Velocity es una conferencia dedicada a sistemas distribuidos. Está organizado por O'Reilly, y tiene lugar tres veces al año: una vez en California, una vez en Nueva York y una vez en Europa (y la ciudad cambia cada año).
En 2018, la conferencia tuvo lugar en Londres del 30 de octubre al 2 de noviembre. La oficina principal de Badoo se encuentra allí, así que mis colegas y yo teníamos dos razones para ir a Velocity.
Su dispositivo resultó ser algo más complicado que el que encontré en las conferencias rusas. Además de los dos días habituales de presentaciones, hubo dos días más de entrenamiento, que se pueden tomar completa, parcial o nada. Juntos, esto se convierte en una búsqueda seria para elegir el tipo de boleto que necesita.
En esta revisión, hablaré sobre esos informes y clases magistrales que recuerdo. Adjunto enlaces a materiales adicionales a algunos informes. En parte, estos son materiales a los que los autores se refirieron, y en parte materiales para estudios posteriores, que encontré yo mismo.
La impresión general de la conferencia: los autores se desempeñan muy bien (y las sesiones magistrales son un espectáculo completo con los oradores presentando y subiendo al escenario con la música), pero al mismo tiempo encontré algunos informes que serían profundos desde un punto de vista técnico.
El tema más candente de esta conferencia es Kubernetes , que se menciona en casi cada segundo informe.
El trabajo con las redes sociales está muy bien construido: en la cuenta oficial de Twitter durante la conferencia hubo muchos retuits operativos con informes. Esto permitió un rápido vistazo a lo que estaba sucediendo en otras habitaciones.
Clases magistrales
El 31 de octubre fue el día en que no hubo informes, pero hubo seis u ocho clases magistrales de tres horas de tiempo puro cada una, de las cuales dos tuvieron que ser elegidas.
PD: En el original, se llaman tutoriales, pero me parece correcto traducirlos como una "clase magistral".
Campamento de ingeniería del caos
Presentador: Ana Medina , ingeniera en Gremlin | Descripción
El taller se dedicó a introducir la ingeniería del caos. Ana contó con fluidez qué es, qué beneficios trae, demostró cómo se puede usar, qué software puede ayudar y cómo comenzar a usarlo en una empresa.
En general, esta fue una buena introducción para principiantes, pero no me gustó mucho la parte práctica, que era el despliegue de una aplicación web de demostración en un clúster de varias máquinas que usan Kubernetes y atormentan el monitoreo de DataDog . El principal problema fue que pasamos casi la mitad del tiempo de la clase magistral en esto y solo era necesario jugar con scripts que emulaban varios problemas en el clúster durante 5-10 minutos y observar los cambios en los gráficos.
Me parece que para el mismo efecto fue suficiente para dar acceso a un DataDog preconfigurado y / o demostrarlo todo desde la escena, y este tiempo debería gastarse, por ejemplo, en una revisión más detallada y ejemplos del uso del mismo Chaos Monkey, del que se habló literalmente Un par de frases.


Interesante: en esta conferencia, los oradores a menudo mencionaron el término "radio de explosión", que no había visto antes. Designaron la parte del sistema que se ve afectada cuando ocurre un problema específico.
Materiales adicionales:
Construyendo infraestructura evolutiva
Presentador: Kief Morris , consultor de infraestructura y autor de Infraestructura como código | Descripción
Los puntos principales de la clase magistral se pueden reducir a dos cosas:
- Los sistemas cambian todo el tiempo, por lo que es normal que la infraestructura también necesite cambiar;
- Una vez que la infraestructura está cambiando, debe asegurarse de que sea simple y segura, y esto solo se puede lograr mediante la automatización.
La parte principal de su historia se dedicó específicamente a la automatización de los cambios de infraestructura, las posibles soluciones a este problema y los cambios de prueba. No soy un experto en este tema, pero me pareció que estaba hablando con mucha confianza y en detalle (y muy rápidamente).
El punto principal que recuerdo de esta clase maestra es la recomendación de maximizar la distinción entre entornos (producción, puesta en escena, etc.) del código en las variables de entorno. Esto reducirá la probabilidad de errores en la infraestructura al cambiar el entorno y la hará más comprobable.



Informes
El 1 y 2 de noviembre fueron días de informes. Se dividieron en dos bloques principales: una serie de tres o cuatro breves informes principales que salieron en una secuencia por la mañana (y para ellos un gran salón reunido de dos más pequeños) e informes temáticos más largos en cinco flujos que duraron el resto del día. . Durante el día hubo varias grandes pausas entre los informes, cuando fue posible pasear por la exposición con los stands de los socios de la conferencia.
Evolución del backend de Runtastic
Simon Lasselsberger (Runtastic GmbH) | Descripción y diapositivas
Uno de los pocos informes en los que el autor no solo dijo cómo hacer algo, sino que mostró detalles de un proyecto específico y lo que le sucedió.
Al principio, Runtastic tenía una base de datos de Servidor Percona común y un monolito con código para aplicaciones móviles y un sitio. Luego comenzaron a escribir en Cassandra (no recuerdo por qué estaba en ella) esa parte de los datos para la cual el valor clave del almacenamiento era suficiente. Poco a poco, la base de datos se hinchó y agregaron MongoDB, en el que comenzaron a escribir datos de la mayoría de los servicios. Con el tiempo, lograron un nivel general que atiende las solicitudes de las aplicaciones web y móviles (algo así como nuestra aplicación , según tengo entendido).
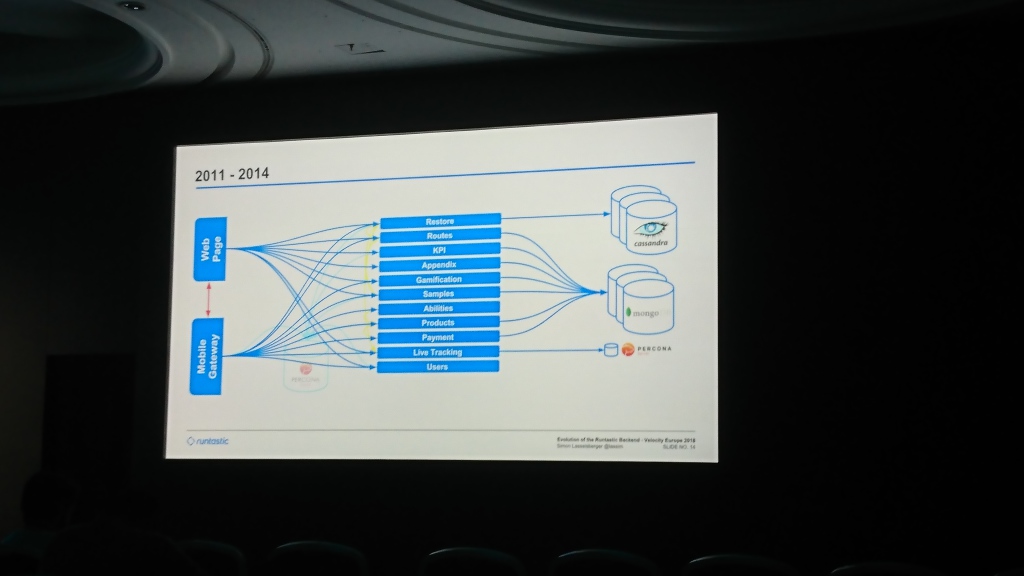
La mayor parte del informe se dedicó a moverse entre centros de datos. Al principio mantuvieron el servidor en Hetzner, que después de un tiempo se consideró insuficientemente estable y los datos migraron a T-Systems. Unos años más tarde, se enfrentaron a una falta de espacio ya allí y se mudaron nuevamente a Linz AG. La parte más interesante aquí es la migración de datos. Comenzaron a copiar datos que duraron varios meses. No podían esperar tanto porque se estaban quedando sin espacio y no podían agregarlo, por lo que recurrieron al código, que intentó leer los datos del antiguo centro de datos si no estaba en el nuevo.
En el futuro, planean dividir los datos en varios centros de datos separados (Simon dijo varias veces que esto es necesario para Rusia y China) y dividir rígidamente las bases de datos por servicios separados (ahora se usa un grupo común para todos los servicios).
Un enfoque interesante para el diseño de módulos en un sistema, sobre el cual Simon mencionó casualmente: arquitectura hexagonal .
Permita que una aplicación sea manejada igualmente por usuarios, programas, pruebas automatizadas o scripts por lotes, y que se desarrolle y pruebe aisladamente de sus eventuales dispositivos y bases de datos en tiempo de ejecución.
Alistair cockburn
Materiales adicionales:
Monitoreo de métricas personalizadas; o, cómo aprendí a instrumentar primero y hacer preguntas después
Maxime Petazzoni (SignalFx) | Descripción y presentación.
La historia se dedicó a recopilar las métricas necesarias para comprender la aplicación. El mensaje principal fue que las métricas RED habituales (tasa, errores y duración) no son suficientes, y además de ellas, debe recopilar inmediatamente otras que ayuden a comprender lo que está sucediendo dentro de la aplicación.
Resumen, el autor sugirió recopilar contadores y temporizadores para algunas acciones importantes en el sistema (y necesariamente contadores de fallas), construir gráficos e histogramas de distribución a partir de ellos, determinar un metamodelo para las métricas del usuario (de modo que las diferentes métricas tengan el mismo conjunto de parámetros requeridos) y los mismos significados se llamaban iguales en todas partes).

Es bastante difícil volver a contar los detalles en palabras, será más fácil ver los detalles y ejemplos en la presentación, cuyo enlace se encuentra en la página del informe en el sitio web de la conferencia.
Materiales adicionales:
Cómo sin servidor cambia el departamento de TI
Paul Johnston (Laboratorios de glorietas) | Descripción y presentación.
El autor se presentó como CTO y ecologista, dijo que sin servidor no es una solución tecnológica, sino comercial ("No paga nada si no se usa"). Luego describió las mejores prácticas para trabajar con servidores sin servidor, qué competencias se necesitan para trabajar con él y cómo afecta la selección de nuevos empleados y el trabajo con los existentes.

El punto clave de la "influencia en el departamento de TI" que recordaba era el cambio de las competencias necesarias de simplemente escribir código para trabajar con la infraestructura y su automatización ("más" ingeniería "que" desarrollar "). Todo lo demás era bastante banal (hay que llevarlo a cabo constantemente revisión de código, para documentar los flujos de datos y eventos disponibles para su uso en el sistema, para comunicarse más y aprender rápidamente), pero por alguna razón el autor los atribuyó a las funciones sin servidor.

En general, el informe parecía un poco confuso. Muchas de las cosas de las que habló el orador se pueden atribuir a cualquier sistema complejo que no cabe en la cabeza por completo.
Materiales adicionales:
¡No entres en pánico! Cómo lidiar ahora que eres responsable de la producción
Euan Finlay (Financial Times) | Descripción y presentación.
Un informe sobre cómo lidiar con incidentes de producción si algo sale mal en este momento. Los puntos principales se dividieron en partes por tiempo.
Antes del incidente:
- diferencie las alertas por criticidad: tal vez algunas puedan esperar y usted no necesite tratarlas con urgencia;
- Prepare un plan para analizar los incidentes por adelantado y mantenga la documentación actualizada;
- realizar ejercicios: romper algo y ver qué sucede (también conocido como ingeniería del caos);
- Establezca un lugar único donde se reúna toda la información sobre cambios y problemas.
Durante el incidente:
- es normal que no lo sepas todo; atrae a otras personas si es necesario;
- establecer un lugar único para la comunicación entre las personas que trabajan en la solución del incidente;
- Busque la solución más simple que devolverá la producción a las condiciones de trabajo y no intente resolver completamente el problema.
Después del incidente:
- averiguar por qué surgió el problema y qué te enseñó;
- es importante escribir un informe sobre esto ("informe de incidentes");
- Identificar lo que se puede mejorar y planificar acciones específicas.
Al final, Ewan contó una historia divertida sobre el incidente en el Financial Times, que surgió porque la base de producción (llamada prod ) se modificó por error en lugar de preproducción ( pprod ), y aconsejó evitar nombres similares.
Aprendiendo de la red de la vida (Keynote)
Claire Janisch (BiomimicrySA) | Descripción
Llegué tarde a este informe, pero en Twitter hablaron muy bien al respecto. Necesita ver si se encuentra.
Se puede ver un video con un fragmento del discurso en el sitio web de la conferencia .
Jane Adams (Dos inversiones Sigma) | Descripción
Informe filosófico sobre el tema "podemos confiar en los algoritmos de toma de decisiones". La conclusión general fue que no: el algoritmo puede optimizar métricas específicas, pero al mismo tiempo afecta seriamente lo que es difícil de medir o se encuentra fuera de estas métricas (como ejemplo, hubo discriminación en el algoritmo para contratar empleados en Amazon, lo que afectó negativamente la cultura de la empresa y obligado a abandonar este algoritmo).
La libertad de Kubernetes (Keynote)
Kris Nova | Descripción
A partir de ahí recordé dos pensamientos:
- la flexibilidad no es libertad, sino caos;
- La complejidad en sí misma no es un problema si tiene algún valor (en el original se llamaba "complejidad necesaria"), lo que excede el costo de esta complejidad.
El informe fue bastante filosófico, por lo tanto, por un lado, no pude sacar mucho provecho de él, pero por otro lado, lo que obtuve fue aplicable no solo a Kubernetes.

¿Qué cambia cuando nos desconectamos primero? (Keynote)
Martin Kleppmann (Universidad de Cambridge), autor de Diseño de aplicaciones intensivas en datos | Descripción
El informe constaba de dos partes lógicas: en la primera, Martin habló sobre el problema de la sincronización de datos entre ellos, que se puede cambiar de forma independiente en varias fuentes, y en la segunda, habló sobre las posibles soluciones y algoritmos que se pueden utilizar para esto ( transformación operativa , OT , y tipo de datos replicados sin conflictos , CRDT) y propuso su solución: la biblioteca de automatización automática para resolver tales problemas.
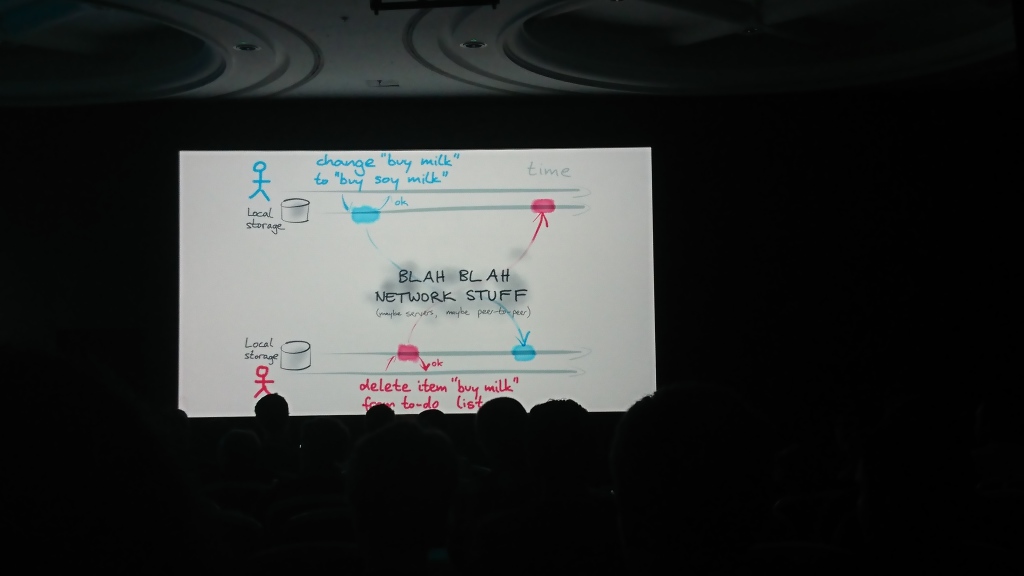


Materiales adicionales:
Una guía del programador para asegurar las conexiones.
Ponente: Liz Rice | Descripción y diapositivas
El informe se realizó en forma de una sesión de codificación en vivo, y en él Liz mostró cómo funciona HTTPS, qué errores pueden ocurrir al trabajar con conexiones seguras y cómo resolverlos. No hubo grandes profundidades, pero la demostración en sí fue muy buena.
Lo más útil: una diapositiva con los principales errores ( también conocido como el informe de Liz en otra conferencia ):

Materiales adicionales:
Todo lo que querías saber sobre monorepos pero tenías miedo de preguntar
Simon Stewart (Proyecto Selenium) | Descripción
La tesis principal del informe es que en monorepo es mucho más fácil administrar las dependencias en el código, y esto cubre todas las ventajas de los repositorios individuales. Apeló al hecho de que Google y Microsoft almacenan datos en un repositorio (86 Tb y 300 Gb de tamaño, respectivamente), y el repositorio de Facebook (archivos de 54 Gb) usa "mercurial de shell".
La sala "explotó" después de la pregunta "¿Quién tiene más repositorios en la empresa que empleados?"
El argumento "con un gran repositorio para trabajar lentamente" se rompió de la siguiente manera:
- no tiene que llevar todo el historial de cambios a la máquina local: use el clon de sombra y el pago escaso ;
- no tiene que usar todos los archivos del repositorio: organice la jerarquía de archivos y trabaje solo con el directorio necesario, y excluya todo lo demás.
Materiales adicionales:
Construyendo un sistema de procesamiento de flujo distribuido en tiempo real
Amy Boyle (nueva reliquia) | Descripción y presentación.
Una buena historia sobre el trabajo con la transmisión de datos de un ingeniero de NewRelic (donde claramente tienen mucha experiencia trabajando con dichos datos). Amy dijo que está trabajando con la transmisión de datos, cómo se pueden agregar, qué se puede hacer con datos rezagados, cómo se pueden fragmentar las secuencias de eventos y cómo reequilibrarlos en caso de fallas del procesador, qué monitorear, etc.
El informe fue mucho material, no intentaré volver a contarlo, pero solo recomiendo ver la presentación en sí (ya está en el sitio web de la conferencia).


Arquitectura para tv
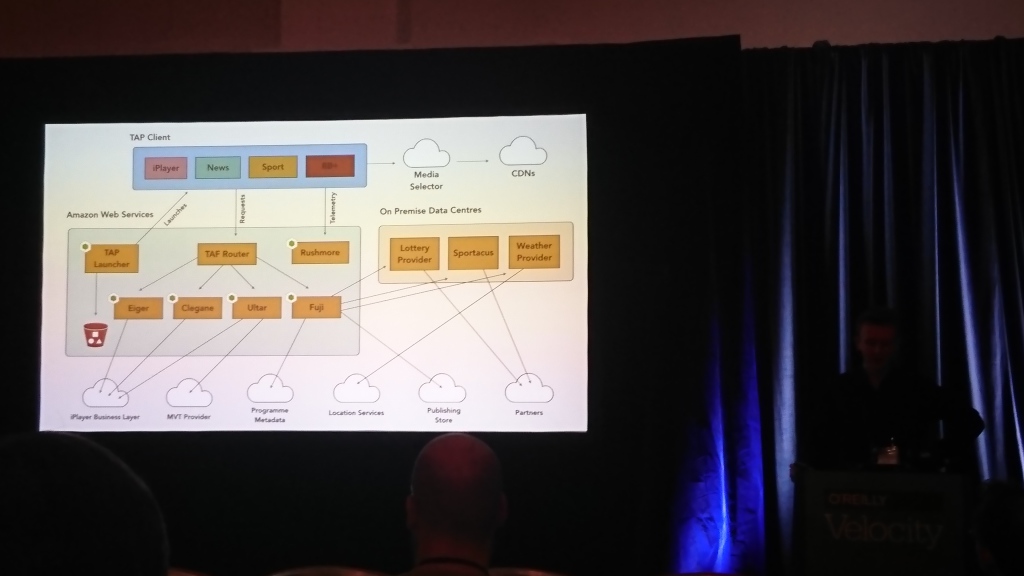
David Buckhurst (BBC), Ross Wilson (BBC) | Descripción
La mayor parte de la conversación fue sobre la interfaz de la BBC. Los chicos tienen televisión interactiva y muchos televisores y otros dispositivos (computadoras, teléfonos, tabletas) en los que esto debería funcionar. Debe trabajar con diferentes dispositivos de maneras completamente diferentes, por lo que se les ocurrió su propio lenguaje basado en JSON para describir interfaces y traducirlo a lo que un dispositivo específico puede entender.
La principal conclusión para mí es que, en comparación con las personas de TV, las aplicaciones móviles no tienen problemas con los clientes antiguos.