Mantener una gran base de código mientras se garantiza una alta productividad para un gran número de desarrolladores es un desafío serio. En los últimos 5 años, Yandex ha estado desarrollando un sistema especial para la integración continua. En este artículo, hablaremos sobre la escala de la base de código Yandex, sobre la transferencia del desarrollo a un único repositorio con un enfoque de desarrollo basado en troncales, sobre qué tareas debe resolver un sistema de integración continua para trabajar de manera efectiva en tales condiciones.

Hace muchos años, Yandex no tenía reglas especiales en el desarrollo de servicios: cada departamento podía usar cualquier idioma, cualquier tecnología, cualquier sistema de implementación. Y como la práctica ha demostrado, esa libertad no siempre ayudó a avanzar más rápido. En ese momento, para resolver los mismos problemas, a menudo había varios desarrollos propietarios o de código abierto. A medida que la empresa creció, ese ecosistema funcionó peor. Al mismo tiempo, queríamos seguir siendo un gran Yandex, y no dividirnos en muchas compañías independientes, porque ofrece muchas ventajas: muchas personas hacen las mismas tareas, los resultados de su trabajo pueden reutilizarse. Comenzando desde una variedad de estructuras de datos, como tablas hash distribuidas y colas sin bloqueo, y terminando con una gran cantidad de códigos especializados diferentes que hemos escrito durante 20 años.
Muchas de las tareas que resolvemos no se resuelven en el mundo de código abierto. No hay MapReduce que funcione bien en nuestros volúmenes (más de 5000 servidores) y nuestras tareas; no hay un rastreador de tareas que pueda manejar todas nuestras decenas de millones de tickets. Esto es atractivo en Yandex: puedes hacer cosas realmente geniales.
Pero estamos perdiendo eficiencia de manera importante cuando resolvemos los mismos problemas de nuevo, rehacemos soluciones ya hechas, lo que dificulta la integración entre componentes. Es bueno y conveniente hacer todo solo por ti mismo en tu propio rincón, no puedes pensar en los demás por el momento. Pero tan pronto como el servicio sea lo suficientemente notable, tendrá dependencias. Solo parece que varios servicios dependen débilmente entre sí, de hecho, hay muchas conexiones entre diferentes partes de la empresa. Muchos servicios están disponibles a través de la aplicación Yandex / Navegador / etc., o están integrados entre sí. Por ejemplo, Alice aparece en el navegador, usando Alice puedes pedir un taxi. Todos usamos componentes comunes: YT , YQL , Nirvana .
El antiguo modelo de desarrollo tenía problemas importantes. Debido a la presencia de muchos repositorios, es difícil para un desarrollador ordinario, especialmente un principiante, descubrir:
- donde esta el componente
- cómo funciona: no hay forma de "tomar y leer"
- ¿Quién lo está desarrollando y apoyando ahora?
- ¿Cómo empezar a usarlo?
Como resultado, surgió el problema del uso mutuo de componentes. Los componentes casi no podían usar otros componentes porque representaban "cajas negras" entre sí. Esto afectó negativamente a la empresa, ya que los componentes no solo no se reutilizaron, sino que a menudo no mejoraron. Muchos componentes se duplicaron, la cantidad de código que tenía que ser compatible crecía significativamente. Generalmente nos movíamos más despacio de lo que podíamos.
Repositorio único e infraestructura
Hace 5 años, comenzamos un proyecto para transferir el desarrollo a un único repositorio, con sistemas comunes de ensamblaje, prueba, implementación y monitoreo.
El objetivo principal que queríamos lograr era eliminar los obstáculos que impiden la integración del código de otra persona. El sistema debe proporcionar un acceso fácil al código de trabajo terminado, un esquema claro para su conexión y uso, capacidad de recolección: los proyectos siempre se recopilan (y pasan las pruebas).
Como resultado del proyecto, surgió una sola pila de tecnologías de infraestructura para la empresa: almacenamiento de código fuente, sistema de revisión de código, sistema de construcción, sistema de integración continua, implementación, monitoreo.
Ahora, la mayor parte del código fuente para los proyectos de Yandex se almacena en un único repositorio, o está en proceso de pasar a él:
- Más de 2000 desarrolladores trabajan en proyectos.
- Más de 50,000 proyectos y bibliotecas.
- El tamaño del repositorio supera los 25 GB.
- Ya se han comprometido más de 3.000.000 de confirmaciones en el repositorio.
Ventajas para la empresa:
- Cualquier proyecto del repositorio recibe una infraestructura preparada:
- un sistema para ver y navegar el código fuente y un sistema de revisión de código.
- Sistema de montaje y montaje distribuido. Este es un gran tema separado, y definitivamente lo cubriremos en los siguientes artículos.
- Sistema de integración continua.
- implementación, integración con el sistema de monitoreo.
- código compartido, interacción activa del equipo.
- todo el código es común, puede venir a otro proyecto y hacer los cambios que necesita allí. Esto es especialmente importante en una gran empresa, porque otro equipo del que necesita algo puede no tener los recursos. Con el código común, tiene la oportunidad de hacer parte del trabajo usted mismo y "ayudar a que suceda" los cambios que necesita.
- Existe la oportunidad de llevar a cabo una refactorización global. No necesita admitir versiones antiguas de su API o biblioteca, puede cambiarlas y cambiar los lugares donde se usan en otros proyectos.
- el código se vuelve menos "diverso". Tiene un conjunto de formas de resolver problemas, y no es necesario agregar otra forma que haga lo mismo, pero con ligeras diferencias.
- en el proyecto a su lado, lo más probable es que no haya bibliotecas y lenguajes absolutamente exóticos.
También debe entenderse que dicho modelo de desarrollo tiene desventajas que deben considerarse:
- Un repositorio compartido requiere una infraestructura separada y específica.
- la biblioteca que necesita puede no estar en el repositorio, pero está en código abierto. Hay costos para agregarlo y actualizarlo. Muy dependiente del idioma y la biblioteca, en algún lugar casi gratis, en algún lugar muy costoso.
- necesita trabajar constantemente en la "salud" del código. Esto incluye al menos la lucha contra las dependencias innecesarias y el código muerto.
Nuestro enfoque hacia un repositorio común impone reglas generales que todos deben seguir. En el caso de utilizar un único repositorio, se imponen restricciones en los idiomas utilizados, las bibliotecas y los métodos de implementación. Pero en el proyecto vecino todo será igual o muy similar al tuyo, e incluso puedes arreglar algo allí.
El modelo de un repositorio común gravita en todas las grandes empresas. El repositorio monolítico es un tema amplio, bien estudiado y discutido, por lo que ahora no entraremos mucho en él. Si desea saber más, al final del artículo encontrará varios enlaces útiles que revelan este tema con más detalle.
Condiciones en las que opera el sistema de integración continua
El desarrollo se lleva a cabo de acuerdo con el modelo de desarrollo basado en Trunk. La mayoría de los usuarios trabajan con HEAD, o la copia más reciente del repositorio, obtenida de la rama principal llamada troncal, en la que se está desarrollando. La confirmación de los cambios en el repositorio se realiza de forma secuencial. Inmediatamente después de la confirmación, el nuevo código es visible y puede ser utilizado por todos los desarrolladores. No se recomienda el desarrollo en ramas separadas, aunque las ramas se pueden usar para lanzamientos.
Los proyectos dependen del código fuente. Los proyectos y las bibliotecas forman un gráfico de dependencia complejo. Y esto significa que los cambios realizados en un proyecto afectan potencialmente al resto del repositorio.
Una gran secuencia de confirmaciones va al repositorio:
- Más de 2000 confirmaciones por día.
- hasta 10 cambios por minuto durante las horas pico.
La base de código contiene más de 500,000 objetivos de compilación y pruebas.
Sin un sistema especial de integración continua en tales condiciones, sería muy difícil avanzar rápidamente.
Sistema de integración continua
El sistema de integración continua lanza ensamblajes y pruebas para cada cambio:
- Verificaciones preliminares. Permiten verificar el código antes de comprometerse y evitar romper las pruebas en el tronco. Los ensamblajes y las pruebas se ejecutan encima de HEAD. Por el momento, los controles previos a la auditoría se inician voluntariamente. Para proyectos críticos, se requieren verificaciones previas a la auditoría.
- Verificaciones posteriores a la confirmación después de confirmar en el repositorio.
Las compilaciones y las pruebas se ejecutan en paralelo en grandes grupos de cientos de servidores. Las compilaciones y las pruebas se ejecutan en diferentes plataformas. Bajo la plataforma principal (Linux), todos los proyectos se ensamblan y todas las pruebas se ejecutan, bajo las otras plataformas, un subconjunto de las configurables por el usuario.
Después de recibir y analizar los resultados de los ensamblajes y ejecutar las pruebas, el usuario recibe comentarios, por ejemplo, si los cambios rompen alguna prueba.

En caso de nuevas fallas de ensamblaje o pruebas, enviamos una notificación a los propietarios de las pruebas y al autor de los cambios. El sistema también almacena y muestra los resultados de las comprobaciones en una interfaz especial. La interfaz web del sistema de integración muestra el progreso y el resultado de la prueba, desglosados por tipo de prueba. La pantalla con los resultados del análisis ahora puede verse así:
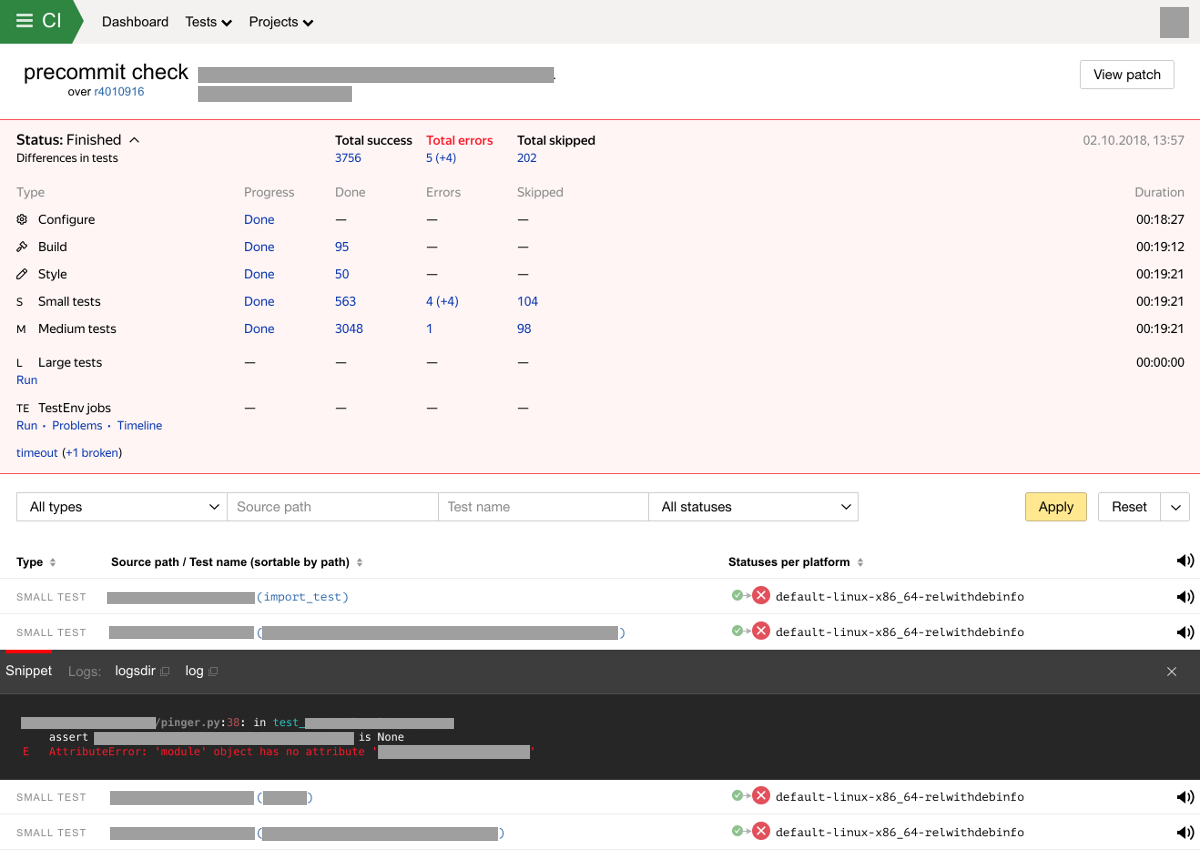
Características y capacidades del sistema de integración continua.
Resolviendo varios problemas que enfrentan los desarrolladores y probadores, desarrollamos nuestro sistema de integración continua. El sistema ya resuelve muchos problemas, pero queda mucho por mejorar.
Tipos y tamaños de pruebas.
Hay varios tipos de objetivos que puede activar un sistema de integración continua:
- configurar La fase de configuración realizada por el sistema de compilación. La configuración incluye un análisis de los archivos de configuración del sistema de ensamblaje, determinando las dependencias entre los proyectos y los parámetros del ensamblaje y ejecutando las pruebas.
- construir. Montaje de bibliotecas y proyectos.
- estilo En esta etapa, el estilo del código coincide con los requisitos especificados.
- prueba Las pruebas se dividen en etapas según su tiempo de espera para el tiempo de trabajo y los requisitos para los recursos informáticos.
- pequeño <1 min
- medio <10 min
- grande > 10 min Además, puede haber requisitos especiales para los recursos informáticos.
- extra grande Este es un tipo especial de prueba. Dichas pruebas se caracterizan por un conjunto de las siguientes características: un tiempo de funcionamiento prolongado, un gran consumo de recursos, una gran cantidad de datos de entrada, pueden requerir accesos especiales y, lo más importante, soporte para los escenarios de prueba complejos que se describen a continuación. Hay menos pruebas de este tipo que otros tipos de pruebas, pero son muy importantes.
Pruebe la frecuencia de lanzamiento y la detección de fallas binarias
Se asignan enormes recursos para pruebas en Yandex, cientos de servidores potentes. Pero incluso con una gran cantidad de recursos, no podemos ejecutar todas las pruebas para cada cambio que los afecte. Pero al mismo tiempo, es muy importante para nosotros ayudar siempre al desarrollador a localizar el lugar donde se rompe la prueba, especialmente en un repositorio tan grande.
Que estamos haciendo Para cada cambio para todos los proyectos afectados, se ejecutan ensamblajes, comprobaciones de estilo y pruebas con tamaños pequeños y medianos. El resto de las pruebas se ejecutan no para cada confirmación que influye, sino con cierta periodicidad, si hay confirmaciones que afectan las pruebas. En algunos casos, los usuarios pueden controlar la frecuencia de inicio; en otros casos, el sistema establece la frecuencia de inicio. Cuando se detecta una falla de prueba, comienza el proceso de búsqueda de una confirmación de ruptura de prueba. Cuanto menos se ejecute la prueba, más tiempo buscaremos una confirmación de ruptura después de detectar una falla.

Al iniciar las comprobaciones previas a la auditoría, también ejecutamos solo ensamblajes y pruebas ligeras. Luego, el usuario puede iniciar manualmente el lanzamiento de pruebas pesadas seleccionando de la lista de pruebas afectadas por los cambios proporcionados por el sistema.
Detección de prueba intermitente
Las pruebas intermitentes son pruebas cuyos resultados de ejecución (Aprobado / Fallido) en el mismo código pueden depender de varios factores. Las causas de las pruebas de flasheo pueden ser diferentes: suspensión en el código de prueba, errores al trabajar con subprocesos múltiples, problemas de infraestructura (falta de disponibilidad de cualquier sistema), etc. Las pruebas intermitentes presentan un problema grave:
- Conducen al hecho de que el sistema de integración continua envía alertas falsas sobre fallas en las pruebas.
- Contaminar los resultados de la prueba. Cada vez es más difícil decidir sobre el éxito de los resultados de la verificación.
- Retrasar lanzamientos de productos.
- Difícil de detectar. Las pruebas pueden parpadear muy raramente.
Los desarrolladores pueden ignorar las pruebas parpadeantes al analizar los resultados de las pruebas. A veces incorrecto
Es imposible eliminar por completo las pruebas de parpadeo, esto debe tenerse en cuenta en un sistema de integración continua.
Actualmente, para cada prueba, ejecutamos todas las pruebas dos veces para detectar pruebas de flasheo. También tomamos en cuenta las quejas de los usuarios (destinatarios de las notificaciones). Si detectamos un parpadeo, marcamos la prueba con una bandera especial (silenciada) e informamos al propietario de la prueba. Después de esto, solo los propietarios de las pruebas recibirán notificaciones de fallas en las pruebas. A continuación, continuamos ejecutando la prueba en modo normal, mientras analizamos el historial de sus lanzamientos. Si la prueba no parpadeó en un período de tiempo determinado, la automatización puede decidir que la prueba ha dejado de parpadear y puede borrar la bandera.
Nuestro algoritmo actual es bastante simple y se planean muchas mejoras en este lugar. En primer lugar, queremos usar señales mucho más útiles.
Actualización automática de entrada de prueba
Cuando se prueban los sistemas Yandex más complejos, además de otros métodos de prueba, a menudo se utilizan pruebas de estrategia de caja negra + pruebas basadas en datos . Para garantizar una buena cobertura, tales pruebas requieren un gran conjunto de datos de entrada. Los datos se pueden seleccionar de grupos de producción. Pero hay un problema con el hecho de que los datos se vuelven obsoletos rápidamente. El mundo no se detiene, nuestros sistemas están en constante evolución. Los datos de prueba obsoletos a lo largo del tiempo no proporcionarán una buena cobertura de prueba, y luego conducirán completamente a un desglose de la prueba debido al hecho de que los programas comienzan a usar datos nuevos que no están disponibles en los datos de prueba obsoletos.
Para que los datos no queden desactualizados, el sistema de integración continua puede actualizarlos automáticamente. Como funciona
- Los datos de prueba se almacenan en un almacenamiento especial de recursos.
- La prueba contiene metadatos que describen la entrada requerida.
- La correspondencia entre la entrada de prueba requerida y los recursos se almacena en un sistema de integración continua.
- El desarrollador proporciona la entrega regular de datos nuevos al almacén de recursos.
- El sistema de integración continua busca nuevas versiones de datos de prueba en el repositorio de recursos y cambia los datos de entrada.
Es importante actualizar los datos para que no se realice la prueba falsa. No puede simplemente tomar y, a partir de una determinada confirmación, comenzar a usar nuevos datos, porque En el caso de un desglose de la prueba, no estará claro quién es el culpable: el compromiso o los nuevos datos. También hará que las pruebas de diferencias (descritas a continuación) no funcionen.

Por lo tanto, lo hacemos para que haya un pequeño intervalo de confirmaciones, en el que la prueba se inicia tanto con la versión anterior como con la nueva de los datos de entrada.

Diferentes pruebas
Las pruebas de diferencia que llamamos un tipo especial de pruebas basadas en datos , que difieren del enfoque generalmente aceptado en que la prueba no tiene un resultado de referencia, pero al mismo tiempo necesitamos encontrar en qué confirmaciones la prueba cambió su comportamiento.
El enfoque estándar en las pruebas basadas en datos es el siguiente. La prueba tiene un resultado de referencia obtenido cuando la prueba se ejecutó por primera vez. El resultado de referencia se puede almacenar en el repositorio al lado de la prueba. Las ejecuciones posteriores de la prueba deberían producir el mismo resultado.

Si el resultado difiere de la referencia, el desarrollador debe decidir si este cambio esperado o error. Si se espera el cambio, el desarrollador debe actualizar el resultado de referencia al mismo tiempo que confirma los cambios en el repositorio.
Existen dificultades al usar este enfoque en un repositorio grande con grandes flujos de confirmación:
- Puede haber muchas pruebas y las pruebas pueden ser muy difíciles. El desarrollador no tiene la capacidad de ejecutar todas las pruebas afectadas en un entorno de trabajo.
- Después de realizar cambios, la prueba puede interrumpirse si el resultado de referencia no se actualizó simultáneamente con los cambios en el código. Luego, otro desarrollador puede hacer cambios en el mismo componente y el resultado de la prueba cambiará nuevamente. Obtenemos la imposición de un error sobre otro. Es muy difícil lidiar con tales problemas, lleva tiempo de los desarrolladores.
Que estamos haciendo Las pruebas de diferencias constan de 2 partes:
- Comprobar componente.
- Comenzamos la prueba y guardamos el resultado en el almacenamiento de recursos.
- No compare el resultado con la referencia.
- Podemos detectar algunos de los errores, por ejemplo, el programa no se inicia / no finaliza, se bloquea, el programa no responde. La validación del resultado también se puede realizar: la presencia de cualquier campo en la respuesta, etc.
- Componente diferencial.
- Compare los resultados obtenidos en diferentes lanzamientos y compile diff. En el caso más simple, esta es una función que toma 2 parámetros y devuelve diff.
- La apariencia de diff depende de la prueba, pero debería ser algo comprensible para alguien que lo vea. diff html .
check diff .

diff, . diff , : diff ( ) / "" .
Para continuar
, .
Referencias
, Trunk-based development
Data-driven testing