
Encontré material interesante sobre inteligencia artificial en juegos. Con una explicación de las cosas básicas sobre IA usando ejemplos simples, y dentro hay muchas herramientas y métodos útiles para su conveniente desarrollo y diseño. Cómo, dónde y cuándo usarlos, también está ahí.
La mayoría de los ejemplos están escritos en pseudocódigo, por lo que no se requieren conocimientos profundos de programación. Debajo del corte 35 hojas de texto con imágenes y gifs, así que prepárate.
UPD Lo
siento , pero
PatientZero ya hizo la traducción de este artículo sobre Habré. Puede leer su versión
aquí , pero por alguna razón el artículo me pasó (utilicé la búsqueda, pero algo salió mal). Y como estoy escribiendo un blog de desarrollo de juegos, decidí dejar mi opción de traducción para los suscriptores (algunos momentos son diferentes para mí, algunos se pierden intencionalmente por el consejo de los desarrolladores).
¿Qué es la IA?
Game AI se centra en las acciones que debe realizar un objeto en función de las condiciones en las que se encuentra. Esto generalmente se llama la gestión de "agentes inteligentes", donde el agente es un personaje del juego, un vehículo, un bot y, a veces, algo más abstracto: un grupo completo de entidades o incluso una civilización. En cada caso, es algo que debe ver su entorno, tomar decisiones sobre la base y actuar de acuerdo con ellas. Esto se llama el ciclo Sentido / Pensar / Actuar:
- Sentido: el agente encuentra o recibe información sobre cosas en su entorno que pueden afectar su comportamiento (amenazas cercanas, elementos para recolectar, lugares interesantes para investigar).
- Piensa: el agente decide cómo reaccionar (considera si es seguro recolectar objetos o si debe luchar / esconderse primero).
- Actuar: el agente realiza acciones para implementar la decisión anterior (comienza a moverse hacia el oponente u objeto).
- ... ahora la situación ha cambiado debido a las acciones de los personajes, por lo que el ciclo se repite con nuevos datos.
La IA tiende a centrarse en la parte sensorial del bucle. Por ejemplo, los automóviles autónomos toman fotos de la carretera, las combinan con datos de radar y lidar e interpretan. Por lo general, esto se hace mediante el aprendizaje automático, que procesa los datos entrantes y les da significado, extrayendo información semántica como "hay otro automóvil 20 yardas por delante de usted". Estos son los llamados problemas de clasificación.
Los juegos no necesitan un sistema complejo para extraer información, ya que la mayoría de los datos ya son una parte integral de la misma. No es necesario ejecutar algoritmos de reconocimiento de imágenes para determinar si hay un enemigo por delante: el juego ya conoce y transfiere información directamente en el proceso de toma de decisiones. Por lo tanto, parte del ciclo de detección es a menudo mucho más simple que pensar y actuar.
Limitaciones de la IA del juego
La IA tiene una serie de restricciones que deben observarse:
- La IA no necesita ser entrenada de antemano, como si fuera un algoritmo de aprendizaje automático. No tiene sentido escribir una red neuronal durante el desarrollo para observar decenas de miles de jugadores y aprender la mejor manera de jugar contra ellos. Por qué Porque el juego no se lanzó, pero no hay jugadores.
- El juego debe entretener y desafiar, por lo tanto, los agentes no deben encontrar el mejor enfoque contra las personas.
- Los agentes deben parecer realistas para que los jugadores sientan que están jugando contra personas reales. AlphaGo destacó a los humanos, pero los pasos dados estaban lejos de la comprensión tradicional del juego. Si el juego imita a un oponente humano, no debería existir ese sentimiento. El algoritmo necesita ser cambiado para que tome decisiones plausibles, no ideales.
- La IA debería funcionar en tiempo real. Esto significa que el algoritmo no puede monopolizar el uso del procesador durante mucho tiempo para la toma de decisiones. Incluso 10 milisegundos para esto es demasiado largo, porque la mayoría de los juegos solo tienen de 16 a 33 milisegundos para completar todo el procesamiento y pasar al siguiente cuadro del gráfico.
- Idealmente, al menos parte del sistema está basado en datos para que los no codificadores puedan hacer cambios y los ajustes sean más rápidos.
Considere los enfoques de IA que abarcan todo el ciclo Sentido / Pensar / Actuar.
Toma de decisiones básicas
Comencemos con el juego más simple: Pong. Objetivo: mover la plataforma (paleta) para que la pelota rebote en lugar de volar. Es como el tenis, en el que pierdes si no golpeas la pelota. Aquí, la IA tiene una tarea relativamente fácil: decidir en qué dirección mover la plataforma.

Declaraciones condicionales
Para AI, Pong tiene la solución más obvia: siempre trate de colocar la plataforma debajo de la pelota.
Un algoritmo simple para esto, escrito en pseudocódigo:
cada cuadro / actualización mientras se ejecuta el juego:
si la pelota está a la izquierda de la pala:
mover la paleta hacia la izquierda
si la pelota está a la derecha de la pala:
mover la paleta hacia la derechaSi la plataforma se mueve a la velocidad de la pelota, entonces este es el algoritmo perfecto para la IA en Pong. No es necesario complicar nada si no hay tantos datos y posibles acciones para el agente.
Este enfoque es tan simple que casi no se nota todo el ciclo Sentido / Pensar / Actuar. Pero él es:
- La parte de sentido está en dos declaraciones if. El juego sabe dónde está la pelota y dónde está la plataforma, por lo que la IA recurre a ella para obtener esta información.
- La parte Think también viene en dos declaraciones if. Incorporan dos soluciones, que en este caso son mutuamente excluyentes. Como resultado, se selecciona una de las tres acciones: mover la plataforma hacia la izquierda, mover hacia la derecha o no hacer nada si ya está posicionada correctamente.
- La parte Act está en las declaraciones Move Paddle Left y Move Paddle Right. Dependiendo del diseño del juego, pueden mover la plataforma al instante o a cierta velocidad.
Tales enfoques se denominan reactivos: hay un conjunto simple de reglas (en este caso, si las declaraciones en el código) responden al estado actual del mundo y actúan.
Árbol de decisiones
El ejemplo de Pong es en realidad igual al concepto formal de IA llamado árbol de decisión. El algoritmo lo pasa para llegar a una "hoja", una decisión sobre qué acción tomar.
Hagamos un diagrama de bloques del árbol de decisión para el algoritmo de nuestra plataforma:
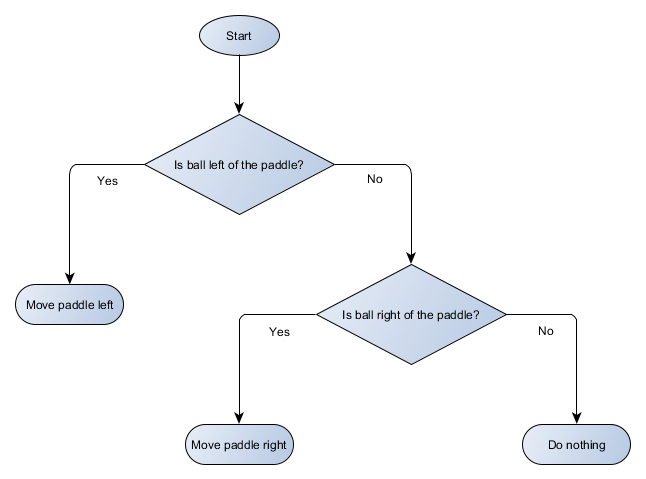
Cada parte del árbol se llama nodo; la IA usa la teoría de grafos para describir tales estructuras. Hay dos tipos de nodos:
- Nodos de decisión: elegir entre dos alternativas en función de verificar una determinada condición en la que cada alternativa se presenta como un nodo separado.
- Nodos finales: una acción a realizar que representa la decisión final.
El algoritmo comienza con el primer nodo (la "raíz" del árbol). Decide a qué nodo hijo ir, o realiza una acción almacenada en el nodo y completa.
¿Cuál es la ventaja si el árbol de decisión hace el mismo trabajo que las declaraciones if en la sección anterior? Aquí hay un sistema común donde cada solución tiene solo una condición y dos resultados posibles. Esto permite al desarrollador crear IA a partir de los datos que representan las decisiones en el árbol, evitando su codificación. Imagina en forma de tabla:
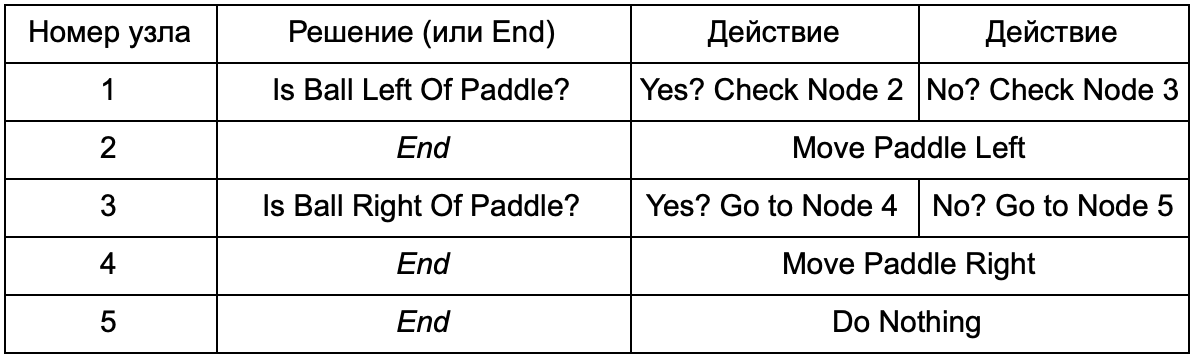
En el lado del código, obtienes un sistema para leer cadenas. Cree un nodo para cada uno de ellos, conecte la lógica de decisión basada en la segunda columna y los nodos secundarios basados en la tercera y cuarta columna. Todavía necesitas programar las condiciones y acciones, pero ahora la estructura del juego será más complicada. En él, agrega decisiones y acciones adicionales, y luego configura toda la IA simplemente editando un archivo de texto con una definición de árbol. A continuación, transfiera el archivo al diseñador del juego, que puede cambiar el comportamiento sin volver a compilar el juego y cambiar el código.
Los árboles de decisión son muy útiles cuando se crean automáticamente en función de un gran conjunto de ejemplos (por ejemplo, utilizando el algoritmo ID3). Esto los convierte en una herramienta eficaz y de alto rendimiento para clasificar situaciones basadas en los datos recibidos. Sin embargo, vamos más allá de un sistema simple para que los agentes seleccionen acciones.
Escenarios
Desmontamos un sistema de árbol de decisión que utilizaba condiciones y acciones pre-creadas. El diseñador de IA puede organizar el árbol de la manera que quiera, pero aún tiene que confiar en el codificador que lo programó todo. ¿Qué pasaría si pudiéramos darle al diseñador herramientas para crear nuestras propias condiciones o acciones?
Para evitar que el programador escriba código para las condiciones Is Ball Left Of Paddle y Is Ball Right Of Paddle, puede crear un sistema en el que el diseñador registre las condiciones para verificar estos valores. Entonces los datos del árbol de decisión se verán así:
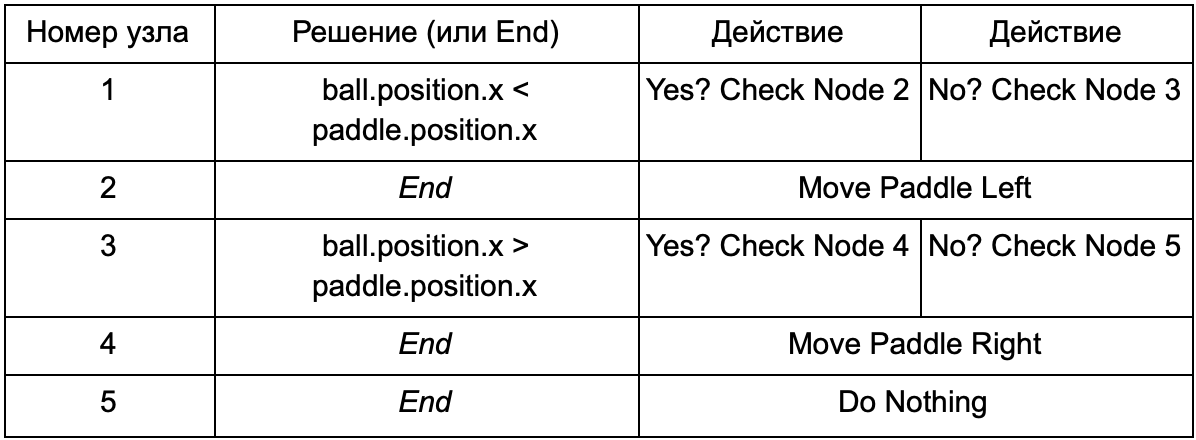
En esencia, esto es lo mismo que en la primera tabla, pero las soluciones dentro de sí mismas tienen su propio código, un poco similar a la parte condicional de la instrucción if. En el lado del código, esto se leería en la segunda columna para los nodos de decisión, pero en lugar de buscar una condición específica para cumplir (Is Ball Left Of Paddle), evalúa la expresión condicional y devuelve verdadero o falso, respectivamente. Esto se hace usando el lenguaje de script Lua o Angelscript. Al usarlos, el desarrollador puede tomar objetos en su juego (pelota y paleta) y crear variables que estarán disponibles en el guión (bola.posición). Además, el lenguaje de secuencias de comandos es más simple que C ++. No requiere una etapa de compilación completa, por lo tanto, es ideal para el ajuste rápido de la lógica del juego y permite a los "no codificadores" crear las funciones necesarias por sí mismos.
En el ejemplo anterior, el lenguaje de secuencias de comandos se usa solo para evaluar una expresión condicional, pero también se puede usar para acciones. Por ejemplo, los datos de Move Paddle Right pueden convertirse en una declaración de script (ball.position.x + = 10). Para que la acción también se defina en el script, sin la necesidad de programar Move Paddle Right.
Puede ir aún más lejos y escribir un árbol de decisión completo en un lenguaje de script. Este será un código en forma de declaraciones condicionales codificadas (codificadas), pero se ubicarán en archivos de script externos, es decir, se pueden cambiar sin recompilar todo el programa. A menudo, puedes cambiar el archivo de script directamente durante el juego para probar rápidamente diferentes reacciones de IA.
Respuesta al evento
Los ejemplos anteriores son perfectos para Pong. Continuamente ejecutan el ciclo Sense / Think / Act y actúan sobre la base del último estado del mundo. Pero en los juegos más complejos, debes responder a eventos individuales y no evaluar todo a la vez. Pong ya es un ejemplo infructuoso. Elige otro.
Imagine un tirador donde los enemigos están inmóviles hasta que encuentran al jugador, después de lo cual actúan dependiendo de su "especialización": alguien correrá para "aplastarse", alguien atacará desde lejos. Este sigue siendo el sistema de respuesta básico: "si se nota al jugador, entonces haga algo", pero se puede dividir lógicamente en el evento Player Seen (se nota al jugador) y la reacción (seleccione la respuesta y ejecútela).
Esto nos lleva de vuelta al ciclo Sentido / Pensar / Actuar. Podemos codificar la parte de detección, que cada cuadro verificará para ver si la IA del jugador es visible. Si no, no pasa nada, pero si se ve, entonces se genera el evento Player Seen. El código tendrá una sección separada que dice: “cuando ocurra el evento Player Seen, hazlo”, ¿dónde está la respuesta que necesitas para referirte a las partes Think and Act? Por lo tanto, configurará reacciones al evento Player Seen: ChargeAndAttack para el personaje "creciente" y HideAndSnipe para el francotirador. Estas relaciones se pueden crear en el archivo de datos para una edición rápida sin tener que volver a compilar. Y aquí también puedes usar el lenguaje de secuencias de comandos.
Tomando decisiones difíciles
Aunque los sistemas de reacción simples son muy efectivos, hay muchas situaciones en las que no son suficientes. A veces es necesario tomar varias decisiones basadas en lo que el agente está haciendo en este momento, pero es difícil imaginar esto como una condición. A veces hay demasiadas condiciones para representarlas efectivamente en un árbol de decisiones o script. A veces es necesario evaluar previamente cómo cambiará la situación antes de decidir el siguiente paso. Resolver estos problemas requiere enfoques más sofisticados.
Máquina de estados finitos
La máquina de estados finitos o FSM (máquina de estados) es una forma de decir que nuestro agente se encuentra actualmente en uno de varios estados posibles y que puede moverse de un estado a otro. Hay un cierto número de tales estados, de ahí el nombre. El mejor ejemplo de la vida es un semáforo. En diferentes lugares, diferentes secuencias de luces, pero el principio es el mismo: cada estado representa algo (pararse, ir, etc.). Un semáforo está solo en un estado en un momento dado y se mueve de uno a otro según reglas simples.
Con los NPC en los juegos, una historia similar. Por ejemplo, tenga cuidado con las siguientes condiciones:
- Patrullando
- Atacando
- Huyendo
Y tales condiciones para cambiar su condición:
- Si el guardia ve al enemigo, ataca.
- Si el guardia ataca, pero ya no ve al enemigo, vuelve a patrullar.
- Si el guardia ataca, pero está gravemente herido, huye.
También puede escribir sentencias if con una variable de estado de guardia y varias comprobaciones: ¿hay un enemigo cerca, cuál es el nivel de salud del NPC, etc. Agreguemos algunos estados más:
- Inacción (inactivo): entre patrullas.
- Buscar (Buscando) - cuando el enemigo notado desapareció.
- Pide ayuda (Encontrar ayuda): cuando se ve al enemigo, pero es demasiado fuerte para luchar solo con él.
La elección para cada uno de ellos es limitada: por ejemplo, un guardia no irá a buscar un enemigo oculto si tiene mala salud.
Al final, la enorme lista de "si <x e y, pero no z>, entonces <p>" puede volverse demasiado engorrosa, por lo que deberíamos formalizar un método que nos permita tener en cuenta los estados y las transiciones entre estados. Para hacer esto, tenemos en cuenta todos los estados, y en cada estado, enumeramos todas las transiciones a otros estados, junto con las condiciones necesarias para ellos.
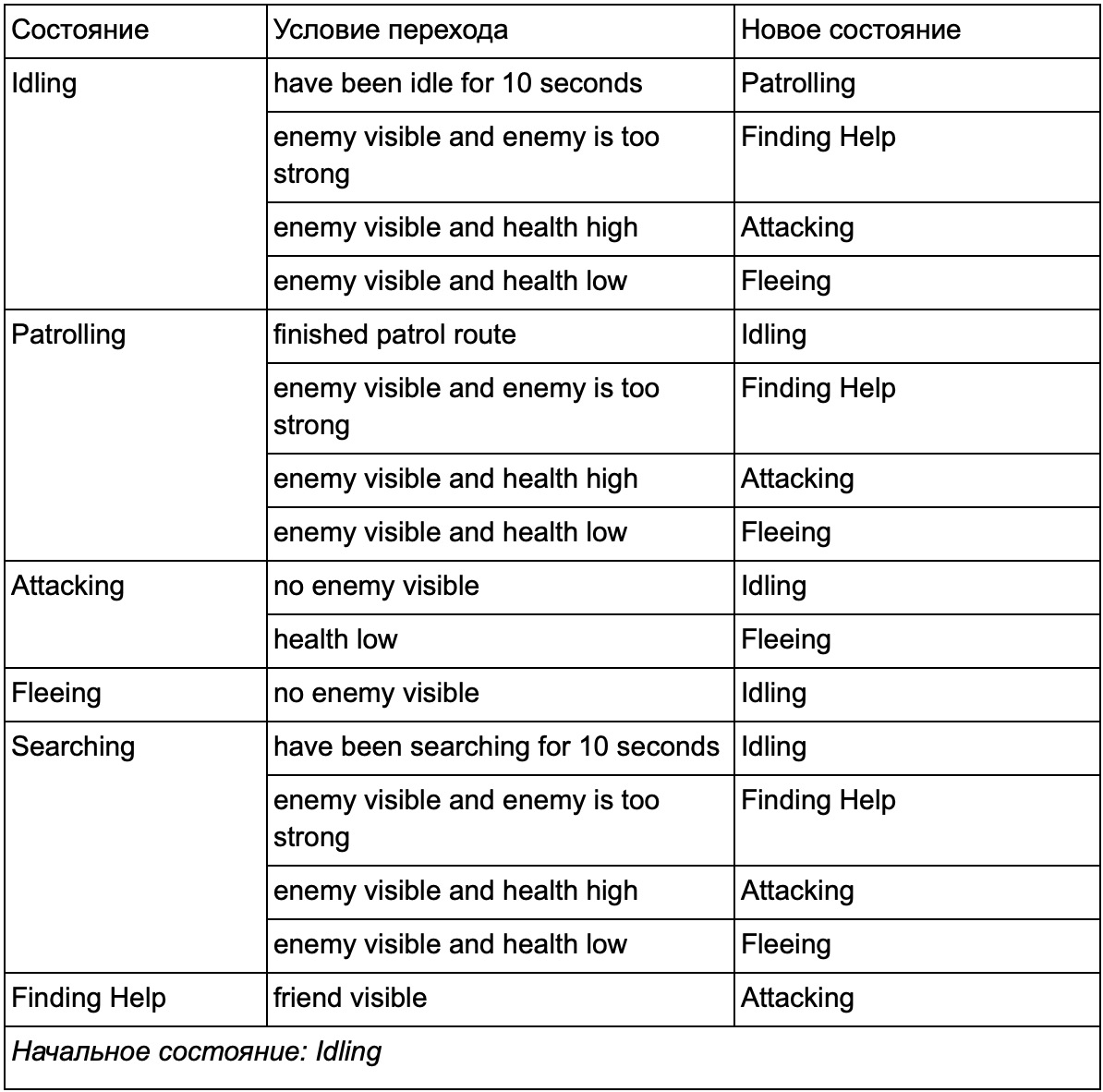
Esta tabla de transición de estado es una forma integral de representar FSM. Dibujemos un diagrama y obtengamos una visión general completa de cómo cambia el comportamiento de los NPC.
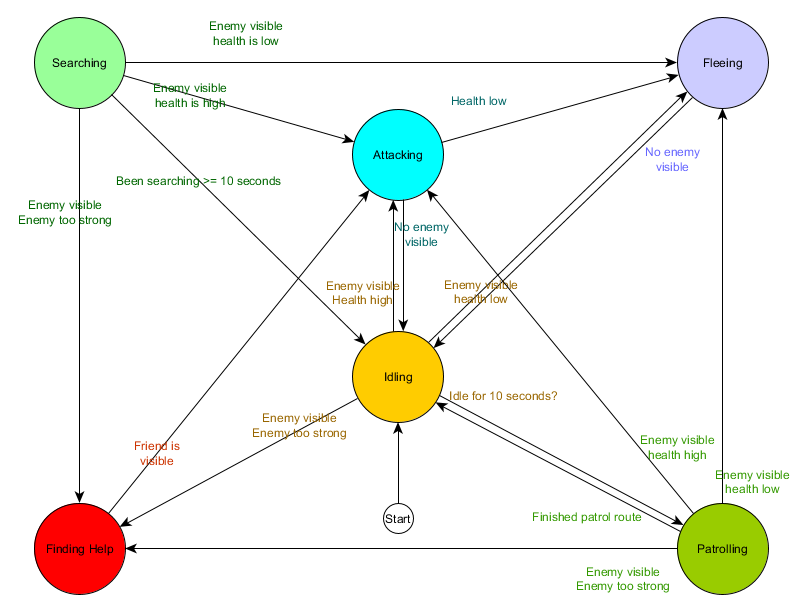
El cuadro refleja la esencia de la toma de decisiones para este agente en función de la situación actual. Además, cada flecha muestra una transición entre estados si la condición al lado es verdadera.
En cada actualización, verificamos el estado actual del agente, miramos la lista de transiciones y, si se cumplen las condiciones para la transición, adquiere un nuevo estado. Por ejemplo, cada cuadro verifica si el temporizador de 10 segundos ha expirado, y si es así, el guardia cambia de Ralentí a Patrullaje. De la misma manera, el estado de ataque verifica la salud del agente; si es bajo, pasa al estado de Huida.
Esto es manejar las transiciones de estado, pero ¿qué pasa con el comportamiento asociado con los estados mismos? Con respecto a la implementación del comportamiento real para un estado en particular, generalmente hay dos tipos de "ganchos" donde asignamos acciones al FSM:
- Acciones que realizamos periódicamente para el estado actual.
- Las acciones que tomamos al pasar de un estado a otro.
Ejemplos para el primer tipo. Estado de patrullaje Cada cuadro moverá al agente a lo largo de la ruta de patrullaje. Estado de ataque cada cuadro intentará iniciar un ataque o entrar en un estado cuando sea posible.
Para el segundo tipo, considere la transición “si el enemigo es visible y el enemigo es demasiado fuerte, entonces vaya al estado Encontrar Ayuda. El agente debe elegir a dónde ir para obtener ayuda y guardar esta información para que el estado de Búsqueda de ayuda sepa a dónde ir. Tan pronto como se encuentra ayuda, el agente vuelve al estado de ataque. En este punto, querrá contarle al aliado sobre la amenaza, por lo que puede ocurrir la acción NotifyFriendOfThreat.
Y nuevamente, podemos ver este sistema a través del prisma del ciclo Sentido / Pensar / Actuar. El sentido se traduce en datos utilizados por la lógica de transición. Pensar: transiciones disponibles en cada estado. Y la Ley se lleva a cabo mediante acciones realizadas periódicamente dentro del estado o en transiciones entre estados.
A veces, el sondeo continuo de las condiciones de transición puede ser costoso. Por ejemplo, si cada agente realizará cálculos complejos en cada cuadro para determinar si ve enemigos y comprende si es posible pasar de Patrullar a Atacar, esto requerirá mucho tiempo del procesador.
Los cambios importantes en el estado del mundo pueden considerarse eventos que se procesarán a medida que ocurran. En lugar de que FSM verifique la condición de transición "¿puede mi agente ver al jugador?" En cada cuadro, puede configurar un sistema separado para realizar verificaciones con menos frecuencia (por ejemplo, 5 veces por segundo). Y el resultado es dar al jugador visto cuando pasa el cheque.
Esto se pasa al FSM, que ahora tiene que entrar en la condición recibida del evento Player Seen y reaccionar en consecuencia. El comportamiento resultante es el mismo, excepto por un retraso casi imperceptible antes de responder. Pero el rendimiento mejoró como resultado de la separación de parte de Sense en una parte separada del programa.
Máquina jerárquica de estados finitos
Sin embargo, trabajar con FSM grandes no siempre es conveniente. Si queremos expandir el estado del ataque, reemplazándolo con MeleeAttacking (cuerpo a cuerpo) y RangedAttacking (a distancia) separados, tendremos que cambiar las transiciones de todos los demás estados que conducen al estado de Ataque (actual y futuro).
Seguramente notó que en nuestro ejemplo hay muchas transiciones duplicadas. La mayoría de las transiciones en el estado inactivo son idénticas a las transiciones en el estado de patrullaje. Sería bueno no repetir, especialmente si agregamos más estados similares. Tiene sentido agrupar a Idling and Patrolling bajo la etiqueta común "no combate", donde solo hay un conjunto común de transiciones para combatir estados. Si presentamos esta etiqueta como un estado, entonces Idling and Patrolling se convertirán en subestados. Un ejemplo de uso de una tabla de conversión separada para un nuevo subestado que no es de combate:
Las principales condiciones: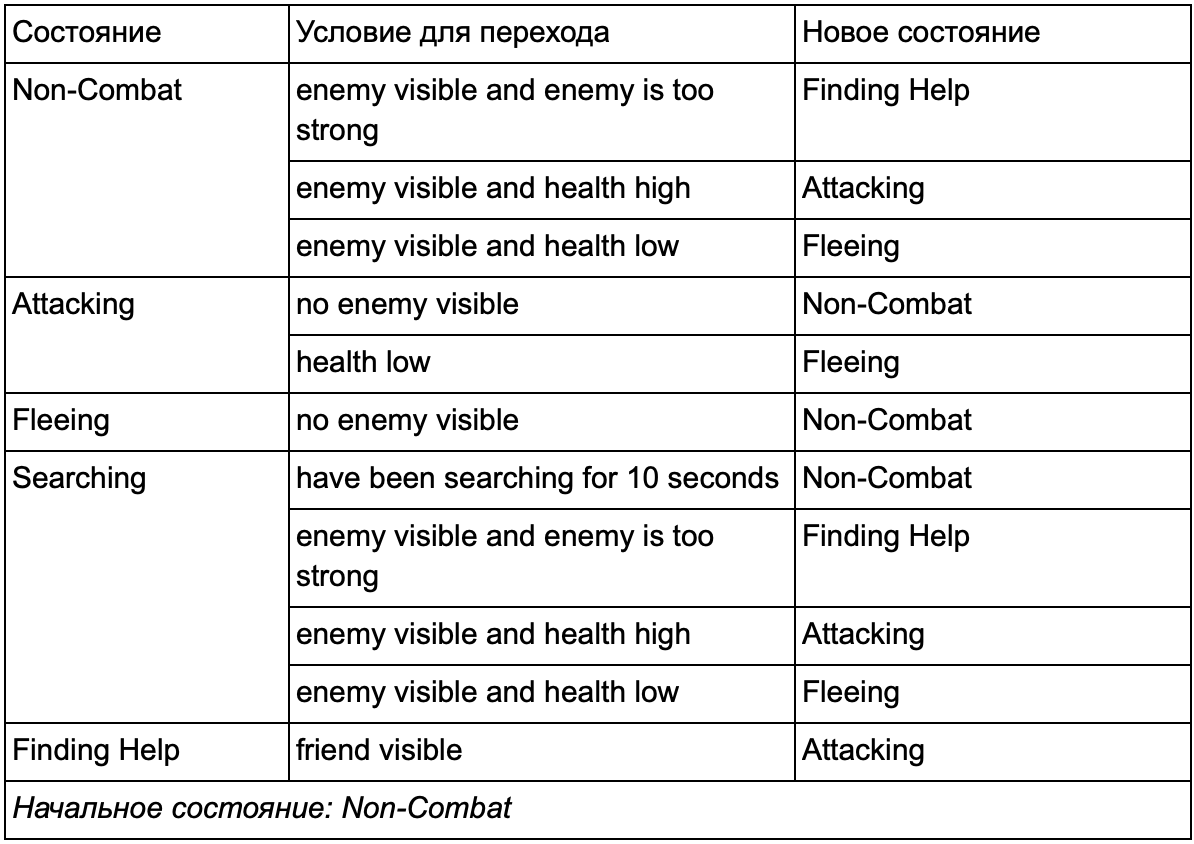 Estado fuera de combate:
Estado fuera de combate:
Y en forma de gráfico:
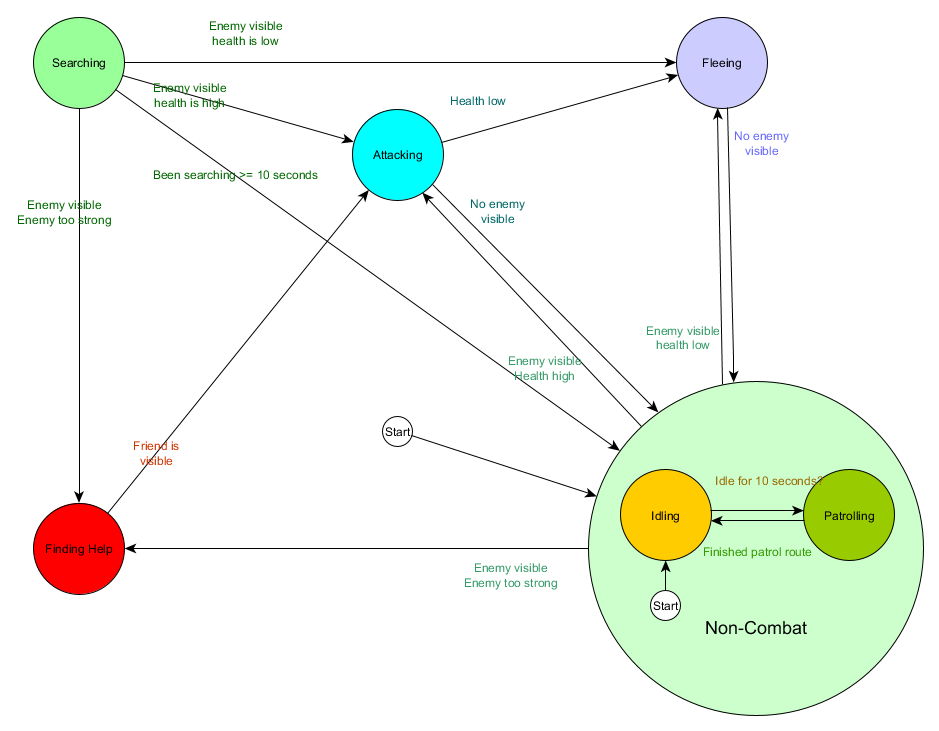
Este es el mismo sistema, pero con un nuevo estado de no combate, que incluye Idling and Patrolling. Con cada estado que contiene FSM con subestados (y estos subestados, a su vez, contienen sus propios FSM, y así sucesivamente, todo lo que necesite), obtenemos una Máquina de estado finito jerárquico o HFSM (máquina de estado jerárquico). Habiendo agrupado un estado que no es de combate, cortamos un montón de transiciones redundantes. Podemos hacer lo mismo para cualquier estado nuevo con transiciones comunes. Por ejemplo, si en el futuro extendemos el estado de ataque a los estados de ataque cuerpo a cuerpo y ataque de misiles, serán subestaciones que se cruzan entre sí en función de la distancia al enemigo y la presencia de municiones. Como resultado, los modelos de comportamiento complejos y los submodelos de comportamiento pueden representarse con un mínimo de transiciones duplicadas.
HFSM . , , . , . . , , . , 25%, , , , — . 25% 10%, .
, « », , . .
, : «» , , , . :
- : Succeeded ( ), Failed ( ) Running ( ).
- . Decorator, . Succeed, .
- , , Running .
. HFSM :
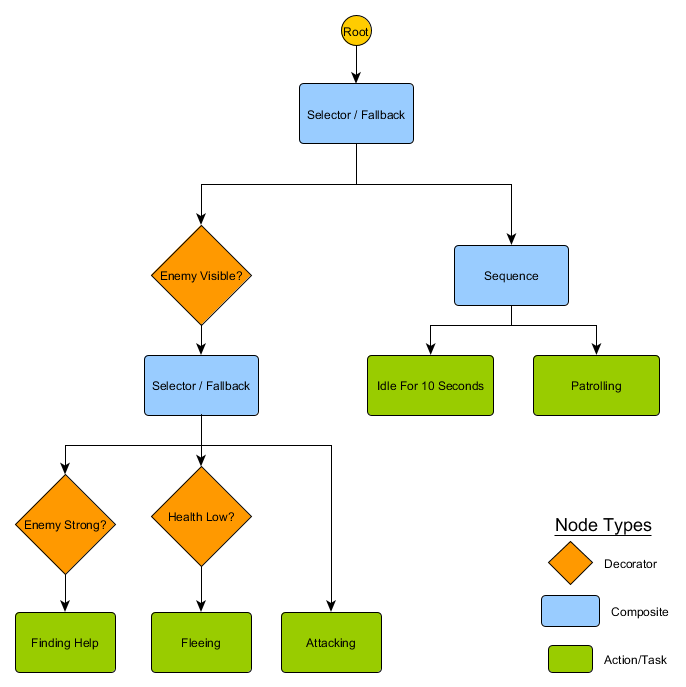
Idling/Patrolling Attacking . , , Fleeing, , — Patrolling, Idling, Attacking .
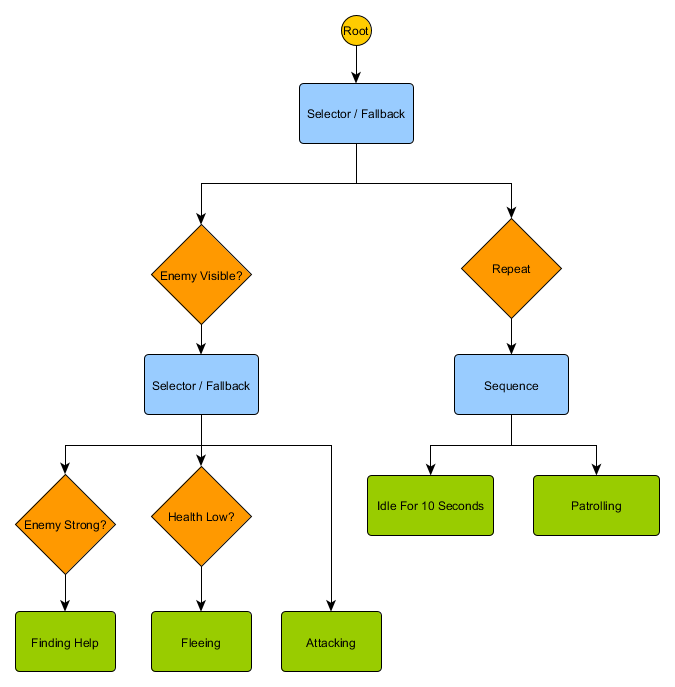
— , . , — , ? , — , Idling 10 , , ?
. , . , .
Utility-based system
. , , . , , .
Utility-based system (, ) . , , , . — , .
, . FSM, , , . , ( , ). , .
— , 0 ( ) 100 ( ). , . :

— . . , , , Fleeing, FindingHelp . FindingHelp . , 50, . .
, . . , Fleeing , , Attacking , . - Fleeing Attacking , , . , , FSM.
. . The Sims, , — «», . , , EatFood , , , EatFood .
, Utility-based system , . . , Utility , , .
, , , . ? , , , , ? .
Gestión
, , , . , , . . Sense/Think/Act, , Think , Act . , , . — , . , , . :
desired_travel = destination_position – agent_position2D-. (-2,-2), - - (30, 20), , — (32, 22). , — 5 , (4.12, 2.83). 8 .
. , , 5 / ( ), . , .
— , , , . . steering behaviours, : Seek (), Flee (), Arrival () . . , , , .
. Seek Arrival — . Obstacle Avoidance ( ) Separation () , . Alignment () Cohesion () . steering behaviours . , Arrival, Separation Obstacle Avoidance, . .
, — , - Arrival Obstacle Avoidance. , , . : , .
, , - .
Steering behaviours ( ), — . pathfinding ( ), .
— . - , , . . , ( , ). , Breadth-First Search BFS ( ). ( breadth, «»). , , — , , .
, . (, pathfinding) — , , .
, , steering behaviours, — 1 2, 2 3 . — , — . - .
BFS — «» , «». A* (A star). , - ( , ), , , . , — «» ( ) , ( ).
, , , . , BFS, — .
Pero la mayoría de los juegos no se presentan en la grilla, y a menudo no se puede hacer sin comprometer el realismo. Se necesitan compromisos. ¿De qué tamaño deben ser los cuadrados? Demasiado grande, y no podrán imaginar correctamente corredores o giros pequeños, demasiado pequeños, habrá demasiados cuadrados para buscar, lo que al final llevará mucho tiempo.
Lo primero que hay que entender es que la cuadrícula nos da un gráfico de nodos conectados. Los algoritmos A * y BFS realmente funcionan en gráficos y no se preocupan por nuestra cuadrícula en absoluto. Podríamos colocar los nodos en cualquier parte del mundo del juego: si hay una conexión entre dos nodos conectados, así como entre los puntos de inicio y finalización y al menos uno de los nodos, el algoritmo funcionará igual de bien que antes. Esto a menudo se llama el sistema de puntos de referencia, ya que cada nodo representa una posición significativa en el mundo, que puede ser parte de cualquier número de caminos hipotéticos.
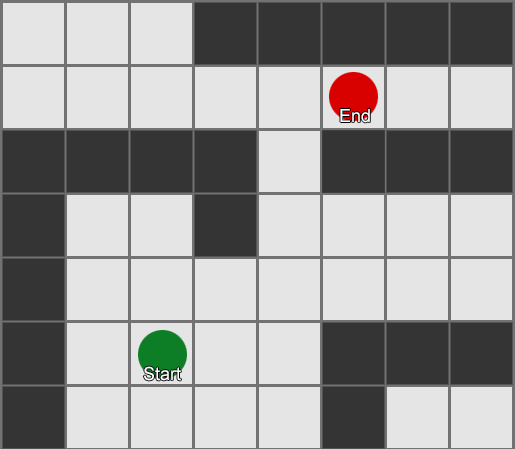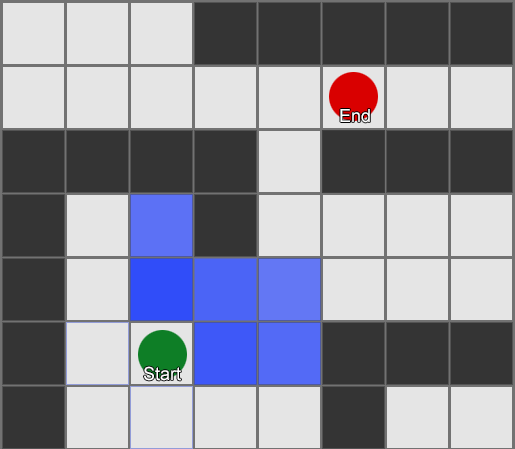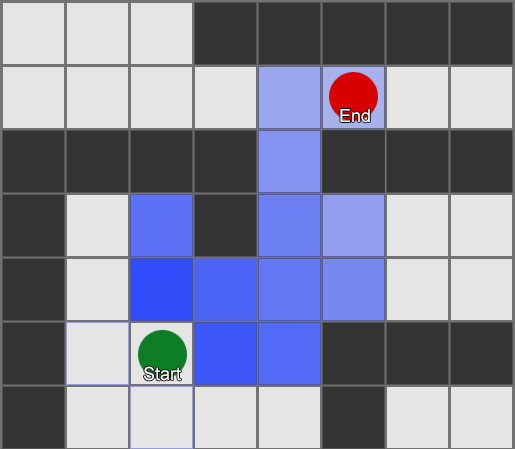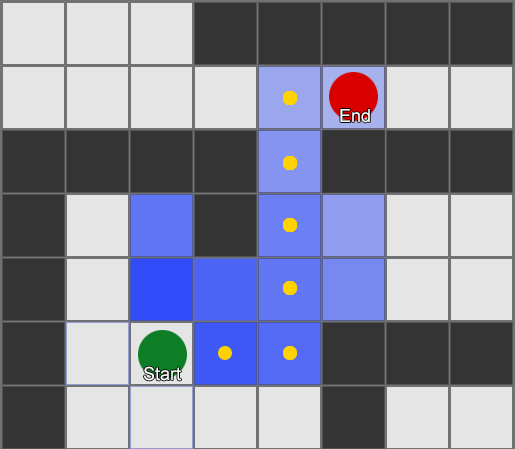
 Ejemplo 1: un nudo en cada cuadrado. La búsqueda comienza desde el nodo donde se encuentra el agente, y termina en el nodo del cuadrado deseado.
Ejemplo 1: un nudo en cada cuadrado. La búsqueda comienza desde el nodo donde se encuentra el agente, y termina en el nodo del cuadrado deseado.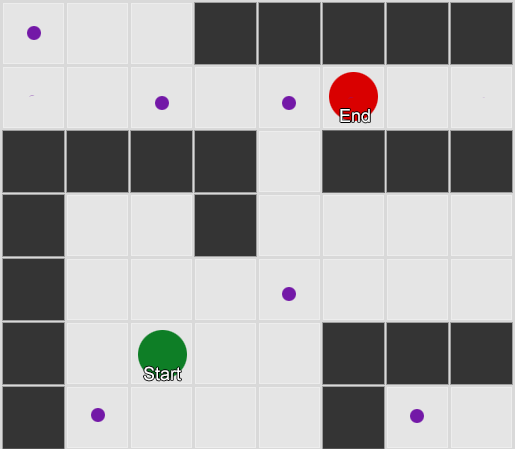 Ejemplo 2: un conjunto más pequeño de nodos (puntos de referencia). La búsqueda comienza al cuadrado con el agente, pasa por el número requerido de nodos y luego continúa hasta el destino.
Ejemplo 2: un conjunto más pequeño de nodos (puntos de referencia). La búsqueda comienza al cuadrado con el agente, pasa por el número requerido de nodos y luego continúa hasta el destino.Este es un sistema completamente flexible y potente. Pero necesita cierta precaución al decidir dónde y cómo colocar el punto de referencia; de lo contrario, los agentes simplemente no podrán ver el punto más cercano y no podrán iniciar el camino. Sería más fácil si pudiéramos establecer automáticamente puntos de referencia basados en la geometría del mundo.
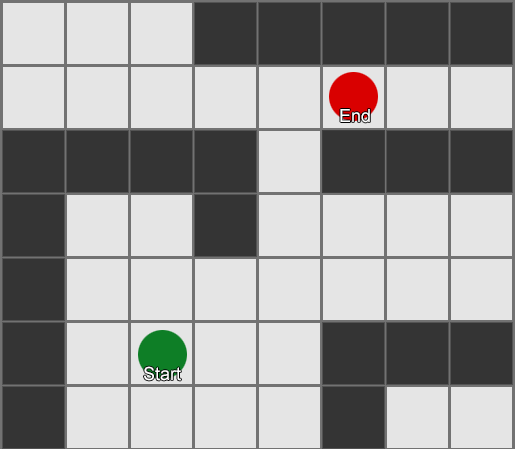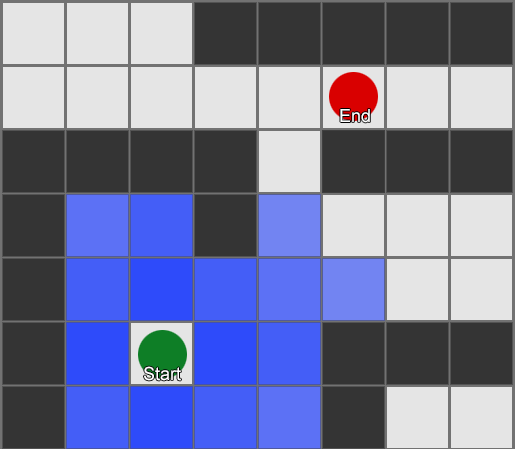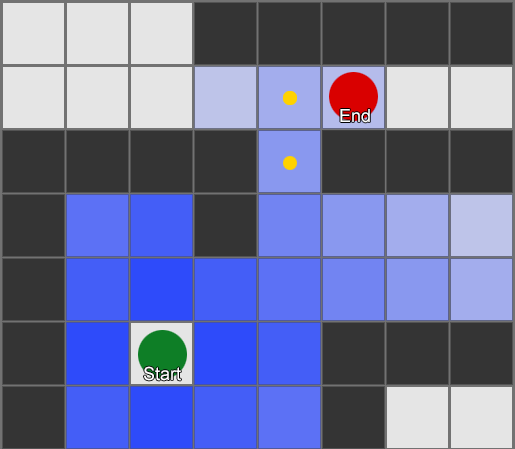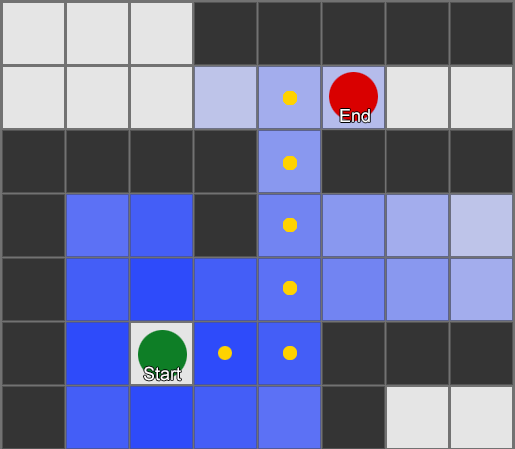
Luego aparece una malla de navegación o malla de navegación. Esta suele ser una malla 2D de triángulos que se superpone a la geometría del mundo, donde sea que el agente pueda caminar. Cada uno de los triángulos en la cuadrícula se convierte en un nodo en el gráfico y tiene hasta tres triángulos adyacentes que se convierten en nodos adyacentes en el gráfico.
Esta imagen es un ejemplo del motor de Unity: analizó la geometría en el mundo y creó navmesh (azul claro en la captura de pantalla). Cada polígono en navmesh es un área en la que un agente puede pararse o moverse de un polígono a otro polígono. En este ejemplo, los polígonos son más pequeños que los pisos en los que están ubicados, hechos para tener en cuenta las dimensiones del agente, que irán más allá de su posición nominal.

Podemos buscar la ruta a través de esta cuadrícula, nuevamente usando el algoritmo A *. Esto nos dará una ruta casi perfecta en el mundo que tiene en cuenta toda la geometría y no requiere nodos y puntos de referencia adicionales.
Pathfinding es un tema demasiado extenso sobre cuál sección del artículo no es suficiente. Si desea estudiarlo con más detalle, el
sitio de Amit Patel lo ayudará.
Planificacion
Con la búsqueda de ruta nos aseguramos de que a veces no basta con elegir una dirección y moverse, debemos elegir una ruta y hacer varios giros para llegar al destino deseado. Podemos resumir esta idea: lograr el objetivo no es solo el siguiente paso, sino una secuencia completa, donde a veces es necesario mirar hacia adelante unos pocos pasos para descubrir cuál debería ser el primero. Esto se llama planificación. Pathfinding se puede considerar como una de varias adiciones de planificación. Desde la perspectiva de nuestro ciclo Sentido / Pensar / Actuar, aquí es donde la parte Pensar planea varias partes Actuar para el futuro.
Veamos el ejemplo del juego de mesa Magic: The Gathering. Primero vamos con un juego de cartas en la mano:
- Pantano: da 1 maná negro (mapa de la tierra).
- Bosque: da 1 maná verde (mapa de la tierra).
- Mago fugitivo: Requiere 1 maná azul para invocar.
- Místico élfico: requiere 1 maná verde para invocar.
Ignoramos las tres cartas restantes para que sea más fácil. Según las reglas, un jugador puede jugar 1 carta de tierra por turno, puede "tocar" esta carta para extraer maná de ella y luego usar hechizos (incluidas las criaturas de invocación) de acuerdo con la cantidad de maná. En esta situación, el jugador humano sabe que necesitas jugar Forest, "tocar" 1 maná verde y luego llamar a Elvish Mystic. Pero, ¿cómo adivinas el juego AI?
Planificación fácil
El enfoque trivial es probar cada acción por turnos hasta que haya otras adecuadas. Mirando las cartas, la IA ve lo que Swamp puede jugar. Y lo juega. ¿Quedan otras acciones este turno? No puede invocar ni a Elvish Mystic ni a Fugitive Wizard, ya que su invocación requiere respectivamente maná verde y azul, y Swamp solo da maná negro. Y no podrá jugar Forest, porque ya ha jugado Swamp. Por lo tanto, el juego AI siguió las reglas, pero lo hizo mal. Se puede mejorar.
La planificación puede encontrar una lista de acciones que llevan el juego al estado deseado. Así como cada cuadrado en el camino tenía vecinos (en la búsqueda de caminos), cada acción en el plan también tiene vecinos o sucesores. Podemos buscar estas acciones y acciones posteriores hasta que alcancemos el estado deseado.
En nuestro ejemplo, el resultado deseado es "convocar a una criatura, si es posible". Al comienzo del movimiento, solo vemos dos acciones posibles permitidas por las reglas del juego:
1. Jugar Swamp (resultado: Swamp en el juego)
2. Jugar Forest (resultado: Forest en el juego)Cada acción tomada puede conducir a acciones adicionales y cerrar otras, nuevamente, dependiendo de las reglas del juego. Imagina que jugamos a Swamp: esto eliminará Swamp como el siguiente paso (ya lo jugamos), también eliminará Forest (porque según las reglas puedes jugar un mapa de la tierra por turno). Después de eso, la IA agrega como el siguiente paso: obtener 1 maná negro, porque no hay otras opciones. Si va más allá y elige Tap the Swamp, recibirá 1 unidad de maná negro y no puede hacer nada con él.
1. Jugar Swamp (resultado: Swamp en el juego)
1.1 Pantano “Tap” (resultado: Pantano “tap”, +1 unidad de maná negro)
No hay acciones disponibles - FIN
2. Jugar Forest (resultado: Forest en el juego)La lista de acciones fue corta, estamos en un punto muerto. Repita el proceso para el siguiente paso. Jugamos a Forest, abrimos la acción "get 1 green mana", que a su vez abrirá la tercera acción: la llamada de Elvish Mystic.
1. Jugar Swamp (resultado: Swamp en el juego)
1.1 Pantano “Tap” (resultado: Pantano “tap”, +1 unidad de maná negro)
No hay acciones disponibles - FIN
2. Jugar Forest (resultado: Forest en el juego)
2.1 Bosque "Tap" (resultado: Bosque "tap", +1 unidad de maná verde)
2.1.1 Invocar místico élfico (resultado: místico élfico en el juego, -1 unidad de maná verde)
No hay acciones disponibles - FINFinalmente, examinamos todas las acciones posibles y encontramos un plan que llama a la criatura.
Este es un ejemplo muy simplificado. Es aconsejable elegir el mejor plan posible, y no uno que cumpla con algunos criterios. Como regla general, puede evaluar los planes potenciales en función del resultado final o los beneficios totales de su implementación. Puedes sumarte 1 punto por jugar un mapa de la tierra y 3 puntos por desafiar a una criatura. Jugar a Swamp sería un plan que da 1 punto. Y para jugar Forest → Tap the Forest → invoca a Elvish Mystic: inmediatamente dará 4 puntos.
Así es como funciona la planificación en Magic: The Gathering, pero por la misma lógica se aplica en otras situaciones. Por ejemplo, mueva un peón para dejar espacio para que el alfil se mueva en el ajedrez. O cúbrete detrás de una pared para disparar con seguridad a XCOM así. En general, entiendes el punto.
Planificación mejorada
A veces hay demasiadas acciones potenciales para considerar todas las opciones posibles. Volviendo al ejemplo con Magic: The Gathering: digamos que en el juego y en tus manos hay varias cartas de tierra y criaturas: la cantidad de combinaciones posibles de movimientos puede estar en las decenas. Hay varias soluciones al problema.
La primera forma es encadenar hacia atrás. En lugar de clasificar todas las combinaciones, es mejor comenzar con el resultado final e intentar encontrar una ruta directa. En lugar del camino desde la raíz del árbol hasta una hoja específica, nos movemos en la dirección opuesta, desde la hoja hasta la raíz. Este método es más simple y rápido.
Si el oponente tiene 1 unidad de salud, puedes encontrar un plan para "infligir 1 o más unidades de daño". Para lograr esto, se deben cumplir una serie de condiciones:
1. El daño puede ser causado por un hechizo, debe estar en la mano.
2. Para lanzar un hechizo, necesitas maná.
3. Para obtener maná, debes jugar una carta de tierra.
4. Para jugar una carta de la tierra, debes tenerla en tu mano.
Otra forma es la mejor búsqueda primero. En lugar de recorrer todos los caminos, elegimos el más adecuado. Muy a menudo, este método ofrece un plan óptimo sin costos de búsqueda innecesarios. A * es la forma de la mejor primera búsqueda: explorando las rutas más prometedoras desde el principio, ya puede encontrar la mejor manera sin tener que consultar otras opciones.
Una opción interesante y cada vez más popular para la mejor búsqueda es Monte Carlo Tree Search. En lugar de adivinar qué planes son mejores que otros al elegir cada acción posterior, el algoritmo selecciona sucesores aleatorios en cada paso hasta llegar al final (cuando el plan condujo a la victoria o la derrota). Luego, el resultado final se utiliza para aumentar o disminuir la clasificación de peso de las opciones anteriores. Repitiendo este proceso varias veces seguidas, el algoritmo da una buena estimación de qué próximo paso es mejor, incluso si la situación cambia (si el oponente toma medidas para evitar que el jugador).
La historia sobre la planificación en los juegos no funcionará sin la Planificación de Acción Orientada a Objetivos o GOAP (planificación de acción orientada a objetivos). Este es un método ampliamente utilizado y discutido, pero además de algunos detalles distintivos, es esencialmente el método de encadenamiento hacia atrás del que hablamos anteriormente. Si la tarea era "destruir al jugador", y el jugador está detrás de la cobertura, el plan puede ser este: destruir con una granada → obtenerlo → soltarlo.
Por lo general, hay varios objetivos, cada uno con su propia prioridad. Si el objetivo con la prioridad más alta no se puede completar (ninguna combinación de acciones crea un plan para "destruir al jugador" porque el jugador no es visible), la IA volverá a los objetivos con una prioridad más baja.
Entrenamiento y adaptación
Ya dijimos que la IA de los juegos generalmente no usa el aprendizaje automático porque no es adecuada para administrar agentes en tiempo real. Pero esto no significa que no pueda pedir prestado nada de esta área. Queremos tal adversario en un tirador del que podamos aprender algo. Por ejemplo, descubra las mejores posiciones en el mapa. O un adversario en un juego de lucha que bloquearía los trucos combinados de uso frecuente del jugador, motivando a otros a usar. Por lo tanto, el aprendizaje automático en tales situaciones puede ser muy útil.
Estadísticas y probabilidades
Antes de pasar a ejemplos complejos, calcularemos hasta dónde podemos llegar tomando algunas medidas simples y usándolas para tomar decisiones. Por ejemplo, una estrategia en tiempo real: ¿cómo podemos determinar si un jugador puede lanzar un ataque en los primeros minutos de un juego y qué defensa preparar contra esto? Podemos estudiar la experiencia pasada del jugador para comprender cuál podría ser la reacción futura. Para empezar, no tenemos esos datos iniciales, pero podemos recopilarlos: cada vez que la IA juega contra una persona, él puede registrar el momento del primer ataque. Después de varias sesiones, obtendremos el tiempo promedio durante el cual el jugador atacará en el futuro.
Los valores promedio tienen un problema: si un jugador "decide" 20 veces y juega lentamente 20 veces, los valores necesarios estarán en algún punto intermedio, y esto no nos dará nada útil. Una solución es limitar la entrada: puede considerar las últimas 20 piezas.
Se utiliza un enfoque similar para evaluar la probabilidad de ciertas acciones, suponiendo que las preferencias pasadas del jugador serán las mismas en el futuro. Si un jugador nos ataca cinco veces con una bola de fuego, dos veces con un rayo y una vez con un combate cuerpo a cuerpo, es obvio que prefiere una bola de fuego. Extrapolamos y vemos la probabilidad de usar varias armas: bola de fuego = 62.5%, rayo = 25% y cuerpo a cuerpo = 12.5%. Nuestro juego AI necesita prepararse para la protección contra incendios.
Otro método interesante es utilizar el clasificador Bayesiano ingenuo (clasificador bayesiano ingenuo) para estudiar grandes volúmenes de datos de entrada y clasificar la situación para que la IA responda de la manera correcta. Los clasificadores bayesianos son más conocidos por usar filtros de correo no deseado. Allí, investigan palabras, las comparan con el lugar donde aparecieron estas palabras antes (en correo no deseado o no) y sacan conclusiones sobre las cartas entrantes. Podemos hacer lo mismo incluso con menos entrada. Sobre la base de toda la información útil que ve la IA (por ejemplo, qué unidades enemigas se crean, qué hechizos usan o qué tecnologías exploraron), y el resultado final (guerra o paz, "aplastar" o defender, etc.) - Seleccionaremos el comportamiento de IA deseado.
Todos estos métodos de entrenamiento son suficientes, pero es recomendable usarlos en base a los datos de las pruebas. AI aprenderá cómo adaptarse a las diversas estrategias que han utilizado tus evaluadores de juego. Una IA que se adapta a un jugador después de un lanzamiento puede volverse demasiado predecible, o viceversa, demasiado complejo para ganar.
Adaptación Basada en el Valor
Dado el contenido de nuestro mundo de juego y las reglas, podemos cambiar el conjunto de valores que afectan la toma de decisiones, y no solo usar los datos de entrada. Hacemos esto:
- Deje que la IA recopile datos sobre el estado del mundo y los eventos clave durante el juego (como se indicó anteriormente).
- Cambiemos algunos valores importantes basados en estos datos.
- Nos damos cuenta de nuestras decisiones basadas en el procesamiento o la evaluación de estos valores.
Por ejemplo, un agente tiene varias salas para elegir un tirador en primera persona en el mapa. Cada habitación tiene su propio valor, que determina qué tan deseable es visitarla. La IA elige aleatoriamente a qué habitación ir en función del valor del valor. Luego, el agente recuerda en qué habitación fue asesinado y reduce su valor (la probabilidad de que regrese allí). De manera similar para la situación inversa: si el agente destruye a muchos oponentes, entonces el valor de la habitación aumenta.
Modelo de Markov
¿Qué pasa si usamos los datos recopilados para el pronóstico? Si recordamos cada habitación en la que vemos al jugador durante un cierto período de tiempo, predeciremos a qué habitación puede entrar el jugador. Al rastrear y registrar el movimiento del jugador en las salas (valores), podemos predecirlos.
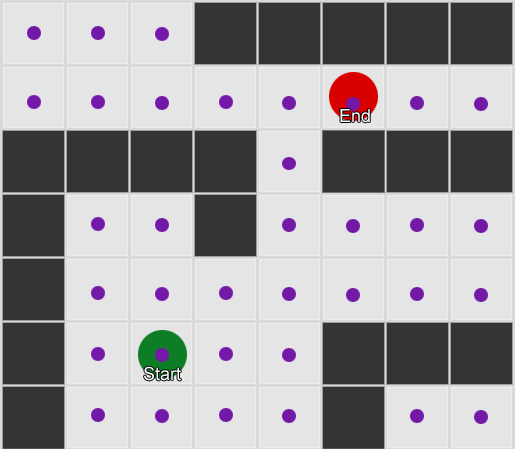
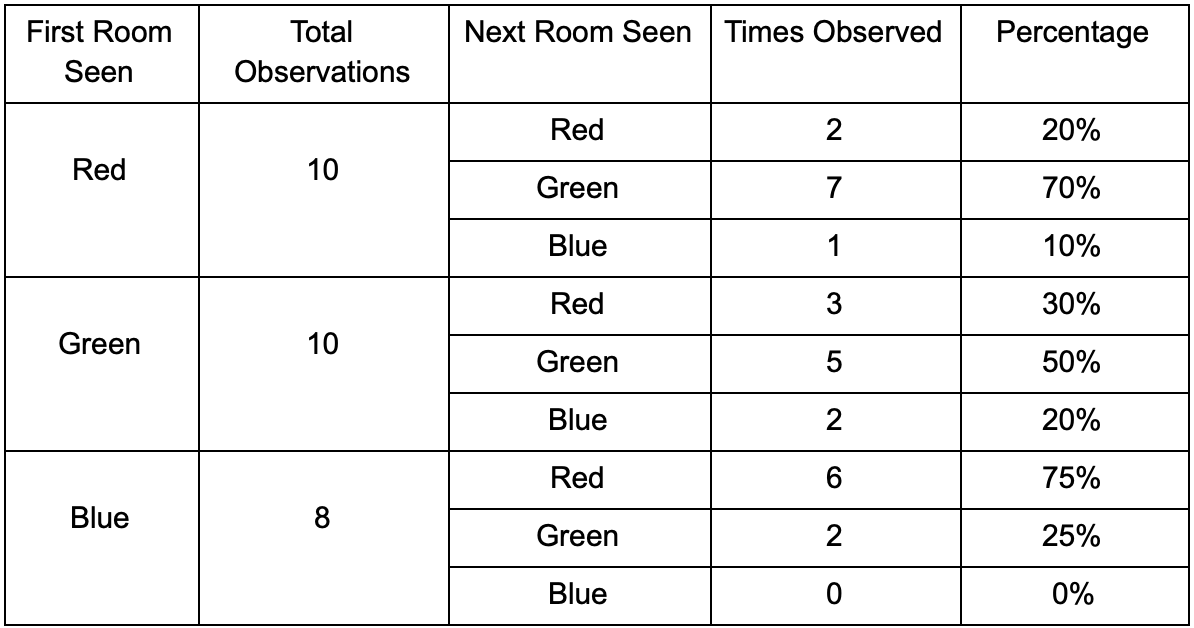
Tomemos tres habitaciones: rojo, verde y azul. Además de las observaciones que registramos al ver una sesión de juego:
El número de observaciones para cada habitación es casi igual: todavía no sabemos dónde hacer un buen lugar para una emboscada. La recopilación de estadísticas también se complica por la reaparición de jugadores que aparecen de manera uniforme en todo el mapa. Pero los datos de la siguiente habitación, que ingresan después de aparecer en el mapa, ya son útiles.
Se puede ver que la sala verde se adapta a los jugadores: la mayoría de las personas de rojo van a ella, el 50% de las cuales permanece allí y más. La sala azul, por el contrario, no es popular, casi nunca se visita, y si lo es, no se demora.
Pero los datos nos dicen algo más importante: cuando el jugador está en la habitación azul, la siguiente habitación en la que probablemente lo veremos será roja, no verde. A pesar de que la sala verde es más popular que la roja, la situación cambia si el jugador está en azul. El siguiente estado (es decir, la sala en la que entrará el jugador) depende del estado anterior (es decir, la sala en la que se encuentra el jugador ahora). Debido al estudio de las dependencias, haremos pronósticos con mayor precisión que si simplemente calculáramos las observaciones independientemente el uno del otro.
La predicción de un estado futuro basado en datos de estados pasados se llama modelo de Markov, y tales ejemplos (con habitaciones) se llaman cadenas de Markov. Dado que los modelos representan la probabilidad de cambios entre estados sucesivos, se muestran visualmente como FSM con una probabilidad cercana a cada transición. Anteriormente, utilizamos FSM para representar el estado de comportamiento en el que se encontraba el agente, pero este concepto se aplica a cualquier estado, independientemente de si está relacionado con el agente o no. En este caso, los estados representan la habitación ocupada por el agente:
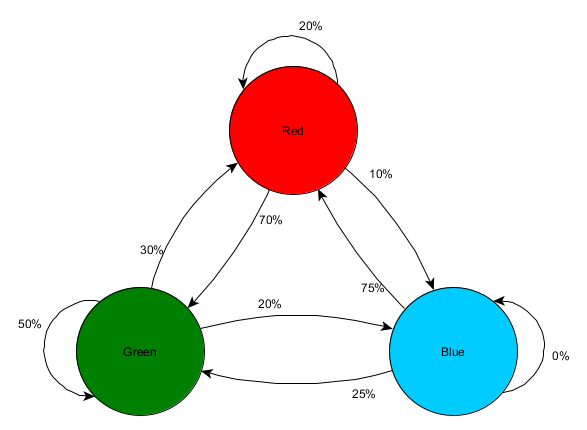
Esta es una versión simple de la representación de la probabilidad relativa de cambios en los estados, dando a la IA alguna oportunidad de predecir el siguiente estado. Puedes predecir algunos pasos hacia adelante.
Si el jugador está en la sala verde, hay un 50% de posibilidades de que permanezca allí durante la próxima observación. Pero, ¿cuál es la probabilidad de que él siga allí incluso después? No solo existe la posibilidad de que el jugador permanezca en la sala verde después de dos observaciones, sino también la posibilidad de que se vaya y regrese. Aquí está la nueva tabla con los nuevos datos:
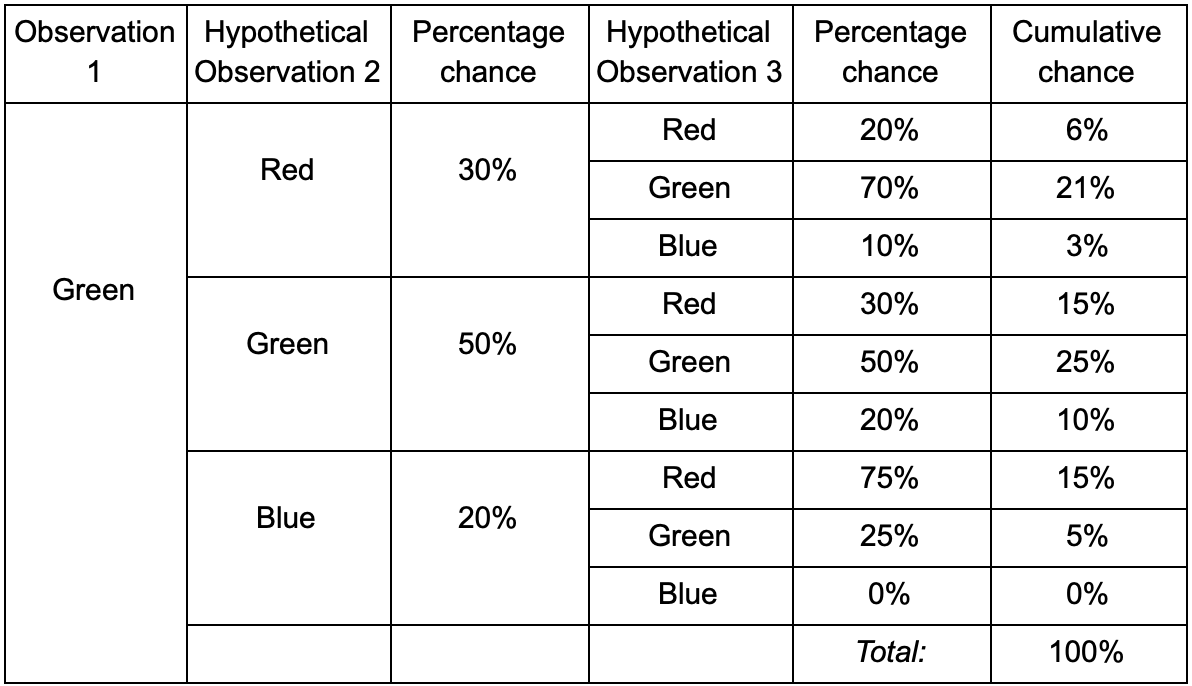
Muestra que la probabilidad de ver a un jugador en la sala verde después de dos observaciones será del 51% - 21%, que vendrá de la sala roja, 5% de ellos, que el jugador visitará la sala azul entre ellos, y 25%, que el jugador no saldrá de la sala verde.
Una tabla es solo una herramienta visual: un procedimiento solo requiere una multiplicación de probabilidades en cada paso. Esto significa que puede mirar hacia el futuro con una enmienda: suponemos que la posibilidad de ingresar a una habitación depende completamente de la habitación actual. Esto se llama la propiedad de Markov: el estado futuro depende solo del presente. Pero esto no es completamente exacto. Los jugadores pueden tomar decisiones dependiendo de otros factores: nivel de salud o cantidad de municiones. Como no fijamos estos valores, nuestros pronósticos serán menos precisos.
N-gramos
- ? ! , , -.
— (, Kick, Punch Block) . , Kick, Kick, Punch, SuperDeathFist, , .
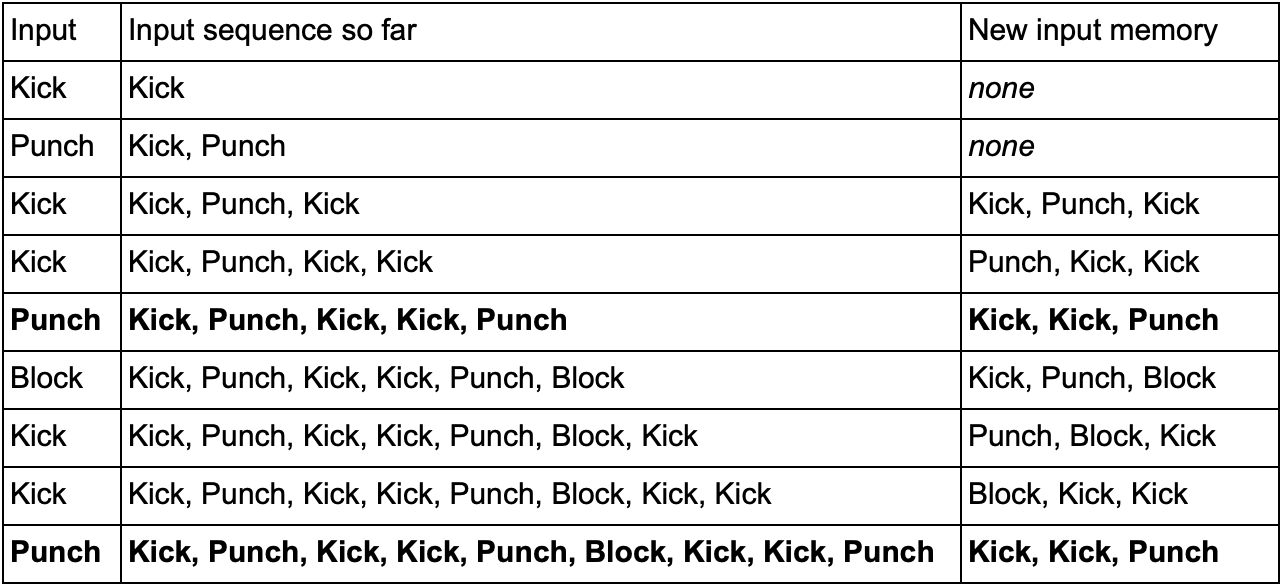
( , SuperDeathFist.)
, Kick, Kick, , Punch. - SuperDeathFist , .
N- (N-grams), N — . 3- (), : . 5- .
N-. N , . , 2- () Kick, Kick Kick, Punch, Kick, Kick, Punch, SuperDeathFist.
, , . Kick, Punch Block, 10-, 60 .
— « / » , . 3- N- , ( N-) , — . Kick Kick Kick Punch. , , , . , , - .
Conclusión
. , .
. , , . , :
- , ,
- / (minimax alpha-beta pruning)
- (, )
- ( , )
- ( )
- ( , anytime, timeslicing)
- :
1. GameDev.net
,
.
2.
AiGameDev.com .
3.
The GDC Vault GDC AI, .
4.
AI Game Programmers Guild .
5. , , YouTube-
AI and Games .
:
1. Game AI Pro , , .
Game AI Pro: Collected Wisdom of Game AI ProfessionalsGame AI Pro 2: Collected Wisdom of Game AI ProfessionalsGame AI Pro 3: Collected Wisdom of Game AI Professionals2. AI Game Programming Wisdom — Game AI Pro. , .
AI Game Programming Wisdom 1AI Game Programming Wisdom 2AI Game Programming Wisdom 3AI Game Programming Wisdom 43.
Artificial Intelligence: A Modern Approach — . — .