A principios de año, decidimos aprender a almacenar y leer registros de depuración de VK de manera más eficiente que antes. Los registros de depuración son, por ejemplo, registros de conversión de video (básicamente la salida del comando ffmpeg y una lista de pasos para preprocesar archivos), que a veces solo necesitamos 2-3 meses después de procesar el archivo del problema.
En ese momento, teníamos 2 formas de almacenar y procesar registros: nuestro propio motor de registros y rsyslog, que utilizamos en paralelo. Comenzamos a considerar otras opciones y nos dimos cuenta de que ClickHouse de Yandex es bastante adecuado para nosotros; decidimos implementarlo.
En este artículo, hablaré sobre cómo comenzamos a usar ClickHouse en VKontakte, qué rastrillo pisamos y qué son KittenHouse y LightHouse. Ambos productos se presentan en enlaces de código abierto al final del artículo.
Tarea de recopilación de registros
Requerimientos del sistema:
- Almacenamiento de cientos de terabytes de troncos.
- Almacenamiento durante meses o (rara vez) años.
- Alta velocidad de escritura.
- Alta velocidad de lectura (la lectura es rara).
- Índice de soporte
- Soporte para cadenas largas (> 4 Kb).
- Simplicidad de operación.
- Almacenamiento compacto
- La capacidad de insertar desde decenas de miles de servidores (UDP será una ventaja).
Posibles soluciones
Enumeremos brevemente las opciones que consideramos y sus contras:
Motor de registros
Nuestro microservicio autoescrito para registros.
- Capaz de dar solo las últimas N líneas que caben en la RAM.
- Almacenamiento no muy compacto (sin compresión transparente).
Hadoop
- No todos los formatos tienen índices.
- La velocidad de lectura podría ser mayor (según el formato).
- La complejidad de la configuración.
- No hay posibilidad de insertar desde decenas de miles de servidores (se necesitan Kafka o análogos).
Rsyslog + archivos
- No hay índices.
- Baja velocidad de lectura (grep / zgrep regular).
- Cadenas arquitectónicamente no compatibles> 4 Kb, UDP incluso menos (1.5 Kb).
± El almacenamiento compacto se logra mediante logrotate sobre la corona
Utilizamos rsyslog como respaldo para el almacenamiento a largo plazo, pero las líneas largas se truncaron, por lo que difícilmente se puede llamar ideal.
Archivos LSD +
- No hay índices.
- Baja velocidad de lectura (grep / zgrep regular).
- No está especialmente diseñado para la inserción de decenas de miles de servidores.
± El almacenamiento compacto se logra mediante logrotate sobre la corona.
Las diferencias con rsyslog en nuestro caso son que LSD admite cadenas largas, pero se requieren cambios significativos en el protocolo interno para insertar desde decenas de miles de servidores, aunque esto se puede hacer.
Búsqueda elástica
- Problemas con la operación.
- Grabación inestable.
- No UDP.
- Mala compresión.
La pila ELK ya es casi el estándar de la industria para el almacenamiento de registros. En nuestra experiencia, todo está bien con la velocidad de lectura, pero hay problemas con la escritura, por ejemplo, al fusionar índices.
ElasticSearch está diseñado principalmente para búsquedas de texto completo y solicitudes de lectura relativamente frecuentes. Para nosotros, la grabación estable y la capacidad de leer nuestros datos más o menos rápidamente son más importantes y por coincidencia exacta. El índice en ElasticSearch se agudiza para la búsqueda de texto completo, y el espacio en disco es bastante grande en comparación con el gzip del contenido original.
Clickhouse
- No UDP.
En general, lo único que no nos convenía en ClickHouse era la falta de comunicación UDP. De hecho, de las opciones anteriores, solo rsyslog lo tenía, pero rsyslog no admitía largas colas.
Según otros criterios, ClickHouse se nos acercó y decidimos usarlo, y los problemas con el transporte se resolvieron en el proceso.
¿Por qué se necesita KittenHouse?
Como probablemente sepa, VKontakte funciona en PHP / KPHP, con "motores" (microservicios) en C / C ++ y un poco en Go. PHP no tiene un concepto de "estado" entre las solicitudes, excepto quizás para la memoria compartida y las conexiones abiertas.
Dado que tenemos decenas de miles de servidores desde los cuales queremos poder enviar registros a ClickHouse, no sería rentable mantener conexiones abiertas de cada trabajador PHP (puede haber más de 100 trabajadores para cada servidor). Por lo tanto, necesitamos algún tipo de proxy entre ClickHouse y PHP. Llamamos a este proxy KittenHouse.
KittenHouse, v1
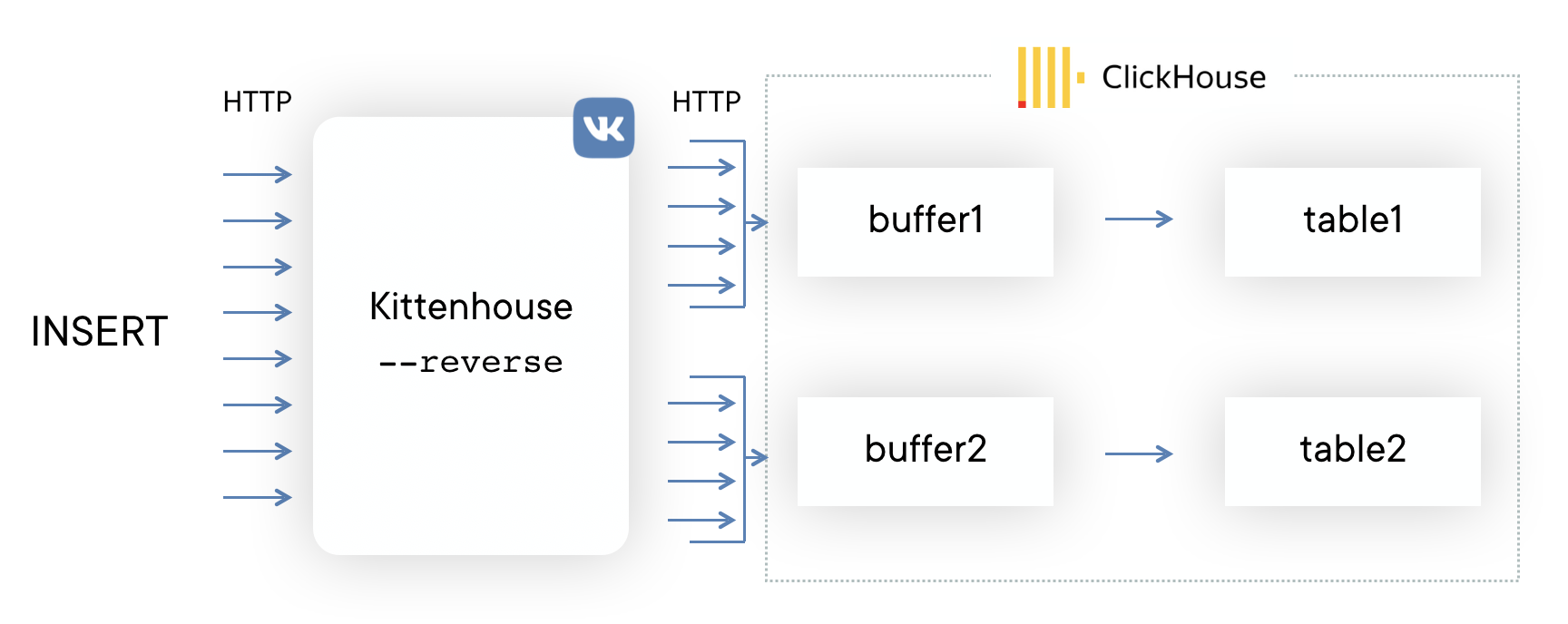
Primero, decidimos probar el esquema más simple posible para comprender si nuestro enfoque funcionará o no. Si Kafka te viene a la mente al resolver este problema, entonces no estás solo. Sin embargo, no queríamos usar servidores intermedios adicionales; en este caso, podríamos descansar fácilmente en el rendimiento de estos servidores y no en ClickHouse. Además, recopilamos registros y necesitábamos un retraso predecible y pequeño en la inserción de datos. El esquema es el siguiente:

En cada uno de los servidores, nuestro proxy local (kittenhouse) está instalado, y cada instancia mantiene estrictamente una conexión HTTP con el servidor ClickHouse necesario. El pegado se realiza en tablas en cola, ya que a menudo no se recomienda insertar MergeTree.
Características KittenHouse, v1
La primera versión de KittenHouse sabía bastante, pero esto fue suficiente para probar:
- Comunicación a través de nuestro RPC (Esquema TL).
- Mantener 1 conexión TCP / IP por servidor.
- Búfer en memoria de forma predeterminada, con un tamaño de búfer limitado (el resto se descarta).
- La capacidad de escribir en el disco, en este caso, hay una garantía de entrega (al menos una vez).
- El intervalo de inserción es una vez cada 2 segundos.
Primeros problemas
Encontramos el primer problema cuando "pagamos" el servidor ClickHouse durante varias horas y luego lo volvimos a encender. A continuación puede ver el promedio de carga en el servidor después de que ha "aumentado":
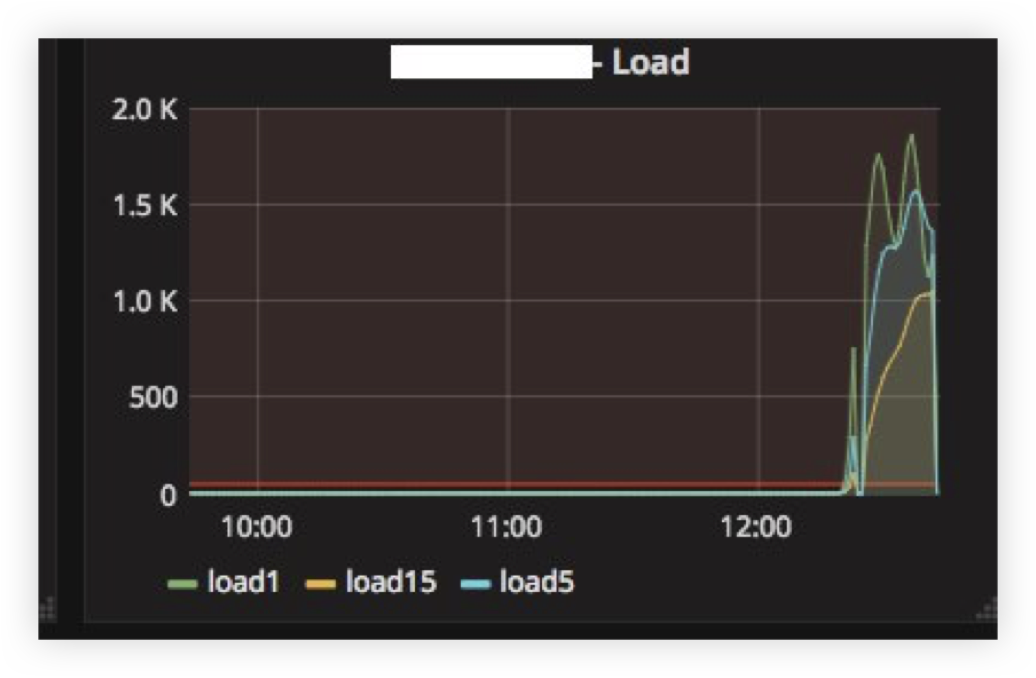
La explicación es bastante simple: ClickHouse tiene una red por modelo de subproceso, por lo que cuando trato de hacer INSERT desde miles de nodos al mismo tiempo, hubo una fuerte competencia por los recursos de la CPU y el servidor apenas respondió. Sin embargo, todos los datos finalmente se insertaron y nada cayó.
Para resolver este problema, colocamos nginx delante de ClickHouse y, en general, ayudó.
Mayor desarrollo
Durante la operación, encontramos varios problemas, principalmente relacionados no con ClickHouse, sino con nuestra forma de operarlo. Aquí hay otro rastrillo que pisamos:
Un gran número de "fragmentos" de tablas de búfer conduce a frecuentes descargas de búfer en MergeTree
En nuestro caso, había 16 piezas de búfer y un intervalo de reinicio cada 2 segundos, y había 20 piezas de tablas, que daban hasta 160 inserciones por segundo. Esto afectó periódicamente el rendimiento de la inserción: hubo muchas fusiones de fondo y la utilización del disco alcanzó el 80% o más.
Solución: aumente el intervalo predeterminado de reinicio del búfer, reduzca el número de piezas a 2.
Nginx devuelve 502 cuando las conexiones al extremo ascendente
Esto en sí mismo no es un problema, pero en combinación con el vaciado frecuente del búfer, esto proporcionó un fondo bastante alto de errores 502 al intentar insertar en cualquiera de las tablas, así como al intentar realizar SELECT.
Solución: escribieron su proxy inverso utilizando la biblioteca
fasthttp , que agrupa la inserción en tablas y consume conexiones de manera muy económica. También distingue entre SELECCIONAR e INSERTAR y tiene agrupaciones de conexiones separadas para inserción y lectura.
Quedarse sin memoria con inserción intensiva
La biblioteca fasthttp tiene sus ventajas y desventajas. Uno de los inconvenientes es que la solicitud y la respuesta están completamente almacenadas en la memoria antes de dar el control al manejador de solicitudes. Para nosotros, esto resultó en el hecho de que si la inserción en ClickHouse "no tenía tiempo", entonces los búferes comenzaron a crecer y, finalmente, se acabó toda la memoria en el servidor, lo que llevó a la eliminación de proxy inverso por parte de OOM. Los colegas dibujaron un desmotivador:
 Solución:
Solución: parchear fasthttp para admitir la transmisión del cuerpo de la solicitud POST resultó ser una tarea desalentadora, por lo que decidimos usar conexiones Hijack () y actualizar la conexión a nuestro protocolo si la solicitud venía con el método HTTP KITTEN. Dado que el servidor debe responder MEOW en respuesta, si comprende este protocolo, todo el esquema se denomina protocolo KITTEN / MEOW.
Solo leemos de 50 conexiones aleatorias a la vez, por lo tanto, gracias a TCP / IP, el resto de los clientes "esperan" y no gastamos memoria en buffers hasta que la cola llegue a los respectivos clientes. Esto redujo el consumo de memoria al menos 20 veces, y no tuvimos más problemas de este tipo.
Las tablas ALTER pueden durar mucho si hay consultas largas
ClickHouse tiene un ALTER sin bloqueo en el sentido de que no interfiere con las consultas SELECT e INSERT. Pero ALTER no puede comenzar hasta que haya terminado de ejecutar consultas a esta tabla enviada antes de ALTER.
Si su servidor tiene un fondo de consultas "largas" para algunas tablas, entonces puede encontrar una situación en la que ALTER en esta tabla no tendrá tiempo para ejecutarse en un tiempo de espera predeterminado de 60 segundos. Pero esto no significa que ALTER fallará: se ejecutará tan pronto como finalicen esas consultas SELECT.
Esto significa que no sabe en qué momento realmente ocurrió ALTER, y no tiene la capacidad de recrear automáticamente las tablas de Buffer para que su diseño sea siempre el mismo. Esto puede conducir a problemas de inserción.

 Solución:
Solución: Como resultado, planeamos abandonar por completo el uso de tablas de búfer. En general, las tablas de búfer tienen un alcance, hasta ahora las usamos y no experimentamos grandes problemas. Pero ahora finalmente llegamos al punto en el que es más fácil implementar la funcionalidad de las tablas de búfer en el lado del proxy inverso que continuar soportando sus deficiencias. Un circuito de ejemplo se verá así (la línea discontinua muestra la asincronía ACK en INSERT).

Lectura de datos
Digamos que descubrimos el inserto. ¿Cómo leer estos registros de ClickHouse? Desafortunadamente, no encontramos ninguna herramienta conveniente y fácil de usar para leer datos sin procesar (sin gráficos y otros) de ClickHouse, por lo que escribimos nuestra propia solución: LightHouse. Sus capacidades son bastante modestas:
- Vista rápida del contenido de la tabla.
- Filtrado, clasificación.
- Edición de una consulta SQL.
- Ver estructura de tabla.
- Muestra el número aproximado de líneas y espacio en disco utilizado.
Sin embargo, LightHouse es rápido y capaz de hacer lo que necesitamos. Aquí hay un par de capturas de pantalla:
Ver estructura de tabla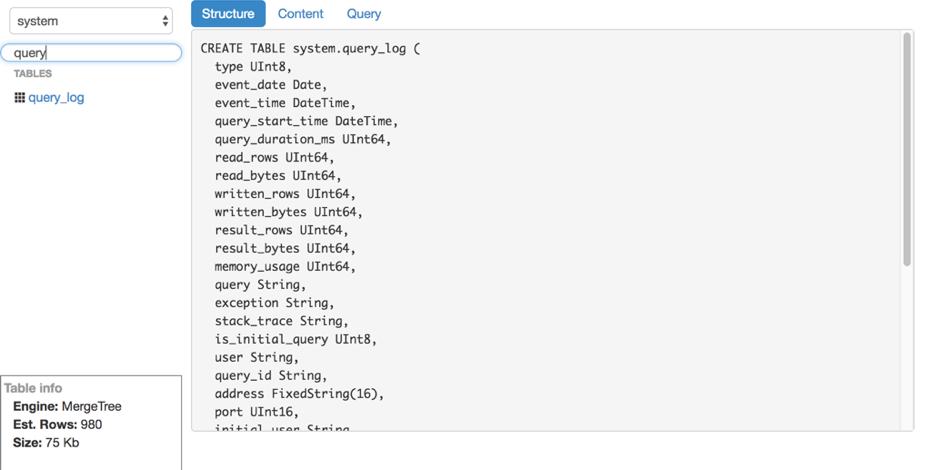 Filtrado de contenido
Filtrado de contenido
Resultados
ClickHouse es prácticamente la única base de datos de código abierto que ha echado raíces en VKontakte. Estamos satisfechos con la velocidad de su trabajo y estamos listos para soportar las deficiencias, que se analizan a continuación.
Dificultad en el trabajo
Con todo, ClickHouse es una base de datos muy estable y muy rápida. Sin embargo, como con cualquier producto, especialmente tan joven, hay características en el trabajo que deben considerarse:
- No todas las versiones son igualmente estables: no actualice directamente a la nueva versión en producción, es mejor esperar varias versiones de corrección de errores.
- Para un rendimiento óptimo, es muy recomendable configurar RAID y algunas otras cosas de acuerdo con las instrucciones. Esto se informó recientemente en alta carga .
- La replicación no tiene límites de velocidad incorporados y puede causar una degradación significativa del rendimiento del servidor si no lo limita usted mismo (pero prometen solucionarlo).
- Linux tiene una característica desagradable del mecanismo de memoria virtual: si escribe activamente en el disco y los datos no tienen tiempo para ser vaciados, en algún momento el servidor "entra en sí mismo" por completo, comienza a vaciar activamente el caché de la página en el disco y bloquea casi por completo el proceso ClickHouse. Esto a veces ocurre con grandes fusiones, y debe supervisar esto, por ejemplo, periódicamente para limpiar los buffers o sincronizar.
Código abierto
KittenHouse y LightHouse ahora están disponibles en código abierto en nuestro repositorio de github:
Gracias
Yuri Nasretdinov, desarrollador en el departamento de infraestructura de back-end de VKontakte