Hola a todos!
Hemos abierto una nueva secuencia para el curso de
Aprendizaje automático , así que espere en un futuro próximo artículos relacionados con esto, por así decirlo, disciplina. Bueno, por supuesto, seminarios abiertos. Ahora veamos qué es el aprendizaje por refuerzo.
El aprendizaje reforzado es una forma importante de aprendizaje automático, donde un agente aprende a comportarse en un entorno realizando acciones y viendo resultados.
En los últimos años, hemos visto muchos éxitos en este fascinante campo de investigación. Por ejemplo,
DeepMind y Deep Q Learning Architecture en 2014,
victoria sobre go campeón con AlphaGo en 2016,
OpenAI y PPO en 2017, entre otros.
 DeepMind DQN
DeepMind DQNEn esta serie de artículos, nos centraremos en estudiar las diferentes arquitecturas utilizadas hoy para resolver el problema del aprendizaje reforzado. Estos incluyen Q-learning, Deep Q-learning, Policy Gradients, Actor Critic y PPO.
En este artículo aprenderás:
- ¿Qué es el aprendizaje por refuerzo y por qué las recompensas son una idea central?
- Tres enfoques de aprendizaje de refuerzo
- Qué significa "profundo" en el aprendizaje de refuerzo profundo
Es muy importante dominar estos aspectos antes de sumergirse en la implementación de agentes de aprendizaje de refuerzo.
La idea del entrenamiento de refuerzo es que el agente aprenderá del entorno al interactuar con él y recibir recompensas por realizar acciones.

Aprender a través de la interacción con el medio ambiente proviene de nuestra experiencia natural. Imagina que eres un niño en la sala de estar. Ves la chimenea y ve hacia ella.
Cerca cálido, te sientes bien (recompensa positiva +1). Entiendes que el fuego es algo positivo.
Pero luego intentas tocar el fuego. ¡Ay! Se quemó la mano (recompensa negativa -1). Acabas de darte cuenta de que el fuego es positivo cuando estás a una distancia suficiente porque produce calor. Pero si te acercas a él, te quemarás.
Así es como las personas aprenden a través de la interacción. El aprendizaje reforzado es simplemente un enfoque computacional para aprender a través de la acción.
Proceso de aprendizaje por refuerzo

Como ejemplo, imagine a un agente aprendiendo a jugar a Super Mario Bros. El proceso de aprendizaje por refuerzo (RL) se puede modelar como un ciclo que funciona de la siguiente manera:
- El agente recibe el estado S0 del entorno (en nuestro caso, obtenemos el primer fotograma del juego (estado) de Super Mario Bros (entorno))
- Basado en este estado S0, el agente toma la acción A0 (el agente se moverá a la derecha)
- El entorno se mueve a un nuevo estado S1 (nuevo marco)
- El entorno da alguna recompensa al agente R1 (no muerto: +1)
Este ciclo RL produce una secuencia de
estados, acciones y recompensas.El objetivo del agente es maximizar las recompensas acumuladas esperadas.
Hipótesis de recompensa de idea central¿Por qué el objetivo de un agente es maximizar las recompensas acumuladas esperadas? Bueno, el aprendizaje por refuerzo se basa en la idea de una hipótesis de recompensa. Todos los objetivos se pueden describir maximizando las recompensas acumuladas esperadas.
Por lo tanto, en el entrenamiento de refuerzo, para lograr el mejor comportamiento, necesitamos maximizar las recompensas acumuladas esperadas.La recompensa acumulada en cada paso t puede escribirse como:

Esto es equivalente a:
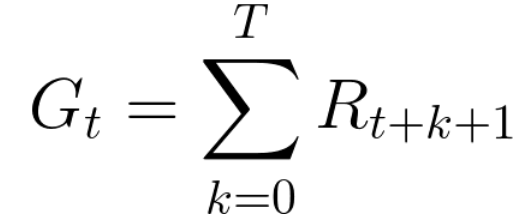
Sin embargo, en realidad, no podemos simplemente agregar tales recompensas. Las recompensas que llegan antes (al comienzo del juego) son más probables, ya que son más predecibles que las recompensas en el futuro.

Supongamos que su agente es un ratón pequeño y su oponente es un gato. Tu objetivo es comer la cantidad máxima de queso antes de que el gato te coma. Como vemos en el diagrama, es más probable que un ratón coma queso junto a sí mismo que el queso cerca de un gato (cuanto más cerca estamos de él, más peligroso es).
Como resultado, la recompensa de un gato, incluso si es mayor (más queso), se reducirá. No estamos seguros de que podamos comerlo. Para reducir la remuneración, hacemos lo siguiente:
- Determinamos la tasa de descuento llamada gamma. Debe estar entre 0 y 1.
- Cuanto mayor sea la gamma, menor será el descuento. Esto significa que el agente de aprendizaje está más preocupado por las recompensas a largo plazo.
- Por otro lado, cuanto más pequeña es la gamma, mayor es el descuento. Esto significa que se da prioridad a las recompensas a corto plazo (queso más cercano).
La contraprestación acumulada esperada, teniendo en cuenta el descuento, es la siguiente:
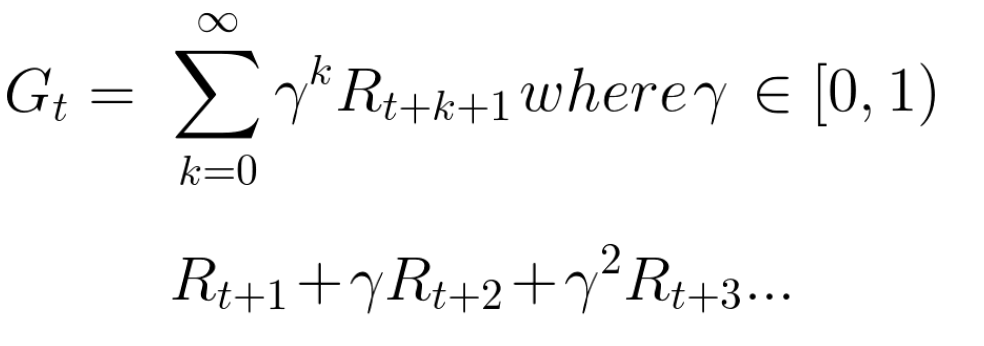
En términos generales, cada recompensa se reducirá utilizando la gamma para el indicador de tiempo. A medida que aumenta el paso del tiempo, el gato se acerca a nosotros, por lo que la recompensa futura es cada vez menos probable.
Tareas ocasionales o continuasUna tarea es una instancia del problema de aprendizaje con refuerzo. Podemos tener dos tipos de tareas: episódicas y continuas.
Tarea episódicaEn este caso, tenemos un punto de inicio y un punto final
(estado terminal). Esto crea un episodio : una lista de estados, acciones, recompensas y nuevos estados.
Tome Super Mario Bros por ejemplo: el episodio comienza con el lanzamiento del nuevo Mario y termina cuando lo matan o alcanzan el final del nivel.
 El comienzo de un nuevo episodio.Tareas continuasEstas son tareas que continúan para siempre (sin un estado terminal)
El comienzo de un nuevo episodio.Tareas continuasEstas son tareas que continúan para siempre (sin un estado terminal) . En este caso, el agente debe aprender a elegir las mejores acciones y al mismo tiempo interactuar con el entorno.
Por ejemplo, un agente que realiza operaciones bursátiles automatizadas. No hay un punto de partida y un estado terminal para esta tarea.
El agente continúa trabajando hasta que decidimos detenerlo. Método Monte Carlo vs. Diferencia horaria
Método Monte Carlo vs. Diferencia horariaHay dos formas de aprender:
- Recolectando recompensas al final del episodio y luego calculando las recompensas futuras máximas esperadas - enfoque Monte Carlo
- Evaluación de recompensas en cada paso: una diferencia temporal
MontecarloCuando finaliza el episodio (el agente alcanza un "estado terminal"), el agente observa la recompensa acumulada total para ver qué tan bien lo ha hecho. En el enfoque de Monte Carlo, las recompensas se reciben solo al final del juego.
Luego comenzamos un nuevo juego con mayor conocimiento.
El agente toma las mejores decisiones con cada iteración.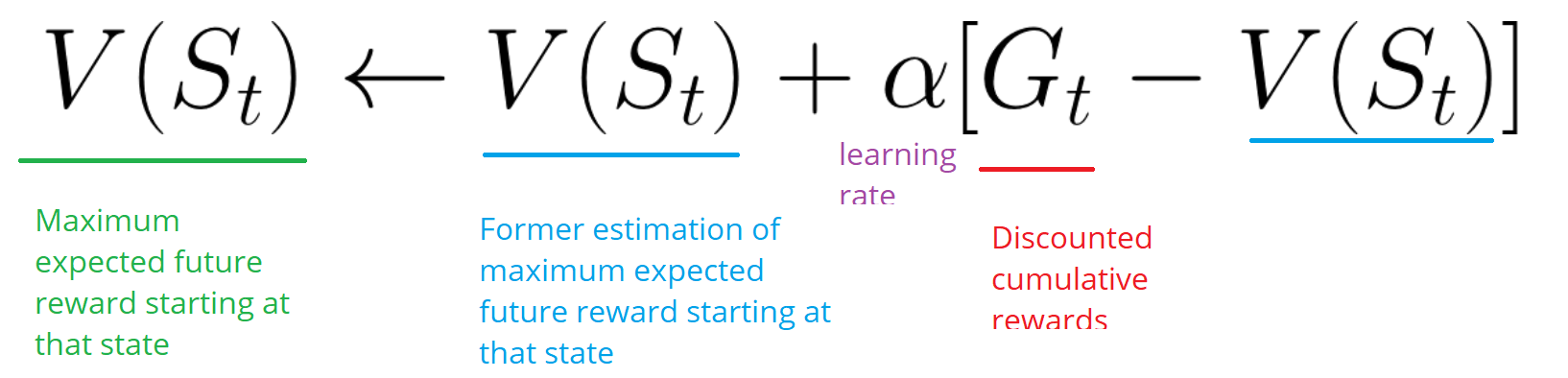
Aquí hay un ejemplo:
Si tomamos el laberinto como un entorno:
- Siempre comenzamos desde el mismo punto de partida.
- Paramos el episodio si el gato nos come o nos movemos> 20 pasos.
- Al final del episodio, tenemos una lista de estados, acciones, recompensas y nuevos estados.
- El agente resume la recompensa total de Gt (para ver qué tan bien lo hizo).
- Luego actualiza V (st) de acuerdo con la fórmula anterior.
- Entonces, un nuevo juego comienza con nuevos conocimientos.
Ejecutando más y más episodios, el
agente aprenderá a jugar cada vez mejor.Diferencias horarias: aprender en cada paso del tiempoEl método de aprendizaje de diferencia temporal (TD) no esperará hasta el final del episodio para actualizar la recompensa más alta posible. Él actualizará V dependiendo de la experiencia adquirida.
Este método se llama TD (0) o
TD paso a paso (actualiza la función de utilidad después de un solo paso).
Los métodos TD solo esperan el próximo
paso para actualizar los valores. En el tiempo t + 1
, se forma un objetivo TD usando la recompensa Rt + 1 y la calificación actual V (St + 1).El objetivo de TD es una estimación de lo esperado: de hecho, actualiza la calificación V (St) anterior al objetivo en un solo paso.
Exploración / operación de compromisoAntes de considerar varias estrategias para resolver problemas de entrenamiento de refuerzo, debemos considerar otro tema muy importante: la compensación entre exploración y explotación.
- La inteligencia encuentra más información sobre el medio ambiente.
- La explotación utiliza información conocida para maximizar las recompensas.
Recuerde que el objetivo de nuestro agente de RL es maximizar las recompensas acumuladas esperadas. Sin embargo, podemos caer en una trampa común.
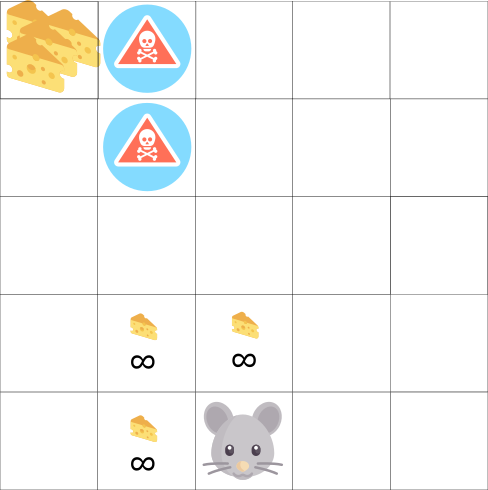
En este juego, nuestro mouse puede tener un número infinito de pequeños trozos de queso (+1 cada uno). Pero en la parte superior del laberinto hay un pedazo gigante de queso (+1000). Sin embargo, si nos centramos solo en las recompensas, nuestro agente nunca alcanzará una porción gigantesca. En cambio, usará solo la fuente de recompensas más cercana, incluso si esta fuente es pequeña (explotación). Pero si nuestro agente reconoce un poco, podrá encontrar una gran recompensa.
Esto es lo que llamamos un compromiso entre exploración y explotación. Debemos definir una regla que ayudará a lidiar con este compromiso. En futuros artículos aprenderá diferentes formas de hacer esto.
Tres enfoques de aprendizaje de refuerzoAhora que hemos identificado los elementos principales del aprendizaje reforzado, pasemos a tres enfoques para resolver el aprendizaje reforzado: basado en costos, basado en políticas y basado en modelos.
Basado en el costoEn RL basado en costos, el objetivo es optimizar la función de utilidad V (s).
Una función de utilidad es una función que nos informa de la recompensa máxima esperada que recibirá un agente en cada estado.
El valor de cada estado es la cantidad total de la recompensa que el agente puede esperar acumular en el futuro, a partir de este estado.
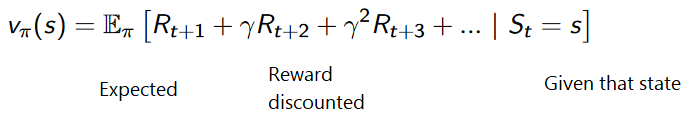
El agente utilizará esta función de utilidad para decidir qué estado elegir en cada paso. El agente selecciona el estado con el valor más alto.
En el ejemplo del laberinto, en cada paso tomaremos el valor más alto: -7, luego -6, luego -5 (etc.) para lograr el objetivo.
Basada en políticasEn RL basado en políticas, queremos optimizar directamente la función de política π (s) sin usar la función de utilidad. Una política es lo que determina el comportamiento de un agente en un momento dado.
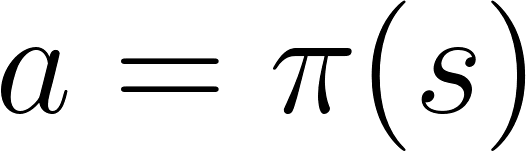 acción = política (estado)
acción = política (estado)Estudiamos la función de la política. Esto nos permite correlacionar cada estado con la mejor acción apropiada.
Hay dos tipos de políticas:
- Determinista: la política en un estado dado siempre devolverá la misma acción.
- Estocástico: muestra la probabilidad de distribución por acción.

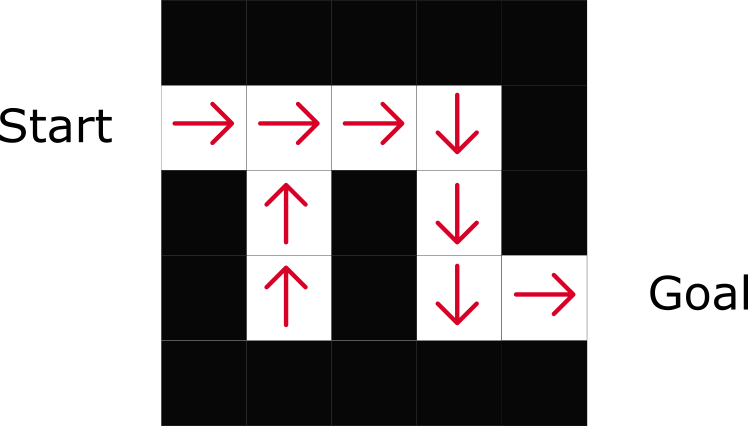
Como puede ver, la política indica directamente la mejor acción para cada paso.
Basado en el modeloEn RL basado en modelos, modelamos el entorno. Esto significa que estamos creando un modelo de comportamiento ambiental. El problema es que cada entorno necesitará una vista diferente del modelo. Es por eso que no nos enfocaremos mucho en este tipo de capacitación en los siguientes artículos.
Introducir aprendizaje de refuerzo profundoDeep Reinforcement Learning introduce redes neuronales profundas para resolver los problemas del aprendizaje reforzado, de ahí el nombre de "profundo".
Por ejemplo, en el próximo artículo, trabajaremos en Q-Learning (aprendizaje de refuerzo clásico) y Deep Q-Learning.
Verá la diferencia en el hecho de que en el primer enfoque usamos el algoritmo tradicional para crear la tabla Q, que nos ayuda a encontrar qué acción tomar para cada estado.
En el segundo enfoque, utilizaremos una red neuronal (para aproximar las recompensas basadas en el estado: valor q).
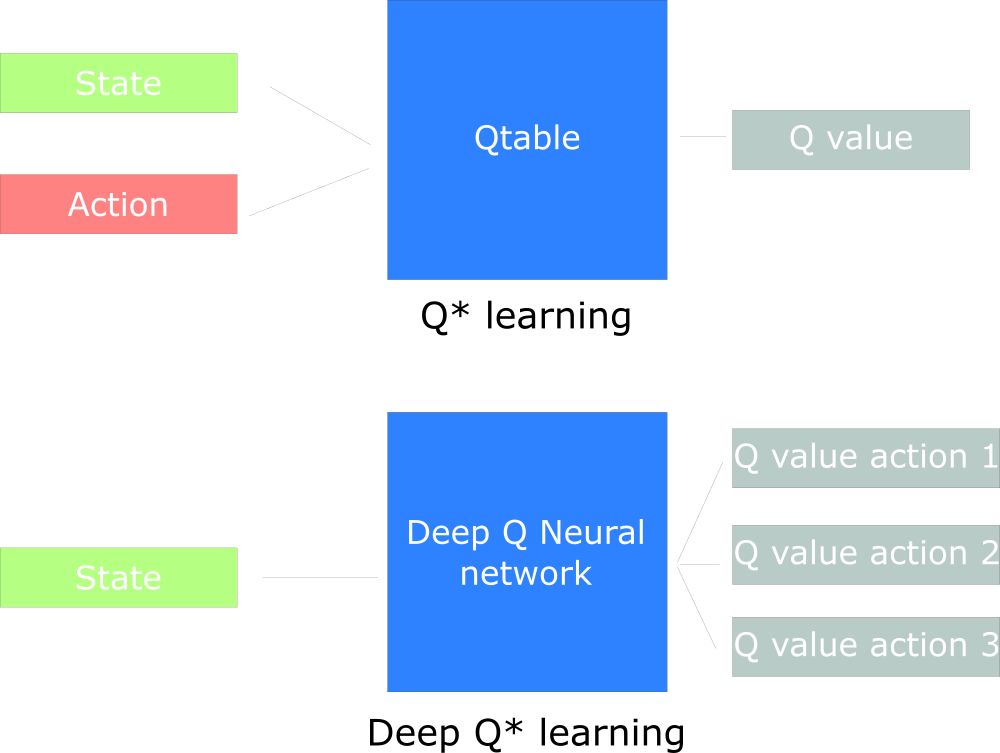 Cuadro de diseño Q inspirado en Udacity
Cuadro de diseño Q inspirado en Udacity
Eso es todo Como siempre, estamos esperando sus comentarios o preguntas aquí, o puede preguntarle al profesor del curso
Arthur Kadurin en su
lección abierta sobre redes.