Ya le contamos sobre
estadísticas interesantes
de textos ,
revisamos artículos sobre el uso de autocodificadores en el análisis de textos y nos sorprendimos con nuestros nuevos algoritmos de
búsqueda de préstamos transferibles y
paráfrasis . Decidí continuar nuestra tradición corporativa y, en primer lugar, comenzar el artículo con “T” y, en segundo lugar, contar:
- cómo encontrar rápidamente un párrafo de texto entre cientos de millones de artículos;
- en qué se convierte el documento después de cargarlo en el sistema antiplagio, y qué hacer a continuación;
- cómo se forma un informe que casi nadie mira, pero que valdría la pena;
- cómo indexar no todos, pero lo suficiente.

Como empezó todo
En 2005, el rector de una de las universidades más grandes de Moscú se nos
acercó en
Forecsys para resolver un problema muy grave: en las instituciones educativas, los estudiantes aprobaron diplomas y documentos académicos totalmente cancelados. Tomamos varios cientos de trabajos de excelentes estudiantes y los buscamos en la red con consultas simples. Más de la mitad de los
"excelentes estudiantes" resultaron ser estafadores que descargaron un diploma de Internet y reemplazaron solo la página del título. ¡Más de la mitad de los excelentes estudiantes, Karl! Lo que les sucedió a los estudiantes comunes es difícil de imaginar. La forma más fácil de buscar un trabajo es una consulta que contenga palabras con "agujeros negros". Nos hemos dado cuenta de la magnitud del desastre. Era urgente resolver algo. En ese momento, las universidades extranjeras de habla inglesa ya usaban soluciones de búsqueda de préstamos, pero por alguna razón nadie verificó el trabajo en ruso.
Los jugadores extranjeros no querían adaptar sus soluciones al idioma ruso en ese momento. Como resultado, el 17 de marzo de 2005, comenzó el desarrollo del primer sistema de búsqueda de préstamos internos. La palabra "antiplagio" se acuñó un poco más tarde, y el dominio antiplagiat.ru se registró el 28 de abril de 2005. Planeamos lanzar el sitio antes del 1 de septiembre de 2005, pero, como suele ser el caso con los programadores, no tuvimos tiempo. El cumpleaños oficial de nuestra empresa es el día en que antiplagiat.ru recibió los primeros usuarios, es decir, el 4 de septiembre. Sabes, incluso me alegro de esto, porque durante una fiesta corporativa con motivo del cumpleaños de la empresa, todos pueden celebrar con calma y no preocuparse por el primer día escolar de sus hijos.
Pero algo me distrajo. En 2005, creamos una especie de motor de búsqueda, en el que, a diferencia de Yandex y Google, la consulta no es dos o tres palabras, sino un texto completo que consta de varias oraciones. Por lo tanto, es razonable usar "Anti-plagio" si tiene texto de 1000 caracteres (esto es aproximadamente media página).
Durante el desarrollo del servicio, se realizó un prototipo en php (elemento web) y Microsoft SQL Server (motor de búsqueda). Inmediatamente se hizo evidente que esto no despegaría y que trabajaría lentamente en varios millones de documentos. Por lo tanto, tuve que cortar mi motor de búsqueda. Ahora el sistema está escrito en C # y python, usa PostgreSQL y MongoDB (de hecho, mucho más, pero más sobre eso en el próximo artículo). El motor de búsqueda aún está completamente desarrollado por nosotros.
Ponga Me gusta Escriba en los comentarios si desea aprender sobre la historia del desarrollo del sistema, el cambio en los procesos de la empresa y el hardware en el que el "Anti-plagio" trabajó en diferentes momentos de su vida, y está funcionando ahora.
La palabra que dio el nombre de la empresa ahora se ha convertido en una palabra familiar. A menudo, en un motor de búsqueda, se pueden encontrar expresiones como "verificar el antiplagio", "aumentar el antiplagio". Todos los que están conectados de alguna manera con el campo de la búsqueda de préstamos en Rusia y los países vecinos están tratando de usar la palabra "antiplagio" para aumentarlo en los resultados de búsqueda. A menudo se nos pregunta acerca de otros "antiplagio". Entonces, "Anti-plagio" es uno, es una marca registrada y el nombre de nuestra empresa.
Al comienzo de la implementación del servicio de búsqueda de préstamos, decidimos que trabajaríamos con el texto como una secuencia de caracteres. Varias construcciones semánticas de textos, la búsqueda de significados, el análisis de oraciones, etc., fueron inmediatamente rechazadas. La solución que elegimos ofrece dos grandes ventajas: alta velocidad de búsqueda y un volumen relativamente pequeño de índices de búsqueda.
Actualmente hay tres productos en nuestra línea. Se distinguen por su funcionalidad, pero contienen básicamente el mismo principio de búsqueda de préstamos. En este artículo, hablaré sobre cómo funciona nuestra búsqueda clásica de préstamos: funcionalidad que se ha convertido en la base del servicio desde el principio y que no se ha cambiado conceptualmente hasta ahora. El esquema de búsqueda de préstamos, como puede ver en la imagen, es simple y directo, como dibujar un búho. Primero, obtenemos el documento del usuario, luego extraemos el texto. Luego buscamos préstamos en este texto, obtenemos "revisiones" (como llamamos al informe para un módulo de búsqueda) y, finalmente, recopilamos revisiones en un gran informe, que mostramos como resultado al usuario.
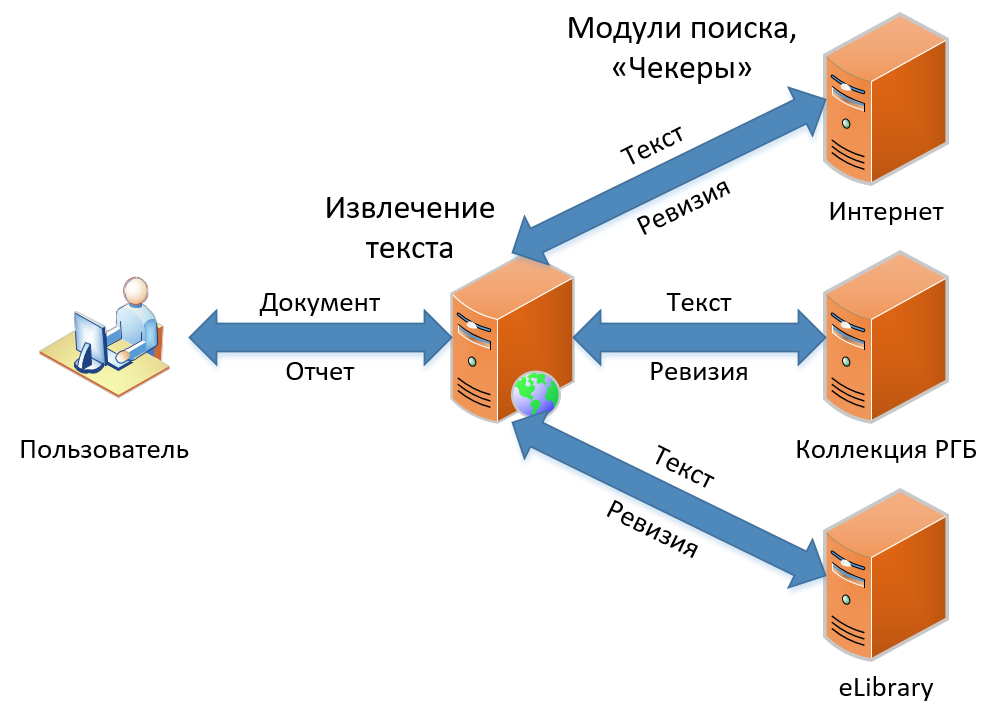
Veamos cómo sucede todo esto en detalle.
Extracción de texto
En primer lugar, "Anti-plagio" es un servicio para buscar solo préstamos de
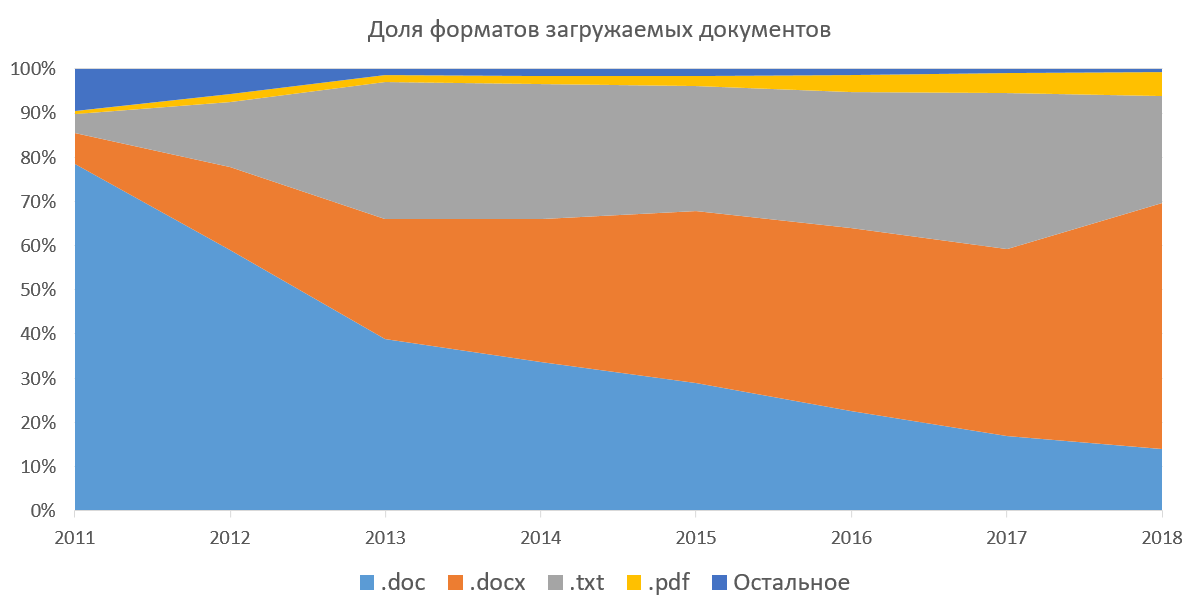
texto , lo que significa que necesitamos extraer texto de todos los documentos para continuar trabajando con él. El sistema admite la capacidad de descargar documentos en docx, doc, txt, pdf, rtf, odt, html, pptx y varios otros formatos (nunca utilizados). También puede descargar todos estos documentos en archivos (7z, zip, rar). Este método fue popular cuando no pudimos cargar varios documentos a la vez a través de la interfaz web. A continuación se muestra un gráfico de la popularidad de los formatos de documentos descargables en la parte corporativa de nuestro sistema. Muestra cómo docx ha sido suplantado por doc durante varios años, y la proporción de pdf está creciendo gradualmente. Si no considera txt (extraer texto es trivial), entonces para nosotros lo más agradable es pdf. En el extranjero, el pdf es el estándar de facto, publica artículos, prepara el trabajo de los estudiantes. Según nuestras estadísticas, el pdf está ganando popularidad gradualmente en Rusia y los países de la CEI. Nosotros mismos estamos promoviendo este formato a las masas, recomendando descargar documentos en él.
Limitamos los formatos de descarga de documentos para clientes privados a pdf y txt, y es por eso que redujimos el consumo de recursos y el costo de apoyar un servicio gratuito. Después de todo, ¿necesita verificar el texto y no probar el sistema? Entonces, ¿cuál es la diferencia en qué formato cargarlo?
La siguiente forma más fácil de extraer texto es docx, porque, de hecho, es un archivo zip con xml dentro, es bastante simple de procesar y se puede hacer mucho a un nivel bajo.
Lo más difícil para nosotros es el doc. Este formato ha estado cerrado durante mucho tiempo, y ahora hay muchas implementaciones. El último Microsoft Word, que no era compatible con .docx (aunque a través del paquete de compatibilidad de Microsoft Office), se lanzó hace 20 años y se incluyó en Microsoft Office 97. El formato usa OLE, que más tarde se convirtió en COM y ActiveX, todo es binario, a veces incompatible entre versiones En general, el terrible sueño de un programador moderno. Es bueno que el formato .doc abandone gradualmente la escena. Creo que ha llegado el momento de ayudarlo a retirarse. Pronto advertiremos deliberadamente a los usuarios que este formato está desactualizado.
Entonces, volviendo al informe. Obtuvimos el archivo y comenzamos a extraer el texto. Junto con el texto, el sistema también extrae las posiciones de las palabras en las páginas para que en el futuro sea posible mostrar a nuestros usuarios el marcado del informe de préstamo en el documento mismo. Además, en la misma etapa, estamos buscando soluciones técnicas para el antiplagio.
Tan pronto como apareció el "Anti-plagio", que muestra el porcentaje de originalidad, hubo personas que querían pasar un cheque para pedir prestado con un mínimo esfuerzo, así como personas que ofrecían dicho servicio por dinero. El problema es que el parámetro numérico pide convertirse en una estimación. Después de todo, es muy simple: en lugar de leer un trabajo utilizando el sistema como herramienta, ¡no lo lea, sino evalúelo por el porcentaje de originalidad! Fue esta desgracia la que dio lugar a una dirección como la optimización de las obras (un cambio en el texto para aumentar el porcentaje de originalidad de la obra). Lea más sobre problemas en los procesos universitarios en el artículo
"Sobre la práctica de detectar préstamos en universidades rusas" .
En los sistemas de búsqueda extranjeros, los problemas de detectar soluciones técnicas y contrarrestarlos prácticamente no valen la pena. El hecho es que la "finta con orejas" descubierta será seguida por un castigo muy duro: la expulsión y una mancha indeleble en la reputación científica, incompatible con una carrera posterior. En nuestro caso, la situación es ridículamente simple: "¡Oh, este sistema estropeó algo!", "¡Oh, no soy yo, es en sí mismo!" Es probable que el estudiante sea enviado a rehacer. El hecho es que descartar, por desgracia, no es algo vergonzoso.
Pero nuevamente distraído. Otra forma de extraer texto es OCR. Imprimimos el documento en una impresora virtual y luego lo reconocemos. Lea más sobre esto en el artículo
"Reconocimiento de imágenes al servicio del antiplagio" .
Ahora un poco de nuestra historia sobre la extracción de textos. Primero, extrajimos textos usando IFilters. Son lentos, solo en Windows, y no devuelven información de formato (no está claro dónde está el texto blanco en el fondo blanco, entonces no puede marcar los bloques de préstamo directamente en el documento del usuario). Pensamos que estos problemas se resolverían si comenzáramos a usar bibliotecas pagas, pero aquí encontramos limitaciones: aún bajo Windows, no ven fórmulas, a veces caen en documentos especialmente preparados (¡bibliotecas diferentes en diferentes!). La siguiente idea fue OCR todos los documentos entrantes, pero este enfoque requiere muchos recursos (procesa solo 10 páginas por minuto en un núcleo) y en algunos lugares el texto no se extrae con precisión.
No encontramos una bala de plata, aunque un par de veces pensamos que era Felicidad. Sin embargo, luego de haber vivido un poco con esto, se dieron cuenta de que nuevamente era una Experiencia. La extracción de texto se equilibra en una línea fina entre el rendimiento (necesita extraer texto de cientos de documentos por minuto), confiabilidad (necesita extraer texto de todo), funcionalidad (formato, soluciones, eso es todo). Ahora todo lo anterior y un poco más de trabajo para nosotros. Estamos constantemente experimentando con esta área y continuamos buscando nuestra Felicidad.
Se extrae el texto, se encuentran rondas y se eliminan parcialmente, ¡partimos para buscar préstamos!
Búsqueda de préstamos
La idea implementada en el procedimiento de búsqueda fue propuesta por Ilya Segalovich y Yuri Zelenkov (puede leer, por ejemplo, en el artículo:
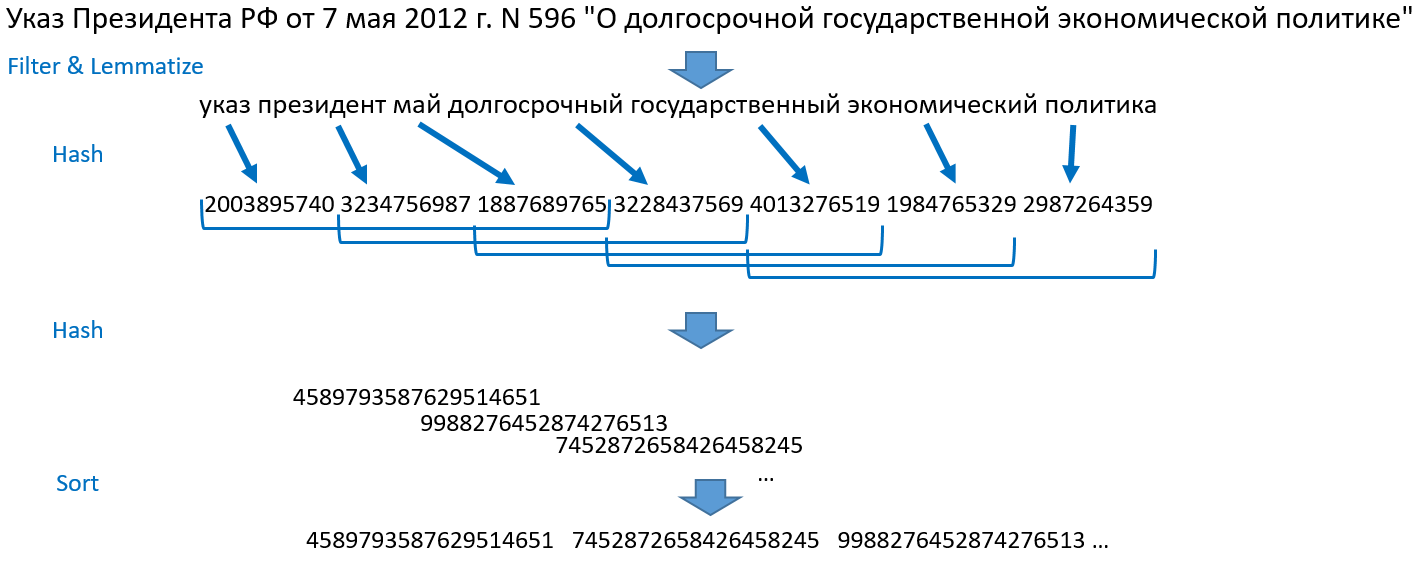
Análisis comparativo de métodos para determinar duplicados difusos para documentos web ). Te diré cómo funciona para nosotros. Tomemos, por ejemplo, la oración: "Decreto del Presidente de la Federación de Rusia del 7 de mayo de 2012 N 596" sobre la política económica estatal a largo plazo "."
- Rompemos oraciones en palabras, tiramos números, signos de puntuación, detenemos palabras. Lematizar (llevar a la forma normal) todas las palabras.
- Convertimos las palabras en números enteros mediante hash, obtenemos una serie de números.
- Tomamos los primeros tres hash, luego el 2º, 3º, 4º hash, luego el 3º, 4º, 5º y así sucesivamente hasta el final del conjunto de hash. Esto es tejas. Este método recibió su nombre debido a los conjuntos superpuestos en mosaico. Fusionamos cada mosaico en un objeto y volvemos a hacer hash
- Ordenamos los números resultantes, obtenemos una matriz ordenada de enteros. Esta es la base de la búsqueda.
Ahora, para la búsqueda, necesitamos una función mágica que, de acuerdo con dicha lista de hashes, convierta los documentos, clasificados en orden descendente del número de hashes coincidentes, en un documento fuente. Esta función debería funcionar rápidamente porque Queremos buscar en miles de millones de documentos. Para encontrar rápidamente dicho conjunto, necesitamos un índice inverso, que por hash devuelve una lista de documentos en los que se encuentra este hash. Hemos implementado una tabla hash tan gigante. A diferencia de nuestros hermanos mayores de búsqueda, almacenamos esta tabla en ssd, no en la memoria. Nos falta bastante ese rendimiento. La búsqueda de índice ocupa una pequeña parte de todo el ciclo de procesamiento de documentos. Vea cómo va la búsqueda:
Etapa 1. Búsqueda de índice
Para cada hash del texto de solicitud, obtenemos una lista de identificadores de los documentos de origen en los que se produce. A continuación, clasificamos la lista de identificadores de documentos de origen por el número de hashes encontrados en el texto de la solicitud. Obtenemos una lista clasificada de documentos candidatos para la fuente del préstamo.
Etapa 2. Construcción de la auditoría.
Para una solicitud de texto grande de candidatos, puede haber aproximadamente 10 mil. Esto todavía es mucho para comparar cada documento con el texto de la solicitud. Actuamos con avidez, pero con decisión. Tomamos el primer documento fuente, hacemos una comparación con el texto de la solicitud y excluimos de todos los demás candidatos los hashes que ya estaban en este primer documento. Eliminamos de la lista de candidatos aquellos que tienen cero hashes, volvemos a clasificar los candidatos de acuerdo con el nuevo número de hashes. Tomamos el primer documento de la nueva lista, lo comparamos con el texto fuente, eliminamos los hashes, eliminamos los candidatos cero, volvemos a clasificar los candidatos. Lo hacemos 10-20 veces, generalmente esto es suficiente para que la lista se agote o solo permanezcan en ella documentos que coincidan con varios hashes.
El uso de hashes de palabras nos permite llevar a cabo operaciones de comparación más rápido, ahorrar en memoria y almacenar no los textos de los documentos fuente, sino sus modelos digitales (TextSpirit, como los llamamos cariñosamente) obtenidos durante la indexación, lo que viola los derechos de autor. La selección de fragmentos de préstamos específicos se realiza utilizando el árbol de sufijos.
Como resultado de la verificación con un módulo de búsqueda, obtenemos una revisión, que contiene una lista de fuentes, sus metadatos y las coordenadas de las unidades de préstamo en relación con el texto de la solicitud.
Informe de montaje
Por cierto, ¿qué pasa si uno de los 10-15 módulos no respondió a tiempo? Buscamos en las colecciones de RSL, eLibrary y Garantor. Estos módulos de búsqueda se encuentran en el territorio de organizaciones de terceros y no pueden transferirse a nuestro sitio por razones de derechos de autor. El punto de falla aquí siempre puede ser un canal de comunicación y varias causas de fuerza mayor en centros de datos no controlados por nosotros. Por un lado, los préstamos se pueden encontrar en cualquier módulo de búsqueda, por otro lado, si uno de los componentes del sistema no está disponible, puede degradar la calidad de la búsqueda, pero dar la mayor parte del resultado, al tiempo que advierte al usuario que el resultado de algunos módulos de búsqueda aún no está listo. ¿Qué opción aplicarías? Aplicamos ambas opciones según corresponda.

Finalmente, se reciben todas las revisiones, comenzamos el ensamblaje del informe. Utiliza un enfoque similar a la preparación de una revisión. Parece que no es nada complicado, pero también hay tareas interesantes. Tenemos dos tipos de préstamos. Las “citas” se indican en verde: citas citadas correctamente (de acuerdo con GOST) del módulo “Citación”, expresiones del tipo “lo que se requería probar” del módulo “Expresiones comunes”, documentos reglamentarios de las bases de datos de Garantes y Lexpro. Todos los demás préstamos están marcados en naranja. Los verdes tienen prioridad sobre las naranjas, a menos que entren en todo el bloque naranja.
Como resultado, el informe se puede comparar con el texto impreso en papel sobre la mesa, sobre el cual se garabatean tiras multicolores (bloques de préstamos y presupuestos), superpuestos entre sí. Lo que vemos arriba es un informe. Tenemos dos indicadores para cada fuente:
La parte del informe es la proporción del volumen de préstamos, que se tiene en cuenta de esta fuente, al volumen total del documento. Si se encontró el mismo texto en varias fuentes, solo se tiene en cuenta en una de ellas. Cuando cambia la configuración del informe (activar o desactivar fuentes), este indicador de la fuente puede cambiar. En total, da el porcentaje de préstamos y citas (dependiendo del color de la fuente).
Compartir en el texto : la proporción del volumen prestado de la fuente dada del texto al volumen total del documento. No tiene sentido resumir los recursos compartidos en el texto por fuentes, resultará fácilmente 146% o incluso más. Este indicador no cambia cuando cambia el informe.
Naturalmente, el informe puede ser editado. Esta es una función especial para el experto que verifica el trabajo para deshabilitar el préstamo de las propias obras del autor (puede parecer que este fragmento no está solo en el trabajo del autor, sino también en otro lugar) y separa los bloques de préstamos, cambie el tipo de fuente pedir prestado para citar. Como resultado de la edición del informe, el experto recibe el valor real de los préstamos. Cualquier trabajo para la verificación debe ser leído. Es conveniente hacer esto mirando la forma original del documento, en la que se marcan los bloques de préstamo, e inmediatamente, mientras lee, edite el informe. Desafortunadamente, esta no es una acción lógica de todos, muchos están satisfechos con el porcentaje de originalidad, sin siquiera mirar el informe.
Sin embargo, retrocedamos un paso y descubramos qué se incluye en el índice del módulo de búsqueda en Internet creado por Anti-Plagiarism.
Indexación de Internet
El antiplagio se centra principalmente en el trabajo de los estudiantes, publicaciones científicas, trabajos de calificación final, disertaciones, etc. Indexamos Internet de manera direccional: buscamos grandes grupos de textos científicos, resúmenes, artículos, disertaciones, revistas científicas, etc. La indexación ocurre así:
- Nuestro robot viene, se presenta y, guiado por robots.txt (tenemos un buen robot), descarga documentos con una carga razonable en cada host (cientos de sitios se están ejecutando al mismo tiempo, por lo que podemos esperar un tiempo entre cargas de página);
- El robot pasa el documento y sus metadatos a la cola de procesamiento, el texto se extrae del documento;
- Se analiza la "calidad" del texto : como recordará del artículo sobre el vertedero, podemos determinar el género del documento, agregar heurística simple al volumen aquí y comprender si nos llegó un texto adecuado o alguna basura;
- El texto cualitativo va más allá y se convierte en hash. Los hashes y metadatos se envían al índice principal de Internet;
- Comparamos el texto recibido con los textos previamente indexados por nosotros. Un novato se agrega solo si es realmente nuevo , es decir 90% - . , url .
Por lo tanto, indexamos textos de alta calidad, y todos los textos indexados son significativamente diferentes para nosotros. El crecimiento del volumen indexado en Internet se muestra en la figura a continuación. Ahora, en promedio, agregamos al índice 15-20 millones de documentos por mes.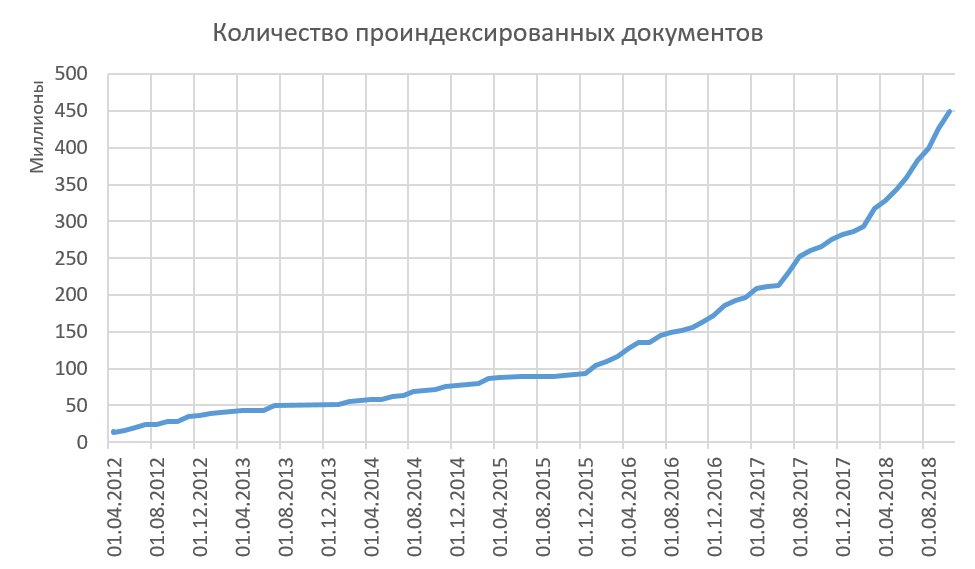 ¿Notó que el procedimiento para eliminar del índice no se describe en ninguna parte? Y ella no lo es! Básicamente no eliminamos documentos del índice. Creemos que si pudiéramos ver algo en Internet, otras personas podrían ver este texto y usarlo de una forma u otra. A este respecto, hay una estadística interesante de lo que una vez estuvo en Internet, y ahora ya no está allí. Sí, ¡imagínese que la expresión "Una vez en Internet permanecerá allí para siempre" no es cierta! Algo desaparece de Internet para siempre. ¿Estás interesado en conocer nuestras estadísticas sobre esto?
¿Notó que el procedimiento para eliminar del índice no se describe en ninguna parte? Y ella no lo es! Básicamente no eliminamos documentos del índice. Creemos que si pudiéramos ver algo en Internet, otras personas podrían ver este texto y usarlo de una forma u otra. A este respecto, hay una estadística interesante de lo que una vez estuvo en Internet, y ahora ya no está allí. Sí, ¡imagínese que la expresión "Una vez en Internet permanecerá allí para siempre" no es cierta! Algo desaparece de Internet para siempre. ¿Estás interesado en conocer nuestras estadísticas sobre esto?Conclusión
Es sorprendente cómo las soluciones técnicas adoptadas hace más de 10 años siguen siendo relevantes. Ahora nos estamos preparando para lanzar la versión 4 del índice, es más rápido, más avanzado tecnológicamente y mejor, sin embargo, se basa en las mismas soluciones. Han aparecido nuevas direcciones de búsqueda: préstamos transferibles, parafraseando, pero nuestro índice también se usa allí, realizando incluso una parte pequeña pero importante del trabajo.Estimados lectores, ¿qué les gustaría saber sobre nuestro servicio?