El comercio minorista tiene un círculo muy diverso de clientes. Hay muchos de ellos: diversas profesiones y niveles de ingresos, desde jóvenes hasta personas mayores. Tal variedad no puede describirse correctamente mediante dos o tres reglas comerciales, porque simplemente no puede cubrir todas las combinaciones de criterios e inevitablemente pierde algunos clientes. Por lo tanto, para el comercio minorista es muy importante segmentar su audiencia con la mayor precisión posible, pero esto inevitablemente complica los modelos. Las tecnologías de Machine Learning vienen al rescate aquí, brindando a las empresas pronósticos y respuestas más precisas a preguntas importantes.
¿Qué preguntas quieres decir? Por ejemplo: ¿se irá el cliente? A menudo, los clientes se van si la tienda no tiene el producto correcto. Por ejemplo, una mujer compra una crema especial cada mes por 10 mil rublos y puede elegir entre dos tiendas de cosméticos. En uno de ellos, a menudo falta el producto requerido, y en el segundo no hay problemas con la disponibilidad. Lo más probable es que compre constantemente en el segundo, aunque un poco más caro.
Otra pregunta urgente: ¿cómo optimizar el trabajo del personal? Por ejemplo, debe planificar turnos de trabajo para cajeros y consultores de ventas. Una forma implica el uso de análisis estadístico. El analista evalúa la actividad de los clientes según el día de la semana y ve que los sábados compran más y los viernes y domingos un poco menos. Esta hipótesis se verifica mediante pruebas estadísticas, y las conclusiones se pasan a la gerencia.
Pero tal análisis puede no tener en cuenta muchas combinaciones de factores. Por ejemplo, si el 7 de marzo es el miércoles, ¿comprarán más en este día que el viernes (después de todo, en horarios normales, el viernes es un día más popular que otros días de la semana)? ¿Y la graduación? O vacaciones locales? Cuantos más factores, más difícil es tenerlos en cuenta con la ayuda de reglas simples. Y en lugar de complicar infinitamente las reglas, puede crear un modelo que prediga la demanda de un día en particular.
Nuestro proyecto en retail no alimentario
En este caso, fue necesario analizar la base de clientes (aproximadamente 2.5 millones de personas) y predecir cuál de ellos volvería a la tienda en las próximas dos semanas. Tomamos dos métodos de la biblioteca CatBoost: CatBoostClassifier y CatBoostRegressor, el primero, para predecir la composición de la audiencia, el segundo, para seleccionar los productos más populares en las próximas 2 semanas. CatBoost
salió al comienzo de nuestro proyecto, era un nuevo enfoque para trabajar con atributos categóricos. Y dado que la gama de productos de nuestro cliente contiene muchas características categóricas, con gusto probamos el nuevo producto. Después de seleccionar los parámetros, el modelo cumplió de inmediato nuestras expectativas con pronósticos precisos. No es de extrañar que CatBoost sea uno de los modelos de aumento de gradiente más populares en la actualidad.
Para el modelo, tomamos estadísticas para 2017:
- cheques: quién posee la tarjeta de bonificación del cheque, cuándo se realiza la compra, qué compraron, tamaño de descuento, compra o reembolso.
- demografía: región y ciudad de residencia del cliente, fecha de nacimiento y sexo, consentimiento para envío por teléfono o correo.
- productos: qué categoría o segmento incluye compras, alcance, etc.
Limpiamos los datos de ruido (tarjetas del vendedor, devoluciones, compras de servicios, no bienes) y calculamos los criterios necesarios (porcentaje de descuento, edad). Después de eso, calculamos el recibo más grande y más pequeño para cada cliente, el promedio, la mediana y los descuentos máximos, cuántas veces entró una persona y cuántos productos de qué categorías compró. Estos parámetros se contaron en intervalos: la semana pasada, dos semanas, un mes, tres meses. Tal trabajo meticuloso hizo posible construir modelos con alta precisión de pronóstico.
Datos agregados para modelos y cálculos lanzados. El primer modelo predijo cuál de los compradores vendría en las próximas dos semanas, y el segundo emitió recomendaciones: qué productos (hasta el nivel del artículo) compraría una persona en particular. Por cierto, el requisito de predecir la popularidad de artículos específicos complicó en gran medida la tarea (por lo general, las empresas necesitan pronósticos basados en categorías y nombres de productos en lugar de posiciones).
Los clientes recomendados por el modelo para el envío dirigido tuvieron una verificación mediana más grande para una visita, y durante el período analizado compraron una cantidad total más alta que otros clientes.
Como resultado, después del envío, aproximadamente el 30% de los clientes compraron al menos uno de los tres productos predichos por el modelo.
Ahora la compañía puede predecir con mayor precisión las ventas: el minorista sabe quién vendrá a él en un futuro cercano y qué comprará. Esto ayuda no solo a optimizar la logística, sino también a reducir los costos asociados. Por ejemplo, si un cliente en particular generalmente no compra nada en el invierno, entonces no necesita enviarle un SMS en enero. Los modelos también optimizan los correos: un especialista basado en un pronóstico comprende de inmediato quién debe enviar un correo electrónico y a quién: un SMS urgente.
Trampas
Están en cualquier tarea de ML: estaban en la nuestra. Por ejemplo, probamos si los envíos de recomendaciones de productos ayudan a aumentar las ventas. Para esto, el segmento de clientes previsto se dividió en tres grupos:
- Control - no recibió el boletín informativo.
- Grupo con recordatorios: recibió un texto común de la tienda.
- Grupo con recomendaciones: recibió SMS con tres productos específicos pronosticados por el modelo.
Resultó que las personas que recibieron recomendaciones compraron menos que los clientes que no recibieron boletines. La factura promedio y la cantidad de bienes comprados fueron menores. La prueba T mostró que las diferencias fueron estadísticamente significativas (pvalue = 0.017).
Para decirlo suavemente, tales resultados desanimaron a todos. Comenzaron a buscar la razón y descubrieron que las tiendas enviaban mensajes a los clientes en un mensajero específico, y sus usuarios en nuestro segmento inicialmente compraron menos que otros clientes. Incluso los vendedores del cliente no sabían sobre esto. Entonces, el experimento resultó ser incorrecto, pero de acuerdo con sus resultados, agregamos el parámetro "usuario de mensajería" al modelo. Este caso demuestra cómo seleccionar cuidadosamente los canales de comunicación con los clientes.
¿Qué otras conclusiones se pueden sacar?
- No hay muchos datos.
- A veces, la visión del analista desde el lado lleva a una idea nueva.
Segmentación de clientes
El análisis de datos le permite detectar patrones que estaban ocultos en información previamente disponible. Un buen ejemplo es comparar grupos de clientes usando la segmentación RFM (Recency Frequency Monetary) y la segmentación usando algoritmos ML.
La segmentación de RFM utiliza tres métricas clave:
- Prescripción de la última compra.
- frecuencia de compras para el período
- cantidad gastada por el cliente.
En base a estos datos, se distinguen los grupos principales: "derrochadores", "clientes leales", "clientes casi perdidos", etc. Y los especialistas en marketing ya incluyen el grupo objetivo deseado en un boletín específico o hacen una oferta específicamente para este grupo.
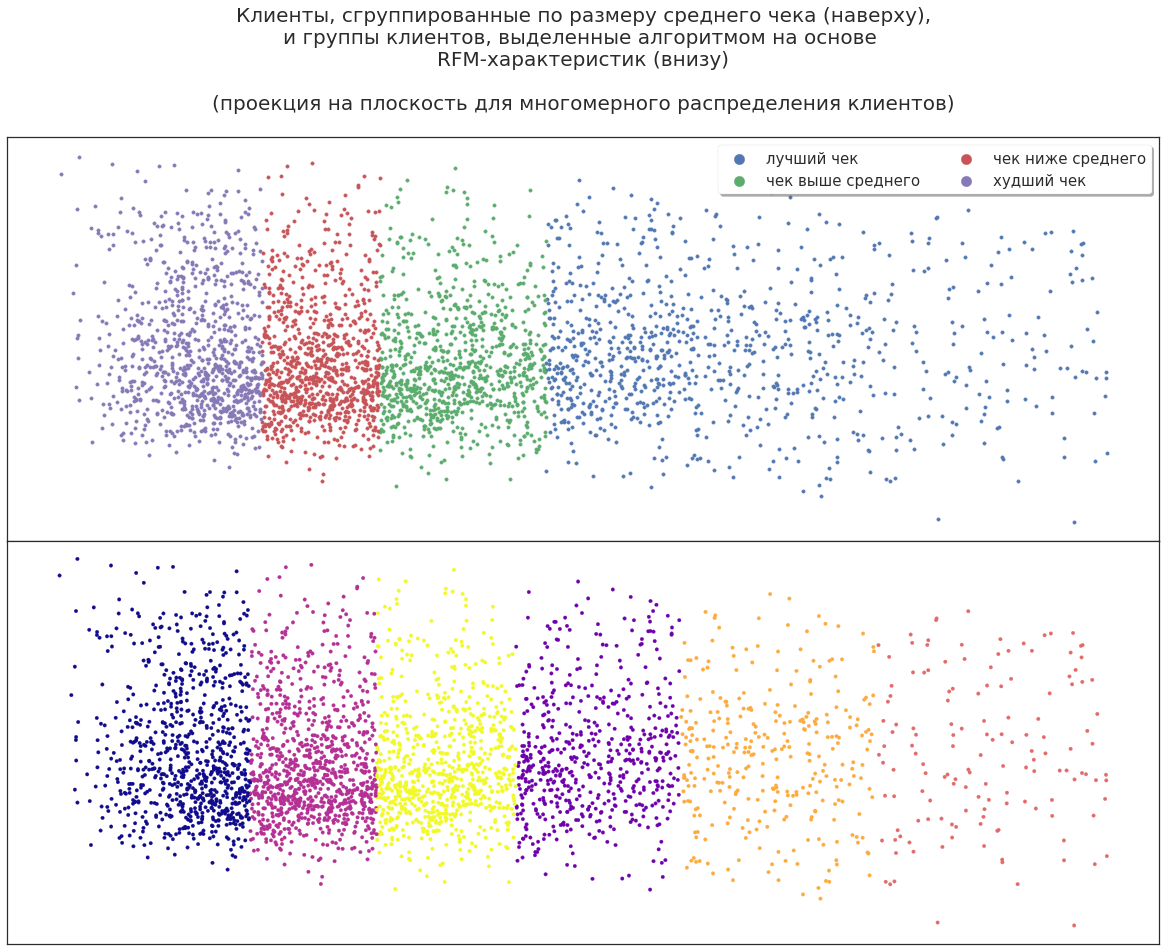
Por ejemplo, con la segmentación de RFM, puede seleccionar segmentos de clientes y representarlos como puntos en un espacio tridimensional:
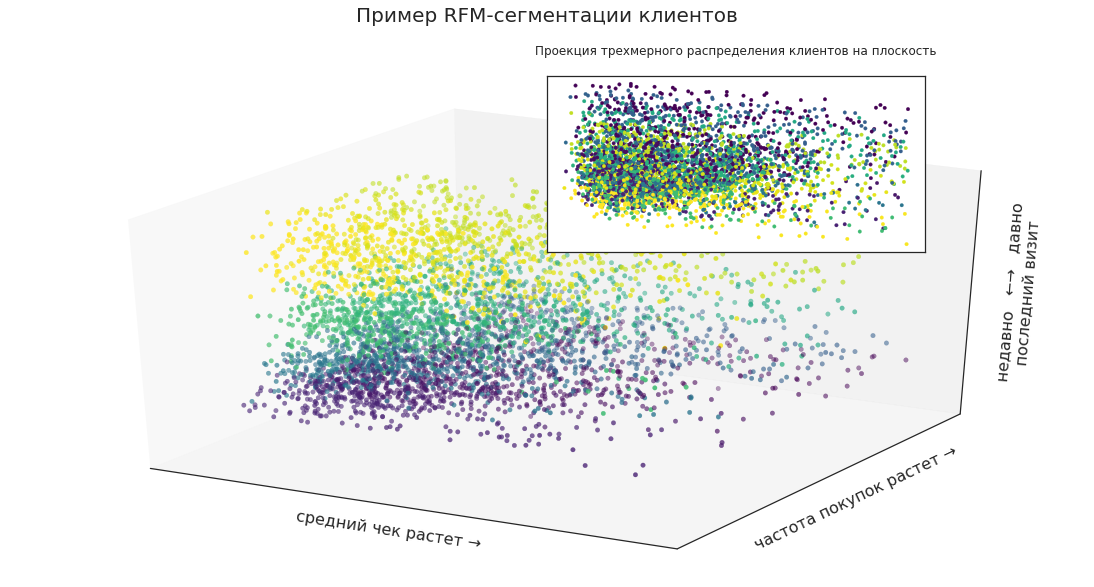
Esto le permite ver visualmente la ubicación de ciertos grupos en la masa total de clientes, sus proporciones y la dinámica de los cambios.
Ahora proyecte la distribución tridimensional de los segmentos en el plano. Los clientes pueden dividirse por los ingresos aportados por la empresa para incluir los más rentables en las campañas de marketing, pero ¿será esto suficiente para una planificación efectiva?
Incluso en dichos datos, el algoritmo de aprendizaje automático encuentra posibilidades adicionales: divide a los clientes en nuevos grupos grandes. Puede analizar esta partición para averiguar por qué el algoritmo dividió a los clientes de esta manera. Por ejemplo, algunos clientes altamente rentables son expertos que acompañan a sus clientes en las compras y usan sus tarjetas de descuento; algunos comparten activamente sus tarjetas con amigos y conocidos. Es decir, después del primer uso de ML, puede obtener información adicional sobre sus clientes basándose en los mismos datos.
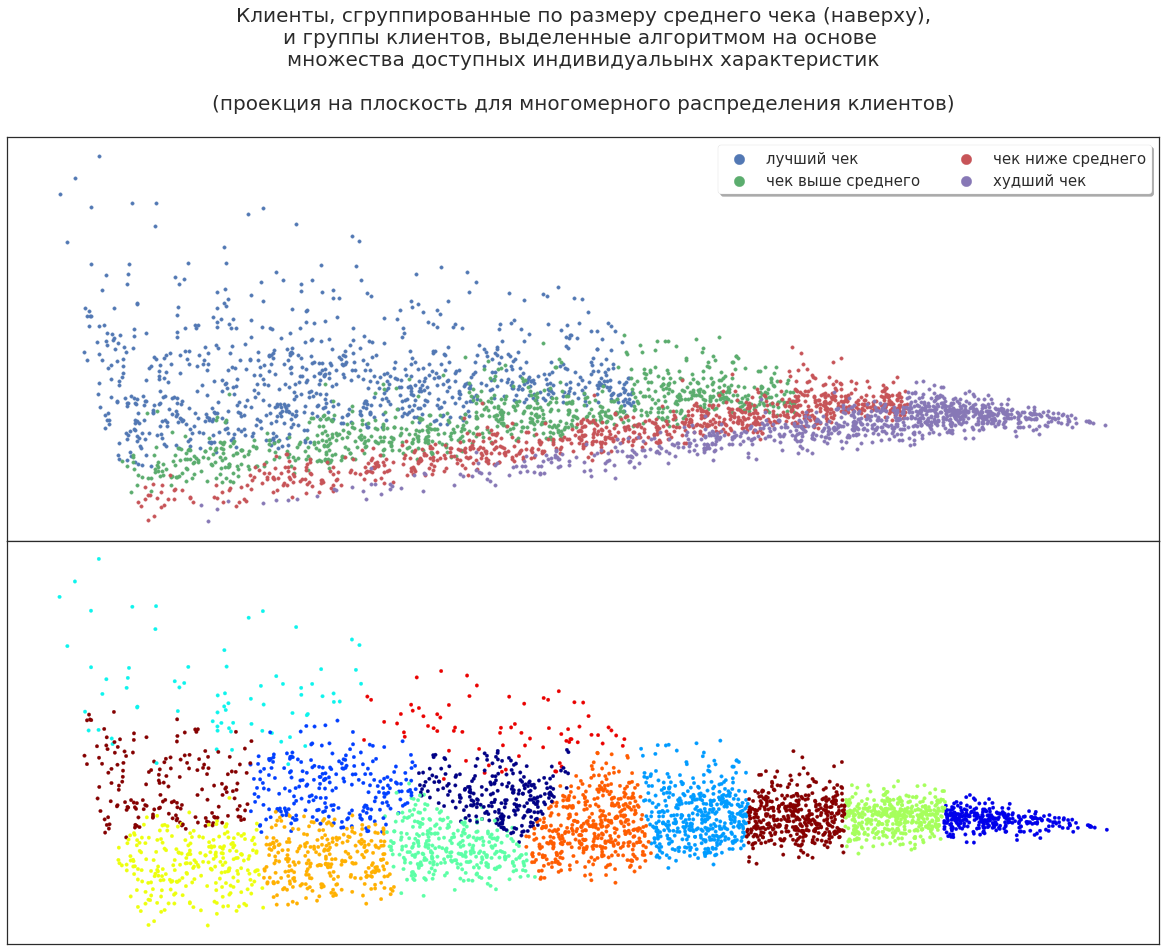
Expandamos el conjunto de características del cliente: agregue género, edad, comportamientos y más. ¿Cómo ahora el algoritmo distribuirá compradores?
Por ejemplo, hay un grupo que cubre tanto a los mejores clientes (los más rentables) como a sus "vecinos", que generan menos ganancias. Por qué el algoritmo asignó este grupo es una pregunta para el analista. Quizás estos clientes con estimulación adicional muestren mayor rentabilidad. O, por el contrario, estos clientes no son particularmente prometedores, y el aumento de la rentabilidad fue una desviación aleatoria; no tiene sentido estimularlos. Se pueden presentar varias teorías, pero deben verificarse experimentalmente.
Planificación de almacenes: previsión de ventas
Además, el proyecto tiene varias opciones de desarrollo. Por ejemplo, puede pronosticar compras en una tienda en particular para el próximo período. Luego, el administrador de la tienda podrá ordenar los productos necesarios del almacén central a tiempo.
El análisis de las compras en un punto de venta particular ayudará a formular la exhibición de productos en las ventanas de exhibición. Por ejemplo, si muchos compradores masculinos vienen a la tienda, el departamento con productos masculinos no debe ubicarse en la esquina más alejada.
No te olvides de la llamada canibalización de las tiendas. Es decir, si dos puntos de venta de la misma red están cerca (por ejemplo, en diferentes extremos de la misma calle), uno de ellos puede alejar a los clientes y el segundo permanecerá inactivo. Puede construir un modelo que rastree tales fenómenos y señale al respecto.
***
En resumen, el aprendizaje automático es una herramienta poderosa que puede hacer mucho. A menudo, cuando se construyen modelos, se revelan patrones no obvios que ni siquiera los usuarios empresariales sabían. Sin embargo, la calidad del modelo depende mucho de la calidad y cantidad de datos.
Analistas de la Dirección de Desarrollo e Implementación de Software, Jet Infosystems