
Como sabes, HTTP 1.1 es un protocolo de transferencia de datos basado en texto. Los mensajes HTTP se codifican utilizando ISO-8859-1 (que puede considerarse condicionalmente una versión extendida de ASCII que contiene diéresis, diacríticos y otros caracteres utilizados en los idiomas de Europa occidental). Al mismo tiempo, se puede usar otra codificación en el cuerpo del mensaje, que debe indicarse en el encabezado "Tipo de contenido". Pero, ¿qué sucede si necesitamos especificar caracteres no ASCII no en el cuerpo del mensaje, sino en los encabezados mismos? Probablemente el caso más común es poner un nombre de archivo en el encabezado "Content-Disposition". Esto parece ser una tarea bastante común, pero su implementación no es tan obvia.
TL; DR: utilice la codificación descrita en
RFC 6266 para “Disposición de contenido” y convierta el texto al latín (transliteración) en otros casos.
Una pequeña introducción a las codificaciones.
El artículo menciona y utiliza las codificaciones US-ASCII (a menudo denominadas simplemente ASCII), ISO-8859-1 y UTF-8. Esta es una pequeña introducción a estas codificaciones. La sección está destinada a desarrolladores que rara vez o completamente no trabajan con codificaciones y han logrado olvidarlas. Si no les pertenece, no dude en saltear la sección.
ASCII es una codificación simple que contiene 128 caracteres e incluye todo el alfabeto inglés, números, signos de puntuación y caracteres de servicio.
7 bits son suficientes para representar cualquier carácter ASCII. La palabra "prueba" se representará en la representación HEX como 0x74 0x65 0x73 0x74. El primer bit para todos los caracteres es siempre 0, porque los caracteres están codificados en 128, y el byte proporciona 2 ^ 8 = 256 opciones.
ISO-8859-1 es una codificación destinada a idiomas de Europa occidental. Contiene diacríticos franceses, diéresis alemanas, etc.
La codificación contiene 256 caracteres y, por lo tanto, se puede representar por un byte. La primera mitad (128 caracteres) es exactamente igual a ASCII. Por lo tanto, si el primer bit = 0, entonces este es un carácter ASCII regular. Si es 1, entonces este es un carácter específico de ISO-8859-1.
UTF-8 es una de las codificaciones más famosas junto con ASCII. Capaz de codificar 1.112.064 caracteres.
El tamaño de cada carácter varía de 1 a 4 bytes (
anteriormente se permitían hasta 6 bytes).

El programa que trabaja con esta codificación determina por los primeros bits cuántos bytes se incluyen en el carácter. Si el octeto comienza en 0, el carácter está representado por un byte. 110 - dos bytes, 1110 - tres bytes, 11110 - 4 bytes.
Al igual que con ISO-8859-1, los primeros 128 caracteres son totalmente compatibles con ASCII. Por lo tanto, los textos que usan solo caracteres ASCII serán absolutamente idénticos en la representación binaria, independientemente de si US-ASCII, ISO-8859-1 o UTF-8 se usaron para la codificación.
Usando UTF-8 en el cuerpo de un mensaje
Antes de pasar a los encabezados, echemos un vistazo rápido a cómo usar UTF-8 en el cuerpo de los mensajes. Para hacer esto, use el encabezado
"Content-Type" .

Si no se especifica el "Tipo de contenido", el navegador debe procesar los mensajes como si estuvieran escritos en ISO-8859-1.
El navegador no debe intentar adivinar la codificación y, además, ignorar el "Tipo de contenido". Pero lo que realmente aparece en una situación en la que el "Tipo de contenido" no se transmite depende de la implementación del navegador. Por ejemplo, Firefox hará según la especificación y leerá el mensaje como si estuviera codificado en ISO-8859-1. Google Chrome, por el contrario, utilizará la codificación del sistema operativo, que para muchos usuarios rusos es igual a Windows-1251. En cualquier caso, si el mensaje estaba en UTF-8, entonces no se mostrará correctamente.

Ponemos el mensaje UTF-8 en el valor del encabezado
Con el cuerpo del mensaje, todo es bastante simple. El cuerpo del mensaje siempre sigue los encabezados, por lo que no hay problemas técnicos. ¿Pero qué pasa con los titulares? La especificación
establece explícitamente que el orden de los encabezados en el mensaje no importa. Es decir no es posible especificar la codificación en un encabezado a través de otro encabezado.
¿Qué sucede si simplemente toma y escribe el valor UTF-8 en el valor del encabezado? Hemos visto que tal truco con el cuerpo del mensaje dará como resultado que el valor se lea simplemente en ISO-8859-1. Sería lógico suponer que sucederá lo mismo con el titular. Pero esto no es así. De hecho, en muchos casos, si no en la mayoría, esta solución funcionará. Esto incluye iPhones viejos, IE11, Firefox, Google Chrome. El único navegador al alcance de mi mano cuando escribí este artículo que no quería trabajar con ese título fue Edge.

Este comportamiento no está registrado en las especificaciones. Quizás los desarrolladores del navegador decidieron facilitarles la vida a los desarrolladores y detectar automáticamente que los encabezados de los mensajes estaban codificados en UTF-8. En general, esta no es una tarea tan difícil. Observamos el primer bit: si es 0, luego ASCII, si es 1, entonces, posiblemente, UTF-8.
¿Hay alguna intersección con ISO-8859-1 en este caso? De hecho, casi ninguno. Tomemos, por ejemplo, UTF-8, un carácter de 2 octetos (las letras rusas están representadas por dos octetos). El símbolo en el binario presentado se verá así:
110xxxxx 10xxxxxx . En la representación HEX:
[0xC0-0x6F] [0x80-0xBF] . En ISO-8859-1, estos caracteres apenas pueden codificar algo que lleve una carga semántica. Por lo tanto, el riesgo de que el navegador descifre el mensaje incorrectamente es muy pequeño.
Sin embargo, cuando intente utilizar este método, puede encontrar problemas técnicos: su servidor web o marco simplemente no puede permitir escribir caracteres UTF-8 en el valor del encabezado. Por ejemplo, Apache Tomcat pone 0x3F (signo de interrogación) en lugar de todos los caracteres UTF-8. Por supuesto, esta restricción se puede eludir, pero si la aplicación en sí misma se da la mano y no permite que se haga algo, tal vez no sea necesario que lo haga.
Pero, independientemente de si su marco o servidor le permite escribir mensajes UTF-8 en el encabezado o no, no recomiendo hacerlo. Esta no es una solución documentada que puede dejar de funcionar en los navegadores en cualquier momento.
Translit
Creo que se usa translit, eto bolee horoshee reshenie. Muchos grandes recursos rusos populares no desdeñan usar la transliteración en los nombres de archivo. Esta es una solución garantizada que no se romperá con el lanzamiento de nuevos navegadores y que no necesita probarse por separado en cada plataforma. Aunque, por supuesto, debe pensar en cómo convertir todo el espectro de posibles caracteres, lo que puede no ser completamente trivial. Por ejemplo, si la aplicación está diseñada para un público ruso, entonces las letras tártaras ә y ң pueden aparecer en el nombre del archivo, que debe procesarse de alguna manera, y no solo reemplazarse con "?".
RFC 2047
Como ya mencioné, el tomkat no me permitió poner UTF-8 en el encabezado del mensaje. ¿Esta característica de comportamiento se refleja en los documentos Java para servlets? Sí, reflejado:
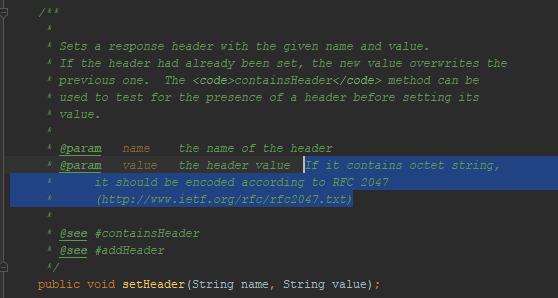
Mencionado
RFC 2047 . Traté de codificar mensajes usando este formato; el navegador no me entendió. Este método de codificación no funciona en HTTP. Aunque trabajó antes. Por ejemplo, un
ticket para eliminar el soporte para esta codificación de Firefox.
RFC 6266
En el ticket, cuyo enlace se encuentra en la sección anterior,
hay referencias de que incluso después de la finalización del soporte para RFC 2047, todavía hay una manera de transferir valores UTF-8 en el nombre de los archivos descargados:
RFC 6266 . En mi opinión, esta es la decisión más correcta hasta la fecha. Muchos recursos populares en línea lo usan. Nosotros en
CUBA Platform también utilizamos este RFC particular para generar la "Disposición de contenido".
RFC 6266 es una especificación que describe el uso del encabezado "Content-Disposition". El método de codificación en sí se describe en detalle en otra especificación,
RFC 8187 .

El parámetro "nombre de archivo" contiene el nombre del archivo en ASCII, "nombre de archivo *", en cualquier codificación necesaria. Con ambos atributos, el "nombre de archivo" se ignora en todos los navegadores modernos (incluidos IE11 y versiones anteriores de Safari). La mayoría de los navegadores antiguos, por el contrario, ignoran "nombre de archivo *".
Cuando se utiliza este método de codificación, el parámetro primero indica la codificación, seguido del valor codificado. Los caracteres visibles de la codificación ASCII no requieren. Los caracteres restantes simplemente se escriben en representación hexadecimal, con un "%" antes de cada octeto.
¿Qué hacer con otros encabezados?
La codificación descrita en RFC 8187 no es universal. Sí, puede poner un parámetro con un prefijo * en el encabezado, y esto incluso puede funcionar para algunos navegadores, pero la
especificación le dice que no lo
haga .
En cada caso donde UTF-8 es compatible con los encabezados, actualmente hay una mención explícita de esto en el RFC relevante. Además de Content-Disposition, esta codificación se usa, por ejemplo, en
Web Linking y
Digest Access Authentication .
Cabe señalar que los estándares en esta área cambian constantemente. El uso de la codificación descrita anteriormente en HTTP se
propuso solo en 2010 . El uso de esta codificación en "Content-Disposition" se
corrigió en el estándar en 2011 . A pesar del hecho de que estos estándares solo se encuentran
en la etapa de "Estándar propuesto" , son compatibles en todas partes. No se descarta la opción de que en el futuro esperamos nuevos estándares que permitan un trabajo más uniforme con diferentes codificaciones en los encabezados. Por lo tanto, solo queda seguir las noticias en el mundo de los estándares HTTP y su nivel de soporte al lado de los navegadores.