En la última publicación, hablé sobre Kubernetes, cómo ThoughtSpot lo usa para sus propias necesidades de soporte de desarrollo. Hoy me gustaría continuar la conversación sobre un breve, pero a partir de ese no menos interesante historial de depuración, que ocurrió recientemente. El artículo se basa en el hecho de que containerización! = Virtualización. Además, se muestra cómo los procesos en contenedores compiten por los recursos incluso con restricciones óptimas en cgroup y alto rendimiento de la máquina.
Anteriormente, lanzamos una serie de operaciones relacionadas con el desarrollo de b CI / CD en el clúster interno de Kubernetes. Todo estaría bien, pero cuando inicia una aplicación "acoplada", el rendimiento de repente cae drásticamente. No éramos tacaños: en cada uno de los contenedores había limitaciones en el poder de cómputo y la memoria (5 CPU / 30 GB de RAM) configurados a través de la configuración del Pod. En una máquina virtual con tales parámetros, todas nuestras solicitudes de un pequeño conjunto de datos (10 Kb) para pruebas volarían. Sin embargo, en Docker & Kubernetes con 72 CPU / 512 GB de RAM, logramos lanzar 3-4 copias del producto, y luego comenzaron los frenos. Las solicitudes que solían completarse en un par de milisegundos ahora se bloquearon durante 1-2 segundos, y esto causó todo tipo de fallas en la canalización de tareas de CI. Tuve que tratar de cerca con la depuración.
Como regla general, se sospecha todo tipo de errores de configuración al empaquetar una aplicación en Docker. Sin embargo, no encontramos nada que pudiera causar al menos algún tipo de desaceleración (en comparación con las instalaciones en hardware desnudo o máquinas virtuales). Todo parece estar bien. Luego, probamos todo tipo de pruebas del paquete Sysbench . Verificamos el rendimiento de la CPU, el disco y la memoria: todo era igual que en metal desnudo. Algunos servicios de nuestro producto almacenan información detallada sobre todas las acciones: luego se puede usar para perfilar el rendimiento. Como regla general, cuando hay una escasez de un recurso (CPU, RAM, disco, red) en algunas llamadas, se observa una falla significativa en el tiempo, por lo que descubrimos qué se ralentiza exactamente y dónde. Sin embargo, no pasó nada en este caso. Las proporciones temporales no diferían de la configuración de trabajo, con la única diferencia de que cada llamada era mucho más lenta que en metal desnudo. Nada indica la fuente real del problema. Estábamos listos para rendirnos cuando de repente encontramos esto .
En este artículo, el autor analiza un caso misterioso similar cuando dos, en principio, procesos ligeros se matan entre sí cuando se ejecutan dentro de Docker en la misma máquina, y los límites de recursos se establecen en valores muy modestos. Llegamos a dos conclusiones importantes:
- La razón principal radica en el núcleo de Linux. Debido a la estructura de los objetos de caché de dentry en el kernel, el comportamiento de un proceso ralentizó la
__d_lookup_loop kernel __d_lookup_loop , lo que afectó directamente el rendimiento de otro. - El autor utilizó
perf para detectar errores en el núcleo. Una gran herramienta de depuración que nunca hemos usado antes (¡lo cual es una pena!).
perf (a veces llamado perf_events o herramientas de perf; anteriormente conocido como Performance Counters for Linux, PCL) es una herramienta de análisis de rendimiento de Linux disponible desde la versión del kernel 2.6.31. La utilidad de gestión de espacio de usuario, perf, está disponible desde la línea de comandos y es una colección de subcomandos.
Realiza perfiles estadísticos de todo el sistema (kernel y espacio de usuario). Esta herramienta admite plataformas de contadores de rendimiento de hardware y software (por ejemplo, hrtimer), puntos de rastreo y muestras dinámicas (por ejemplo, kprobes o uprobes). En 2012, dos ingenieros de IBM reconocieron a perf (junto con OProfile) como una de las dos herramientas de perfilado de contador de rendimiento más utilizadas en Linux.
Entonces pensamos: ¿quizás tengamos lo mismo? Comenzamos cientos de procesos diferentes en contenedores, y todos tenían el mismo núcleo. ¡Sentimos que habíamos atacado el camino! Armados con perf , perf la depuración, y al final estábamos esperando el descubrimiento más interesante.
A continuación se muestran las entradas de perf de los primeros 10 segundos de ThoughtSpot ejecutándose en una máquina saludable (rápida) (izquierda) y dentro del contenedor (derecha).
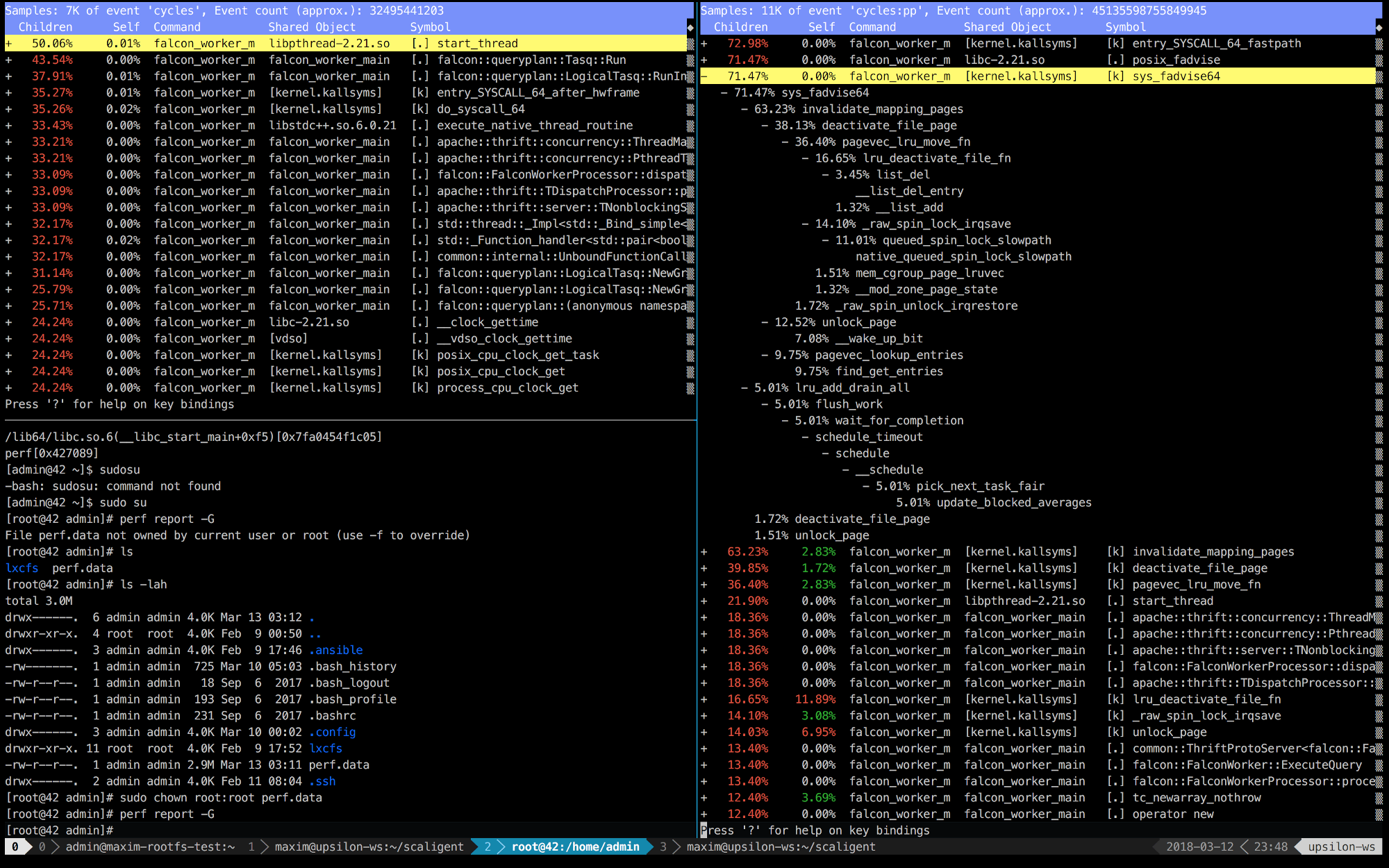
Está claro de inmediato que a la derecha las primeras 5 llamadas están conectadas con el núcleo. El tiempo se dedica principalmente al espacio del kernel, mientras que a la izquierda, la mayor parte del tiempo se dedica a nuestros propios procesos que se ejecutan en el espacio del usuario. Pero lo más interesante es que la llamada posix_fadvise toma todo el tiempo.
Los programas usan posix_fadvise (), declarando su intención de acceder a los datos del archivo de acuerdo con un patrón específico en el futuro. Esto le da al núcleo la oportunidad de llevar a cabo la optimización necesaria.
La llamada se usa para cualquier situación, por lo tanto, no indica la fuente del problema explícitamente. Sin embargo, al profundizar en el código, encontré solo un lugar que, en teoría, afectaba a todos los procesos del sistema:
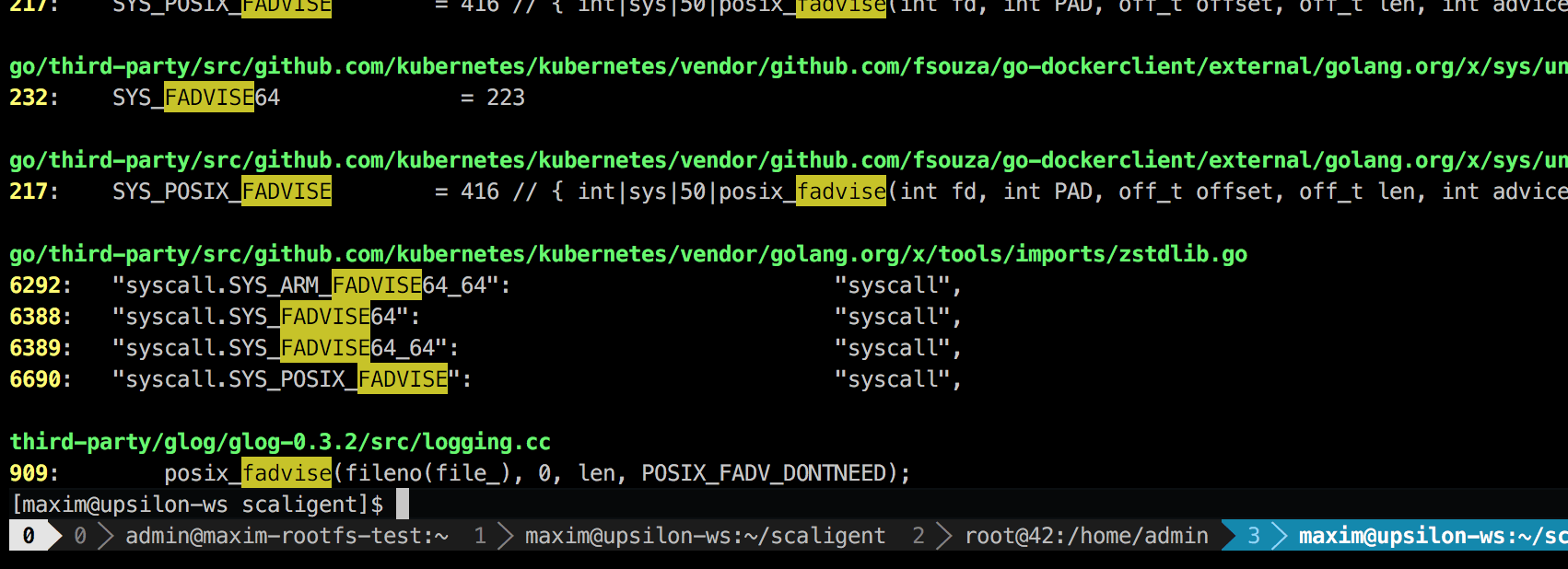
Esta es una biblioteca de registro de terceros llamada glog . Lo usamos para el proyecto. Específicamente, esta línea (en LogFileObject::Write ) es probablemente la ruta más crítica de toda la biblioteca. Se llama a todos los eventos "registro a archivo" (registro a archivo), y muchas instancias de nuestro producto registran con bastante frecuencia. Un vistazo rápido al código fuente sugiere que la parte fadvise se puede desactivar configurando el parámetro --drop_log_memory=false :
if (file_length_ >= logging::kPageSize) {
lo cual, por supuesto, hicimos y ... ¡en la diana!
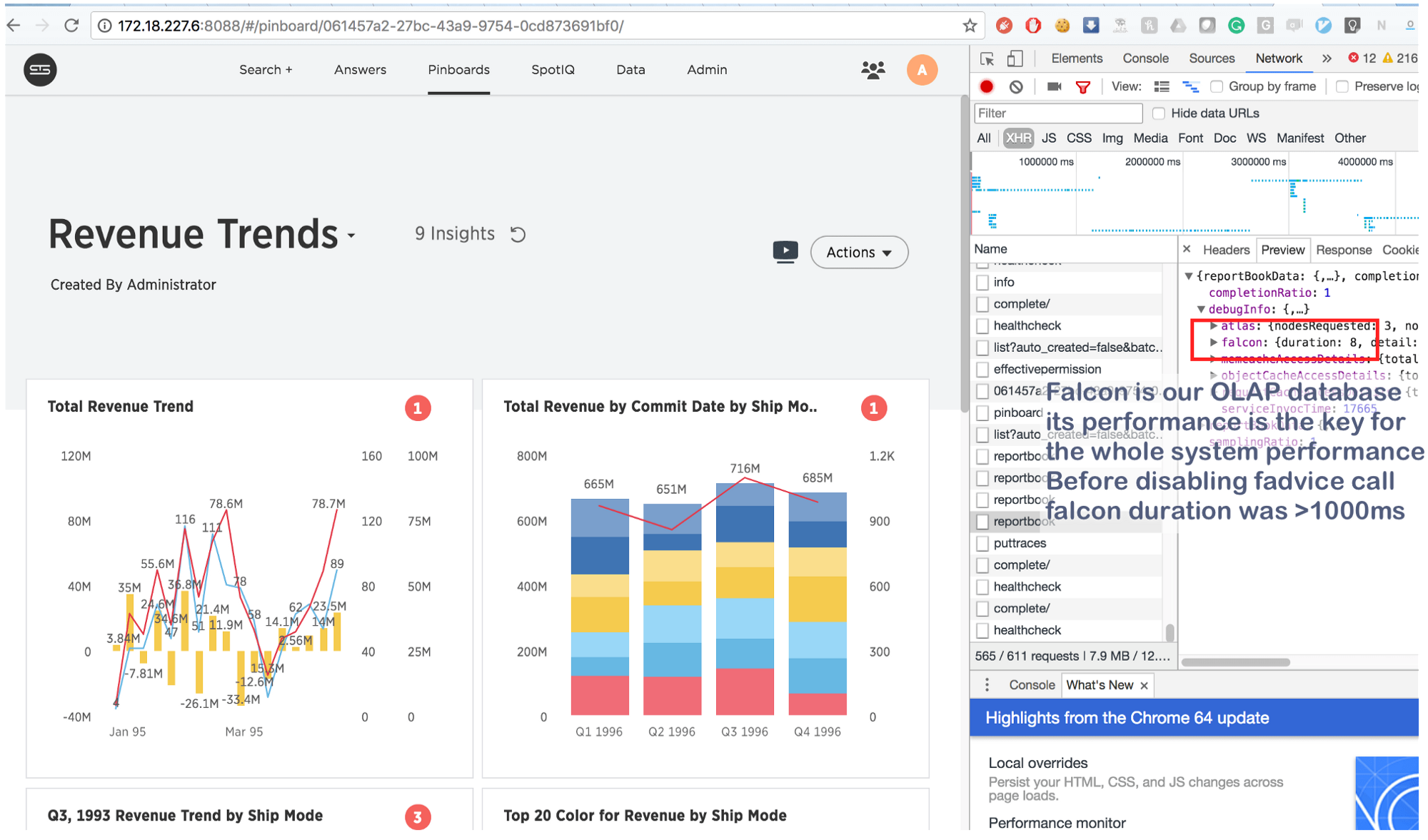
Lo que solía tomar un par de segundos ahora se hace en 8 (¡ocho!) Milisegundos. Un poco en Google, encontramos esto: https://issues.apache.org/jira/browse/MESOS-920 y también esto: https://github.com/google/glog/pull/145 , que una vez más confirmó nuestra corazonada sobre la verdadera causa de la inhibición. Lo más probable es que sucediera lo mismo en la máquina virtual / bare metal, pero como teníamos 1 copia del proceso por máquina / kernel, la intensidad de la llamada de Fadvise era mucho menor, lo que explicaba la falta de consumo de recursos adicionales. Al aumentar los procesos de registro en 3-4 veces y resaltar un núcleo común para ellos, vimos que realmente se estancó.
Y en conclusión:
Esta información no es nueva, pero por alguna razón muchas personas olvidan lo principal: en casos con contenedores, los procesos "aislados" compiten por todos los recursos centrales , y no solo por CPU , RAM , espacio en disco y red . Y dado que el núcleo es una estructura extremadamente compleja, pueden producirse bloqueos en cualquier lugar (como, por ejemplo, en __d_lookup_loop del artículo de Sysdig ). Sin embargo, esto no significa que los contenedores sean peores o mejores que la virtualización tradicional. Son una excelente herramienta que resuelve sus tareas. Solo recuerde: el núcleo es un recurso compartido y prepárese para depurar conflictos inesperados en el espacio del núcleo. Además, tales conflictos son una gran oportunidad para que los atacantes rompan el aislamiento "reducido" y creen canales ocultos entre los contenedores. Y finalmente, hay perf : una excelente herramienta que mostrará lo que está sucediendo en el sistema y ayudará a depurar cualquier problema de rendimiento. Si planea ejecutar aplicaciones altamente cargadas en Docker, asegúrese de tomarse el tiempo para aprender perf .