Creación de enrutamiento de clientes / búsqueda semántica y agrupación de corpus externos arbitrarios en Profi.ru
TLDR
Este es un resumen ejecutivo muy breve (o un teaser) sobre lo que logramos hacer en aproximadamente 2 meses en el departamento de Profi.ru DS (estuve allí un poco más de tiempo, pero incorporarme a mí y a mi equipo fue algo aparte. hecho al principio).
Metas proyectadas
- Comprenda la entrada / intención del cliente y enrute a los clientes en consecuencia (al final, optamos por un clasificador agnóstico de calidad de entrada, aunque también consideramos modelos de nivel de caracteres de escritura anticipada y modelos de lenguaje. Reglas de simplicidad);
- Encuentre servicios y sinónimos totalmente nuevos para los servicios existentes;
- Como un objetivo secundario de (2): aprender a construir grupos adecuados en corpus externos arbitrarios;
Objetivos alcanzados
Obviamente, algunos de estos resultados fueron logrados no solo por nuestro equipo, sino por varios equipos (es decir, obviamente no hicimos la parte de raspado para los corpus de dominio y la anotación manual, aunque creo que nuestro equipo también puede resolver el raspado, solo necesita suficientes proxies + probablemente algo de experiencia con selenio).
Objetivos comerciales:
- ~
88+% (vs ~ 60% con búsqueda elástica) precisión en la clasificación del enrutamiento / intento del cliente (~ 5k clases); - La búsqueda es independiente de la calidad de entrada (erratas / entrada parcial);
- El clasificador generaliza, la estructura morfológica del lenguaje es explotada;
- El clasificador supera severamente la búsqueda elástica en varios puntos de referencia (ver más abajo);
- Para estar seguro: se encontraron al menos
1,000 nuevos servicios + al menos 15,000 sinónimos (en comparación con el estado actual de 5,000 + ~ 30,000 ). Espero que esta cifra se duplique o incluso triplique;
La última viñeta es una estimación aproximada, pero conservadora.
También se realizarán pruebas AB. Pero tengo confianza en estos resultados.
Objetivos "científicos":
- Comparamos a fondo muchas técnicas modernas de incrustación de oraciones utilizando una tarea de clasificación aguas abajo + KNN con una base de datos de sinónimos de servicio;
- Logramos superar la búsqueda elástica débilmente supervisada (esencialmente su clasificador es una bolsa de ngrams) en este punto de referencia (ver detalles a continuación) utilizando métodos NO SUPERVISADOS ;
- Desarrollamos una nueva forma de construir modelos de PNL aplicados (una simple bolsa de incrustaciones de vainilla bi-LSTM +, esencialmente texto rápido cumple con RNN): esto toma en consideración la morfología del idioma ruso y se generaliza bien;
- Demostramos que nuestra técnica de inclusión final (una capa de cuello de botella del mejor clasificador) combinada con algoritmos sin supervisión de última generación (UMAP + HDBSCAN) puede producir grupos estelares;
- Demostramos en la práctica la posibilidad, viabilidad y usabilidad de:
- Destilación del conocimiento;
- Aumentos para datos de texto (sic!);
- La capacitación de clasificadores basados en texto con aumentos dinámicos redujo drásticamente el tiempo de convergencia (10x) en comparación con la generación de conjuntos de datos estáticos más grandes (es decir, la CNN aprende a generalizar el error que se muestra con oraciones drásticamente menos aumentadas);
Estructura general del proyecto
Esto no incluye el clasificador final.
También, al final, abandonamos los modelos falsos de RNN y de pérdida de tripletes a favor del cuello de botella del clasificador.

¿Qué funciona en PNL ahora?
Una vista de pájaro:

También puede saber que NLP puede estar experimentando el momento Imagenet ahora .
Hack de UMAP a gran escala
Cuando construimos clústeres, nos topamos con una forma / truco para aplicar esencialmente UMAP a conjuntos de datos de más de 100 millones de puntos (o tal vez incluso mil millones). Esencialmente construya un gráfico KNN con FAISS y luego simplemente reescriba el bucle principal de UMAP en PyTorch usando su GPU. No necesitábamos eso y abandonamos el concepto (después de todo, teníamos solo 10-15 millones de puntos), pero sigan este hilo para más detalles.
Lo que funciona mejor
- Para la clasificación supervisada, el texto rápido cumple con el conjunto de n-gramos RNN (bi-LSTM) + cuidadosamente elegido;
- Implementación: python simple para n-gramos + capa de bolsa de inclusión PyTorch;
- Para el agrupamiento: la capa de cuello de botella de este modelo + UMAP + HDBSCAN;
Los mejores puntos de referencia clasificadores
Conjunto de desarrollo anotado manualmente
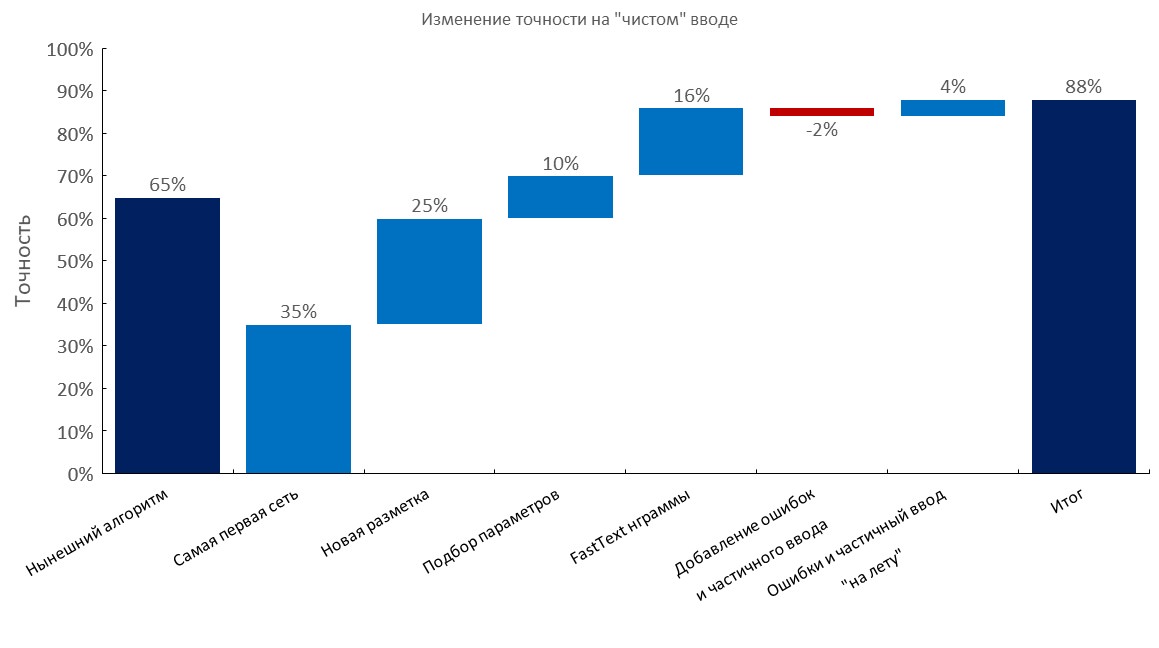
De izquierda a derecha
(Precisión Top1)
- Algoritmo actual (búsqueda elástica);
- Primer RNN;
- Nueva anotación;
- Tuning
- Capa de bolsa de incrustación de texto rápido;
- Agregar errores tipográficos y entrada parcial;
- Generación dinámica de errores y entrada parcial ( tiempo de entrenamiento reducido 10x );
- Puntuación final
Conjunto de desarrollo anotado manualmente + 1-3 errores por consulta

De izquierda a derecha
(Precisión Top1)
- Algoritmo actual (búsqueda elástica);
- Capa de bolsa de inclusión de texto rápido;
- Agregar errores tipográficos y entrada parcial;
- Generación dinámica de errores y entrada parcial;
- Puntuación final
Conjunto de desarrollo anotado manualmente + entrada parcial
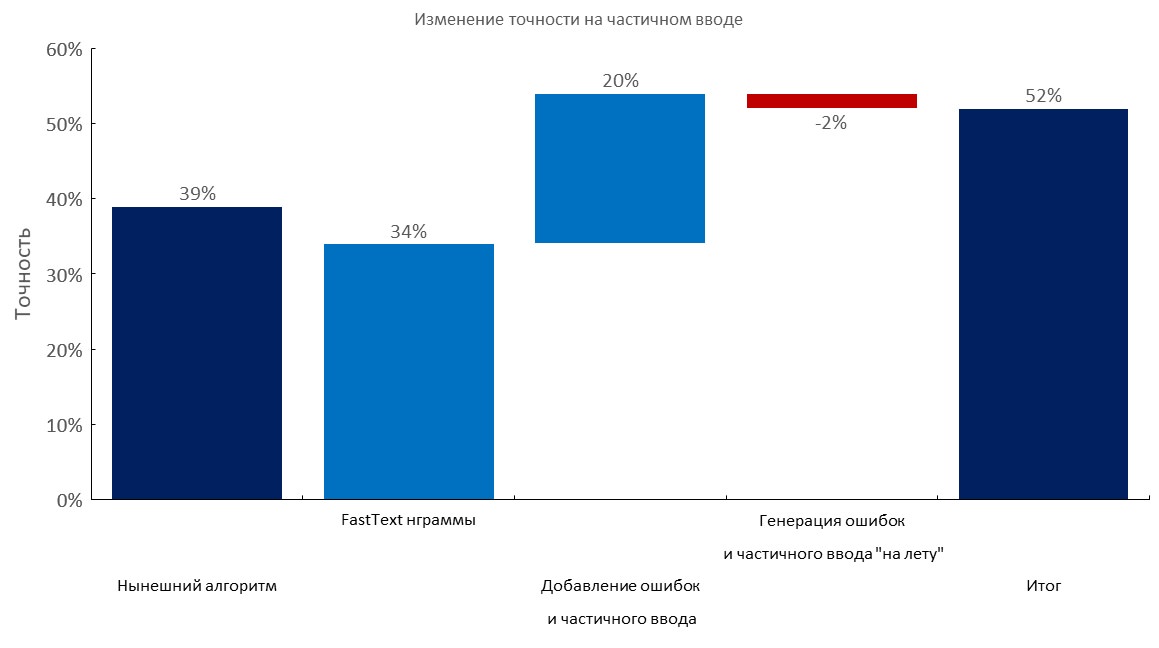
De izquierda a derecha
(Precisión Top1)
- Algoritmo actual (búsqueda elástica);
- Capa de bolsa de incrustación de texto rápido;
- Agregar errores tipográficos y entrada parcial;
- Generación dinámica de errores y entrada parcial;
- Puntuación final
Corpus a gran escala / selección de n-gramas
- Recolectamos los corpus más grandes para el idioma ruso:
- Areneum - una versión procesada está disponible aquí - los autores del conjunto de datos no respondieron;
- Taiga
- Common crawl and wiki : siga estos artículos;
- Recopilamos un diccionario de palabras de
100m con 1 TB de rastreo ; - También use este truco para descargar dichos archivos más rápido (durante la noche);
- Seleccionamos un conjunto óptimo de
1m n-gramos para que nuestro clasificador generalice mejor ( 500k n-gramos más populares de texto rápido entrenado en Wikipedia en ruso + 500k n-gramos más populares en nuestros datos de dominio);
Prueba de resistencia de nuestros 1M n-gramos en vocabulario 100M:

Aumentos de texto
En pocas palabras:
- Tome un diccionario grande con errores (por ejemplo, 10-100m palabras únicas);
- Genere un error (suelte una letra, cambie una letra usando probabilidades calculadas, inserte una letra aleatoria, tal vez use la distribución del teclado, etc.);
- Verifique que la nueva palabra esté en el diccionario;
Bruto forzamos muchas consultas a servicios como este (en un intento de realizar ingeniería inversa en su conjunto de datos), y tienen un diccionario muy pequeño en su interior (también este servicio funciona con un clasificador de árbol con funciones de n-gramo). Fue divertido ver que cubrían solo el 30-50% de las palabras que teníamos en algunos corpus .
Nuestro enfoque es muy superior si tiene acceso a un amplio vocabulario de dominio .
Los mejores resultados sin supervisión / semi-supervisados
KNN se utiliza como punto de referencia para comparar diferentes métodos de inclusión.
(tamaño del vector) Lista de modelos probados:
- (512) Detector de oraciones falsas a gran escala capacitado en 200 GB de datos de rastreo comunes;
- (300) Detector de frases falsas entrenado para distinguir una frase aleatoria de Wikipedia de un servicio;
- (300) Texto rápido obtenido de aquí, pre-entrenado en araneum corpus;
- (200) Texto rápido entrenado en nuestros datos de dominio;
- (300) Texto rápido entrenado en 200 GB de datos de rastreo común;
- (300) Una red siamesa con pérdida de triplete entrenada con servicios / sinónimos / oraciones aleatorias de Wikipedia;
- (200) Primera iteración de la capa de incrustación de la bolsa de inclusión RNN, una oración se codifica como una bolsa completa de incrustaciones;
- (200) Lo mismo, pero primero la oración se divide en palabras, luego cada palabra se incrusta, luego se toma el promedio;
- (300) Lo mismo que arriba pero para el modelo final;
- (300) Lo mismo que arriba pero para el modelo final;
- (250) Capa de cuello de botella del modelo final (250 neuronas);
- Línea de base de búsqueda elástica débilmente supervisada;
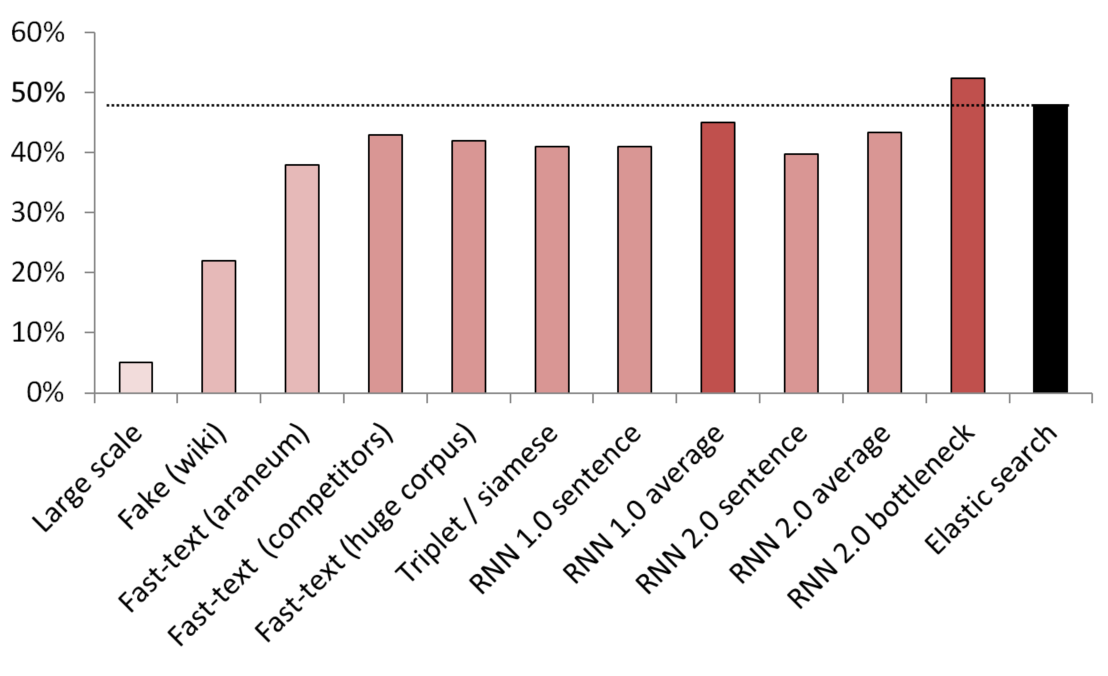
Para evitar fugas, todas las oraciones aleatorias se muestrearon aleatoriamente. Su extensión en palabras fue la misma que la duración de los servicios / sinónimos con los que se compararon. También se tomaron medidas para asegurarse de que los modelos no solo aprendieran separando vocabularios (las incrustaciones se congelaron, Wikipedia se submuestreó para asegurarse de que hubiera al menos una palabra de dominio en cada oración de Wikipedia).
Visualización de clúster
3D

2D

"Interfaz" de exploración de clústeres
Verde - nueva palabra / sinónimo.
Fondo gris - probablemente nueva palabra.
Texto gris: sinónimo existente.

Pruebas de ablación y qué funciona, qué probamos y qué no.
- Ver los cuadros anteriores;
- Promedio simple / tf-idf promedio de incrustaciones de texto rápido: una línea de base MUY formidable ;
- Texto rápido> Word2Vec para ruso;
- La incrustación de oraciones mediante la detección de oraciones falsas funciona, pero palidece en comparación con otros métodos;
- BPE (oración) no mostró mejoras en nuestro dominio;
- Los modelos de nivel de char lucharon por generalizar, a pesar del papel retractado de google;
- Probamos un transformador de múltiples cabezales (con clasificador y cabezales de modelado de lenguaje), pero en la anotación disponible a mano, funcionó más o menos igual que los modelos basados en LSTM. Cuando migramos a incorporar malos enfoques, abandonamos esta línea de investigación debido a la menor practicidad del transformador y la impracticabilidad de tener un cabezal LM junto con una capa de bolsa de inclusión;
- BERT : parece ser excesivo, también algunas personas afirman que los transformadores entrenan literalmente durante semanas;
- ELMO : usar una biblioteca como AllenNLP parece contraproducente en mi opinión tanto en entornos de investigación / producción como en educación por razones que no proporcionaré aquí;
Implementar
Hecho usando:
- Contenedor Docker con un servicio web simple;
- CPU solo para inferencia es suficiente;
- ~
2.5 ms por consulta en la CPU, el procesamiento por lotes no es realmente necesario; - ~
1GB memoria RAM; - Casi no hay dependencias, aparte de
PyTorch , numpy y pandas (y servidor web ofc). - Imite la generación de n-gramas de texto rápido como esta ;
- Incrustar la capa de bolsa + índices como recién almacenados en un diccionario;