
Hola Habr! Hace dos años
escribimos sobre cómo cambiamos a PHP 7.0 y ahorramos un millón de dólares. En nuestro perfil de carga, la nueva versión resultó ser dos veces más eficiente en el uso de la CPU: la carga que solíamos servir a ~ 600 servidores, después de que la transición comenzó a servir a ~ 300. Como resultado, durante dos años tuvimos una reserva de capacidades.
Pero Badoo está creciendo. El número de usuarios activos aumenta constantemente. Estamos mejorando y desarrollando nuestra funcionalidad, gracias a la cual los usuarios pasan cada vez más tiempo en la aplicación. Y esto, a su vez, se refleja en el número de solicitudes, que en los últimos dos años aumentó de 2 a 2.5 veces.
Nos encontramos en una situación en la que una ganancia doble en el rendimiento se estabilizó por un aumento de más del doble en las solicitudes, y nuevamente comenzamos a acercarnos a los límites de nuestro grupo. En el núcleo de PHP, nuevamente se esperan
optimizaciones útiles (JIT, precarga), pero solo están planificadas para PHP 7.4, y esta versión se lanzará no antes de un año. Por lo tanto, el truco de transición no se puede repetir ahora: debe optimizar el código de la aplicación en sí.
Debajo del corte, le diré cómo abordamos tales tareas, qué herramientas usamos y daré ejemplos de optimizaciones, ideas y enfoques que aplicamos y que nos ayudaron en nuestro tiempo.
Por qué optimizar
La forma más fácil y obvia de resolver el problema de rendimiento es agregar hierro. Si su código se ejecuta en el mismo servidor, agregar uno más duplicará el rendimiento de su clúster. Al transferir estos costos al tiempo de trabajo del desarrollador, nos preguntamos: ¿podrá obtener un doble aumento en la productividad durante este tiempo debido a las optimizaciones? Tal vez sí, pero tal vez no: depende de qué tan óptimamente esté funcionando el sistema y qué tan bueno sea el desarrollador. Por otro lado, el servidor comprado seguirá siendo propiedad de la empresa y no se devolverá el tiempo empleado.
Resulta que en pequeños volúmenes la solución correcta a menudo será la adición de hierro.
Pero toma nuestra situación. Ahora, después de que la ganancia de cambiar a PHP 7.0 fue compensada por el crecimiento de la actividad y el número de usuarios, nuevamente tenemos 600 servidores que atienden solicitudes a la aplicación PHP. Para aumentar la capacidad una vez y media, necesitamos agregar 300 servidores.
Tome como cálculo el costo promedio de un servidor: $ 4,000. 300 * 4000 = $ 1,200,000: el costo de aumentar la capacidad una vez y media.
Es decir, en nuestras condiciones, podemos invertir una cantidad significativa de tiempo de trabajo en la optimización del sistema, y seguirá siendo más rentable que comprar hierro.
Planificación de la capacidad
Antes de emprender cualquier cosa, es importante entender si hay un problema. Si ella no está allí, entonces vale la pena intentar predecir cuándo puede aparecer. Este proceso se llama planificación de la capacidad.
Un indicador concreto de la presencia de problemas de rendimiento es el tiempo de respuesta. De hecho, no importa si la CPU (u otros recursos) se carga al 6% o 146%: si un cliente recibe un servicio de la calidad requerida en un tiempo satisfactorio, entonces todo funciona bien.
La desventaja de centrarse en el tiempo de respuesta es que generalmente comienza a aumentar solo cuando el problema ya ha aparecido. Si aún no es así, es difícil predecir su aparición. Además, el tiempo de respuesta refleja los resultados de la influencia de todos los factores (servicios de frenado, red, unidades, etc.) y no proporciona una comprensión de las causas de los problemas.
En nuestro caso, la CPU suele ser el cuello de botella, por lo que al planificar el tamaño y el rendimiento de los clústeres, principalmente prestamos atención a las métricas asociadas con su uso. Recopilamos el uso de CPU de todas nuestras máquinas y construimos gráficos con el valor promedio, mediana, percentil 75 y 95:
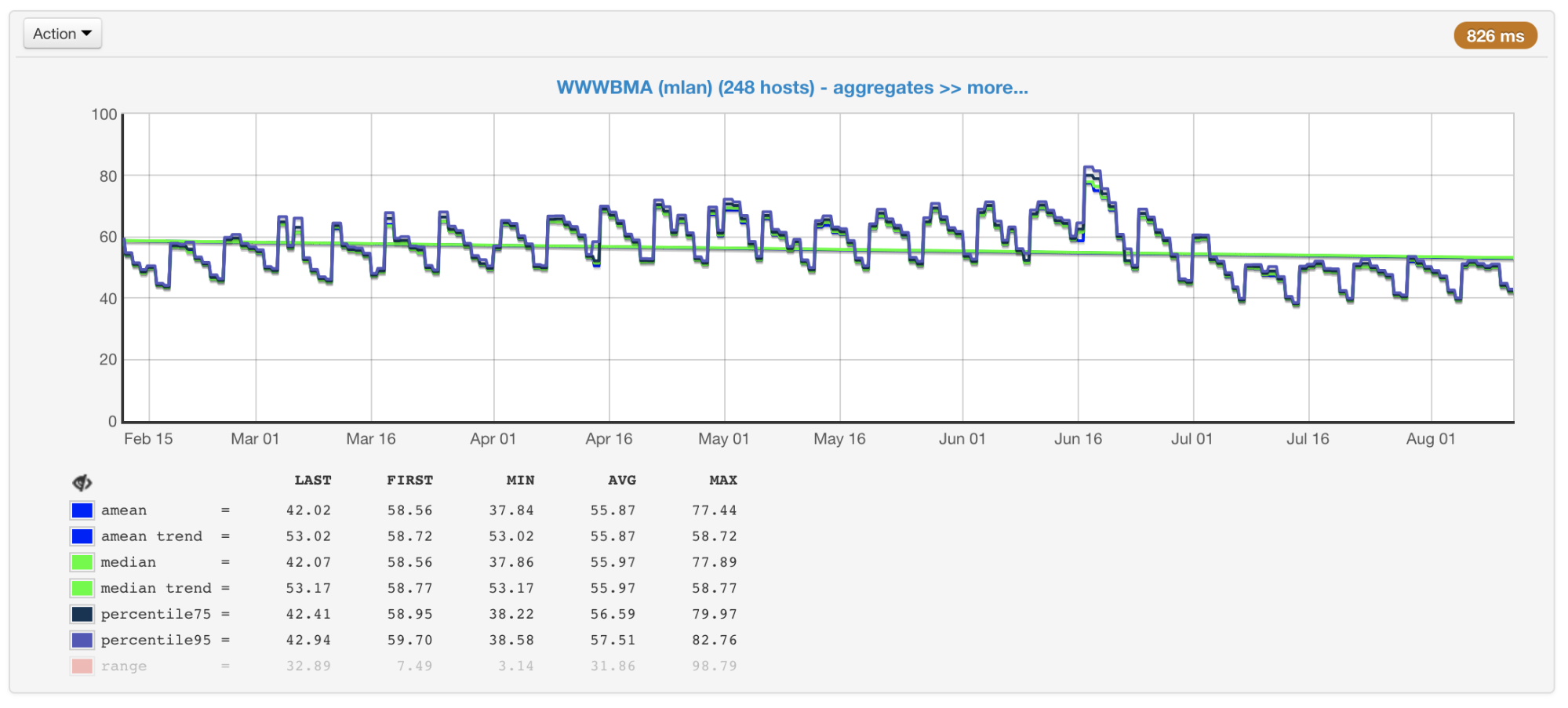 Utilización de CPU de máquinas de clúster en porcentaje: promedio, mediana, percentiles
Utilización de CPU de máquinas de clúster en porcentaje: promedio, mediana, percentilesHay cientos de máquinas en nuestros clústeres que se han agregado allí durante muchos años. Son diferentes en configuración y rendimiento (el clúster no es homogéneo). Nuestro equilibrador tiene esto en cuenta (
artículo y
video ) y carga las máquinas de acuerdo con sus capacidades. Para controlar este proceso, también tenemos un programa de máquinas con carga máxima y mínima.
 Las máquinas de clúster más y menos cargadas
Las máquinas de clúster más y menos cargadasSi observa estos gráficos (o solo la salida del comando superior) y ve la carga de la CPU del 50%, pensaría que todavía tenemos un margen para un aumento doble en la carga. Pero en realidad este no suele ser el caso. Y aquí está el por qué.
Hyper threading
Imagine un solo núcleo sin hypertreading. Lo cargamos con un hilo enlazado a la CPU. Veremos un 100% de carga en la parte superior.
Ahora active hyperreading en este kernel y cárguelo exactamente de la misma manera. En la parte superior, ya veremos dos núcleos lógicos, y la carga total será del 50% (generalmente en un 0% y en el otro 100%).
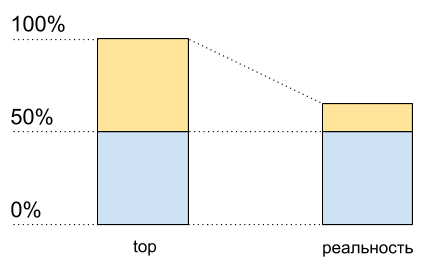 Utilización de la CPU: datos principales y lo que realmente sucede
Utilización de la CPU: datos principales y lo que realmente sucedeComo si el procesador solo estuviera cargado al 50%. Pero físicamente no apareció ningún núcleo libre adicional. Hypertreading permite
en algunos casos ejecutar en un núcleo físico más de un proceso a la vez. Pero esto está lejos de duplicar el rendimiento en situaciones típicas, aunque en el gráfico de uso de la CPU parece la mitad de los recursos: del 50% al 100%.
Esto significa que después del 50% del uso de la CPU cuando se habilita hypertreading, no crecerá igual que antes.
Escribí este código para demostrar (este es un tipo de caso sintético, en realidad los resultados serán diferentes):
Código de script<?php $concurrency = $_SERVER['argv'][1] ?? 1; $hashes = 100000000; $chunkSize = intval($hashes / $concurrency); $t1 = microtime(true); $children = array(); for ($i = 0; $i < $concurrency; $i++) { $pid = pcntl_fork(); if (0 === $pid) { $first = $i * $chunkSize; $last = ($i + 1) * $chunkSize - 1; for ($j = $first; $j < $last; $j++) { $dummy = md5($j); } printf("[%d]: %d hashes in %0.4f sec\n", $i, $last - $first, microtime(true) - $t1); exit; } else { $children[$pid] = 1; } } while (count($children) > 0) { $pid = pcntl_waitpid(-1, $status); if ($pid > 0) { unset($children[$pid]); } else { exit("Got a error pid=$pid"); } }
Tengo dos núcleos físicos en mi computadora portátil. Ejecute este código con diferentes datos de entrada para medir su rendimiento con un número diferente de procesos paralelos en C.
Trazamos los resultados de los lanzamientos:
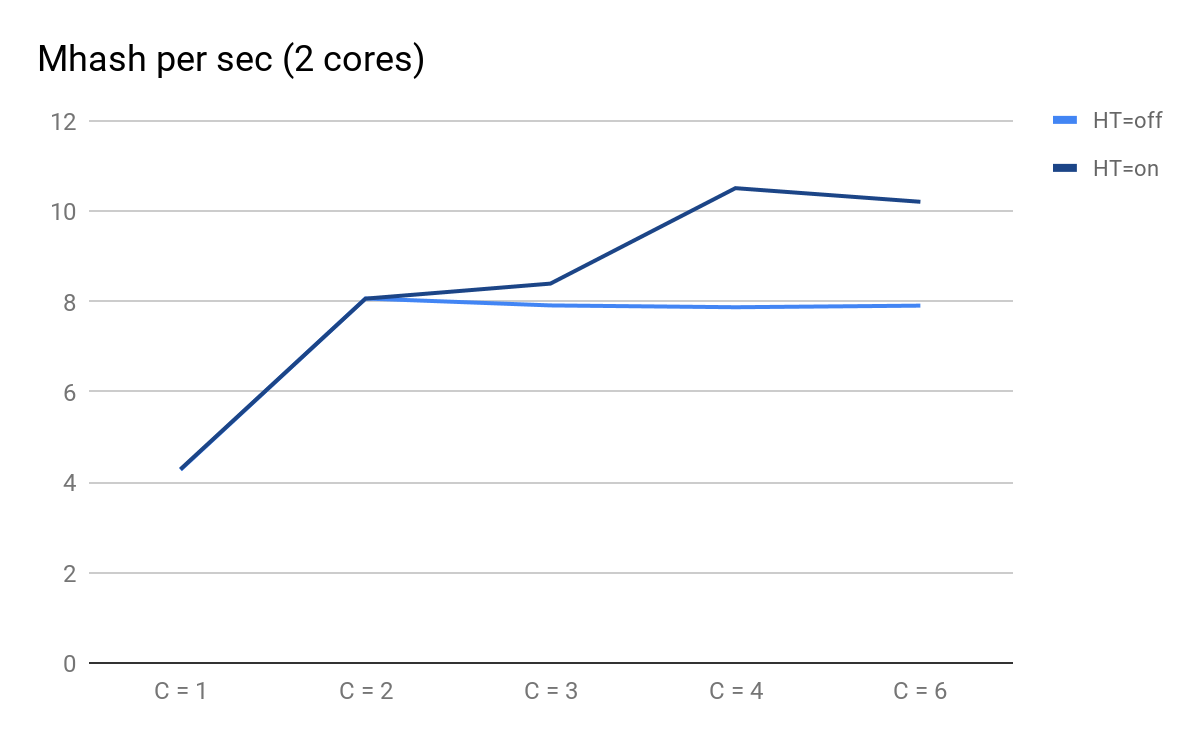 Rendimiento del script según la cantidad de procesos paralelos
Rendimiento del script según la cantidad de procesos paralelosA qué puedes prestar atención:
- C = 1 y C = 2 son predeciblemente iguales para HT = activado y HT = desactivado, el rendimiento se duplica cuando se agrega un núcleo físico;
- en C = 3, las ventajas de HT se hacen evidentes: para HT = activado, pudimos obtener un rendimiento adicional, mientras que para HT = desactivado con C = 3 en adelante, comienza a disminuir previsiblemente lentamente;
- en C = 4 vemos todos los beneficios de HT; pudimos exprimir un 30% adicional de productividad, pero en comparación con C = 2 en este momento, el uso de la CPU aumentó del 50% al 100%.
Total, viendo en el 50% superior de la carga de la CPU, al ejecutar este script obtenemos 8.065 Mhash / seg, y al 100% - 10.511 Mhash / seg. Esto significa que en alrededor del 50% de la parte superior, obtenemos 8.065 / 10.511 ~ 77% del rendimiento máximo del sistema, y de hecho nos queda aproximadamente el 100%: 77% = 23%, y no el 50%, como podría parecer.
Este hecho debe ser considerado al planificar.
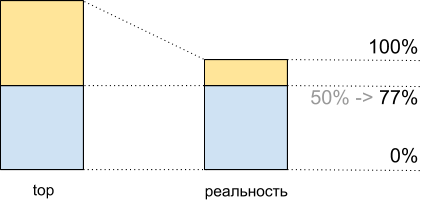 Utilización de CPU para demoscript: datos principales y lo que realmente sucede
Utilización de CPU para demoscript: datos principales y lo que realmente sucedeInconsistencia de tráfico
Además de hypertreading, la planificación también complica la irregularidad del tráfico dependiendo de la hora del día, día de la semana, temporada y otras frecuencias. Para nosotros, por ejemplo, el pico es el domingo por la noche.
 Número de solicitudes por segundo, pico domingo por la noche
Número de solicitudes por segundo, pico domingo por la nocheNo siempre el número de solicitudes cambia de manera obvia. Por ejemplo, los usuarios pueden interactuar de alguna manera con otros usuarios: la actividad de algunos puede generar push / email a otros y, por lo tanto, involucrarlos en el proceso. A esto se agregan campañas promocionales que aumentan el tráfico y para las cuales también debe estar preparado.
También es importante tener en cuenta todo esto al planificar: por ejemplo, construir una tendencia por días pico y tener en cuenta la posible no linealidad del crecimiento máximo.
Herramientas de perfilado y medición
Supongamos que descubrimos que hay problemas de rendimiento, comprendamos que esta no es la base de datos / servicios / cosas y, sin embargo, decidimos optimizar el código. Para hacer esto, en primer lugar, necesitamos un generador de perfiles o algunas herramientas para encontrar cuellos de botella y luego ver los resultados de nuestras optimizaciones.
Desafortunadamente, para PHP hoy no existe una buena herramienta universal.
perf
perf es una herramienta de creación de perfiles integrada en el kernel de Linux. Es un generador de perfiles de
muestreo que se inicia mediante un proceso separado, por lo tanto, no agrega directamente una sobrecarga al programa que se perfila. La sobrecarga añadida indirectamente está uniformemente "manchada", por lo que no distorsiona las mediciones.
Por todas sus ventajas, perf solo puede trabajar con código compilado y con JIT y no puede trabajar con código que se ejecuta "bajo una máquina virtual". Por lo tanto, el código PHP en sí no se puede perfilar en él, pero puede ver claramente cómo funciona PHP en su interior, incluidas varias extensiones de PHP, y cuántos recursos se gastan en él.
Por ejemplo, con perf, encontramos varios cuellos de botella, incluido un lugar de compresión, que analizaré a continuación.
Un ejemplo:
perf record --call-graph dwarf,65528 -F 99 -p $(pgrep php-cgi | paste -sd "," -) -- sleep 20
perf report(si el proceso y perf se ejecutan bajo diferentes usuarios, entonces perf debe ejecutarse desde under sudo).
 Ejemplo de salida de informe de rendimiento para PHP-FPM
Ejemplo de salida de informe de rendimiento para PHP-FPMAgregador XHProf y XHProf
XHProf es una extensión para PHP que coloca temporizadores alrededor de todas las llamadas a funciones / métodos, y también contiene herramientas para visualizar los resultados así obtenidos. A diferencia de perf, le permite operar con términos de código PHP (al mismo tiempo, lo que sucede en las extensiones no es visible).
Las desventajas incluyen dos cosas:
- todas las mediciones se recopilan en el marco de una sola solicitud, por lo tanto, no proporcionan información sobre la imagen en su conjunto;
- la sobrecarga, aunque no tan grande como, por ejemplo, cuando se usa Xdebug, pero es, y en algunos casos los resultados están muy distorsionados (cuanto más a menudo se llama una función y cuanto más simple es, mayor es la distorsión).
Aquí hay un ejemplo que ilustra el último punto:
function child1() { return 1; } function child2() { return 2; } function parent1() { child1(); child2(); return; } for ($i = 0; $i < 1000000; $i++) { parent1(); }
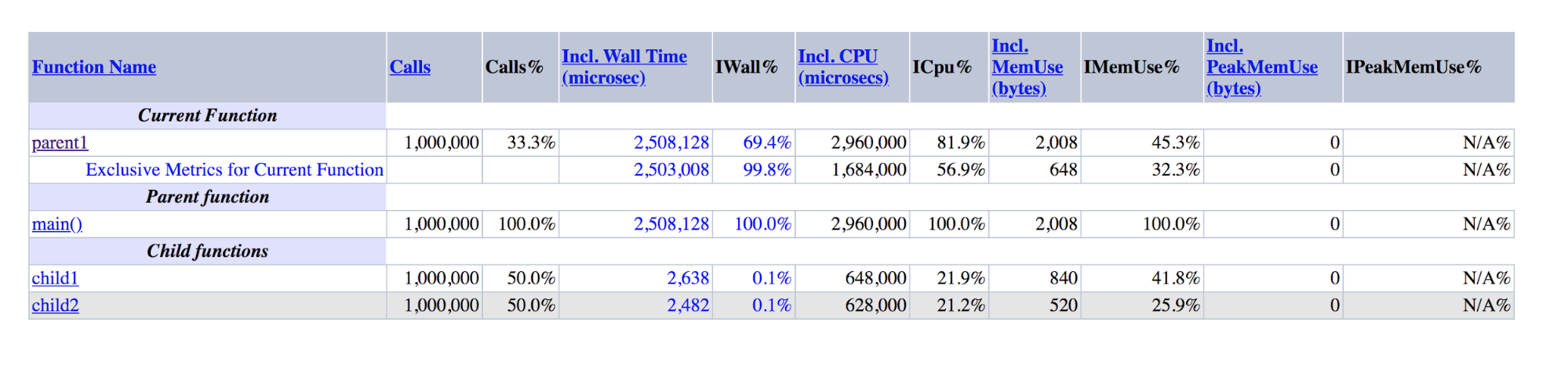 Salida XHProf para demos: parent1 es un orden de magnitud mayor que la suma de child1 y child2
Salida XHProf para demos: parent1 es un orden de magnitud mayor que la suma de child1 y child2Se puede ver que parent1 () se ejecutó ~ 500 veces más que child1 () + child2 (), aunque en realidad estos números deberían ser aproximadamente iguales, al igual que main () y parent1 ().
Si el último inconveniente es difícil de combatir, entonces para combatir el primero creamos un complemento para XHProf, que agrega los perfiles de diferentes solicitudes y visualiza datos agregados.
Además de XHProf, hay muchos otros perfiladores menos conocidos que trabajan en un principio similar. Tienen ventajas y desventajas similares.
Pinba
Pinba le permite
monitorear el rendimiento por secuencias
de comandos (acciones) y por temporizadores preestablecidos. Todas las mediciones en el contexto de los scripts se realizan de forma inmediata; para esto, no se requieren pasos adicionales. Para cada secuencia de comandos y temporizador, se
realiza getrusage , por lo que sabemos exactamente cuánto tiempo se dedicó al procesador en un fragmento de código en particular (a diferencia de los perfiladores de muestreo, donde este tiempo puede resultar en la red, el disco, etc.). Pinba es ideal para guardar datos históricos y obtener una imagen tanto en general como dentro de tipos específicos de consultas.
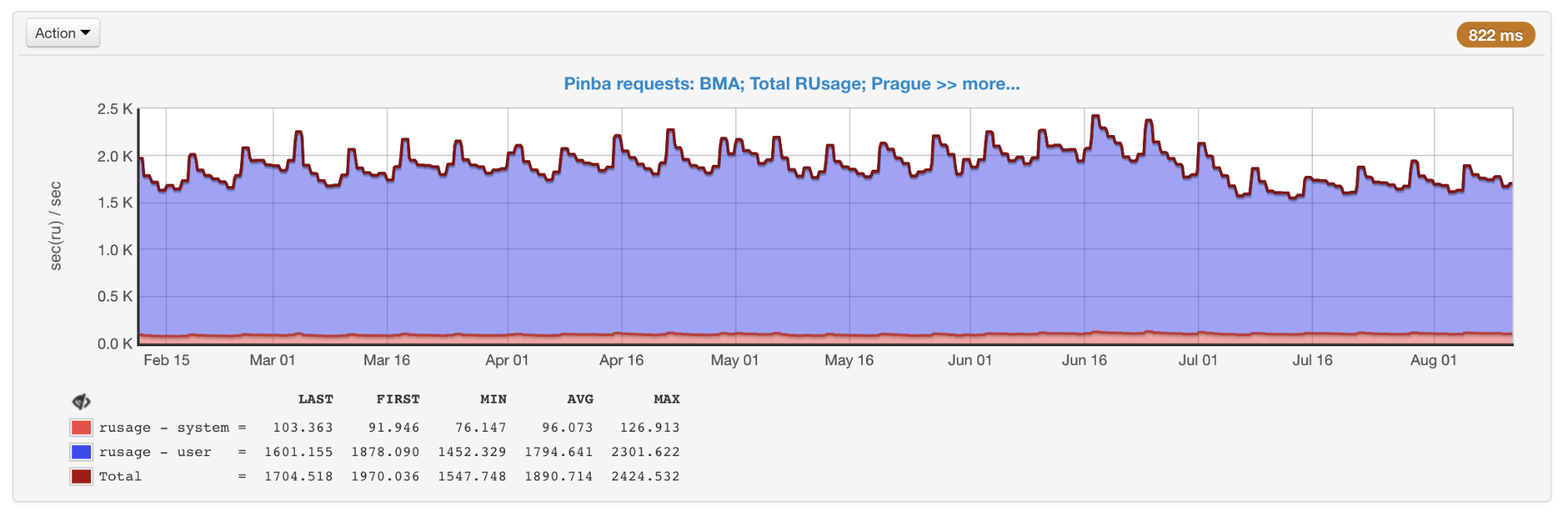 El rusage general de todos los guiones obtenidos de Pinba
El rusage general de todos los guiones obtenidos de PinbaLas desventajas incluyen el hecho de que los temporizadores que perfilan secciones específicas del código, y no los scripts completos, deben organizarse por adelantado en el código, así como la presencia de una sobrecarga que (como en XHProf) puede distorsionar los datos.
phpspy
phpspy es un proyecto relativamente nuevo (el primer compromiso en GitHub fue hace medio año), que parece prometedor, por lo que lo estamos monitoreando de cerca.
Desde el punto de vista del usuario, phpspy es similar a perf: se inicia un proceso paralelo, que copia periódicamente las partes de la memoria del proceso PHP, las analiza y recibe trazas de la pila y otros datos desde allí. Esto se hace de una manera bastante específica. Para minimizar la sobrecarga, phpspy no detiene el proceso de PHP y copia la memoria directamente mientras se está ejecutando. Esto lleva al hecho de que el generador de perfiles puede tener un estado inconsistente, los rastros de la pila pueden romperse. Pero phpspy puede detectar esto y descarta dichos datos.
En el futuro, utilizando esta herramienta, será posible recopilar tanto datos sobre la imagen como un conjunto y perfiles de tipos específicos de consultas.
Tabla de comparación
Para estructurar las diferencias entre las herramientas, hagamos una tabla dinámica:
 Comparación de las principales características de los perfiladores.Gráficos de llamas
Comparación de las principales características de los perfiladores.Gráficos de llamasOptimización y enfoques
Con estas herramientas, supervisamos constantemente el rendimiento y el uso de nuestros recursos. Cuando se usan injustificadamente o nos estamos acercando al umbral (para la CPU elegimos empíricamente un valor del 55% para tener un margen de tiempo en caso de crecimiento), como escribí anteriormente, una de las soluciones al problema es la optimización.
Bueno, si la optimización ya ha sido realizada por otra persona, como fue el caso de PHP 7.0, cuando esta versión resultó ser mucho más productiva que las anteriores. En general, intentamos utilizar tecnologías y herramientas modernas, incluidas actualizaciones oportunas de las últimas versiones de PHP. Según
los puntos de referencia públicos , PHP 7.2 es 5-12% más rápido que PHP 7.1. Pero esta transición, por desgracia, nos dio mucho menos.
Durante todo el tiempo hemos implementado una gran cantidad de optimizaciones. Desafortunadamente, la mayoría de ellos están fuertemente relacionados con nuestra lógica de negocios. Hablaré sobre aquellos que pueden ser relevantes no solo para nosotros, o ideas y enfoques que pueden usarse fuera de nuestro código.
Compresión Zlib => zstd
Usamos compresión para teclas grandes de memkey. Esto nos permite gastar tres o cuatro veces menos memoria para el almacenamiento debido a los costos adicionales de CPU para la compresión / descompresión. Usamos zlib para esto (nuestra extensión para trabajar con memekes es diferente de las que vienen con PHP, pero las oficiales
también usan zlib).
En perf, la producción era algo como esto:
+ 4.03% 0.22% php-cgi libz.so.1.2.11 [.] inflate
+ 3.38% 0.00% php-cgi libz.so.1.2.11 [.] deflateEl 7-8% del tiempo se dedicó a la compresión / descompresión.
Decidimos probar diferentes niveles y algoritmos de compresión. Resultó que zstd se ejecuta en nuestros datos casi diez veces más rápido, perdiendo en su lugar ~ 1.1 veces. Un cambio bastante simple en el algoritmo nos ahorró ~ 7.5% de CPU (esto, recuerdo, en nuestros volúmenes es equivalente a ~ 45 servidores).
Es importante comprender que la proporción del rendimiento de diferentes algoritmos de compresión puede variar mucho según los datos de entrada. Existen varias
comparaciones , pero con mayor precisión, esto solo puede estimarse utilizando ejemplos del mundo real.
IS_ARRAY_IMMUTABLE como repositorio de datos raramente modificados
Al trabajar con tareas reales, debe lidiar con los datos que necesita con frecuencia y, al mismo tiempo, rara vez cambia y tiene un tamaño limitado. Tenemos muchos datos similares, un buen ejemplo es la configuración de
pruebas divididas . Verificamos si el usuario se encuentra bajo las condiciones de una prueba en particular y, dependiendo de esto, le mostramos la funcionalidad experimental o normal (esto sucede casi durante cada solicitud). En otros proyectos, las configuraciones y varios directorios pueden ser un ejemplo: países, ciudades, idiomas, categorías, marcas, etc.
Dado que tales datos a menudo se solicitan, su recepción puede crear una carga adicional notable tanto en la propia aplicación como en el servicio en el que se almacenan estos datos. El último problema se puede resolver, por ejemplo, utilizando APCu, que utiliza la memoria de la misma máquina que ejecuta PHP-FPM como almacenamiento. Pero incluso entonces:
- habrá costos de serialización / deserialización;
- necesita de alguna manera invalidar los datos al cambiar;
- Hay algunos gastos generales en comparación con acceder solo a una variable en PHP.
PHP 7.0 presenta la optimización
IS_ARRAY_IMMUTABLE . Si declara una matriz, cuyos elementos se conocen en el momento de la compilación, se procesará y se colocará en la memoria OPCache una vez, los trabajadores de PHP-FPM se referirán a esta memoria compartida sin perder el tiempo antes de intentar cambiar. También se deduce que la inclusión de dicha matriz tomará un tiempo constante independientemente del tamaño (generalmente ~ 1 microsegundo).
A modo de comparación: un ejemplo del tiempo para obtener una matriz de 10,000 elementos a través de include y apcu_fetch:
$t0 = microtime(true); $a = include 'test-incl-1.php'; $t1 = microtime(true); printf("include (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6); $t0 = microtime(true); $a = apcu_fetch('a'); $t1 = microtime(true); printf("apcu_fetch (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6);
Verificar si esta optimización se ha aplicado puede ser muy simple si observa los códigos de operación generados:
$ cat immutable.php <?php return [ 'key1' => 'val1', 'key2' => 'val2', 'key3' => 'val3', ]; $ cat mutable.php <?php return [ 'key1' => \SomeClass::CONST_1, 'key2' => 'val2', 'key3' => 'val3', ]; $ php -d opcache.enable=1 -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 immutable.php $_main: ; (lines=1, args=0, vars=0, tmps=0) ; (after optimizer) ; /home/ubuntu/immutable.php:1-8 L0 (4): RETURN array(...) $ php -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 mutable.php $_main: ; (lines=5, args=0, vars=0, tmps=2) ; (after optimizer) ; /home/ubuntu/mutable.php:1-8 L0 (4): T1 = FETCH_CLASS_CONSTANT string("SomeClass") string("CONST_1") L1 (4): T0 = INIT_ARRAY 3 T1 string("key1") L2 (5): T0 = ADD_ARRAY_ELEMENT string("val2") string("key2") L3 (6): T0 = ADD_ARRAY_ELEMENT string("val3") string("key3") L4 (6): RETURN T0
En el primer caso, se puede ver que solo hay un código de operación en el archivo: el retorno de la matriz terminada. En el segundo caso, su formación elemento por elemento ocurre cada vez que se ejecuta este archivo.
Por lo tanto, es posible generar estructuras en una forma que no requiera una mayor transformación en tiempo de ejecución. Por ejemplo, en lugar de desarmar los nombres de las clases con los signos "_" y "\" cada vez para la carga automática, puede generar previamente el mapa de correspondencia "Clase => Ruta". En este caso, la función de conversión se reducirá a una sola llamada de tabla hash. Composer realiza este tipo de optimización si habilita la
opción de optimización del cargador automático .
Para la invalidación de dichos datos, no necesita hacer nada específicamente: PHP mismo recompilará el archivo al cambiar, tal como lo haría con una implementación de código normal. El único inconveniente que no debe olvidar: si el archivo es muy grande, la primera solicitud después de cambiarlo provocará una recompilación, lo que puede llevar un tiempo tangible.
El rendimiento incluye / requiere
A diferencia del ejemplo de matriz estática, adjuntar archivos con declaraciones de clase y función no es tan rápido. A pesar de la presencia de OPCache, el motor PHP debe copiarlos en la memoria del proceso, conectando las dependencias de forma recursiva, que al final puede tomar cientos de microsegundos o incluso milisegundos por archivo.
Si crea un nuevo proyecto vacío en
Symfony 4.1 y coloca
get_included_files () como la primera línea de la acción, puede ver que 310 archivos ya están conectados. En un proyecto real, este número puede llegar a miles por solicitud. Vale la pena prestar atención a las siguientes cosas.
Falta de características de carga automáticaExiste
RFC de carga automática de funciones , pero no se ha visto ningún desarrollo durante varios años. Por lo tanto, si una dependencia en Composer define funciones fuera de la clase y estas funciones deben ser accesibles para el usuario, esto se hace
conectando obligatoriamente un archivo con estas funciones a cada inicialización del cargador automático.
Por ejemplo, eliminando una de las dependencias de composer.json, que declara muchas funciones y se reemplaza fácilmente por cien líneas de código, ganamos un par por ciento de la CPU.
El cargador automático se llama con más frecuencia de lo que parece.Para demostrar la idea, cree dicho archivo con una clase:
<?php class A extends B implements C { use D; const AC1 = \E::E1; const AC2 = \F::F1; private static $as3 = \G::G1; private static $as4 = \H::H1; private $a5 = \I::I1; private $a6 = \J::J1; public function __construct(\K $k = null) {} public static function asf1(\L $l = null) :? LR { return null; } public static function asf2(\M $m = null) :? MR { return null; } public function af3(\N $n = null) :? NR { return null; } public function af4(\P $p = null) :? PR { return null; } }
Registrar cargador automático: spl_autoload_register(function ($name) { echo "Including $name...\n"; include "$name.php"; });
Y haremos varios casos de uso para esta clase: include 'A.php' Including B... Including D... Including C... \A::AC1 Including A... Including B... Including D... Including C... Including E... new A() Including A... Including B... Including D... Including C... Including E... Including F... Including G... Including H... Including I... Including J...
Puede notar que cuando de alguna manera conectamos la clase, pero no creamos su instancia, se conectarán los padres, las interfaces y los rasgos. Esto se hace de forma recursiva para todos los archivos conectados como resuelve.
Al crear una instancia, se agrega la resolución de todas las constantes y campos, lo que conduce a la conexión de todos los archivos necesarios para esto, lo que, a su vez, también causará una conexión recursiva de rasgos, padres e interfaces de las clases recién conectadas.
 Conexión de clases relacionadas para el proceso de creación de instancias y otros casos
Conexión de clases relacionadas para el proceso de creación de instancias y otros casosNo existe una solución universal para este problema, solo debe tenerlo en cuenta y controlar las conexiones entre clases: una línea puede extraer la conexión de cientos de archivos.
Configuración de OPCacheSi utiliza el método de
implementación atómica cambiando el enlace simbólico propuesto por Rasmus Lerdorf, el creador de PHP, para
resolver el problema de "pegar" el enlace simbólico en la versión anterior, debe incluir opcache.revalidate_path, como se recomienda, por ejemplo, en este
artículo sobre OPCache traducido por correo .Ru Grupo.
El problema es que esta opción significativamente (en promedio, una vez y media o dos veces) aumenta el tiempo para incluir cada archivo. En total, esto puede consumir una cantidad significativa de recursos (en nuestro caso, deshabilitar esta opción dio una ganancia de 7 a 9%).
Para deshabilitarlo, debe hacer dos cosas:
- hacer que el servidor web resuelva enlaces simbólicos;
- deje de conectar archivos dentro del script PHP a lo largo de las rutas que contienen enlaces simbólicos, o forzarlos a través de readlink () o realpath ().
Si todos los archivos están conectados con el cargador automático de Composer, el segundo elemento se ejecutará automáticamente después de que se complete el primero: omposer utiliza la constante __DIR__, que se resolverá correctamente.
OPCache tiene algunas opciones más que pueden aumentar el rendimiento a cambio de flexibilidad. Puede leer más sobre esto en el
artículo que mencioné anteriormente.
A pesar de todas estas optimizaciones, incluir aún no será gratuito. Para combatir esto, PHP 7.4 planea agregar
precarga .
APCu Lock
Aunque no estamos hablando de bases de datos y servicios aquí, también pueden ocurrir varios tipos de bloqueos en el código, lo que aumenta el tiempo de ejecución del script.
A medida que crecieron las solicitudes, notamos una fuerte desaceleración en respuesta en las horas pico. Después de descubrir las razones, resultó que aunque APCu es la forma más rápida de obtener datos (en comparación con Memcache, Redis y otro almacenamiento externo), también puede funcionar lentamente con la sobrescritura frecuente de las mismas claves.
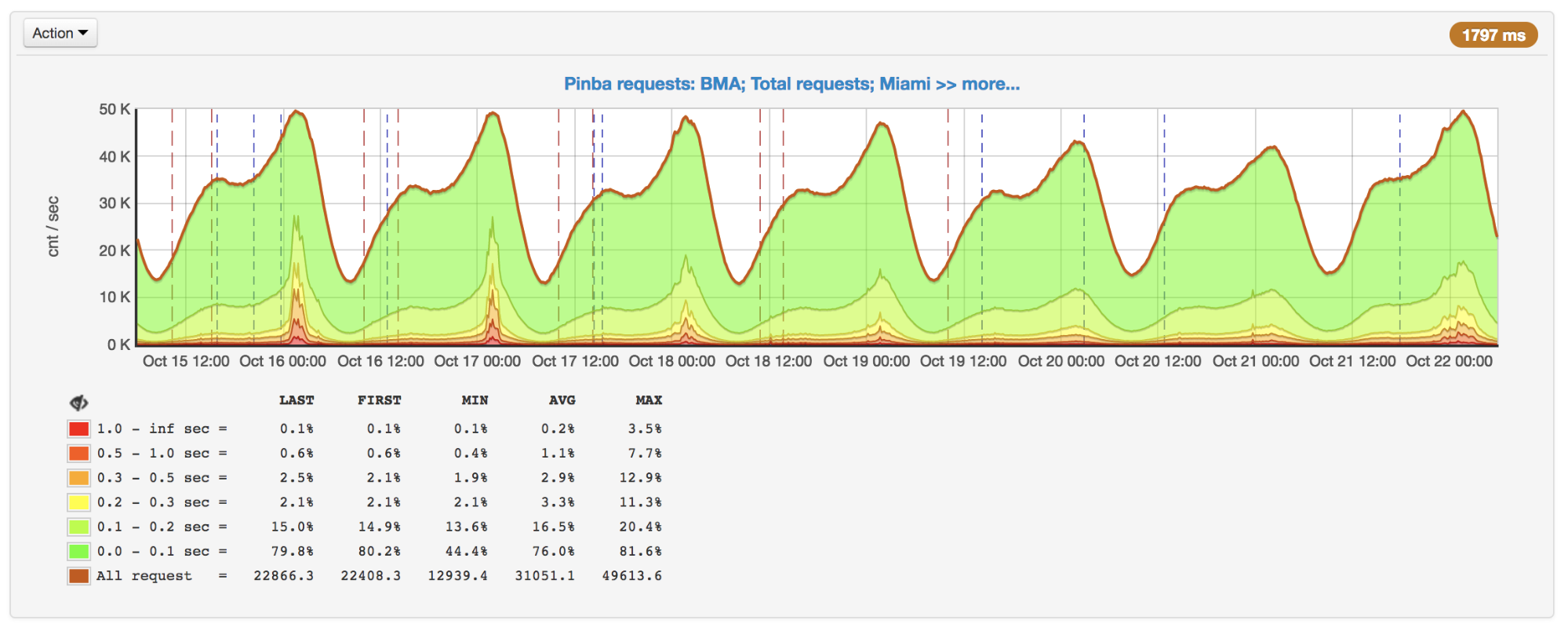 Número de solicitudes por segundo y tiempo de ejecución: picos el 16 y 17 de octubre
Número de solicitudes por segundo y tiempo de ejecución: picos el 16 y 17 de octubreCuando se usa APCu como caché, este problema no es tan relevante, ya que el almacenamiento en caché generalmente implica escritura rara y lectura frecuente. Pero algunas tareas y algoritmos (por ejemplo,
Circuit Breaker (
implementación en PHP )) también implican grabaciones frecuentes, lo que provoca bloqueos.
No existe una solución universal para este problema, pero en el caso de Circuit Breaker se puede resolver, por ejemplo, poniéndolo en un
servicio separado instalado en máquinas con PHP.
Procesamiento por lotes
Incluso si no tiene en cuenta la inclusión, por lo general, una parte significativa del tiempo de ejecución de la consulta todavía se dedica a la inicialización: un marco (por ejemplo, construir un contenedor DI e inicializar todas sus dependencias, enrutar, ejecutar a todos los oyentes), elevar la sesión, Usuario, etc. más lejos
Si su backend es una API interna para algo, entonces algunas solicitudes de clientes pueden agruparse y enviarse como una sola solicitud. En este caso, la inicialización se realizará una vez para varias solicitudes.
, , . - , . .
Badoo , . PHP-FPM, CPU, , , : IO, CPU .
PHP-FPM — , PHP.
(CPU, IO), . , , , , - , . , . , , .
Conclusión
. PHP .
:
- ;
- ;
- - , : , ;
- : (, , );
- : ;
- , OPCache PHP, , , ;
- : (, , PHP 7.2 , );
- : , .
?
Gracias por su atencion!