Anteriormente, en Avito, podía encontrar el producto adecuado mediante el filtrado de palabras clave o la navegación del árbol de categorías. Este método, aunque parecía familiar, no siempre era conveniente: para encontrar un producto o servicio, era necesario hacer una gran cantidad de clics. Hace más de un año, hemos ganado relevancia, gracias a lo cual la búsqueda ha mejorado, y ahora es más fácil y conveniente encontrar un producto o servicio incluso en la página principal. Con esta innovación, los bienes inadecuados y francamente "basura" dejaron de caer en el tema. Y este es solo uno de los pasos para mejorar su búsqueda. Estamos cambiando gradualmente la infraestructura, lo que nos permite trabajar en la calidad de búsqueda con mayor intensidad, mejorarla más rápido y desplegar nuevas características que beneficien a los vendedores y compradores en Avito.
En el artículo, le diré cómo ha cambiado la búsqueda en Avito: dónde comenzamos y cómo avanzamos ahora para mejorar la vida de nuestros usuarios, compartiré nuestras innovaciones tanto en el producto como en su llenado, la parte técnica. No habrá carne hardcore aquí, pero espero que lo disfruten.

Algunas notas introductorias: Avito es el servicio publicitario más popular en Rusia. Tenemos más de 450 mil anuncios por día, y la cantidad mensual de visitantes únicos alcanza los 35 millones, lo que hace más de 140 millones de búsquedas por día.
Escenario de búsqueda típico antes
Veamos un ejemplo simple de cómo funcionó una búsqueda hace más de un año. Supongamos que necesita un piano (bueno, ¿por qué no?). Vamos a la página principal, escribimos "piano".
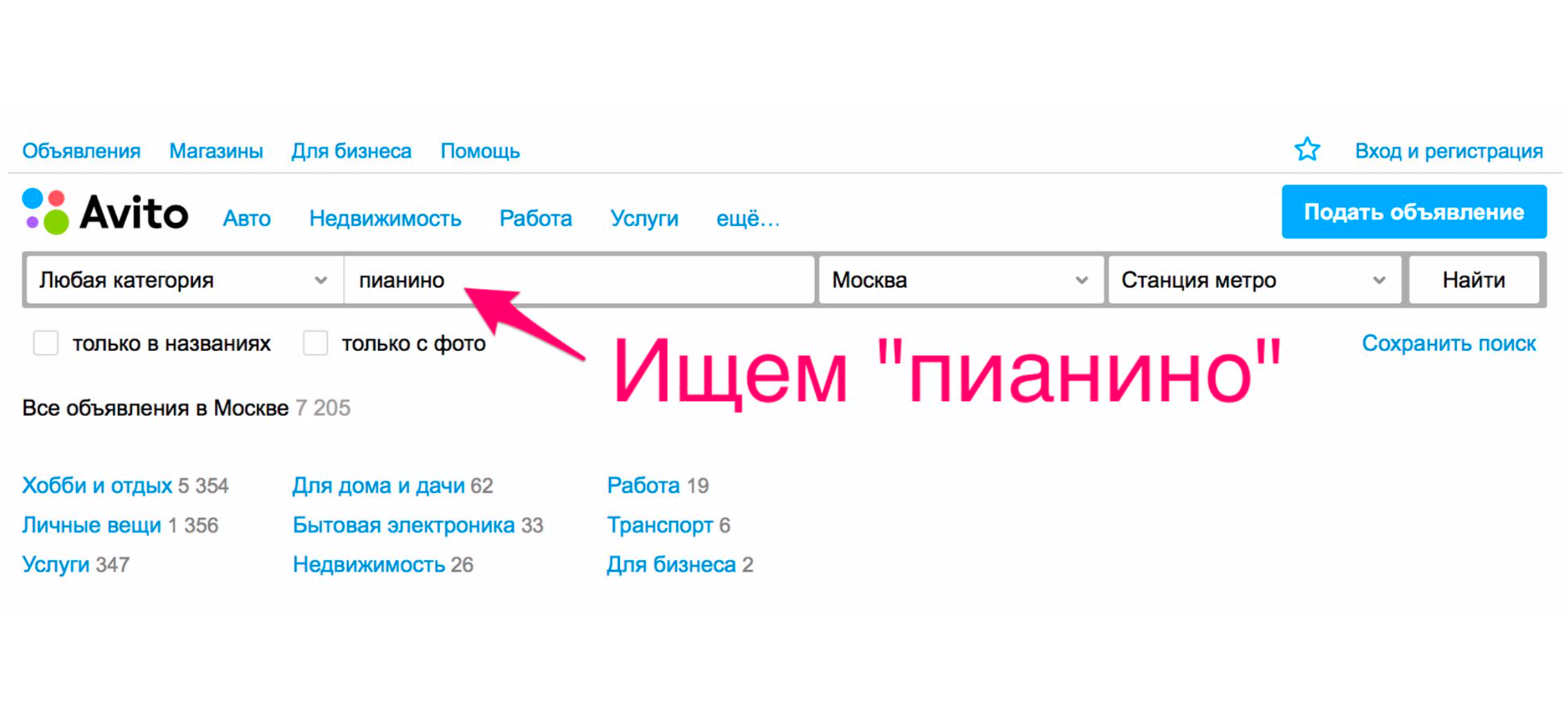
En la extradición, lo más probable es que reciba mudanzas, servicios de transporte de piano o algo similar, pero no un instrumento musical.

Esto sucede porque tendremos que ordenar por la fecha de colocación, y estos servicios se colocan con mayor frecuencia.
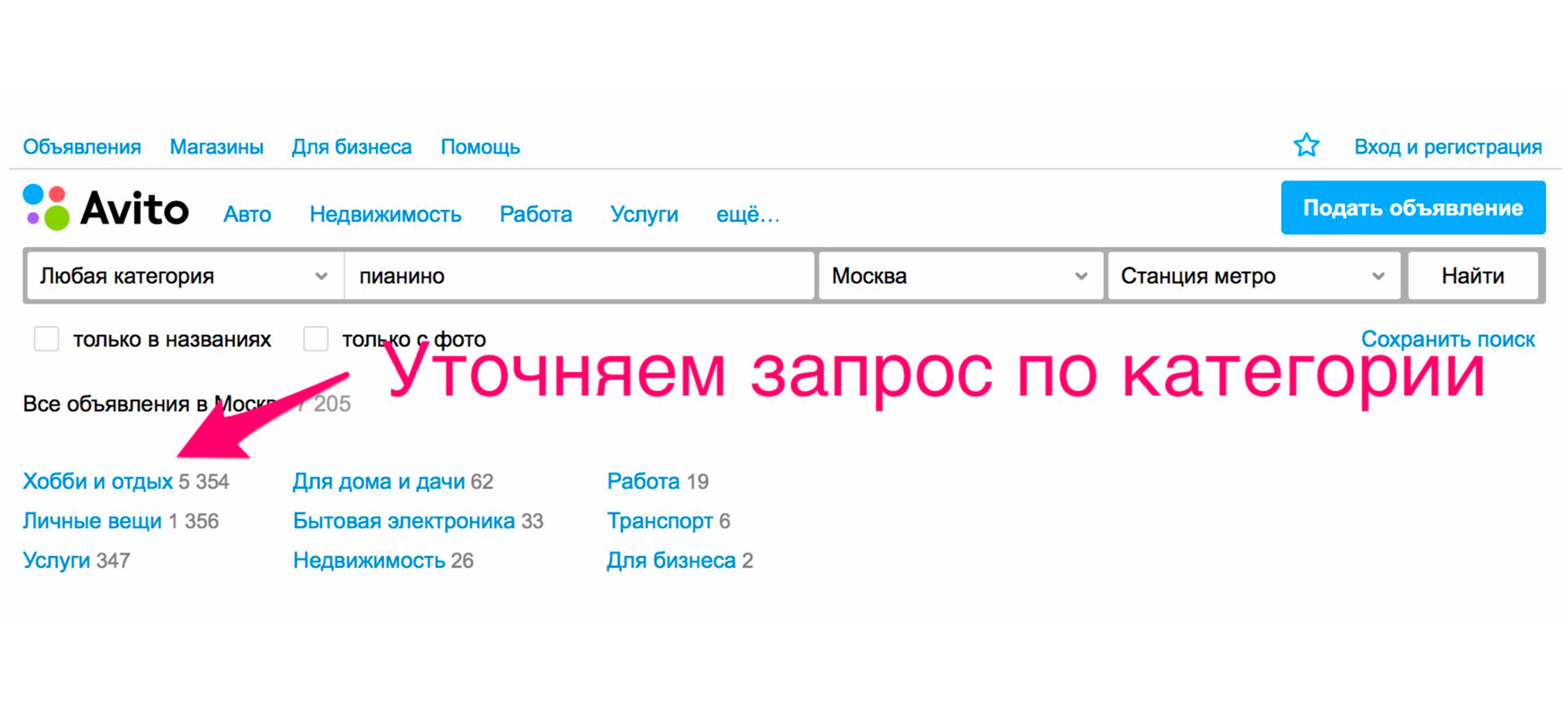
Para ver el piano, debe especificar la categoría. Hacemos clic en el encabezado “Aficiones y tiempo libre”, bajamos en el árbol de categorías a “Instrumentos musicales”, luego “Instrumentos de teclado”.
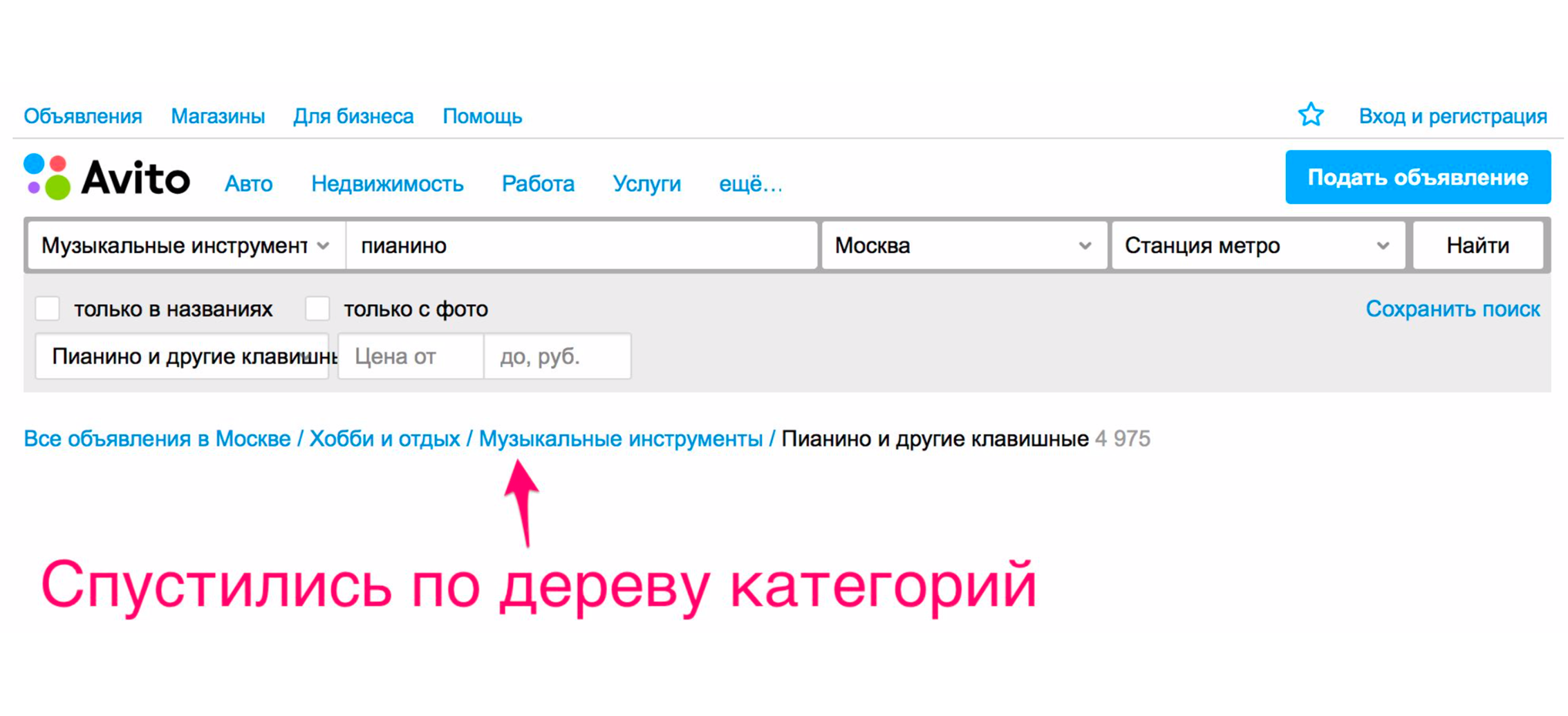
Y solo después de eso vemos el piano que estábamos buscando.
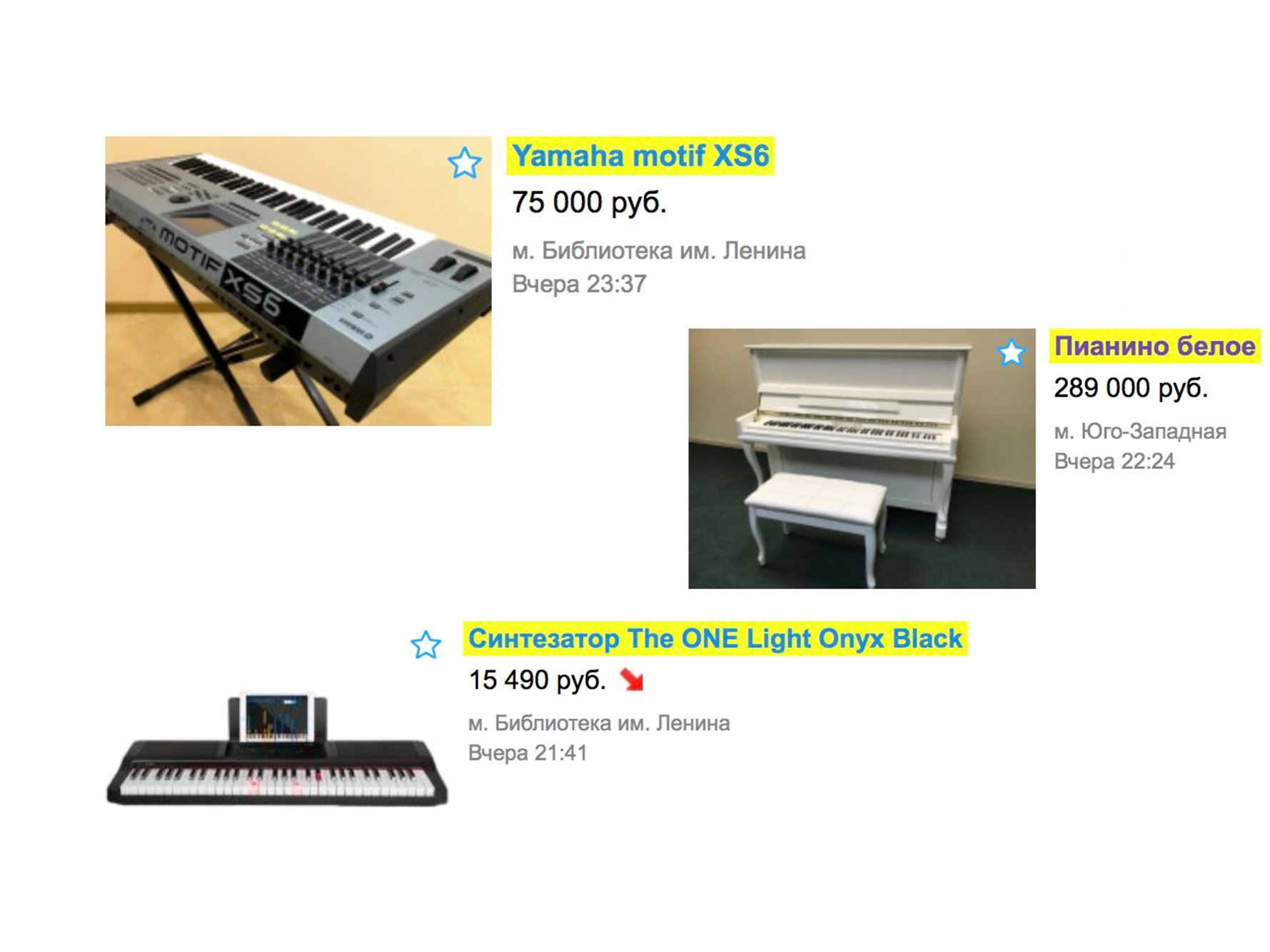
Resulta que, para encontrar el anuncio deseado, había las siguientes opciones:
- refinamiento de la categoría al buscar por palabras clave,
- ordenando por frescura y precio,
- filtros
- busca solo por nombre.
¿Qué ha cambiado debido a la relevancia?
Debido a la relevancia, los anuncios que no se ajustan en absoluto han dejado de incluirse en la emisión. Ahora, si está buscando un piano en la página principal, lo más probable es que no vea los servicios de los cargadores que lo ayudan a transportarlo, pero verá de inmediato el instrumento musical que desea. Al mismo tiempo, se agregó una nueva clasificación: "Por defecto". Está formado por dos indicadores: relevancia del anuncio para la consulta de texto y frescura.

En la parte superior, verá el más reciente de los relevantes.
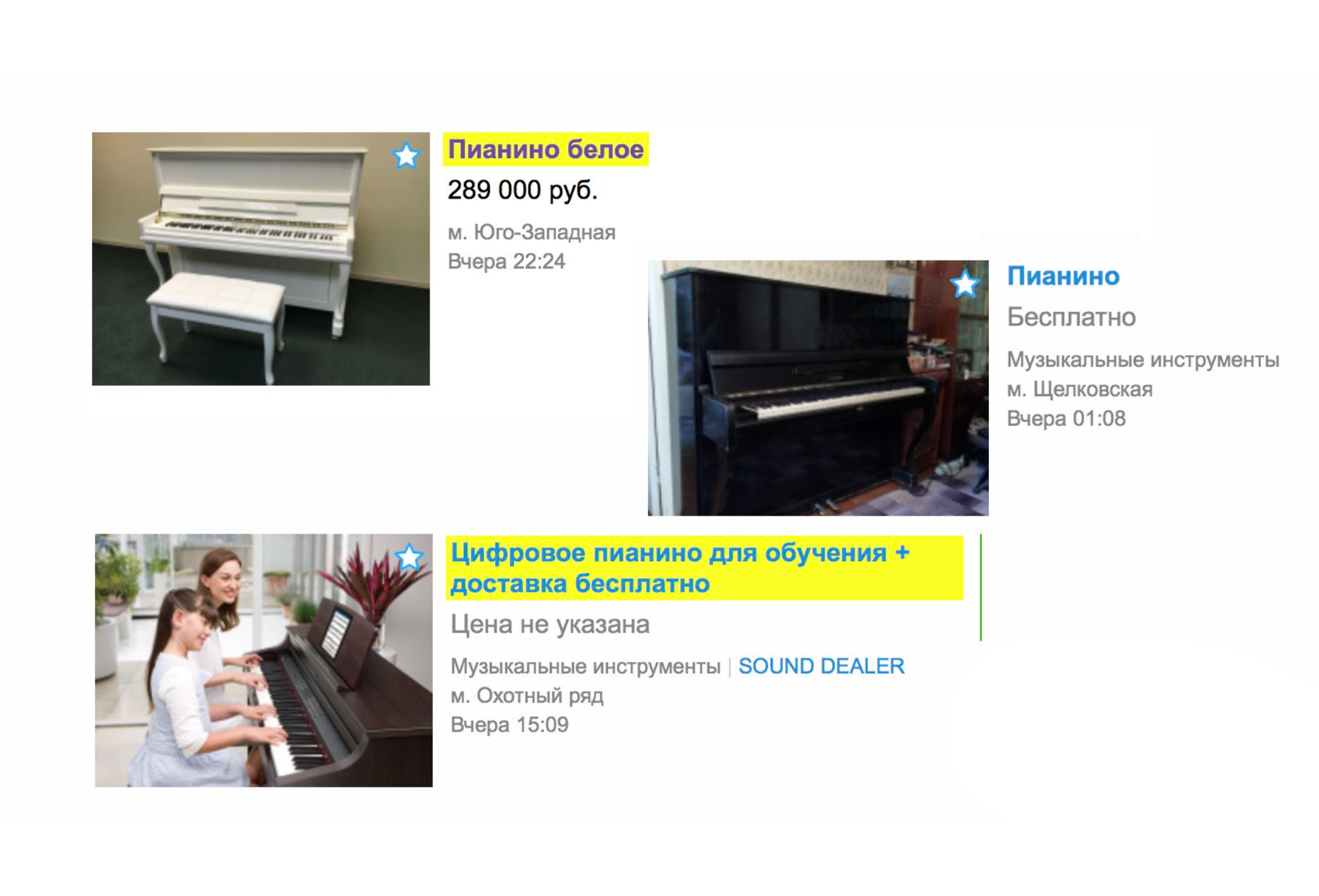
En Avito, por una tarifa adicional, puede subir su anuncio. Y con la introducción de relevancia, las elevaciones remuneradas funcionan de manera más eficiente. Funcionarán, en primer lugar, si su anuncio es relevante para la consulta de texto.
La introducción de relevancia no significa que abandonamos por completo las transiciones al árbol de categorías. Solo para la mayoría de los casos, redujimos el número de clics en el anuncio deseado cuando realizamos búsquedas desde la página principal. Si aún necesita servicios de transporte, aunque acaba de escribir "piano" en la búsqueda, vaya al árbol de categorías y encontrará estos anuncios. La búsqueda también comenzó a funcionar de manera más eficiente y dentro de la categoría, por ejemplo, "Artículos personales" y "Electrodomésticos".
Cómo encontrar el producto correcto en tres clics
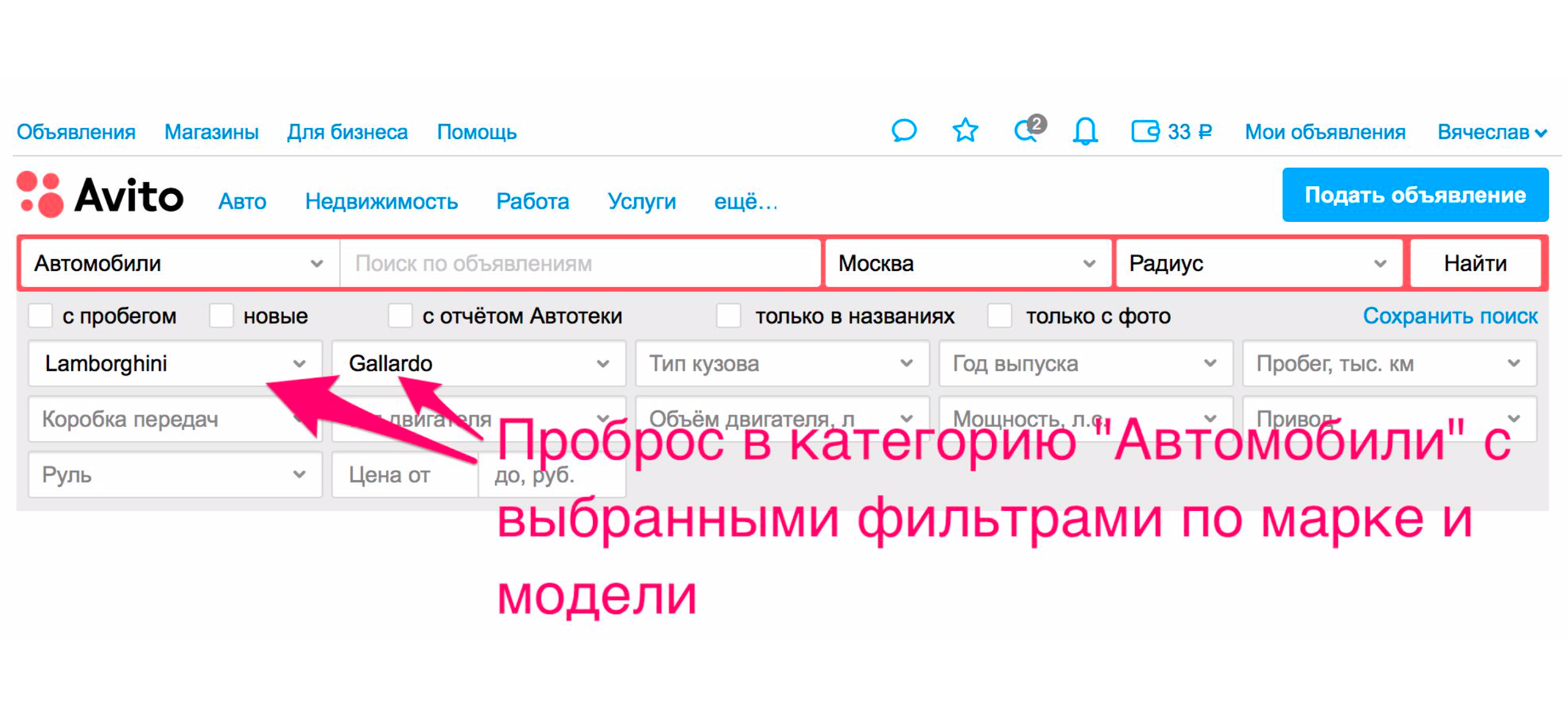
La búsqueda se está volviendo más conveniente para los usuarios no solo debido a la calidad de los resultados de búsqueda. Hay otras formas de mejorarlo. Uno de ellos está reenviando a la categoría. Por ejemplo, estamos buscando Lamborghini Gayardo (sí, te gusta tocar el piano y quieres montar Lamborghini). Para ingresar a la categoría de un automóvil de un modelo en particular, debe hacer dos clics adicionales. Con relevancia, lo más probable es que obtenga lo que desea.
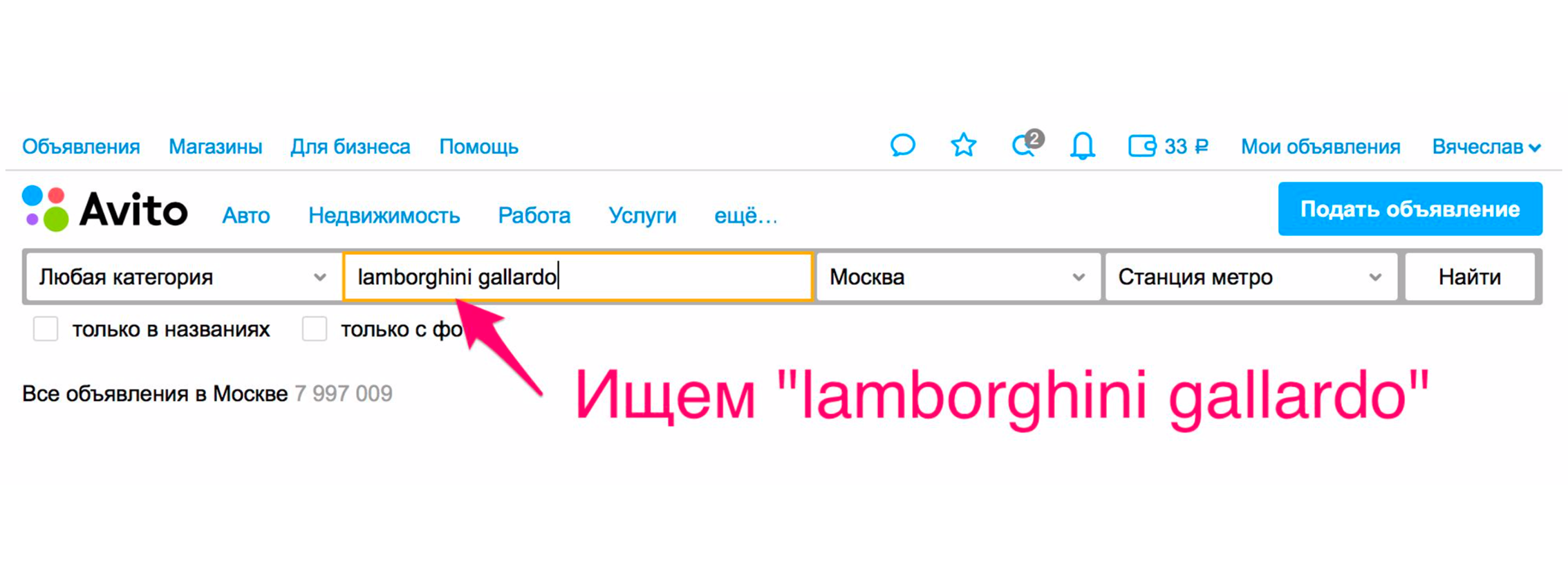
Pero hay un método adicional que lo arrojará inmediatamente a los automóviles. La emisión se reducirá, se seleccionará el automóvil correcto en los filtros y realmente recibirá automóviles en la emisión.

Otra forma es expandir las etiquetas. Por ejemplo, cuando ingresa la palabra "chaqueta", obtendrá pistas.
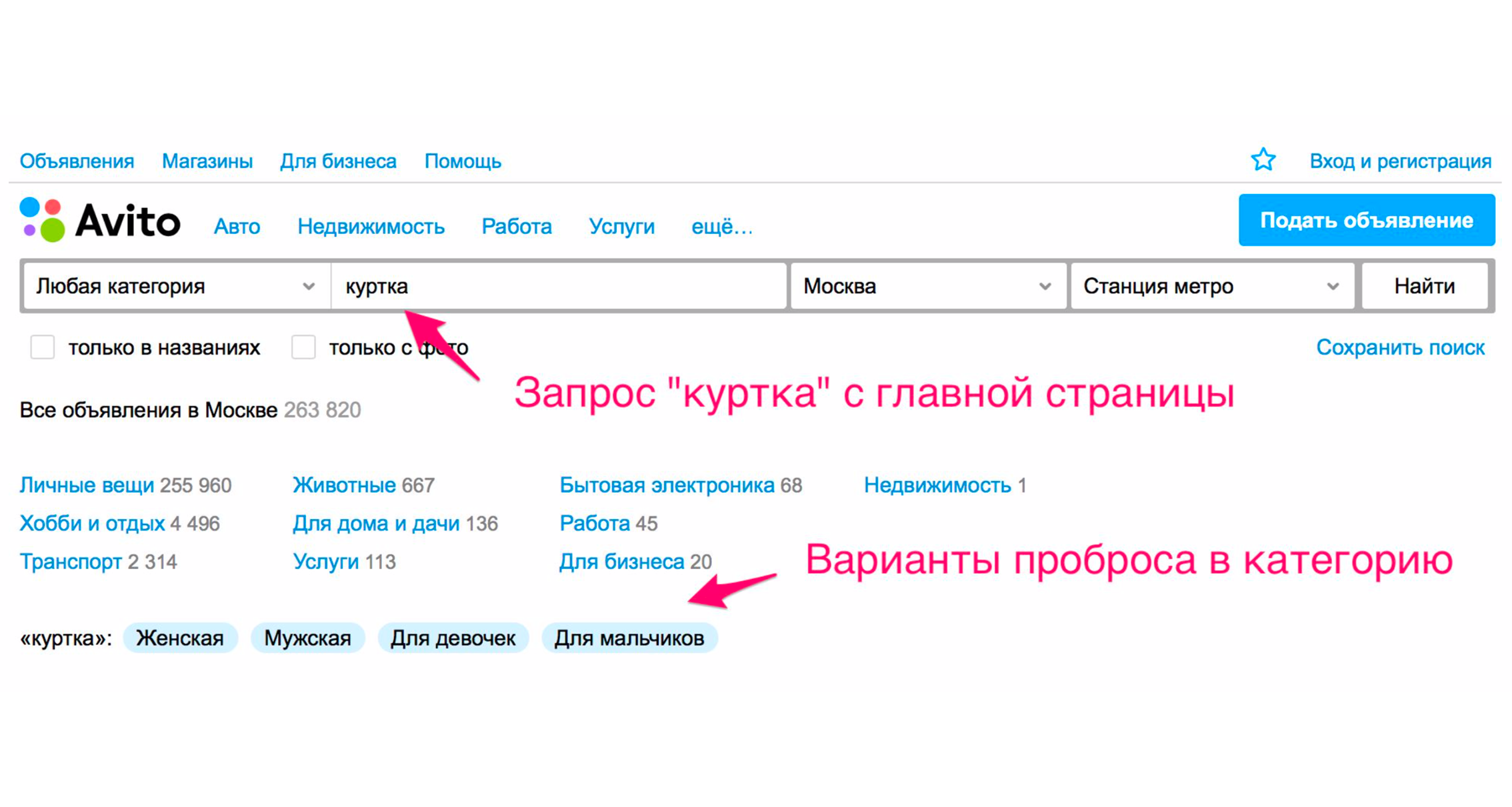
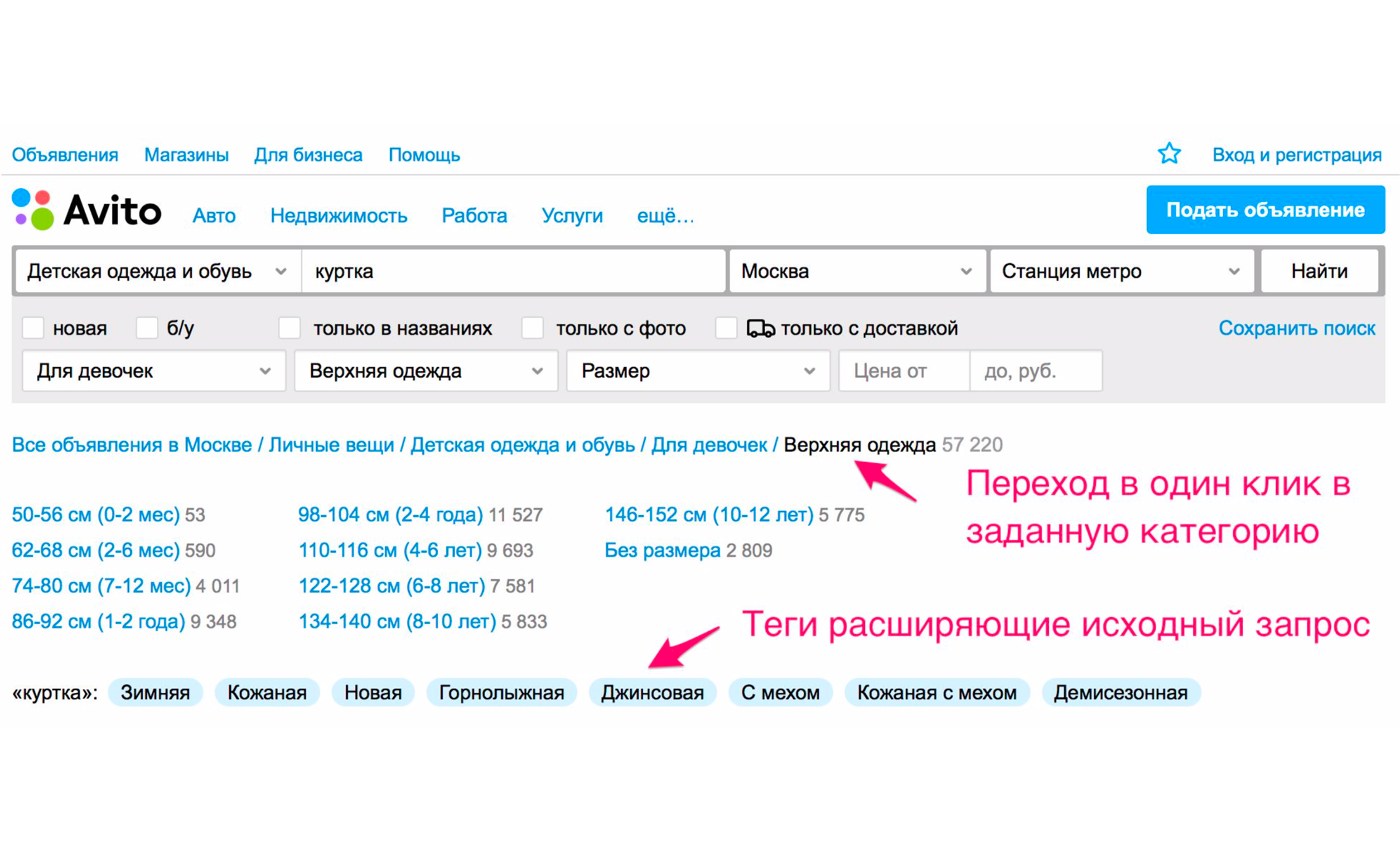
La captura de pantalla anterior muestra los consejos: el tipo de chaquetas: mujeres, hombres, niñas y niños. Si hace clic en "For Girls", inmediatamente entrará en la categoría donde se seleccionarán los filtros apropiados. Aquí también aparecerá un conjunto de etiquetas adicionales expandibles: chaqueta de invierno, cuero, nuevas, etc. Si baja manualmente el árbol de categorías al producto deseado, entonces necesita realizar más acciones.
¿Cuál es la diferencia entre búsqueda y filtros?
Cuando hablé en RIT ++ , el público tenía una pregunta: ¿cuál es la diferencia entre la búsqueda de texto y los filtros? Todo es bastante simple. También puede encontrar el anuncio deseado sin una solicitud de texto bajando el árbol de categorías. En este caso, la búsqueda seguirá encontrando bienes y servicios, no por el texto dado, sino por el conjunto de parámetros pasados de los filtros correspondientes de la categoría seleccionada.
Cada categoría tiene su propio conjunto de filtros. Por ejemplo, en la categoría "Autos" - algunos filtros, en la categoría "Cosas personales" - otros filtros. Es decir, los filtros están rígidamente vinculados a una categoría.
Colocación del anuncio en dos minutos.
Una innovación importante ha aparecido para los vendedores que sienten al enviar su anuncio. Si su anuncio no contiene ningún "prohibido" o no es un duplicado, el buen anuncio habitual, lo verá en la publicación casi de inmediato. En realidad, este retraso dura aproximadamente dos minutos, pero en casos excepcionales puede extenderse hasta 30 minutos. Anteriormente, un anuncio siempre aparecía en el sitio solo después de media hora.
Asistente Avito
Avito Helper es una extensión para Chrome que muestra el precio de un producto similar en Avito en sitios de terceros. En la extensión, puede comparar los precios en muchas tiendas en línea con los precios de Avito o simplemente buscar los bienes y servicios necesarios en nuestro servicio sin ir directamente al sitio web o la aplicación. Pudimos implementar el "Asistente", incluso gracias a los nuevos cambios de infraestructura.

Arquitectura
Serrar un monolito
Avito tiene un monolito en PHP. Hace un año, toda la funcionalidad de búsqueda que funciona en Avito estaba en este monolito. La búsqueda en el monolito funcionó con cuatro plataformas: Android, iOS, la versión móvil en el navegador y el escritorio. Para dar el resultado, las consultas SQL correspondientes se generaron en Sphinx dentro de este código, el procesamiento estaba en curso y el resultado se envió en formato JSON o HTML. Luego, los usuarios vieron lo que estaban buscando.
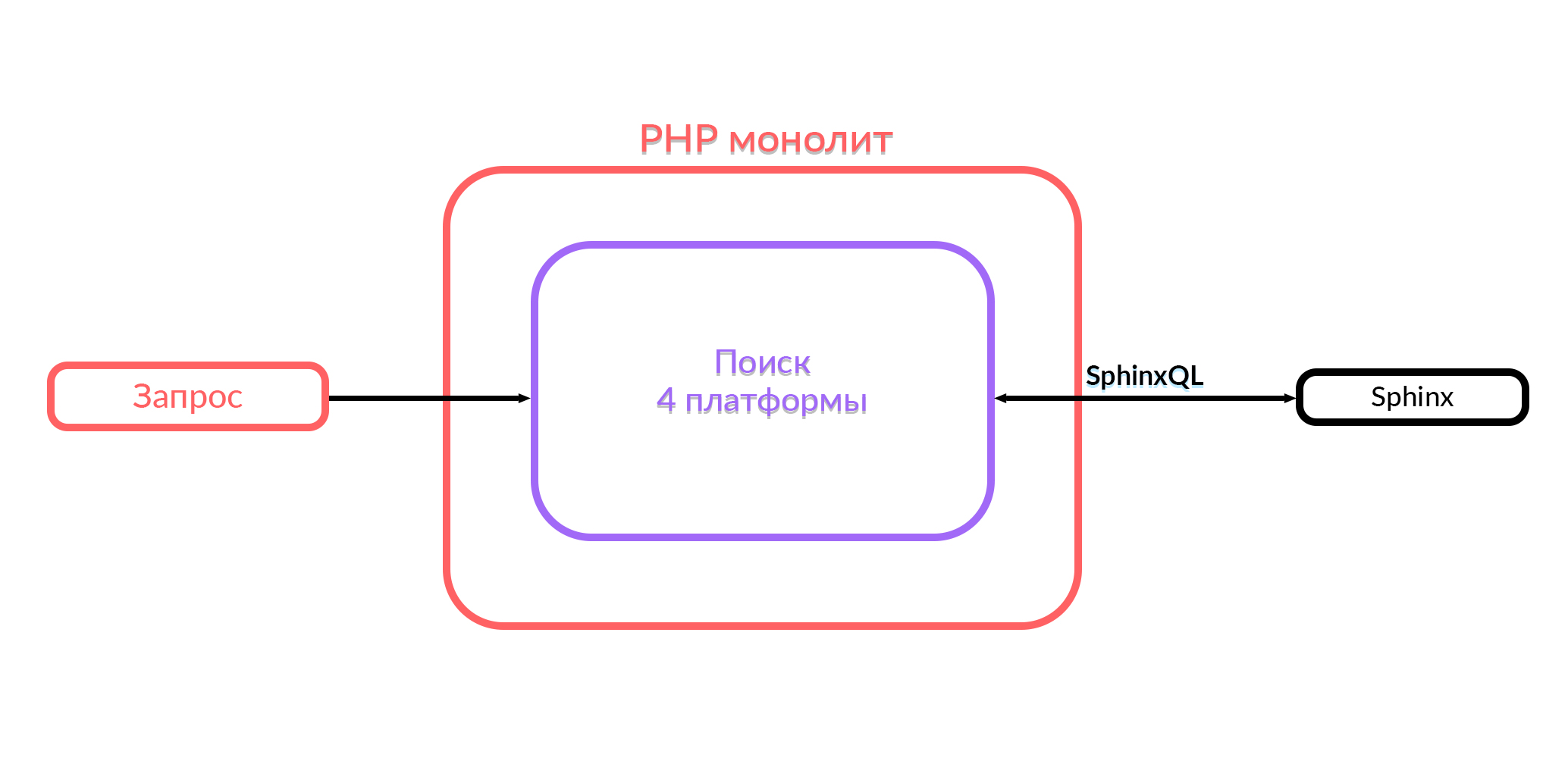
Lo que tenemos ahora
Si implementa nuevas funciones, es muy difícil integrarse con este monolito. Por lo tanto, decidimos desarrollar un servicio de búsqueda, al que llamamos "Búsqueda". Ahora el monolito va a este servicio de búsqueda, y el servicio va a Sphinx.

Razones para crear un servicio de búsqueda.
Al desarrollar servicios, siempre debe comprender por qué está haciendo esto. La primera ventaja obvia es la eliminación de la lógica de bajo nivel. En nuestro caso, esto está ocultando la cocina para procesar consultas SphinxQL. Además, podemos proporcionar más fácilmente la funcionalidad de búsqueda a sistemas de terceros.
Consulta asíncrona de ejecución. Esta ventaja es bastante obvia y dependiendo de la implementación, se puede lograr uno u otro éxito. Nuestro servicio se implementó en Golang, y había una funcionalidad que se podía paralelizar: tres solicitudes en Sphinx, lo que resultó en buenos resultados.
Despliegue rápido. Hemos identificado una funcionalidad separada con menos código, pruebas adicionales (el monolito tiene muchas pruebas, no solo la funcionalidad de búsqueda), y es más fácil de implementar. Lo que es más importante, debido a un enfoque exitoso para la implementación de este servicio, pudimos reducir cosas interesantes e implementar algoritmos de clasificación avanzados, para hacer un procesamiento bastante complicado que no podríamos hacer en un monolito. Esto nos proporciona una base muy buena para experimentar con la calidad de búsqueda.
Como beneficio adicional, tenemos la oportunidad de cambiar de Sphinx a Elastic, porque la lógica de bajo nivel ahora está oculta.
Este diagrama ya muestra el caso cuando hay un monolito, el servicio "Búsqueda" y el servicio de terceros "Avito Assistant".
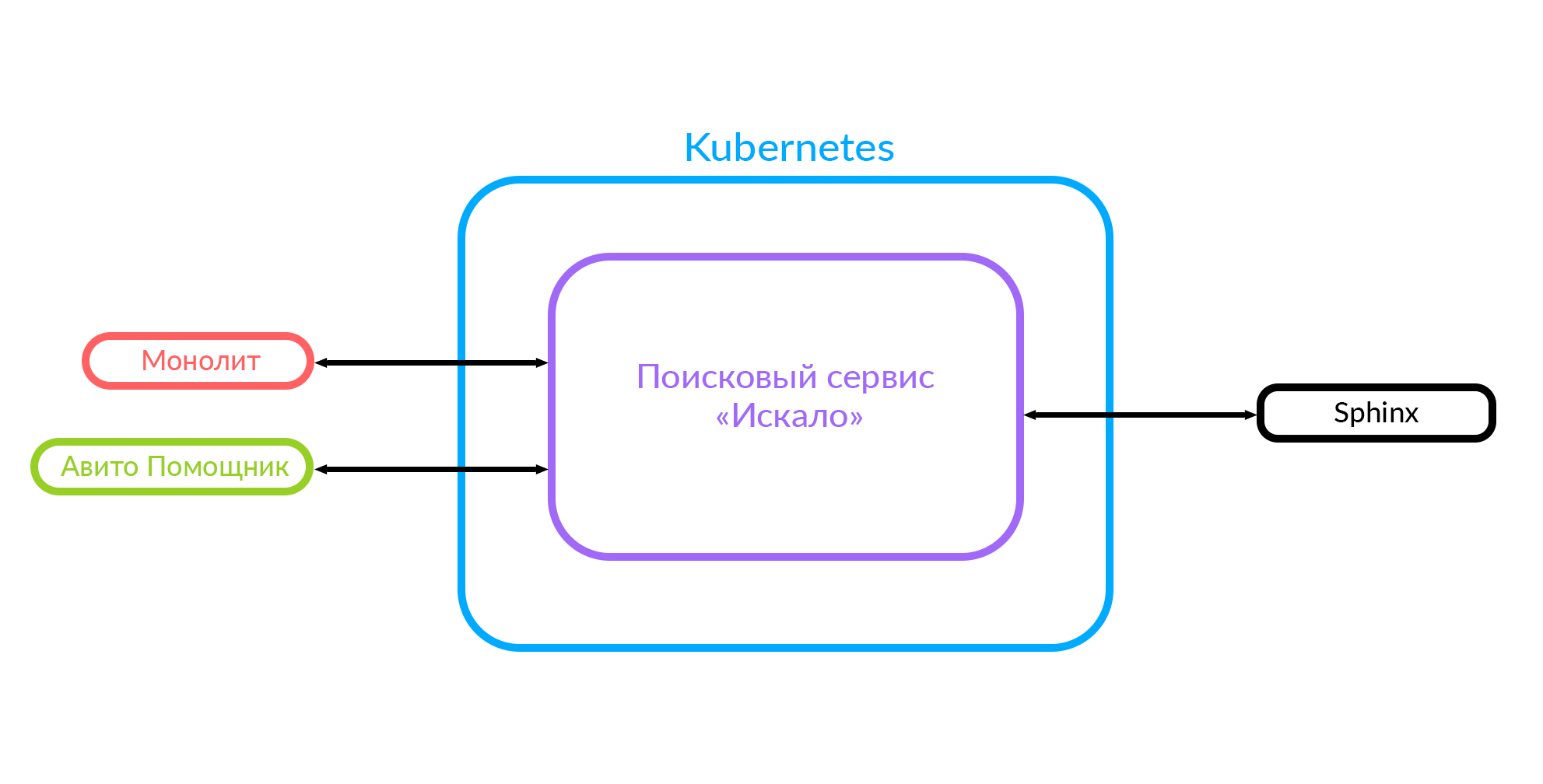
¿Cómo funciona un servicio de búsqueda?
Tiene un conjunto de agregadores. Cada agregador realiza una cierta lógica comercial relacionada con el procesamiento de la emisión. Él puede formar este problema de cierta manera.
La solicitud llega al planificador. El planificador selecciona el agregador de acuerdo con los criterios de consulta en términos de sus parámetros (o si el agregador deseado se especifica en la solicitud). El agregador va a Sphinx. Después de recibir una respuesta de Sphinx, genera una salida y le da la respuesta al cliente.

En este caso, la solicitud estaba fuera, no desde la nube en la que funciona nuestro servicio de búsqueda. Pero también es posible otra opción: algunos de nuestros servicios, dentro de la nube, por ejemplo, Avito Assistant, recurren a un servicio de búsqueda. Esta solicitud ya va a otro agregador: hay otra lógica de negocios. Así es como funciona:
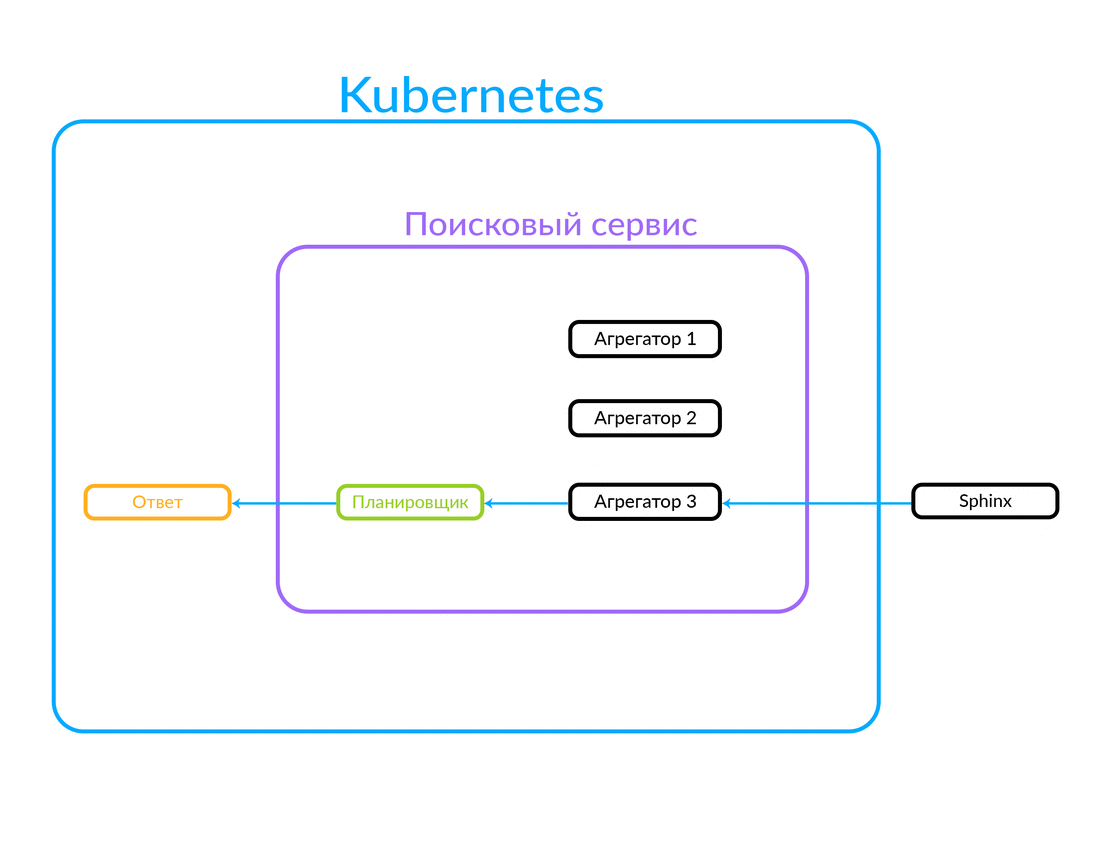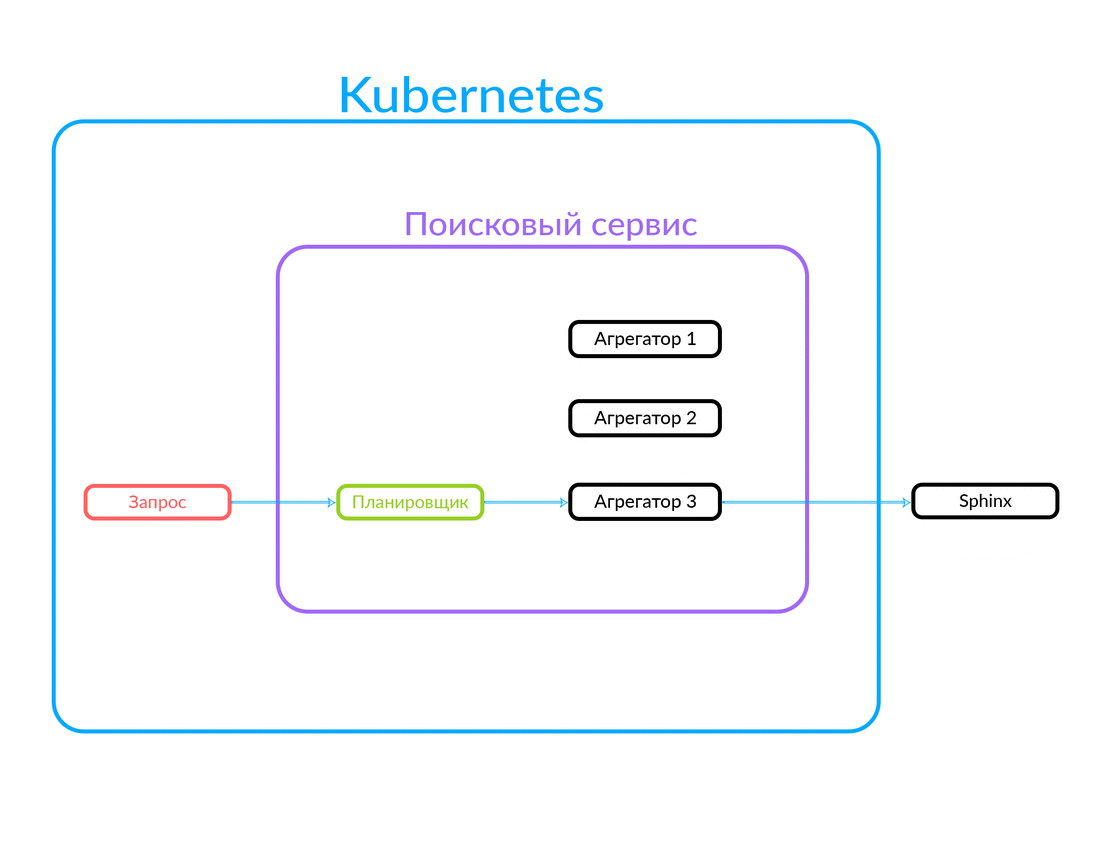
Cómo funciona la ejecución de consultas asíncronas en el agregador
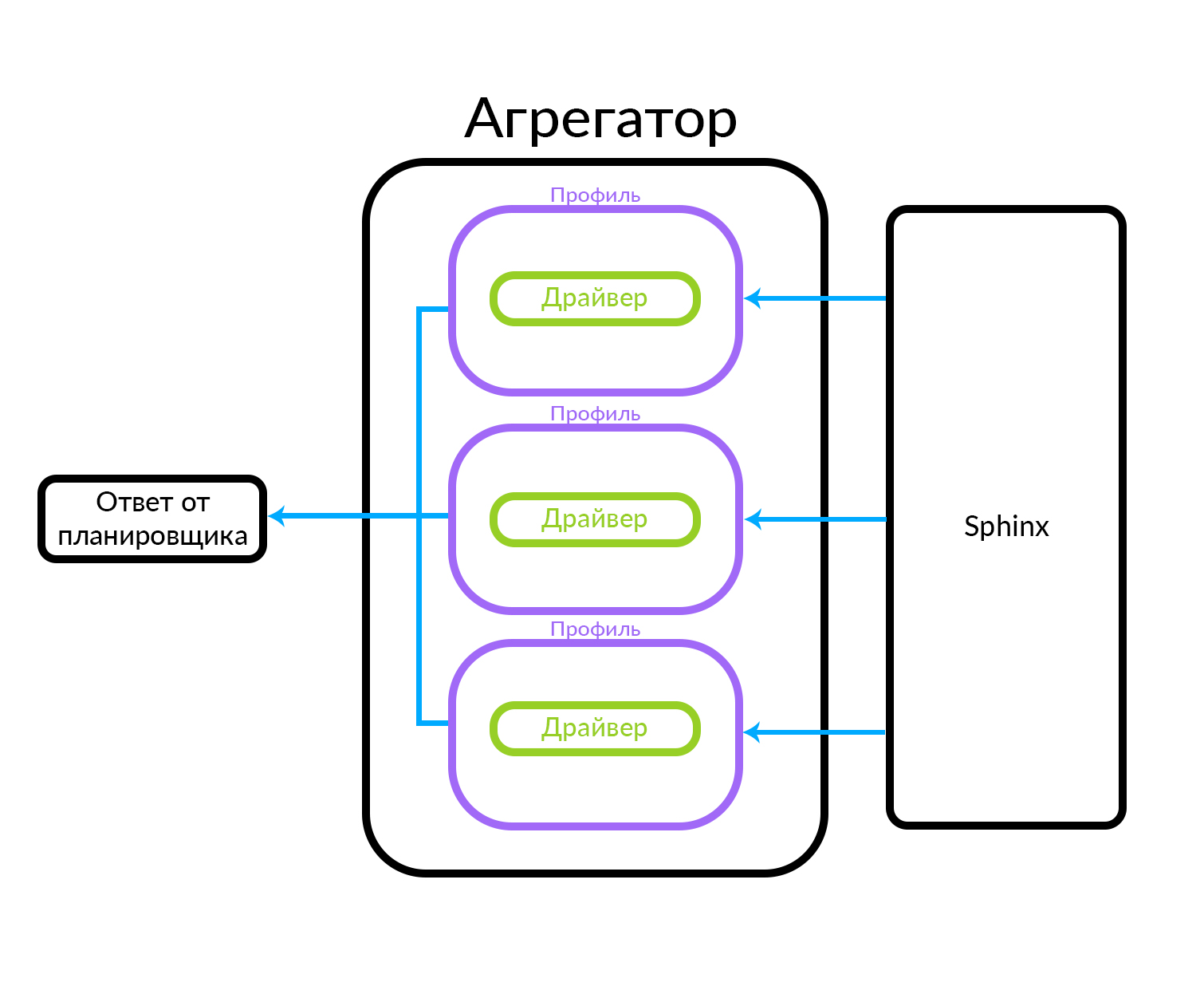
El agregador consta de varios perfiles. Un perfil es, en términos generales, una entidad en la que puede obtener un anuncio de algún tipo o de alguna manera específica. Por ejemplo, esto puede explicarse a través de una analogía: hay anuncios "Premium", "VIP" y regulares en Avito. El agregador recibe una solicitud del planificador, mientras que las solicitudes paralelas se ejecutan para el conjunto de perfiles conocidos en el agregador. El perfil tiene un controlador en su interior que accede físicamente al nivel subyacente, en este caso en Sphinx, pero puede ser cualquier otra fuente de datos
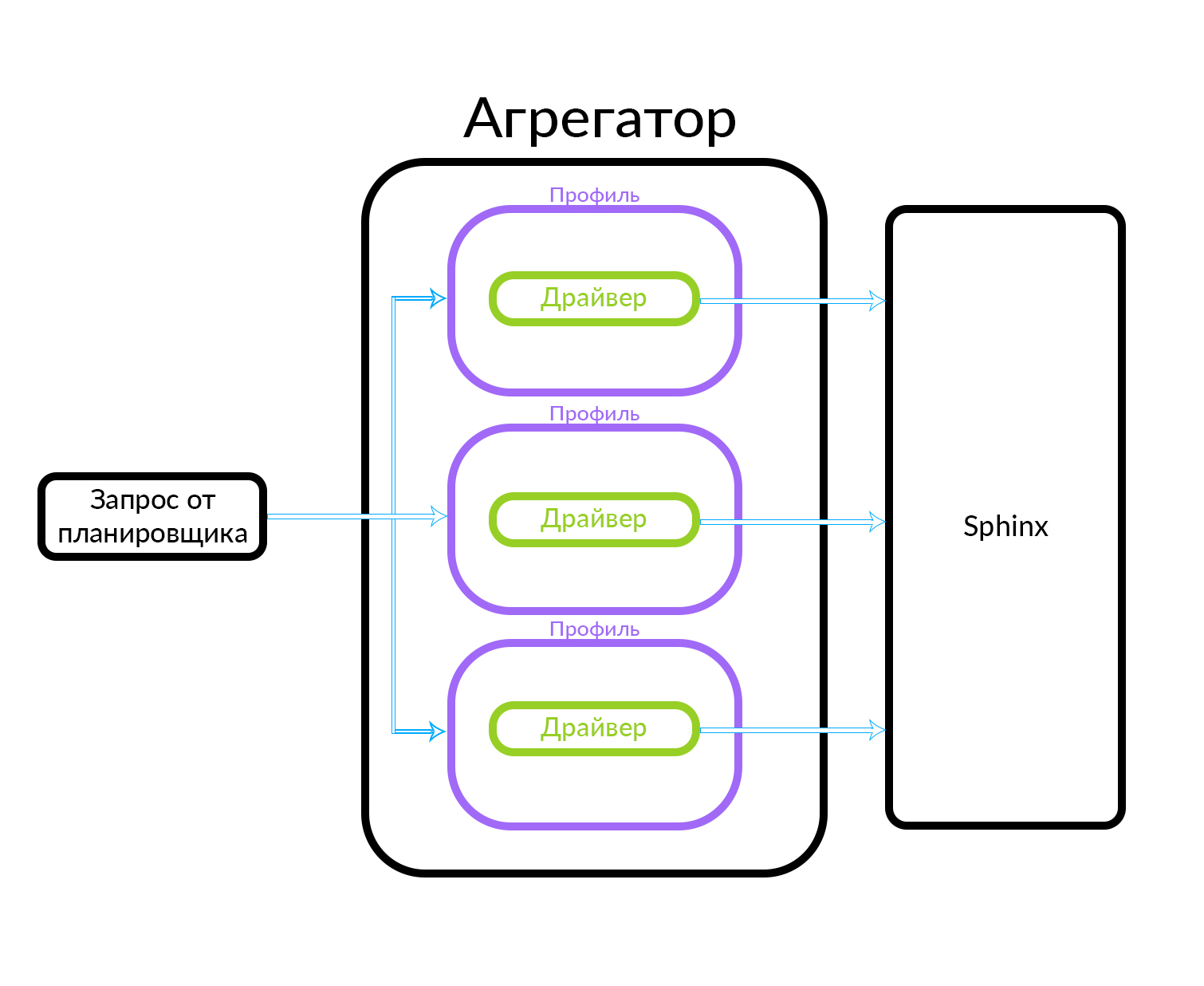
El agregador puede simplemente dar al planificador los resultados de las consultas a los perfiles, y también puede realizar acciones más complejas, por ejemplo, mezclar estos resultados usando uno u otro algoritmo.
Buscar índice de almacenamiento
Debido al hecho de que utilizamos Kubernetes en la arquitectura, en RIT ++ se me hizo una pregunta sobre el almacenamiento del índice de búsqueda: ¿está almacenado en Kubernetes? No, tenemos a Sphinx viviendo en máquinas físicas. En Kubernetes, estamos implementando un servicio de búsqueda que procesa la lógica de búsqueda. La nube también contiene un índice de búsqueda de muestra para el entorno de desarrollo en el que se ejecutan las pruebas, pero no es deseable colocar un índice de combate allí, porque los servicios que funcionan en Kubernetes son, en primer lugar, servicios sin estado.
Servicio de búsqueda de carga
Ahora este servicio está en batalla, sirve el 100% de la carga con algunas excepciones. La carga que tiene es de aproximadamente 200 krpm. Retardo: mediana - hasta 17 ms, percentil 95 - hasta 120 ms, percentil 99 - hasta 320 ms.
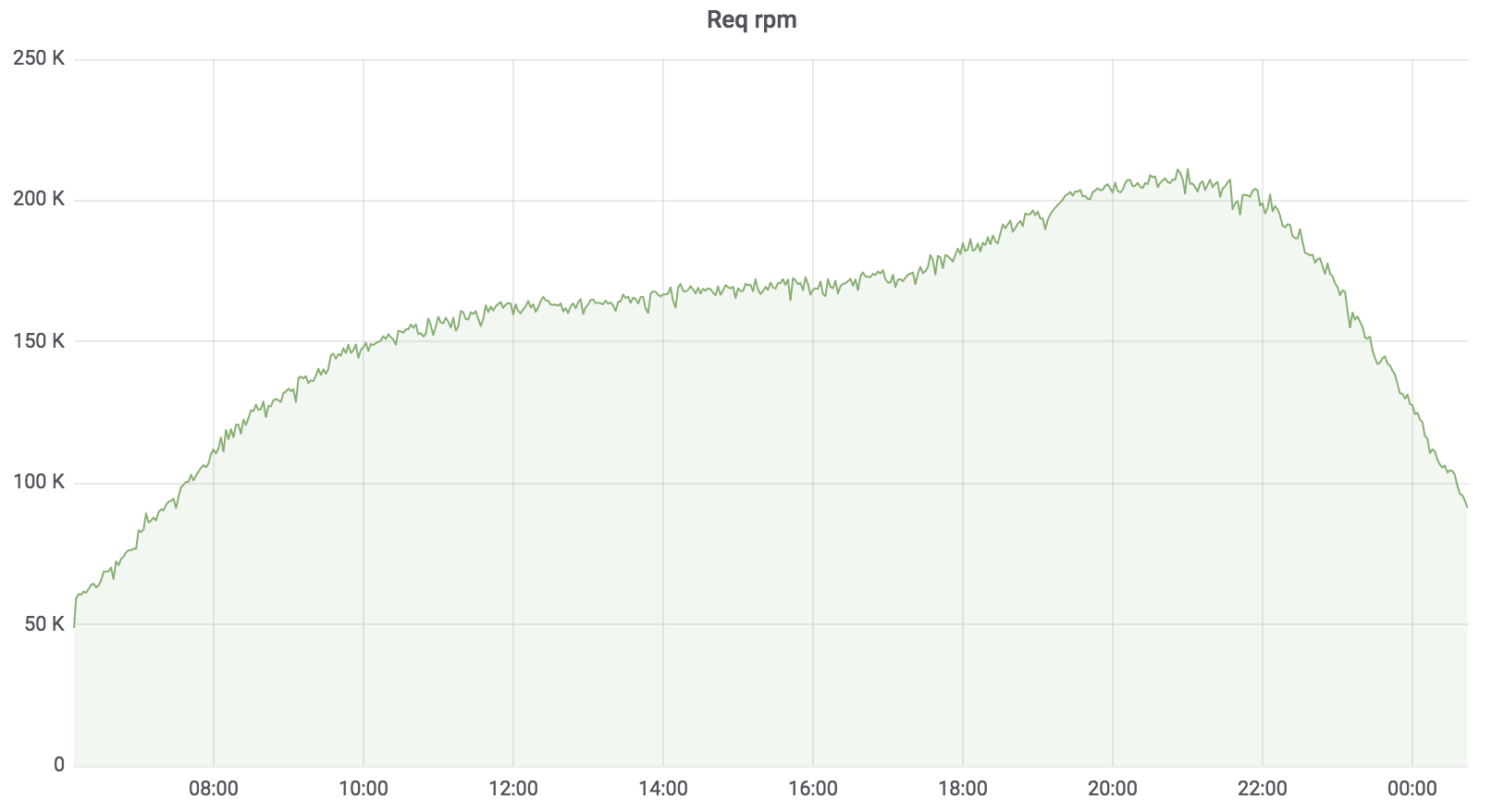
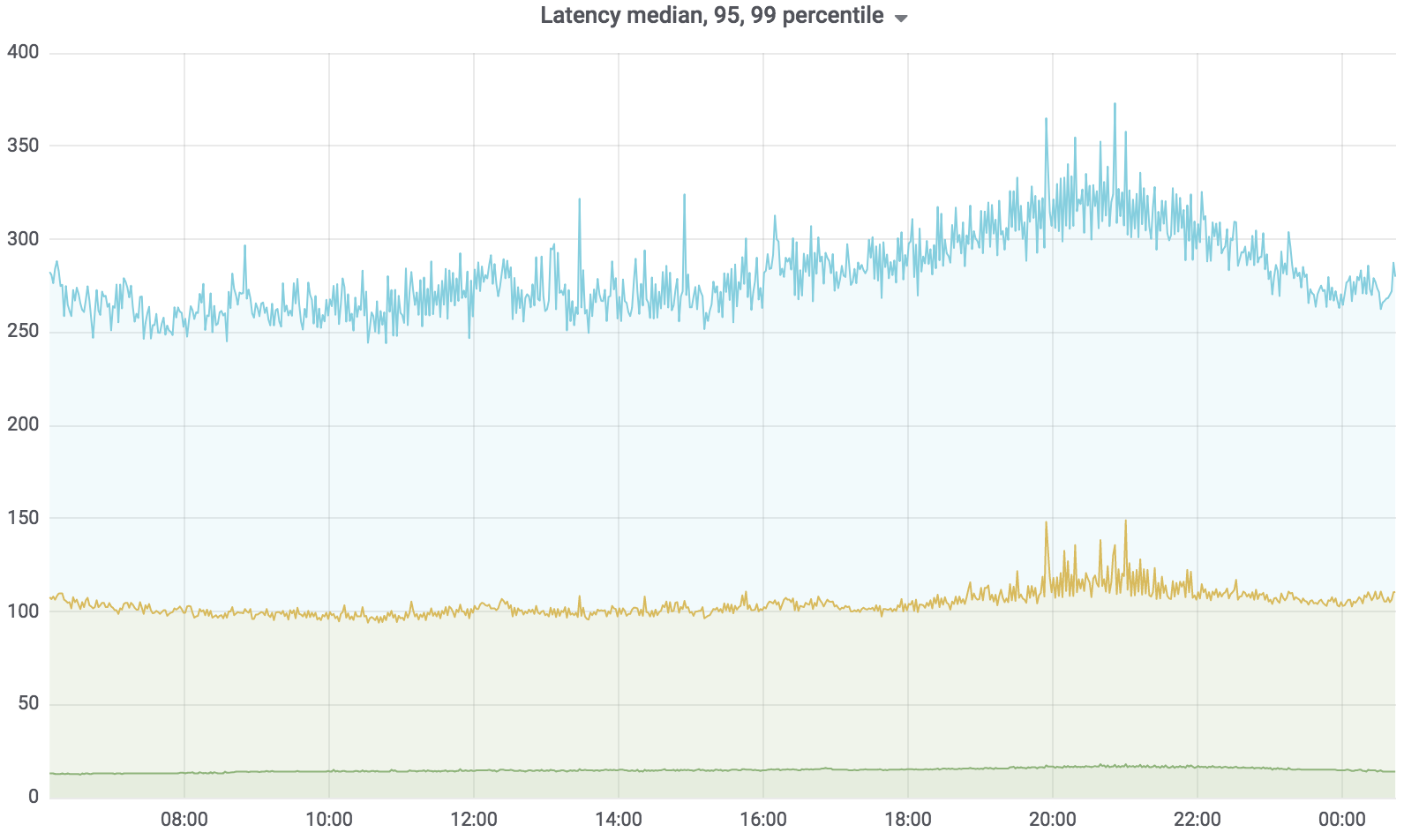
Servicio de búsqueda total
El servicio de búsqueda está escrito en Golang, implementado en Kubernetes, el agregador funciona de forma asíncrona con varios perfiles. El perfil funciona con el controlador especificado, el controlador accede a la fuente de datos especificada, por ejemplo, Sphinx. La cantidad de solicitudes que atiende nuestro servicio es de hasta 200 krpm en este momento. Retardo: mediana - hasta 17 ms, percentil 95 - hasta 120 ms, percentil 99 - hasta 320 ms.
Implementación del servicio en un sistema de trabajo.
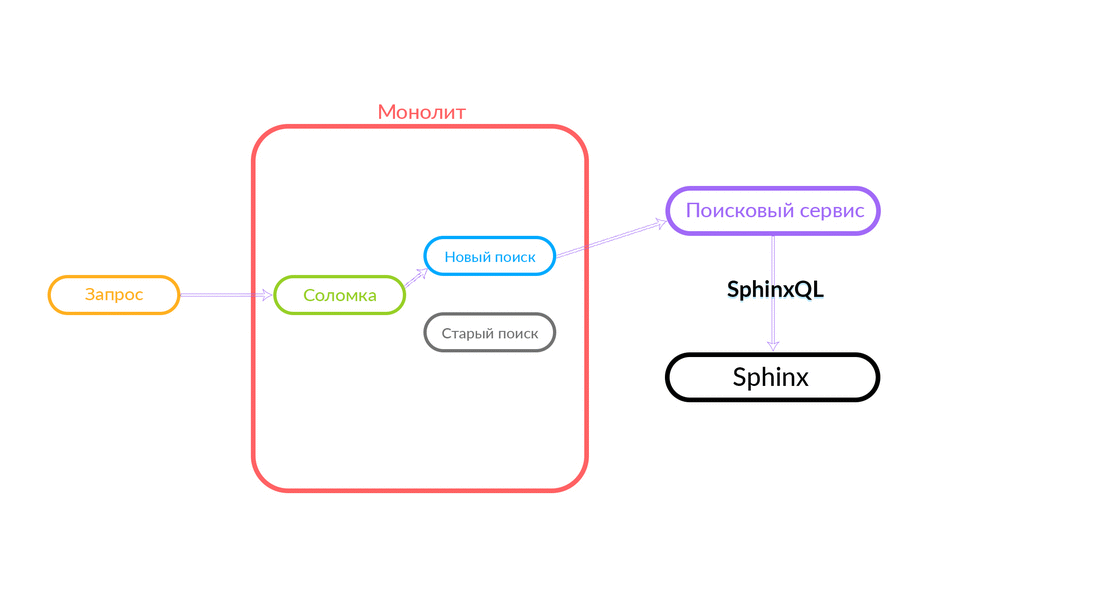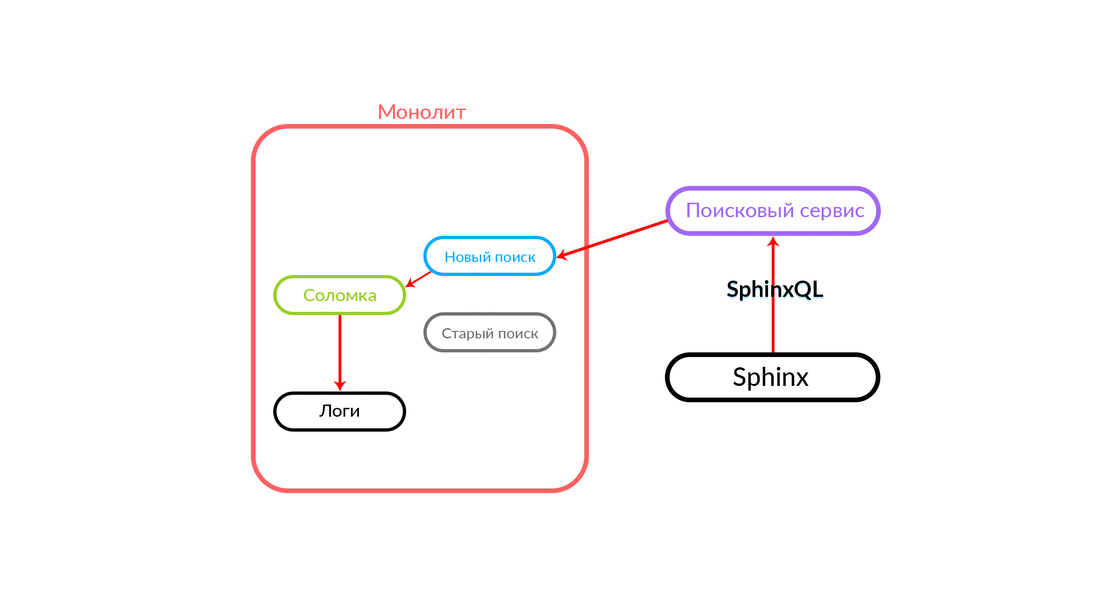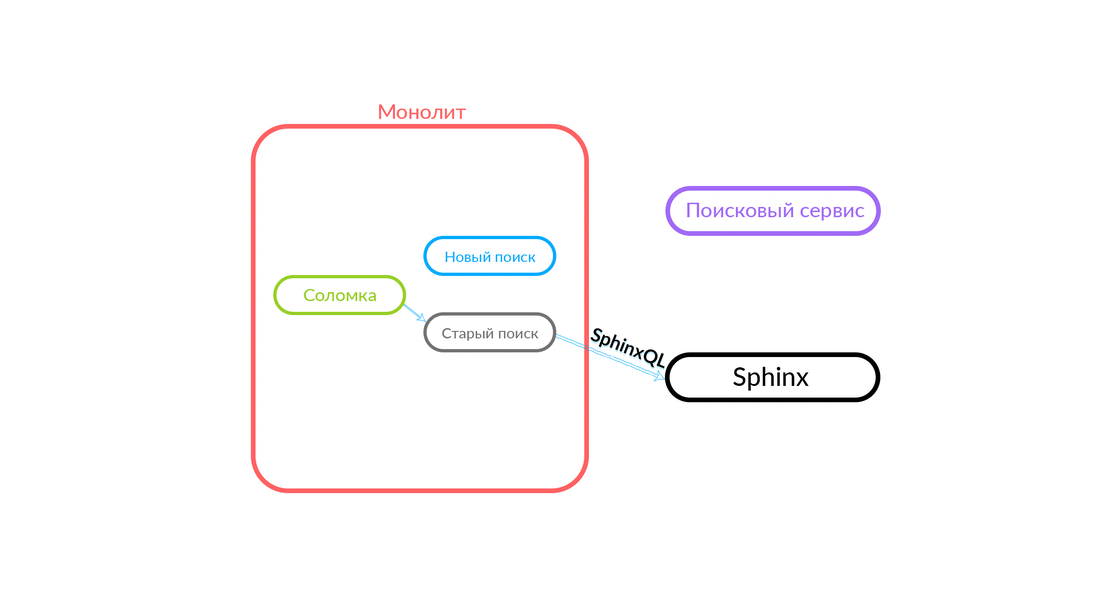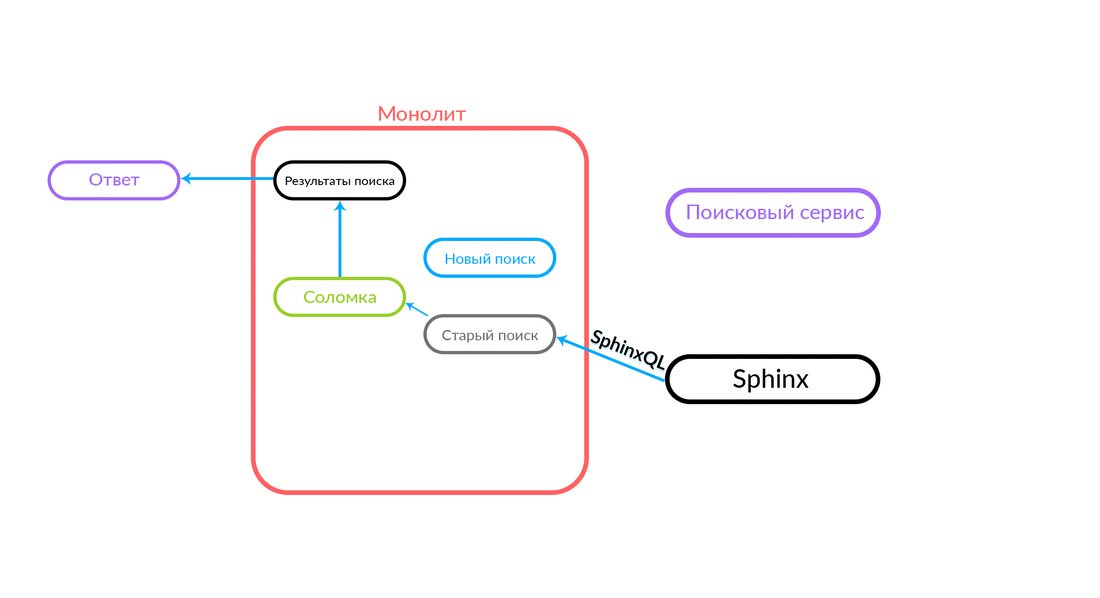
El problema de la doble funcionalidad es bastante obvio, tenemos que admitir dos bases de código que deben realizar la misma tarea. Necesitamos una reserva. Lo llamamos "pajitas", recordamos sobre "pajitas". Además, necesitamos control de tráfico, es deseable que sea rápido, a través de un tablero de instrumentos.
¿Cómo funciona la "paja"
La consulta de búsqueda llega a la "Paja", que funciona dentro del monolito y puede realizar una nueva llamada a una nueva búsqueda o una antigua. Ella llama a una nueva búsqueda, él la cumple y, si tiene éxito, solo obtenemos el resultado de una nueva búsqueda.
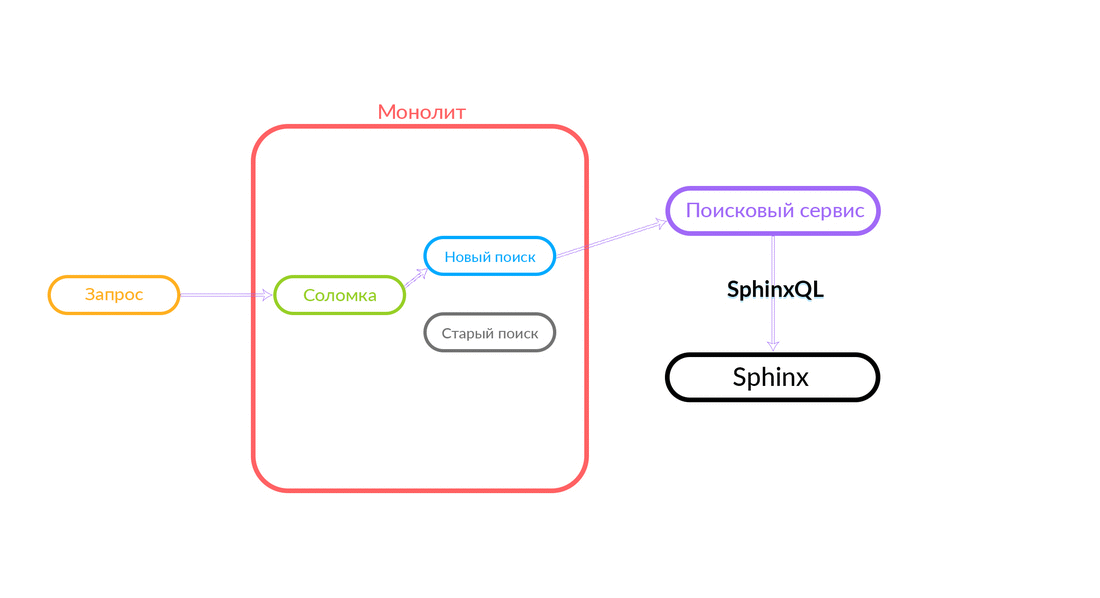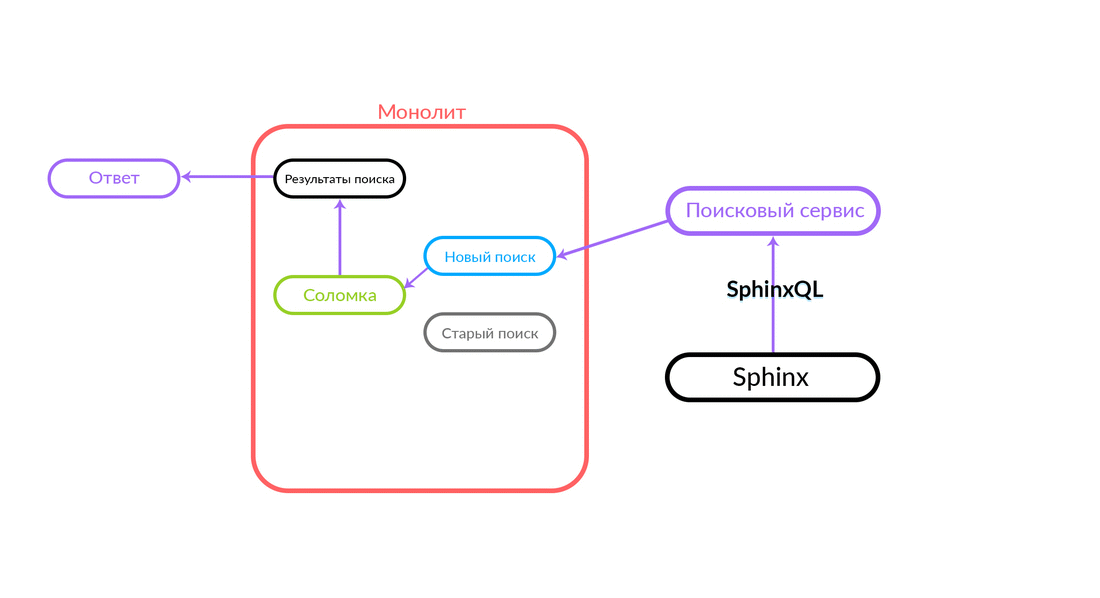
Hay situaciones en las que falla alguna consulta al servicio de búsqueda: por ejemplo, y hasta que se implementa algún tipo de funcionalidad dentro del servicio de búsqueda. Luego, necesariamente prometemos dicha solicitud: "The Straw" la ejecutará en la búsqueda anterior. La búsqueda anterior del monolito se convertirá en Sphinx, y la respuesta irá al cliente. El cliente no sentirá nada.
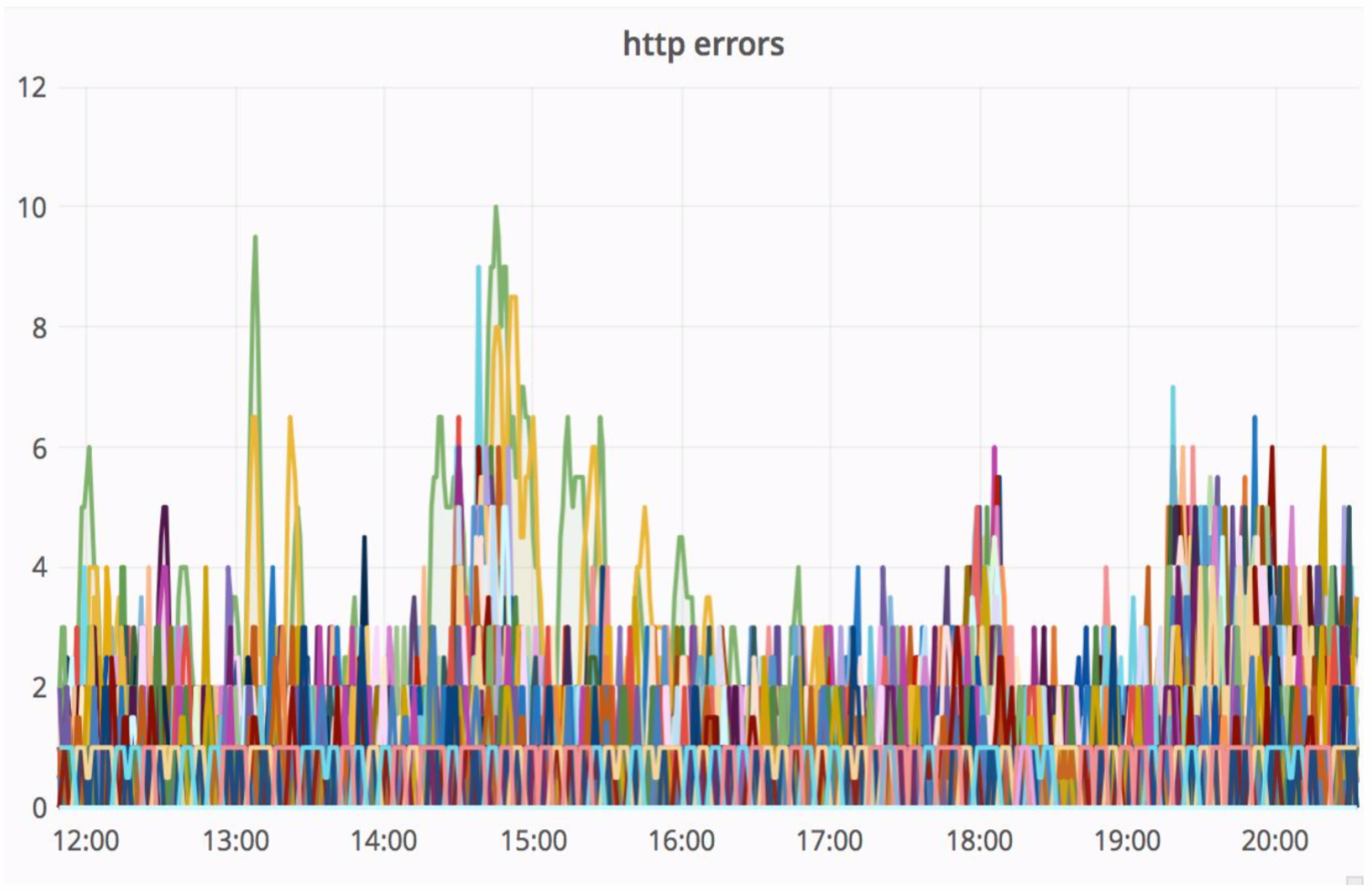
Un esquema bastante confiable, y siempre es interesante ver lo que sucede en la práctica. El Departamento de Arquitectura de Avito está mejorando constantemente nuestra nube, afinando, haciéndola más confiable y productiva. En algún momento, hubo problemas que al dar servicio a uno de los nodos con una intensidad suficientemente alta, los errores provenían del monolito (100 errores por segundo).

Al mismo tiempo, el retraso del servicio aumentó considerablemente: en la imagen a continuación puede ver los picos.
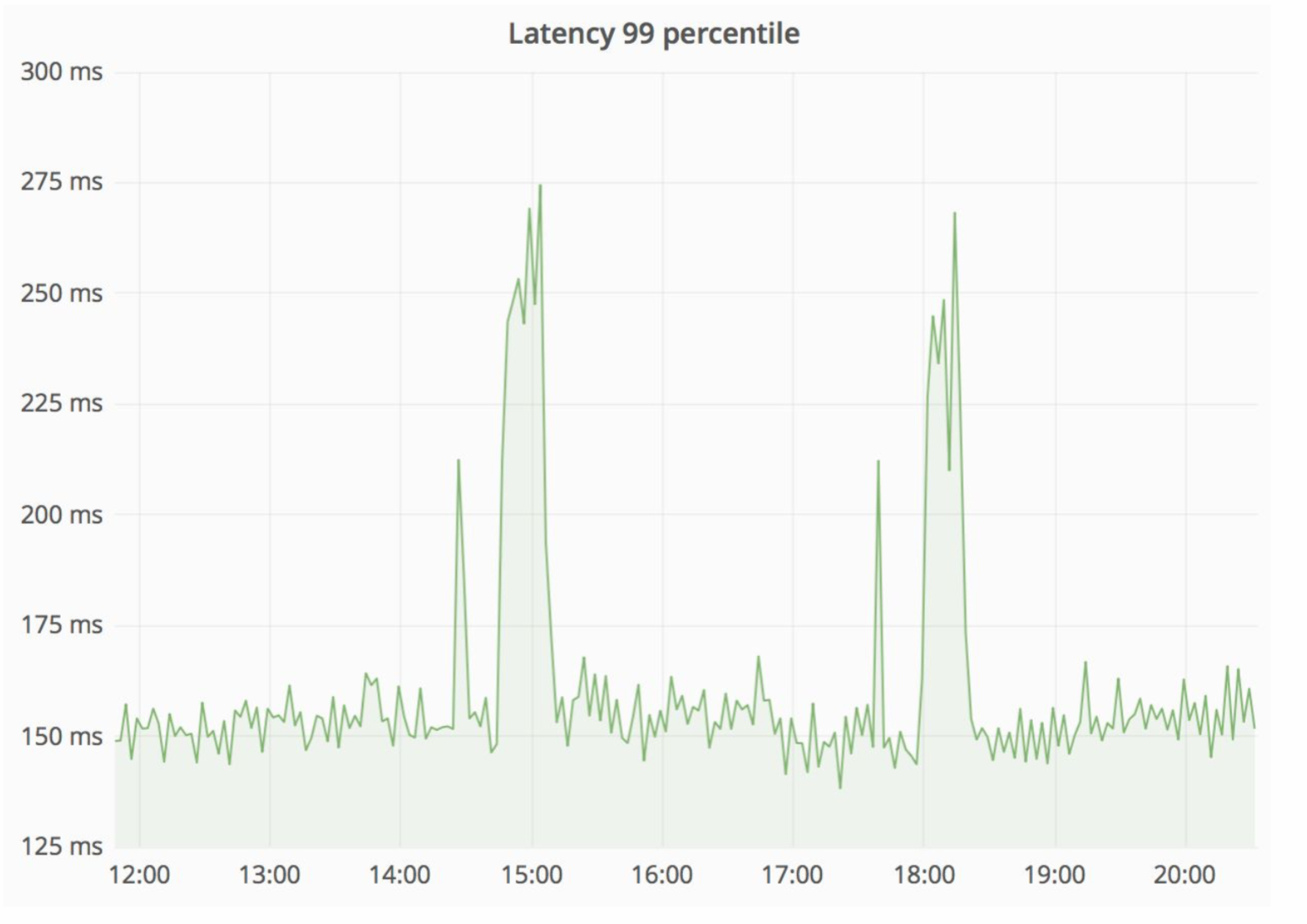
La "gota" resolvió esta situación notablemente, y los errores HTTP resultantes estaban al mismo nivel, una unidad de errores para todo el Avito. Nuestros visitantes no notaron nada.
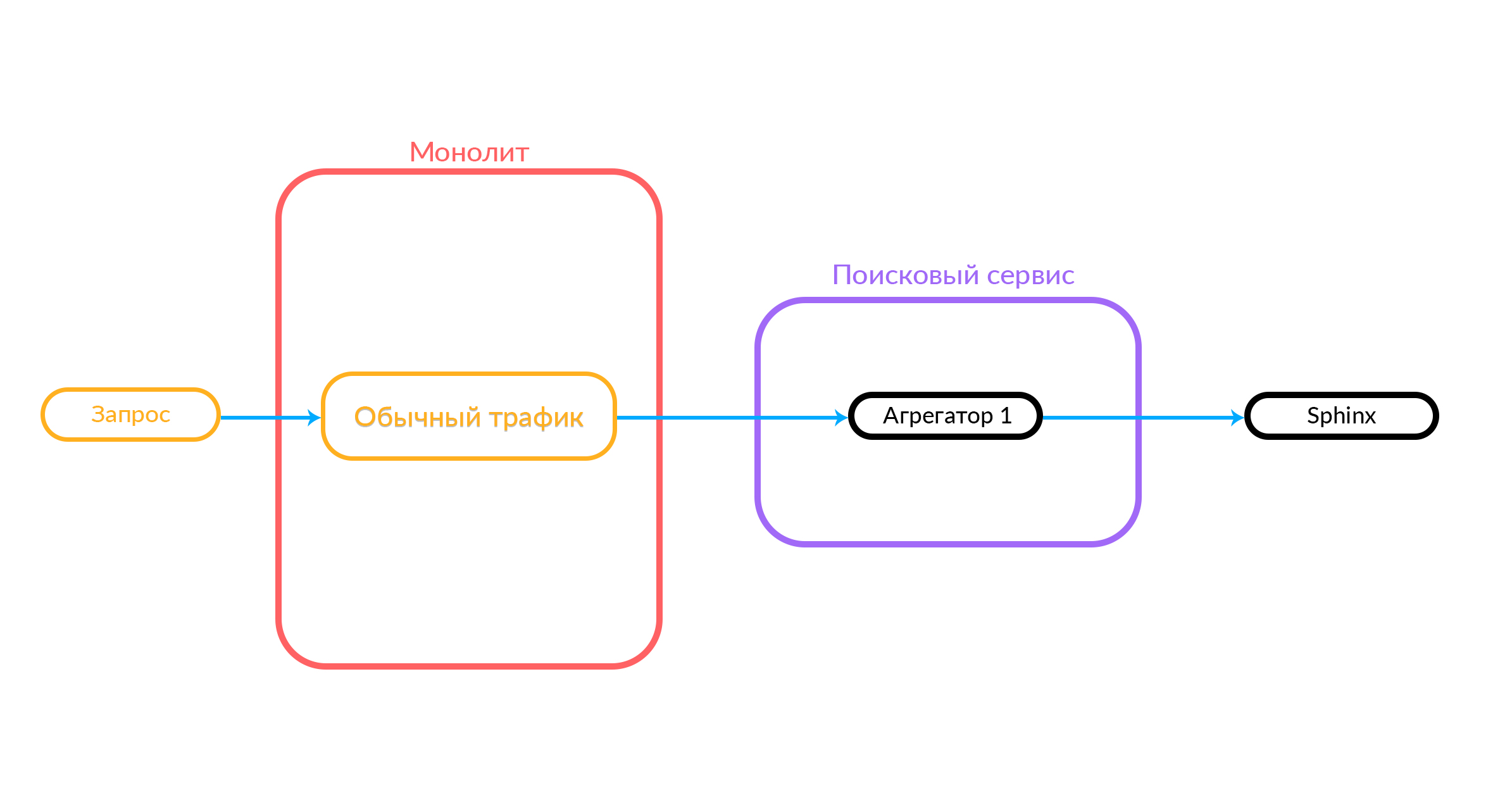
Automatización Experimental
Queremos que la búsqueda se desarrolle rápidamente, y la implementación de nuevas características fue más fácil. Para esto, se necesita una infraestructura adecuada. Hemos configurado la automatización de las pruebas A / B. Usando el tablero, podemos comenzar nuevos experimentos, configurarlos en base a las innovaciones agregadas y, en consecuencia, ejecutar experimentos sin rodar el monolito.
En el estado inicial, cuando no se lanzó un solo experimento, todos los visitantes ven la funcionalidad de búsqueda habitual.
En un experimento típico, los usuarios se dividen en grupos. El grupo de control, con la funcionalidad habitual para nuestros visitantes. Hay varios grupos de prueba, con innovaciones. Cuando necesitamos crear un nuevo experimento, en el servicio de búsqueda implementamos una nueva funcionalidad de búsqueda (agregamos nuevos agregadores) y a través del tablero configuramos el experimento con los grupos necesarios, vinculándolos con nuevos agregadores.
Al analizar los experimentos, comparamos el comportamiento de los visitantes en el grupo de control con los de la prueba y, en base a esto, sacamos conclusiones sobre el éxito del experimento.

Supongamos que hemos desarrollado una nueva fórmula de clasificación. ¿Qué necesitamos hacer para experimentar con ella?
- En el servicio de búsqueda, despliegue el agregador apropiado (que sea "Agregador 2").
- Cree un experimento a través de un tablero y conecte uno de los grupos en este experimento con este agregador.
- Ahora, si llega una consulta en la búsqueda que pertenece al grupo de prueba, se dirige al servicio de búsqueda en "Agregador 2".
Podemos continuar creando nuevos experimentos y asociar sus grupos de prueba con nuevos agregadores.
Infraestructura de búsqueda total
Hay un clúster de servidores Sphinx 3. Contiene 13 krps de consultas SphinxQL y tiene más de 45 millones de anuncios activos.
Sphinx 3.0 es estable y satisface su rendimiento. Por cierto, los binarios son de dominio público . Además, gracias a Avito, se filman nuevas características en Sphinx 3, por ejemplo, la operación del producto escalar de vectores, y los errores encontrados son corregidos.
Utilizamos arquitectura de servicio. Tenemos el servicio de búsqueda "Iskalo" y el servicio "Avito Assistant". Parte de la funcionalidad se ha mantenido en el monolito, pero seguimos trabajando en su corte.
Conclusiones
Durante el año pasado, se recibió un sistema de desarrollo de funcionalidad de búsqueda avanzada. Tuvimos la oportunidad de realizar experimentos rápidos y flexibles. Y ahora la búsqueda de usuarios se ha vuelto más conveniente, más rápida y mejor ayuda a resolver sus problemas.
Que sigue
Además, continuaremos eliminando del monolito lo que queda: renderizado, filtros. Trabajaremos para mejorar la calidad de la búsqueda, continuaremos deleitando a nuestros visitantes. Espero que tu también.
Si tiene preguntas sobre el trabajo de nuestra búsqueda, nos gustaría conocer más detalles técnicos, escriba en los comentarios. Contestaré con gusto. Por cierto, recientemente, Andrey Drozdov habló en Highload ++ 2018 con un informe sobre la optimización de criterios múltiples de los resultados de búsqueda , aquí está su presentación .