Vladimir Ivanov vivanov879 , Sr. El ingeniero de aprendizaje profundo de NVIDIA continúa hablando sobre el aprendizaje por refuerzo. Este artículo se centrará en entrenar al agente para completar misiones y cómo las redes neuronales usan filtros para reconocer imágenes.
En un
artículo anterior, se discutió la capacitación de agentes para tiradores simples.
Vladimir hablará sobre la aplicación del aprendizaje reforzado en la práctica en la
Conferencia de AI el 22 de noviembre.
La última vez que vimos ejemplos de videojuegos, donde el entrenamiento de refuerzo ayuda a resolver el problema. Curiosamente, para el juego exitoso de la red neuronal, solo se necesitaba información visual. Cada red neuronal de cuarto cuadro analiza la captura de pantalla y toma una decisión.
A primera vista, parece magia. Una determinada estructura compleja, que es una red neuronal, recibe una imagen en la entrada y emite la solución correcta. Veamos qué sucede dentro: ¿qué convierte un conjunto de píxeles en acción?
Antes de pasar a la computadora, descubramos lo que ve una persona.Cuando una persona mira una imagen, su mirada se aferra a pequeños detalles (caras, figuras de personas, árboles) y a la imagen en su conjunto. Ya sea un juego de niños en el callejón o un partido de fútbol, una persona puede comprender el contenido, el estado de ánimo y el contexto de la imagen en función de su experiencia de vida.

Cuando admiramos el trabajo de un maestro en una galería de arte, nuestra experiencia de vida aún nos dice que los personajes están ocultos detrás de capas de pintura. Puedes adivinar sus intenciones y movimiento en la imagen.

En el caso de la pintura abstracta, el ojo encuentra figuras simples en la imagen: círculos, triángulos, cuadrados. Son mucho más fáciles de encontrar. A veces esto es todo lo que se puede ver.

Los elementos se pueden organizar para que la imagen tome un tono inesperado.

Es decir, podemos percibir la imagen como un todo, abstrayéndose de sus componentes específicos. A diferencia de nosotros, una computadora inicialmente no tiene esta capacidad. Tenemos una gran experiencia en la vida que nos dice qué artículos son importantes y qué propiedades físicas tienen. Pensemos cómo dotar a la máquina de una herramienta para que pueda estudiar imágenes.
Muchos propietarios felices de teléfonos con cámaras de alta calidad antes de publicar una foto de un teléfono en una red social imponen varios filtros. Usando el filtro, puede cambiar el estado de ánimo de la foto. Puede resaltar algunos objetos más claramente.
Además, el filtro puede resaltar los bordes de los objetos en la foto.
Dado que los filtros tienen esta capacidad de resaltar diferentes objetos en una imagen, démosle a la computadora la oportunidad de recogerlos. ¿Qué es una imagen digital? Esta es una matriz cuadrada de números, en cada punto de los cuales hay valores de intensidad para tres canales de color: rojo, verde y azul. Ahora le daremos a la red neuronal, por ejemplo, 32 filtros. Cada filtro a su vez se superpone a la imagen. El núcleo del filtro se aplica a los píxeles vecinos.
Inicialmente, los valores centrales de cada filtro son aleatorios. Pero le daremos a las redes neuronales la capacidad de configurarlas dependiendo de la tarea. Después de la primera capa con filtros, podemos poner algunos más. Como tenemos muchos filtros, necesitamos muchos datos para configurarlos. Para esto, es adecuado un gran banco de imágenes marcadas. Por ejemplo, conjunto de datos MSCoco.

La red neuronal ajustará los pesos para resolver este problema. En nuestro caso, para la segmentación de imágenes, es decir, la definición de la clase de cada píxel de imagen. Ahora veamos cómo se verán las imágenes después de cada capa de filtros.
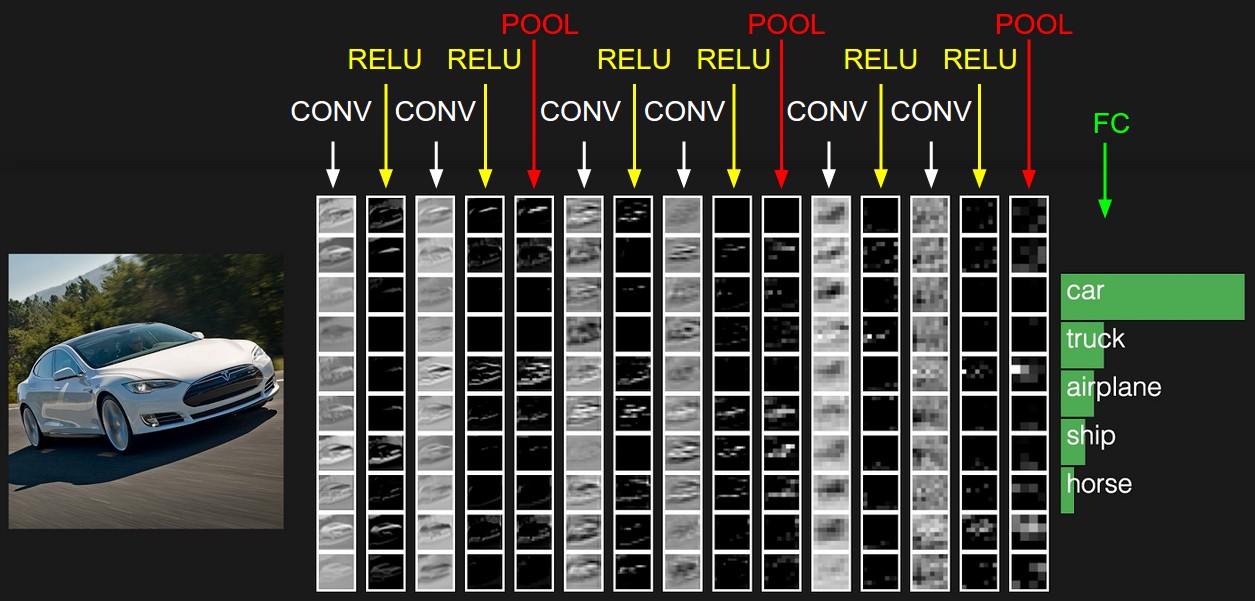
Si observa detenidamente, notará que los filtros abandonan el automóvil en un grado u otro y limpian el área circundante: la carretera, los árboles y el cielo.
De vuelta con el agente que aprende a jugar. Por ejemplo, toma el juego de carreras Mario Kart.
Le dimos una poderosa herramienta de análisis de imágenes: una red neuronal. Veamos qué filtros elige para aprender a montar. Tomemos un área abierta para empezar.
Veamos cómo se ve la imagen después de las primeras 24 películas. Aquí se encuentran en forma de una tabla de 8x3.
Es completamente opcional que cada una de las 24 salidas tenga un significado obvio, porque las imágenes van más allá de la entrada con los siguientes filtros. Las dependencias pueden ser completamente diferentes. Sin embargo, en este caso, puede encontrar algo de lógica en las salidas. Por ejemplo, el segundo filtro en la primera línea resalta la carretera en negro. El primer filtro de la séptima línea duplica su función. Y en la mayoría de los otros filtros, las tarjetas que controlamos son claramente visibles.
En este juego, el área circundante cambia y se encuentra un túnel. ¿A qué presta atención una red neuronal de carreras cuando encuentra una entrada a un túnel?
Las salidas de la primera capa de filtros:
En la sexta línea, el primer filtro resalta la entrada al túnel. Así, durante el viaje, la red aprendió a identificarlos.
¿Y qué pasa cuando la máquina entra al túnel?
El resultado de los primeros 24 filtros:
A pesar de que la iluminación de la escena ha cambiado, así como el entorno, la red neuronal captura lo más importante: la carretera y los mapas. Nuevamente, el segundo filtro en la primera línea, que fue responsable de encontrar el camino al aire libre, en el túnel conserva sus funciones. Y de la misma manera, el primer filtro de la séptima línea, como antes, encuentra el camino.
Ahora que hemos descubierto lo que ve la red neuronal, intentemos usarla para resolver problemas más complejos. Antes de esto, consideramos tareas en las que prácticamente no necesita pensar con anticipación, pero debe resolver el problema que nos enfrenta en este momento. En los juegos de disparos y las carreras, debes actuar "reflexivamente", respondiendo rápidamente a los cambios repentinos en el juego. ¿Qué hay de completar el juego de búsqueda? Por ejemplo, el juego Montezuma Revenge, en el que debes encontrar las llaves y abrir las puertas cerradas para salir de la pirámide.

La vez anterior discutimos que el agente no aprenderá a buscar nuevas llaves y puertas, ya que estas acciones requieren mucho tiempo de juego y, por lo tanto, la señal en forma de puntos recibidos será muy rara. Si usas puntos para enemigos derrotados como recompensa para el agente, él noqueará constantemente cráneos rodantes y no buscará nuevos movimientos.
Recompensemos al agente por abrir nuevas habitaciones. Utilizaremos el hecho conocido a priori de que esta es una búsqueda, y todas las habitaciones son diferentes.

Por lo tanto, si la imagen en la pantalla es fundamentalmente diferente de lo que vimos antes, el agente recibe una recompensa.
Antes de esto, consideramos agentes de juego que se basan únicamente en datos visuales durante el entrenamiento. Pero si tenemos acceso a otros datos del juego, también los usaremos. Considere, por ejemplo, el juego de Dot. Aquí, la red recibe veinte mil números en la entrada, que describen completamente el estado del juego. Por ejemplo, la posición de los aliados, la salud de las torres.

Los jugadores se dividen en dos equipos, cinco personas cada uno. Un juego dura un promedio de 40 minutos. Cada jugador selecciona un héroe con habilidades únicas. Y cada jugador puede comprar artículos que cambian los parámetros de daño, velocidad y campo de visión.
A pesar de que el juego a primera vista es significativamente diferente de Doom, el proceso de aprendizaje sigue siendo el mismo. Excepto por algunos puntos. Dado que el horizonte de planificación en este juego es más alto que en Doom, procesaremos los últimos 16 cuadros para tomar decisiones. Y la señal de recompensas que recibe el agente será un poco más complicada. Incluye la cantidad de enemigos derrotados, el daño infligido y el dinero ganado en el juego. Para que las redes neuronales jueguen juntas, incluiremos el bienestar de los miembros del equipo de agentes como recompensa.
Como resultado, el equipo de bots
derrota a equipos de personas bastante fuertes, pero pierde ante los campeones. La razón de la derrota es que los bots rara vez jugaban partidos de una hora. Y los juegos con personas reales duraron más que los que se jugaron en simuladores. Es decir, si un agente se encuentra en una situación en la que no se ha entrenado, comienzan a surgir dificultades en él.