Traducción de arquitecturas de redes neuronalesLos algoritmos de las redes neuronales profundas han ganado gran popularidad hoy, lo que está garantizado en gran medida por la arquitectura bien pensada. Veamos la historia de su desarrollo en los últimos años. Si está interesado en un análisis más profundo, consulte
este trabajo .
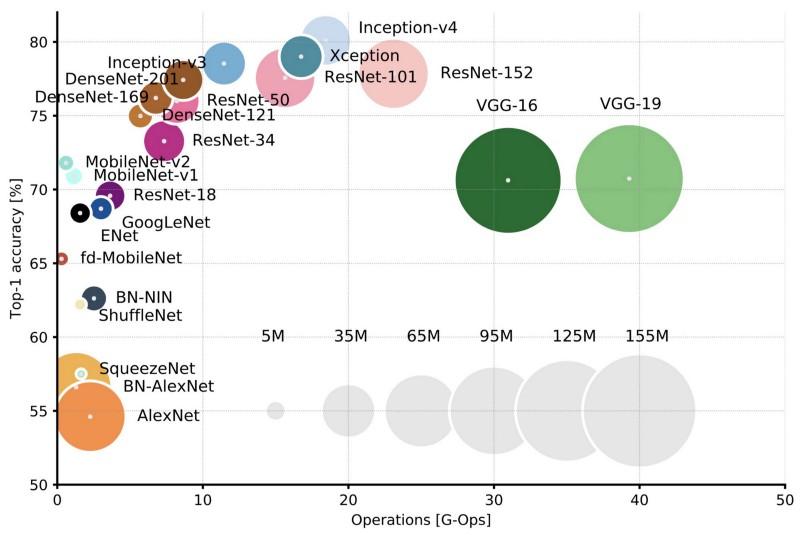 Comparación de arquitecturas populares para la precisión de un cultivo Top-1 y el número de operaciones requeridas para un pase directo. Más detalles aquí .
Comparación de arquitecturas populares para la precisión de un cultivo Top-1 y el número de operaciones requeridas para un pase directo. Más detalles aquí .Lenet5
En 1994, se desarrolló una de las primeras redes neuronales convolucionales, que sentó las bases para el aprendizaje profundo. Este trabajo pionero de Yann LeCun, después de muchas iteraciones exitosas desde 1988, se llamó
LeNet5 .

La arquitectura LeNet5 se ha convertido en fundamental para el aprendizaje profundo, especialmente en términos de la distribución de las propiedades de la imagen en toda la imagen. Las convoluciones con los parámetros de aprendizaje permitieron usar varios parámetros para extraer eficientemente las mismas propiedades de diferentes lugares. En esos años, no había tarjetas de video que pudieran acelerar el proceso de aprendizaje, e incluso los procesadores centrales eran lentos. Por lo tanto, la ventaja clave de la arquitectura era la capacidad de guardar parámetros y resultados de cálculo, en contraste con el uso de cada píxel como datos de entrada separados para una gran red neuronal multicapa. En LeNet5, los píxeles no se usan en la primera capa, ya que las imágenes están fuertemente correlacionadas espacialmente, por lo que usar píxeles individuales como propiedades de entrada no le permitirá aprovechar estas correlaciones.
Características de LeNet5:
- Una red neuronal convolucional que utiliza una secuencia de tres capas: capas de convolución, capas de agrupación y capas de no linealidad -> desde la publicación del trabajo de Lekun, esta es quizás una de las principales características del aprendizaje profundo en relación con las imágenes.
- Utiliza convolución para recuperar propiedades espaciales.
- Submuestreo usando promedios de mapas espaciales.
- No linealidad en forma de tangente hiperbólica o sigmoidea.
- El clasificador final en forma de red neuronal multicapa (MLP).
- La escasa matriz de conectividad entre las capas reduce la cantidad de cómputo.
Esta red neuronal formó la base de muchas arquitecturas posteriores e inspiró a muchos investigadores.
Desarrollo
De 1998 a 2010, las redes neuronales estuvieron en estado de incubación. La mayoría de las personas no notaron sus capacidades de crecimiento, aunque muchos desarrolladores gradualmente perfeccionaron sus algoritmos. Gracias al apogeo de las cámaras de teléfonos móviles y el abaratamiento de las cámaras digitales, cada vez hay más datos de capacitación disponibles para nosotros. Al mismo tiempo, las capacidades informáticas crecieron, los procesadores se volvieron más potentes y las tarjetas de video se convirtieron en la principal herramienta informática. Todos estos procesos permitieron el desarrollo de redes neuronales, aunque bastante lento. El interés en las tareas que podrían resolverse con la ayuda de las redes neuronales fue creciendo, y finalmente la situación se hizo evidente ...
Dan ciresan net
En 2010, Dan Claudiu Ciresan y Jurgen Schmidhuber publicaron una de las primeras descripciones de la implementación de
redes neuronales de
GPU . Su trabajo contenía la implementación directa e inversa de una red neuronal de 9 capas en el
NVIDIA GTX 280 .
Alexnet
En 2012, Alexei Krizhevsky publicó
AlexNet , una versión en profundidad y extendida de LeNet, que ganó por un amplio margen en la difícil competencia de ImageNet.
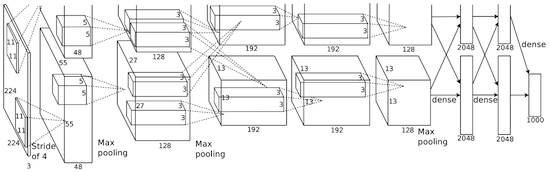
En AlexNet, los resultados de los cálculos de LeNet se escalan en una red neuronal mucho más grande, que puede estudiar objetos mucho más complejos y sus jerarquías. Características de esta solución:
- Uso de unidades de rectificación lineal (ReLU) como no linealidades.
- El uso de técnicas de descarte para ignorar selectivamente las neuronas individuales durante el entrenamiento, lo que evita el sobreentrenamiento del modelo.
- Superposición de agrupación máxima, lo que evita los efectos de promediar la agrupación promedio.
- Usando NVIDIA GTX 580 para acelerar el aprendizaje.
En ese momento, el número de núcleos en las tarjetas de video había crecido significativamente, lo que permitió reducir el tiempo de entrenamiento en aproximadamente 10 veces, y como resultado fue posible usar conjuntos de datos e imágenes mucho más grandes.
El éxito de AlexNet lanzó una pequeña revolución, las redes neuronales convolucionales se han convertido en un caballo de batalla del aprendizaje profundo: este término ahora significa "grandes redes neuronales que pueden resolver tareas útiles".
Sobrepeso
En diciembre de 2013, el laboratorio de la NYU de Jan Lekun publicó una descripción de
Overfeat , una variante de AlexNet. Además, el artículo describía los cuadros delimitadores entrenados, y posteriormente se publicaron muchos otros trabajos sobre este tema. Creemos que es mejor aprender a segmentar objetos, en lugar de usar cajas de límite artificiales.
Vgg
En las redes
VGG desarrolladas en Oxford, en cada capa convolucional, por primera vez, se usaron filtros 3x3, e incluso estas capas se combinaron en una secuencia de convoluciones.
Esto contradice los principios establecidos en LeNet, según los cuales se utilizaron grandes convoluciones para extraer las mismas propiedades de imagen. En lugar de los filtros 9x9 y 11x11 utilizados en AlexNet, comenzaron a usarse filtros mucho más pequeños, peligrosamente cercanos a convoluciones 1x1, que los autores de LeNet intentaron evitar, al menos en las primeras capas de la red. Pero la gran ventaja de VGG fue el hallazgo de que varias convoluciones 3x3 combinadas en una secuencia pueden emular campos receptivos más grandes, por ejemplo, 5x5 o 7x7. Estas ideas luego se utilizarán en las arquitecturas Inception y ResNet.
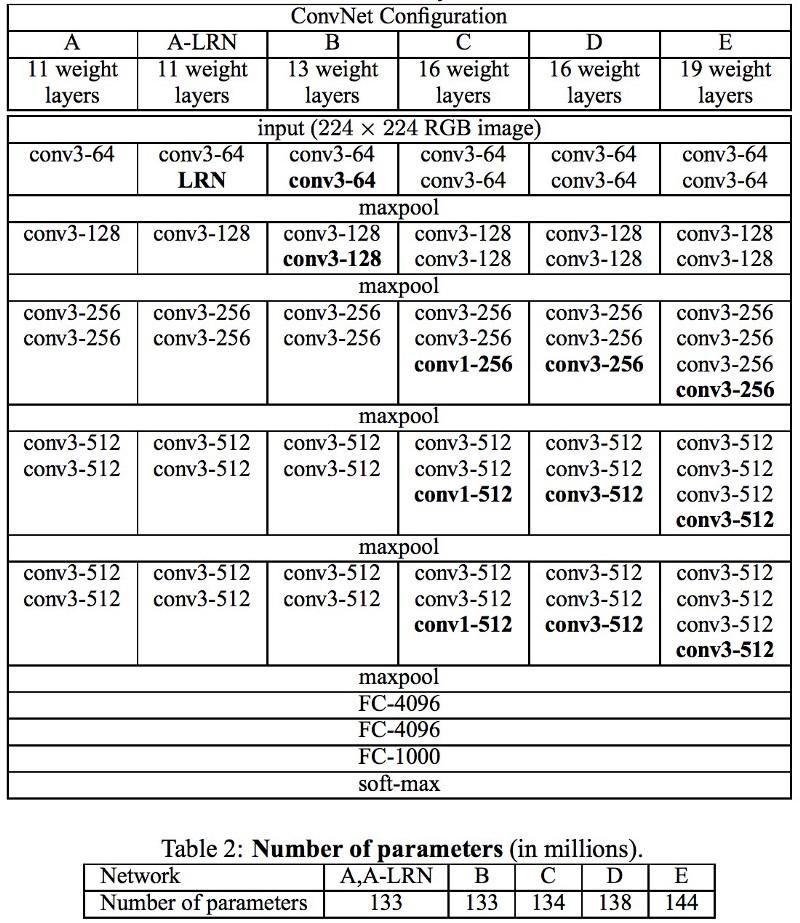
Las redes VGG usan múltiples capas convolucionales de 3x3 para representar propiedades complejas. Preste atención a los bloques 3, 4 y 5 en VGG-E: para extraer propiedades más complejas y combinarlas, se utilizan secuencias de filtro 256 × 256 y 512 × 512 3 × 3. ¡Esto es equivalente a un clasificador convolucional grande 512x512 con tres capas! Esto nos da una gran cantidad de parámetros y excelentes habilidades de aprendizaje. Pero fue difícil aprender tales redes; tuve que dividirlas en otras más pequeñas, agregando capas una por una. La razón fue la falta de formas efectivas para regularizar modelos o algunos métodos para limitar un gran espacio de búsqueda, que es promovido por muchos parámetros.
VGG en muchas capas utiliza una gran cantidad de propiedades, por lo que la capacitación fue
computacionalmente costosa . La carga se puede reducir reduciendo el número de propiedades, como se hace en las capas de cuello de botella de la arquitectura Inception.
Red en red
La arquitectura de
red en red (NiN) se basa en una idea simple: usar convoluciones 1x1 para aumentar la combinatoria de propiedades en capas convolucionales.
En NiN, después de cada convolución, se utilizan capas espaciales de MLP para combinar mejor las propiedades antes de alimentar a la siguiente capa. Puede parecer que el uso de convoluciones 1x1 contradice los principios LeNet originales, pero en realidad permite combinar propiedades mejor que simplemente rellenar más capas convolucionales. Este enfoque es diferente del uso de píxeles desnudos como entrada para la siguiente capa. En este caso, las convoluciones 1x1 se usan para la combinación espacial de propiedades después de la convolución dentro del marco de los mapas de propiedades, por lo que puede usar muchos menos parámetros que son comunes a todos los píxeles de estas propiedades.
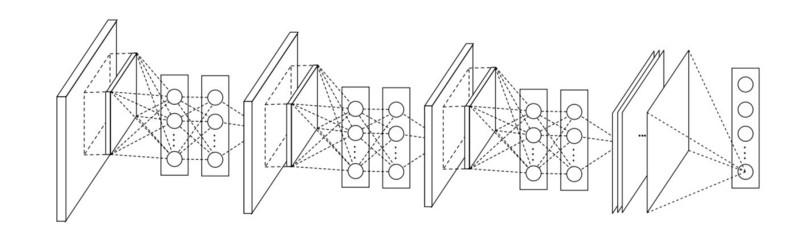
MLP puede aumentar en gran medida la eficacia de las capas convolucionales individuales combinándolas en grupos más complejos. Esta idea fue utilizada más tarde en otras arquitecturas, como ResNet, Inception y sus variantes.
GoogLeNet e Inception
Google Christian Szegedy está preocupado por reducir los cálculos en redes neuronales profundas y, como resultado, creó
GoogLeNet, la primera arquitectura de inicio .
Para el otoño de 2014, los modelos de aprendizaje profundo se habían vuelto muy útiles para categorizar contenido de imágenes y marcos de videos. Muchos escépticos han reconocido los beneficios del aprendizaje profundo y las redes neuronales, y los gigantes de Internet, incluido Google, se han interesado mucho en desplegar redes eficientes y grandes en sus capacidades de servidor.
Christian estaba buscando formas de reducir la carga computacional en las redes neuronales, logrando el mayor rendimiento (por ejemplo, en ImageNet). O preservar la cantidad de cómputo, pero aún así aumentar la productividad.
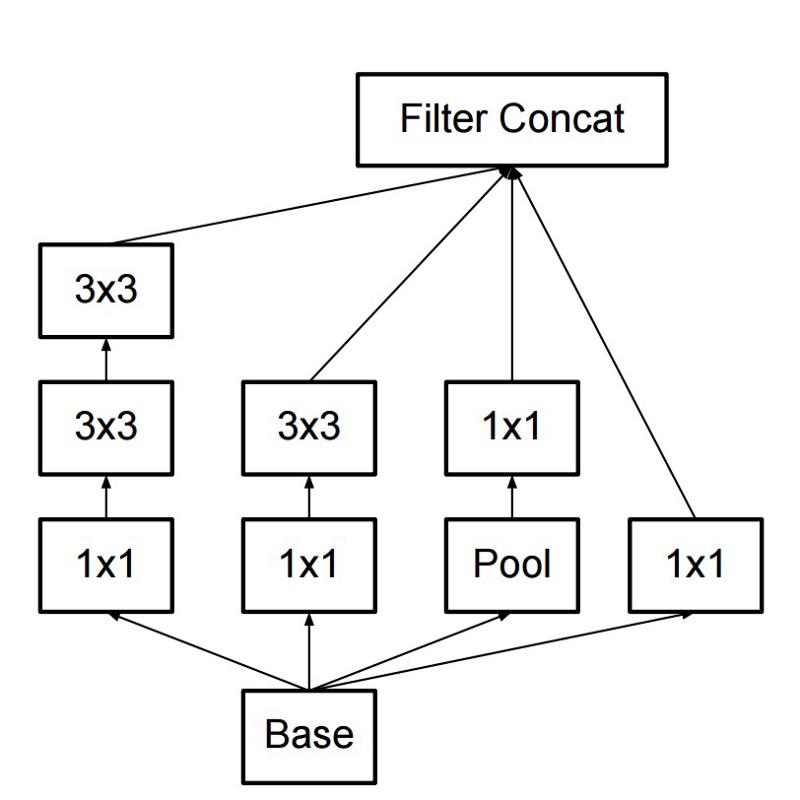
Como resultado, el comando creó un módulo Inception:

A primera vista, esta es una combinación paralela de filtros convolucionales 1x1, 3x3 y 5x5. Pero lo más destacado fue el uso de bloques de convolución 1x1 (NiN) para reducir el número de propiedades antes de servir en los bloques paralelos "caros". Por lo general, esta parte se llama cuello de botella, se describe con más detalle en el próximo capítulo.
GoogLeNet usa un vástago sin módulos de inicio como la capa inicial, y también usa una agrupación promedio y un clasificador softmax similar a NiN. Este clasificador realiza muy pocas operaciones en comparación con AlexNet y VGG. También ayudó a crear una
arquitectura de red neuronal muy eficiente .
Capa de cuello de botella
Esta capa reduce el número de propiedades (y, por lo tanto, operaciones) en cada capa, de modo que la velocidad de obtención del resultado se puede mantener a un nivel alto. Antes de transferir datos a módulos convolucionales "costosos", el número de propiedades se reduce, por ejemplo, 4 veces. Esto reduce en gran medida la cantidad de cómputo, lo que ha hecho que la arquitectura sea popular.
Vamos a resolverlo. Supongamos que tenemos 256 propiedades en la entrada y 256 en la salida, y dejamos que la capa de inicio realice solo convoluciones de 3x3. Obtenemos convoluciones de 256x256x3x3 (589,000 operaciones de multiplicación de acumulación, es decir, operaciones MAC). Esto puede ir más allá de nuestros requisitos de velocidad computacional; digamos que una capa se procesa en 0.5 milisegundos en Google Server. Luego reduzca el número de propiedades para plegar a 64 (256/4). En este caso, primero realizamos una convolución 1x1 de 256 -> 64, luego otra convolución 64 en todas las ramas de inicio, y luego nuevamente aplicamos una convolución 1x1 de 64 -> 256 propiedades. Número de operaciones:
- 256 × 64 × 1 × 1 = 16,000
- 64 × 64 × 3 × 3 = 36,000
- 64 × 256 × 1 × 1 = 16,000
¡Solo alrededor de 70,000, redujeron el número de operaciones en casi 10 veces! Pero al mismo tiempo, no perdimos la generalización en esta capa. Las capas de cuello de botella han demostrado un excelente rendimiento en el conjunto de datos de ImageNet y se han utilizado en arquitecturas posteriores como ResNet. La razón de su éxito es que las propiedades de entrada están correlacionadas, lo que significa que puede deshacerse de la redundancia combinando correctamente propiedades con convoluciones 1x1. Y después de doblar con menos propiedades, puede volver a implementarlas en una combinación significativa en la siguiente capa.
Inicio V3 (y V2)
Christian y su equipo han demostrado ser investigadores muy efectivos. En febrero de 2015, se introdujo la arquitectura
Inception normalizada por lotes como la segunda versión de
Inception . La normalización por lotes calcula la media y la desviación estándar de todos los mapas de distribución de propiedades en la capa de salida, y normaliza sus respuestas con estos valores. Esto corresponde al "blanqueamiento" de los datos, es decir, las respuestas de todos los mapas neuronales se encuentran en el mismo rango y con una media cero. Este enfoque facilita el aprendizaje, ya que la siguiente capa no requiere recordar desplazamientos de datos de entrada y solo puede buscar las mejores combinaciones de propiedades.
En diciembre de 2015,
se lanzó una
nueva versión de los módulos Inception y la arquitectura correspondiente . El artículo del autor explica mejor la arquitectura original de GoogLeNet, que cuenta mucho más sobre las decisiones tomadas. Ideas clave
- Maximizando el flujo de información en la red debido al cuidadoso equilibrio entre su profundidad y ancho. Antes de cada agrupación, los mapas de propiedades aumentan.
- Con el aumento de la profundidad, el número de propiedades o el ancho de la capa también aumenta sistemáticamente.
- El ancho de cada capa aumenta para aumentar la combinación de propiedades antes de la siguiente capa.
- En la medida de lo posible, solo se utilizan convoluciones 3x3. Dado que los filtros 5x5 y 7x7 se pueden descomponer usando múltiples 3x3
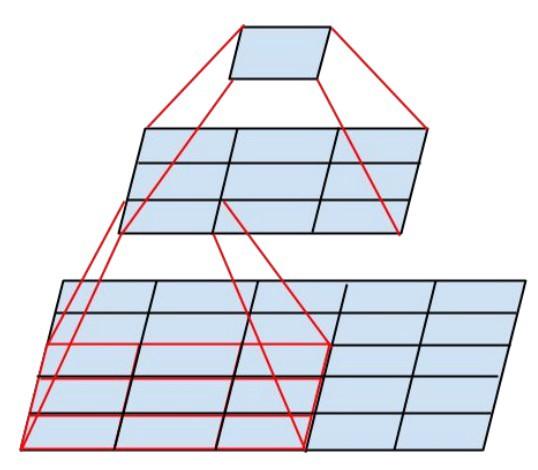
El nuevo módulo de inicio se ve así:
- Los filtros también se pueden descomponer mediante convoluciones suavizadas en módulos más complejos:

- Los módulos de inicio pueden reducir el tamaño de los datos mediante la agrupación durante los cálculos de inicio. Esto es similar a realizar una convolución con zancadas en paralelo con una capa de agrupación simple:

Inception usa la capa de agrupación con softmax como el clasificador final.
Resnet
En diciembre de 2015, aproximadamente al mismo tiempo que se introdujo la arquitectura Inception v3, se produjo una revolución: publicaron
ResNet . Contiene ideas simples: envíe la salida de dos capas convolucionales exitosas ¡Y omita la entrada para la siguiente capa!

Tales ideas ya se han propuesto, por ejemplo,
aquí . Pero en este caso, los autores omiten DOS capas y aplican el enfoque a gran escala. Omitir una capa no ofrece muchos beneficios, y omitir dos es un hallazgo clave. ¡Esto puede verse como un pequeño clasificador, como red en red!
También fue el primer ejemplo de entrenamiento de una red de varios cientos, incluso miles de capas.
ResNet multicapa utilizó una capa de cuello de botella similar a la utilizada en Inception:

Esta capa reduce el número de propiedades en cada capa, primero usando una convolución 1x1 con una salida más baja (generalmente una cuarta parte de la entrada), luego una capa 3x3, y luego convolucionando 1x1 en una mayor cantidad de propiedades. Como en el caso de los módulos Inception, esto ahorra recursos computacionales mientras mantiene una gran cantidad de combinaciones de propiedades. Compare con los tallos más complejos y menos obvios en Inception V3 y V4.
ResNet usa una capa de agrupación con softmax como el clasificador final.
Todos los días, aparece información adicional sobre la arquitectura ResNet:
- Se puede considerar como un sistema de módulos simultáneos paralelos y en serie: en muchos módulos, la señal de entrada viene en paralelo, y las señales de salida de cada módulo están conectadas en serie.
- ResNet se puede considerar como varios conjuntos de módulos paralelos o seriales .
- Resultó que ResNet generalmente opera con bloques de profundidad relativamente pequeños de 20-30 capas que trabajan en paralelo, en lugar de ejecutarse secuencialmente a lo largo de toda la red.
- Dado que la señal de salida vuelve y se alimenta como entrada, como se hace en RNN, ResNet puede considerarse un modelo plausible mejorado de la corteza cerebral .
Inicio V4
Christian y su equipo se destacaron nuevamente con una
nueva versión de Inception .
El módulo de inicio que sigue la raíz es el mismo que en Inception V3:

En este caso, el módulo Inception se combina con el módulo ResNet:

Esta arquitectura resultó, a mi gusto, más complicada, menos elegante y también llena de soluciones heurísticas opacas. Es difícil entender por qué los autores tomaron estas o aquellas decisiones, y es igualmente difícil darles algún tipo de evaluación.
Por lo tanto, el premio para una red neuronal limpia y simple, fácil de entender y modificar, es para ResNet.
Squeezenet
SqueezeNet publicado recientemente. Este es un remake en una nueva forma de muchos conceptos de ResNet e Inception. Los autores demostraron que mejorar la arquitectura reduce el tamaño de la red y la cantidad de parámetros sin algoritmos de compresión complejos.
ENet
Todas las características de las arquitecturas recientes se combinan en una red muy eficiente y compacta, que utiliza muy pocos parámetros y potencia informática, pero al mismo tiempo ofrece excelentes resultados. La arquitectura se llamaba
ENet , fue desarrollada por Adam Paszke (
Adam Paszke ). Por ejemplo, lo usamos para marcar con mucha precisión objetos en la pantalla y analizar escenas.
Algunos ejemplos de Enet . Estos videos no están relacionados con el
conjunto de datos de capacitación .
Aquí puede encontrar los detalles técnicos de ENet. Es una red basada en codificador y decodificador. El codificador se basa en el esquema de categorización CNN habitual, y el decodificador es un netowrk de muestreo superior diseñado para la segmentación mediante la difusión de las categorías a la imagen de tamaño original. Para la segmentación de imágenes, solo se usaron redes neuronales, no otros algoritmos.
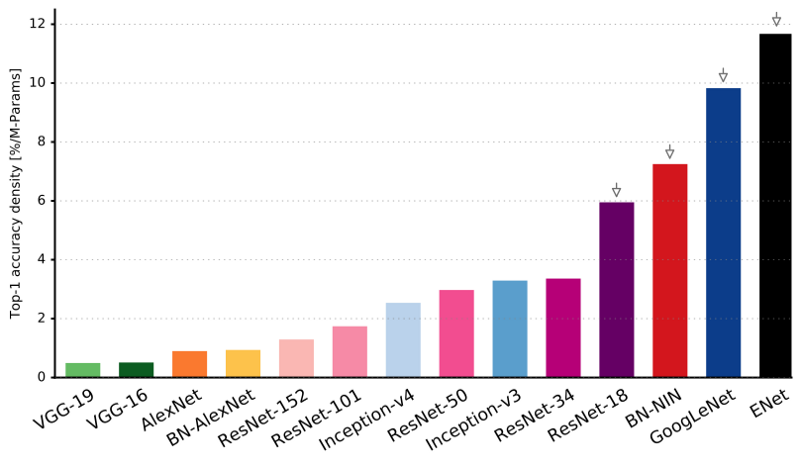
Como puede ver, ENet tiene la mayor precisión específica en comparación con todas las demás redes neuronales.
ENet fue diseñado para usar la menor cantidad de recursos posible desde el principio. Como resultado, el codificador y el decodificador juntos ocupan solo 0.7 MB con precisión fp16. Y con un tamaño tan pequeño, ENet no es inferior a la precisión de segmentación ni superior a otras soluciones de red puramente neuronales.
Análisis de módulos
Publicó una evaluación sistemática de los módulos CNN. Resultó ser beneficioso:
- Utilice la no linealidad ELU sin normalización de lote (batchnorm) o ReLU con normalización.
- Aplicar la transformación aprendida del espacio de color RGB.
- Use una política de disminución de la tasa de aprendizaje lineal.
- Use la suma de la capa de agrupación media y máxima.
- Use un mini paquete de 128 o 256. Si esto es demasiado para su tarjeta de video, reduzca la velocidad de aprendizaje en proporción al tamaño del paquete.
- Use capas completamente conectadas como capas convolucionales y pronósticos promedio para dar la solución final.
- Si aumenta el tamaño del conjunto de datos de entrenamiento, asegúrese de no haber alcanzado una meseta en el entrenamiento. La limpieza de datos es más importante que el tamaño.
- Si no puede aumentar el tamaño de la imagen de entrada, reduzca el paso en las capas posteriores, el efecto será aproximadamente el mismo.
- Si su red tiene una arquitectura compleja y altamente optimizada, como en GoogLeNet, modifíquela con precaución.
Xception
Xception introdujo una arquitectura más simple y elegante en el módulo Inception, que no es menos eficiente que ResNet e Inception V4.
Así es como se ve el módulo Xception:
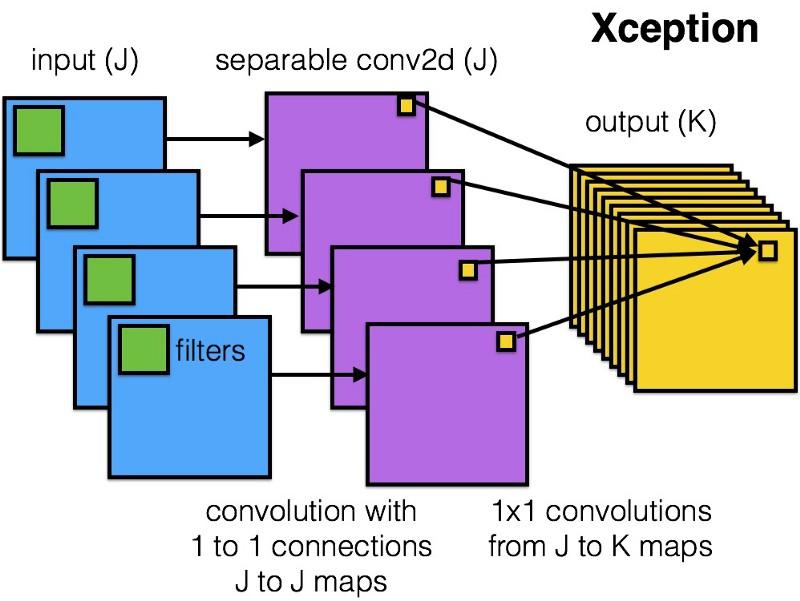
A cualquiera le gustará esta red debido a la simplicidad y elegancia de su arquitectura:

Contiene 36 pasos de convolución, y esto es similar a ResNet-34. Al mismo tiempo, el modelo y el código son simples, como en ResNet, y mucho más agradables que en Inception V4.
Una implementación de antorcha7 de esta red está disponible
aquí , mientras que una implementación de Keras / TF está disponible aquí.
Curiosamente, los autores de la reciente arquitectura Xception también se inspiraron en
nuestro trabajo sobre filtros convolucionales separables .
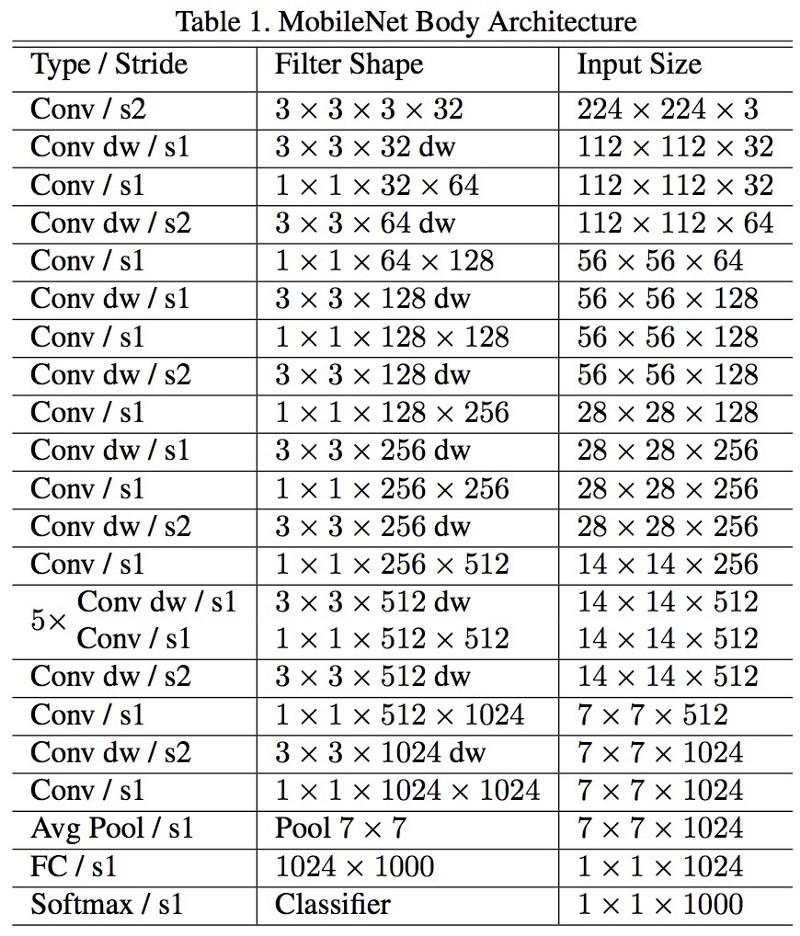
MobileNets
La nueva arquitectura de M
obileNets se lanzó en abril de 2017. Para reducir el número de parámetros, utiliza convoluciones desmontables, lo mismo que en Xception. También se afirma en el trabajo que los autores pudieron reducir en gran medida el número de parámetros: aproximadamente la mitad en el caso de FaceNet. :
, 1 (batch of 1) Titan Xp. :
- resnet18: 0,002871
- alexnet: 0,001003
- vgg16: 0,001698
- squeezenet: 0,002725
- mobilenet: 0,033251
! , .
FractalNet , ImageNet ResNet.
, . , .
, , , , ? , .
.
, . , .
, .
.