Las publicaciones anteriores en el blog corporativo no contenían un solo equipo de consola, y decidimos ponernos al día.
Nuestra empresa tiene una métrica diseñada para evitar grandes fakaps en hosting compartido. En cada servidor de alojamiento compartido hay un sitio de prueba en WordPress, al que se accede periódicamente.
Así es como se ve el sitio de prueba en cada servidor de alojamiento compartido
Se mide la velocidad y el éxito de la respuesta del sitio. Cualquier empleado de la compañía puede mirar las estadísticas generales y ver qué tan bien le está yendo a la compañía. Puede ver el porcentaje de respuestas exitosas de un sitio de prueba para todo el alojamiento o para un servidor específico. No es necesario ser un empleado de la empresa: en el panel de control, los clientes también ven estadísticas en el servidor donde se encuentra su cuenta.
Llamamos a esta métrica de tiempo de actividad (el porcentaje de respuestas exitosas del sitio de prueba a todas las solicitudes al sitio de prueba). No es un muy buen nombre, es fácil confundirlo con el tiempo de actividad , que es el tiempo total después del último reinicio del servidor .
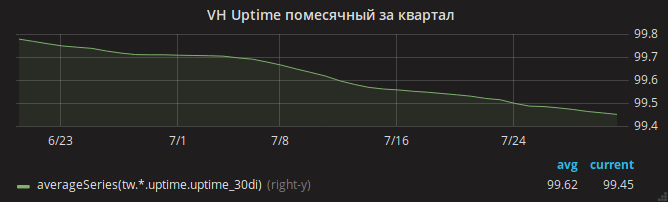
El verano pasó y el horario de actividad disminuyó lentamente.
Los administradores identificaron de inmediato la razón: falta de RAM. Fue fácil ver los casos de OOM en los registros cuando el servidor se quedó sin memoria y el kernel mató a nginx.
El jefe del departamento, Andrey, divide una tarea en varias de la mano de un mago y las pone en paralelo con diferentes administradores. Uno va a analizar la configuración de Apache, ¿tal vez la configuración no sea óptima y con mucho tráfico Apache usa toda la memoria? Otro analiza el consumo de memoria mysqld: de repente, ¿hay alguna configuración desactualizada desde el momento en que el alojamiento compartido utilizaba el sistema operativo Gentoo? El tercero analiza los cambios recientes en la configuración de nginx.
Uno por uno, los administradores regresan con resultados. Cada uno logró reducir el consumo de memoria en el área asignada a él. En el caso de nginx, por ejemplo, se detectó un mod_security incluido pero no utilizado. OOM, mientras tanto, también es frecuente.
Finalmente, es posible notar que el consumo de memoria central (en particular, SUnreclaim) es terriblemente grande en algunos servidores. ¡Ni en la salida ps ni en htop es visible este parámetro, por lo que no lo notamos de inmediato! Ejemplo de servidor con SUnreclaim infernal:
root@vh28.timeweb.ru:~
Se le dan 24 gigabytes de RAM al kernel, ¡y el kernel los gasta porque nadie sabe qué!
El administrador (llamémosle Gabriel) se apresura a la batalla. Vuelve a ensamblar el kernel con las opciones KMEMLEAK para la detección de fugas.
Opciones para reconstruirPara habilitar KMEMLEAK, solo especifique las opciones enumeradas a continuación y cargue el kernel con el parámetro kmemleak = on.
CONFIG_HAVE_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK=y CONFIG_DEBUG_KMEMLEAK_DEFAULT_OFF=y CONFIG_DEBUG_KMEMLEAK_EARLY_LOG_SIZE=10000
KMEMLEAK escribe (en /sys/kernel/debug/kmemleak ) estas líneas:
unreferenced object 0xffff88013a028228 (size 8): comm "apache2", pid 23254, jiffies 4346187846 (age 1436.284s) hex dump (first 8 bytes): 00 00 00 00 00 00 00 00 ........ backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d450a>] kmem_cache_alloc_trace+0xca/0x1d0 [<ffffffff8136dcc3>] apparmor_file_alloc_security+0x23/0x40 [<ffffffff81332d63>] security_file_alloc+0x33/0x50 [<ffffffff811f8013>] get_empty_filp+0x93/0x1c0 [<ffffffff811f815b>] alloc_file+0x1b/0xa0 [<ffffffff81728361>] sock_alloc_file+0x91/0x120 [<ffffffff8172b52e>] SyS_socket+0x7e/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff unreferenced object 0xffff880d67030280 (size 624): comm "hrrb", pid 23713, jiffies 4346190262 (age 1426.620s) hex dump (first 32 bytes): 01 00 00 00 03 00 ff ff 00 00 00 00 00 00 00 00 ................ 00 e7 1a 06 10 88 ff ff 00 81 76 6e 00 88 ff ff ..........vn.... backtrace: [<ffffffff818570c8>] kmemleak_alloc+0x28/0x50 [<ffffffff811d4337>] kmem_cache_alloc+0xc7/0x1d0 [<ffffffff8172a25d>] sock_alloc_inode+0x1d/0xc0 [<ffffffff8121082d>] alloc_inode+0x1d/0x90 [<ffffffff81212b01>] new_inode_pseudo+0x11/0x60 [<ffffffff8172952a>] sock_alloc+0x1a/0x80 [<ffffffff81729aef>] __sock_create+0x7f/0x220 [<ffffffff8172b502>] SyS_socket+0x52/0xc0 [<ffffffff81003854>] do_syscall_64+0x54/0xc0 [<ffffffff818618ab>] return_from_SYSCALL_64+0x0/0x6a [<ffffffffffffffff>] 0xffffffffffffffff
Gabriel no nos reveló todos sus secretos y no contó cómo, en las líneas anteriores, descubrió la causa exacta de la pérdida de memoria. Lo más probable es que haya usado el addr2line /usr/lib/debug/lib/modules/`uname -r`/vmlinux ffffffff81722361 para encontrar la línea exacta. O simplemente abrió el net/socket.c y lo miró hasta que el archivo se volvió incómodo.
El problema resultó ser un parche en el net/socket.c , que se agregó a nuestro repositorio hace muchos años. Su propósito es prohibir a los clientes el uso de la llamada al sistema bind (), esta es una protección simple contra el servidor proxy que inician los clientes. El parche cumplió su propósito, pero no borró la memoria después de sí mismo.
Tal vez hubo un nuevo malware de moda en PHP que intentó ejecutar un servidor proxy en un bucle, lo que condujo a cientos de miles de llamadas bloqueadas bind () y perdió gigabytes de RAM.
Luego fue simple: Gabriel arregló el parche y reconstruyó el núcleo. Monitoreo agregado del valor de SUnreclaim en todos los servidores que ejecutan Linux. Los ingenieros advirtieron a los clientes y reiniciaron el alojamiento en el nuevo núcleo.
OOM desapareció.
Pero el problema con la disponibilidad de sitios permaneció
En todos los servidores, el sitio de prueba dejó de responder varias veces al día.
Aquí, el autor comenzaría a rasgar el cabello en diferentes partes del cuerpo. Pero Gabriel mantuvo la calma y activó la grabación del tráfico a partes de los servidores de alojamiento.
En el volcado de tráfico, se observó que con mayor frecuencia la solicitud al sitio de prueba cae después de la recepción repentina de un paquete TCP RST . En otras palabras, la solicitud llegó al servidor, pero la conexión terminó siendo interrumpida por nginx.
Además más interesante! La utilidad strace lanzada por Gabriel muestra que el demonio nginx no está enviando este paquete. ¿Cómo puede ser esto, porque solo nginx está escuchando en el puerto 80?
La razón fue una combinación de varios factores:
- en la configuración de nginx, se
reuseport opción de reuseport (incluida la SO_REUSEPORT socket SO_REUSEPORT ), que permite que diferentes procesos acepten conexiones en la misma dirección y puerto - en (en ese momento, la versión más reciente) de nginx 1.13.0 hay un error debido al cual al iniciar la prueba de configuración de
nginx -t través de nginx -t y al usar la SO_REUSEPORT este proceso de prueba de nginx realmente comenzó a escuchar el puerto 80 e interceptar solicitudes de clientes reales . Y al final del proceso de prueba de configuración, los clientes recibieron el Connection reset by peer - finalmente, al monitorear el zabbix, se configuró el monitoreo de corrección de la configuración de nginx en todos los servidores con nginx instalado: se llamó al comando
nginx -t una vez por minuto.
Solo después de actualizar nginx podría exhalar con calma. El gráfico de tiempo de actividad de los sitios ha aumentado.
¿Cuál es la moraleja de toda esta historia? Sea optimista y evite el uso de núcleos autoensamblados.