Como ingeniero de infraestructura en el equipo de desarrollo de la plataforma en la nube , tuve la oportunidad de trabajar con muchos sistemas de almacenamiento distribuido, incluidos los que se indican en el encabezado. Parece que hay una comprensión de sus fortalezas y debilidades, y trataré de compartir mis pensamientos con usted sobre este tema. Por así decirlo, veamos quién tiene más tiempo la función hash.

Descargo de responsabilidad: anteriormente en este blog podías ver artículos sobre GlusterFS. No tengo nada que ver con estos artículos. Este es el blog del autor del equipo de proyecto de nuestra nube y cada uno de sus miembros puede contar su historia. El autor de esos artículos es ingeniero de nuestro grupo operativo y tiene sus propias tareas y su experiencia, que compartió. Tenga esto en cuenta si de repente ve una diferencia de opinión. ¡Aprovecho esta oportunidad para transmitir mis saludos al autor de esos artículos!
Lo que se discutirá
Hablemos de los sistemas de archivos que se pueden construir sobre la base de GlusterFS y CephFS. Discutiremos la arquitectura de estos dos sistemas, los veremos desde diferentes ángulos y al final incluso me arriesgaré a sacar conclusiones. Otras características de Ceph, como RBD y RGW, no se verán afectadas.
Terminología
Para que el artículo sea completo y comprensible para todos, veamos la terminología básica de ambos sistemas:
Terminología cefálica:
RADOS (Reliable Autonomic Distributed Object Store) es un almacenamiento de objetos autónomo, que es la base del proyecto Ceph.
CephFS , RBD (RADOS Block Device), RGW (RADOS Gateway): gadgets de alto nivel para RADOS, que proporcionan a los usuarios finales varias interfaces para RADOS.
Específicamente, CephFS proporciona una interfaz de sistema de archivos compatible con POSIX. De hecho, los datos de CephFS se almacenan en RADOS.
OSD (Object Storage Daemon) es un proceso que sirve un almacenamiento separado de disco / objeto en un clúster RADOS.
RADOS Pool (pool): varios OSD unidos por un conjunto común de reglas, como, por ejemplo, una política de replicación. Desde el punto de vista de la jerarquía de datos, un grupo es un directorio o un espacio de nombres separado (plano, sin subdirectorios) para objetos.
PG (Placement Group): presentaré el concepto de PG un poco más tarde, en el contexto, para una mejor comprensión.
Dado que RADOS es la base sobre la cual se construye CephFS, a menudo hablaré sobre esto y esto se aplicará automáticamente a CephFS.
Terminología de GlusterFS (en adelante gl):
Brick es un proceso que sirve un solo disco, un análogo de OSD en la terminología RADOS.
Volumen : volumen en el que se unen los ladrillos. Tom es un análogo de grupo en RADOS, también tiene una topología de replicación específica entre ladrillos.
Distribución de datos
Para hacerlo más claro, considere un ejemplo simple que puede ser implementado por ambos sistemas.
La configuración que se utilizará como ejemplo:
- 2 servidores (S1, S2) con 3 discos de igual volumen (sda, sdb, sdc) en cada uno;
- volumen / grupo con replicación 2.
Ambos sistemas necesitan al menos 3 servidores para su funcionamiento normal. Pero hacemos la vista gorda a esto, ya que este es solo un ejemplo para un artículo.
En el caso de gl, este será un volumen distribuido-replicado que consta de 3 grupos de replicación:

Cada grupo de replicación es dos ladrillos en diferentes servidores.
De hecho, resulta el volumen que combina los tres RAID-1.
Cuando lo monte, obtenga el sistema de archivos deseado y comience a escribir archivos en él, encontrará que cada archivo que escribe pertenece a uno de estos grupos de replicación como un todo.
La distribución de archivos entre estos grupos distribuidos es manejada por DHT (Distributed Hash Tables), que es esencialmente una función hash (volveremos a ello más adelante).
En el "diagrama" se verá así:
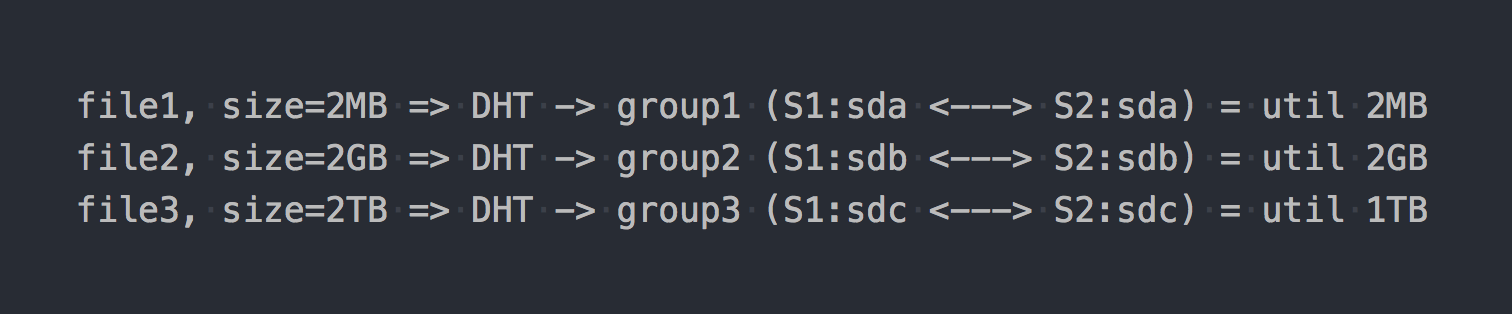
Como si las primeras características arquitectónicas ya se hubieran manifestado:
- el lugar en grupos se desecha de manera desigual, depende del tamaño de los archivos;
- al escribir un archivo, IO va solo a un grupo, el resto está inactivo;
- No puede obtener el IO de todo el volumen al escribir un solo archivo;
- Si no hay suficiente espacio en el grupo para escribir el archivo, recibirá un error, el archivo no se escribirá y no se redistribuirá a otro grupo.
Si usa otros tipos de volúmenes, por ejemplo, Distributed-Striped-Replicated o incluso Dispersed (Erasure Coding), solo la mecánica de la distribución de datos dentro de un grupo cambiará fundamentalmente. DHT también descompondrá los archivos completamente en estos grupos, y al final tendremos los mismos problemas. Sí, si el volumen consistirá en un solo grupo, o si tiene todos los archivos de aproximadamente el mismo tamaño, entonces no habrá ningún problema. Pero estamos hablando de sistemas normales, bajo cientos de terabytes de datos, incluidos archivos de diferentes tamaños, por lo que creemos que hay un problema.
Ahora echemos un vistazo a CephFS. Los RADOS mencionados anteriormente entran en escena. En RADOS, cada disco es servido por un proceso separado: OSD. Según nuestra configuración, solo obtenemos 6 de ellos, 3 en cada servidor. A continuación, necesitamos crear un grupo para los datos y establecer el número de PG y el factor de replicación de datos en este grupo, en nuestro caso 2.
Digamos que creamos un grupo con 8 PG. Estas PG se distribuirán de manera más o menos uniforme en todo el OSD:
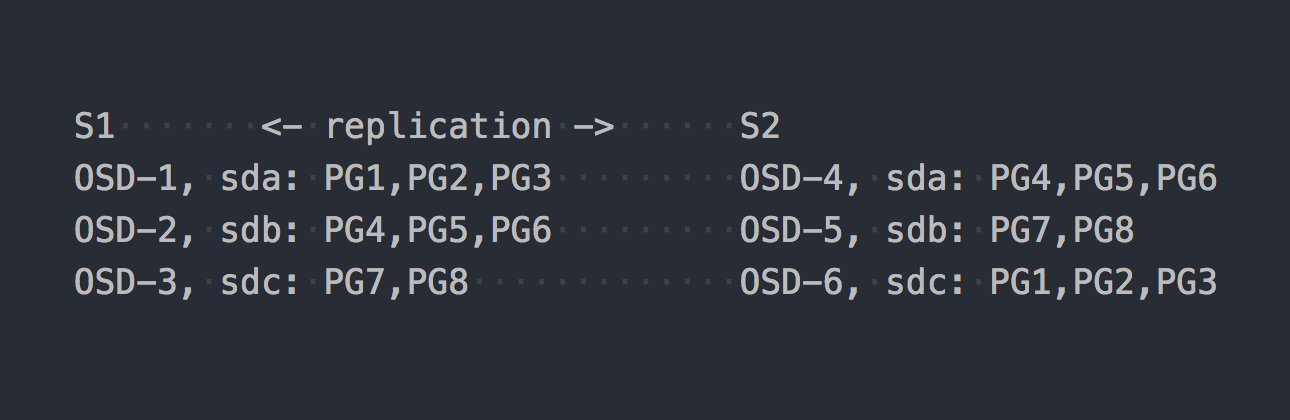
Es hora de aclarar que PG es un grupo lógico que combina varios objetos. Dado que establecemos el hecho de replicación 2, cada PG tiene una réplica en algún otro OSD en otro servidor (por defecto). Por ejemplo, PG1, que está en OSD-1 en el servidor S1, tiene un gemelo en S2 en OSD-6. En cada par de PG (o triple, si la replicación 3) es PRIMARY PG, que se está registrando. Por ejemplo, PRIMARY para PG4 está en S1, pero PRIMARY para PG3 está en S2.
Ahora que sabe cómo funciona RADOS, podemos pasar a escribir archivos en nuestro nuevo grupo. Aunque RADOS es un almacenamiento completo, no es posible montarlo como un sistema de archivos o usarlo como un dispositivo de bloque. Para escribir datos directamente en él, debe usar una utilidad o biblioteca especial.
Escribimos los mismos tres archivos que en el ejemplo anterior:
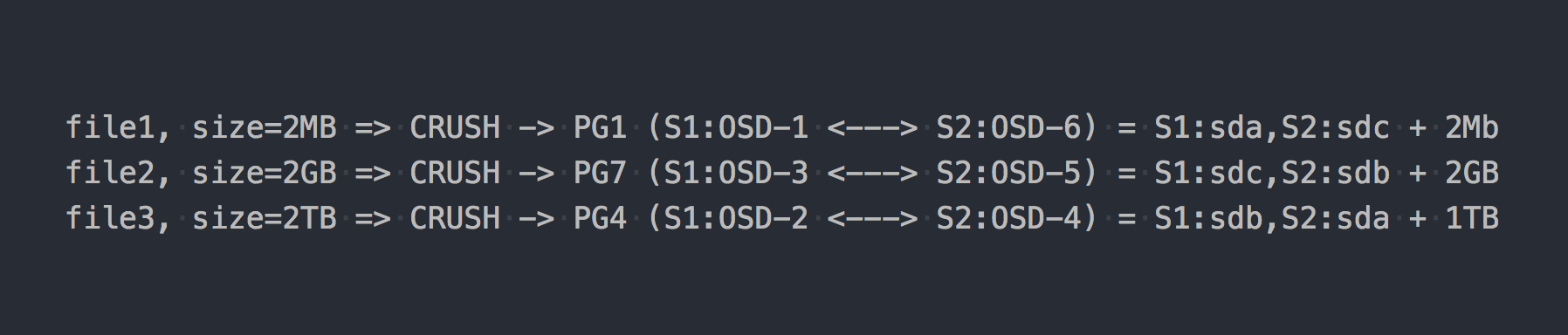
En el caso de RADOS, todo se ha vuelto algo más complicado, de acuerdo.
Entonces CRUSH (Replicación controlada bajo hash escalable) apareció en la cadena. CRUSH es el algoritmo en el que se apoya RADOS (volveremos a ello más adelante). En este caso particular, usando este algoritmo, se determina dónde se debe escribir el archivo en qué PG. Aquí CRUSH realiza la misma función que DHT en gl. Como resultado de esta distribución pseudoaleatoria de archivos en PG, obtuvimos los mismos problemas que gl, solo en un esquema más complejo.
Pero deliberadamente guardé silencio sobre un punto importante. Casi nadie usa RADOS en su forma pura. Para un trabajo conveniente con RADOS, se desarrollaron las siguientes capas: RBD, CephFS, RGW, que ya mencioné.
Todos estos traductores (clientes RADOS) proporcionan una interfaz de cliente diferente, pero son similares en su trabajo con RADOS. La similitud más importante es que todos los datos que pasan a través de ellos se cortan en pedazos y se colocan en RADOS como objetos RADOS separados. Por defecto, los clientes oficiales cortan el flujo de entrada en 4 MB. Para RBD, el tamaño de la franja se puede establecer al crear el volumen. En el caso de CephFS, este es el atributo (xattr) del archivo y se puede administrar a nivel de archivos individuales o para todos los archivos de catálogo. Bueno, RGW también tiene un parámetro correspondiente.
Ahora supongamos que apilamos CephFS sobre el grupo RADOS que se presentó en el ejemplo anterior. Ahora los sistemas en cuestión están completamente en igualdad de condiciones y proporcionan una interfaz de acceso a archivos idéntica.
Si volvemos a escribir nuestros archivos de prueba en el nuevo CephFS, encontraremos una distribución de datos completamente diferente y casi uniforme en el OSD. Por ejemplo, el archivo 2 de 2 GB de tamaño se dividirá en 512 piezas, que se distribuirán en diferentes PG y, como resultado, en diferentes OSD de manera casi uniforme, y esto prácticamente resuelve los problemas con la distribución de datos descritos anteriormente.
En nuestro ejemplo, solo se utilizan 8 PG, aunque se recomienda tener ~ 100 PG en un OSD. Y necesita 2 grupos para que CephFS funcione. También necesita algunos demonios de servicio para que RADOS funcione en principio. No pienses que todo es tan simple, específicamente omito mucho, para no apartarme de la esencia.
Entonces ahora CephFS parece más interesante, ¿verdad? Pero no mencioné otro punto importante, esta vez sobre gl. Gl también tiene un mecanismo para cortar archivos en trozos y ejecutar esos trozos a través de DHT. El llamado sharding ( Sharding ).
Historia de cinco minutos
El 21 de abril de 2016, el equipo de desarrollo de Ceph lanzó "Jewel", la primera versión de Ceph en la que CephFS se considera estable.
¡Esto es todo un grito a la izquierda y a la derecha sobre CephFS! Y hace 3-4 años usarlo sería al menos una decisión dudosa. Buscamos otras soluciones, y gl con la arquitectura descrita anteriormente no era bueno. Pero creíamos en él más que en CephFS, y esperamos la fragmentación, que se estaba preparando para el lanzamiento.
Y aquí está el día X:
4 de junio de 2015: la Comunidad Gluster anunció hoy la disponibilidad general del software de almacenamiento definido por software abierto GlusterFS 3.7.
3.7 - la primera versión de gl, en la cual el sharding se anunció como una oportunidad experimental. Tenían casi un año antes del lanzamiento estable de CephFS para poder establecerse en el podio ...
Entonces fragmentar significa. Como todo en gl, esto se implementa en un traductor separado, que estaba por encima del DHT (también traductor) en la pila. Como es más alto que DHT, DHT recibe fragmentos listos para usar en la entrada y los distribuye entre los grupos de replicación como archivos normales. Sharding está habilitado en el nivel de volumen individual. El tamaño del fragmento se puede configurar, de forma predeterminada, 4 MB, como lociones Ceph.
Cuando realicé las primeras pruebas, ¡estaba encantado! ¡Les dije a todos que gl ahora es lo más importante y ahora viviremos! Con el fragmentado habilitado, la grabación de un archivo va en paralelo a diferentes grupos de replicación. La descompresión después de la compresión "al escribir" puede ser incremental al nivel de fragmento. En presencia de disparos en caché aquí, también, todo se vuelve bueno y fragmentos separados se mueven al caché, y no a los archivos completos. En general, me alegré, porque Parecía que había conseguido un instrumento genial en sus manos.
Quedaba por esperar las primeras correcciones de errores y el estado de "listo para la producción". Pero todo resultó no tan color de rosa ... Para no estirar el artículo con una lista de errores críticos relacionados con el fragmentación, que de vez en cuando surgen en las próximas versiones, solo puedo decir que el último "problema importante" con la siguiente descripción:
La expansión de un volumen de reflejo fragmentado puede provocar daños en el archivo. Los volúmenes fragmentados generalmente se usan para imágenes de VM, si tales volúmenes se expanden o posiblemente se contraen (es decir, agregar / eliminar ladrillos y reequilibrar) hay informes de imágenes de VM que se corrompen.
se cerró en la versión 3.13.2, 20 de enero de 2018 ... ¿tal vez esta no sea la última?
Comentario sobre uno de nuestros artículos sobre esto, por así decirlo, de primera mano.
RedHat en su documentación para el actual RedHat Gluster Storage 3.4 señala que el único caso de fragmentación que admiten es el almacenamiento para discos VM.
Sharding tiene un caso de uso compatible: en el contexto de proporcionar Red Hat Gluster Storage como un dominio de almacenamiento para Red Hat Enterprise Virtualization, para proporcionar almacenamiento para imágenes de máquinas virtuales en vivo. Tenga en cuenta que el particionamiento también es un requisito para este caso de uso, ya que proporciona mejoras significativas de rendimiento con respecto a implementaciones anteriores.
No sé por qué tal restricción, pero debes admitir que es alarmante.
Ahora tengo todo aquí para ti
Ambos sistemas utilizan una función hash para distribuir datos de forma pseudoaleatoria entre los discos.
Para RADOS, se ve más o menos así:
PG = pool_id + "." + jenkins_hash(object_name) % pg_coun # eg pool id=5 => pg = 5.1f OSD = crush_hash_based_on_jenkins(PG) # eg pg=5.1f => OSD = 12
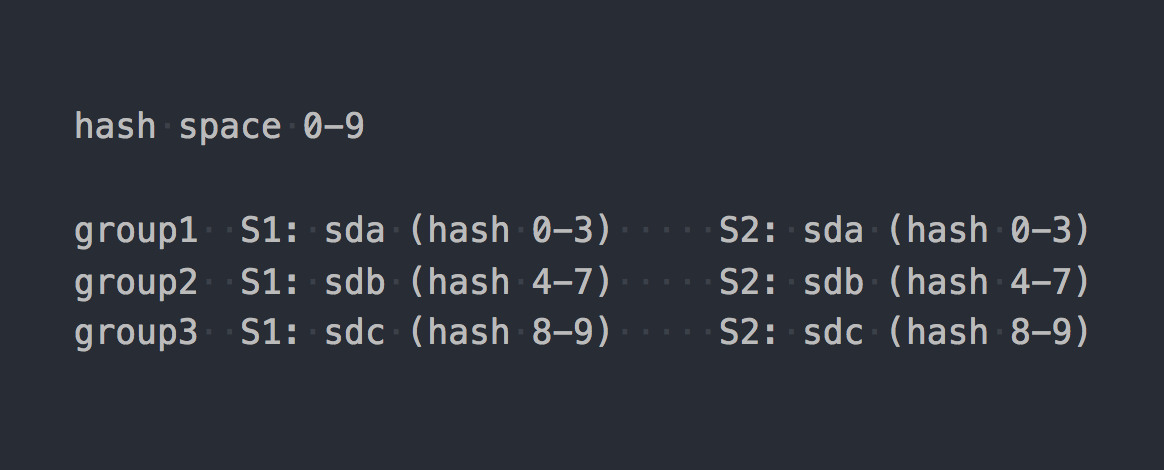
Gl usa el llamado hashing consistente . Cada ladrillo obtiene un "rango dentro de un espacio hash de 32 bits". Es decir, todos los ladrillos comparten el espacio hash de dirección lineal completo sin rangos ni agujeros de intersección. El cliente ejecuta el nombre del archivo a través de la función hash, y luego determina en qué rango de hash cae el hash recibido. Así se selecciona ladrillo. Si hay varios ladrillos en el grupo de replicación, entonces todos tienen el mismo rango de hash. Algo como esto:
Si llevamos el trabajo de dos sistemas a una cierta forma lógica, resultará algo como esto:
file -> HASH -> placement_unit
donde ubicación_unidad en el caso de RADOS es PG, y en el caso de gl es un grupo de replicación de varios ladrillos.
Entonces, una función hash, luego esta distribuye, distribuye archivos, y de repente resulta que una ubicación_unidad se utiliza más que la otra. Tal es la característica fundamental de los sistemas de distribución hash. Y nos enfrentamos a una tarea muy común: desequilibrar los datos.
Gl es capaz de reconstruir, pero debido a la arquitectura con los rangos de hash descritos anteriormente, puede ejecutar la reconstrucción tanto como desee, pero ningún rango de hash (y, como resultado, los datos) no se moverán. El único criterio para redistribuir los rangos de hash es un cambio en la capacidad de volumen. Y le queda una opción: agregar ladrillos. Y si estamos hablando de un volumen con replicación, entonces debemos agregar un grupo de replicación completo, es decir, dos nuevos ladrillos en nuestra configuración. Después de expandir el volumen, puede comenzar a reconstruir: los rangos de hash se redistribuirán teniendo en cuenta el nuevo grupo y se distribuirán los datos. Cuando se elimina un grupo de replicación, los rangos de hash se asignan automáticamente.
RADOS tiene todo un coche de posibilidades. En un artículo de Ceph, me quejé mucho sobre el concepto de PG, pero aquí, en comparación con gl, por supuesto, RADOS a caballo. Cada OSD tiene su propio peso, generalmente se establece en función del tamaño del disco. A su vez, los OSD distribuyen los PG según el peso de este último. Todo, luego solo cambiamos el peso del OSD hacia arriba o hacia abajo y el PG (junto con los datos) comienza a moverse a otros OSD. Además, cada OSD tiene un peso de ajuste adicional, que le permite equilibrar los datos entre los discos de un servidor. Todo esto es inherente a CRUSH. El beneficio principal es que no es necesario expandir la capacidad del grupo para desequilibrar mejor los datos. Y no es necesario agregar discos en grupos, solo puede agregar un OSD y una parte de PG se transferirá a él.
Sí, es posible que al crear un grupo no crearan suficiente PG y resultó que cada uno de los PG es bastante grande en volumen, y donde quiera que se muevan, el desequilibrio permanecerá. En este caso, puede aumentar el número de PG, y se dividen en más pequeños. Sí, si el clúster está lleno de datos, entonces duele, pero lo principal en nuestra comparación es que existe esa oportunidad. Ahora solo se permite un aumento en el número de PG y con esto debe ser más cuidadoso, pero en la próxima versión de Ceph - Nautilus habrá soporte para reducir el número de PG (fusión de páginas).
Replicación de datos
Nuestros grupos y volúmenes de prueba tienen un factor de replicación de 2. Curiosamente, los sistemas en cuestión utilizan diferentes enfoques para lograr este número de réplicas.
En el caso de RADOS, el esquema de grabación se parece a esto:
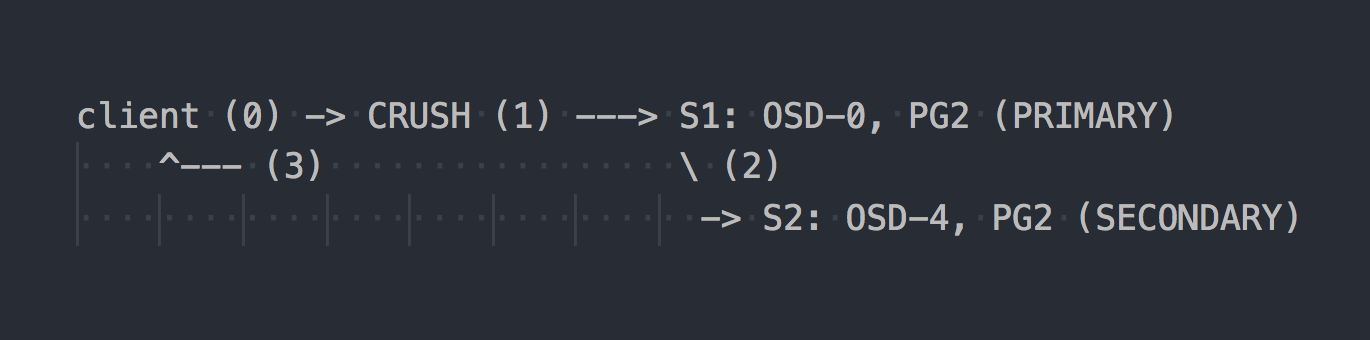
El cliente conoce la topología de todo el clúster, usa CRUSH (paso 0) para seleccionar un PG específico para escritura, escribe en PRIMARY PG en OSD-0 (paso 1), luego OSD-0 replica sincrónicamente los datos en SECUNDARY PG (paso 2), y solo después paso 2 exitoso / no exitoso, OSD confirma / no confirma la operación al cliente (paso 3). La replicación de datos entre dos OSD es transparente para el cliente. Los OSD generalmente pueden usar un "clúster" separado, una red más rápida para la replicación de datos.
Si se configura la replicación triple, entonces también se ejecuta sincrónicamente con OSD PRIMARIO en dos SECUNDARIOS, transparente para el cliente ... bueno, solo que la letanía es mayor.
Gl funciona de manera diferente:
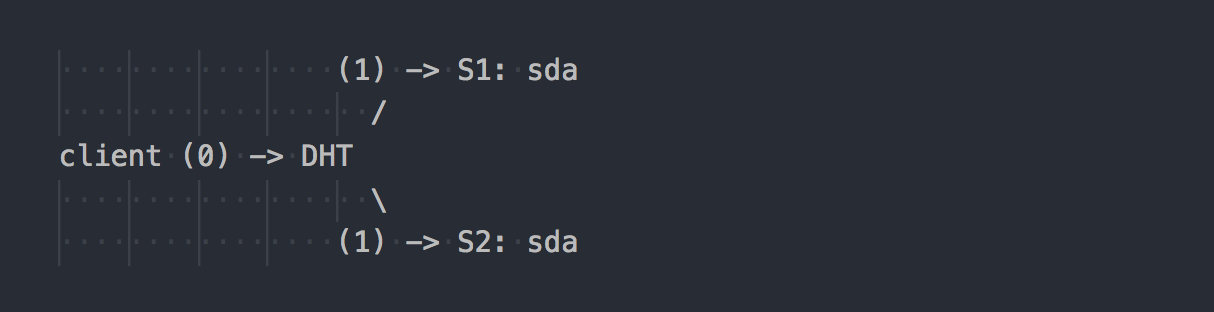
El cliente conoce la topología del volumen, usa DHT (paso 0) para determinar el ladrillo deseado, luego escribe en él (paso 1). Todo es simple y claro. Pero aquí recordamos que todos los ladrillos en el grupo de replicación tienen el mismo rango de hash. Y esta característica menor hace que todas las vacaciones. El cliente escribe en paralelo a todos los ladrillos que tienen un rango hash adecuado.
En nuestro caso, con doble replicación, el cliente realiza una grabación dual en paralelo en dos ladrillos diferentes. Durante la replicación triple, se realizará una grabación triple, respectivamente, y 1 MB de datos se convertirá aproximadamente en 3 MB de tráfico de red desde el cliente al lado de los servidores gl. De acuerdo, los conceptos de sistemas son perpendiculares.
En tal esquema, se asigna más trabajo al cliente gl y, como resultado, necesita más CPU, bueno, ya dije sobre la red.
La replicación la realiza el traductor AFP (Replicación automática de archivos): un xlator del lado del cliente que realiza la replicación sincrónica. Las réplicas escriben en todos los ladrillos de la réplica → Utiliza un modelo de transacción.
Si es necesario, sincronice las réplicas en el grupo (curación), por ejemplo, después de una indisponibilidad temporal de un ladrillo, los demonios gl lo hacen solos utilizando el AFP incorporado, transparente para los clientes y sin su participación.
Es interesante que si no trabaja a través del cliente gl nativo, sino que escribe a través del servidor NFS incorporado en gl, obtendremos el mismo comportamiento que RADOS. En este caso, AFP se utilizará en demonios gl para replicar datos sin intervención del cliente. Pero el NFS incorporado está asegurado en gl v4, y si desea este comportamiento, se recomienda usar NFS-Ganesha.
Por cierto, debido a un comportamiento tan diferente cuando se usa NFS y el cliente nativo, puede ver indicadores de rendimiento completamente diferentes.
¿Tienes el mismo grupo, solo "en la rodilla"?
A menudo veo en Internet discusiones sobre todo tipo de configuraciones de rótula, donde se construye un clúster de datos a partir de lo que está a la mano. En este caso, una solución basada en RADOS puede darle más libertad al elegir sus unidades. En RADOS, puede agregar unidades de casi cualquier tamaño. Cada disco tendrá un peso correspondiente a su tamaño (generalmente), y los datos se distribuirán entre los discos casi proporcionalmente a su peso. En el caso de gl, no existe el concepto de "discos separados" en volúmenes con replicación. Los discos se agregan en pares en doble replicación o se triplican en triple. Si hay discos de diferentes tamaños en un grupo de replicación, se encontrará con un lugar en el disco más pequeño del grupo y desplegará la capacidad de los discos grandes. En dicho esquema, gl supondrá que la capacidad de un grupo de replicación es igual a la capacidad del disco más pequeño del grupo, lo cual es lógico. Al mismo tiempo, se permite tener grupos de replicación que consisten en discos de diferentes tamaños, grupos de diferentes tamaños. Los grupos más grandes pueden recibir un rango de hash más grande en relación con otros grupos y, como resultado, recibir más datos.
Hemos estado viviendo con Ceph por quinto año. Comenzamos con discos del mismo volumen, ahora presentamos otros más espaciosos. Con Ceph, puede quitar el disco y reemplazarlo por otro más grande o un poco más pequeño sin ninguna dificultad arquitectónica. Con gl, todo es más complicado: sacó un disco de 2 TB, coloque el mismo, por favor. Bueno, o retirar todo el grupo en su conjunto, lo que no es muy bueno, de acuerdo.
Conmutación por error
Ya nos familiarizamos un poco con la arquitectura de las dos soluciones y ahora podemos hablar sobre cómo vivir con ella y cuáles son las características al realizar el mantenimiento.
Supongamos que rechazamos sda en s1, algo común.
En el caso de gl:
- una copia de los datos en el disco en vivo que queda en el grupo no se redistribuye automáticamente a otros grupos;
- hasta que se reemplace el disco, solo queda una copia de los datos;
- Cuando se reemplaza un disco fallido por uno nuevo, la replicación se realiza de un disco en funcionamiento a uno nuevo (1 en 1).
Esto es como servir un estante con múltiples RAID-1. Sí, con la triple replicación, si falla una unidad, no queda una copia, sino dos, pero este enfoque aún tiene serios inconvenientes, y los mostraré con un buen ejemplo con RADOS.
Supongamos que fallamos sda en S1 (OSD-0), algo común:
- Los PG que estaban en OSD-0 se reasignarán automáticamente a otros OSD después de 10 minutos (predeterminado). En nuestro ejemplo, en OSD 1 y 2. Si había más servidores, entonces en un mayor número de OSD.
- Los PG que almacenan la segunda copia sobreviviente de los datos los replicarán automáticamente en aquellos OSD donde se transfieren los PG restaurados. Resulta una replicación de muchos a muchos, no una replicación uno a uno como gl.
- Cuando se introduce un nuevo disco, en lugar de uno roto, se acumularán algunas PG de acuerdo con su peso en el nuevo OSD y se redistribuirán los datos de otros OSD.
Creo que no tiene sentido explicar las ventajas arquitectónicas de RADOS. No puede contraerse cuando recibe una carta que dice que la unidad falló. Y cuando venga a trabajar por la mañana, descubra que todas las copias que faltan ya se han restaurado en docenas de otros OSD o en el proceso. En clústeres grandes, donde cientos de PG se distribuyen en un montón de discos, la recuperación de datos de un OSD puede tener lugar a velocidades mucho más altas que la velocidad de un disco debido al hecho de que están involucradas docenas de OSD (lectura y escritura). Bueno, tampoco debes olvidarte del equilibrio de carga.
Escalamiento
En este contexto, probablemente le daré al pedestal gl. En un artículo sobre Ceph, ya escribí sobre algunas de las complejidades de la escala RADOS asociadas con el concepto PG. Si el aumento de PG con el crecimiento del grupo aún se puede experimentar, entonces, ¿qué pasa con Ceph MDS no está claro? CephFS se ejecuta sobre RADOS y utiliza un grupo separado para metadatos y un proceso especial, el servidor de metadatos seph (MDS), para atender los metadatos del sistema de archivos y coordinar todas las operaciones con el FS. No digo que tener MDS ponga fin a la escalabilidad de CephFS, no, especialmente porque puede ejecutar múltiples MDS en modo activo-activo. Solo quiero señalar que gl está arquitectónicamente desprovisto de todo esto. No tiene contraparte PG, nada como MDS. Gl realmente escala perfectamente simplemente agregando grupos de replicación, casi linealmente.
En los días anteriores a CephFS, diseñamos la solución para los petabytes de datos y analizamos gl. Luego tuvimos dudas sobre la escalabilidad de gl y lo descubrimos a través de la lista de correo. Aquí está una de las respuestas (P: mi pregunta):
Estoy usando 60 servidores, cada uno tiene discos de 26x8TB, un total de 1560 discos, 16 + 4 de volumen EC con 9PB de espacio utilizable.
P: ¿Utiliza libgfapi o FUSE o NFS en el lado del cliente?
Uso FUSE y tengo casi 1000 clientes.
P: ¿Cuántos archivos tienes en tu volumen?
P: ¿Los archivos son más grandes o más pequeños?
Tengo más de 1 millón de archivos y se utiliza% 13 del clúster, lo que hace que el tamaño promedio de los archivos sea de 1 GB.
El tamaño mínimo / máximo del archivo es de 100 MB / 2 GB. Todos los días entran en el volumen 10-20 TB de datos nuevos.
P: ¿Qué tan rápido funciona "ls"?
Las operaciones de metadatos son lentas como esperas. Intento no poner más de 2-3K archivos en un directorio. Mi caso de uso es para copia de seguridad / archivo, por lo que rara vez hago operaciones de metadatos.
Renombrar archivos
Volver a las funciones hash nuevamente. Descubrimos cómo se enrutan archivos específicos a discos específicos, y ahora la pregunta se vuelve relevante, pero ¿qué sucederá al cambiar el nombre de los archivos?
Después de todo, si cambiamos el nombre del archivo, entonces el hash en su nombre también cambiará, lo que significa el lugar de este archivo en otro disco (en un rango de hash diferente) o en otro PG / OSD en el caso de RADOS. Sí, pensamos correctamente, y aquí en dos sistemas todo vuelve a ser perpendicular.
En el caso de gl, al cambiar el nombre de un archivo, el nuevo nombre se ejecuta a través de una función hash, se define un nuevo bloque y se crea un enlace especial al antiguo bloque, donde el archivo permanece como antes. Topovka, ¿verdad? Para que los datos realmente se muevan a un nuevo lugar, y el cliente no hizo clic en el enlace innecesariamente, debe hacer un nuevo equilibrio.
Pero RADOS generalmente no tiene un método para renombrar objetos solo por la necesidad de su movimiento posterior. Se propone utilizar una copia justa para renombrar, lo que conduce a un movimiento sincrónico del objeto. Y CephFS, que se ejecuta sobre RADOS, tiene una carta de triunfo bajo la manga en forma de un grupo con metadatos y MDS. Cambiar el nombre del archivo no afecta el contenido del archivo en el grupo de datos.
Replicación 2.5
Gl tiene una característica muy interesante que me gustaría mencionar por separado. Todos entienden que la replicación 2 no es una configuración confiable, pero sin embargo se realiza periódicamente para estar bastante justificada. Para protegerse contra el cerebro dividido en tales esquemas y para garantizar la coherencia de los datos, gl le permite crear volúmenes con la réplica 2 y un árbitro adicional. El árbitro es aplicable para la replicación de 3 o más. Este es el mismo bloque en el grupo que los otros dos, solo que en realidad solo crea una estructura de archivos a partir de archivos y directorios. Los archivos en un ladrillo de este tipo son de tamaño cero, pero sus atributos extendidos del sistema de archivos (atributos extendidos) se mantienen sincronizados con archivos de tamaño completo en la misma réplica. Creo que la idea es clara. Creo que esta es una buena oportunidad.
El único momento ... el tamaño del lugar en el grupo de replicación está determinado por el tamaño del ladrillo más pequeño, y esto significa que el árbitro debe deslizar un disco al menos del mismo tamaño que el resto del grupo. Para hacer esto, se recomienda crear ficticios LV delgados (delgados), tamaños grandes, para no usar un disco real.
¿Y qué hay de los clientes?
La API nativa de los dos sistemas se implementa en forma de bibliotecas libgfapi (gl) y libcephfs (CephFS). Los enlaces para idiomas populares también están disponibles. En general, con las bibliotecas, todo es igual de bueno. El ubicuo NFS-Ganesha es compatible con ambas bibliotecas como FSAL, que también es la norma. Qemu también admite la API gl nativa a través de libgfapi.
Pero fio (Flexible I / O Tester) ha soportado libgfapi por mucho tiempo y con éxito, pero no es compatible con libcephfs. Este es un plus gl, porque usar fio es realmente bueno para probar gl directamente. Solo trabajando desde el espacio de usuario a través de libgfapi obtendrá todo lo que gl puede de gl.
Pero si estamos hablando del sistema de archivos POSIX y de cómo montarlo, gl solo puede ofrecer el cliente FUSE y la implementación de CephFS en el núcleo ascendente. Está claro que en el módulo del núcleo puede hacer un truco que FUSE mostrará un mejor rendimiento. Pero en la práctica, FUSE siempre es una sobrecarga en el cambio de contexto. Personalmente, he visto más de una vez cómo FUSE dobló un servidor de doble socket solo con CS.
De alguna manera, Linus dijo:
Sistema de archivos del espacio de usuario? El problema está justo ahí. Siempre ha sido. Las personas que piensan que los sistemas de archivos del espacio de usuario son realistas para cualquier cosa que no sean juguetes simplemente están equivocados.
Los desarrolladores de Gl, por el contrario, piensan que FUSE es genial. Se dice que esto brinda más flexibilidad y se separa de las versiones del kernel. En cuanto a mí, usan FUSE porque gl no se trata de velocidad. De alguna manera está escrito, bueno, es normal, y molestarse con la implementación en el núcleo es realmente extraño.
Rendimiento
No habrá comparaciones).
Esto es muy complicado. Incluso en una configuración idéntica, es demasiado difícil realizar pruebas objetivas. De todos modos, habrá alguien en los comentarios que dará 100500 parámetros que "aceleran" uno de los sistemas y dirán que las pruebas son una mierda. Por lo tanto, si está interesado, pruébelo, por favor.
Conclusión
RADOS y CephFS, en particular, son una solución más compleja tanto en comprensión, configuración y mantenimiento.
Pero personalmente, me gusta la arquitectura de RADOS y correr sobre CephFS más que GlusterFS. Más manejadores (PG, peso OSD, jerarquía CRUSH, etc.), los metadatos CephFS aumentan la complejidad, pero dan más flexibilidad y hacen que esta solución sea más efectiva, en mi opinión.
Ceph se adapta mucho mejor a los criterios SDS actuales y me parece más prometedor. Pero esta es mi opinión, ¿qué te parece?