
De alguna manera, resolviendo el problema del análisis lingüístico en Power BI y al mismo tiempo buscando ejemplos para mi
artículo anterior , recordé el problema que intenté resolver en Excel hace varios años: era necesario implementar un diccionario de idioma ruso en el sistema analítico para el análisis lingüístico de un gran número de consultas en lenguaje natural Y era deseable utilizar herramientas de oficina estándar. La gran mayoría de las personas tomaría inmediatamente esta tarea en Excel, y una vez tomé el mismo camino. Usé el corpus abierto del idioma ruso (
http://opencorpora.org/ ) como diccionario.
Pero la decepción me esperaba: el diccionario constaba de 300 mil formas de palabras, más de 5 millones de entradas, y para Excel es, en principio, una cantidad imposible. Incluso si inserta "solo" 1 millón de líneas en él, solo una persona muy paciente que nunca tendrá prisa podrá realizar manipulaciones con ellos o, Dios no lo permita, cálculos. Pero esta vez decidí establecer una herramienta más adecuada para la tarea: Power BI.
¿Qué es Power BI?
Encuentro este producto en gran medida subestimado por la comunidad profesional. Power BI es un conjunto de herramientas de análisis empresarial que se creó para usuarios que poseen Excel en un nivel ligeramente superior al de "dividir la cantidad en columnas". Si una persona puede escribir fórmulas de complejidad media en Excel, dominará Power BI en un par de noches.
Este no es un producto único con algún tipo de lógica de programación interna, sino un sistema de tres componentes:

- Power Query Este es un ETL, en el que es necesario escribir consultas usando su propio lenguaje de programación completamente funcional: M. Para ser justos, debe tenerse en cuenta que, lo más probable es que un usuario común no tenga que programar en él: la mayoría de las funciones están disponibles directamente a través del menú o el asistente en la interfaz del componente. El lenguaje M es completamente diferente del lenguaje de consulta DAX (PowerPivot). Sin embargo, Microsoft los unió. Esto tiene sentido desde el punto de vista del desarrollo: ETL está diseñado para recibir y saturar inicialmente los datos (no rápido), y DAX, para los cálculos que nos ayudan a visualizar estos datos (rápidamente). Es decir, DAX es para el front end y Power Query para el backend, para el proceso de extracción y formateo de datos.
- PowerPivot . Un módulo de procesamiento en memoria basado en el motor xVelocity. Utiliza el lenguaje de consulta DAX, muy similar al lenguaje de fórmulas de Excel.
- Componente de visualización . Es muy útil para aplicaciones en sistemas en los que necesita visualizar datos: en el sitio web de una empresa o en un portal de soporte técnico (por ejemplo, una nube de solicitudes) o en un recurso corporativo interno. Existen herramientas que pueden hacer esto sin Power BI, pero muchas de ellas no ayudarán cuando el número de registros sea de millones y los datos deban agregarse de alguna manera. Y con otras herramientas de este tipo, Power BI compite debido a su simplicidad y bajo costo de procesamiento en memoria. Está claro que si hablamos de terabytes de datos, se necesitará un enfoque diferente. Y para tales casos, Microsoft ya tiene algo que ofrecer, pero este es un tema para un artículo separado.
La curva de aprendizaje en la primera etapa aumenta mucho: si eres bueno en Excel, el 80% de las funciones de Power BI se abrirán después de un breve estudio. Esta es una herramienta muy poderosa, bastante fácil de usar, pero hasta cierto punto. Para usarlo a plena capacidad, ya necesitará experiencia y un conocimiento profundo de los idiomas M y DAX.
¿Para qué sirve Power BI Desktop?
¿Para quién puede ser útil? En primer lugar, cualquier usuario de negocios que tenga que procesar y analizar grandes cantidades de datos cuando Excel ya no pueda hacer frente o inflarlo al límite. Destaco: Power BI Desktop está diseñado
para una amplia gama de usuarios que resuelven una gama muy diversa de tareas . Por ejemplo, en mi caso, se trataba de normalizar 5 millones de entradas de texto para la posterior determinación de la frecuencia de las palabras clave.
Esto es muy necesario cuando se procesan cuestionarios, consultas de motores de búsqueda, anuncios, dictados / ensayos, algún tipo de matrices estadísticas, etc. O para resolver crucigramas ...
Otro caso y opción de implementación se considera en un
artículo sobre el "reconocedor" de Dmitry Tumaikin. Implementado en Excel clásico, pero usando macros ...
Otro escenario popular para esta aplicación de Power BI es calcular la proporción de indicadores para el período actual y anterior. Por ejemplo, tenemos datos de ingresos agregados previamente, y debe compararlos por días con el trimestre, año o período similar anterior. Y quiero / necesito insertar el resultado de la comparación en la siguiente columna en forma de valores, no de fórmulas. Parecería que para Excel la tarea más simple es escribir una fórmula de comparación simple y extenderla sobre todas las celdas de la columna. Pero no si tienes varios millones de filas en la tabla. En DAX, esta tarea es aún más fácil que en Excel, pero también solo con la ayuda de los cálculos posteriores.
Se pueden dar muchos otros escenarios prácticos para usar Power BI, pero creo que usted ya ha entendido la esencia. Por supuesto, todas estas tareas no son un problema para un programador que posee, por ejemplo, Python o R, pero tales especialistas son a priori más pequeños en orden de magnitud que los expertos de Excel. Excel solo tiene posibilidades limitadas, pero no es así con Power BI, que utiliza el lenguaje de fórmulas DAX, que es muy similar al lenguaje de fórmulas de Excel, y es capaz de procesar millones y decenas de millones de registros sobre la marcha. Y luego necesita aumentar la RAM (al menos hasta 100, al menos hasta 300 GB).
Ayudamos a las solicitudes de proceso de soporte técnico
Pero volviendo a mi tarea. Era necesario pensar cómo la línea cero de soporte técnico evaluaría automáticamente el tema de las solicitudes de los usuarios. Para empezar, decidí aislar ciertas formas de palabras y determinar los temas más importantes que los usuarios plantean con mayor frecuencia por la frecuencia de su aparición en los mensajes.
El diccionario fuente es un archivo de texto simple que tiene una estructura regular y se ve así:
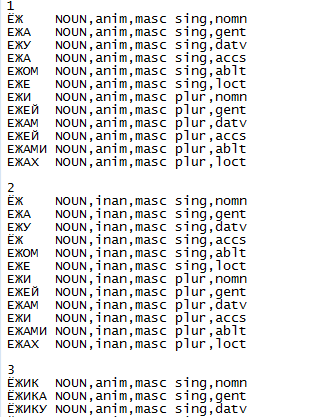
Para fines estadísticos, fue necesario determinar la forma inicial de cada forma de palabra: para sustantivos - un número único del caso nominativo, para verbos - una forma indefinida, etc. Para los programadores, esta tarea era más simple que simple: para cada palabra en la columna izquierda, encuentre la correspondencia con la forma que sigue inmediatamente al número de esta palabra en el diccionario.
Eso es solo el usuario comercial promedio que no posee Python, herramientas especializadas y habilidades de desarrollo, no puede resolver este problema sin el uso de BI de autoanálisis o herramientas similares fáciles de usar. Además, si los datos deben procesarse para sus necesidades internas o si no hay información confidencial que requiera protección, Power BI en este caso también será gratuito *.
Texto oculto*) Esto se refiere a la versión de Power BI Desktop y la versión de Power BI Services para uso personal con tarifa gratuita.
Para analizar los datos, necesitaba en Power Query, en una tabla de 5 millones de registros, agregar una nueva columna, desplazada por una posición. Al principio, traté de aplicar el enfoque clásico utilizando Power Query, que Marcel Beug, autor de la guía de referencia en línea original de Power Query
describe en el portal de la comunidad de Power BI (también escrito en Power Query). En el artículo se proponen dos algoritmos diferentes: uno está inspirado en las ideas de Matt Elington, un famoso gurú y entrenador de Power BI, y el segundo enfoque es la idea original del propio Marcel, utilizando una función adicional. A pesar de que para aumentar la productividad, almacené en caché por completo los datos de origen, ambos enfoques requirieron una cantidad de tiempo gigantesca: ya habían pasado el octavo día y el proceso no se había completado. El tamaño del archivo fuente era de 270 MB y el tamaño actual de los datos procesados era cercano a 17 TB. Estoy seguro de que pocos usuarios de Power BI han visto esos números en la ventana para cargar datos desde una fuente de archivo.
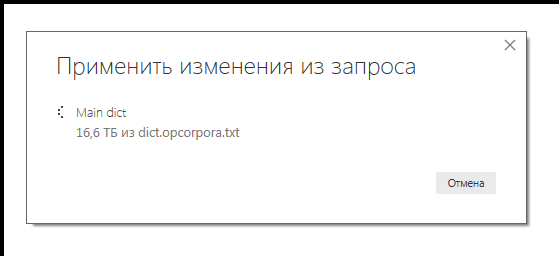
Por qué el volumen está tan hinchado, no está claro; Incluso el producto cartesiano de todos los registros es mucho menos de 16 Tb. Aquí, el optimizador interno claramente no estaba a la altura. Y, por ejemplo, DAX-Studio no permite el seguimiento de consultas de Power Query, solo DAX. ¿Quizás alguien compartirá su experiencia con PQ?
Sin esperar a que se completara el primer proceso, decidí en otra máquina intentar resolver el problema usando DAX a través de una consulta autoescrita. La solicitud se cumplió ... en unos 180 segundos, y el consumo de memoria aumentó ligeramente.

Código fuente para una solicitud DAX:
KeyWord =
CALCULATE(
TOPN(1;
CALCULATETABLE(
VALUES(ShiftedList[Word])
;ALLEXCEPT(ShiftedList;ShiftedList[Word Nr])
)
)//TOPN
)//CALCULATE
Es decir, para cada fila de la nueva columna [Palabra clave], se busca el primer valor de la columna [Palabra], que contiene todas las variantes de formas de palabras que tienen el mismo número de forma de palabra básica (columna [Palabra Nr]). Mientras el formato del archivo fuente permanezca sin cambios, la solicitud debe cumplirse sin errores en todas las versiones posteriores del diccionario.
El código de consulta en Power Query, que forma la tabla fuente en el formato requerido, se generó "automáticamente" y se completó en menos de un minuto:

Después de que se haya formado una columna de palabras clave en la interfaz de PowerPivot en tres minutos, la búsqueda de cualquier forma de palabra en la interfaz de Power BI no lleva más de 4 segundos. Además, una búsqueda de control para los mismos datos en su Notepad ++ x64 favorito podría tomar 20 segundos o más. Pero esto no es una piedra en el jardín de la central nuclear: es más difícil (y más largo) buscar en toda la matriz de datos que según los datos ya marcados.
Por cierto, la solicitud DAX anterior no nació la primera vez, y las opciones intermedias consumieron toda la memoria disponible, funcionaron durante mucho tiempo y terminaron con un error de datos o un resultado irrelevante.

Como resultado, el tamaño del archivo PBIX guardado se hizo un 60% (112 MB) más pequeño que el diccionario de texto original, pero más de 4 veces el tamaño del archivo ZIP con el mismo diccionario.
Volviendo a la batalla entre Power Query y DAX: la diferencia en la duración de la misma operación en diferentes componentes sugiere que Power BI no es una palanca contra la cual no hay recepción. Tiene su propio carácter y características de la aplicación, que deben tenerse en cuenta en su trabajo. En realidad, como cualquier herramienta. Y las recomendaciones de incluso gurús reconocidos deben tratarse con precaución.
Parece que el premio Nobel Richard Smalley solía decir, parafraseando la primera ley de Clark: "Cuando los expertos dicen que algo es factible, probablemente tengan razón (simplemente no saben cuándo). Cuando dicen que esto es imposible, lo más probable es que estén equivocados ".
Características de la máquina de prueba:
Procesador: Intel Core i7 4770 @ 3.4 GHz (4 núcleos)
RAM: 16 GB
SO: Windows 7 Enterprise SP1 x64El diccionario listo para usar en formato Power BI se puede descargar
desde aquí .
Y
aquí está disponible una versión en línea modificada del diccionario. Puedes resolver crucigramas a tu gusto :)

... Por cierto, hace varios años, sin embargo, la tarea se resolvió en Excel, aunque no al 100%. Solo para el análisis de los textos, no se utilizó todo el corpus del idioma ruso, sino el diccionario de frecuencias. Para la limpieza básica del texto, cualquiera de las 100 principales
listas de frecuencias disponibles
aquí para varias decenas de kilobytes es bastante adecuada.
Yuri Kolmakov, Experto, Departamento de Sistemas de Consolidación y Visualización de Datos, Jet Infosystems ( McCow )