
Hola a todos!
Continuando con el estudio del tema del
aprendizaje profundo , una vez quisimos hablar con usted acerca de
por qué las ovejas parecen estar en todas partes en las redes neuronales . Este tema se
discute en el noveno capítulo del libro de Francois Scholl.
Por lo tanto, fuimos a los maravillosos estudios de Tecnologías Positivas,
presentados en Habré , así como al excelente trabajo de dos empleados del MIT que consideran que el "aprendizaje malicioso de máquinas" no es solo un obstáculo y un problema, sino también una herramienta de diagnóstico maravillosa.
Siguiente - debajo del corte.
En los últimos años, los casos de interferencia maliciosa han atraído una atención seria en la comunidad de aprendizaje profundo. En este artículo, nos gustaría describir este fenómeno en términos generales y analizar cómo encaja en el contexto más amplio de la fiabilidad del aprendizaje automático.
Intervenciones maliciosas: un fenómeno intrigantePara describir el alcance de nuestra discusión, damos algunos ejemplos de tales interferencias maliciosas. Creemos que la mayoría de los investigadores involucrados en la Región de Moscú encontraron imágenes similares:
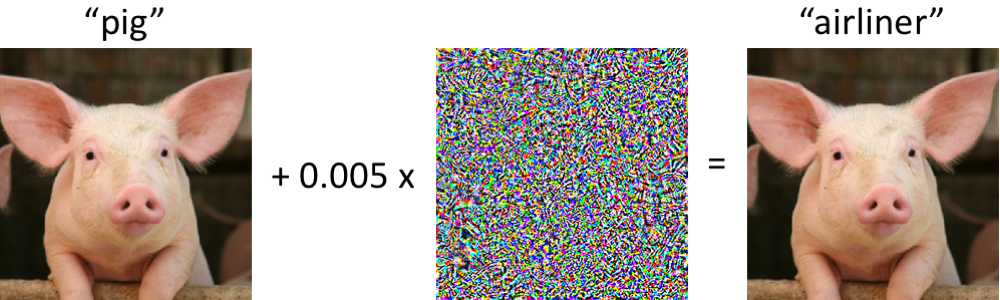
A la izquierda hay un cerdito, correctamente clasificado como un lechón por la moderna red neuronal convolucional. Una vez que hacemos cambios mínimos en la imagen (todos los píxeles están en el rango [0, 1], y cada uno cambia en no más de 0.005), y ahora la red devuelve la clase "avión" con alta confiabilidad. Tales ataques a clasificadores entrenados se conocen desde al menos 2004 (
enlace ), y el primer trabajo sobre interferencia maliciosa con clasificadores de imágenes se remonta a 2006 (
enlace ). Luego, este fenómeno comenzó a atraer significativamente más atención desde aproximadamente 2013, cuando resultó que las redes neuronales son vulnerables a ataques de este tipo (ver
aquí y
aquí ). Desde entonces, muchos investigadores han propuesto opciones para construir ejemplos maliciosos, así como formas de aumentar la resistencia de los clasificadores a tales perturbaciones patológicas.
Sin embargo, es importante recordar que no es necesario profundizar en las redes neuronales para observar estos ejemplos maliciosos.
¿Qué tan robustos son los ejemplos de malware?Quizás la situación en la que la computadora confunde al lechón con el avión puede ser alarmante al principio. Sin embargo, debe tenerse en cuenta que el clasificador utilizado en este caso (
red Inception-v3 ) no es tan frágil como podría parecer a primera vista. Aunque la red probablemente esté equivocada al intentar clasificar un lechón distorsionado, esto solo ocurre en el caso de violaciones especialmente seleccionadas.
La red es mucho más resistente a perturbaciones aleatorias de magnitud comparable. Por lo tanto, la pregunta principal es si son las perturbaciones maliciosas las que causan la fragilidad de las redes. Si la malicia como tal depende críticamente del control sobre cada píxel de entrada, cuando se clasifican las imágenes en condiciones realistas, esas muestras maliciosas no parecen ser un problema grave.
Estudios recientes indican lo contrario: es posible garantizar la estabilidad de las perturbaciones a varios efectos de canal en escenarios físicos específicos. Por ejemplo, las muestras maliciosas se pueden imprimir en una impresora de oficina normal, por lo que las imágenes fotografiadas con la cámara de un teléfono inteligente
aún no se clasifican correctamente . También puede hacer stickers, debido a que las redes neuronales clasifican incorrectamente varias escenas reales (ver, por ejemplo,
link1 ,
link2 y
link3 ). Finalmente, recientemente, los investigadores imprimieron una tortuga 3D en una impresora 3D, que la red Inception estándar
considera erróneamente
un rifle en casi cualquier ángulo de visión.
Preparación de ataque de clasificación errónea¿Cómo crear tales perturbaciones maliciosas? Existen muchos enfoques, pero la optimización nos permite reducir todos estos métodos a una representación generalizada. Como saben, el entrenamiento del clasificador a menudo se formula como encontrar parámetros del modelo
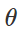
para minimizar la función de pérdida empírica para un conjunto dado de ejemplos

:
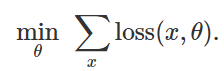
Por lo tanto, para provocar una clasificación errónea para un modelo fijo
y entrada "inofensiva"
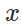
naturalmente, trate de encontrar una perturbación limitada

tal que las pérdidas en

resultó ser el máximo:
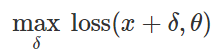
Basado en esta redacción, muchos métodos para crear entradas maliciosas pueden considerarse varios algoritmos de optimización (pasos de gradiente individuales, descenso de gradiente proyectado, etc.) para varios conjuntos de restricciones (pequeño
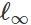
-alteración normal, pequeños cambios en píxeles, etc.). Se dan varios ejemplos en los siguientes artículos:
enlace1 ,
enlace2 ,
enlace3 ,
enlace4 y
enlace5 .
Como se explicó anteriormente, muchos métodos exitosos para generar muestras maliciosas funcionan con un clasificador de destino fijo. Por lo tanto, la pregunta importante es: ¿estas perturbaciones no afectan solo a un modelo objetivo específico? Curiosamente, no. Cuando se utilizan muchos métodos de perturbación, las muestras maliciosas resultantes se transfieren del clasificador al clasificador entrenado con un conjunto diferente de valores aleatorios iniciales (semillas aleatorias) o arquitecturas de modelos diferentes. Además, puede crear muestras maliciosas que solo tienen acceso limitado al modelo de destino (a veces en este caso hablan de "ataques de caja negra"). Ver, por ejemplo, los siguientes cinco artículos:
link1 ,
link2 ,
link3 ,
link4 y
link5 .
No solo fotosLas muestras maliciosas se encuentran no solo en la clasificación de imágenes. Se conocen fenómenos similares en el
reconocimiento de voz , en
los sistemas de preguntas y respuestas , en el
aprendizaje reforzado y en la resolución de otros problemas. Como ya sabe, el estudio de muestras maliciosas se ha llevado a cabo durante más de diez años:
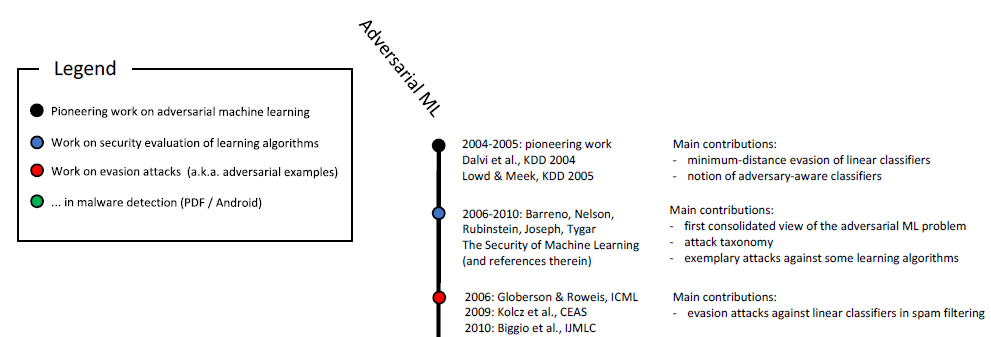
Escala cronológica del aprendizaje automático malicioso (inicio). La escala completa se muestra en la fig. 6 en
este estudio .
Además, las aplicaciones relacionadas con la seguridad son un medio natural para estudiar los aspectos maliciosos del aprendizaje automático. Si un atacante puede engañar al clasificador y pasar información maliciosa (por ejemplo, correo no deseado o virus) como inofensivo, entonces un detector de correo no deseado o un escáner antivirus basado en aprendizaje automático será
ineficaz . Cabe destacar que estas consideraciones no son puramente académicas. Por ejemplo, el equipo de Google Safebrowsing en 2011 publicó un
estudio de
varios años sobre cómo los atacantes intentaron eludir sus sistemas de detección de malware. Consulte también este
artículo sobre muestras maliciosas en el contexto del filtrado de correo no deseado en el correo GMail.
No solo seguridadTodo el trabajo más reciente sobre el estudio de muestras maliciosas se sustenta claramente en la clave para garantizar la seguridad. Este es un punto de vista razonable, pero creemos que tales muestras deben considerarse en un contexto más amplio.
FiabilidadEn primer lugar, las muestras maliciosas plantean la cuestión de la fiabilidad de todo el sistema. Antes de que podamos discutir razonablemente las propiedades del clasificador desde el punto de vista de la seguridad, debemos asegurarnos de que el mecanismo proporcione una alta precisión de clasificación. Al final, si vamos a implementar nuestros modelos entrenados en escenarios del mundo real, entonces es necesario que demuestren un alto grado de confiabilidad al cambiar la distribución de los datos subyacentes, independientemente de si estos cambios se deben a interferencias maliciosas o solo a fluctuaciones naturales.
En este contexto, las muestras de malware son una herramienta de diagnóstico útil para evaluar la confiabilidad de los sistemas de aprendizaje automático. En particular, el enfoque basado en malware le permite ir más allá del protocolo de evaluación estándar, donde el clasificador entrenado se ejecuta en un conjunto de pruebas cuidadosamente seleccionado (y generalmente estático).
Para que pueda llegar a conclusiones sorprendentes. Por ejemplo, resulta que uno puede crear fácilmente muestras maliciosas sin siquiera recurrir a métodos sofisticados de optimización. En un
artículo reciente, mostramos que los clasificadores de imágenes de vanguardia son sorprendentemente vulnerables a pequeñas transiciones o giros patológicos. (Ver
aquí y
aquí para otros trabajos sobre este tema).

Por lo tanto, incluso si no damos importancia a, por ejemplo, las perturbaciones de la descarga ℓ∞ℓ∞, a menudo surgen problemas de confiabilidad debido a rotaciones y transiciones. En un sentido más amplio, es necesario comprender los indicadores de confiabilidad de nuestros clasificadores antes de que puedan integrarse en sistemas más grandes como componentes verdaderamente confiables.
El concepto de clasificadores.Para comprender cómo funciona un clasificador entrenado, necesita encontrar ejemplos de sus operaciones claramente exitosas o no exitosas. En este caso, las muestras maliciosas ilustran que las redes neuronales entrenadas a menudo no corresponden a nuestra comprensión intuitiva de lo que significa "aprender" un concepto específico. Esto es especialmente importante en el aprendizaje profundo, donde a menudo se reclaman algoritmos y redes biológicamente plausibles cuyo éxito no es inferior al éxito humano (ver, por ejemplo,
aquí ,
aquí o
aquí ). Las muestras maliciosas claramente hacen dudar esto en muchos contextos:
- Al clasificar las imágenes, si el conjunto de píxeles cambia mínimamente o la imagen gira ligeramente, esto difícilmente evitará que una persona la asigne a la categoría correcta. Sin embargo, tales cambios están completamente cortados por los clasificadores más modernos. Si coloca objetos en un lugar inusual (por ejemplo, ovejas en un árbol ), también es fácil asegurarse de que la red neuronal interprete la escena de manera muy diferente a la de un ser humano.
- Si sustituye las palabras necesarias en un pasaje de texto, puede confundir seriamente el sistema de preguntas y respuestas , aunque, desde el punto de vista de una persona, el significado del texto no cambiará debido a tales inserciones.
- A lo largo de este artículo , ejemplos de texto cuidadosamente seleccionados muestran los límites de Google Translate.
En los tres casos, los ejemplos maliciosos ayudan a probar la fortaleza de nuestros modelos actuales y enfatizan en qué situaciones estos modelos actúan de manera completamente diferente de lo que haría una persona.
SeguridadFinalmente, las muestras maliciosas presentan un peligro en áreas donde el aprendizaje automático ya está logrando una cierta precisión en material "inofensivo". Hace solo unos años, tareas como la clasificación de imágenes todavía se realizaban muy mal, por lo que el problema de seguridad en este caso parecía secundario. Al final, el grado de seguridad de un sistema de aprendizaje automático se vuelve significativo solo cuando este sistema comienza a procesar la entrada "inofensiva" con suficiente calidad. De lo contrario, todavía no podemos confiar en sus pronósticos.
Ahora, en varias áreas temáticas, la precisión de tales clasificadores ha mejorado significativamente, y su despliegue en situaciones donde las consideraciones de seguridad son críticas es solo cuestión de tiempo. Si queremos abordar esto de manera responsable, es importante investigar sus propiedades precisamente en el contexto de la seguridad. Pero el tema de la seguridad necesita un enfoque holístico. Forjar algunas características (por ejemplo, un conjunto de píxeles) es mucho más fácil que, por ejemplo, otras modalidades sensoriales, características categóricas o metadatos. Al final, al garantizar la seguridad, es mejor confiar precisamente en esos signos que son difíciles o incluso imposibles de cambiar.
Resultados (¿es demasiado pronto para fallar?)A pesar del progreso impresionante en el aprendizaje automático que hemos visto en los últimos años, es necesario tener en cuenta los límites de las capacidades de las herramientas que tenemos a nuestra disposición. Hay una gran variedad de problemas (por ejemplo, los relacionados con la honestidad, la privacidad o los efectos de retroalimentación), y la confiabilidad es de suma importancia. La percepción y la cognición humanas son resistentes a una variedad de interferencias ambientales de fondo. Sin embargo, las muestras maliciosas demuestran que las redes neuronales aún están muy lejos de una resistencia comparable.
Por lo tanto, estamos seguros de la importancia de estudiar ejemplos maliciosos. Su aplicabilidad en el aprendizaje automático está lejos de limitarse a problemas de seguridad, pero puede servir como un
estándar de diagnóstico para evaluar modelos entrenados. El enfoque que usa muestras maliciosas se compara favorablemente con los procedimientos de evaluación estándar y las pruebas estáticas, ya que identifica fallas potencialmente no obvias. Si queremos comprender la fiabilidad del aprendizaje automático moderno, es importante investigar los últimos logros desde el punto de vista de un atacante (seleccionando correctamente muestras maliciosas).
Mientras nuestros clasificadores fallen incluso con cambios mínimos entre el entrenamiento y la distribución de pruebas, no podemos lograr una confiabilidad garantizada satisfactoria. Al final, nos esforzamos por crear modelos que no solo sean confiables, sino que sean consistentes con nuestras ideas intuitivas sobre lo que significa "estudiar" un problema. Entonces serán seguros, confiables y fáciles de implementar en una amplia variedad de entornos.