Hola% username%!
Más recientemente, la conferencia Highload ++ terminó (gracias de nuevo a todo el equipo de organizadores y
olegbunin personalmente. ¡Fue genial!).
En la víspera de la conferencia, Alexey
Fisher propuso crear un grupo de iniciativa de "acosadores" en la conferencia. Durante los informes, escribimos pequeñas notas que intercambiamos. Algunas notas resultaron ser bastante detalladas y detalladas.
La comunidad en las redes sociales evaluó positivamente este formato, por lo que (con permiso) decidí publicar una sinopsis del primer informe. Si este formato es interesante, entonces puedo preparar varios artículos más.

Condujo
Avito tiene muchos servicios y muchas conexiones entre ellos. Esto causa problemas:
- Muchos repositorios. Es difícil cambiar el código en todas partes a la vez
- Los equipos están limitados por su contexto. Máxima superposición leve y no todo
- Se agrega la fragmentación de los datos.
Una gran cantidad de elementos de infraestructura:
- Registro
- Solicitar rastreo (Jaeger)
- Agregación de errores (centinela)
- Estados / Mensajes / Eventos de Kubernetes
- Límite de carrera / disyuntor (Hystrix)
- Conectividad de servicio (Istio)
- Monitoreo (Grafana)
- Asamblea (Teamcity)
- Comunicación
- Rastreador de tareas
- La documentación
- ...
Hay varias capas; el informe describe solo una (PaaS).
La plataforma tiene 3 partes principales:
- Generadores controlados por cli
- Agregador (colector), que se controla a través de un tablero
- Almacenamiento con disparadores para ciertas acciones.
Tubería estándar de desarrollo de microservicios
CLI-push -> CI -> Bake -> Deploy -> Test -> Canary -> ProductionCLI-push
Durante mucho tiempo enseñó a hacer los desarrolladores correctos. De todos modos, seguía siendo un punto débil.
Automatizado a través de la utilidad cli que ayuda a crear una base para el microservicio:
- Crea un servicio de plantillas (se admiten plantillas para varios PL).
- Implementa automáticamente la infraestructura para el desarrollo local.
- Conecta una base de datos (no requiere configuración, el desarrollador no piensa en el acceso a ninguna base de datos).
- Construcción en vivo
- Generación de disco de autotest.
La configuración se describe en el archivo toml.
Archivo de ejemplo:
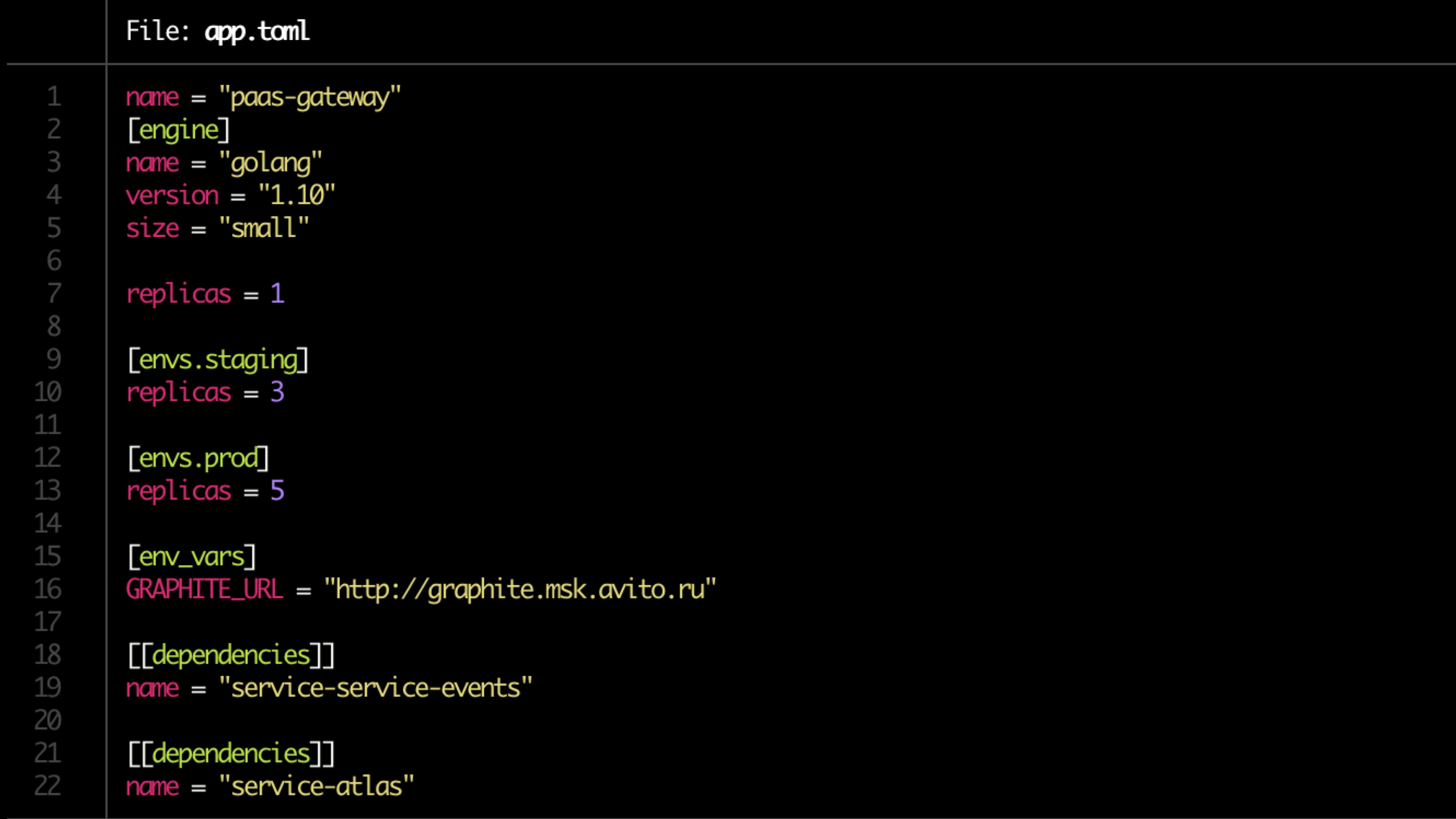
Validación
Comprobaciones básicas de validación:
- Disponibilidad de Dockerfile
- app.toml
- Disponibilidad de documentación
- Dependencias
- Reglas de alerta para el monitoreo (establecido por el propietario del servicio)
La documentación
Todos deberían tener documentación, pero casi nadie la tiene
La documentación debe incluir:
- Descripción del servicio (breve)
- Enlace al diagrama de arquitectura
- Runbook
- FAQ
- Descripción de la API de punto final
- Etiquetas (vinculantes al producto, funcionalidad, división estructural)
- El propietario (s) del servicio (puede haber varios, en la mayoría de los casos se puede determinar automáticamente).
La documentación necesita ser revisada.
Preparación de la tubería
- Repositorios de cocina
- Haciendo una tubería en TeamCity
- Establecemos los derechos
- Estamos buscando al propietario (dos, uno no confiable)
- Servicio de registro en Atlas (producto interno)
- Verifica la migración.
Hornear
- Construyendo la aplicación en la imagen acoplable.
- Generación de gráficos de timón para el servicio en sí y recursos relacionados (DB, caché)
- Se crean tickets para que los administradores abran puertos, se tienen en cuenta las restricciones de memoria y CPU.
- Ejecute pruebas unitarias. Se mantiene la cobertura del código. Si está por debajo de cierto, entonces la implementación finaliza. Si la cobertura no progresa, se envían notificaciones.
La búsqueda del propietario está determinada por la inserción (la cantidad de inserción y la cantidad de código en ellas).
Si hay migraciones potencialmente peligrosas (alterar), el disparador se registra en el Atlas y el servicio se pone en cuarentena.
La cuarentena se resuelve mediante la inserción a los propietarios (en modo manual?)
Verificación de convenciones
Comprobamos:
- Punto final de servicio
- Correspondencia de respuestas al esquema
- Formato de registro
- Configuración de encabezados (incluyendo X-Source-ID cuando se envían mensajes al bus para rastrear la conectividad a través del bus)
Pruebas
La prueba se realiza en un circuito cerrado (por ejemplo, hoverfly.io): se registra una carga típica. Luego se emula en un circuito cerrado.
Se verifica la correspondencia del consumo de recursos (observamos por separado los casos extremos, muy pocos / muchos recursos), cortada por rps.
La prueba de carga también muestra un delta de rendimiento entre versiones.
Pruebas canarias
Comenzamos el lanzamiento con un número muy pequeño de usuarios (<0.1%).
Carga mínima 5 minutos. Los principales 2 horas. Luego, el volumen de usuarios aumenta si todo está bien.
Buscamos:
- Métricas del producto (en primer lugar): hay muchas de ellas (100500)
- Errores centinela
- Estados de respuesta,
- Tiempo de los encuestados: tiempo de respuesta exacto y promedio
- Latencia
- Excepciones (procesadas y sin procesar)
- Más específico para el lenguaje métrico (por ejemplo, trabajadores php-fpm)
Prueba de compresión
Pruebas de extrusión.
Cargamos usuarios reales 1 instancia hasta el punto de falla. Nos fijamos en su techo. A continuación, agregue otra instancia y cárguela. Nos fijamos en el siguiente techo. Nos fijamos en la regresión. Enriquecemos o reemplazamos datos de pruebas de carga en Atlas.
Escalamiento
Solo la CPU es mala, debe agregar métricas de producto.
El esquema final:
- CPU + RAM
- Numero de solicitudes
- Tiempo de respuesta
- Pronóstico Histórico
Al escalar, no olvide mirar las dependencias del servicio. Recuerda la cascada de escala (nivel +1). Observamos los datos históricos del servicio de inicialización.
Opcional
- Manejo de disparadores: migraciones si no queda ninguna versión debajo de X
- El servicio no ha sido actualizado por mucho tiempo
- Cuarentena
- Actualizaciones seguras
Tablero de instrumentos
Observamos todo desde arriba en forma agregada y sacamos conclusiones.
- Servicio y filtrado de etiquetas
- Integración con rastreo, registro, monitoreo
- Documentación de servicio de punto único
- Un único punto de visualización de todos los eventos de servicio.
Un ejemplo:
