Un inicio genial al comienzo de su viaje es similar a Sapsan. Un pequeño equipo está ganando impulso rápidamente y corriendo hacia el futuro, llevando un montón de tareas a la producción. Si el proyecto resultó ser prometedor, como Skyeng, en unos pocos años habrá muchos más equipos, y es posible que entre ellos haya locomotoras de vapor en las que deba tirar constantemente leña al horno para que al menos algo llegue a los usuarios.
Echa un vistazo o lee la
charla de Alexey Kataev en Saint
TeamLead Conf si no sabes qué criterios formales determinar si tu equipo es
increíble . Si desea poder medir la deuda técnica en horas, en lugar de operar con las categorías "bastante", "cuánto", "muchísimo". Si su gerente de producto cree que un equipo de tres personas en un mes realizará 60 tareas, muéstrele este artículo. Si su gerente ha colgado el desarrollo con métricas y le sugiere que tome medidas basadas en resultados como: “34% piensa que el equipo tiene un problema con la planificación”, este informe es para usted.
Sobre el orador: Alexei Kataev (
deusdeorum ) ha estado involucrado en el desarrollo web durante 15 años. Gestionado para trabajar como backend, frontend, fullstack-developer y líder de equipo. Actualmente participa en la racionalización de los procesos de desarrollo en
Skyeng . Puede ser familiar para los líderes de equipo al
hablar sobre el trabajo de un equipo distribuido.
Ahora finalmente pasamos el piso al orador. Comencemos con el contexto y pasemos gradualmente al problema principal.

Me uní a Skyeng en 2015 y fui uno de los cinco desarrolladores: todos eran desarrolladores de la empresa.
Han pasado poco más de tres años, y ahora tenemos
15 equipos: 68 desarrolladores .
 Todos los desarrolladores trabajan de forma remota
Todos los desarrolladores trabajan de forma remota , se encuentran dispersos por todo el mundo.
Veamos los problemas que surgen inevitablemente al escalar una empresa de 5 a 68 empleados.
En la imagen, Sergey es el gerente de desarrollo.

Una vez tuvimos un equipo, y fue Sapsan, quien se apresuró hacia el futuro y llevó a cabo un montón de tareas en producción. Pero no solo tareas, sino un poco de deuda técnica. Luego, en algún momento, inesperadamente para nosotros, había muchos más equipos.
La primera pregunta a la que se enfrenta Sergey es
si todos nuestros equipos son Sapsans , o si hay máquinas de
vapor entre nosotros donde necesites tirar leña a la caja de fuego.

Esta pregunta es importante porque tal situación puede surgir: un gerente de producto o representante comercial vendrá a Sergey y le dirá que no tenemos tiempo, el equipo está trabajando mal. Pero, de hecho, el problema puede estar no solo en el equipo. El problema puede estar en la relación entre el equipo y el negocio o en el negocio en sí mismo; puede que no establezca objetivos bien o tenga planes demasiado optimistas.
Debes entender si el equipo es genial .
 La segunda pregunta son los recursos del equipo
La segunda pregunta son los recursos del equipo : cuántas tareas podemos llevar a los productos. Este problema es importante porque el producto siempre tiene muchos planes para el futuro cercano. Es importante comprender si el equipo hará frente a estos planes, o si necesita deshacerse de la mitad de las tareas. O tal vez valga la pena contratar a algunas personas más para realizar todas las tareas.
 La tercera pregunta es ¿cuánta deuda técnica llevamos con nosotros?
La tercera pregunta es ¿cuánta deuda técnica llevamos con nosotros? Esta es una pregunta crítica, porque si su cantidad excede el valor límite, al final nuestro tren no podrá ir a ningún lado. Tendremos que despedir al equipo, comenzar el proyecto desde el principio y no queremos permitirlo.

Finalmente, ¿cómo nos aseguramos de que
todos los equipos sean Sapsans y no trenes?
1. Determinamos cuán geniales son nuestros equipos.
Por supuesto, lo primero que viene a la mente es medir algunas métricas. Ahora te contaré sobre nuestra experiencia y cómo nos equivocamos una y otra vez.

En primer lugar, tratamos de controlar la
velocidad : cuántas tareas estamos implementando para el sprint. Pero resultó que la mitad de nuestros equipos no tienen sprints, tienen Kanban. Y donde hay sprints, las tareas se clasifican en horas o en puntos de historia. Todavía hay un par de equipos que solo realizan las tareas: no tienen Kanban, no saben qué es Scrum.
Esto es inconsistencia de datos. Estamos tratando de calcular un número en datos completamente diferentes. Al mismo tiempo, hacer sprints en todas partes para que todos los equipos sean idénticos será muy costoso. Para calcular una métrica, uno tendría que cambiar los procesos.
Pensamos, probamos algunas opciones más y llegamos a una métrica simple: la
implementación de planes . También es costoso, pero solo los planes de productos deben hacerse idénticos, consistentes. Alguien los lleva a Jira, alguien en Google Spreadsheets, alguien crea gráficos: la conversión a un formato es mucho más barata que cambiar los procesos en los equipos.
Cada trimestre, vemos si el equipo cumple con los requisitos del negocio, cuántas tareas planificadas se han completado.

Contando el
número de incidentes también falló.
Registramos cada implementación fallida o error que causó daños a la empresa, y después de la muerte. Sergei vino a mí como líder del equipo y dijo: “Tu equipo admite la mayor cantidad de caídas. ¿Por qué así? Pensamos, miramos y resultó que nuestro equipo es el más responsable y el único que registra todas las caídas. El resto actúa sobre el principio de elevarse rápidamente, no se considera que haya caído.
El problema nuevamente es la inconsistencia de datos y el muestreo insuficiente. Tenemos equipos que simplemente tienen un aterrizaje, nunca se bloquea en absoluto. No podemos decir que este equipo es mejor, porque tiene un proyecto más estable.
El segundo, mi tema favorito, es
la distorsión cognitiva . La facilidad cognitiva es cuando llegamos a una conclusión que nos parece simple, e inmediatamente comenzamos a creer en ella. No incluimos el pensamiento crítico: si hay muchas caídas, significa un mal equipo.
Llegamos a la misma métrica del número de incidentes, pero solo revisamos su implementación. Hicimos un proceso en el que
se registran todas las caídas . Al final de cada mes, le preguntamos a las personas que no están interesadas en ocultar incidentes; estos son control de calidad y productos, ¿es esta una lista completa de los problemas que ocurrieron debido a la culpa del equipo? Recuerdan cuando dejamos caer algo y complementan esta lista.

También hay problemas con las encuestas. Parece una herramienta súper universal: entrevistaremos a todos (productos, líderes de equipo, clientes) sobre los problemas que tenemos en los equipos. Según sus respuestas, crearemos gráficos y lo descubriremos todo. Pero hay muchos problemas.
En primer lugar, si hace preguntas cerradas, no se pueden sacar conclusiones de estos datos. Por ejemplo, preguntamos: "¿Tiene el equipo un problema con la planificación?" y el 34% dice que sí, ¿y qué hacer al respecto? Si hace preguntas abiertas: "¿Cuáles son los problemas en el equipo con la infraestructura?" - obtendrá respuestas vacías, porque todos son demasiado vagos para escribir algo.
No se pueden sacar conclusiones de estos datos .
Desarrollamos esta idea: primero realizamos encuestas como análisis y luego entrevistas para comprender cuál es exactamente el problema. Hablaremos de la entrevista un poco más tarde.
Di tres ejemplos, de hecho
probamos docenas de métricas .
Ahora solo usamos:
- Cumplimiento de planes.
- El número de incidentes.
- Encuestas + entrevistas.
Estoy engañando si digo que incluso medimos estas cosas simples en todos los equipos, porque lo
más costoso es la implementación . Especialmente cuando hay 15 equipos diferentes, cuando el producto dice: "¡Sí, no lo necesitamos en absoluto! Tendríamos que desplegar nuestra tarea, ¡ahora no está a la altura! Es muy difícil hacerlo para medir un número en todos los equipos.
La entrevista
Hagamos una breve digresión sobre la
entrevista con los desarrolladores . Leí varios artículos, pasé por el curso de comestibles. Hay mucho sobre la investigación del usuario y el desarrollo del cliente. Tomé varias prácticas a partir de ahí, y se comunicaron muy bien con los desarrolladores.
Si su objetivo es averiguar qué problemas tiene el equipo, en primer lugar, debe escribir preguntas específicas para las que buscará la respuesta. Es decir, no solo lanzas 30 preguntas,
eliges 2-3 preguntas para las que estás buscando una respuesta. Por ejemplo: ¿tiene el equipo problemas de infraestructura? cómo se establece la comunicación entre empresa y equipo.
En este caso, las preguntas deben ser:
- Abierto . La respuesta a la pregunta: "¿Hay algún problema?" "¡Sí!" "No te dirá nada".
- Neutro Una pregunta sobre un problema es una mala pregunta. Es mejor preguntar: "Cuéntame sobre el proceso de planificación en tu equipo". Una persona habla sobre el proceso y ya estás empezando a hacerle preguntas más profundas.
Otro enfoque muy bueno es la
priorización . Tienes diferentes aspectos de la vida en equipo. Usted le pregunta al empleado cuáles, en su opinión, son los mejores y deberían seguir siendo los mismos, y cuáles, tal vez, deberían mejorarse.
Hay otro enfoque que tomé del capítulo sobre entrevistas en el libro "Who. Resuelva su problema número uno ". Haga preguntas como esta:"
Si le preguntara a un producto, ¿qué piensa, qué problemas mencionaría? " Esto obliga al desarrollador a mirar el panorama general, y no desde su posición, para ver todos los problemas.
2. Evaluar recursos
Ahora hablemos sobre la
evaluación de los recursos .
Comencemos con el enfoque del producto, ya que generalmente evalúa los recursos de su equipo. Hay 3 personas, 20 días hábiles en un mes: multiplicamos personas por días, obtenemos 60 tareas.

Por supuesto, exagero, un producto normal multiplicará esto como 60 días de desarrollo. Pero esto también está mal, nadie desplegará tareas calificadas para 60 días en 60 días. Incluso Scrum le aconseja que considere el factor de enfoque y multiplique por un cierto número mágico, por ejemplo, 0.2. De hecho, de iteración en iteración implementaremos 12, luego 17 y luego 10 tareas. Creo que esta es una evaluación muy aproximada.
Tengo mi propio enfoque para evaluar los recursos. Para empezar, consideramos el recurso total del equipo en horas de trabajo. Multiplicamos horas por desarrolladores, nos quitamos vacaciones y días libres. Supongamos que obtienes 750.
Pero no todo desarrollo es desarrollo en sí mismo.
Arriba están los datos reales usando uno de los comandos como ejemplo:
- El 36,9% del tiempo dedicado a la comunicación son reuniones, debates, revisiones técnicas, revisiones de códigos, etc.
- 63.1% - directamente para resolver problemas.
¿Puede el producto contar con estos 63.1%? No, no puede, porque las tareas del producto son solo parte. Todavía hay una
cuota (alrededor del 20%) para corregir errores y refactorizar . Esto es lo que distribuye el timlid, y el producto ya no cuenta con este tiempo.

De las tareas del producto, tampoco todas las tareas son las que el producto ha planeado. Hay tareas de productos de otros equipos que solicitan ayuda urgente debido al lanzamiento. Estimamos aproximadamente del
8 al 10% de las tareas que provienen de otros equipos .

¡Y ahora tenemos 287 horas! Todo sería genial si siempre encajamos en nuestras calificaciones. Pero en este equipo se contó el gasto excesivo promedio: 1.51, es decir, en promedio, la tarea tomó una vez y media más de lo que se estimó.
 Un total de 750 quedan 189 horas para completar las tareas principales
Un total de 750 quedan 189 horas para completar las tareas principales . Por supuesto, esto es una aproximación, pero esta fórmula tiene variables que se pueden cambiar. Por ejemplo, si dedica un mes a la refactorización, puede sustituir este valor y averiguar con qué puede contar.
Dediqué todo el día a esto: tomé tareas, en Excel calculé el tiempo promedio, lo analicé, pasé mucho tiempo y decidí que nunca volvería a hacerlo. Necesito un enfoque rápido para esto, para no hacerlo con mis manos cada vez.
Me recomendaron un complemento para Jira y
EazyBI . Esta es una herramienta súper complicada, o no tenía suficientes habilidades, pero en el medio me di por vencido.
Encontré una manera de generar rápidamente cualquier informe.
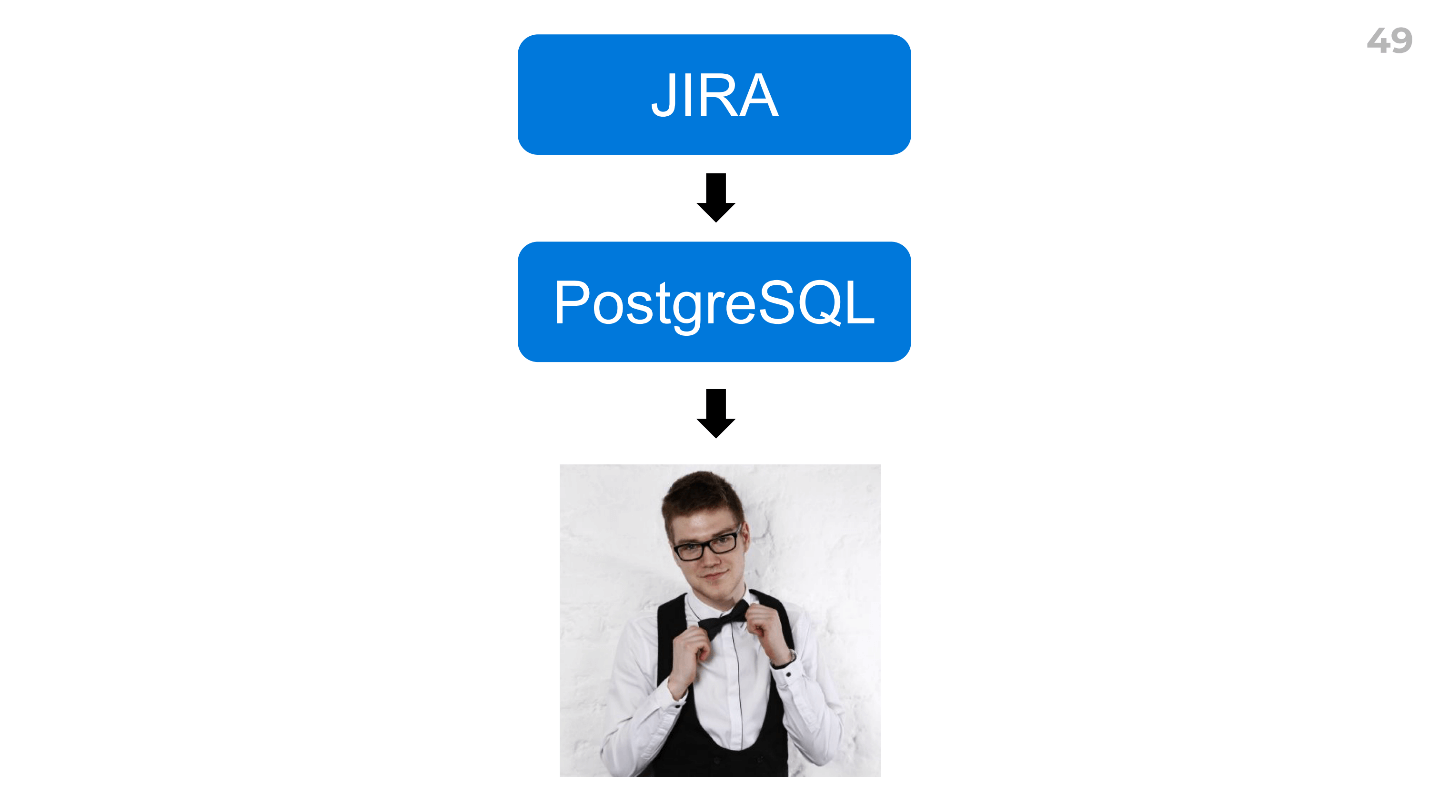
Suba los datos de su rastreador de tareas a cualquier DBMS que conozca (PostgreSQL para nosotros) y luego solicite al analista que calcule todo. Lo tenemos Dima, y lo calculó todo en 2 horas.

Al mismo tiempo, brindó un montón de datos adicionales: horas extras para desarrolladores, horas extras para tipos de tareas, algunos coeficientes, nos contó sobre sus ideas y nuevas hipótesis: divertido y escalable: puede usarlo inmediatamente en todos los equipos.
Cómo aumentar el recurso
Ahora sobre
cómo puede acelerar un equipo : aumente sus recursos sin aumentar el número de desarrolladores.
En primer lugar, para acelerar algo, primero debes medirlo. Generalmente contamos dos métricas:
- Evaluación inicial resumida de tareas para iteración en horas. Por ejemplo, implementamos tareas durante 100 horas en una semana.
- Y a veces, el tiempo promedio de rodamiento es el tiempo desde el momento en que la tarea entró en desarrollo, antes de estar en producción. Esta es una métrica más comercial y es interesante para el producto, no para el desarrollador.
No me cansaré de decirle al bot Arseny, a quien escribí el fin de semana. Cada semana publica un resumen: cuántas tareas implementamos.

Aquí hay dos cosas interesantes:
- Lo que yo llamo el efecto observador : evaluando algún indicador, ya lo estamos cambiando. Tan pronto como comenzamos a usar este bot, aumentamos la cantidad de tareas que realizamos durante la iteración.
- La métrica debería ser motivadora . Comencé mostrando cuán lejos no tenemos tiempo para correr. Resultó que no estábamos a tiempo en un 10%, en un 20%. Esto no motiva en absoluto, no habrá efecto de observador.
La velocidad es una métrica rezagada; no podemos influir directamente en ella. Muestra algo, pero hay métricas que afectan y podemos influir en la velocidad. En mi opinión, hay dos principales:
1. La precisión de las tareas de evaluación.Aquí nuevamente fuimos ayudados por nuestro analista Dima, quien calculó el tiempo real de la tarea, dependiendo de la evaluación inicial.

Estos son datos reales. Arriba hay un gráfico del tiempo real para completar la tarea, y abajo está nuestra estimación.
Joel Spolsky afirma que 16 horas por tarea es el límite. Para nosotros está claro que después de 12 horas la evaluación no tiene sentido, la variación es demasiado grande allí. Realmente introdujimos soft-limit e intentamos no evaluar las tareas, más de 12 horas. Después de eso, descomposición o investigación adicional.
2. Una pérdida de
tiempo, es decir, cuando los desarrolladores dedican tiempo a algo en lo que no podrían dedicarlo.
En uno de nuestros equipos, hasta el 50% del tiempo se dedicó a la comunicación. Comenzamos a analizar y entender cuál era la razón. Resultó que el problema está en los procesos: todos los clientes escribieron directamente a los desarrolladores, hicieron preguntas. Cambiamos un poco los procesos, redujimos este tiempo y mejoramos los indicadores de velocidad.
En su caso, esto no necesariamente serán comunicaciones, por ejemplo, puede ser el momento de la implementación o la infraestructura. Pero el requisito previo para esto es que todos sus desarrolladores deben registrar el tiempo. Si nadie registra su tiempo en Jira, obviamente será muy costoso implementarlo.
3. Manejo de la deuda técnica.
Cuando digo "deber técnico", lo visualizo como algo borroso: ¿no está claro cómo se puede medir?

Si te digo que tenemos exactamente 648 horas de servicio técnico en uno de los equipos, no me creerás. Pero te diré el algoritmo por el cual lo medimos.

Nos reunimos una vez por trimestre como un equipo completo (lo llamamos una reunión de refactorización) y elaboramos tarjetas: qué muletas (nuestras y otras) vieron las personas en el código, decisiones dudosas y otras cosas malas, por ejemplo, versiones antiguas de bibliotecas, cualquier cosa. Después de generar un montón de estas tarjetas, para cada una escribimos resolución, qué hacer con ella. Tal vez no haga nada, porque no es un deber técnico en absoluto, o necesita actualizar la versión de la biblioteca, refactorizar, etc. A continuación, creamos tickets en Jira, donde escribimos: "Este es el problema, esta es su solución".
Y aquí tenemos 150 boletos en Jira, ¿qué hacer con ellos?

Después de eso, llevamos a cabo una encuesta que demora 10 minutos para un desarrollador. Cada desarrollador otorga una calificación de 1 a 5, donde 1 - "Algún día lo haremos en la próxima vida", y 5 - "Tenemos que hacerlo ahora, nos ralentiza mucho". Agregamos esta calificación directamente al boleto en Jira. Creamos un campo personalizado, llamado "Prioridad de refactorización", y con él obtenemos una lista priorizada de nuestras deudas técnicas y problemas. Después de evaluar los primeros 10-20, y luego multiplicar la cola por la calificación promedio (somos demasiado vagos para evaluar los 150 tickets), obtenemos
deuda técnica en horas .
¿Por qué necesitamos esto? Realizamos esta evaluación una vez por trimestre. Si tuvimos 700 horas en el primer trimestre, y luego se convirtió, por ejemplo, en 800, entonces todo está en orden. Y si se convirtió en 1400, significa que existe una amenaza y que es necesario aumentar la cuota para la refactorización; acuerde con el negocio que ahora refactorizaremos todo el mes o el 40% de todos los tiempos.
Bueno, resolvimos el problema técnico de la deuda, está bajo llave.

Pero hablemos de las razones que conducen a su aparición. Esto suele ser una mala revisión del código.
Revisión de código incorrecto
Una de las principales razones de la mala revisión del código es el factor bus.
Hemos aprendido a formalizar el factor bus . Tomamos un equipo, escribimos una lista de áreas relevantes para este equipo, por ejemplo, para un equipo de plataforma: comunicación de video, sincronización de ejercicios, herramientas. Cada desarrollador otorga una calificación de 1 a 3:
- 1 - "No entiendo qué es, lo escuché un par de veces".
- 2 - "Puedo hacer tareas desde esta área".
- 3 - "Soy un súper experto en esta área".
Curiosamente, para algunas áreas no había un solo experto en el equipo, nadie sabía cómo funciona esto.
¿Cómo resolvimos el problema con el factor bus ?
A continuación, calculamos el valor medio de cada área y realizamos una serie de informes en las reuniones regulares del equipo en las que los expertos informaron a todo el equipo sobre esas áreas. Por supuesto, este método no escala muy bien, pero, en primer lugar, hay un video de estos informes y, en segundo lugar, es una forma muy rápida. Todo el equipo ahora sabe más o menos cómo funcionan las videollamadas. Para algunas áreas, todavía no hemos escrito documentación, pero hemos hecho la tarea de escribir documentación. Algún día escribiremos.

Ahora
sobre la revisión de código cuando no hay suficiente tiempo. , review code review. pull requests, code review . , , - , review. - — , — , code review .
. —
, .
4.
. , , cross review . -, : , , , . , . , .
, Google Suite : , , , .
—
- .

-, . , , Continuous Integration ..
- — , .
— , . , , , , , , . -.
:
Bono
, .
- QA- — 10 , .
- , - Skyeng - . — , , .
- open source, , .
Telegram (@ax8080)
facebook , .
, Call for Papers TeamLead Conf 2019, 25–26 , . , , , .
! , .