Estos cambios deberían ser suficientes para implementar una muestra más interesante, que incluye la verdadera relación entre la canasta y los productos que se le agregan.
Después de reiniciar la aplicación, puede probar una nueva consulta en la consola Graph
i QL.
{ cart(id: 1) { items { product { title price sku images } quantity total } subTotal } }
Y aquí está el resultado de la ejecución de la consulta:

Aunque
productId ha marcado como
@deprecated , las consultas que indican este campo continuarán funcionando. Pero la consola Graph
i QL no ofrecerá autocompletar para tales campos y destacará su uso de una manera especial:

Es hora de mostrar Document Explorer, parte de la consola Graph
i QL, que se basa en el esquema GraphQL y muestra información sobre todos los tipos definidos. Así es como se ve Document Explorer para el tipo
CartItem :

Pero volvamos al ejemplo. Para lograr la misma funcionalidad que en la primera demostración, todavía no hay un límite suficiente para el número de imágenes devueltas. De hecho, para una cesta, por ejemplo, solo necesita una imagen para cada producto:
images(limit: 1)
Para hacer esto, cambie el esquema y agregue un nuevo parámetro para el campo de
imágenes al Tipo de
producto :
type Product { id: ID! title: String! price: BigDecimal! description: String sku: String! images(limit: Int = 0): [String!]! }
Y en el código de la aplicación lo usaremos nuevamente GraphQLResolver, solo que esta vez por tipo Product: @Bean public GraphQLResolver<Product> productResolver() { return new GraphQLResolver<Product>() { public List<String> images(Product product, int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }; }
Nuevamente llamo la atención sobre el hecho de que el nombre del método no es accidental: coincide con el nombre del campo images. El objeto de contexto Productda acceso a las imágenes y limites un parámetro del campo en sí.Si el cliente no especificó nada como valor para limit, entonces nuestro servicio devolverá todas las imágenes del producto. Si el cliente especificó un valor específico, el servicio devolverá exactamente la misma cantidad (pero no más de lo que hay en el producto).Compilamos el proyecto y esperamos hasta que el servidor se reinicie. Al reiniciar el circuito en la consola y ejecutar la solicitud, vemos que una solicitud completa realmente funciona. { cart(id: 1) { items { product { title price sku images(limit: 1) } quantity total } subTotal } }
De acuerdo, todo esto es muy bueno. En poco tiempo, no solo aprendimos qué es GraphQL, sino que también transferimos un sistema de microservicio simple para admitir dicha API. Y no nos importó de dónde provenían los datos: tanto las API de SQL como las de HTTP se ajustan bien bajo un mismo techo.Code-First y GraphQL SPQR Approach
Es posible que haya notado que durante el proceso de desarrollo hubo algunos inconvenientes, a saber, la necesidad de mantener constantemente sincronizados el código y el esquema GraphQL. Los cambios de tipo siempre tuvieron que hacerse en dos lugares. En muchos casos, es más conveniente utilizar el enfoque de código primero. Su esencia es que el esquema para GraphQL se genera automáticamente a partir del código. En este caso, no necesita mantener el circuito por separado. Ahora voy a mostrar cómo se ve.Solo las características básicas de GraphQL Java no son suficientes para nosotros, también necesitaremos la biblioteca GraphQL SPQR. La buena noticia es que GraphQL SPQR es un complemento para GraphQL Java, y no una implementación alternativa del servidor GraphQL en Java.Agregue la dependencia deseada a pom.xml: <dependency> <groupId>io.leangen.graphql</groupId> <artifactId>spqr</artifactId> <version>0.9.8</version> </dependency>
Aquí está el código que implementa la misma funcionalidad basada en GraphQL SPQR para la cesta: @Component public class CartGraph { private final CartService cartService; @Autowired public CartGraph(CartService cartService) { this.cartService = cartService; } @GraphQLQuery(name = "cart") public Cart cart(@GraphQLArgument(name = "id") Long id) { return cartService.findCart(id); } }
Y para el producto: @Component public class ProductGraph { private final RestTemplate http; @Autowired public ProductGraph(RestTemplate http) { this.http = http; } @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); } @GraphQLQuery(name = "images") public List<String> images(@GraphQLContext Product product, @GraphQLArgument(name = "limit", defaultValue = "0") int limit) { List<String> images = product.getImages(); int normalizedLimit = limit > 0 ? limit : images.size(); return images.subList(0, Math.min(normalizedLimit, images.size())); } }
La anotación @GraphQLQuery se usa para marcar los métodos del cargador de campo. La anotación @GraphQLContextdefine el tipo de selección para el campo. Y la anotación @GraphQLArgumentmarca claramente los parámetros del argumento. Todos estos son partes de un mecanismo que ayuda a GraphQL SPQR a generar un esquema automáticamente. Ahora, si elimina la configuración y el esquema de Java anterior, reinicie el servicio Cart utilizando los nuevos chips de GraphQL SPQR, puede asegurarse de que todo funcione de la misma manera que antes.Resolvemos el problema de N + 1
, « ». GraphQL API, ?
:

cart SQL- .
items subtotal , , JPA- eager fetch:
@Data public class Cart { @ElementCollection(fetch = FetchType.EAGER) private List<Item> items = new ArrayList<>(); ... }
 Cuando se trata de descargar datos en productos, las solicitudes de un servicio de Producto se ejecutarán exactamente tanto como en esta canasta de productos. Si hay tres productos diferentes en la cesta, recibiremos tres solicitudes a la API HTTP del servicio del producto, y si hay diez de ellos, entonces el mismo servicio tendrá que responder a diez de esas solicitudes.
Cuando se trata de descargar datos en productos, las solicitudes de un servicio de Producto se ejecutarán exactamente tanto como en esta canasta de productos. Si hay tres productos diferentes en la cesta, recibiremos tres solicitudes a la API HTTP del servicio del producto, y si hay diez de ellos, entonces el mismo servicio tendrá que responder a diez de esas solicitudes. Aquí está la comunicación entre el servicio de Carrito y el servicio de Producto en Charles Proxy: en
Aquí está la comunicación entre el servicio de Carrito y el servicio de Producto en Charles Proxy: en consecuencia, volvemos al clásico problema N + 1. Exactamente de la que intentaron tanto escaparse al comienzo del informe. Indudablemente, tenemos progreso, porque se ejecuta exactamente una solicitud entre el cliente final y nuestro sistema. Pero dentro del ecosistema del servidor, el rendimiento claramente necesita ser mejorado.Quiero resolver este problema obteniendo todos los productos correctos en una sola solicitud. Afortunadamente, el servicio del Producto ya admite esta característica a través de un parámetro
consecuencia, volvemos al clásico problema N + 1. Exactamente de la que intentaron tanto escaparse al comienzo del informe. Indudablemente, tenemos progreso, porque se ejecuta exactamente una solicitud entre el cliente final y nuestro sistema. Pero dentro del ecosistema del servidor, el rendimiento claramente necesita ser mejorado.Quiero resolver este problema obteniendo todos los productos correctos en una sola solicitud. Afortunadamente, el servicio del Producto ya admite esta característica a través de un parámetro idsen el recurso de recopilación: GET /products?ids=:id1,:id2,...,:idn
Veamos cómo puede modificar el código del método de muestra para el campo del producto . Versión anterior: @GraphQLQuery(name = "product") public Product product(@GraphQLContext CartItem cartItem) { return http.getForObject( "http://localhost:9090/products/{id}", Product.class, cartItem.getProductId() ); }
Reemplace con uno más efectivo: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}", Products.class, productIds ).getProducts(); }
Hicimos exactamente tres cosas:- marcó el método del gestor de arranque con la anotación @Batched , dejando en claro a GraphQL SPQR que la carga debería ocurrir con un lote;
- cambió el tipo de retorno y el parámetro de contexto a una lista, porque trabajar con el lote supone que se aceptan y devuelven varios objetos;
- cambió el cuerpo del método, implementando una selección de todos los productos necesarios a la vez.
Estos cambios son suficientes para resolver nuestro problema N + 1. La ventana de la aplicación Charles Proxy ahora muestra una solicitud al servicio de Producto, que devuelve tres productos a la vez:
Muestras de campo efectivas
Resolvimos el problema principal, ¡pero puede hacer la selección aún más rápido! Ahora el servicio del Producto devuelve todos los datos, independientemente de lo que necesite el cliente final. Podríamos mejorar la consulta y devolver solo los campos solicitados. Por ejemplo, si el cliente final no solicitó la imagen, ¿por qué necesitamos transferirla al servicio de Carrito?Es genial que la API HTTP del servicio del Producto ya sea compatible con esta función a través del parámetro de inclusión para el mismo recurso de recopilación: GET /products?ids=...?include=:field1,:field2,...,:fieldN
Para el método del gestor de arranque, agregue un parámetro de tipo Set con anotación @GraphQLEnvironment. GraphQL SPQR entiende que el código en este caso "solicita" una lista de nombres de campo que se solicitan para el producto, y los completa automáticamente: @GraphQLQuery(name = "product") @Batched public List<Product> products(@GraphQLContext List<Item> items, @GraphQLEnvironment Set<String> fields) { String productIds = items.stream() .map(Item::getProductId) .collect(Collectors.joining(",")); return http.getForObject( "http://localhost:9090/products?ids={ids}&include={fields}", Products.class, productIds, String.join(",", fields) ).getProducts(); }
Ahora nuestra muestra es realmente efectiva, sin el problema N + 1 y usa solo los datos necesarios:
Consultas "pesadas"
Imagine trabajar con un gráfico de usuario en una red social clásica como Facebook. Si dicho sistema proporciona la API GraphQL, entonces nada impide que el cliente envíe una solicitud de la siguiente naturaleza: { user(name: "Vova Unicorn") { friends { name friends { name friends { name friends { name ... } } } } } }
En el nivel de anidación 5-6, la implementación completa de dicha solicitud conducirá a una selección de todos los usuarios del mundo. El servidor ciertamente no podrá hacer frente a tal tarea de una sola vez y lo más probable es que simplemente "caiga".Hay una serie de medidas que deben tomarse para protegerse de tales situaciones:- Limite la profundidad de la solicitud. En otras palabras, no se debe permitir que los clientes soliciten datos de anidamiento arbitrario.
- Limite la complejidad de la solicitud. Al asignar un peso a cada campo y calcular la suma de los pesos de todos los campos en la solicitud, puede aceptar o rechazar tales solicitudes en el servidor.
Por ejemplo, considere la siguiente consulta: { cart(id: 1) { items { product { title } quantity } subTotal } }
Obviamente, la profundidad de tal solicitud es 4, porque el camino más largo está dentro de ella cart -> items -> product -> title.Si suponemos que el peso de cada campo es 1, teniendo en cuenta 7 campos en la consulta, su complejidad también es 7.En GraphQL Java, la superposición de las comprobaciones se logra indicando instrumentación adicional al crear el objeto GraphQL: GraphQL.newGraphQL(schema) .instrumentation(new ChainedInstrumentation(Arrays.asList( new MaxQueryComplexityInstrumentation(20), new MaxQueryDepthInstrumentation(3) ))) .build();
La instrumentación MaxQueryDepthInstrumentationverifica la profundidad de la solicitud y no permite que se inicien solicitudes demasiado "profundas" (en este caso, con una profundidad mayor que 3).La instrumentación MaxQueryComplexityInstrumentationantes de ejecutar una consulta cuenta y verifica su complejidad. Si este número excede el valor especificado (20), dicha solicitud es rechazada. Puede redefinir el peso para cada campo, porque algunos de ellos obviamente se vuelven "más difíciles" que otros. Por ejemplo, al campo del producto se le puede asignar complejidad 10 a través de la anotación @GraphQLComplexity,admitida en GraphQL SPQR: @GraphQLQuery(name = "product") @GraphQLComplexity("10") public List<Product> products(...)
Aquí hay un ejemplo de verificación de profundidad cuando excede claramente el valor especificado: Por cierto, el mecanismo de instrumentación no se limita a imponer restricciones. También se puede utilizar para otros fines, como el registro o el seguimiento.Examinamos las medidas de "protección" específicas de GraphQL. Sin embargo, hay una serie de trucos a los que vale la pena prestar atención independientemente del tipo de API:
Por cierto, el mecanismo de instrumentación no se limita a imponer restricciones. También se puede utilizar para otros fines, como el registro o el seguimiento.Examinamos las medidas de "protección" específicas de GraphQL. Sin embargo, hay una serie de trucos a los que vale la pena prestar atención independientemente del tipo de API:- limitación / limitación de velocidad: limite el número de solicitudes por unidad de tiempo
- tiempos de espera: límite de tiempo para operaciones con otros servicios, bases de datos, etc.
- paginación - soporte de paginación.
Mutación de datos
Hasta ahora, hemos estado considerando un mero muestreo de datos. Pero GraphQL le permite organizar orgánicamente no solo la recepción de datos, sino también su cambio. Hay un mecanismo para esto mutation: schema { query: EntryPoints, mutation: Mutations }
Por ejemplo, agregar un producto a una cesta puede organizarse mediante la siguiente mutación: type Mutations { addProductToCart(cartId: Long!, productId: String!, count: Int = 1): Cart }
Esto es similar a la definición de un campo, porque una mutación también tiene parámetros y un valor de retorno.La implementación de una mutación en el código del servidor usando GraphQL SPQR es la siguiente: @GraphQLMutation(name = "addProductToCart") public Cart addProductToCart( @GraphQLArgument(name = "cartId") Long cartId, @GraphQLArgument(name = "productId") String productId, @GraphQLArgument(name = "quantity", defaultValue = "1") int quantity) { return cartService.addProductToCart(cartId, productId, quantity); }
Por supuesto, la mayor parte del trabajo útil se realiza internamente cartService. Y la tarea de este método de capa intermedia es asociarlo con la API. Como en el caso del muestreo de datos, gracias a las anotaciones, es @GraphQL*muy fácil entender qué esquema GraphQL se genera a partir de esta definición de método.En la consola GraphQL, ahora puede realizar una solicitud de mutación para agregar un producto específico a nuestra cesta en una cantidad de 2: mutation { addProductToCart( cartId: 1, productId: "59eb83c0040fa80b29938e3f", quantity: 2) { items { product { title } quantity total } subTotal } }
Dado que la mutación tiene un valor de retorno, es posible solicitarle campos de acuerdo con las mismas reglas que para las muestras ordinarias.Varios equipos de desarrollo de WIX están utilizando activamente GraphQL con Scala y la biblioteca Sangria, la implementación principal de GraphQL en este lenguaje.Una de las técnicas útiles utilizadas en WIX es el soporte para consultas GraphQL cuando se procesa HTML. Hacemos esto para generar JSON directamente en el código de la página. Aquí hay un ejemplo de llenar una plantilla HTML: // Pre-rendered <html> <script data-embedded-graphiql> { product(productId: $productId) title description price ... } } </script> </html>
Y aquí está el resultado: // Rendered <html> <script> window.DATA = { product: { title: 'GraphQL Sticker', description: 'High quality sticker', price: '$2' ... } } </script> </html>
Tal combinación de renderizador HTML y servidor GraphQL nos permite reutilizar nuestra API al máximo y no crear una capa adicional de controladores. Además, esta técnica a menudo resulta ventajosa en términos de rendimiento, porque después de cargar la página, la aplicación JavaScript no necesita ir al backend para obtener los primeros datos necesarios, ya está en la página.Desventajas de GraphQL
Hoy, GraphQL utiliza una gran cantidad de empresas, incluidos gigantes como GitHub, Yelp, Facebook y muchos otros. Y si decide unir su número, debe conocer no solo las ventajas de GraphQL, sino también sus desventajas, y hay muchas de ellas:- -, GraphQL . GraphQL , HTTP API. Cache-Control Last-Modified HTTP GraphQL API. , proxy gateways (Varnish, Fastly ). , GraphQL , , .
- GraphQL — . , API, , .
- GraphQL . .
- . GraphQL — . JSON XML, , , GraphQL, .
- GraphQL . , HTTP PUT POST -. , . GraphQL . .
- . , -: «delete» «kill», «annihilate» «terminate», . GraphQL API . HTTP DELETE .
- Joker 2016 . GraphQL . API- , , , HATEOAS, , « REST». , , GraphQL .
También vale la pena recordar que si no logró desarrollar bien la API HTTP, lo más probable es que no pueda desarrollar la API GraphQL. Después de todo, ¿qué es lo más importante en el desarrollo de cualquier API? Separe el modelo de dominio interno del modelo de API externo. Cree una API basada en escenarios de uso, no en el dispositivo interno de la aplicación. Abra solo la información mínima necesaria, y no toda en una fila. Elige los nombres correctos. Describe la gráfica correctamente. Hay un gráfico de recursos en la API HTTP y un gráfico de campo en la API GraphQL. En ambos casos, este gráfico debe hacerse cualitativamente.Existen alternativas en el mundo de la API HTTP, y no siempre tiene que usar GraphQL cuando necesita selecciones complejas. Por ejemplo, existe el estándar OData, que admite selecciones parciales y en expansión, como GraphQL, y funciona sobre HTTP. Existe una API JSON estándar que funciona con JSON y admite capacidades de recuperación hipermedia y compleja. También está LinkRest, del que puede obtener más información en el https://youtu.be/EsldBtrb1Qc "> informe de Andrus Adamchik sobre Joker 2017.Para aquellos que quieran probar GraphQL, les recomiendo leer artículos de comparación de ingenieros que están muy familiarizados con REST y GraphQL desde un punto de vista práctico y filosófico:Finalmente sobre suscripciones y aplazar
GraphQL tiene una ventaja interesante sobre las API estándar. En GraphQL, los casos de uso síncronos y asíncronos pueden estar bajo el mismo techo.Consideramos recibir datos a través de usted query, cambiando el estado del servidor mutation, pero hay una bondad más. Por ejemplo, la capacidad de organizar suscripciones subscriptions.Imagine que un cliente desea recibir notificaciones sobre cómo agregar un producto a la cesta de forma asincrónica. A través de la API GraphQL, esto se puede hacer en base a dicho esquema: schema { query: Queries, mutation: Mutations, subscription: Subscriptions } type Subscriptions { productAdded(cartId: String!): Cart }
El cliente puede suscribirse a través de la siguiente solicitud: subscription { productAdded(cart: 1) { items { product ... } subTotal } }
Ahora, cada vez que se agrega un producto a la cesta 1, el servidor enviará a cada cliente suscrito un mensaje en WebSocket con los datos solicitados en la cesta. Nuevamente, continuando con la política GraphQL, solo vendrán los datos que el cliente solicitó al suscribirse: { "data": { "productAdded": { "items": [ { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … }, { "product": …, "subTotal": … } ], "subTotal": 289.33 } } }
El cliente ahora puede volver a dibujar la canasta, no necesariamente redibujando toda la página.Esto es conveniente porque tanto la API síncrona (HTTP) como la API asíncrona (WebSocket) se pueden describir a través de GraphQL.Otro ejemplo de uso de comunicación asincrónica es el mecanismo de aplazamiento . La idea principal es que el cliente elige qué datos quiere recibir de forma inmediata (sincrónica) y aquellos que está listo para recibir más tarde (asincrónicamente). Por ejemplo, para tal solicitud: query { feedStories { author { name } message comments @defer { author { name } message } } }
El servidor primero devolverá al autor y un mensaje para cada historia: { "data": { "feedStories": [ { "author": …, "message": … }, { "author": …, "message": … } ] } }
Después de eso, el servidor, después de recibir datos sobre los comentarios, los entregará al cliente a través de WebSocket de forma asincrónica, indicando en la ruta para la cual los comentarios del historial están ahora listos: { "path": [ "feedStories", 0, "comments" ], "data": [ { "author": …, "message": … } ] }
Fuente de muestra
El código utilizado para preparar este informe se puede encontrar en GitHub .Más recientemente, anunciamos JPoint 2019 , que se llevará a cabo del 5 al 6 de abril de 2019. Puede obtener más información sobre qué esperar de la conferencia desde nuestro centro . Hasta el primero de diciembre, los boletos Early Bird todavía están disponibles al precio más bajo.