Hola a todos! Trabajo en Veeam en el proyecto Veeam Agent para Linux. Con este producto, puede hacer una copia de seguridad de una máquina Linux. "Agente" en el nombre significa que el programa le permite hacer copias de seguridad de máquinas físicas. Virtualalkans también realiza copias de seguridad, pero se encuentra en el sistema operativo invitado.
La inspiración para este artículo fue mi informe en la conferencia
Linux Piter , que decidí publicar como un artículo para todos los interesados habragiteli.
En este artículo, revelaré el tema de la creación de una instantánea que le permite realizar copias de seguridad y hablar sobre los problemas que encontramos al crear nuestro propio mecanismo para crear instantáneas de dispositivos de bloque.
Todos los interesados por favor pidan un corte!

Un poco de teoría al principio
Históricamente, hay dos enfoques para crear copias de seguridad: copia de seguridad de archivos y copia de seguridad de volumen. En el primer caso, copiamos cada archivo como un objeto separado, en el segundo, copiamos todo el contenido del volumen como una especie de imagen.
Ambos métodos tienen muchas ventajas y desventajas, pero los consideraremos a través del prisma de recuperación del fracaso:
- En el caso de la copia de seguridad de archivos, para recuperar completamente el servidor completo, primero tendremos que instalar el sistema operativo, luego los servicios necesarios, y solo luego restaurar los archivos de la copia de seguridad.
- En el caso de la copia de seguridad de volumen, para una recuperación completa, es suficiente simplemente restaurar todos los volúmenes de una máquina sin esfuerzos innecesarios por parte de una persona.
Obviamente, en el caso de la copia de seguridad de volumen, puede restaurar el sistema más rápido, y esta es una
característica importante
del sistema . Por lo tanto, para nosotros, notamos la copia de seguridad de volumen como la opción preferida.
¿Cómo tomamos y guardamos todo el volumen? Por supuesto, simplemente copiando no lograremos nada bueno. Durante la copia, se producirá alguna actividad con datos en el volumen, como resultado, los datos inconsistentes aparecerán en la copia de seguridad. Se violará la estructura del sistema de archivos, se dañarán los archivos de la base de datos, así como otros archivos con los que se realizarán operaciones durante la copia.
Para evitar todos estos problemas, a la humanidad progresiva se le ocurrió una tecnología de instantánea: instantánea. En teoría, todo es simple: creamos una copia sin cambios, una instantánea, y respaldamos los datos. Cuando finaliza la copia de seguridad, destruimos la instantánea. Suena simple, pero, como siempre, hay matices.
Gracias a ellos, nacieron muchas implementaciones de esta tecnología. Por ejemplo, las soluciones basadas en el
mapeador de dispositivos , como LVM y Thin provisioning, proporcionan instantáneas de volumen completo, pero requieren un diseño de disco especial en la etapa de instalación del sistema, lo que significa que, en general, no son adecuadas.
BTRFS y ZFS hacen posible crear instantáneas de las subestructuras del sistema de archivos, lo cual es muy bueno, pero en este momento su participación en los servidores es pequeña, y estamos tratando de hacer una solución universal.
Supongamos que hay un EXT banal en nuestro dispositivo de bloque. En este caso, podemos usar
dm-snap (por cierto,
dm-bow se está desarrollando ahora), pero aquí está su propio matiz. Debe tener un dispositivo de bloque libre listo para que pueda colocar datos de instantáneas donde sea.
Al prestar atención a las soluciones alternativas de respaldo, notamos que, por regla general, usan su módulo de kernel para crear instantáneas de dispositivos de bloque. Decidimos seguir este camino, escribiendo nuestro módulo. Se decidió distribuirlo bajo la licencia GPL, para que esté disponible públicamente en
github .
Cómo funciona, en teoría
Instantánea del microscopio
Por lo tanto, ahora consideraremos el principio general del funcionamiento del módulo y nos detendremos en cuestiones clave con más detalle.
De hecho, veeamsnap (como lo llamamos nuestro módulo del núcleo) es un filtro de controlador de dispositivo de bloque.

Su trabajo es interceptar las solicitudes de un controlador de dispositivo de bloque.
Después de interceptar una solicitud de escritura, el módulo copia datos del dispositivo de bloque original al área de datos de la instantánea. Llamamos a esta área snapstore.
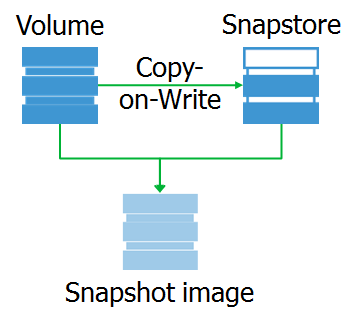
¿Y cuál es la instantánea en sí misma? Este es un dispositivo de bloque virtual, una copia del dispositivo original en un punto particular en el tiempo. Al acceder a los bloques de datos en este dispositivo, se pueden leer desde el complemento o desde el dispositivo original.
Quiero señalar que la instantánea es exactamente el dispositivo de bloque que es completamente idéntico al original en el momento en que se eliminó la instantánea. Gracias a esto, podemos montar el sistema de archivos en una instantánea y realizar el preprocesamiento necesario.
Por ejemplo, podemos obtener un mapa de bloques ocupados del sistema de archivos. La forma más fácil de hacer esto es usar ioctl
GETFSMAP .
Los datos en bloques ocupados le permiten leer solo los últimos datos de una instantánea.
También puede excluir algunos archivos. Bueno, una acción completamente opcional: indexar los archivos que caen en la copia de seguridad, para la posibilidad de un restaurante granular en el futuro.
CoW vs RoW
Detengámonos un poco en la elección del algoritmo de instantánea. La elección aquí no es muy extensa:
Copiar al escribir o Redirigir al escribir .
Redirect-on-Write al interceptar una solicitud de escritura lo redireccionará al complemento, después de lo cual todas las solicitudes para leer este bloque también irán allí. Un gran algoritmo para sistemas de almacenamiento basados en árboles B +, como BTRFS, ZFS y Thin Provisioning. La tecnología es tan antigua como el mundo, pero se manifiesta especialmente bien en hipervisores, donde puede crear un nuevo archivo y escribir nuevos bloques allí durante la instantánea. El rendimiento es excelente en comparación con la vaca. Pero hay un gran inconveniente: la estructura del dispositivo original cambia, y al eliminar la instantánea, debe copiar todos los bloques del complemento a la ubicación original.
Copy-on-Write, cuando intercepta una solicitud, copia datos en el almacén de instantáneas que debe sufrir un cambio, después de lo cual permite que se sobrescriban en el lugar original. Se usa para crear instantáneas para volúmenes LVM y instantáneas de VSS. Obviamente, es más adecuado para crear instantáneas de dispositivos de bloque, porque no cambia la estructura del dispositivo original, y cuando elimina (o bloquea) la instantánea simplemente puede descartarse sin arriesgar datos. La desventaja de este enfoque es la degradación del rendimiento, ya que se agregan un par de operaciones de lectura / escritura a cada operación de escritura.
Dado que la seguridad de los datos es nuestra principal prioridad, nos centramos en CoW.
Hasta ahora, todo parece simple, así que repasemos los problemas de la vida real.
Cómo funciona: en la práctica
Condición consistente
Por su bien, todo fue concebido.
Por ejemplo, si al momento de crear una instantánea (en una primera aproximación, podemos suponer que se creó instantáneamente) se grabará un registro en algún archivo, entonces en una instantánea el archivo estará incompleto, lo que significa que estará dañado y carecerá de sentido. La situación es similar con los archivos de base de datos y el sistema de archivos en sí.
¡Pero vivimos en el siglo XXI! ¡Existen mecanismos de registro que protegen contra tales problemas! Es cierto, la verdad es que hay un importante "pero": esta protección no es del fracaso, sino de sus consecuencias. Al restaurar a un estado consistente de acuerdo con el registro, las operaciones incompletas se descartarán, lo que significa que se perderán. Por lo tanto, es importante cambiar la prioridad a la protección de la causa, en lugar de tratar las consecuencias.
Se puede advertir al sistema que ahora se creará una instantánea. Para esto, el núcleo tiene las funciones
freeze_bdev y
thaw_bdev . Extraen las funciones del sistema de archivos freeze_fs y unfreeze_fs. Cuando llama al primero, el sistema debe restablecer la memoria caché, suspender la creación de nuevas solicitudes para el dispositivo de bloqueo y esperar la finalización de todas las solicitudes generadas previamente. Y cuando se llama a unfreeze_fs, el sistema de archivos restaura su funcionamiento normal.
Resulta que podemos advertir al sistema de archivos. ¿Qué pasa con las aplicaciones? Aquí, desafortunadamente, todo está mal. Mientras que en Windows hay un mecanismo
VSS que, con la ayuda de Writers, proporciona interacción con otros productos, en Linux cada uno sigue su propio camino. Por el momento, esto ha llevado a la situación de que la tarea del administrador del sistema de escribir (copiar,
robar , comprar, etc.) guiones de precongelación y descongelación por su cuenta, lo que preparará su aplicación para la instantánea. Por nuestra parte, en la próxima versión presentaremos soporte para Oracle Application Processing, como la característica más solicitada por nuestros clientes. Entonces, otras aplicaciones pueden ser compatibles, pero en general la situación es bastante triste.
¿Dónde colocar el complemento?
Este es el segundo problema que se interpone en nuestro camino. A primera vista, el problema no es obvio, pero después de un poco de comprensión, vemos que esto sigue siendo una astilla.
Por supuesto, la solución más fácil es colocar el complemento en la RAM. Para el desarrollador, ¡la opción es simplemente genial! Todo es rápido, muy conveniente para depurar, pero hay una jamba: la RAM es un recurso valioso, y nadie nos dará una gran oportunidad allí.
Bien, hagamos que el archivo instantáneo sea un archivo normal. Pero surge otro problema: no puede hacer una copia de seguridad del volumen en el que se encuentra la instantánea. La razón es simple: interceptamos solicitudes de grabación, lo que significa que interceptaremos nuestras propias solicitudes de grabación en el complemento. Los caballos corrían de manera científica: punto muerto. Luego, existe un gran deseo de utilizar un disco separado para esto, pero nadie agregará discos a nuestro servidor por nuestro bien. Debes poder trabajar en lo que es.
Posicionar remotamente el complemento es una excelente idea, pero se puede implementar en círculos muy estrechos de redes con gran ancho de banda y latencias microscópicas. De lo contrario, mientras mantiene la instantánea en la máquina, habrá una estrategia por turnos.
Por lo tanto, debe colocar de alguna manera difícil el complemento en el disco local. Pero, por regla general, todo el espacio en los discos locales ya está distribuido entre los sistemas de archivos y, al mismo tiempo, debe pensar detenidamente cómo solucionar el problema del punto muerto.
La dirección para la reflexión, en principio, es una: necesita asignar espacio de alguna manera en el sistema de archivos, pero trabajar directamente con el dispositivo de bloque. La solución a este problema se implementó en el código de espacio de usuario, en el servicio.
Hay una
llamada al sistema de
Falcocate que le permite crear un archivo vacío del tamaño deseado. Sin embargo, de hecho, solo se crean metadatos en el sistema de archivos que describen la ubicación del archivo en el volumen. Y ioctl
FIEMAP nos permite obtener un mapa de la ubicación de los bloques de archivos.
Y listo: creamos un archivo instantáneo usando Falocate, FIEMAP nos da un mapa de la ubicación de los bloques de este archivo, que podemos transferir para trabajar en nuestro módulo veeamsnap. Además, al acceder al snapstor, el módulo realiza solicitudes directamente al dispositivo de bloque en bloques que conocemos, y sin puntos muertos.
Pero hay un matiz. La llamada al sistema de Falcocate solo es compatible con XFS, EXT4 y BTRFS. Para otros sistemas de archivos como EXT3, debe escribirlo completamente para asignar el archivo. La funcionalidad se ve afectada por un aumento en el tiempo para preparar snappads, pero no hay otra opción. Nuevamente, necesitas poder trabajar en lo que es.
¿Qué sucede si ioctl FIEMAP tampoco es compatible? Esta es la realidad de NTFS y FAT32, donde ni siquiera hay soporte para el antiguo FIBMAP. Tuve que implementar un cierto algoritmo genérico, cuya operación no depende de las características del sistema de archivos. En pocas palabras, el algoritmo es:
- El servicio crea un archivo y comienza a escribirle un patrón específico.
- El módulo intercepta las solicitudes de escritura, verifica los datos que se escriben.
- Si los datos del bloque coinciden con el patrón dado, entonces el bloque se marca como perteneciente al snapstop.
Sí, difícil, sí, lentamente, pero mejor que nada. Se utiliza en casos excepcionales para sistemas de archivos sin soporte FIEMAP y FIBMAP.
Desbordamiento de instantánea
Más bien, el lugar que asignamos en la tienda de instantáneas termina. La esencia del problema es que no hay ningún lugar para descartar nuevos datos, lo que significa que la instantánea queda inutilizable.
Que hacer
Obviamente, necesita aumentar el tamaño de los snappants. Cuanto? La forma más fácil de establecer el tamaño de los snappants es determinar el porcentaje de espacio libre en el volumen (como se hizo para VSS). Para un volumen de 20 TB, el 10% será de 2 TB, que es mucho para un servidor descargado. Para un volumen de 200 GB, el 10% es 20 GB, lo que puede ser muy poco para un servidor que está actualizando sus datos de manera intensiva. Y todavía hay volúmenes delgados ...
En general, solo el administrador del sistema del servidor puede determinar el tamaño óptimo del complemento requerido por adelantado, es decir, debe hacer que la persona piense y dar su opinión experta. Esto no cumple con el principio de "Simplemente funciona".
Para resolver este problema, desarrollamos el algoritmo de instantánea de estiramiento. La idea es dividir el complemento en porciones. Al mismo tiempo, se crean nuevas porciones después de la creación de una instantánea según sea necesario.

Nuevamente, brevemente el algoritmo:
- Antes de crear una instantánea, la primera parte de la instantánea se crea y se entrega al módulo.
- Cuando se crea la instantánea, la porción comenzará a llenarse.
- Tan pronto como la mitad de la porción esté llena, se envía una solicitud al servicio para crear una nueva.
- El servicio lo crea, entrega los datos al módulo.
- El módulo comienza a llenar el siguiente lote.
- El algoritmo se repite hasta que se complete la copia de seguridad o hasta que alcancemos el límite en el uso de espacio libre en disco.
Es importante tener en cuenta que el módulo debe tener tiempo para crear nuevas porciones de snapposts según sea necesario; de lo contrario, desbordamiento, reinicio de instantáneas y sin respaldo. Por lo tanto, la operación de dicho algoritmo solo es posible en sistemas de archivos con soporte de Falcocate, donde puede crear rápidamente un archivo vacío.
¿Qué hacer en otros casos? Estamos tratando de adivinar el tamaño requerido y crear todo el snappast completo. Pero según nuestras estadísticas, la gran mayoría de los servidores Linux ahora usan EXT4 y XFS. EXT3 se encuentra en máquinas más antiguas. Pero en SLES / openSUSE puede tropezar con BTRFS.
Cambiar seguimiento de bloque (CBT)
Copia de seguridad incremental o diferencial (por cierto, el rábano picante de rábano picante es más dulce o no, sugiero leer
aquí ); sin él, no puede imaginar ningún producto de copia de seguridad para adultos. Y para que esto funcione, necesita CBT. Si alguien se perdió: CBT le permite realizar un seguimiento de los cambios y escribir en la copia de seguridad solo los datos modificados desde la última copia de seguridad.

Muchos tienen su propia experiencia en esta área. Por ejemplo, en VMware vSphere, esta característica ha estado disponible desde la versión 4 en 2009. En Hyper-V, se introdujo la compatibilidad con Windows Server 2016, y para admitir versiones anteriores, su propio controlador VeeamFCT se desarrolló en 2012. Por lo tanto, para nuestro módulo no nos convertimos en originales y utilizamos algoritmos que ya funcionan.
Sobre cómo funciona.
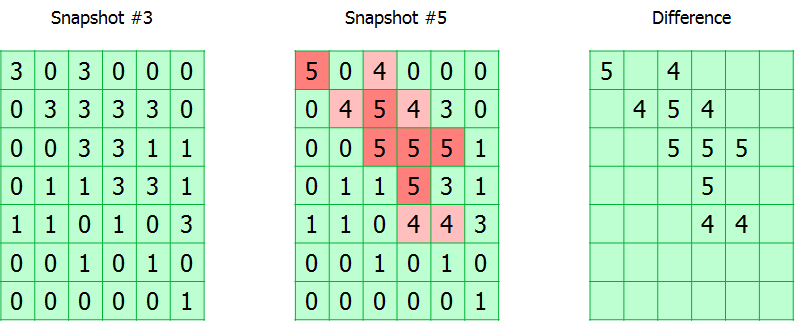
Todo el volumen rastreado se divide en bloques. El módulo simplemente realiza un seguimiento de todas las solicitudes de escritura, marcando los bloques modificados en la tabla. De hecho, la tabla CBT es una matriz de bytes, donde cada byte corresponde a un bloque y contiene el número de la instantánea en la que se modificó.
Durante la copia de seguridad, el número de instantánea se registra en los metadatos de la copia de seguridad. Por lo tanto, conociendo los números de la instantánea actual y de la que se realizó la copia de seguridad exitosa anterior, puede calcular el mapa de la ubicación de los bloques modificados.
Hay dos matices.
Como dije, se asigna un byte para el número de instantánea en la tabla CBT, lo que significa que la longitud máxima de la cadena incremental no puede ser superior a 255. Cuando se alcanza este umbral, la tabla se restablece y se produce una copia de seguridad completa. Puede parecer inconveniente, pero de hecho, una cadena de 255 incrementos está lejos de ser la mejor solución al crear un plan de respaldo.
La segunda característica es el almacenamiento de la tabla CBT solo en RAM. Por lo tanto, cuando reinicie la máquina de destino o descargue el módulo, se reiniciará y, de nuevo, deberá crear una copia de seguridad completa. Tal solución permite no resolver el problema del inicio del módulo al inicio del sistema. Además, no es necesario guardar las tablas CBT cuando apaga el sistema.
Problema de rendimiento
La copia de seguridad siempre es una buena carga para el IO de su equipo. Si ya hay suficientes tareas activas, el proceso de copia de seguridad puede convertir su sistema en una especie de
pereza .
A ver por qué.
Imagine que el servidor simplemente escribe linealmente algunos datos. La velocidad de grabación en este caso es máxima, todos los retrasos se minimizan, el rendimiento tiende al máximo. Ahora agregamos el proceso de copia de seguridad aquí, que en cada escritura aún necesita completar el algoritmo de Copia en escritura, y esta es una operación de lectura adicional con escritura posterior. Y no olvide que para la copia de seguridad aún necesita leer datos del mismo volumen. En una palabra, su hermoso acceso lineal se convierte en un acceso aleatorio despiadado con todas las consecuencias.
Obviamente, tenemos que hacer algo con esto, e implementamos una canalización para procesar las solicitudes, no una a la vez, sino en paquetes completos. Funciona asi.
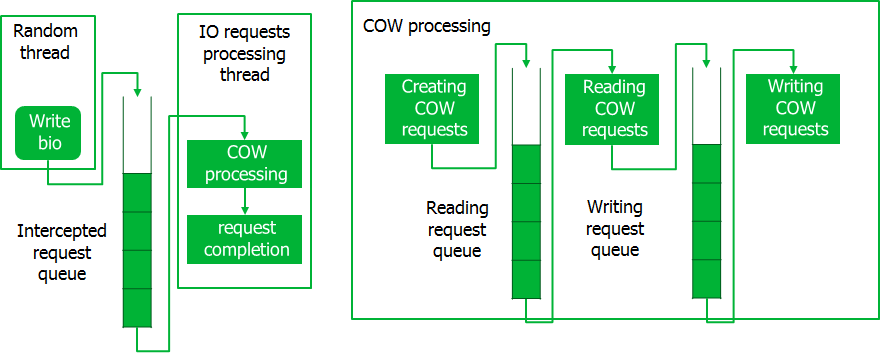
Al interceptar solicitudes, se colocan en una cola, donde una secuencia especial los toma en porciones. En este momento, se crean solicitudes CoW, que también se procesan en lotes. Cuando se procesan solicitudes CoW, primero se realizan todas las operaciones de lectura para toda la porción, luego de lo cual se realizan las operaciones de escritura. Solo después de que se complete el procesamiento de toda la parte de las solicitudes de CoW, se ejecutan las solicitudes interceptadas. Tal transportador proporciona acceso al disco en grandes porciones de datos, lo que minimiza las pérdidas de tiempo.
Estrangulamiento
Ya en la etapa de depuración, surgió otro matiz. Durante la copia de seguridad, el sistema dejó de responder, es decir Las solicitudes de E / S del sistema comenzaron a ejecutarse con largas demoras. Pero, las solicitudes de lectura de datos de una instantánea se realizaron a una velocidad cercana al máximo.
Tuve que estrangular un poco el proceso de copia de seguridad implementando el mecanismo de aceleración. Para hacer esto, el proceso de lectura de la imagen de la instantánea se pone en estado de espera si la cola de solicitudes interceptadas no está vacía. Como era de esperar, el sistema cobró vida.
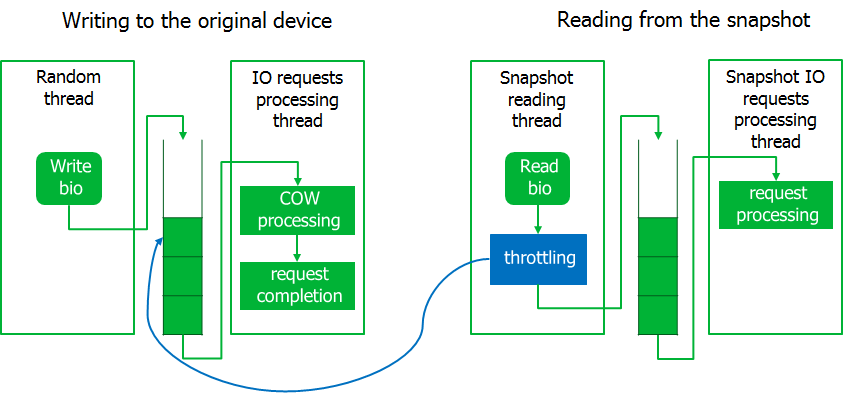
Como resultado, si la carga en el sistema de E / S aumenta bruscamente, el proceso de lectura de la instantánea esperará. Aquí decidimos guiarnos por el principio de que es mejor finalizar la copia de seguridad con un error que interrumpir el servidor.
Punto muerto
Creo que debemos explicar con más detalle de qué se trata.
Ya en la etapa de prueba, comenzamos a encontrar situaciones de un bloqueo total del sistema con un diagnóstico de siete problemas: un reinicio.
Ellos comenzaron a entender. Resultó que esta situación se puede observar si, por ejemplo, crea una instantánea del dispositivo de bloque en el que se encuentra el volumen LVM y coloca la instantánea en el mismo volumen LVM. Permítame recordarle que LVM usa el módulo del kernel del mapeador de dispositivos.

En esta situación, al interceptar una solicitud de escritura, el módulo, copiando los datos en el complemento, enviará la solicitud de escritura al volumen LVM. El mapeador de dispositivos redirigirá esta solicitud al dispositivo de bloque. Una solicitud del mapeador de dispositivos será nuevamente interceptada por el módulo. Pero una nueva solicitud no se puede procesar hasta que se haya procesado la anterior. Como resultado, el procesamiento de la solicitud está bloqueado, el punto muerto lo recibe.
Para evitar esta situación, el módulo del kernel proporciona un tiempo de espera para la operación de copiar datos en el complemento. Esto le permite detectar el punto muerto y la copia de seguridad de bloqueo. La lógica aquí es la misma: es mejor no hacer una copia de seguridad que suspender el servidor.
Base de datos Round Robin
Esto ya es un problema lanzado por los usuarios después del lanzamiento de la primera versión.
Resultó que existen tales servicios que solo se dedican a sobrescribir constantemente los mismos bloques.
Un ejemplo sorprendente son los servicios de monitoreo, que constantemente generan datos sobre el estado del sistema y los sobrescriben en un círculo. Para tales tareas, use bases de datos cíclicas especializadas ( RRD ).Resultó que con una copia de seguridad de tales bases se garantiza que la instantánea se desborde. En un estudio detallado del problema, encontramos una falla en la implementación del algoritmo CoW. Si se sobrescribió el mismo bloque, los datos se copiaron en el complemento cada vez. Resultado: duplicación de datos en el complemento.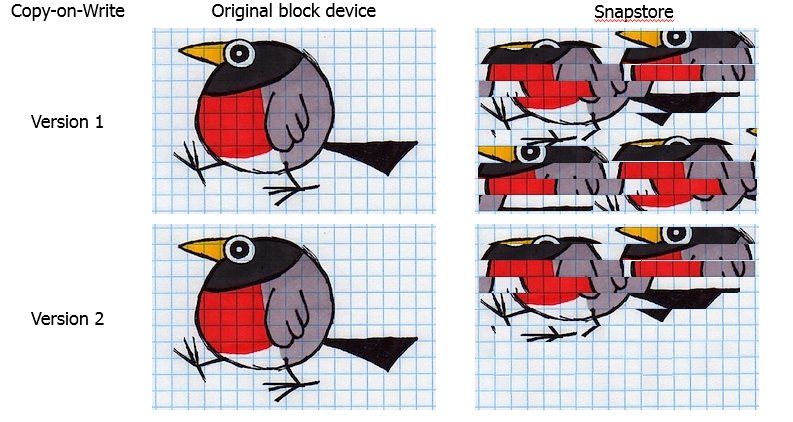 Naturalmente, cambiamos el algoritmo. Ahora el volumen se divide en bloques y los datos se copian en el bloque de ajuste. Si el bloque ya se ha copiado una vez, este proceso no se repite.
Naturalmente, cambiamos el algoritmo. Ahora el volumen se divide en bloques y los datos se copian en el bloque de ajuste. Si el bloque ya se ha copiado una vez, este proceso no se repite.Selección de tamaño de bloque
Ahora, cuando el snapstrap se divide en bloques, surge la pregunta: ¿cuál es, de hecho, el tamaño de los bloques para dividir las snappastes?El problema es doble. Si el bloque se hace grande, es más fácil para ellos operar, pero si al menos un sector cambia, debe enviar todo el bloque a la plataforma y, como resultado, aumentan las posibilidades de sobrellenar la plataforma. Obviamente, cuanto menor sea el tamaño del bloque, mayor será el porcentaje de datos útiles enviados al almacén de instantáneas, pero ¿cómo afectará el rendimiento?Buscaron la verdad empíricamente y obtuvieron 16KiB. También tenga en cuenta que Windows VSS también utiliza 16 bloques KiB.
Obviamente, cuanto menor sea el tamaño del bloque, mayor será el porcentaje de datos útiles enviados al almacén de instantáneas, pero ¿cómo afectará el rendimiento?Buscaron la verdad empíricamente y obtuvieron 16KiB. También tenga en cuenta que Windows VSS también utiliza 16 bloques KiB.En lugar de una conclusión
Eso es todo por ahora. Dejaré muchos otros problemas, no menos interesantes, como la dependencia de las versiones del kernel, la elección de las opciones de distribución del módulo, la compatibilidad de kABI, el trabajo en condiciones de backport, etc. El artículo resultó ser voluminoso, así que decidí detenerme en los problemas más interesantes.Ahora nos estamos preparando para la versión de lanzamiento 3.0, el código del módulo está en github y cualquiera puede usarlo bajo la licencia GPL.