
En el corazón mismo de los motores de búsqueda Meltwater y
Fairhair.ai se encuentra Elasticsearch, una colección de grupos con miles de millones de artículos de medios y redes sociales.
Los fragmentos de índice en grupos varían mucho en la estructura de acceso, la carga de trabajo y el tamaño, lo que plantea algunos problemas muy interesantes.
En este artículo, describiremos cómo utilizamos la programación lineal (optimización lineal) para distribuir la carga de trabajo de búsqueda e indexación de la manera más uniforme posible en todos los nodos de los clústeres. Esta solución reduce la probabilidad de que un nodo se convierta en un cuello de botella en el sistema. Como resultado, aumentamos la velocidad de búsqueda y ahorramos en infraestructura.
Antecedentes
Los motores de búsqueda de Fairhair.ai contienen alrededor de 40 mil millones de publicaciones de redes sociales y editoriales, que procesan millones de consultas diarias. La plataforma proporciona a los clientes resultados de búsqueda, gráficos, análisis, exportación de datos para un análisis más avanzado.
Estos conjuntos de datos masivos residen en varios grupos Elasticsearch de 750 nodos con miles de índices en más de 50,000 fragmentos.
Para obtener más información sobre nuestro clúster, consulte los artículos anteriores sobre
su arquitectura y el
equilibrador de carga de aprendizaje automático .
Distribución desigual de la carga de trabajo
Tanto nuestros datos como las consultas de los usuarios suelen estar vinculados por fecha. La mayoría de las solicitudes se encuentran dentro de un cierto período de tiempo, por ejemplo, la semana pasada, el mes pasado, el último trimestre o un rango arbitrario. Para simplificar la indexación y las consultas, utilizamos la
indexación de tiempo , similar a
la pila ELK .
Esta arquitectura de índice ofrece varias ventajas. Por ejemplo, puede realizar una indexación masiva eficiente, así como eliminar índices completos cuando los datos son obsoletos. También significa que la carga de trabajo para un índice dado varía mucho con el tiempo.
Exponencialmente más consultas van a los últimos índices, en comparación con los anteriores.
 Fig. 1. Esquema de acceso para índices de tiempo. El eje vertical representa el número de consultas completadas, el eje horizontal representa la antigüedad del índice. Las mesetas semanales, mensuales y anuales son claramente visibles, seguidas de una larga cola de menor carga de trabajo en los índices más antiguos.
Fig. 1. Esquema de acceso para índices de tiempo. El eje vertical representa el número de consultas completadas, el eje horizontal representa la antigüedad del índice. Las mesetas semanales, mensuales y anuales son claramente visibles, seguidas de una larga cola de menor carga de trabajo en los índices más antiguos.Los patrones en la fig. 1 eran bastante predecibles, ya que nuestros clientes están más interesados en información fresca y comparan regularmente el mes actual con el pasado y / o este año con el año pasado. ¡El problema es que Elasticsearch no conoce este patrón y no se optimiza automáticamente para la carga de trabajo observada!
El algoritmo de asignación de fragmentos Elasticsearch incorporado solo tiene en cuenta dos factores:
- El número de fragmentos en cada nodo. El algoritmo intenta equilibrar de manera uniforme el número de fragmentos por nodo en todo el clúster.
- Etiquetas de espacio libre en disco. Elasticsearch considera el espacio en disco disponible en un nodo antes de decidir si asignar nuevos fragmentos a este nodo o mover segmentos de este nodo a otros. Con el 80% del disco utilizado, está prohibido colocar fragmentos nuevos en un nodo, el 90% del sistema comenzará a transferir fragmentos activamente desde este nodo.
La suposición fundamental del algoritmo es que cada segmento del clúster recibe aproximadamente la misma cantidad de carga de trabajo y que todos tienen el mismo tamaño. En nuestro caso, esto está muy lejos de la verdad.
El equilibrio de carga estándar conduce rápidamente a puntos calientes en el clúster. Aparecen y desaparecen al azar, a medida que la carga de trabajo cambia con el tiempo.
Una zona activa es esencialmente un host que opera cerca de su límite de uno o más recursos del sistema, como una CPU, E / S de disco o ancho de banda de red. Cuando esto sucede, el nodo primero pone en cola las solicitudes durante un tiempo, lo que aumenta el tiempo de respuesta a la solicitud. Pero si la sobrecarga dura mucho tiempo, en última instancia, las solicitudes se rechazan y los usuarios obtienen errores.
Otra consecuencia común de la congestión es la presión inestable de la basura JVM debido a consultas y operaciones de indexación, lo que lleva al fenómeno del "infierno aterrador" del recolector de basura JVM. En tal situación, la JVM no puede recuperar la memoria lo suficientemente rápido y se queda sin memoria, o se atasca en un ciclo interminable de recolección de basura, se congela y deja de responder a las solicitudes y pings del clúster.
El problema empeoró cuando
reestructuramos nuestra arquitectura bajo AWS . Anteriormente, estábamos "salvados" por el hecho de que ejecutamos hasta cuatro nodos Elasticsearch en nuestros propios servidores potentes (24 núcleos) en nuestro centro de datos. Esto enmascara la influencia de la distribución asimétrica de los fragmentos: la carga se suavizó en gran medida por un número relativamente grande de núcleos en la máquina.
Después de refactorizar, colocamos solo un nodo a la vez en máquinas menos potentes (8 núcleos), y las primeras pruebas revelaron de inmediato grandes problemas con los "puntos calientes".
Elasticsearch asigna fragmentos en orden aleatorio, y con más de 500 nodos en un clúster, la probabilidad de que haya demasiados fragmentos "activos" en un solo nodo ha aumentado considerablemente, y dichos nodos se han desbordado rápidamente.
Para los usuarios, esto significaría un grave deterioro en el trabajo, ya que los nodos congestionados responden lentamente y, a veces, rechazan por completo las solicitudes o se bloquean. Si pone en marcha un sistema de este tipo, los usuarios verán frecuentes, al parecer, ralentizaciones de la interfaz de usuario aleatorias y tiempos de espera aleatorios.
Al mismo tiempo, queda una gran cantidad de nodos con fragmentos sin mucha carga, que en realidad están inactivos. Esto lleva a un uso ineficiente de nuestros recursos de clúster.
Ambos problemas podrían evitarse si Elasticsearch distribuye fragmentos de manera más inteligente, ya que el uso promedio de los recursos del sistema en todos los nodos se encuentra en un nivel saludable del 40%.
Cambio continuo de clúster
Al trabajar más de 500 nodos, observamos una cosa más: un cambio constante en el estado de los nodos. Los fragmentos se mueven constantemente hacia adelante y hacia atrás en los nodos bajo la influencia de los siguientes factores:
- Se crean nuevos índices y se descartan los antiguos.
- Las etiquetas de disco se activan debido a la indexación y otros cambios de fragmentos.
- Elasticsearch aleatoriamente decide que hay muy pocos o demasiados fragmentos en el nodo en comparación con el valor promedio del clúster.
- Los bloqueos de hardware y bloqueos a nivel del sistema operativo hacen que se inicien nuevas instancias de AWS y las unan al clúster. Con 500 nodos, esto sucede en promedio varias veces a la semana.
- Se agregan nuevos sitios casi todas las semanas debido al crecimiento normal de los datos.
Con todo esto en cuenta, llegamos a la conclusión de que una solución compleja y continua de todos los problemas requiere un algoritmo de re-optimización continuo y dinámico.
Solución: Shardonnay
Después de un largo estudio de las opciones disponibles, llegamos a la conclusión de que queremos:
- Crea tu propia solución. No encontramos ningún buen artículo, código u otras ideas existentes que funcionen bien en nuestra escala y para nuestras tareas.
- Inicie el proceso de reequilibrio fuera de Elasticsearch y use las API de redireccionamiento agrupadas en lugar de intentar crear un complemento . Queríamos un ciclo de retroalimentación rápido, y la implementación de un complemento en un clúster de esta escala puede llevar varias semanas.
- Use la programación lineal para calcular los movimientos óptimos de fragmentos en cualquier momento dado.
- Realice la optimización continuamente para que el estado del clúster llegue gradualmente al óptimo.
- No muevas demasiados fragmentos a la vez.
Notamos algo interesante: si mueve demasiados fragmentos al mismo tiempo, es muy fácil desencadenar una
tormenta en cascada de movimiento de fragmentos . Después del inicio de tal tormenta, puede continuar durante horas, cuando los fragmentos se mueven incontrolablemente hacia adelante y hacia atrás, causando la aparición de marcas sobre el nivel crítico de espacio en disco en varios lugares. A su vez, esto conduce a nuevos movimientos de fragmentos, etc.
Para comprender lo que está sucediendo, es importante saber que cuando mueve un segmento indexado activamente, en realidad comienza a utilizar mucho más espacio en el disco desde el que se mueve. Esto se debe a cómo Elasticsearch almacena
los registros de transacciones . Hemos visto casos en los que al mover un nodo, el índice se duplicó. Esto significa que el nodo que inició el movimiento de fragmentos debido al uso elevado de espacio en disco utilizará
aún más espacio en disco durante un tiempo hasta que mueva suficientes fragmentos a otros nodos.
Para resolver este problema, desarrollamos el servicio
Shardonnay en honor a la famosa variedad de uva Chardonnay.
Optimización lineal
La optimización lineal (o
programación lineal , LP) es un método para lograr el mejor resultado, como el beneficio máximo o el costo más bajo, en un modelo matemático cuyos requisitos están representados por relaciones lineales.
El método de optimización se basa en un sistema de variables lineales, algunas restricciones que deben cumplirse y una función objetivo que determina cómo se ve una solución exitosa. El objetivo de la optimización lineal es encontrar los valores de las variables que minimizan la función objetivo, sujeto a restricciones.
Distribución de fragmentos como un problema de optimización lineal
Shardonnay debería funcionar continuamente, y en cada iteración realiza el siguiente algoritmo:
- Utilizando la API, Elasticsearch recupera información sobre fragmentos, índices y nodos existentes en el clúster, así como su ubicación actual.
- Modela el estado de un clúster como un conjunto de variables LP binarias. Cada combinación (nodo, índice, fragmento, réplica) obtiene su propia variable. En el modelo LP, hay una serie de heurísticas, restricciones y una función objetivo cuidadosamente diseñadas, más sobre esto a continuación.
- Envía el modelo LP a un solucionador lineal, que ofrece una solución óptima teniendo en cuenta las restricciones y la función objetivo. La solución es reasignar fragmentos a nodos.
- Interpreta la solución del LP y la convierte en una secuencia de movimientos de fragmentos.
- Indica a Elasticsearch que mueva fragmentos a través de la API de redireccionamiento de clúster.
- Espera a que el grupo mueva los fragmentos.
- Regresa al paso 1.
Lo principal es desarrollar las restricciones correctas y la función objetivo. El resto lo hará Solver LP y Elasticsearch.
¡No es sorprendente que la tarea fuera muy difícil para un grupo de este tamaño y complejidad!
Limitaciones
Basamos algunas restricciones en el modelo basado en las reglas dictadas por Elasticsearch. Por ejemplo, siempre adhiérase a las etiquetas del disco o prohíba colocar una réplica en el mismo nodo que otra réplica del mismo fragmento.
Otros se agregan en base a la experiencia adquirida durante años de trabajo con grandes grupos. Aquí hay algunos ejemplos de nuestras propias limitaciones:
- No mueva los índices de hoy, ya que son los más populares y obtienen una carga casi constante en lectura y escritura.
- Da preferencia a mover fragmentos más pequeños, porque Elasticsearch los maneja más rápido.
- Es recomendable crear y colocar fragmentos futuros unos días antes de que se activen, comiencen a indexarse y sufran una gran carga.
Función de costo
Nuestra función de costos sopesa una serie de factores diferentes. Por ejemplo, queremos:
- minimizar la variación de las consultas de indexación y búsqueda para reducir el número de "puntos críticos";
- mantener la variación mínima del uso del disco para un funcionamiento estable del sistema;
- minimice el número de movimientos de fragmentos para que no comiencen las "tormentas" con una reacción en cadena, como se describió anteriormente.
Reducción de variables LP
En nuestra escala, el tamaño de estos modelos LP se convierte en un problema. Rápidamente nos dimos cuenta de que los problemas no podían resolverse en un tiempo razonable con más de 60 millones de variables. Por lo tanto, aplicamos muchos trucos de optimización y modelado para reducir drásticamente el número de variables. Entre ellos se encuentran el muestreo sesgado, la heurística, el método de divide y vencerás, la relajación iterativa y la optimización.
 Fig. 2. El mapa de calor muestra la carga desequilibrada en el clúster Elasticsearch. Esto se manifiesta en una gran dispersión del uso de recursos en el lado izquierdo del gráfico. A través de la optimización continua, la situación se estabiliza gradualmente.
Fig. 2. El mapa de calor muestra la carga desequilibrada en el clúster Elasticsearch. Esto se manifiesta en una gran dispersión del uso de recursos en el lado izquierdo del gráfico. A través de la optimización continua, la situación se estabiliza gradualmente.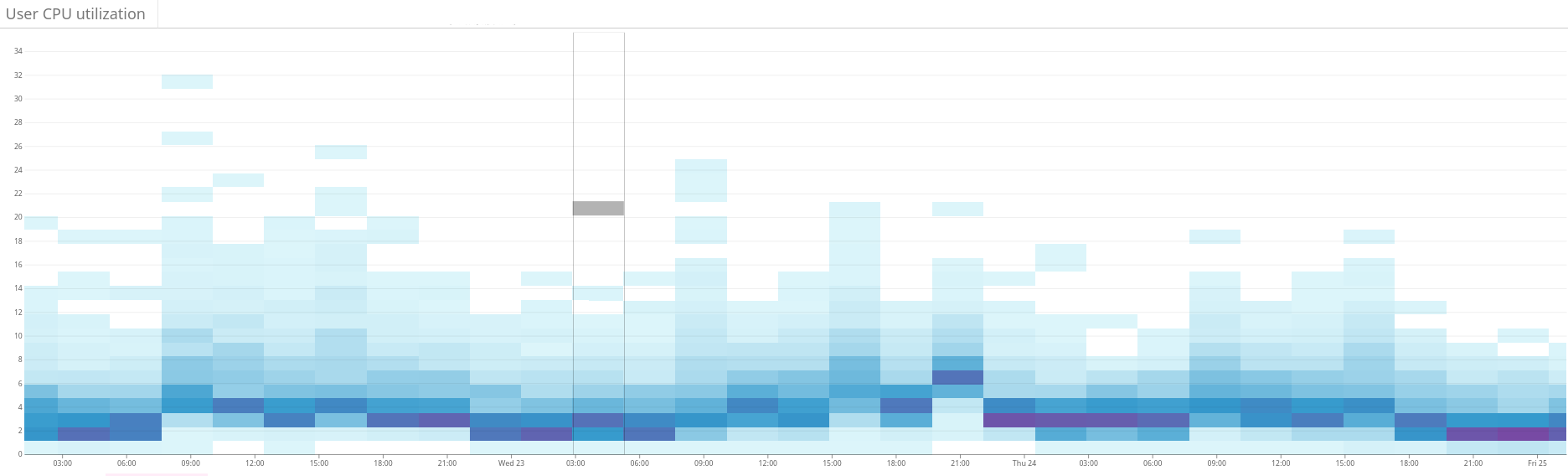 Fig. 3. El mapa de calor muestra el uso de la CPU en todos los nodos del clúster antes y después de configurar la función de calor en Shardonnay. Se observa un cambio significativo en el uso de la CPU con una carga de trabajo constante.
Fig. 3. El mapa de calor muestra el uso de la CPU en todos los nodos del clúster antes y después de configurar la función de calor en Shardonnay. Se observa un cambio significativo en el uso de la CPU con una carga de trabajo constante. Fig. 4. El mapa de calor muestra el rendimiento de lectura de los discos durante el mismo período que en la fig. 3. Las operaciones de lectura también se distribuyen de manera más uniforme en todo el clúster.
Fig. 4. El mapa de calor muestra el rendimiento de lectura de los discos durante el mismo período que en la fig. 3. Las operaciones de lectura también se distribuyen de manera más uniforme en todo el clúster.Resultados
Como resultado, nuestro solucionador de LP encuentra buenas soluciones en pocos minutos, incluso para nuestro enorme clúster. Por lo tanto, el sistema mejora iterativamente el estado del clúster en la dirección de la optimización.
¡Y la mejor parte es que la dispersión de la carga de trabajo y el uso del disco convergen como se esperaba, y este estado casi óptimo se mantiene después de muchos cambios intencionales e inesperados en el estado del clúster desde entonces!
Ahora admitimos una distribución saludable de la carga de trabajo en nuestros clústeres de Elasticsearch. Todo gracias a la optimización lineal y a nuestro servicio, que nos encanta llamar
Chardonnay .