Anteriormente, para llamar a un taxi, tenían que llamar a diferentes números de servicios de despacho y esperar a que se entregara el automóvil durante media hora o más. Ahora los servicios de taxi están bien automatizados, y el tiempo promedio para la entrega de automóviles Yandex.Taxi en Moscú es de aproximadamente 3-4 minutos. Pero vale la pena llover o terminar un evento masivo, y nuevamente podemos encontrar una escasez de autos gratis.
Mi nombre es Anton Skogorev, encabezo el grupo de desarrollo de rendimiento de la plataforma Yandex.Taxi. Hoy les contaré a los lectores de Habr cómo aprendimos a predecir la alta demanda y, además, a atraer conductores para que los usuarios puedan encontrar un automóvil gratis en cualquier momento. Aprenderá cómo se forma un coeficiente que afecta el valor del pedido. Todo lo que hay lejos de ser tan simple como parece a primera vista.
Desafío dinámico de precios
La tarea más importante de los precios dinámicos es brindar siempre la oportunidad de pedir un taxi. Se logra utilizando el coeficiente de aumento de precios, por el cual se multiplica el precio calculado. Lo llamamos simplemente aumento. Es importante decir que el aumento no solo regula la demanda de taxis, sino que también ayuda a atraer nuevos conductores para aumentar la oferta.
Si el aumento es demasiado grande, reduciremos la demanda demasiado, habrá un exceso de autos gratis. Si se configura demasiado bajo, los usuarios verán "no hay autos gratis". Debe poder elegir un coeficiente en el que caminemos sobre hielo delgado entre la falta de automóviles gratuitos y la baja demanda.
¿De qué debería depender este coeficiente? Inmediatamente me viene a la mente la dependencia de la cantidad de autos y pedidos alrededor del usuario. Ahora puede simplemente dividir el número de pedidos por el número de controladores, obtener el coeficiente y convertirlo en nuestro aumento con alguna fórmula (posiblemente lineal).
Pero hay un pequeño problema en esta tarea: puede ser demasiado tarde para contar los pedidos alrededor del usuario. Después de todo, un pedido es casi siempre una máquina ya ocupada, lo que significa que un aumento en nuestro coeficiente siempre llegará tarde. Por lo tanto, consideramos órdenes no creadas, sino
intenciones de ordenar un automóvil. Un pin es una etiqueta "A" en una tarjeta que un usuario coloca al iniciar nuestra aplicación.

Formulemos el problema: necesitamos leer los valores
instantáneos de máquinas y pines en algún punto del usuario.
Contamos el número de pines y autos alrededor
Cuando cambia la posición del pin (el usuario selecciona el punto "A"), la aplicación del usuario envía nuevas coordenadas y una pequeña hoja de información adicional al backend, lo que ayuda a evaluar el pin con mayor precisión (por ejemplo, la tarifa seleccionada).
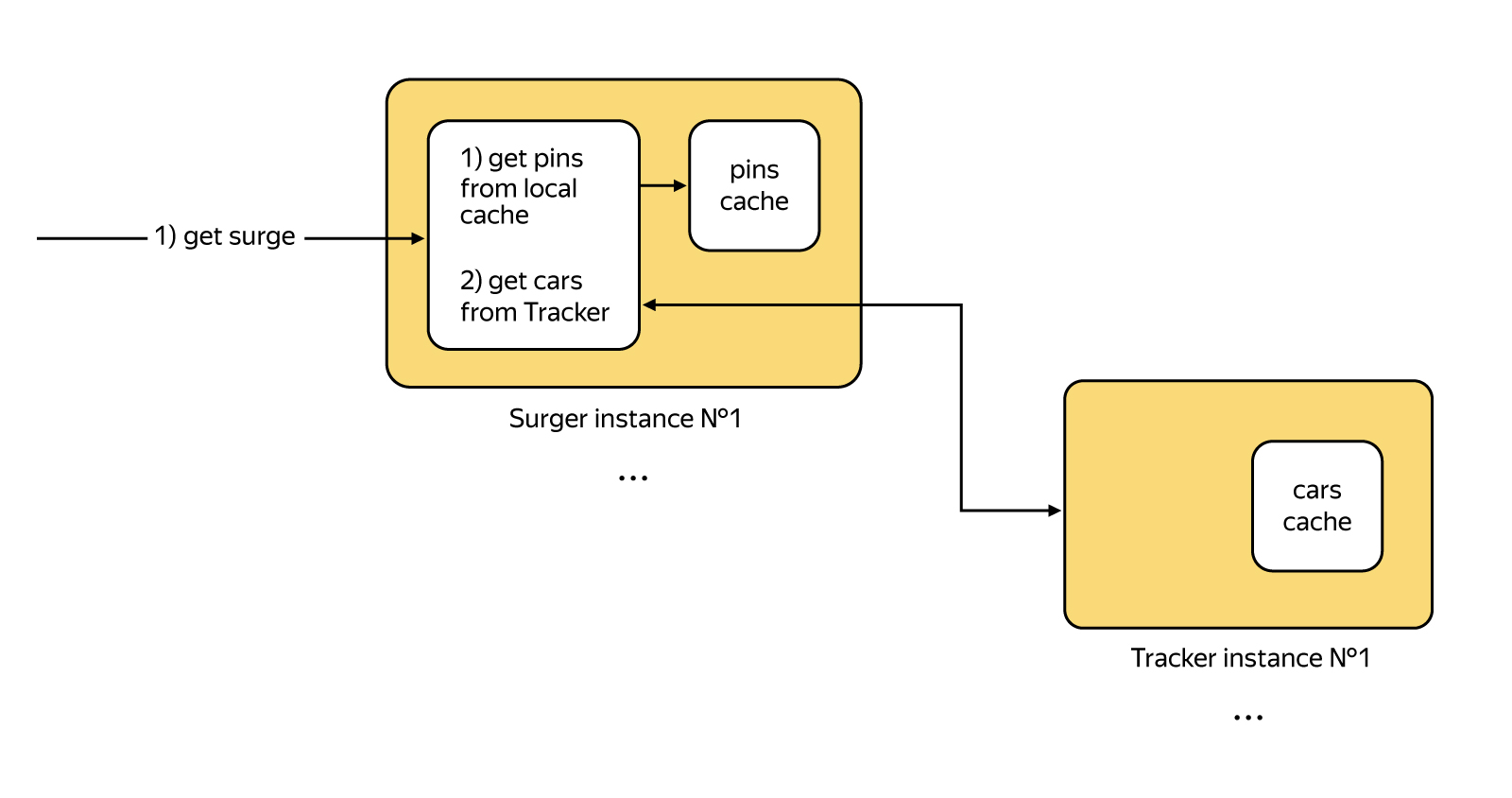
Intentamos adherirnos a la arquitectura del microservicio, donde cada microservicio se dedica a tareas separadas. El microservicio de cirugía se dedica al cálculo de la sobretensión. Registra los pines, los guarda en la base de datos y también actualiza la pepita de los pines en la RAM, en la que encajan bastante bien. El retraso de la caché durante dicho trabajo es de solo unos segundos, lo cual es aceptable en nuestro caso.
Algunas palabras sobre la base de datosAl registrarse, cada pin se agrega de forma asíncrona a MongoDb con el
Índice TTL , donde TTL es la "vida útil" del pin, en el que lo consideramos activo para calcular el coeficiente de aumento. El usuario no espera mientras realizamos estas acciones. Incluso si algo sale mal, perder un alfiler no es una gran tragedia.

Se construye una caché activa con un índice
geo-hash . Agrupamos todos los pines por geohash, y luego recogemos los pines para el radio deseado alrededor del punto de orden.
Hacemos lo mismo con los automóviles, pero en otro servicio llamado Rastreador, al que Surger responde simplemente con la pregunta "cuántos conductores hay en este radio".
Entonces consideramos los valores instantáneos del coeficiente.
Almacenamiento en caché
Caso : estás parado en el Garden Ring en Moscú y quieres reservar un auto. Al mismo tiempo, el precio sube con bastante frecuencia y esto es molesto.
Ya conociendo la mecánica, uno puede entender que esto puede deberse al hecho de que los conductores se acumulan en un semáforo condicional al momento de la solicitud de sobretensión y también se van rápidamente. Debido a esto, el aumento y el precio pueden notablemente "saltar".
Para evitar esto, almacenamos en caché el valor del aumento por usuario. Cuando un usuario acude a una sobretensión, observamos si hay un valor de sobretensión guardado para este usuario en un radio aceptable (un recorrido lineal de todas las sobretensiones guardadas del usuario). Si lo hay, lo devolvemos, de lo contrario, contamos con uno nuevo y también lo guardamos.
Esto funcionó bien, pero hay otras situaciones.
Caso : 2 usuarios solicitan oleada. Uno ordena 30 segundos más tarde que el otro cuando los automóviles de un semáforo de un caso anterior ya se han ido. Obtenemos una imagen donde 2 usuarios que ordenan casi simultáneamente pueden tener oleadas notablemente diferentes.
Y aquí vamos de caché por usuario a caché por posición. Ahora, en lugar de almacenar en caché el valor de aumento solo por el usuario, comenzamos a almacenarlo por el geo-hash que ya conocemos. Así que casi arreglamos el problema. ¿Por qué casi? Porque puede haber diferencias en los bordes de las geoheshes. Pero el problema no es tan significativo, porque tenemos suavizado.
Suavizado
Quizás, al leer un caso sobre un semáforo, se le ocurrió que de alguna manera era injusto considerar un aumento instantáneo, dependiendo del semáforo. También creemos que sí, así que descubrimos cómo solucionar la situación.
Decidimos tomar prestado el
método de vecinos más cercanos del aprendizaje automático para el problema de regresión con el fin de determinar cuánto es diferente el valor del aumento instantáneo de lo que sucede a su alrededor.
La etapa de entrenamiento, como en la descripción formal del método, consiste en almacenar todos los objetos; en nuestro caso, los valores calculados de la sobretensión en el pin, ya hacemos todo esto al momento de cargar todos los pines en el caché. Lo pequeño es calcular el valor instantáneo, compararlo con el valor en la zona y aceptar que no podemos desviarnos demasiado del valor en la zona.
Entonces obtenemos un sistema con una respuesta rápida a los eventos y que le permite leer rápidamente el valor del coeficiente creciente.
Tarjeta de conducción de sobretensión
Para comunicarnos con el conductor, debemos poder mostrar el mapa de sobretensión en la aplicación del conductor: un taxímetro. Esto le da al conductor comentarios sobre si hay demanda en el área donde se encuentra ahora y dónde debe moverse para obtener los pedidos más caros. Para nosotros, esto significa que más conductores vendrán a la zona con alta demanda y la resolverán.
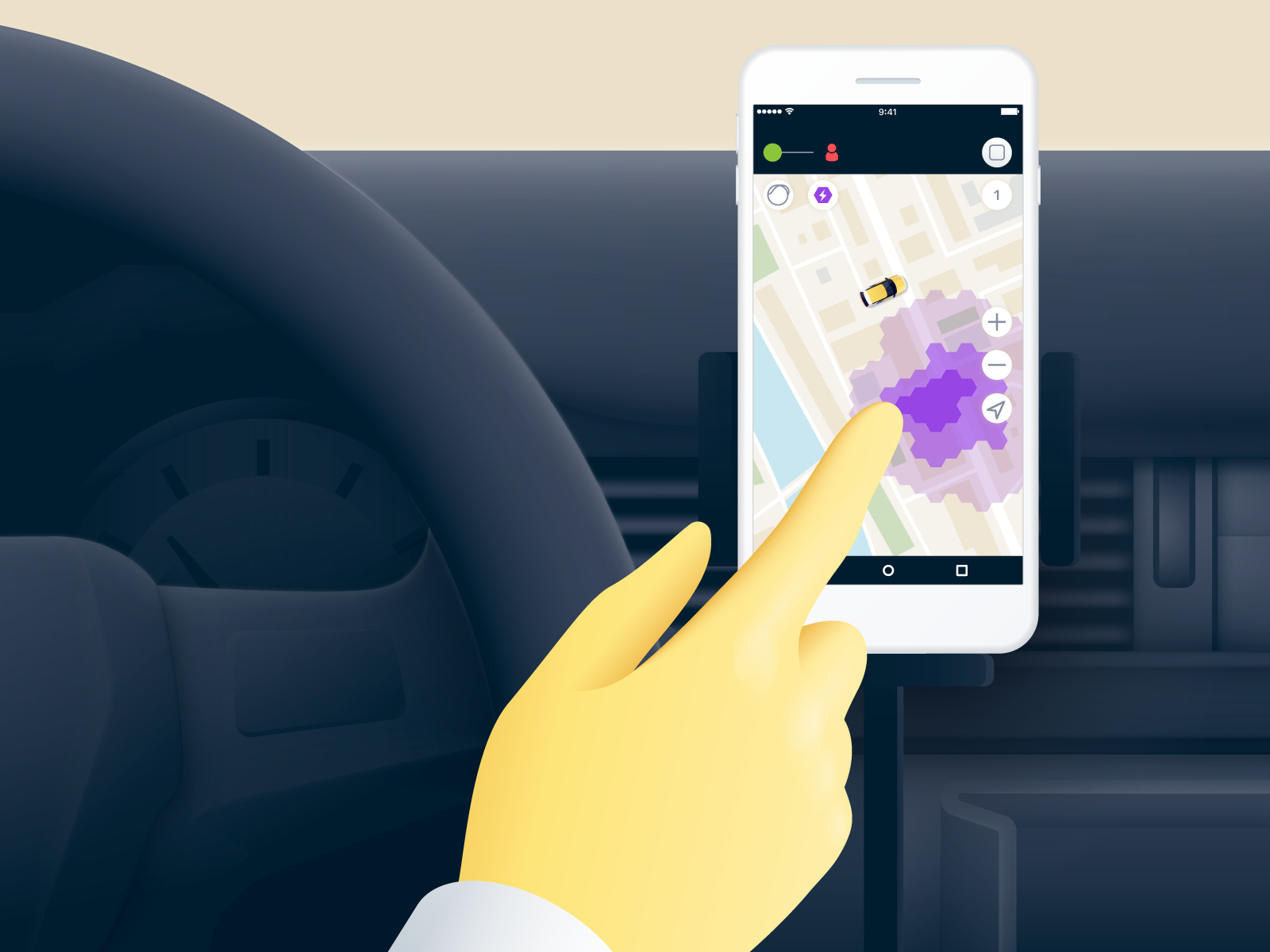
Vivimos con el paradigma de que el dispositivo del controlador es un dispositivo bastante débil. Por lo tanto, la representación de la rejilla hexagonal de sobretensión se encuentra en el lado del backend. El cliente llega al backend por los mosaicos. Estas son imágenes ráster cortadas para su visualización directa en el mapa.
Tenemos un servicio separado que recoge periódicamente moldes de pines del microservicio Surger y calcula toda la metainformación necesaria para representar la cuadrícula hexagonal: dónde está qué hexágono y qué oleada hay en cada uno.
Conclusión
El precio dinámico es una búsqueda constante de un equilibrio entre la oferta y la demanda, de modo que los usuarios siempre tengan autos gratis disponibles, incluso a través del mecanismo de atraer conductores adicionales a áreas de alta demanda. Por ejemplo, actualmente estamos trabajando en un uso más profundo del aprendizaje automático para calcular el aumento. Como parte de una de las tareas en esta área, estamos aprendiendo a determinar la probabilidad de que un pin se convierta en un pedido y tener en cuenta esta información. Aquí hay suficiente trabajo, por lo que siempre estamos contentos con los
nuevos especialistas en el equipo.
Si está interesado en conocer una parte de este gran tema con más detalle, escriba los comentarios. ¡Los comentarios y las ideas también son bienvenidos!
PD: En la próxima
publicación, mi colega hablará sobre el uso del aprendizaje automático para predecir la hora prevista de llegada de un taxi.