Para aquellos a quienes les gustó mi
artículo anterior , sigo compartiendo mis impresiones sobre la herramienta de prueba de estrés Locust.
Trataré de demostrar claramente las ventajas de escribir un python de prueba de carga con código en el que pueda preparar convenientemente cualquier dato para la prueba y procesar los resultados.
Procesamiento de respuesta del servidor
A veces, en las pruebas de carga, no es suficiente simplemente obtener 200 OK del servidor HTTP. Sucede que debe verificar el contenido de la respuesta para asegurarse de que, bajo carga, el servidor emite los datos correctos o realiza cálculos precisos. Solo para tales casos, Locust agregó la capacidad de anular los parámetros de éxito de respuesta del servidor. Considere el siguiente ejemplo:
from locust import HttpLocust, TaskSet, task import random as rnd class UserBehavior(TaskSet): @task(1) def check_albums(self): photo_id = rnd.randint(1, 5000) with self.client.get(f'/photos/{photo_id}', catch_response=True, name='/photos/[id]') as response: if response.status_code == 200: album_id = response.json().get('albumId') if album_id % 10 != 0: response.success() else: response.failure(f'album id cannot be {album_id}') else: response.failure(f'status code is {response.status_code}') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
Solo tiene una solicitud, lo que creará una carga en el siguiente escenario:
Desde el servidor, solicitamos fotos de objetos con una identificación aleatoria en el rango de 1 a 5000 y verificamos la identificación del álbum en este objeto, asumiendo que no puede ser un múltiplo de 10
Aquí puede dar algunas explicaciones de inmediato:
- la increíble construcción con request () como respuesta: puede reemplazarlo con éxito con response = request () y trabajar en silencio con el objeto de respuesta
- La URL se forma usando la sintaxis de formato de cadena agregada en Python 3.6, si no me equivoco: f '/ photos / {photo_id}' . ¡En versiones anteriores, este diseño no funcionará!
- Un nuevo argumento que no habíamos usado antes, catch_response = True , le dice a Locust que nosotros mismos determinaremos el éxito de la respuesta del servidor. Si no lo especifica, recibiremos el objeto de respuesta de la misma manera y podremos procesar sus datos, pero no redefiniremos el resultado. A continuación se muestra un ejemplo detallado.
- Otro argumento name = '/ photos / [id]' . Es necesario agrupar las solicitudes en estadísticas. El nombre puede ser cualquier texto, no es necesario repetir la URL. Sin ella, cada solicitud con una dirección o parámetros únicos se registrará por separado. Así es como funciona:
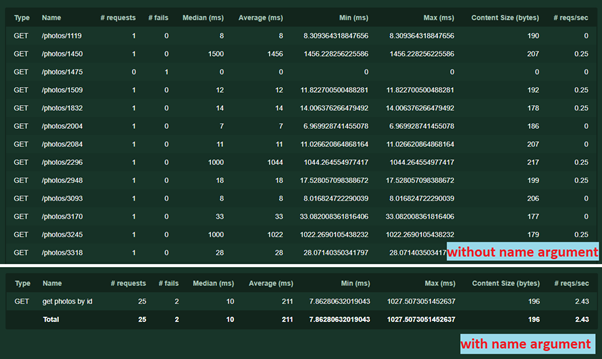
Con el mismo argumento, puede realizar otro truco: a veces sucede que un servicio con diferentes parámetros (por ejemplo, diferentes contenidos de solicitudes POST) realiza una lógica diferente. Para que los resultados de la prueba no se mezclen, puede escribir varias tareas separadas, especificando para cada una su propio
nombre de argumento.
A continuación hacemos los controles. Tengo 2 de ellos. Primero, verificamos que el servidor devolvió una respuesta if
response.status_code == 200 :
En caso afirmativo, verifique si la identificación del álbum es un múltiplo de 10. Si no es un múltiplo, marque esta respuesta como una
respuesta exitosa
.En otros casos, indicamos por qué la respuesta falló
response.failure ('texto de error') . Este texto se mostrará en la página Fallos durante la prueba.
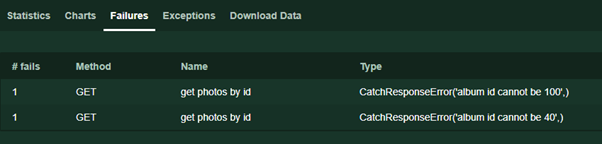
Además, los lectores atentos podrían notar la ausencia de excepciones que son características del código que funciona con las interfaces de red. De hecho, en el caso de tiempo de espera, error de conexión y otros incidentes imprevistos, Locust manejará los errores y aún devolverá una respuesta, indicando, sin embargo, que el estado del código de respuesta es 0.
Si el código aún arroja una excepción, se escribirá en la pestaña Excepciones en tiempo de ejecución para que podamos manejarlo. La situación más típica es que el json'e de la respuesta no devolvió el valor que estábamos buscando, pero ya estamos realizando las siguientes operaciones.
Antes de cerrar el tema, en el ejemplo utilizo el servidor json para mayor claridad, ya que es más fácil procesar las respuestas. Pero puede trabajar con el mismo éxito con HTML, XML, FormData, archivos adjuntos y otros datos utilizados por los protocolos basados en HTTP.
Trabaja con escenarios complejos.
Casi cada vez que la tarea es realizar pruebas de carga de una aplicación web, rápidamente queda claro que es imposible proporcionar una cobertura decente solo con los servicios GET, que simplemente devuelven datos.
Ejemplo clásico: para probar una tienda en línea, es deseable que el usuario
- Abrió la tienda principal
- Estaba buscando bienes
- Detalles del artículo abierto
- Artículo agregado al carrito
- Pagado
Del ejemplo, podemos suponer que los servicios de llamadas en orden aleatorio no funcionarán, solo secuencialmente. Además, los bienes, cestas y formas de pago pueden tener identificadores únicos para cada usuario.
Usando el ejemplo anterior, con modificaciones menores, puede implementar fácilmente la prueba de tal escenario. Adaptamos el ejemplo para nuestro servidor de prueba:
- El usuario está escribiendo una nueva publicación.
- El usuario escribe un comentario en la nueva publicación.
- El usuario lee el comentario
from locust import HttpLocust, TaskSet, task class FlowException(Exception): pass class UserBehavior(TaskSet): @task(1) def check_flow(self):
En este ejemplo, agregué una nueva clase
FlowException . Después de cada paso, si no salió como se esperaba, lanzo esta clase de excepción para interrumpir el script; si la publicación no funcionó, entonces no habrá nada que comentar, etc. Si lo desea, la construcción se puede reemplazar con el
retorno habitual, pero en este caso, durante la ejecución y al analizar los resultados, no quedará tan claro dónde cae el script ejecutado en la pestaña Excepciones. Por la misma razón, no uso el
intento ... excepto construir.
Hacer que la carga sea realista
Ahora me pueden reprochar, en el caso de la tienda todo es realmente lineal, pero el ejemplo con publicaciones y comentarios es demasiado descabellado: leen las publicaciones 10 veces más a menudo de lo que crean. Razonablemente, hagamos que el ejemplo sea más viable. Y hay al menos 2 enfoques:
- Puede "codificar" la lista de publicaciones que los usuarios leen y simplificar el código de prueba si existe tal posibilidad y la funcionalidad del backend no depende de publicaciones específicas
- Guarde las publicaciones creadas y léalas si no es posible preestablecer la lista de publicaciones o la carga realista depende de las publicaciones que se leen (eliminé la creación de comentarios del ejemplo para hacer su código más pequeño y más visual)
from locust import HttpLocust, TaskSet, task import random as r class UserBehavior(TaskSet): created_posts = [] @task(1) def create_post(self): new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'} post_response = self.client.post('/posts', json=new_post) if post_response.status_code != 201: return post_id = post_response.json().get('id') self.created_posts.append(post_id) @task(10) def read_post(self): if len(self.created_posts) == 0: return post_id = r.choice(self.created_posts) self.client.get(f'/posts/{post_id}', name='read post') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
En la clase
UserBehavior, creé una lista
created_posts . Preste especial atención: este es un objeto y no se creó en el constructor de la
clase __init __ (), por lo tanto, a diferencia de la sesión del cliente, esta lista es común para todos los usuarios. La primera tarea crea una publicación y escribe su identificación en la lista. El segundo, 10 veces más seguido, lee una publicación seleccionada al azar de la lista. Una condición adicional de la segunda tarea es verificar si hay publicaciones creadas.
Si queremos que cada usuario opere solo con sus propios datos, podemos declararlos en el constructor de la siguiente manera:
class UserBehavior(TaskSet): def __init__(self, parent): super(UserBehavior, self).__init__(parent) self.created_posts = list()
Algunas características más
Para el lanzamiento secuencial de tareas, la documentación oficial sugiere que también usemos la anotación de tarea @seq_task (1), especificando el número de serie de la tarea en el argumento
class MyTaskSequence(TaskSequence): @seq_task(1) def first_task(self): pass @seq_task(2) def second_task(self): pass @seq_task(3) @task(10) def third_task(self): pass
En este ejemplo, cada usuario ejecutará primero
first_task , luego
second_task , luego 10 veces
third_task .
Francamente, la disponibilidad de tal oportunidad agrada, pero, a diferencia de los ejemplos anteriores, no está claro cómo transferir los resultados de la primera tarea a la segunda si es necesario.
Además, para escenarios particularmente complejos, es posible crear conjuntos de tareas anidadas, de hecho, crear varias clases de TaskSet y conectarse entre sí.
from locust import HttpLocust, TaskSet, task class Todo(TaskSet): @task(3) def index(self): self.client.get("/todos") @task(1) def stop(self): self.interrupt() class UserBehavior(TaskSet): tasks = {Todo: 1} @task(3) def index(self): self.client.get("/") @task(2) def posts(self): self.client.get("/posts") class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
En el ejemplo anterior, con una probabilidad de 1 a 6, se iniciará el script
Todo y se ejecutará hasta que, con una probabilidad de 1 a 4, regrese al script
UserBehavior . Es muy importante que tenga una llamada a
self.interrupt () : sin ella, las pruebas se centrarán en la subtarea.
Gracias por leer En el artículo final escribiré sobre pruebas distribuidas y pruebas sin una interfaz de usuario, así como sobre las dificultades que encontré durante las pruebas con Locust y cómo solucionarlas.