En servicios grandes, resolver un problema usando el aprendizaje automático significa hacer solo una parte del trabajo. Incrustar modelos ML no es tan fácil, y construir procesos de CI / CD a su alrededor es aún más difícil. En la conferencia de Yandex
"Datos y ciencia: el programa de aplicación", Adam Eldarov
, jefe de ciencia de datos en YouDo, habló sobre cómo administrar el ciclo de vida de los modelos, configurar procesos de reciclaje y reciclaje, desarrollar microservicios escalables y mucho más.
- Comencemos con la introducción. Hay un científico de datos, escribe un código en el cuaderno de Jupyter, hace ingeniería de características, validación cruzada, entrena modelos de modelos. La velocidad está creciendo.

Pero en algún momento lo comprende: para aportar un valor comercial a la empresa, debe adjuntar la solución en algún lugar de la producción, a una producción mítica, lo que nos causa muchos problemas. La computadora portátil que vimos en producción en la mayoría de los casos no se puede enviar. Y surge la pregunta: cómo enviar este código dentro de la computadora portátil a un determinado servicio. En la mayoría de los casos, debe escribir un servicio que tenga una API. O se comunican a través de PubSub, a través de colas.

Cuando hacemos recomendaciones, a menudo necesitamos entrenar modelos y volver a entrenarlos. Este proceso debe ser monitoreado. En este caso, siempre se debe verificar con pruebas tanto el código en sí como los modelos, para que en un momento nuestro modelo no se vuelva loco y no siempre comience a predecir cero. También debe verificarse en usuarios reales a través de pruebas AB: lo que hicimos mejor o al menos no peor.
¿Cómo nos acercamos al código? Tenemos GitLab Todo nuestro código se divide en muchas bibliotecas pequeñas que resuelven un problema de dominio específico. Al mismo tiempo, es un proyecto separado de GitLab, control de versiones de Git y el modelo de ramificación de GitFlow. Usamos cosas como ganchos de confirmación previa para que no pueda confirmar código que no satisface nuestras comprobaciones de prueba de estadísticas. Y las pruebas mismas, pruebas unitarias. Utilizamos el enfoque de prueba basado en la propiedad para ellos.

Por lo general, cuando escribe pruebas, quiere decir que tiene una función de prueba y los argumentos que crea con sus manos, algunos ejemplos y qué valores devuelve su función de prueba. Esto es inconveniente. El código está inflado, muchos en principio son demasiado vagos para escribirlo. Como resultado, tenemos un montón de código descubierto por las pruebas. Las pruebas basadas en propiedades implican que todos sus argumentos tienen una cierta distribución. Hagamos fases, y muchas veces muestreemos todos nuestros argumentos de estas distribuciones, llamemos a la función bajo prueba con estos argumentos, y verifiquemos que ciertas propiedades sean el resultado de esta función. Como resultado, tenemos mucho menos código y, al mismo tiempo, hay muchas más pruebas.
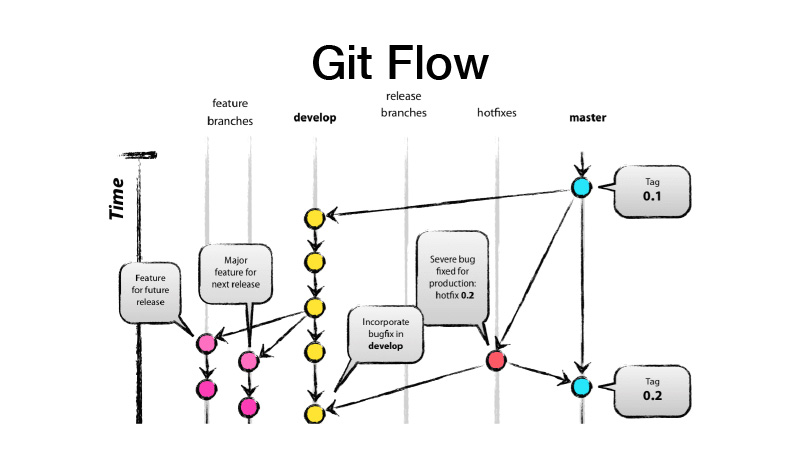
¿Qué es GitFlow? Este es un modelo de ramificación, lo que implica que tiene dos ramas principales: desarrollo y maestro, donde se encuentra el código listo para producción, y todo el desarrollo se lleva a cabo en la rama de desarrollo, donde todas las nuevas características se obtienen de los brunches de características. Es decir, cada característica es un nuevo brunch de características, mientras que el brunch de características debe ser de corta duración y para siempre, también cubierto a través de la alternancia de características. Luego hacemos un lanzamiento, desde dev lanzamos los cambios a master y ponemos la etiqueta de versión de nuestra biblioteca o servicio en él.
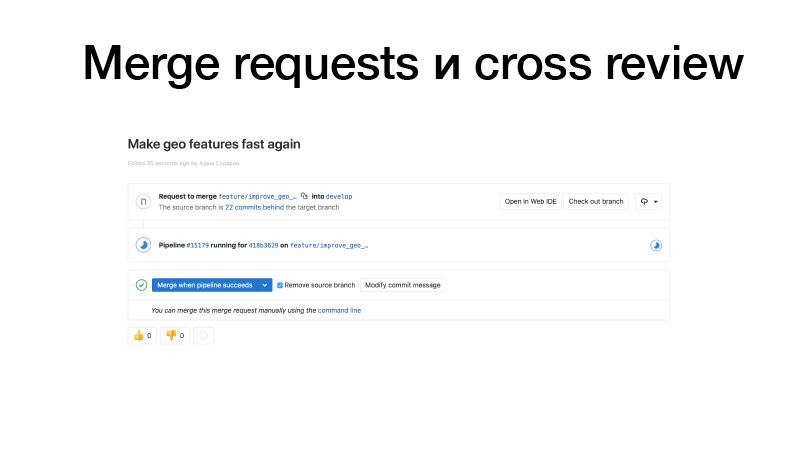
Estamos desarrollando, recogiendo algunas funciones, introduciéndolas en GitLab, creando una solicitud de fusión del brunch de funciones a las doncellas. Los disparadores funcionan, ejecutan pruebas, si todo está bien, podemos congelarlo. Pero no somos nosotros quienes lo sostenemos, sino alguien del equipo. Revisa el código y, por lo tanto, aumenta el factor de bus. Esta sección de código ya es conocida por dos personas. Como resultado, si alguien es atropellado por un autobús, alguien ya sabe lo que está haciendo.

La integración continua para bibliotecas generalmente parece pruebas para cualquier cambio. Y si lo lanzamos, también se publica en el servidor privado PyPI de nuestro paquete.
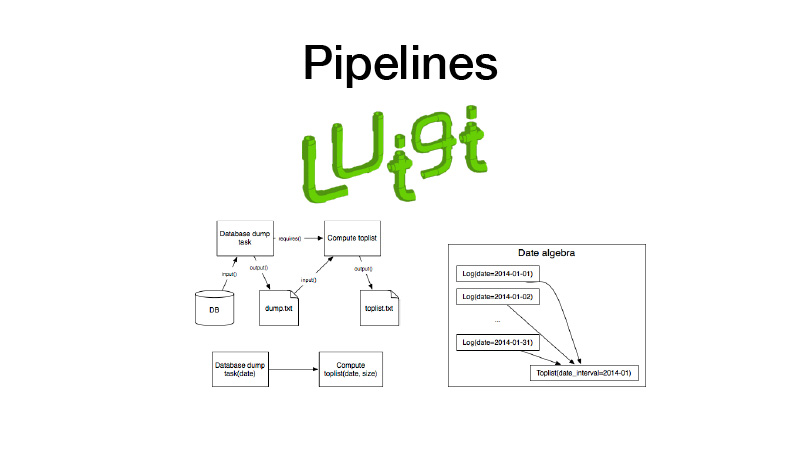
Además podemos recogerlo en tuberías. Para esto usamos la biblioteca Luigi. Funciona con una entidad como la tarea, que tiene una salida, donde se guarda el artefacto creado durante la ejecución de la tarea. Hay un parámetro de tarea que parametriza la lógica de negocios que ejecuta, identifica la tarea y su salida. Al mismo tiempo, las tareas siempre tienen requisitos que otras tareas plantean. Cuando ejecutamos algún tipo de tarea, todas sus dependencias se verifican mediante la verificación de sus salidas. Si la salida existe, nuestra dependencia no se inicia. Si falta el artefacto en algún almacenamiento, se inicia. Esto forma una tubería, un gráfico cíclico dirigido.
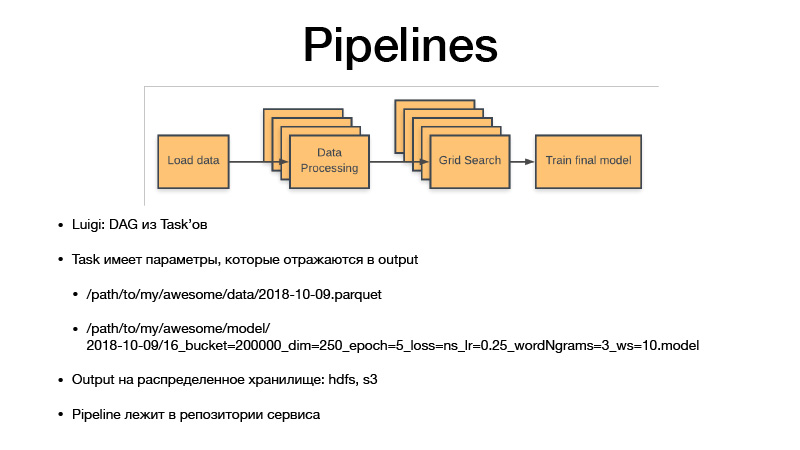
Todos los parámetros identifican la lógica empresarial. Al hacerlo, identifican el artefacto. Siempre es una fecha con cierta granularidad, sensibilidad, o una semana, día, hora, tres horas. Si entrenamos algún modelo, Luigi Taska siempre tiene hiperparámetros de esta tarea, se filtran en el artefacto que producimos, los hiperparámetros se reflejan en el nombre del artefacto. Por lo tanto, esencialmente versionamos todos los conjuntos de datos intermedios y artefactos finales, y nunca se sobrescriben, siempre se vuelcan solo al almacenamiento, y el almacenamiento es privado HDFS y S3, que ve artefactos finales de algunos encurtidos, modelos o algo más. . Y todo el código de canalización se encuentra en el proyecto de servicio en el repositorio con el que se relaciona.

Necesita ser reparado de alguna manera. La pila de HashiCorp viene al rescate, usamos Terraform para declarar la infraestructura en forma de código, Vault para administrar secretos, hay todas las contraseñas, apariencias en la base de datos. Consul es un servicio de descubrimiento distribuido por almacenamiento de valor clave que puede usar para configurar. Y también Consul realiza controles de estado de sus nodos y sus servicios, verificando su disponibilidad.
Y - nómada. Es un sistema de orquestación, que elimina sus servicios y algún tipo de trabajo por lotes.
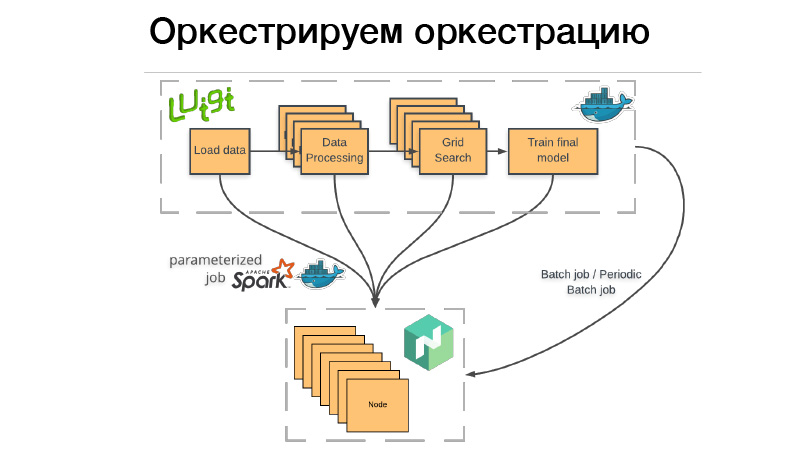
¿Cómo usamos esto? Hay una tubería de Luigi, la empacaremos en el contenedor Docker, colocaremos el bate o el trabajo por lotes periódico en Nomad. Trabajo por lotes: esto es algo completado, terminado, y si todo tiene éxito, todo está bien, podemos comenzarlo manualmente nuevamente. Pero si algo salió mal, Nomad lo reintenta hasta que agota el intento, o no termina con éxito.
Trabajo por lotes periódico: esto es exactamente lo mismo, solo funciona en un horario.
Hay un problema Cuando implementamos un contenedor en cualquier sistema de orquestación, debemos indicar cuánta memoria necesita este contenedor, CPU o memoria. Si tenemos una tubería que se ejecuta durante tres horas, dos horas de esto consumen 10 GB de RAM, 1 hora - 70 GB. Si superamos el límite que le dimos, el demonio Docker viene y mata a Dockers y (nrzb.) [02:26:13] No queremos recuperar la memoria constantemente, por lo que debemos especificar los 70 GB, la carga máxima de memoria. Pero aquí está el problema, los 70 GB por tres horas serán asignados e inaccesibles para cualquier otro trabajo.
Por lo tanto, fuimos por el otro lado. Nuestra línea completa de Luigi no inicia ningún tipo de lógica de negocios, solo lanza un conjunto de dados en Nomad, el llamado trabajo parametrizado. De hecho, este es un análogo de las funciones del Servidor (NRZB.) [02:26:39], AVS Lambda, quién sabe. Cuando hacemos una biblioteca, desplegamos a través de CI todo nuestro código en forma de trabajos parametrizados, es decir, un contenedor con algunos parámetros. Supongamos, Lite JBM Classifier, que tiene un parámetro para la ruta a los datos de entrada para el entrenamiento, hiperparámetros de los modelos y la ruta a los artefactos de salida. Todo esto está registrado en Nomad, y luego desde la tubería de Luigi podemos obtener todos estos trabajos de Nomad a través de la API, mientras que Luigi se asegura de no ejecutar la misma tarea muchas veces.
Supongamos que tenemos el mismo procesamiento de texto. Hay 10 modelos condicionales, y no queremos reiniciar el procesamiento de texto cada vez. Comenzará solo una vez, y al mismo tiempo habrá un resultado final cada vez que se reutilice. Y al mismo tiempo, todo esto funciona de manera distribuida, podemos ejecutar una búsqueda de cuadrícula gigante en un grupo grande, solo tenemos tiempo para volcar el hierro.
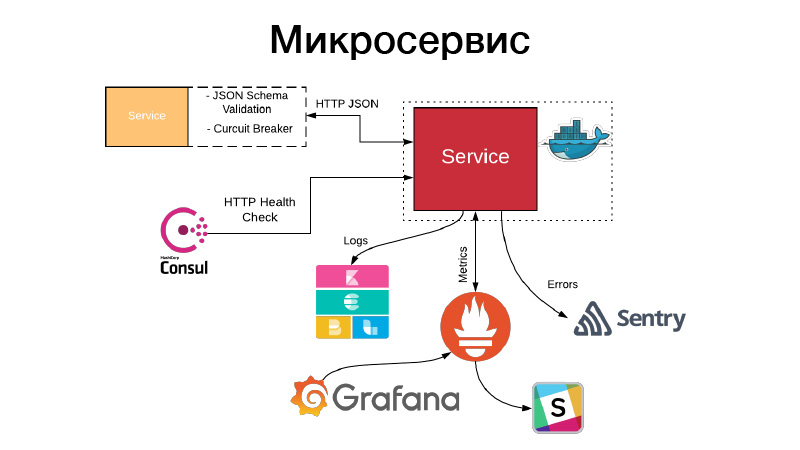
Tenemos un artefacto, necesitamos organizarlo de alguna manera en forma de servicio. Los servicios exponen una API HTTP o se comunican a través de colas. En este ejemplo, esta es la API HTTP, el ejemplo más simple. Al mismo tiempo, la comunicación con el servicio, o nuestro servicio se comunica con otros servicios a través de la API HTTP JSON, valida el esquema JSON. El servicio en sí mismo siempre describe un objeto JSON en la documentación de su API y el esquema de este objeto. Pero no siempre se necesitan todos los campos del objeto JSON, por lo tanto, los contratos impulsados por el consumidor se validan, este esquema se valida, la comunicación se realiza a través del disyuntor de patrón para evitar que nuestro sistema distribuido falle debido a fallas en cascada.
Al mismo tiempo, el servicio debe establecer una comprobación de estado HTTP para que el Cónsul pueda venir y verificar la disponibilidad de este servicio. Al mismo tiempo, Nomad puede hacerlo para que haya un servicio para tres cheques de saludo seguidos, puede reiniciar el servicio para ayudarlo. El servicio escribe todos sus registros en formato JSON. Usamos el controlador de registro JSON y la pila Elastics, en cada punto FileBit simplemente toma todos los registros JSON, los arroja a la caché del registro, desde allí llegan a Elastic, podemos analizar KBan. Al mismo tiempo, no utilizamos registros para la recopilación de métricas y la creación de paneles, es ineficiente, utilizamos el sistema de entrada Prometheus para esto, tenemos un proceso para crear plantillas para cada servicio de panel y podemos analizar las métricas técnicas que produce el servicio.
Además, si algo salió mal, entran alertas, pero en la mayoría de los casos esto no es suficiente. Sentry viene en nuestra ayuda, esto es algo para el análisis de incidentes. De hecho, capturamos todos los registros de nivel de error mediante el controlador Sentry y los enviamos a Sentry. Y luego hay un rastreo detallado, hay toda la información sobre en qué entorno se encontraba el servicio, qué versión, qué funciones fueron llamadas por qué argumentos y qué variables en este ámbito estaban con qué valores. Todas las configuraciones, todo esto es visible, y ayuda mucho a comprender rápidamente lo que sucedió y corregir el error.
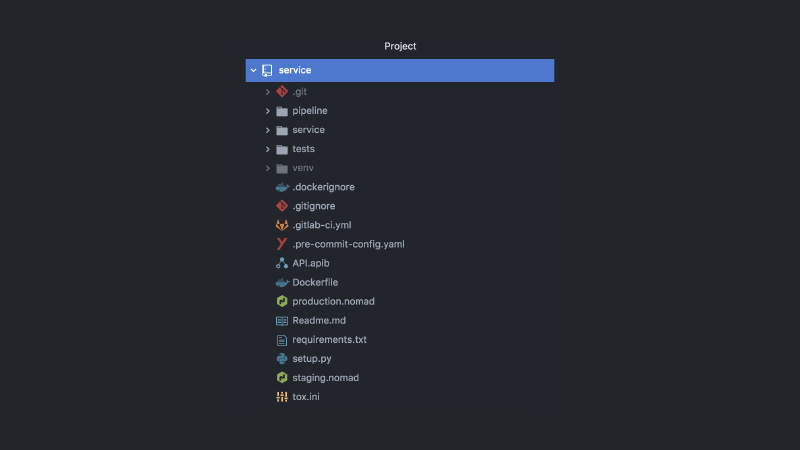
Como resultado, el servicio se parece a esto. Proyecto separado de GitLab, código de canalización, código de prueba, código de servicio en sí, un montón de configuraciones diferentes, Nomad, configuraciones CI, documentación de API, enlaces de compromiso y más.
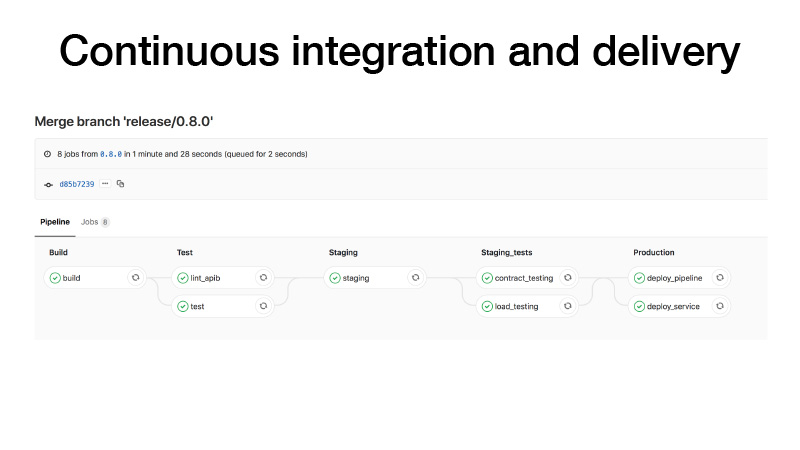
CI, cuando hacemos un lanzamiento, lo hacemos de esta manera: construimos un contenedor, ejecutamos pruebas, lanzamos un clúster en un escenario, ejecutamos un contrato de prueba para nuestro servicio allí, realizamos pruebas de estrés para asegurarnos de que nuestra predicción no sea demasiado lenta y mantener la carga que creemos . Si todo está bien, implementaremos este servicio en producción. Y hay dos maneras: podemos implementar la tubería, si el trabajo por lotes periódico, funciona en algún lugar en segundo plano y produce artefactos, o con los bolígrafos activamos alguna tubería, entrena algún modelo, luego entendemos que todo está bien e implementar el servicio.

¿Qué más pasa en este caso? Dije que en el desarrollo de brunches de funciones existe un paradigma de alternancia de funciones. En el buen sentido, debes cubrir las características con algunos cambios, solo para eliminar una característica en la batalla si algo sale mal. Luego podemos recopilar todas las funciones en los trenes de lanzamiento, e incluso si las funciones están sin terminar, podemos implementarlas. Solo la función de alternar se desactivará. Como todos somos científicos de datos, también queremos hacer pruebas AV. Digamos que reemplazamos LightGBM con CatBoost. Queremos comprobar esto, pero al mismo tiempo, la prueba AV se gestiona con referencia a algún ID de usuario. La alternancia de funciones está vinculada a la ID de usuario y, por lo tanto, pasa la prueba AV. Necesitamos verificar estas métricas aquí.
Todos los servicios se implementan en Nomad. Tenemos dos grupos de producción Nomad: uno para trabajos por lotes y otro para servicios.
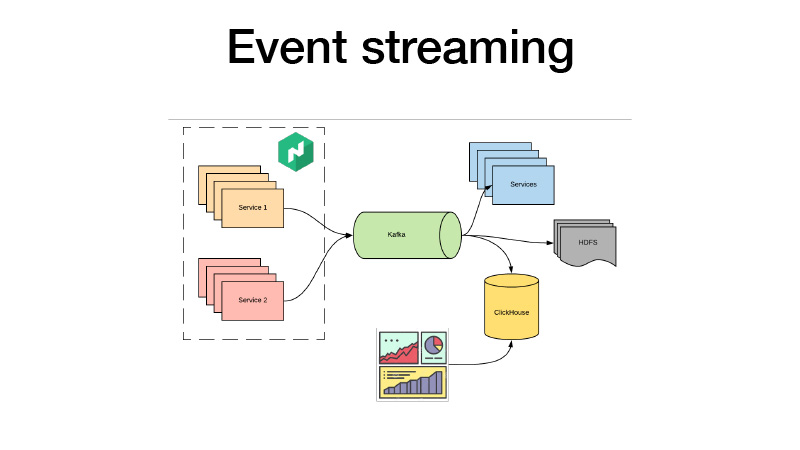
Empujan todos sus eventos de negocios a Kafka. Desde allí podemos recogerlos. En esencia, es una arquitectura de cordero. Podemos suscribirnos a HDFS con algunos servicios, hacer algunos análisis en tiempo real y, al mismo tiempo, todos hacemos clic en ClickHouse y creamos paneles para analizar todos los eventos comerciales de nuestros servicios. Podemos analizar las pruebas AV, lo que sea.
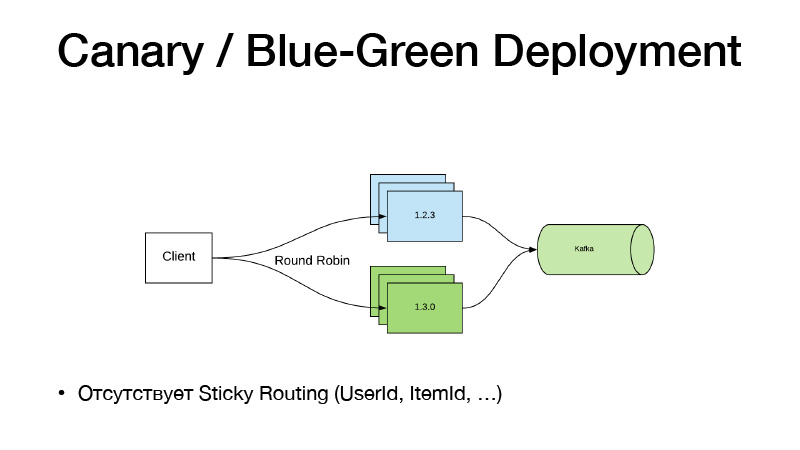
Y si no cambiamos el código, no use las funciones de alternancia. Acabamos de empezar a trabajar con algunos bolígrafos en una tubería, él nos enseñó un nuevo modelo. Tenemos un nuevo camino hacia ello. Simplemente cambiamos la ruta de Nomad al modelo en la configuración, lanzamos el nuevo servicio, y aquí el paradigma de Canary Deployment viene en nuestra ayuda, está disponible en Nomad de fábrica.
Tenemos la versión actual del servicio en tres instancias. Decimos que queremos tres canarios: se implementan tres réplicas más de nuevas versiones sin eliminar las antiguas. Como resultado, el tráfico comienza a dividirse en dos partes. Parte del tráfico recae en nuevas versiones de servicios. Todos los servicios llevan todos sus eventos de negocios a Kafka. Como resultado, podemos analizar métricas en tiempo real.
Si todo está bien, entonces podemos decir que todo está bien. Implemente, Nomad pasará, apaga suavemente todas las versiones antiguas y escala las nuevas.
Este modelo es malo, ya que si necesitamos vincular el enrutamiento de versiones por alguna entidad, Elemento de usuario. Tal esquema no funciona, porque el tráfico se equilibra a través de round-robin. Por lo tanto, seguimos el siguiente camino y dividimos el servicio en dos partes.
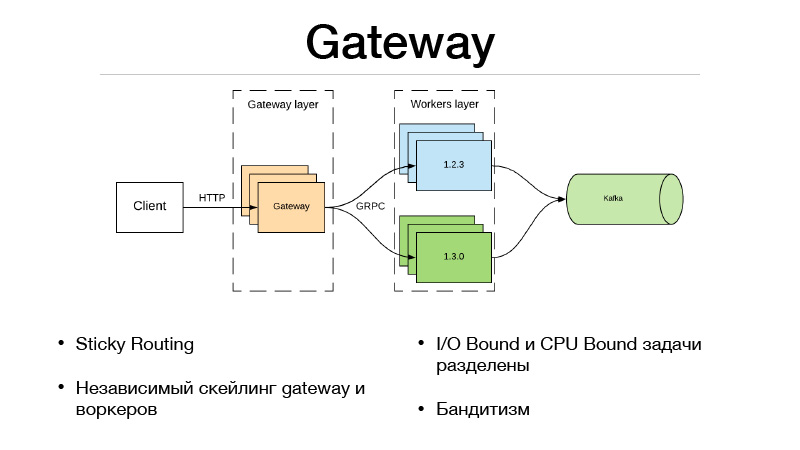
Esta es la capa Gateway y la capa de trabajadores. El cliente se comunica a través de HTTP con la capa Gateway, toda la lógica de selección de versión y equilibrio de tráfico está en el Gateway. Al mismo tiempo, todas las tareas vinculadas de E / S necesarias para completar el predicado también se encuentran en la puerta de enlace. Supongamos que obtenemos un ID de usuario en el predicado en la solicitud, que necesitamos enriquecer con cierta información. Debemos extraer otros microservicios y recoger toda la información, características o bases. Como resultado, todo esto sucede en el Gateway. Se comunica con los trabajadores que solo están en el modelo, y hace una cosa: predecir. Entrada y salida.
Pero como dividimos nuestro servicio en dos partes, la sobrecarga apareció debido a una llamada de red remota. ¿Cómo nivelarlo? El marco JRPC de Google, el RPC de Google, que se ejecuta sobre HTTP2 viene al rescate. Puede usar multiplexación y compresión. JPRC usa protobuff. Este es un protocolo binario fuertemente tipado que tiene una serialización y deserialización rápidas.
Como resultado, también tenemos la capacidad de escalar independientemente Gateway y el trabajador. Digamos que no podemos mantener una cierta cantidad de conexiones HTTP abiertas. De acuerdo, escalando la puerta de enlace. Nuestra predicción es demasiado lenta, no tenemos tiempo para mantener la carga, está bien, escalamos a los trabajadores. Este enfoque encaja muy bien con bandidos con múltiples brazos. En Gateway, dado que se implementa toda la lógica del equilibrio de tráfico, puede ir a microservicios externos y tomar todas las estadísticas de cada versión, así como tomar decisiones sobre cómo equilibrar el tráfico. Digamos usando Thompson Sampling.
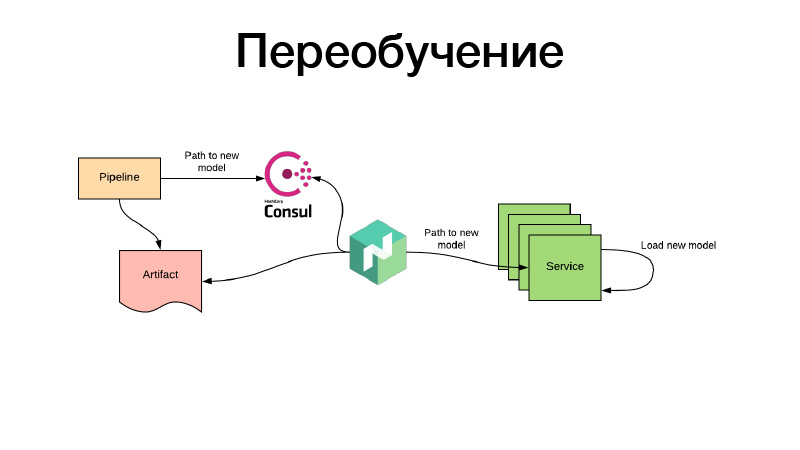
Todo bien, los modelos fueron entrenados de alguna manera, los registramos en la configuración de Nomad. Pero, ¿qué pasa si hay un modelo de recomendaciones que ya tiene tiempo de volverse obsoleto durante el entrenamiento, y necesitamos capacitarlas constantemente? Todo se hace de la misma manera: a través de trabajos por lotes periódicos se produce algún artefacto, por ejemplo, cada tres horas. Al mismo tiempo, al final de su trabajo, la tubería establece el camino para el nuevo modelo en Consul. Este es el almacenamiento de valor clave, que se utiliza para la configuración. Nomad puede configurar configuraciones. Que haya una variable de entorno basada en los valores del almacenamiento de valores clave Consul. Supervisa los cambios y, tan pronto como aparece un nuevo camino, decide que se pueden tomar dos caminos. Descarga el artefacto en sí a través de un nuevo enlace, coloca el contenedor de servicio en Docker usando el volumen y lo vuelve a cargar, y lo hace todo para que no haya tiempo de inactividad, es decir, lentamente, de forma individual. O presenta una nueva configuración y le informa el servicio. O el servicio mismo lo detecta, y dentro de sí mismo puede, independientemente, actualizar en vivo su modelka. Eso es todo, gracias.