Análisis de publicaciones de Lenta.ru durante 18 años (de septiembre de 1999 a diciembre de 2017) utilizando python, sklearn, scipy, XGBoost, pymorphy2, nltk, gensim, MongoDB, Keras y TensorFlow.

El estudio utilizó datos de la publicación " Analizar esto - Lenta.ru " de ildarchegg . El autor proporcionó amablemente 3 gigabytes de artículos en un formato conveniente, y decidí que esta era una gran oportunidad para probar algunos métodos de procesamiento de texto. Al mismo tiempo, si tienes suerte, aprende algo nuevo sobre el periodismo ruso, la sociedad y en general.
Contenido:
MongoDB para importar json en python
Desafortunadamente, json con textos resultó estar un poco roto, no es crítico para mí, pero Python se negó a trabajar con el archivo. Por lo tanto, primero lo importé a MongoDB, y solo entonces, a través de MongoClient desde la biblioteca pymongo, cargué la matriz y la volví a almacenar en csv en pedazos.
De los comentarios: 1. Tuve que iniciar la base de datos con el comando sudo service mongod start: hay otras opciones, pero no funcionaron; 2. mongoimport: una aplicación separada, no se inicia desde la consola mongo, solo desde la terminal.
Las brechas de datos se distribuyen uniformemente a través de los años. No planeo usar el período de menos de un año, espero que no afecte la exactitud de las conclusiones.
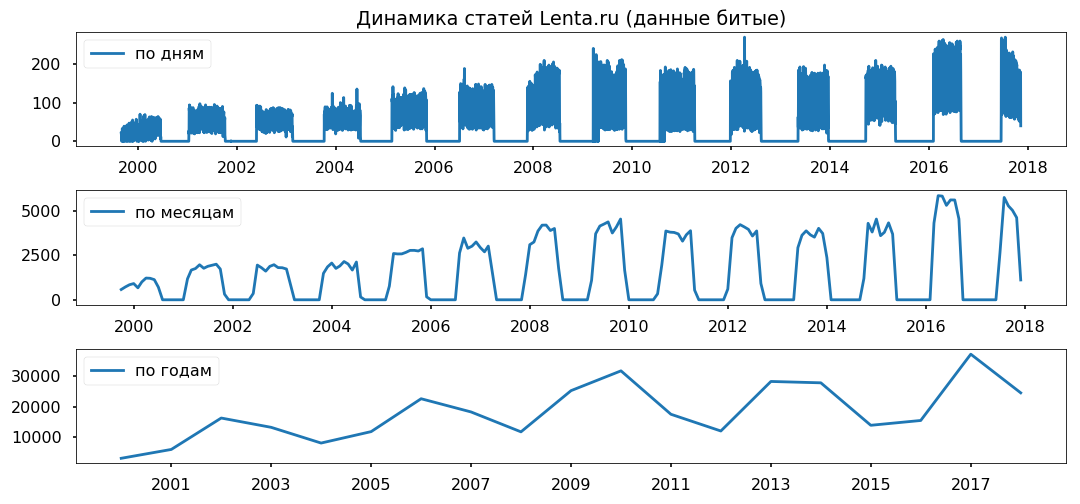
Limpieza y normalización de texto.
Antes de analizar directamente la matriz, debe llevarla a la forma estándar: eliminar caracteres especiales, convertir el texto a minúsculas (los métodos de cadena de pandas hicieron un gran trabajo), eliminar las palabras de detención (stopwords.words ('ruso') de nltk.corpus), devolver las palabras a su forma normal utilizando lematización (pymorphy2.MorphAnalyzer).
Hubo algunos defectos, por ejemplo, Dmitry Peskov se convirtió en "Dmitry" y "arena", pero en general estuve satisfecho con el resultado.
Nube de etiquetas
Como semilla, veamos qué publicaciones están en la forma más general. Mostraremos las 50 palabras más frecuentes utilizadas por los periodistas de Lenta de 1999 a 2017 en forma de nube de etiquetas.

Ria Novosti (la fuente más popular), mil millones de dólares y millones de dólares (temas financieros), presente (circulación de discurso común en todos los sitios de noticias), agencia de aplicación de la ley y caso penal (noticias criminales) ), "Primer Ministro" y "Vladimir Putin" (política): el estilo y los temas esperados para el portal de noticias.
Modelado temático de LDA
Calculamos los temas más populares para cada año utilizando el LDA de gensim. LDA (modelado temático utilizando el método de colocación latente de Dirichlet) revela automáticamente temas ocultos (un conjunto de palabras que ocurren juntas y con mayor frecuencia) por las frecuencias de palabras observadas en los artículos.
La piedra angular del periodismo doméstico fue Rusia, Putin, Estados Unidos.
En algunos años, este tema se diluyó con la guerra de Chechenia (de 1999 a 2000), el 11 de septiembre, en 2001, e Irak (de 2002 a 2004). De 2008 a 2009, la economía ocupó el primer lugar: interés, empresa, dólar, rublo, mil millones, millones. En 2011, a menudo escribieron sobre Gadafi.
De 2014 a 2017 Los años de Ucrania comenzaron y continúan en Rusia. El pico se produjo en 2015, luego la tendencia comenzó a disminuir, pero aún continúa en un nivel alto.
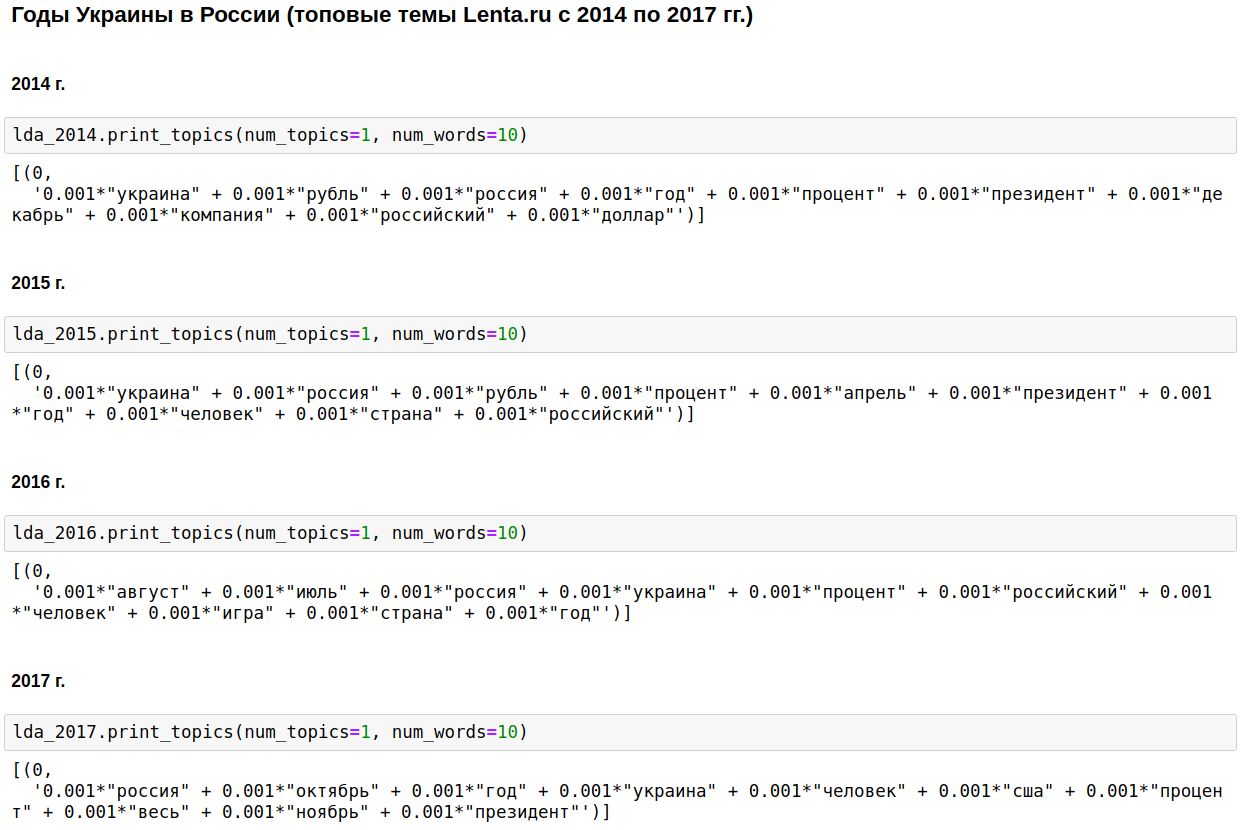
Es interesante, por supuesto, pero no hay nada que no sepa o adivine.
Cambiemos un poco el enfoque: seleccione los temas principales para todo el tiempo y vea cómo su relación ha cambiado de un año a otro, es decir, estudiaremos la evolución de los temas.
La opción más interpretada fue Top 5:
- Delincuencia (hombre, policía, ocurrir, detener, policía);
- Política (Rusia, Ucrania, Presidente, Estados Unidos, Jefe);
- Cultura (spinner, purulenta, instagram, divagación: sí, esta es nuestra cultura, aunque específicamente este tema resultó ser bastante mixto);
- Deporte (partido, equipo, juego, club, atleta, campeonato);
- Ciencia (científico, espacio, satélite, planeta, célula).
A continuación, tomamos cada artículo y vemos cómo se relaciona con un tema en particular, como resultado, todos los materiales se dividirán en cinco grupos.
La política resultó ser la más popular: menos del 80% de todas las publicaciones. Sin embargo, el pico de popularidad de los materiales políticos se aprobó en 2014, ahora su participación está disminuyendo y la contribución a la agenda de información de Crime and Sports está creciendo.
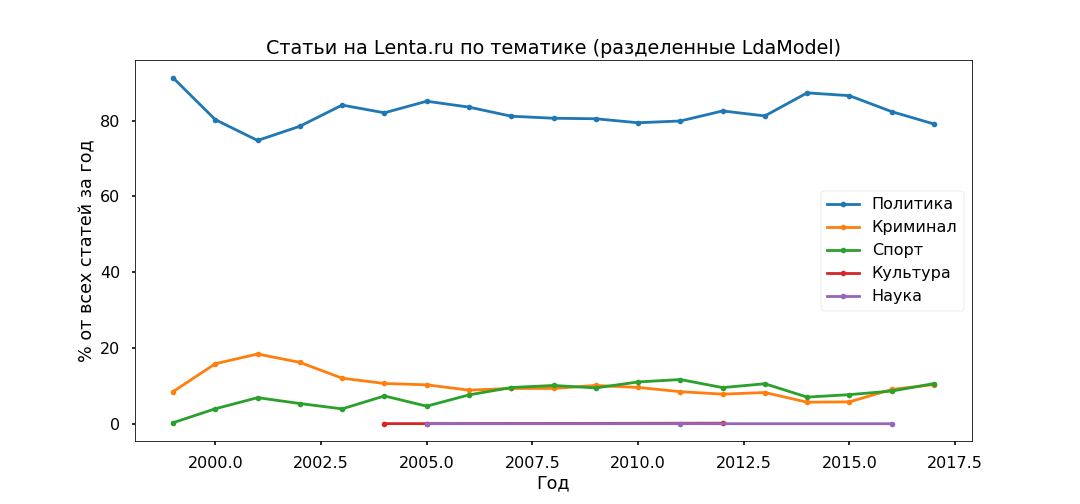
Verificaremos la adecuación de los modelos temáticos utilizando los subtítulos indicados por los editores. Las principales subcategorías se han identificado más o menos correctamente desde 2013.

No se notaron contradicciones particulares: la política se estancó en 2017, el fútbol y los incidentes están creciendo, Ucrania todavía está en tendencia, con un pico en 2015.
Predicción de popularidad: XGBClassifier, LogisticRegression, Embedded y LSTM
Tratemos de entender si es posible predecir la popularidad de un artículo en la cinta a partir del texto, y de qué depende generalmente esta popularidad. Como variable objetivo, tomé la cantidad de reposiciones de Facebook para 2017.
3 mil artículos para 2017 no tenían reposts en Fb: se les asignó la clase "impopular", 3 mil artículos con el mayor número de reposts recibieron la etiqueta "más popular".
El texto (6 mil publicaciones para 2017) se dividió en unogramas y bigramas (palabras simbólicas, frases de una o dos palabras) y se construyó una matriz donde las columnas son fichas, las filas son artículos y en la intersección es relativa frecuencia de aparición de palabras en artículos. Funciones utilizadas de sklearn: CountVectorizer y TfidfTransformer.
Los datos preparados se ingresaron en XGBClassifier (un clasificador basado en el aumento de gradiente de la biblioteca xgboost), que después de 13 minutos de enumerar hiperparámetros (GridSearchCV con cv = 3) dio una precisión del 76% en la prueba.

Luego usé la regresión logística habitual (sklearn.linear_model.LogisticRegression) y después de 17 segundos obtuve una precisión del 81%.
Una vez más, estoy convencido de que los métodos lineales son los más adecuados para la clasificación de textos, siempre que los datos estén cuidadosamente preparados.
Como homenaje a la moda, probé un poco las redes neuronales. Traduje las palabras a números usando one_hot de keras, llevé todos los artículos a la misma longitud (función pad_sequences de keras) y apliqué LSTM (red neuronal convolucional usando el backend TensorFlow) a través de la capa de incrustación (para reducir la dimensión y acelerar el tiempo de procesamiento).
La red funcionó en 2 minutos y mostró una precisión en la prueba del 70%. No es en absoluto el límite, pero en este caso no tiene sentido molestarse demasiado.
En general, todos los métodos produjeron una precisión relativamente baja. Como lo demuestra la experiencia, los algoritmos de clasificación funcionan bien con una variedad de estilos, en otros materiales de copyright. Existen tales materiales en Lenta.ru, pero hay muy pocos, menos del 2%.

La matriz principal se escribe usando vocabulario neutral de noticias. Y la popularidad de las noticias no está determinada por el texto en sí y ni siquiera por el tema como tal, sino por su pertenencia a una tendencia ascendente de información.
Por ejemplo, algunos artículos populares cubren eventos en Ucrania, los menos populares casi no se refieren a este tema.
Explorando objetos usando Word2Vec
En conclusión, quería realizar un análisis sentimental para comprender cómo los periodistas se relacionan con los objetos más populares que mencionan en sus artículos, si su actitud cambia con el tiempo.
Pero no tengo los datos marcados, y es poco probable que una búsqueda en tesauros semánticos funcione correctamente, ya que el vocabulario de las noticias es bastante neutral, tacaño con las emociones. Por lo tanto, decidí centrarme en el contexto en el que se mencionan los objetos.
Tomé Ucrania (2015 vs 2017) y Putin (2000 vs 2017) como prueba. Seleccioné los artículos en los que se mencionan, traduje el texto a un espacio vectorial multidimensional (Word2Vec de gensim.models) y lo proyecté en dos dimensiones utilizando el método de Componentes principales.
Después de renderizar las imágenes, resultaron ser épicas, nada menos que el tamaño de un tapiz de Bayeux. Recorté los grupos necesarios para simplificar la percepción, como pude, perdón por los "chacales".


Lo que noté
Putin del modelo 2000 siempre ha aparecido en el contexto de Rusia y se ha dirigido personalmente. En 2017, el Presidente de la Federación de Rusia se convirtió en un líder (lo que sea que eso signifique) y se distanció del país, ahora, a juzgar por el contexto, es un representante del Kremlin que se comunica con el mundo a través de su secretario de prensa.
Ucrania-2015 en los medios de comunicación rusos: guerra, batallas, explosiones; se menciona despersonalizado (declaró Kiev, comenzó Kiev). Ucrania-2017 aparece principalmente en el contexto de negociaciones entre funcionarios, y estas personas tienen nombres específicos.
...
Puede interpretar la información recibida durante bastante tiempo, pero, como creo, este es un recurso fuera de tema en este recurso. Los que lo deseen pueden verlo por sí mismos Adjunto el código y los datos.
Enlace de script
Enlace de datos