Quiero hablar sobre nuestra experiencia en el desarrollo de aplicaciones basadas en la plataforma de búsqueda de texto completo Apache Solr.
Nuestra tarea consistía en desarrollar un sistema de análisis del habla para centros de contacto. El sistema se basa en dos tecnologías básicas: reconocimiento de voz y búsqueda indexada. Para el reconocimiento, utilizamos nuestros motores, y para indexar y buscar, elegimos Solr.
¿Por qué solr? No realizamos nuestra propia investigación comparativa de motores de búsqueda indexados, sino que examinamos cuidadosamente las
opiniones de nuestros colegas . Por supuesto, la elección podría hacerse a favor de Elasticsearch o Sphinx, pero, aparentemente, las estrellas en nuestro proyecto se formaron a favor de Solr, lo "aserramos". Ya durante el curso del proyecto, determinamos que la configuración disponible en Solr es suficiente para configurar nuestras tareas.
Características de nuestro proyecto.
El sistema fue desarrollado para el análisis de las llamadas de los clientes, que se registran en el centro de contacto para monitorear la calidad del servicio. No analiza el sonido, sino el texto obtenido como resultado del reconocimiento automático del diálogo. Los textos de discurso reconocido son fundamentalmente diferentes de los textos que encontramos regularmente en sitios web o correos electrónicos. Incluso con una precisión de reconocimiento del 100%, los textos de habla espontánea reconocida pueden parecer no tener significado.
Esto se debe a dos factores principales. En primer lugar, en el discurso oral, las expresiones no verbales y faciales se usan con mucha frecuencia, lo cual no se reconoce en el texto, pero es importante para comprender lo que se ha dicho. En segundo lugar, en el habla, se usan constantemente abreviaturas y omisiones de las estructuras del lenguaje, que pueden restaurarse del contexto de una situación comunicativa. Este fenómeno en lingüística se llama elipsis.
Para ver con sus propios ojos el texto del discurso reconocido con todas sus características, mire los subtítulos automáticos del video en YouTube con el sonido apagado. Se trata de este contenido, el material va a la entrada del sistema de análisis de voz.
Consultas complicadas
Aunque Solr admite
declaraciones y
agrupaciones condicionales estándar, a menudo estas capacidades no son suficientes para implementar todos los escenarios para los analistas.
A menudo, el analista necesita construir una consulta con parámetros no incluidos en el índice Solr. Por ejemplo, encuentre todas las palabras "gracias" que se pronunciaron en los últimos 30 segundos de la conversación. Solr indexa las palabras, pero no las posiciones temporales de las palabras. Llamamos a estas consultas "complejas": consultas que incluyen los parámetros del índice Solr y cualquier otro parámetro de selección de datos que no esté incluido en el índice Solr.
¿Cómo hace un analista consultas?
El analista no tiene una idea sobre la composición del índice Solr, es importante para él buscar y atravesar todos los atributos de los fonogramas de las llamadas y sus transcripciones de texto. Por lo tanto, el concepto de "consulta compleja" para el analista es puramente pragmático: las consultas en las que hay muchos parámetros de selección, o las consultas se organizan en una jerarquía.
Al describir las acciones del analista en el lenguaje de la teoría de conjuntos, se puede decir que con la ayuda de consultas, el analista explora las relaciones entre diferentes subconjuntos: intersecciones, diferencias, adiciones. Mediante consultas jerárquicas, el analista analiza la matriz de datos al nivel de detalle requerido de su estructura.
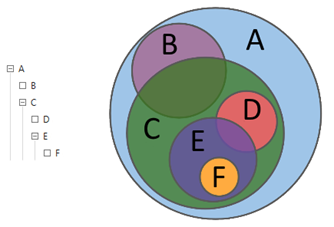 Figura 1. Consultas jerárquicas
Figura 1. Consultas jerárquicasLa Figura 2 muestra un ejemplo clásico de una consulta compleja que contiene criterios de selección textuales y numéricos.
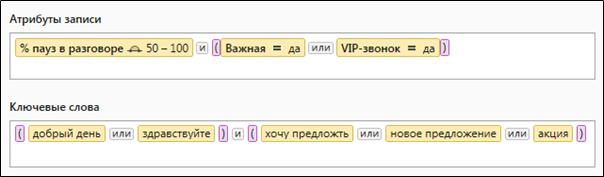 Figura 2. Una consulta compleja que contiene parámetros de selección de datos cuantitativos y léxicos
Figura 2. Una consulta compleja que contiene parámetros de selección de datos cuantitativos y léxicos¿Cómo son las consultas para Solr?
Considere el mecanismo general para ejecutar una consulta en Solr usando el ejemplo de la consulta
B en la Figura 1. Como podemos ver, la consulta
B tiene una consulta primaria
A , en otras palabras
B⊆A . En el análisis del habla, una solicitud no se puede cumplir mientras que al menos uno de sus "padres" no se ha cumplido. Por lo tanto, la consulta
A se ejecuta primero, y solo luego
B. Obviamente,
B debe contener las condiciones de la consulta
A.Lo primero que viene a la mente es combinar las condiciones de ambas consultas a través de
AND y pegarlo en la
query :
q=key:A AND key:BSin embargo, si simplemente combinamos todas las consultas consecutivas en una sola
query , será grande, será diferente para cada consulta y se calculará en su totalidad. Además, las condiciones
A afectarán la relevancia de los resultados de la consulta
B , lo que no sería deseable.
Intentemos agregar consultas principales como
FilterQuery . En este caso, la consulta
A no se verá afectada por la falta de relevancia y podemos esperar que ya se haya completado y sus resultados estén en la memoria caché. Por lo tanto, Solr tendrá que calcular solo la consulta
B , mientras que Solr ordenará la selección resultante de la manera que necesitamos:
q=keyword:B &fq=keyword:ASi consideramos el formato de la solicitud para Solr esquemáticamente, podemos distinguir dos entidades principales:
MainQuery : la consulta principal con un conjunto de parámetros que el documento debe satisfacer. Por ejemplo, una solicitud de búsqueda para operadores educados se vería así: text_operator: ” ” .
Esto significa que el campo text_operator del documento de búsqueda debe contener la frase “ ”
FilterQuery : un conjunto de filtros adicionales que limitan la selección resultante. FilterQuery formato MainQuery coincide con MainQuery
Dividir la solicitud en
Main y
Filter permite:
- indique explícitamente qué parámetros de consulta deberían afectar el rango del documento en la selección y cuáles sirven solo para la selección en la selección resultante. La relevancia para generar el rango de documentos se calcula cuando se ejecuta la parte de la consulta
FilterQuery y cuando se ejecuta la parte de la consulta FilterQuery documentos que no cumplen con las condiciones de la consulta - reduce significativamente la carga en el motor de búsqueda, ya que la muestra resultante obtenida después de los cálculos de
FilterQuery se almacena en caché por completo, mientras que los resultados del cálculo de MainQuery se almacenan en la memoria caché solo para los primeros en el rango de 50 valores
MainQuery y
FiletrQuery tienen diferentes efectos en las funciones de Solr. Por ejemplo, para
resaltar , la función responsable de resaltar fragmentos de documentos relevantes, solo
MainQuery y los parámetros
FilterQuery no afectan el
highlighting . Esto es lógico, porque la relevancia se calcula exactamente en la parte de la consulta
MainQuery . Así es como se ven los resultados
highlighting en una búsqueda real de textos con las palabras "hola" y "servicios".
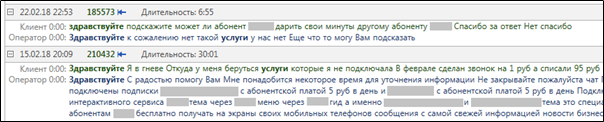 Figura 3. Resaltado de palabras relevantes después de completar una consulta
Figura 3. Resaltado de palabras relevantes después de completar una consulta MainQuery .
Consultas complicadas en Solr
Volvamos al ejemplo de un operador cortés. En este ejemplo, determinamos las llamadas apropiadas por la presencia de la frase "buenas tardes" en el discurso del operador, pero no indicamos el intervalo de tiempo en el que buscar palabras clave relacionadas con el comienzo o el final de la conversación.
Parece que hay todo lo necesario para esto: la transcripción del texto de la conversación telefónica contiene la marca de tiempo de cada palabra, así como información sobre a cuál de los participantes en el diálogo pertenece. Estos datos también se pueden usar en la búsqueda.
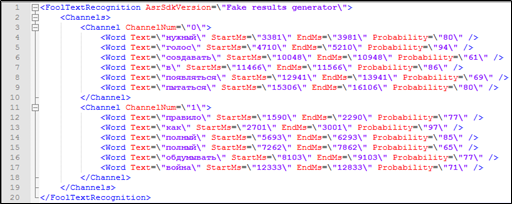 Figura 4. Un fragmento de descifrado textual con marcado que no está incluido en el índice Solr: afiliación del orador, marcas de tiempo.
Figura 4. Un fragmento de descifrado textual con marcado que no está incluido en el índice Solr: afiliación del orador, marcas de tiempo.Pero, ¿cómo procesar una consulta de búsqueda a Solr si hay parámetros no indexables involucrados en la consulta? ¿Cuándo se pronuncia la palabra?
Surgen dos formas obvias de resolver este problema:
- agregue parámetros no indexados al índice Solr. Al mismo tiempo, el consumo de memoria aumentará ligeramente, pero el índice será significativamente más pesado.
- La selección de datos por parámetros no indexables debe llevarse a cabo utilizando su servicio, y en la recopilación de documentos obtenidos después de dicha selección, buscar utilizando el índice Solr. Al mismo tiempo, el consumo de memoria será significativamente mayor que en el primer caso, pero el rendimiento será predecible.
Hemos elegido la segunda opción. Para hacer esto, hemos desarrollado un servicio que calcula colecciones mediante solicitudes que contienen parámetros lógicos y numéricos que no están incluidos en el índice Solr. Como resultado del trabajo de este servicio, la parte de la colección que no satisfizo la solicitud se marcó con una etiqueta especial ("escapado") y luego no participó en el cálculo de los resultados de la consulta.
Imagine que queremos imponer una restricción en la búsqueda en la consulta
B que ya conocemos, solo en los primeros 30 segundos del diálogo. En la primera etapa, ejecutamos
B como una simple consulta, luego "filtramos" las palabras que van más allá del rango seleccionado para que no entren en el índice Solr, pero al mismo tiempo, podemos restaurar el documento original a partir de ellas. Los documentos resultantes se colocan en una colección Solr separada y la búsqueda de la consulta
B se reinicia en ella.
Aquí debo decir que las restricciones al comienzo o al final de la conversación son flores, las bayas son restricciones en los resultados de la solicitud de los padres. Considere la ejecución de tal solicitud.
Imagine que nuestros documentos consisten en bolas con números. Tratemos de encontrar todas las bolas "6" ubicadas en no más de dos bolas a la derecha de "5".
Ya te diste cuenta de que los números de las bolas están incluidos en el índice Solr, y que no hay distancia entre las bolas.
|  |
Encuentre todos los documentos con bolas "6" y "5". Como MainQuery usamos una consulta para bolas "5", y una consulta para "6" la enviaremos a FilterQuery . Como resultado, Solr resaltará las bolas "5" en los resultados de búsqueda, lo que simplificará enormemente nuestra vida en el siguiente paso. | 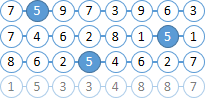 |
| Detectamos todas las bolas excepto las que están a la distancia deseada de "5". Los documentos recibidos (documentos con las bolas deseadas) se colocarán en una colección separada. |  |
FilterQuery en las bolas "6" en la colección resultante, el resultado son los documentos que estamos FilterQuery . |  |
En la práctica, las bolas 5 y 6 generalmente ocultan consultas que ocupan varias pantallas en su representación textual. Me alegra que hayamos implementado esta búsqueda no en vano: los analistas a menudo usan consultas con restricciones de los padres.
Conclusión
¿Qué aprendimos, qué aprendimos y qué logramos como resultado del proyecto?
Sabemos cómo usar Solr de manera efectiva para trabajar con datos de varios tipos, podemos "enseñar" a Solr a procesar consultas con parámetros que no están incluidos en su índice de búsqueda.
Hemos desarrollado un sistema de análisis de voz industrial que funciona bajo una gran carga: las consultas complejas de búsqueda de analistas se calculan para muestras de hasta cinco millones de documentos de texto. Es posible y más, pero no había necesidad práctica. La muestra de trabajo habitual del analista es de aproximadamente 500 mil textos de llamadas telefónicas reconocidas, y el número total de llamadas puede alcanzar los 15 millones.
Para nuestros clientes en centros de contacto, el sistema ofrece oportunidades sin precedentes para análisis de una naturaleza muy diferente: análisis de temas y razones para solicitudes, análisis de satisfacción del cliente y muchos otros.
Ahora estamos conectando nuevas fuentes a nuestros análisis: chats de texto de clientes con operadores. Implementamos una única aplicación para el análisis de llamadas de clientes en todos los canales del centro de contacto: teléfono, chat, formularios en sitios, etc.
Estaremos encantados de responder a sus preguntas.
Gracias
PS Solr es algo muy difícil y requiere un buen ajuste para obtener buenos resultados. Hablaremos sobre nuestra experiencia en este campo en los siguientes artículos.