El reconocimiento óptico de caracteres (OCR) es el proceso de obtención de textos impresos en formato digitalizado. Si leyó una novela clásica en un dispositivo digital o le pidió a un médico que recogiera registros médicos antiguos a través del sistema informático del hospital, probablemente haya utilizado OCR.
OCR hace que el contenido previamente estático sea editable, buscable y compartible. Pero muchos documentos que deben digitalizarse contienen manchas de café, páginas con esquinas curvadas y muchas arrugas que mantienen algunos documentos impresos sin digitalizar.
Todos saben desde hace mucho tiempo que hay millones de libros antiguos que se almacenan en el almacenamiento. El uso de estos libros está prohibido debido a su dilapidación y decrepitud, y por lo tanto, la digitalización de estos libros es tan importante.
El documento considera la tarea de eliminar texto del ruido, reconocer el texto en una imagen y convertirlo a formato de texto.

Para el entrenamiento, se utilizaron 144 imágenes. El tamaño puede ser diferente, pero preferiblemente debe estar dentro de lo razonable. Las imágenes deben estar en formato PNG. Después de leer la imagen, se utiliza la binarización: el proceso de convertir una imagen en color a blanco y negro, es decir, cada píxel se normaliza en un rango de 0 a 255, donde 0 es negro, 255 es blanco.
Para entrenar una red convolucional, necesita más imágenes de las que hay. Se decidió dividir las imágenes en partes. Como la muestra de entrenamiento consta de imágenes de diferentes tamaños, cada imagen se comprimió a 448x448 píxeles. El resultado fue 144 imágenes en una resolución de 448x448 píxeles. Luego, todos ellos se cortaron en ventanas no superpuestas de 112x112 píxeles de tamaño.

Así, de 144 imágenes iniciales, se obtuvieron aproximadamente 2304 imágenes en el conjunto de entrenamiento. Pero esto no fue suficiente. Se necesita más capacitación para una buena capacitación en redes convolucionales. Como resultado de esto, la mejor opción era rotar las imágenes 90 grados, luego 180 y 270 grados. Como resultado, se suministra una matriz con el tamaño [16,112,112,1] a la entrada de red. Donde 16 es el número de imágenes, 112 es el ancho y alto de cada imagen, 1 es los canales de color. Resultó 9216 ejemplos de capacitación. Esto es suficiente para entrenar una red convolucional.
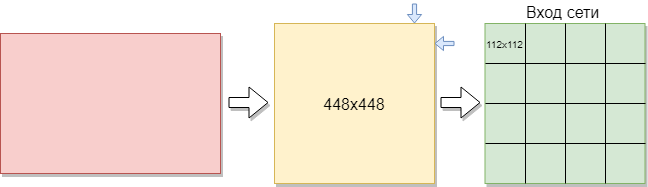
Cada imagen tiene un tamaño de 112x112 píxeles. Si el tamaño es demasiado grande, la complejidad computacional aumentará, respectivamente, se violarán las restricciones en la velocidad de respuesta, la determinación del tamaño en este problema se resuelve mediante el método de selección. Si selecciona un tamaño demasiado pequeño, la red no podrá identificar los signos clave. Cada imagen tiene un formato en blanco y negro, por lo que se divide en 1 canal. Las imágenes en color se dividen en 3 canales: rojo, azul, verde. Como tenemos imágenes en blanco y negro, el tamaño de cada imagen es de 112x122x1 píxeles.
En primer lugar, es necesario entrenar una red neuronal convolucional en imágenes preparadas y procesadas. Para esta tarea, se seleccionó la arquitectura U-Net.
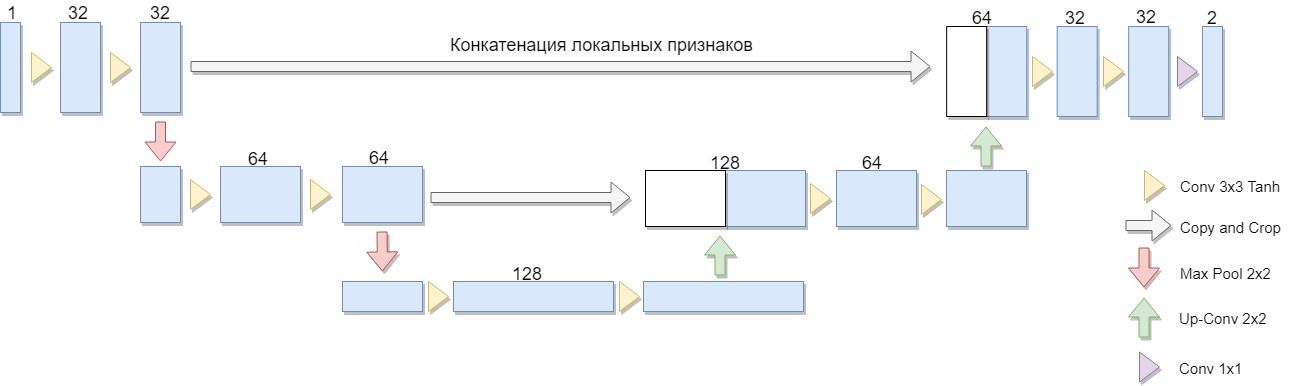
Se seleccionó una versión reducida de la arquitectura, que consta de solo dos bloques (la versión original de cuatro). Una consideración importante fue el hecho de que una gran clase de algoritmos de binarización bien conocidos se expresa explícitamente en dicha arquitectura o arquitectura similar (como ejemplo, podemos modificar el algoritmo de Niblack reemplazando la desviación estándar por la desviación media, en cuyo caso la red se construye especialmente simple).
La ventaja de esta arquitectura es que para entrenar la red, puede crear una cantidad suficiente de datos de entrenamiento a partir de un pequeño número de imágenes de origen. Además, la red tiene un número relativamente pequeño de pesos debido a su arquitectura convolucional. Pero hay algunos matices. En particular, la red neuronal artificial utilizada, estrictamente hablando, no resuelve el problema de binarización: para cada píxel de la imagen de origen, asocia un número del 0 al 1, que caracteriza el grado en que este píxel pertenece a una de las clases (relleno significativo o fondo) y que es necesario Todavía convertir a la respuesta binaria final. [1]
U-Net consiste en una ruta de compresión y descompresión y "hacia adelante" entre ellos. La ruta de compresión, en esta arquitectura, consta de dos bloques (en la versión original de cuatro). Cada bloque tiene dos convoluciones con un filtro 3x3 (usando la función de activación Tanh después de la convolución) y una agrupación con un tamaño de filtro 2x2 en pasos de 2. El número de canales en cada paso hacia abajo se duplica.
El camino de compresión también consta de dos bloques. Cada uno de ellos consiste en un "barrido" con un tamaño de filtro de 2x2, reduciendo a la mitad el número de canales, concatenación con un mapa de características recortado correspondiente de la ruta de compresión ("reenvío") y dos convoluciones con un filtro de 3x3 (usando la función de activación Tanh después de la convolución). Luego, en la última capa, una convolución 1x1 (usando la función de activación Sigmoide) para obtener una imagen plana de salida. Tenga en cuenta que recortar el mapa de características durante la concatenación es esencial debido a la pérdida de píxeles de límite para cada convolución. Adam fue elegido como el método de optimización estocástica.
En general, la arquitectura es una secuencia de capas de convolución + agrupación que reducen la resolución espacial de la imagen, luego la aumentan combinándola con los datos de la imagen por adelantado y pasando a través de las otras capas de la convolución. Por lo tanto, la red actúa como una especie de filtro. [2]
La muestra de prueba consistió en imágenes similares, las diferencias fueron solo en la textura de ruido y en el texto. Se realizaron pruebas de red en esta imagen.

En la salida de la red neuronal convolucional, se obtiene una matriz de números con un tamaño de [16,112,112,1]. Cada número es un píxel separado procesado por la red. Las imágenes tienen un formato de 112x112 píxeles, como antes, se cortó en pedazos. Ella necesita traicionar la apariencia original. Combinamos las imágenes obtenidas en una parte, como resultado, la imagen tiene un formato de 448x448. Luego, multiplicamos cada número en la matriz por 255 para obtener un rango de 0 a 255, donde 0 es negro, 255 es blanco. Devolvemos la imagen a su tamaño original, como antes, estaba comprimida. El resultado es la imagen de abajo en la figura.

En este ejemplo, se ve que la red convolucional hizo frente a la mayor parte del ruido y demostró ser eficiente. Pero es claramente visible que la imagen se volvió más nublada y los ruidos perdidos son visibles. En el futuro, esto puede afectar la precisión del reconocimiento de texto.
En base a este hecho, se decidió utilizar otra red neuronal: un perceptrón multicapa. En el resultado esperado, la red debería aclarar el texto de la imagen y eliminar el ruido que falta en la red neuronal convolucional.
Una imagen ya procesada por la red de convolución se envía a la entrada del perceptrón multicapa. En este caso, la muestra de capacitación para esta red será diferente de la muestra para la red convolucional, ya que las redes procesan la imagen de manera diferente. La red convolucional se considera la red principal y elimina la mayor parte del ruido en la imagen, mientras que el perceptrón multicapa procesa lo que ha fallado la convolucional.
Aquí hay algunos ejemplos del conjunto de entrenamiento para un perceptrón multicapa.

Los datos de imagen se obtuvieron procesando la muestra de entrenamiento para la red convolucional con un perceptrón multicapa. Al mismo tiempo, el perceptrón fue entrenado en la misma muestra, pero en un pequeño número de ejemplos y un pequeño número de eras.
Para el entrenamiento de perceptrón, se procesaron 36 imágenes. La red se entrena píxel por píxel, es decir, un píxel de la imagen se envía a la entrada de la red. En la salida de la red, también obtenemos una neurona de salida, un píxel, es decir, la respuesta de la red. Para aumentar la precisión del procesamiento, se hicieron 29 neuronas de entrada. Y en la imagen obtenida después del procesamiento por la red de convolución, se superponen 28 filtros. El resultado son 29 imágenes con diferentes filtros. Enviamos un píxel de cada imagen 29 a la entrada de la red y solo se recibe un píxel en la salida de la red, es decir, la respuesta de la red.
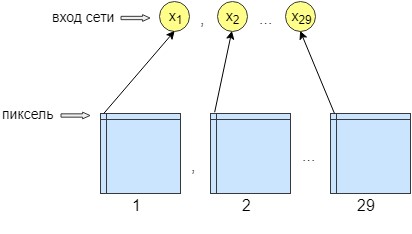
Esto se hizo para mejorar la capacitación y la creación de redes. Después de eso, la red comenzó a aumentar la precisión y el contraste de la imagen. También limpia errores menores que no pueden borrar la red convolucional.
Como resultado, la red neuronal tiene 29 neuronas de entrada, un píxel de cada imagen. Después de los experimentos, se descubrió que solo se necesitaba una capa oculta, en la que 500 neuronas. Solo hay una salida de la red. Como la capacitación se realizó píxel por píxel, se accedió a la red n * m veces, donde n es el ancho de la imagen ym es la altura, respectivamente.

Después de procesar la imagen secuencialmente por dos redes neuronales, lo principal que queda es reconocer el texto. Para esto, se tomó una solución preparada, a saber, la biblioteca Python Pytesseract. Pytesseract no proporciona enlaces de Python verdaderos. Más bien, es un contenedor simple para el binario tesseract. En este caso, tesseract se instala por separado en la computadora. Pytesseract guarda la imagen en un archivo temporal en el disco y luego llama al archivo binario tesseract y escribe el resultado en un archivo.
Este contenedor fue desarrollado por Google y es gratuito y de uso gratuito. Se puede utilizar tanto para fines propios como comerciales. La biblioteca funciona sin conexión a Internet, admite muchos idiomas para reconocimiento e impresiona con su velocidad. Su aplicación se puede encontrar en varias aplicaciones populares.
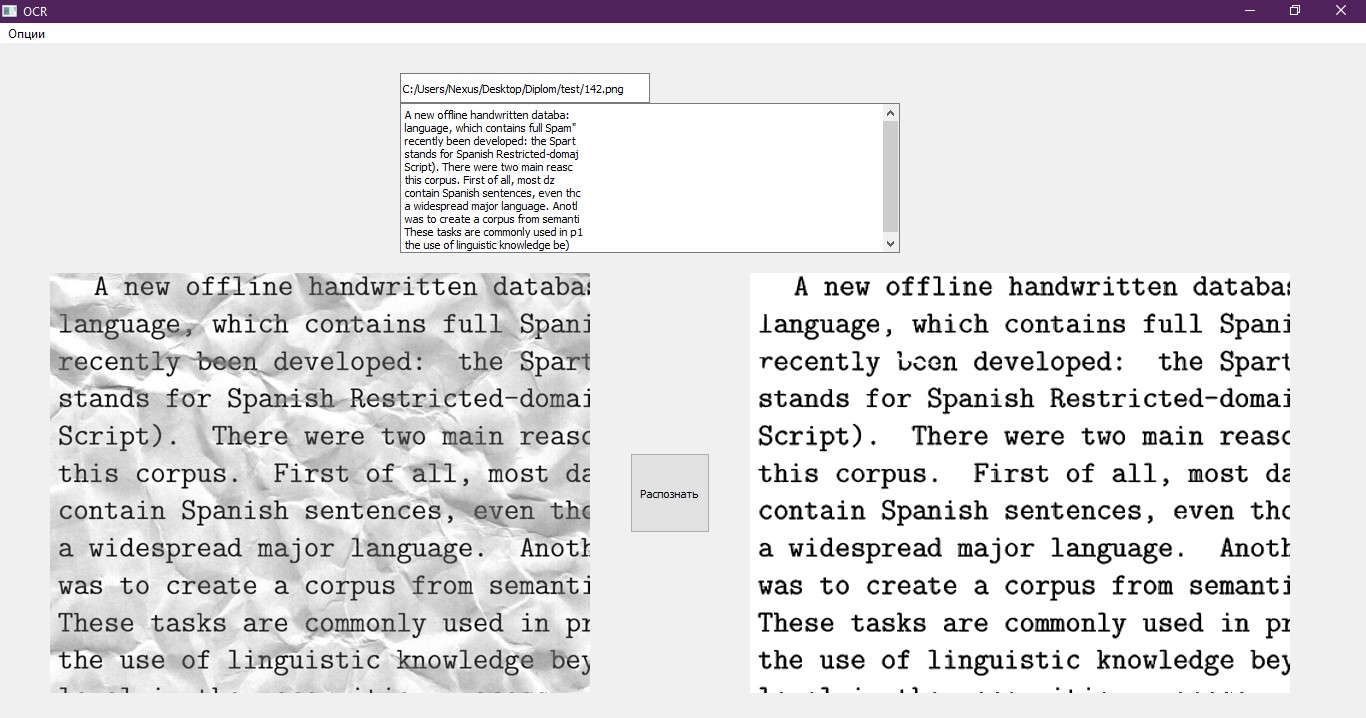
El último elemento que queda es escribir el texto reconocido en un archivo en un formato adecuado para procesarlo. Usamos para esto un cuaderno normal, que se abre después de que el programa finaliza. Además, el texto se muestra en la interfaz de prueba. Un buen ejemplo de una interfaz.
Referencias
- La historia de la victoria en el concurso internacional de reconocimiento de documentos del equipo SmartEngines [recurso electrónico]. Modo de acceso: https://habr.com/company/smartengines/blog/344550/
- Segmentación de imagen utilizando una red neuronal: U-Net [recurso electrónico]. Modo de acceso: http://robocraft.ru/blog/machinelearning/3671.html
> Repositorio de Github