En la primera parte, nos familiarizamos con los métodos de adaptación de dominios a través del aprendizaje profundo. Hablamos sobre los principales conjuntos de datos, así como los enfoques no generativos basados en la discrepancia y en la confrontación. Estos métodos funcionan bien para algunas tareas. Y esta vez analizaremos los métodos basados en la confrontación más complejos y prometedores: modelos generativos, así como algoritmos que muestran los mejores resultados en el conjunto de datos de VisDA (adaptaciones de datos sintéticos a fotos reales).

Modelos generativos
La base de este enfoque es la capacidad de la GAN para generar datos a partir de la distribución necesaria. Gracias a esta propiedad, puede obtener la cantidad correcta de datos sintéticos y usarla para capacitación. La idea principal de los métodos de la familia de modelos generativos es generar datos utilizando el dominio fuente que sea lo más similar posible a los representantes del dominio objetivo. Por lo tanto, los nuevos datos sintéticos tendrán las mismas etiquetas que los representantes del dominio original en función de los cuales se obtuvieron. Luego, el modelo para el dominio de destino simplemente se entrena en estos datos generados.
Introducido en ICML-2018, el método CyCADA: La adaptación ( código ) del dominio adverso al ciclo es un miembro representativo de la familia de modelos generativos. Combina varios enfoques exitosos de GAN y adaptación de dominio. Una parte importante de esto es el uso de la pérdida de consistencia del ciclo, presentada por primera vez en un artículo sobre CycleGAN . La idea de la pérdida de consistencia del ciclo es que la imagen obtenida generando desde el dominio fuente al dominio objetivo, seguida de la transformación inversa, debe estar cerca de la imagen inicial. Además, CyCADA incluye adaptación a nivel de píxel y a nivel de representaciones vectoriales, así como pérdida semántica para guardar la estructura en la imagen generada.
Dejar y - redes para los dominios de destino y de origen, respectivamente, y - dominios de destino y fuente, - marcado en el dominio de origen, y - generadores desde el origen hasta el dominio de destino y viceversa, y - discriminadores de pertenencia a los dominios de destino y de origen, respectivamente. Entonces, la función de pérdida, que se minimiza en CyCADA, es la suma de seis funciones de pérdida (el esquema de entrenamiento con números de pérdida se presenta a continuación):
- - clasificación del modelo en datos generados y pseudo-etiquetas del dominio fuente.
- - Pérdidas adversarias para el entrenamiento del generador. .
- - Pérdidas adversarias para el entrenamiento del generador. .
- (pérdida de consistencia del ciclo) - -gloss, asegurando que las imágenes obtenidas de y Estará cerca.
- - pérdida de confrontación para representaciones vectoriales y en los datos generados (similar a lo que se usa en ADDA).
- (pérdida de consistencia semántica) - pérdida, responsable del hecho de que funcionará de manera similar a las imágenes obtenidas de ambos de .
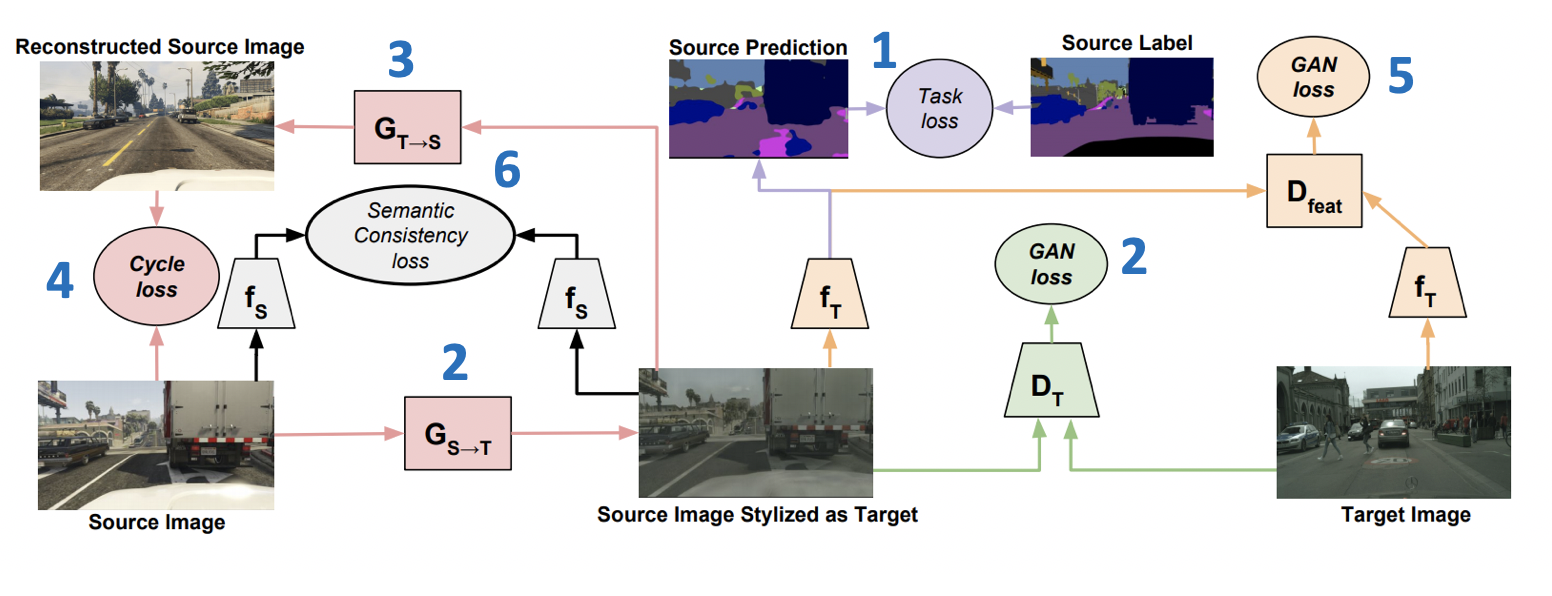
Resultados de CyCADA:
- En un par de dominios digitales de USPS -> MNIST: 95.7%.
- En la tarea de segmentación GTA 5 -> Paisajes urbanos: Media IoU = 39.5%.
Como parte del enfoque, Generate To Adapt: Alineing Domains using Generative Adversarial Networks ( code ) train a tal generador para que en la salida produzca imágenes cercanas al dominio original. Tal le permite convertir datos del dominio de destino y aplicarles el clasificador entrenado en los datos marcados del dominio de origen.
Para entrenar a dicho generador, los autores usan un discriminador modificado del artículo AC-GAN . Característica de esto radica en el hecho de que no solo responde 1 si la entrada proviene del dominio de origen, y 0 en caso contrario, sino que también en el caso de una respuesta positiva, clasifica los datos de entrada de acuerdo con las clases del dominio de origen.
Denotamos como una red convolucional que produce una representación vectorial de una imagen, - un clasificador que funciona en un vector derivado de . Aprendizaje y algoritmos de inferencia:
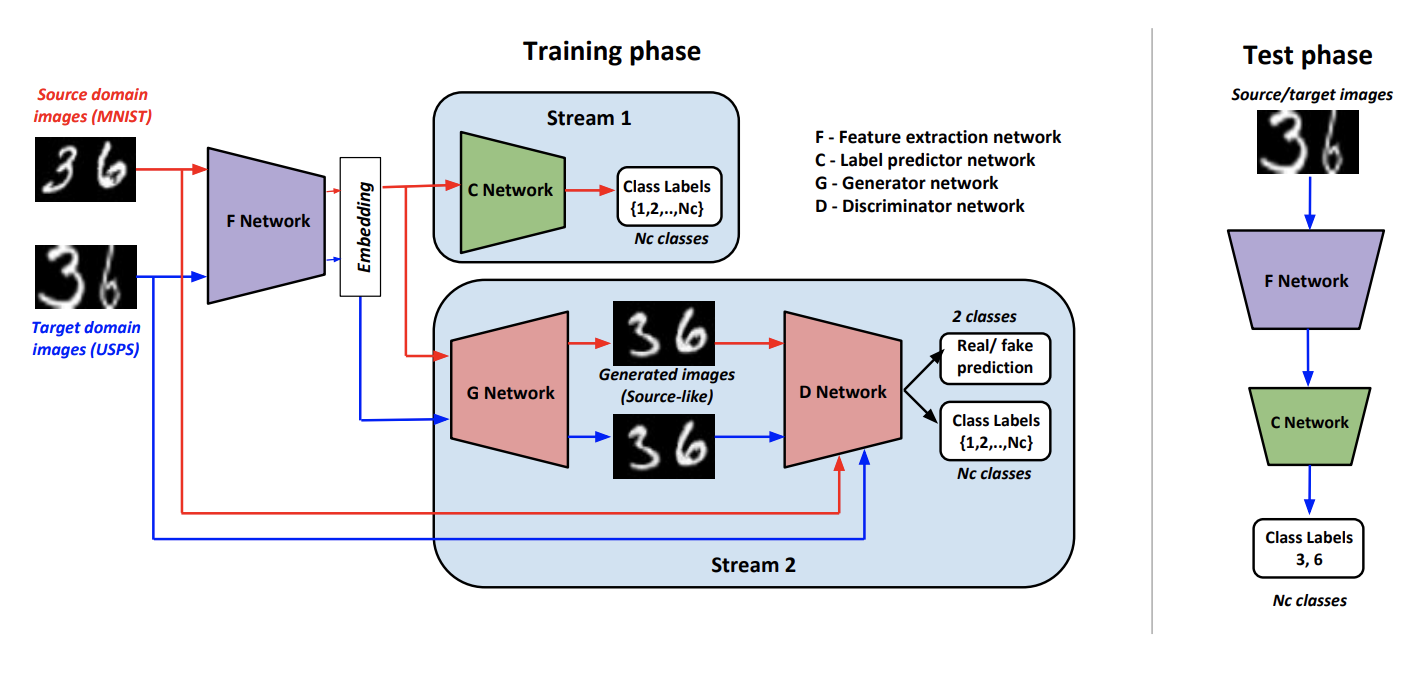
El procedimiento de capacitación consta de varios componentes:
- Discriminador aprende a determinar el dominio para todos los recibidos de datos, y para el dominio de origen, todavía se agrega una pérdida de clasificación, como se describió anteriormente.
- Sobre datos del dominio fuente utilizando una combinación de pérdida de adversidad y pérdida de clasificación, está entrenado para generar un resultado similar al dominio de origen y clasificado correctamente .
- y Aprenda a clasificar datos del dominio de origen. También con la ayuda de otra pérdida de clasificación, se cambia para aumentar la calidad de la clasificación .
- Usando la pérdida de adversarios aprende a "engañar" en datos del dominio de destino.
- Los autores concluyeron empíricamente que antes de someterse a tiene sentido concatenar un vector de con ruido normal y un vector de clase caliente ( para datos objetivo).
Los resultados del método en los puntos de referencia:
- En dominios digitales de USPS -> MNIST: 90.8%.
- En el conjunto de datos de Office, la calidad de adaptación promedio para pares de dominios de Amazon y Webcam es del 86.5%.
- En el conjunto de datos de VisDA, el valor de calidad promedio para 12 categorías sin una clase desconocida es 76.7%.
En el artículo De la fuente al destino y viceversa: GAN adaptativo bidireccional simétrico ( código ), se introdujo el modelo SBADA-GAN, que es bastante similar a CyCADA y cuya función objetivo, como CyCADA, consta de 6 componentes. En la notación de los autores y - generadores desde el dominio fuente hasta el destino y viceversa, y - discriminadores que distinguen los datos reales de los generados en los dominios de origen y destino, respectivamente, y - clasificadores entrenados en datos del dominio de origen y en sus versiones transformadas en el dominio de destino.
SBADA-GAN, como CyCADA, utiliza la idea de CycleGAN, pérdida de consistencia y pseudo-etiquetas para los datos generados en el dominio objetivo, componiendo la función objetivo a partir de los términos correspondientes. Las características de SBADA-GAN incluyen:
- La imagen + ruido se alimenta a la entrada a los generadores.
- La prueba utiliza una combinación lineal de predicciones del modelo de destino y el modelo fuente basado en la transformación. .
Esquema de entrenamiento SBADA-GAN:
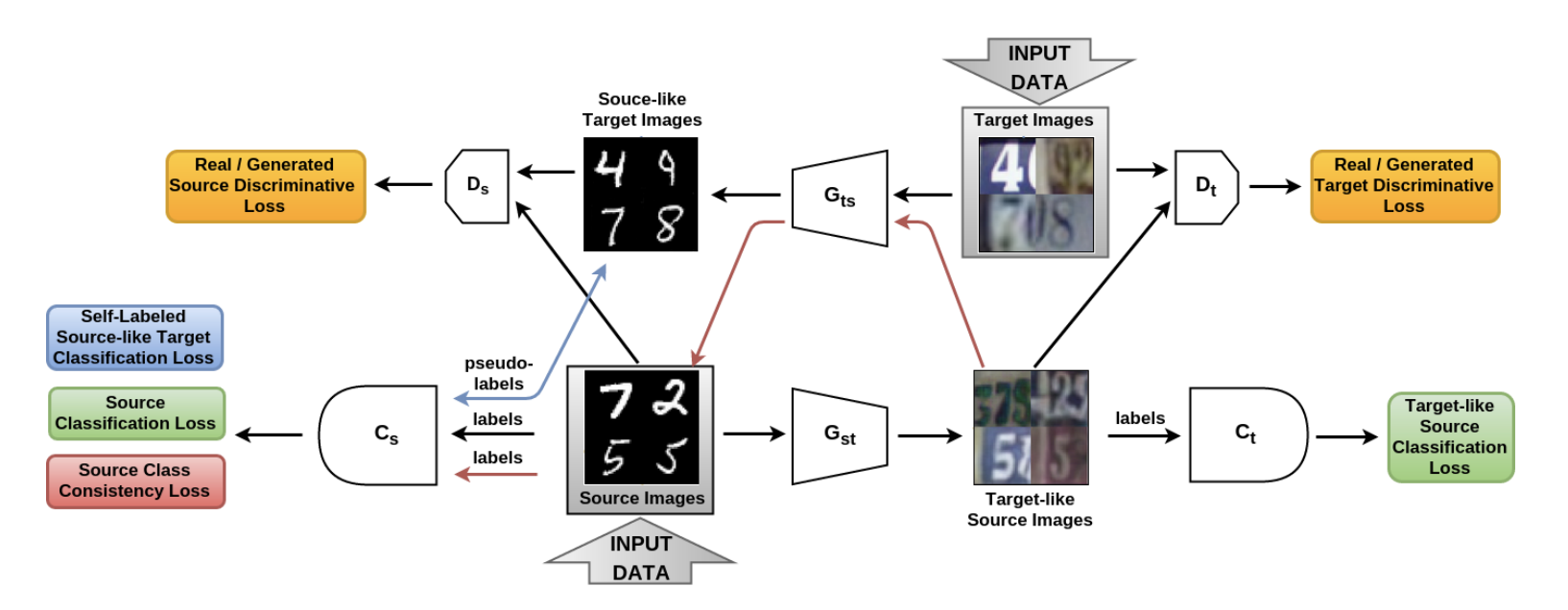
Los autores de SBADA-GAN realizaron más experimentos que los autores de CyCADA, y obtuvieron los siguientes resultados:
- En USPS -> dominios MNIST: 95.0%.
- En los dominios MNIST -> SVHN: 61.1%.
- En señales de tráfico Signos de sintetizador -> GTSRB: 97.7%.
De la familia de modelos generativos, tiene sentido considerar los siguientes artículos significativos:
Desafío de adaptación del dominio visual
Como parte del taller, las conferencias ECCV e ICCV organizan un concurso de adaptación de dominio del Desafío de adaptación del dominio visual . En él, los participantes están invitados a capacitar al clasificador en datos sintéticos y adaptarlo a los datos no asignados de ImageNet.
El algoritmo presentado en el autoensamblaje para la adaptación del dominio visual ( código ) ganó en VisDA-2017. Este método se basa en la idea del autoensamblaje: hay una red de maestros (modelo de maestros) y una red de estudiantes. En cada iteración, la imagen de entrada se ejecuta a través de ambas redes. El alumno se entrena utilizando la suma de la pérdida de clasificación y la pérdida de consistencia, donde la pérdida de clasificación es la entropía cruzada habitual con una etiqueta de clase conocida, y la pérdida de consistencia es la diferencia cuadrática promedio entre las predicciones del profesor y del alumno (diferencia cuadrática). Los pesos de la red de maestros se calculan como el promedio móvil exponencial de los pesos de la red de estudiantes. Este procedimiento de entrenamiento se ilustra a continuación.
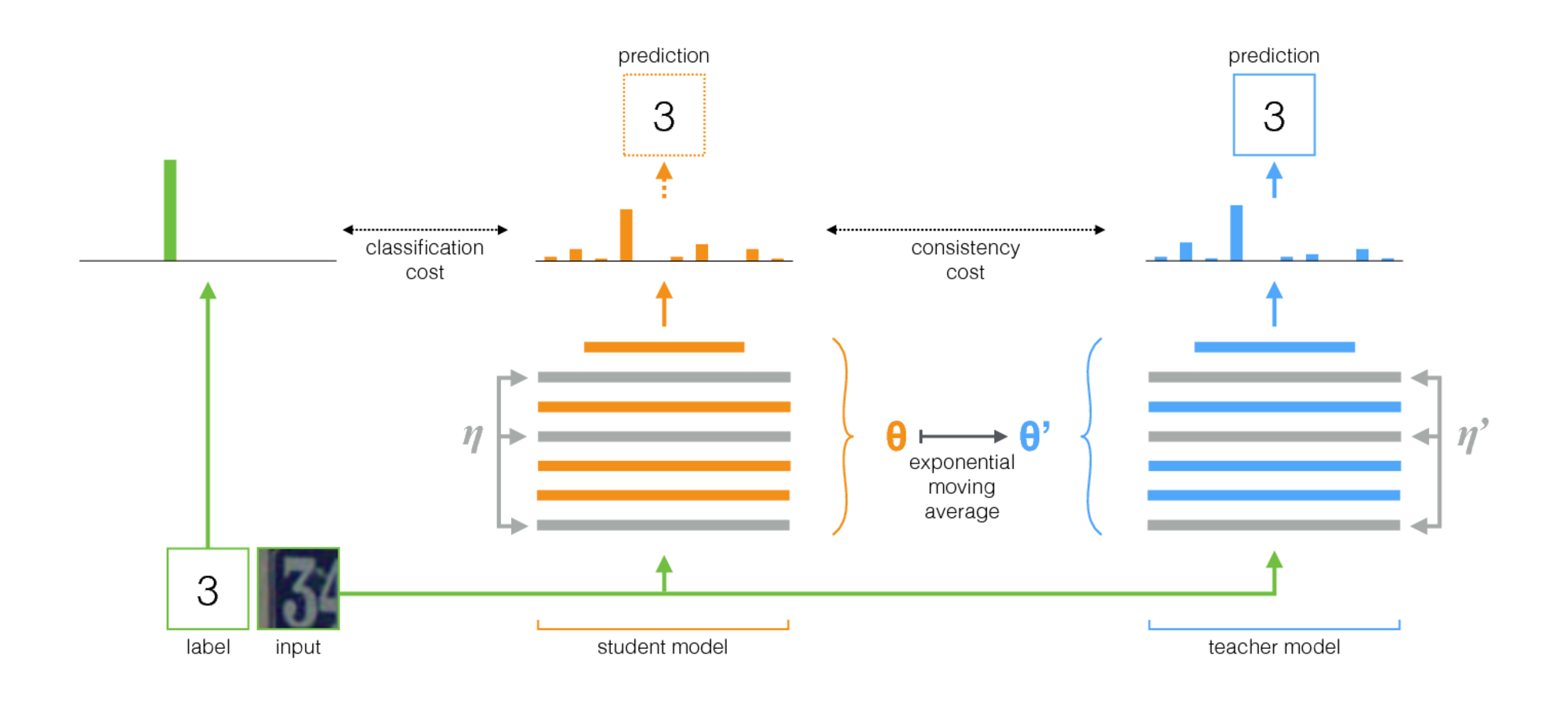
Las características importantes de la aplicación de este método para la adaptación del dominio son:
- En el lote de entrenamiento, los datos del dominio de origen se mezclan con etiquetas de clase y datos del dominio de destino sin etiquetas
- Antes de ingresar imágenes a las redes neuronales, se aplican varios aumentos fuertes: ruidos gaussianos, transformaciones afines, etc.
- Ambas redes utilizaron fuertes métodos de regularización (como la deserción).
- - salida de la red de estudiantes, - Profesores de la red. Si la entrada era del dominio de destino, solo la pérdida de consistencia entre y , pérdida de entropía cruzada = 0.
- Para la sostenibilidad del aprendizaje, se utiliza el umbral de confianza: si la predicción del maestro es menor que el umbral (0.9), la pérdida de pérdida de consistencia = 0.
Esquema del procedimiento descrito:

En los conjuntos de datos principales, el algoritmo alcanzó un alto rendimiento. Es cierto que los autores seleccionaron por separado un conjunto de aumentos para cada tarea.
- USPS -> MNIST: 99.54%.
- MNIST -> SVHN: 97.0%.
- Números de sintetizador -> SVHN: 97.11%.
- En señales de tráfico Signos de sintetizador -> GTSRB: 99.37%.
- En el conjunto de datos de VisDA, el valor de calidad promedio para 12 categorías sin la clase Desconocido es 92.8%. Es importante tener en cuenta que este resultado se obtuvo utilizando un conjunto de 5 modelos y utilizando el aumento de tiempo de prueba.
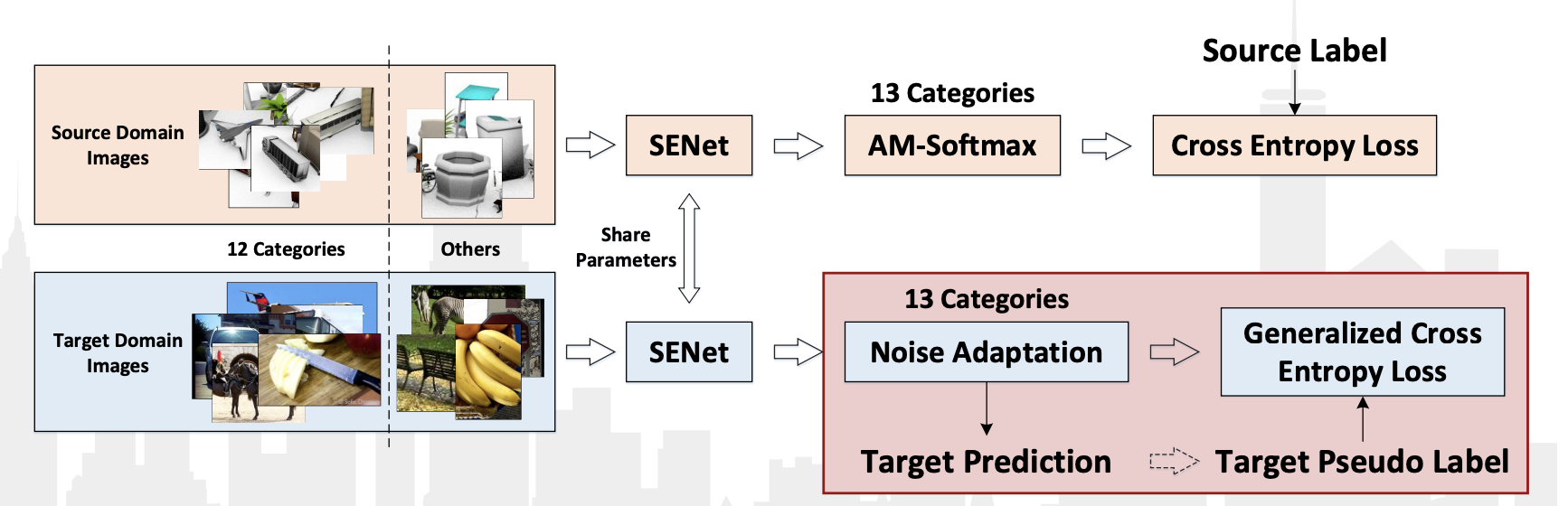
La competencia VisDA-2018 se celebró este año como parte de la conferencia ECCV-2018. Esta vez agregaron la clase 13: Desconocida, que obtuvo todo lo que no se clasificó en 12 clases. Además, se realizó una competencia por separado para detectar objetos pertenecientes a estas 12 clases. En ambas categorías, ganó el equipo chino JD AI Research . En el concurso de clasificación, lograron un resultado de 92.3% (el valor promedio de calidad en 13 categorías). No hay publicaciones con una descripción detallada de su método, solo hay una presentación del taller .
De las características de su algoritmo se pueden observar:
- Usando pseudo-etiquetas para datos del dominio de destino y reentrenando el clasificador en ellos junto con datos del dominio de origen.
- Usando la red de convolución SE-ResNeXt-101, AM-Softmax y la capa de adaptación de ruido, pérdida de entropía cruzada generalizada para datos del dominio objetivo.
Diagrama de algoritmo de la presentación:
Conclusión
En su mayor parte, hemos discutido los métodos de adaptación basados en el enfoque basado en la confrontación. Sin embargo, en los últimos dos concursos de VisDA, ganaron algoritmos que no estaban relacionados con él y usaron capacitación en pseudo-etiquetas y modificaciones de métodos de aprendizaje profundo más clásicos. En mi opinión, esto se debe al hecho de que los métodos basados en GAN todavía están al comienzo de su desarrollo y son extremadamente inestables. Pero cada año obtenemos más y más resultados nuevos que mejoran el trabajo de las GAN. Además, el foco de interés de la comunidad científica en el campo de la adaptación de dominios se centra principalmente en métodos basados en la confrontación, y los nuevos artículos estudian principalmente este enfoque. Por lo tanto, es probable que los algoritmos asociados con las GAN lleguen gradualmente a la vanguardia en cuestiones de adaptación.
Pero la investigación de enfoques no adversos también está en curso. Aquí hay algunos artículos interesantes de esta área:
Los métodos basados en discrepancias pueden clasificarse como "históricos", pero muchas de las ideas utilizadas en los últimos métodos: MMD, pseudo-etiquetas, aprendizaje métrico, etc. Además, a veces en problemas de adaptación simples tiene sentido aplicar estos métodos debido a su relativa facilidad de entrenamiento y mejor interpretación de los resultados.
En conclusión, quiero señalar que los métodos de adaptación de dominios todavía están buscando su aplicación en campos aplicados, pero gradualmente hay tareas cada vez más prometedoras que requieren el uso de la adaptación. Por ejemplo, la adaptación de dominio se usa activamente en el entrenamiento de módulos de automóviles autónomos : dado que es costoso y lento recopilar datos reales en las calles de la ciudad para entrenar pilotos automáticos, los automóviles autónomos usan datos sintéticos (las bases de datos SYNTHIA y GTA 5 sirven como ejemplos), en particular. para resolver el problema de segmentación de lo que la cámara "ve" desde el automóvil.
Obtener modelos de alta calidad basados en un entrenamiento en profundidad en Computer Vision depende en gran medida de la disponibilidad de grandes conjuntos de datos etiquetados para el entrenamiento. El marcado casi siempre requiere mucho tiempo y dinero, lo que aumenta significativamente el ciclo de desarrollo de modelos y, como resultado, productos basados en ellos.
Los métodos de adaptación de dominio están destinados a resolver este problema y pueden contribuir potencialmente a un gran avance en muchos problemas aplicados y en la inteligencia artificial en general. Transferir conocimiento de un dominio a otro es una tarea realmente difícil e interesante, que actualmente se está estudiando activamente. Si sufre una falta de datos en sus tareas y puede emular datos o encontrar dominios similares, ¡le recomiendo probar métodos de adaptación de dominio!