
Habr, este es un informe del ingeniero de software Alexei Starkov en la conferencia Moscow Python Conf ++ 2018 en Moscú. Video al final de la publicación.
Hola a todos! Mi nombre es Alexei Starkov, soy yo, en mis mejores años, trabajo en una fábrica.
Ahora trabajo en Qrator Labs. Básicamente, toda mi vida, estudié C y C ++, me encanta Alexandrescu, The Gang of Four, los principios de SOLID, eso es todo. Lo que me convierte en un astronauta arquitectónico. He estado escribiendo Python durante los últimos años porque me gusta.
En realidad, ¿quiénes son los "cosmonautas arquitectónicos"? La primera vez que conocí este término con Joel Spolsky, probablemente lo leyó. Describe a los "astronautas" como personas que quieren construir una arquitectura ideal, que cuelgan la abstracción, sobre la abstracción, sobre la abstracción, que se está volviendo cada vez más general. Al final, estos niveles son tan altos que describen todos los programas posibles, pero no resuelven ningún problema práctico. En este momento, el "astronauta" (esta es la última vez que este término está rodeado de comillas) se queda sin aire y muere.
También tengo tendencias hacia la exploración espacial arquitectónica, pero en este informe hablaré un poco sobre cómo me mordió y no me permitió construir un sistema con el rendimiento necesario. Lo principal es cómo lo superé.
Resumen de mi informe: was / was.

Un aumento de miles y millones de veces. Cuando hice esta diapositiva, el único pensamiento que tuve fue "¿Cómo?"

¿Dónde podría fastidiar tanto? Si no quieres equivocarte como yo, sigue leyendo.

Hablaré sobre el sistema de configuración. El sistema de configuración es una herramienta interna en Qrator Labs que almacena configuraciones para la Red definida por software (SDN), nuestra red de filtrado. Se compromete a sincronizar la configuración entre componentes y monitorear su estado.

¿En qué consiste, en resumen? Tenemos una base de datos que almacena una instantánea de nuestra configuración para toda la red, y tenemos un servidor que procesa los comandos que ingresan y de alguna manera cambia la configuración.
Nuestros administradores y clientes técnicos llegan a este servidor y a través de la consola, a través de las API de punto final, las API REST, JSON RPC y otras cosas emiten comandos al servidor, como resultado de lo cual cambia nuestra configuración.
Los equipos pueden ser muy simples o más complicados. Luego, tenemos un cierto conjunto de receptores que componen nuestro SDN y el servidor envía la configuración a estos receptores. Eso suena bastante simple. Básicamente, hablaré sobre esta parte.
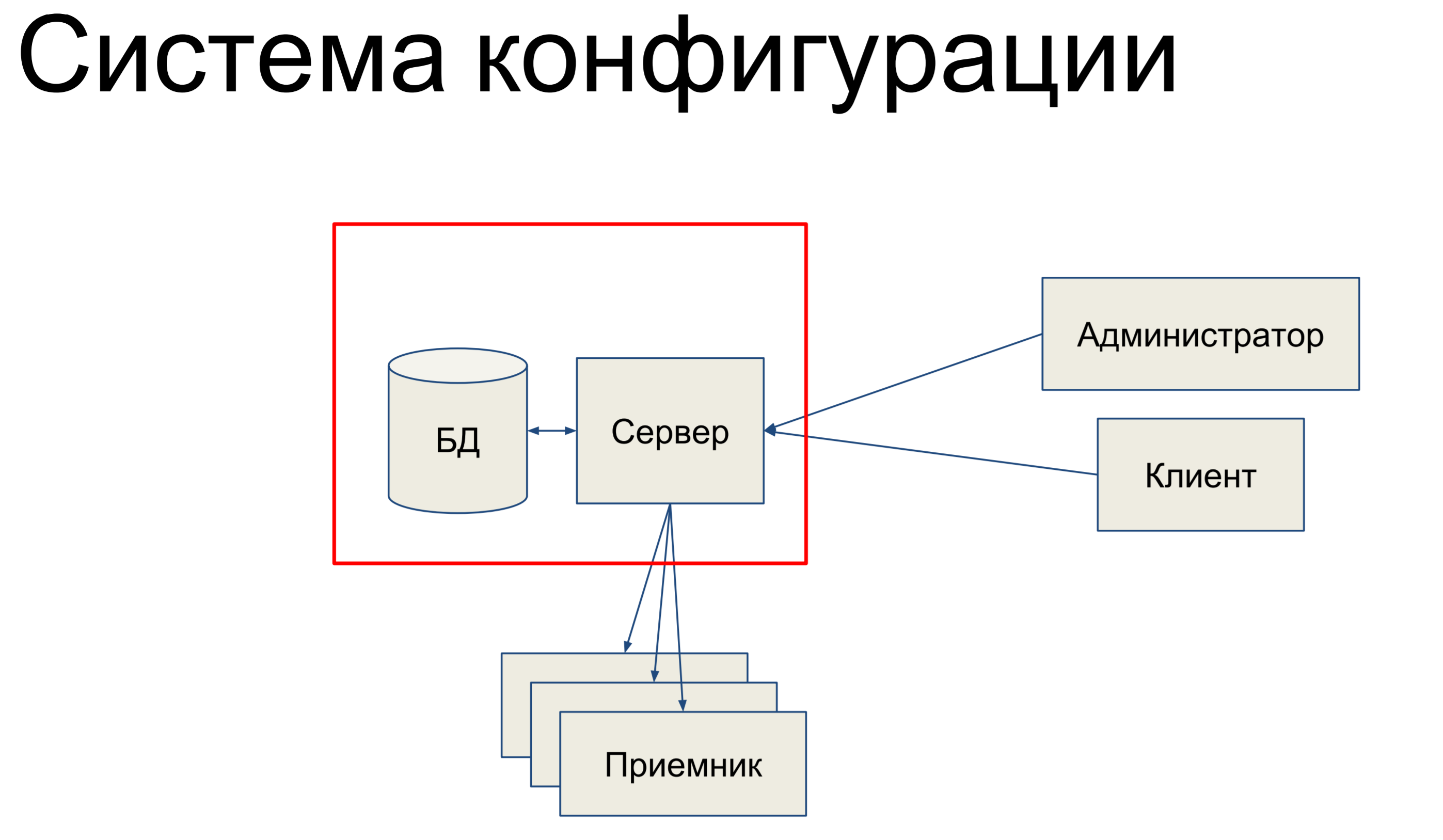
Ya que es ella quien está relacionada con la base de datos y la alquimia.

¿Cuál es la peculiaridad de este sistema? Es bastante pequeño, mediocre. Cientos de miles, hasta millones, de entidades se almacenan en esta base de datos. La peculiaridad es que el gráfico de las relaciones entre entidades es bastante complejo. Hay varias jerarquías de herencia entre entidades, hay inclusiones, simplemente hay dependencias entre ellas. Todas estas restricciones están determinadas por la lógica empresarial y debemos cumplirlas.
La proporción de solicitudes de escritura a solicitudes de lectura es de aproximadamente 15: 1. Aquí está claro: hay muchos comandos para cambiar la configuración y una vez en un período de tiempo prolongado tenemos la configuración de inserción a los puntos finales.
MySQL se usa internamente: también está disponible en otros productos de nuestra empresa, tenemos una experiencia bastante seria en esta base de datos, hay personas que pueden trabajar con ella: crear un esquema de datos, diseñar consultas y todo lo demás. Por lo tanto, tomamos MySQL como una base de datos relacional universal.

¿Cuál fue el problema después de diseñar este sistema? La ejecución de un comando tomó de uno a treinta segundos, dependiendo de la complejidad del equipo. En consecuencia, el retraso en la ejecución llegó a cinco minutos. Llegó un equipo, 30 segundos, el segundo y así sucesivamente, una acumulación de acumulados, un retraso de 5 minutos.
El retraso en la aplicación de la configuración es de hasta diez minutos. Se decidió que esto no era suficiente para nosotros y que la optimización era necesaria.

Primero, antes de realizar cualquier optimización, es necesario llevar a cabo una investigación y descubrir cuál es el problema.

Al final resultó que no teníamos el componente más importante para la investigación: no teníamos telemetría. Por lo tanto, si está diseñando algún tipo de sistema, primero, en la etapa de diseño, agregue telemetría. Incluso si el sistema es inicialmente pequeño, luego un poco más, luego aún más; al final, todos llegan a una situación en la que necesita ver pistas, pero no hay telemetría.
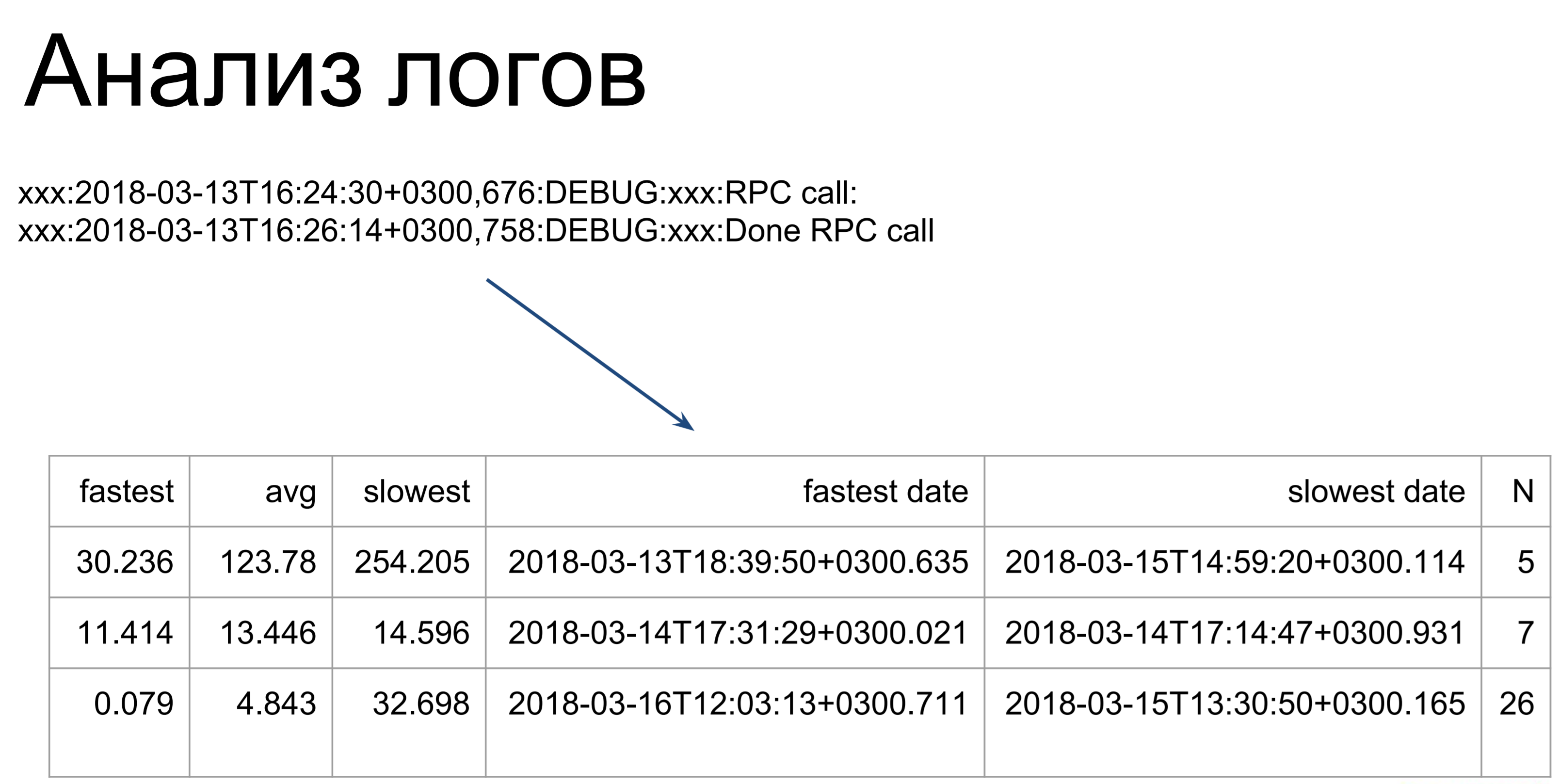
¿Qué se puede hacer a continuación si no tiene telemetría? Puedes analizar los registros. Aquí, los guiones bastante simples pasan por nuestros registros y los convierten en una tabla de este tipo, ilustrando los tiempos de ejecución de comandos más rápidos, lentos y promedio. A partir de aquí, ya podemos ver en qué lugares tenemos gags: qué equipos tardan más en ejecutarse y cuáles más rápido.

Lo único a tener en cuenta es que al analizar los registros, solo consideramos el tiempo de ejecución de estos comandos en el servidor. Esta es la primera etapa, la marcada como t2. t1: así es como el cliente verá el tiempo de ejecución de nuestro equipo: entrar en la cola, esperar, ejecutar en el servidor. Este tiempo será más largo, por lo que optimizamos el tiempo t2 y luego usamos el tiempo t1 para determinar si hemos alcanzado el objetivo.
t1 es la métrica de calidad de nuestro rendimiento.

En consecuencia, así es como perfilamos a todos los equipos, es decir, tomamos el registro del servidor, lo manejamos a través de nuestros scripts, buscamos e identificamos los componentes que funcionaron más lentamente. El servidor está construido de forma bastante modular, un componente separado es responsable de cada comando, y podemos perfilar los componentes individualmente, y hacer puntos de referencia para ellos. Así que aquí teníamos una clase, para cada componente problemático que escribimos en el que en code_under_test () realizamos alguna actividad que representa el uso de combate del componente. Y había dos métodos: profile () y bench (). La primera llama a cProfile, que muestra cuántas veces se llamó, dónde están los cuellos de botella.
bench () se ejecutó varias veces y consideró diferentes métricas para nosotros; así es como evaluamos el rendimiento.
¡Pero resultó que este no es el problema!

El principal problema fue la cantidad de consultas a la base de datos. Hubo muchas solicitudes, y para entender por qué había tantas, veamos cómo se organizó todo.
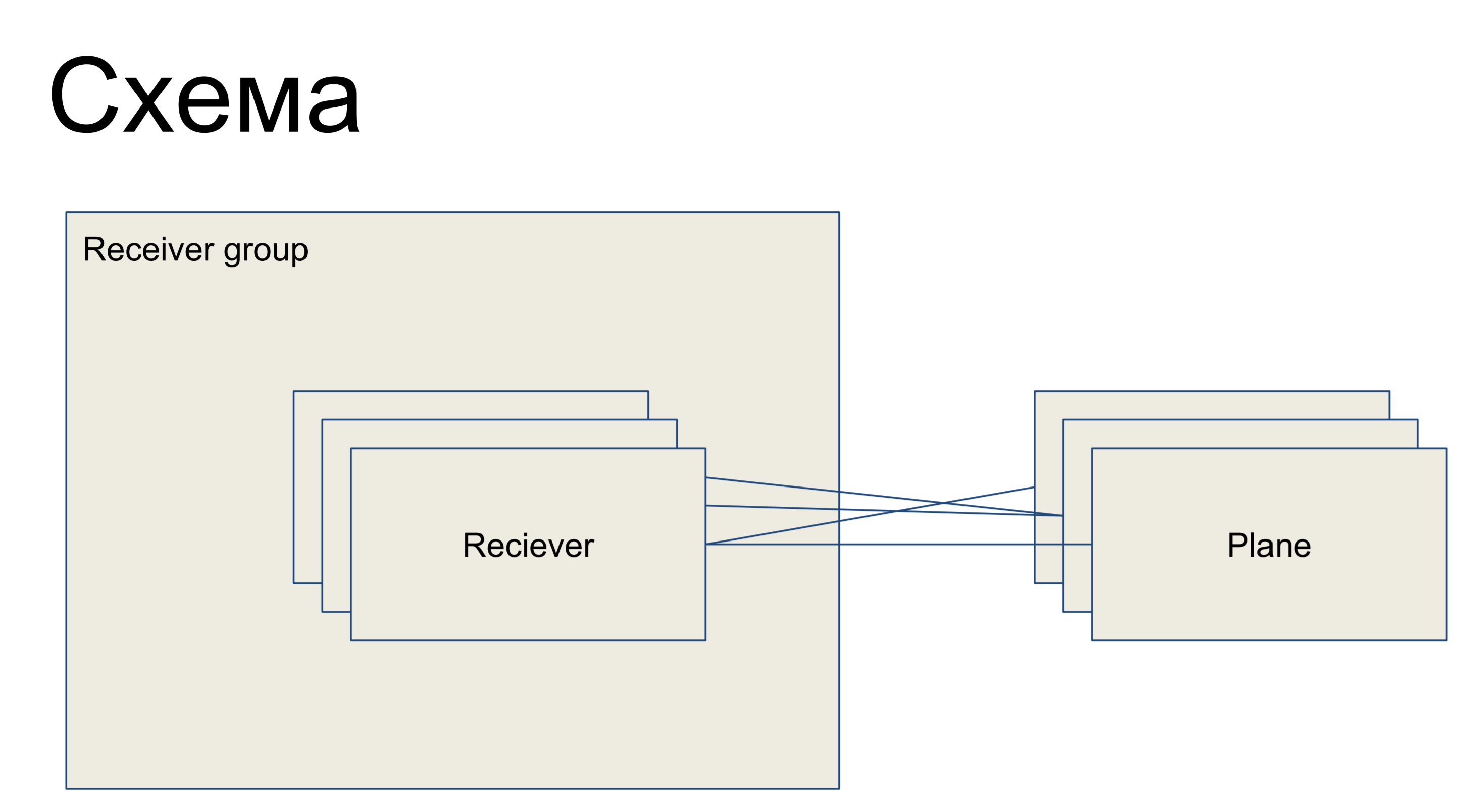
Ante nosotros hay una pieza de un circuito simple que representa a nuestros receptores, presentada en forma de la clase Receptor. Están unidos en algún grupo - grupo receptor. Y, en consecuencia, hay algunos planos de configuración: segmentos de la configuración, que son un subconjunto de las configuraciones que son responsables de un "rol" de este receptor. Por ejemplo, para enrutamiento - plano de enrutamiento. Las llanuras con receptores se pueden conectar en cualquier orden, es decir, esta es una relación de muchos a muchos.
Esta es una parte del gran esquema que estoy presentando aquí para que los ejemplos puedan entenderse mejor.
¿Qué quiere hacer cada cosmonauta arquitectónico cuando ve la API de otra persona? Quiere ocultarlo, abstraer y escribir su interfaz para poder eliminar esta API, o más bien ocultarla.
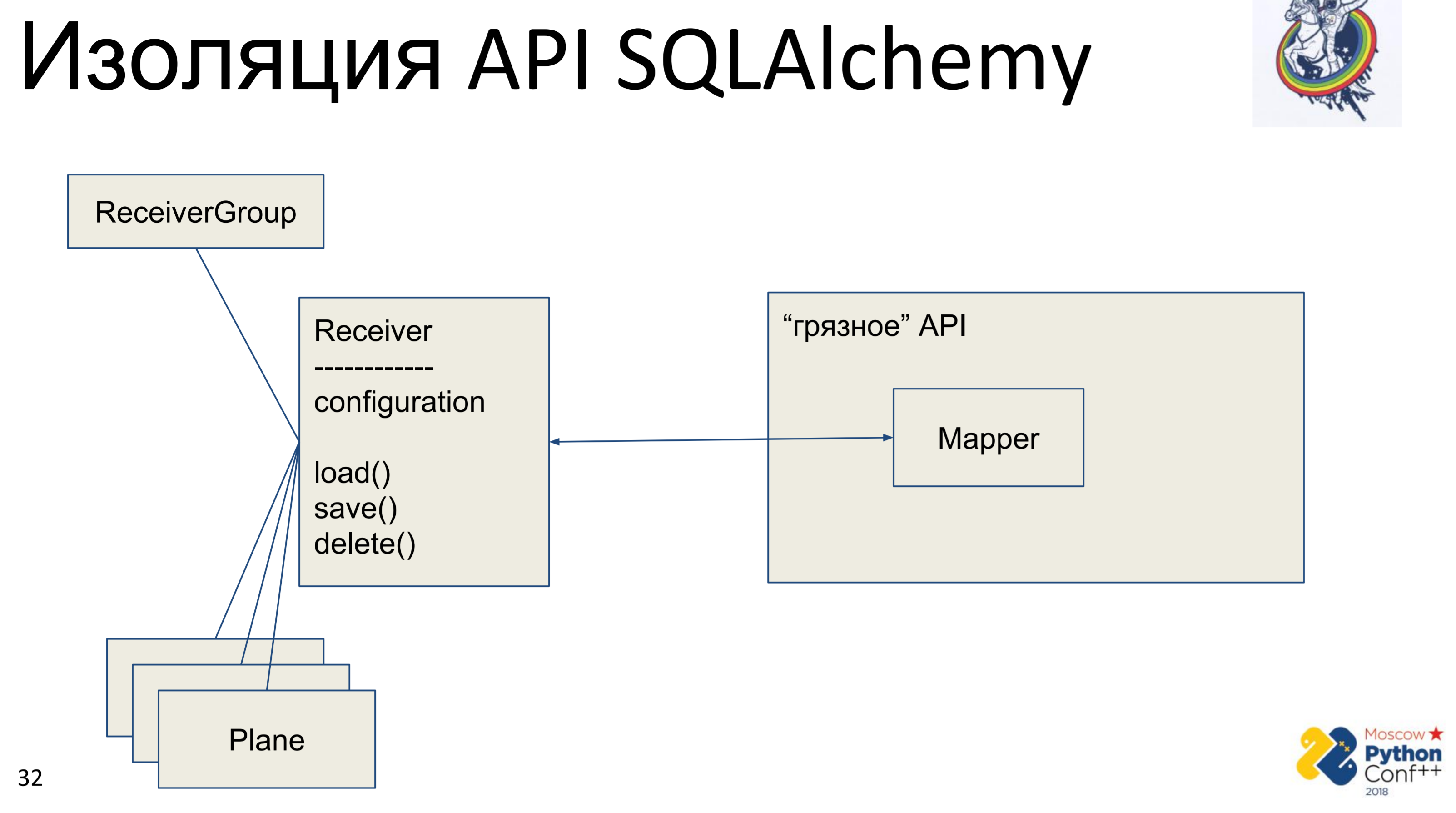
En consecuencia, hay una API de alquimia "sucia", en la que hay, de hecho, mapeadores y nuestra clase "pura" - Receiver, en la que se almacena alguna configuración y hay métodos: load (), save (), delete (). Y todas las otras clases asociadas con él. Obtenemos un gráfico de objetos Python, de alguna manera conectados entre sí: cada uno de ellos tiene un método load (), save (), delete (), que se refiere al mapeador de alquimia, que, a su vez, llama a la API.

La implementación aquí es muy simple. Tenemos un método de carga que realiza una consulta a la base de datos y para cada objeto recibido crea su propio objeto Python. Hay un método de guardar que hace la operación opuesta: busca si hay un objeto en la base de datos utilizando la clave primaria, si no, crea, agrega y luego guardamos el estado de este objeto. delete en la clave primaria recibe y elimina el objeto de la base de datos.

El problema principal es inmediatamente visible: esto es el mapeo. Primero, lo hacemos una vez desde el objeto Python al mapeador, luego el mapeador a la base. El mapeo adicional es una o dos llamadas, lo que puede no ser tan aterrador todavía. El principal problema fue la sincronización manual. Tenemos dos objetos de nuestra interfaz "limpia" y uno de ellos cambia el atributo: ¿cómo vemos que el atributo ha cambiado en el otro? De ninguna manera Es necesario fusionar los cambios en la base de datos y obtener el atributo en otro objeto. Por supuesto, si sabemos que los objetos están presentes en el mismo contexto, de alguna manera podemos rastrear esto. Pero si tenemos dos sesiones en diferentes lugares, solo a través de la base, o bloqueamos la base en la memoria, lo que no hicimos.
Este cargar / guardar / eliminar es otro mapeador que duplica completamente el interior de la alquimia, que está bien escrito, probado. Esta herramienta tiene muchos años, hay mucha ayuda en Internet y duplicarla tampoco es muy buena.
¿Ves el ícono en la esquina superior derecha? Así que marcaré las diapositivas en las que se hace algo por "pureza", para aumentar el nivel de abstracción, para la astronáutica arquitectónica. Es decir, las diapositivas sin este ícono son pragmáticas y aburridas, poco interesantes y no se pueden leer.
Qué hacer si muchas consultas son lentas. Cuantas En realidad mucho. Imagine una cadena de herencia: un objeto, tiene un padre, ese tiene otro padre. Sincronizamos el objeto hijo; para hacer esto, primero debe sincronizar los padres. Para sincronizar un padre, debe sincronizar su padre. Bueno, todos estaban sincronizados. De hecho, dependiendo de cómo hayamos construido el gráfico, podríamos caminar y sincronizar todos estos objetos cientos de veces, de ahí una gran cantidad de solicitudes.
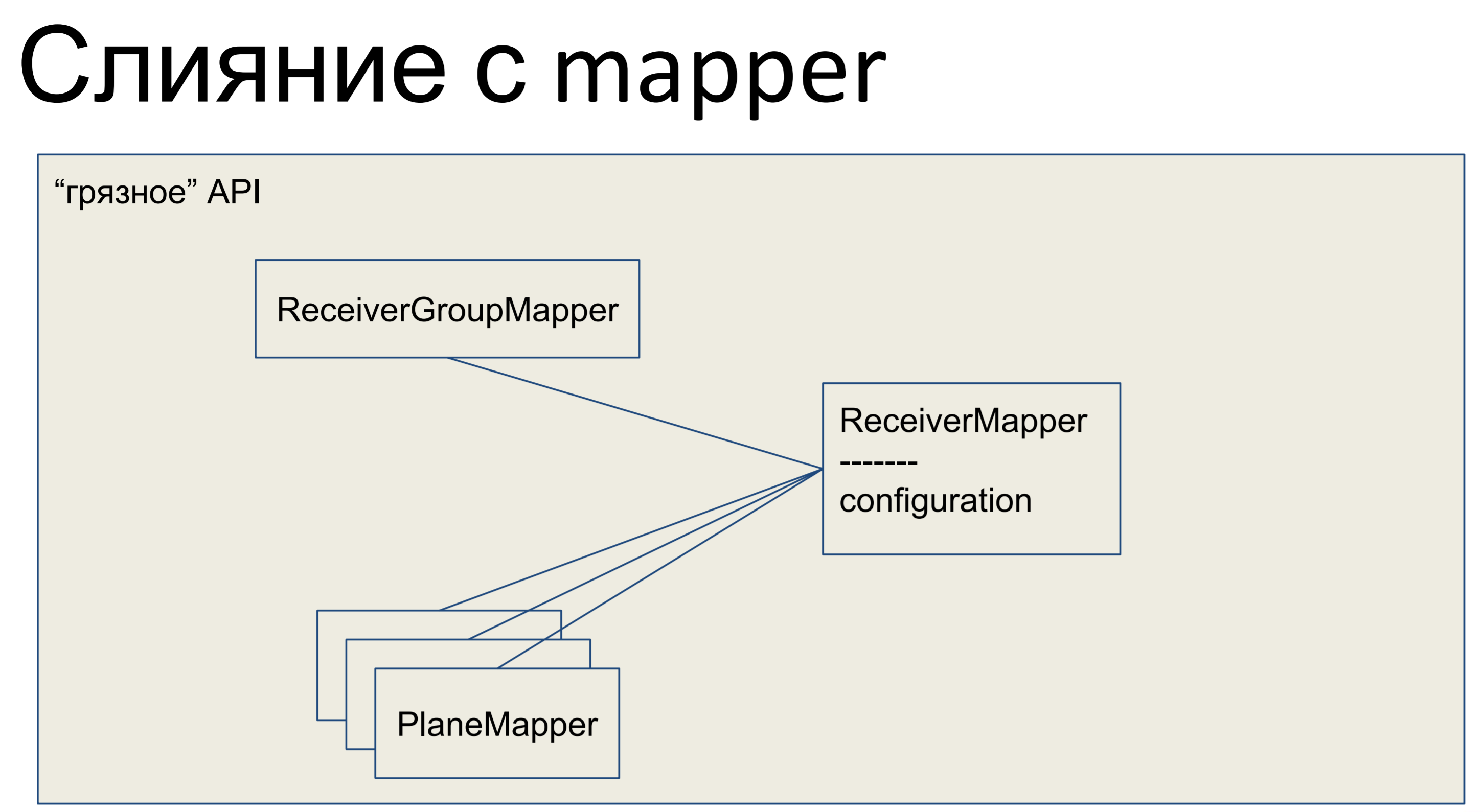
Que hemos hecho Tomamos toda nuestra lógica de negocios y la metimos en el mapeador. Todos los demás objetos aquí también se fusionaron con los mapeadores, y nuestra API completa, toda la capa de abstracción de datos, resultó sucia.

Así es como se ve en Python: nuestro mapeador tiene algún tipo de lógica de negocios, hay una descripción declarativa de esta placa allí mismo. Se enumeran columnas, relaciones. Aquí tenemos tal clase.

Por supuesto, desde el punto de vista de cualquier astronauta, una API sucia es un inconveniente. Lógica empresarial en una descripción declarativa de la base. Los esquemas se mezclan con la lógica empresarial. Uf Feo
La descripción del circuito está abarrotada. Esto es realmente un problema: si la lógica de negocios no tiene dos líneas, sino un volumen mayor, entonces en esta clase necesitamos desplazarnos o buscar mucho tiempo para llegar a descripciones específicas. Antes de eso, todo era hermoso: en un lugar, la descripción de la base, declarativa, descripción de los esquemas, en otro lugar, la lógica de negocios. Y luego el circuito está abarrotado.
Pero, por otro lado, obtenemos inmediatamente los mecanismos de la alquimia: unidad de trabajo, que le permite rastrear qué objetos están sucios y qué relés deben actualizarse; obtenemos una relación que nos permite deshacernos de preguntas adicionales en la base de datos, sin garantizar que se llenen las colecciones relevantes; y el mapa de identidad que más nos ayudó. El mapa de identidad garantiza que dos objetos de Python serán el mismo objeto de Python si tienen la misma clave primaria.
En consecuencia, redujimos inmediatamente la complejidad a lineal.

Estos son resultados intermedios. El rendimiento aumentó de inmediato 10 veces, el número de consultas a la base de datos disminuyó entre 40 y 80 veces y el RPS aumentó a 1-5. Pues bien. Pero la API está sucia. Que hacer
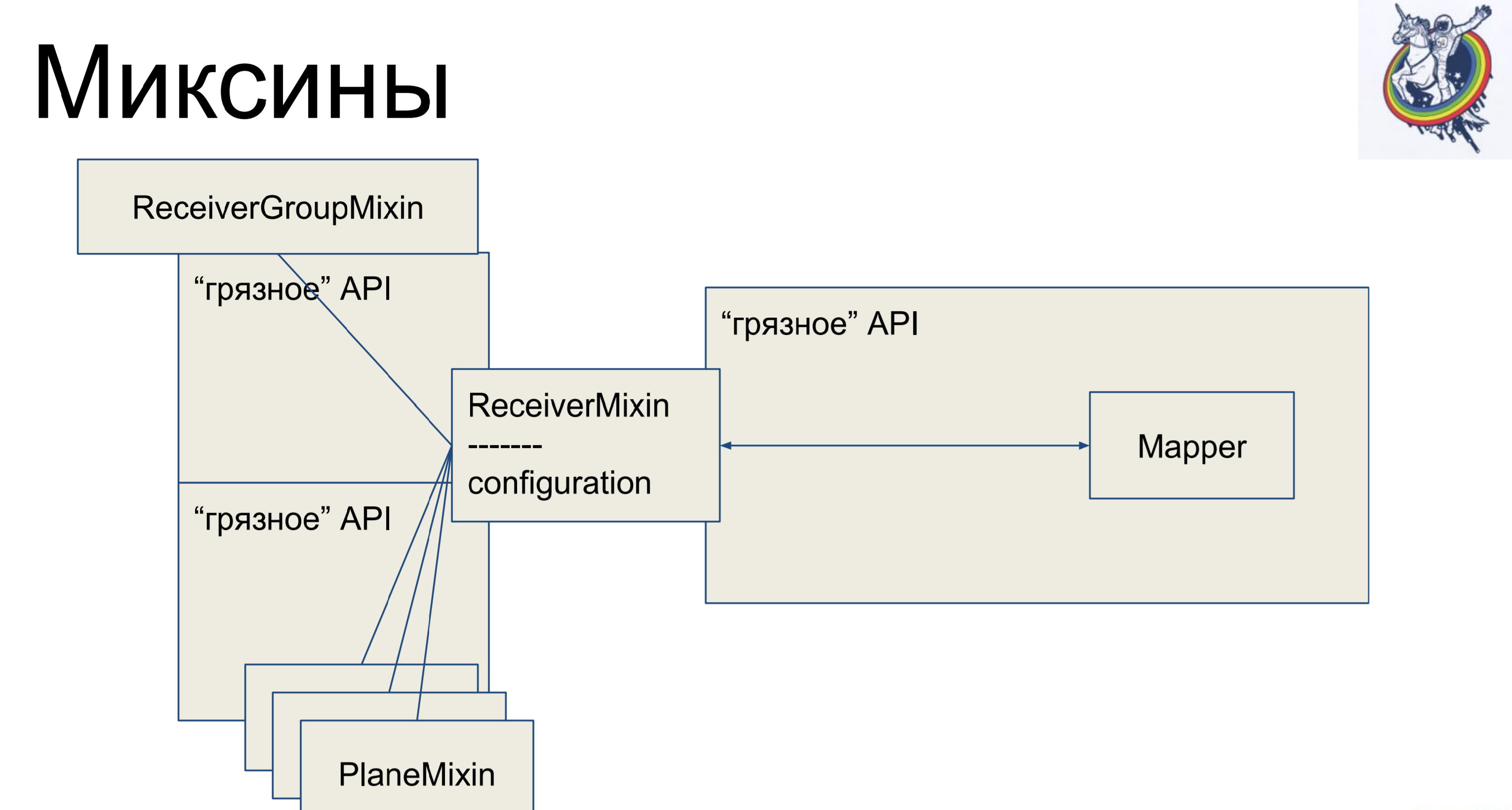
Mixins Tomamos la lógica comercial, nuevamente la eliminamos de nuestro mapeador, pero para que no haya mapeo nuevamente, heredaremos nuestro mapeador dentro de la alquimia de nuestro mixin. ¿Por qué no al revés? Esto no funcionará en la alquimia, ella jurará y dirá: "Tienes dos clases diferentes que se refieren a una tableta, no hay polformismo, ve desde aquí". Y así, es posible.
Por lo tanto, tenemos una descripción declarativa en el mapeador, que se hereda del mixin y recibe toda la lógica de negocios. Muy comodo Y el resto de las clases son exactamente iguales. Parece - genial, todo está limpio. Pero hay una advertencia: las conexiones y los relés permanecen dentro de la alquimia, y cuando, por ejemplo, nos unimos a través de una tabla secundaria de placas intermedias, entonces el mapeador de esta placa estará de alguna manera presente en el código del cliente, lo que no es muy hermoso.
La alquimia no habría sido un marco tan bueno y famoso si no me hubiera dado la oportunidad de luchar contra esto.

¿Cómo se ve un mixin? Tiene lógica de negocios, mapeadores por separado, una descripción declarativa de la placa. Las conexiones permanecen dentro de la alquimia, pero la lógica de negocios está separada.
¿Cómo se ve el esquema general?
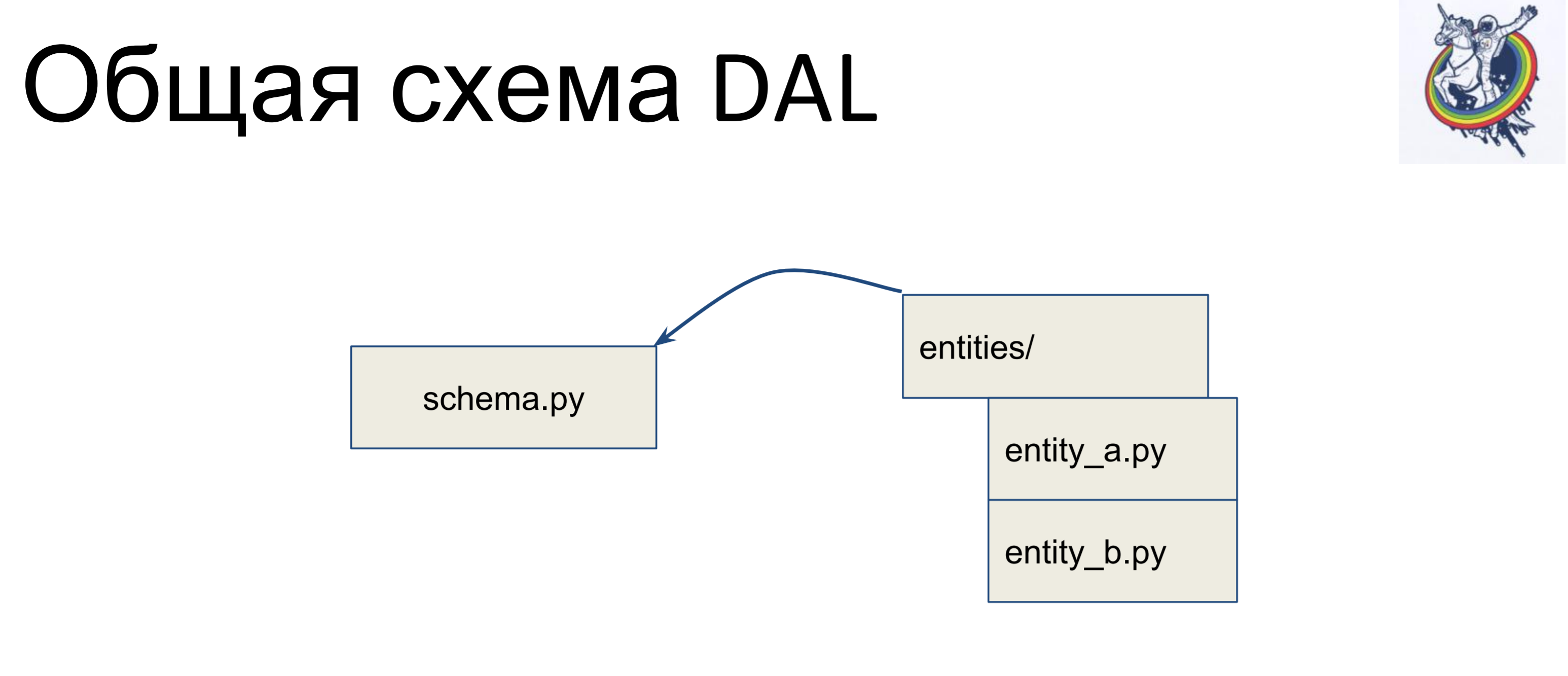
Tenemos un archivo con un esquema en el que se recopilan todas nuestras clases declarativas, llamémoslo schema.py. Y tenemos entidades en lógica de negocios, por separado. Y, estas entidades se heredan dentro del archivo de esquema: escribimos una clase separada para cada entidad y la heredamos en el esquema. Por lo tanto, la lógica empresarial se encuentra en un montón, el esquema en otro y se pueden cambiar de forma independiente.
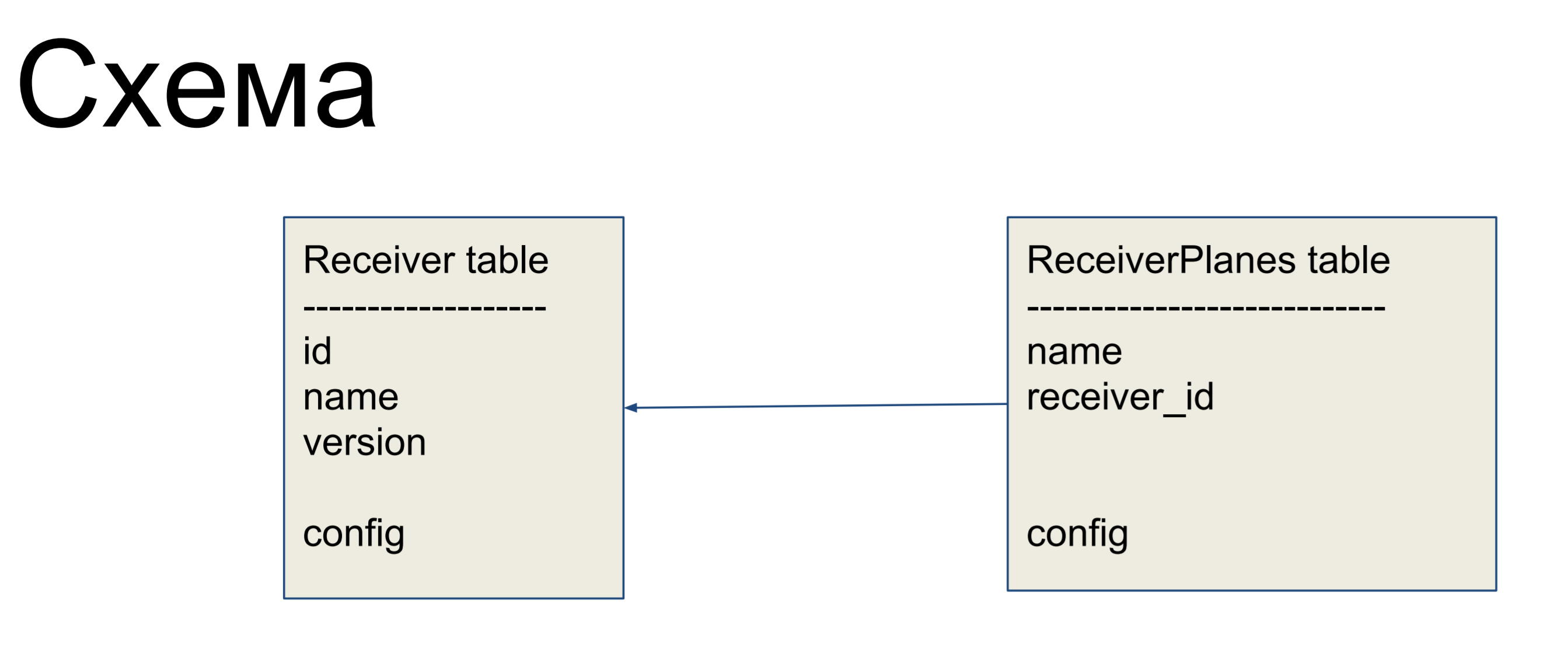
Como ejemplo de mejora, consideraremos un esquema simple de dos etiquetas: receptores (tabla de receptores) y segmentos de la configuración (tabla de planos de receptores). Muchos segmentos de configuración uno a uno están asociados con la etiqueta del receptor. No hay nada particularmente complicado.
Para ocultar las relaciones dentro de la interfaz "sucia" de la alquimia, utilizamos relaciones y colecciones.

Nos permiten ocultar nuestros mapeadores del código del cliente.

En particular, dos colecciones muy útiles son association_proxy y attribute_mapped_collection. Los usamos juntos. Cómo funciona la relación clásica en alquimia: tenemos una relación: esta es una cierta colección, lista, mapeadores. Los mapeadores son objetos de relación de extremo lejano. Attribute_mapped_collection le permite reemplazar esta lista con un dict, cuyas claves serán algunos de los atributos de los mapeadores, y los valores son los propios mapeadores.
Este es el primer paso.
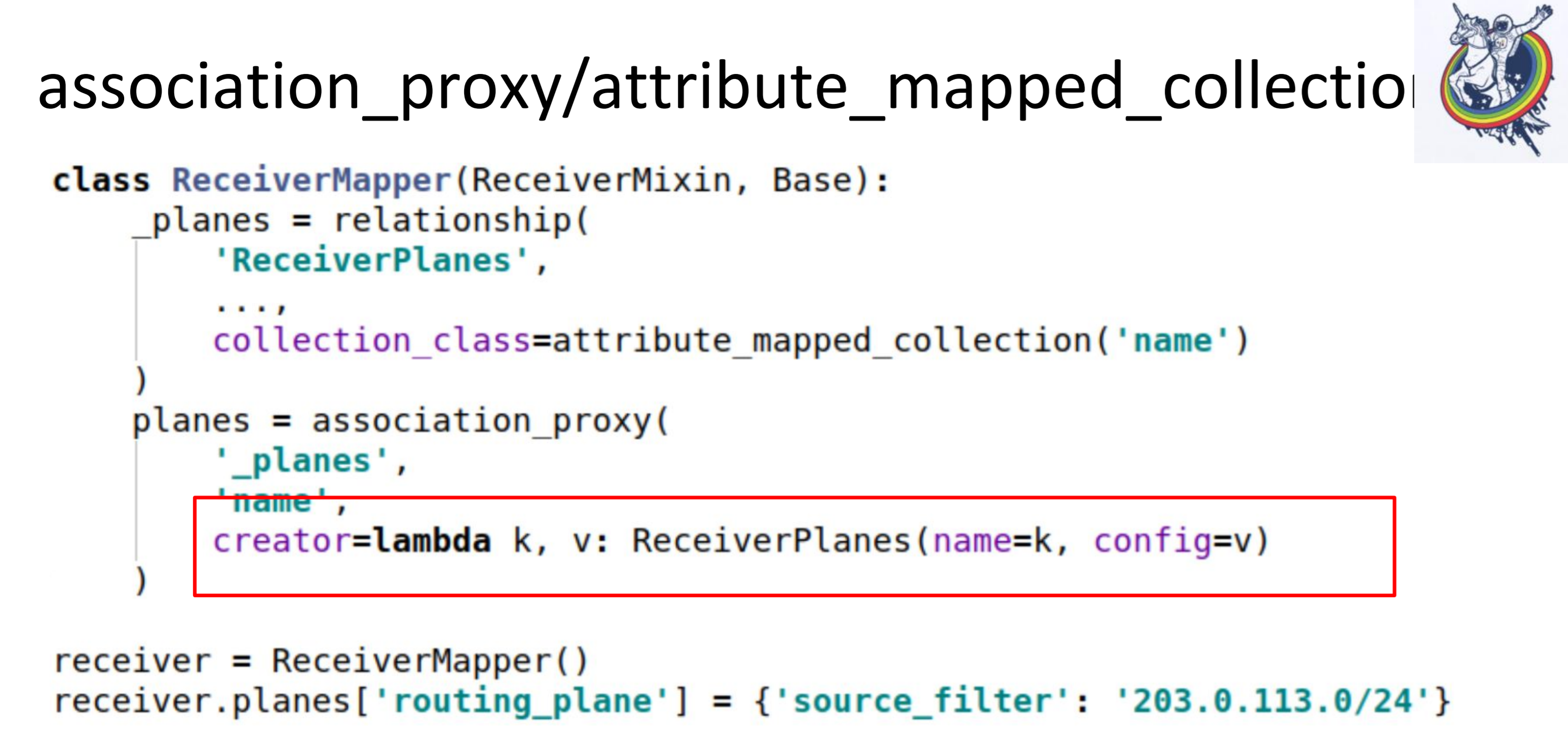
El segundo paso, hacemos asociación_proxy sobre esta relación. Nos permite no pasar el mapeador a la colección, sino pasar algún valor que luego se utilizará para inicializar nuestro mapeador, ReceiverPlanes.
Aquí tenemos lambda, en el que pasamos la clave y el valor. La clave se convierte en el nombre del segmento de configuración y el valor en el valor del segmento de configuración. Como resultado, en el código del cliente, todo se ve así.

Acabamos de poner algún tipo de dictado en algún tipo de diccionario. Todo funciona: sin mapeadores, sin alquimia, sin bases de datos.
Es cierto que hay dificultades.

Si asignamos valores diferentes, o incluso uno, a la misma clave dos veces, se llama lambda para cada elemento del conjunto, se crea un objeto, un mapeador. Y, dependiendo de cómo esté estructurado el esquema, esto puede llevar a varias consecuencias, desde "solo violaciones de las constantes" hasta consecuencias impredecibles. Por ejemplo, eliminó un objeto de la colección, pero aún permaneció allí: eliminó solo uno. Cuando comencé, mataba mucho tiempo en esas cosas.
Y una pequeña sincronización implícita. Association_proxy y attribute_mapped_collection puede retrasarse un poco: cuando creamos un objeto de mapeador, se agrega a la base de datos, pero aún no está presente en el atributo de colección. Aparecerá allí solo cuando el atributo caduque en esta sesión. Cuando caduque, se producirá una nueva sincronización con la base de datos y llegará allí.
Para superar esto, utilizamos nuestras propias colecciones, auto escritas. Esto ni siquiera es alquimia: simplemente puede crear su propia colección para superar todo esto.
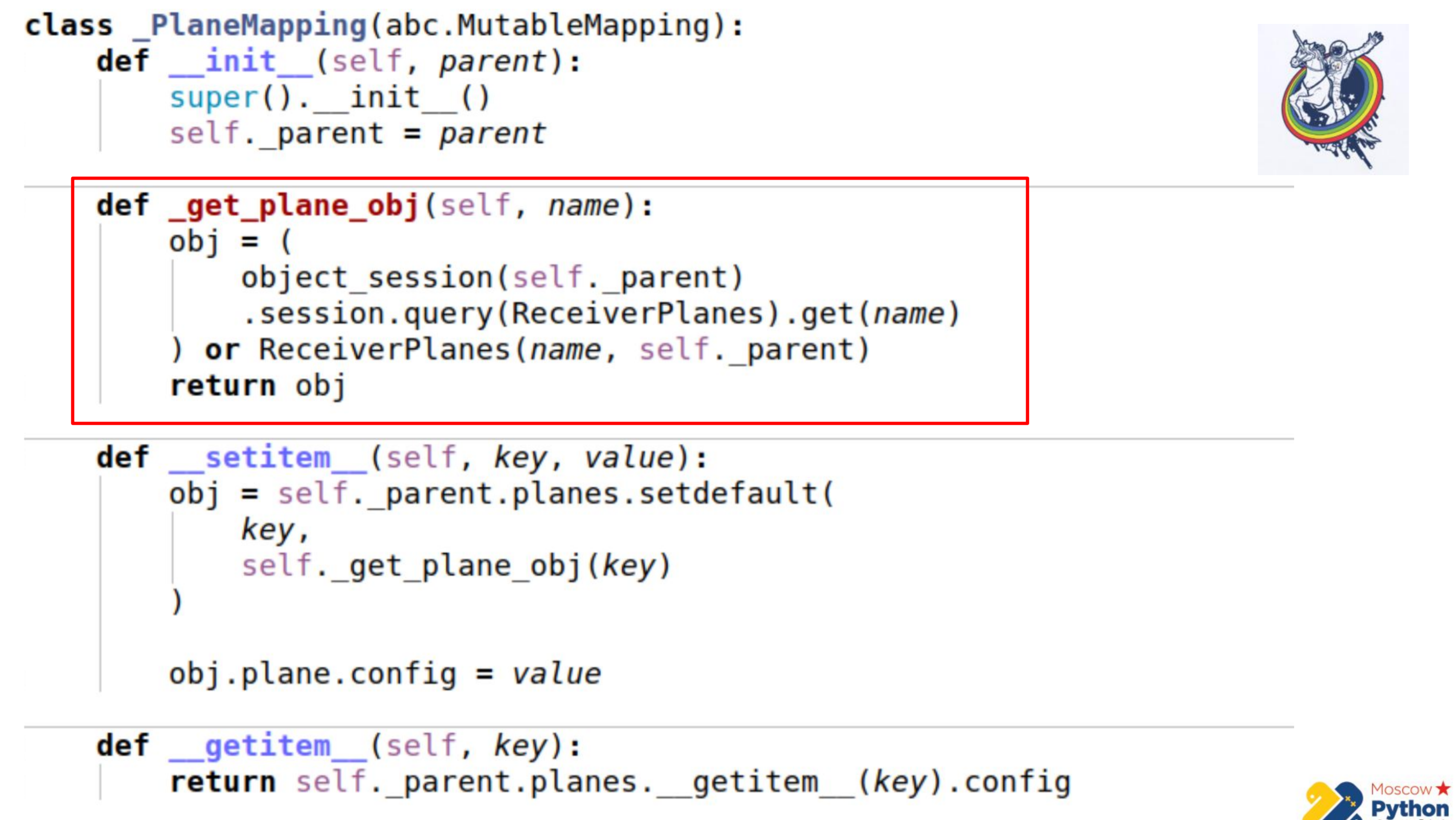
Hay más código y se resalta la parte más importante. Tenemos una cierta colección que hereda del mapeo mutable: esta es una sentencia, en cuyas claves puede cambiar los valores. Y hay un método _get_plane_obj: para obtener el objeto de segmento de configuración.
Aquí hacemos cosas simples: intentamos obtenerlo por nombre, por alguna clave primaria y, si no es así, creamos y devolvemos este objeto.
A continuación, redefinimos solo dos métodos: __setitem__ y __getitem__
En __setitem__, ponemos estos objetos en nuestra colección, en una relación. Lo único es que asignamos valor al final. Por lo tanto, implementamos el mismo mecanismo que association_proxy: pasa el valor, dict allí, y se asigna al atributo correspondiente.
__getitem__ realiza la manipulación inversa. Recibe por clave algún objeto del relé y devuelve su atributo. También hay un pequeño inconveniente aquí: si almacena en caché la colección dentro de nuestro mapeo, es posible que se salga un poco de la sincronización. Porque cuando el atributo de la colección caduca en alquimia, la colección se reemplaza por otra, después de la caducidad. Por lo tanto, podemos mantener la referencia a la colección anterior y no saber si la anterior ha expirado y ya ha aparecido una nueva. Por lo tanto, en la última parte, vamos directamente a la instancia de alquimia, nuevamente obtenemos la colección a través de __getattr__ y hacemos __getitem__ con ella. Es decir, no podemos almacenar en caché la colección Planes aquí.
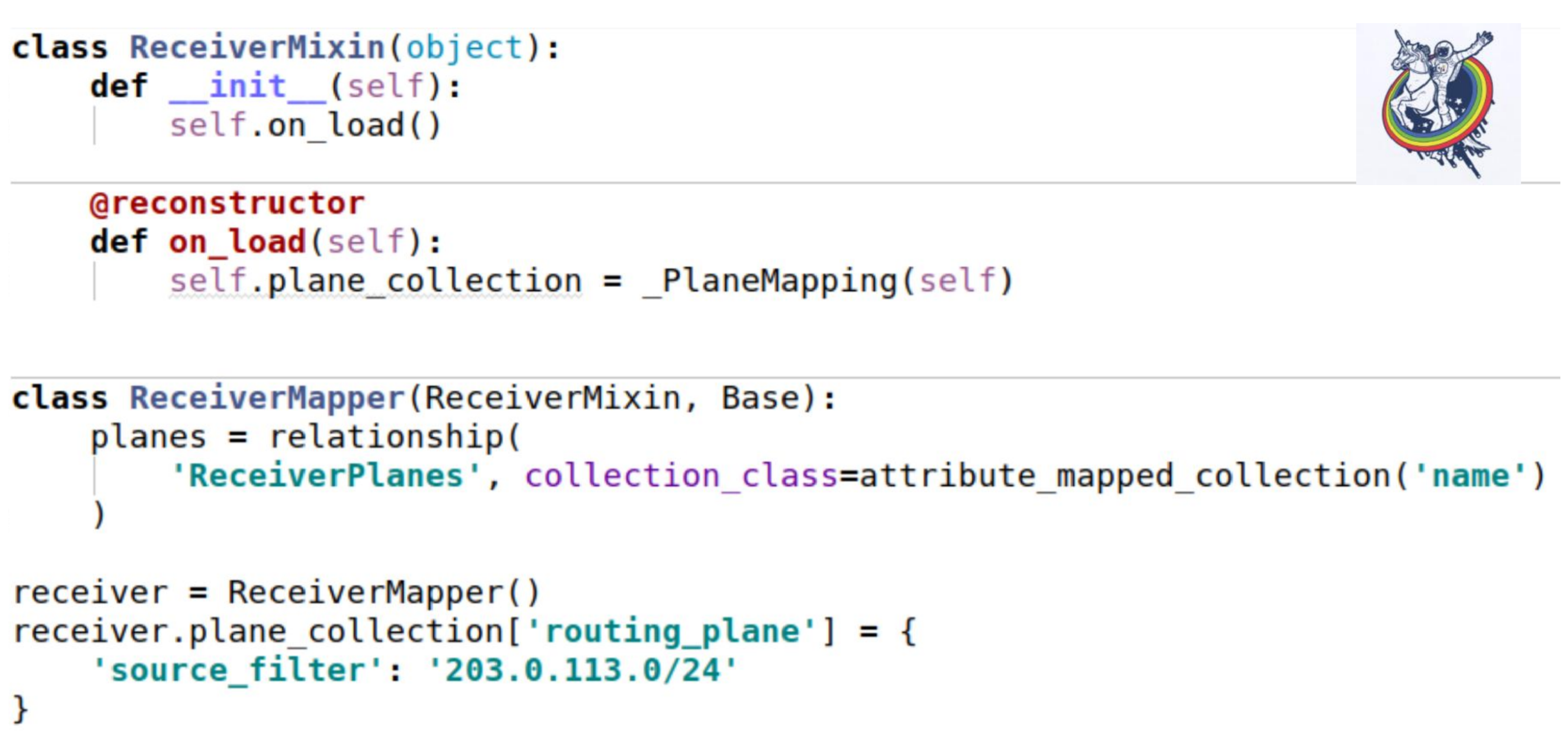
¿Cómo afecta esta colección a nuestros mixins? Como de costumbre, configure un atributo de colección. El único lugar interesante es que cuando cargamos una instancia de la base de datos, no se llama al método __init__. Todos los atributos se sustituyen ex post.
Alchemy ofrece un decorador de reconstrucción estándar, que le permite marcar algún método como llamado después de cargar un objeto desde la base de datos. Y justo en el momento del arranque tenemos que inicializar nuestra colección. El yo es solo esa instancia. El uso es exactamente el mismo que en el ejemplo anterior.
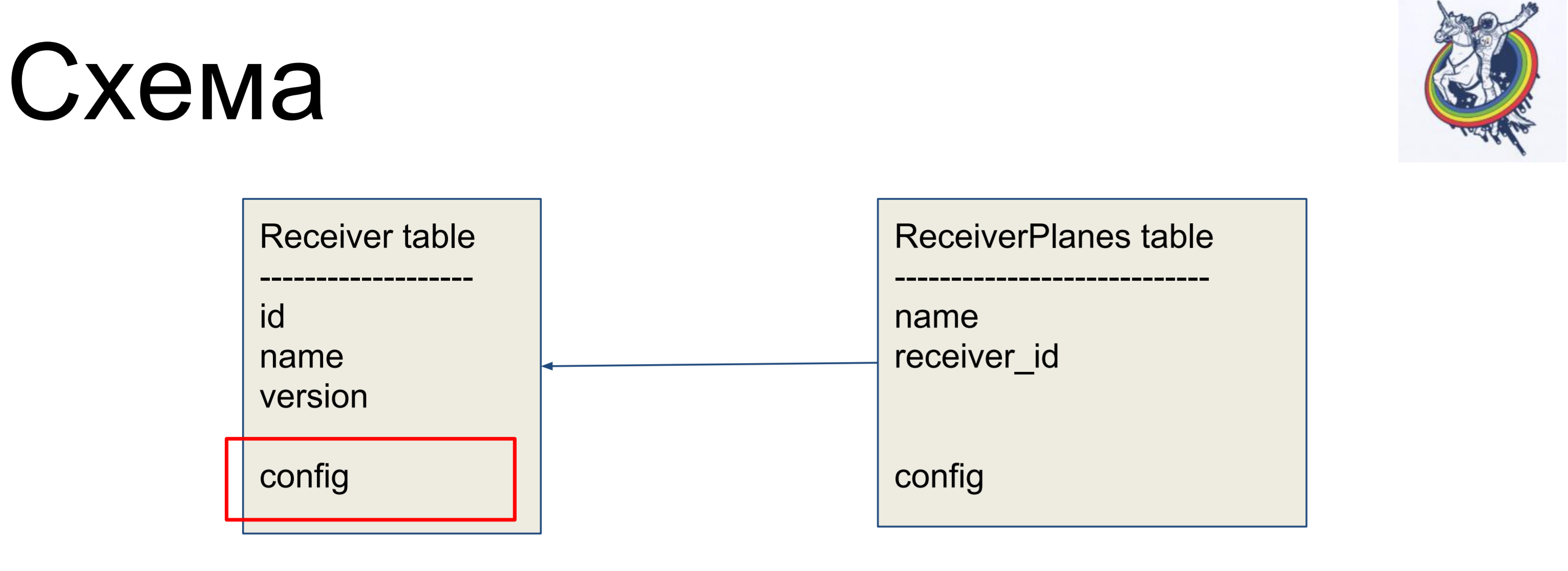
Pero en nuestro esquema, los oídos de la base de datos todavía son visibles: esta es la configuración. ¿Qué tipo de configuración? ¿Es varchar o es blob? De hecho, el cliente no está interesado.
Debe trabajar con entidades abstractas de su nivel. Para esto, la alquimia proporciona una decoración tipo. Un simple ejemplo. Nuestra base de datos almacena IPAddress como varchar. Usamos la clase TypeDecorator, que es parte de la alquimia, que permite, en primer lugar, indicar qué tipo de base de datos subyacente se usará para este tipo y, en segundo lugar, determinar dos parámetros: process_bind_param que convierte el valor al tipo de base de datos y process_result_value cuando valoramos desde el tipo de base de datos, convertir a un objeto Python.El atributo de la dirección toma el tipo de dirección IP de tipo python. Y podemos llamar a métodos de este tipo y asignarle objetos de este tipo, y todo funciona para nosotros. Y se almacena en la base de datos ... No sé qué se almacena, varchar (45), pero podemos reemplazar esa línea y se almacenará el blob. O si algún tipo nativo admite direcciones IP, puede usarlo.El código del cliente no depende de esto, no necesita ser reescrito.
Un simple ejemplo. Nuestra base de datos almacena IPAddress como varchar. Usamos la clase TypeDecorator, que es parte de la alquimia, que permite, en primer lugar, indicar qué tipo de base de datos subyacente se usará para este tipo y, en segundo lugar, determinar dos parámetros: process_bind_param que convierte el valor al tipo de base de datos y process_result_value cuando valoramos desde el tipo de base de datos, convertir a un objeto Python.El atributo de la dirección toma el tipo de dirección IP de tipo python. Y podemos llamar a métodos de este tipo y asignarle objetos de este tipo, y todo funciona para nosotros. Y se almacena en la base de datos ... No sé qué se almacena, varchar (45), pero podemos reemplazar esa línea y se almacenará el blob. O si algún tipo nativo admite direcciones IP, puede usarlo.El código del cliente no depende de esto, no necesita ser reescrito.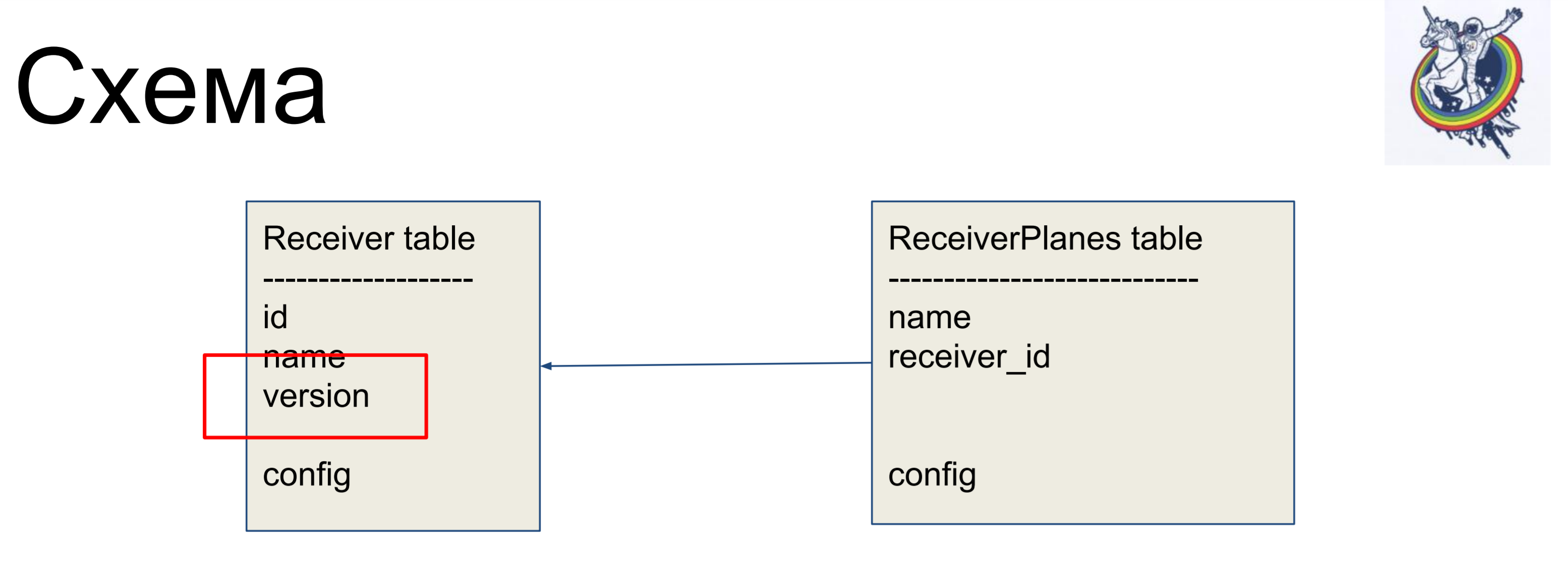 Otra cosa interesante es que tenemos una versión. Queremos que tan pronto como cambiemos nuestro objeto, la versión aumente de inmediato. Tenemos un contador de versiones, cambiamos el objeto; ha cambiado, la versión ha aumentado. Hacemos esto automáticamente para no olvidar.
Otra cosa interesante es que tenemos una versión. Queremos que tan pronto como cambiemos nuestro objeto, la versión aumente de inmediato. Tenemos un contador de versiones, cambiamos el objeto; ha cambiado, la versión ha aumentado. Hacemos esto automáticamente para no olvidar. Para esto, utilizamos eventos. Los eventos son eventos que ocurren en diferentes etapas de la vida de un mapeador y pueden activarse cuando los atributos cambian, cuando una entidad cambia de un estado a otro, por ejemplo, "creado", "guardado en la base de datos", "cargado de la base de datos", "eliminado"; y también - en eventos a nivel de sesión, antes de que el código sql se emita a la base de datos, antes de la confirmación, después de la confirmación y también después de la reversión.Alchemy nos permite asignar controladores para todos estos eventos, pero no se garantiza el orden en que se ejecutan los controladores para el mismo evento. Es decir, es específico, pero no se sabe cuál. Por lo tanto, si la orden de ejecución es importante para usted, entonces necesita hacer un mecanismo de registro.
Para esto, utilizamos eventos. Los eventos son eventos que ocurren en diferentes etapas de la vida de un mapeador y pueden activarse cuando los atributos cambian, cuando una entidad cambia de un estado a otro, por ejemplo, "creado", "guardado en la base de datos", "cargado de la base de datos", "eliminado"; y también - en eventos a nivel de sesión, antes de que el código sql se emita a la base de datos, antes de la confirmación, después de la confirmación y también después de la reversión.Alchemy nos permite asignar controladores para todos estos eventos, pero no se garantiza el orden en que se ejecutan los controladores para el mismo evento. Es decir, es específico, pero no se sabe cuál. Por lo tanto, si la orden de ejecución es importante para usted, entonces necesita hacer un mecanismo de registro.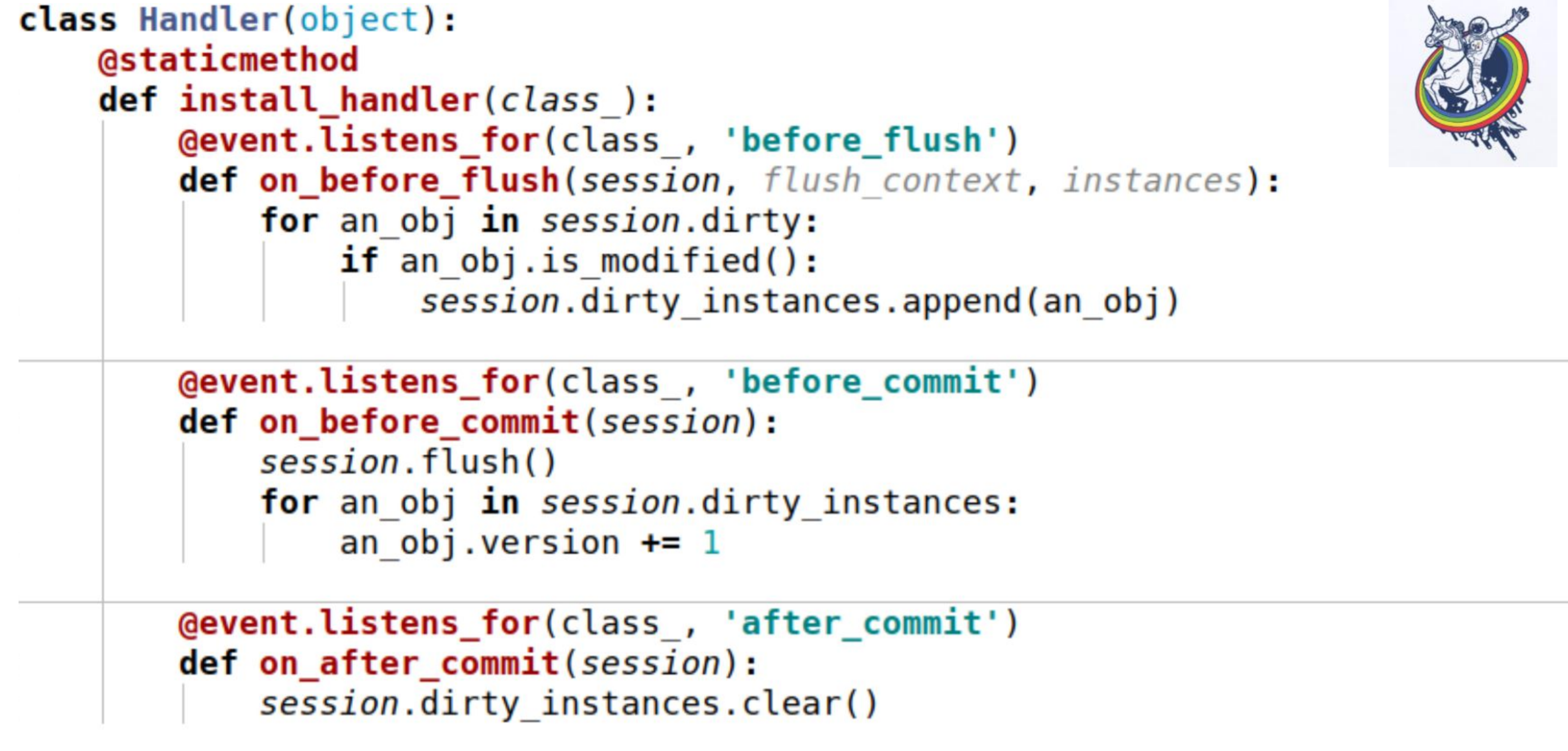 Aquí hay un ejemplo. Aquí se utilizan tres eventos:on_before_flush: antes de que el código sql se emita a la base de datos, revisamos todos los objetos que la alquimia marcó como sucios en esta sesión y verificamos si este objeto está modificado o no. ¿Por qué es esto necesario si la alquimia ya ha marcado todo? Alchemy marca un objeto sucio tan pronto como algún atributo ha cambiado. Si asignamos el mismo valor a este atributo que tenía, se marcará como sucio. Hay un método de sesión is_modified para esto: se usa internamente, no lo dibujé. Además, desde el punto de vista de nuestra semántica, desde el punto de vista de nuestra lógica empresarial, incluso si el atributo ha cambiado, el objeto puede permanecer sin modificaciones. Por ejemplo, hay una cierta lista en la que se intercambian dos elementos: desde el punto de vista de la alquimia, el atributo ha cambiado, pero no importa la lógica de negocios si, por ejemplo,algún tipoY, al final, llamamos a otro método específico para cada objeto para comprender si el objeto se modifica o no. Y los agregamos a una determinada variable asociada con la sesión que creamos nosotros mismos: esta es nuestra variable dirty_instances, en la que agregamos este objeto.El siguiente evento ocurre antes del commit - before_commit. Aquí también hay un pequeño inconveniente: si durante toda la transacción no tuvimos una sola descarga, entonces se llamará a la descarga antes de la confirmación; en mi caso, se llamó al controlador antes de la confirmación antes de la descarga.Como puede ver, lo que hicimos en el párrafo anterior puede no ayudarnos y session.dirty_instances estará vacío. Por lo tanto, dentro del manejador, nuevamente hacemos vaciado para que todos los manejadores sean llamados antes del vaciado y simplemente incrementen la versión en uno.after_commit, after_soft_rollback: después del commit, simplemente lo limpiamos para que no haya excesos la próxima vez.Por lo tanto, verá: este método install_handler instala controladores para tres eventos a la vez. Como clase, pasamos la sesión aquí, ya que este es un evento de su nivel.
Aquí hay un ejemplo. Aquí se utilizan tres eventos:on_before_flush: antes de que el código sql se emita a la base de datos, revisamos todos los objetos que la alquimia marcó como sucios en esta sesión y verificamos si este objeto está modificado o no. ¿Por qué es esto necesario si la alquimia ya ha marcado todo? Alchemy marca un objeto sucio tan pronto como algún atributo ha cambiado. Si asignamos el mismo valor a este atributo que tenía, se marcará como sucio. Hay un método de sesión is_modified para esto: se usa internamente, no lo dibujé. Además, desde el punto de vista de nuestra semántica, desde el punto de vista de nuestra lógica empresarial, incluso si el atributo ha cambiado, el objeto puede permanecer sin modificaciones. Por ejemplo, hay una cierta lista en la que se intercambian dos elementos: desde el punto de vista de la alquimia, el atributo ha cambiado, pero no importa la lógica de negocios si, por ejemplo,algún tipoY, al final, llamamos a otro método específico para cada objeto para comprender si el objeto se modifica o no. Y los agregamos a una determinada variable asociada con la sesión que creamos nosotros mismos: esta es nuestra variable dirty_instances, en la que agregamos este objeto.El siguiente evento ocurre antes del commit - before_commit. Aquí también hay un pequeño inconveniente: si durante toda la transacción no tuvimos una sola descarga, entonces se llamará a la descarga antes de la confirmación; en mi caso, se llamó al controlador antes de la confirmación antes de la descarga.Como puede ver, lo que hicimos en el párrafo anterior puede no ayudarnos y session.dirty_instances estará vacío. Por lo tanto, dentro del manejador, nuevamente hacemos vaciado para que todos los manejadores sean llamados antes del vaciado y simplemente incrementen la versión en uno.after_commit, after_soft_rollback: después del commit, simplemente lo limpiamos para que no haya excesos la próxima vez.Por lo tanto, verá: este método install_handler instala controladores para tres eventos a la vez. Como clase, pasamos la sesión aquí, ya que este es un evento de su nivel. Bueno aqui. Te recordaré lo que hemos logrado: velocidad de 30-40 segundos para equipos complejos y grandes. En absoluto, algunos se completaron en un segundo, otros en 200 milisegundos, como puede ver en RPS. Las consultas de bases de datos comenzaron a contarse en cientos.
Bueno aqui. Te recordaré lo que hemos logrado: velocidad de 30-40 segundos para equipos complejos y grandes. En absoluto, algunos se completaron en un segundo, otros en 200 milisegundos, como puede ver en RPS. Las consultas de bases de datos comenzaron a contarse en cientos. El resultado es un sistema bastante equilibrado. Hubo, sin embargo, una advertencia. Algunas solicitudes nos llegan en lotes, emisiones. Es decir, ¡llegan unas 30 solicitudes y cada una de ellas es así! (el orador muestra el pulgar)Si los procesamos un segundo a la vez, la última solicitud en la cola funcionará durante 30 segundos. El primero, los segundos dos, y así sucesivamente.
El resultado es un sistema bastante equilibrado. Hubo, sin embargo, una advertencia. Algunas solicitudes nos llegan en lotes, emisiones. Es decir, ¡llegan unas 30 solicitudes y cada una de ellas es así! (el orador muestra el pulgar)Si los procesamos un segundo a la vez, la última solicitud en la cola funcionará durante 30 segundos. El primero, los segundos dos, y así sucesivamente. Por lo tanto, aún necesitamos acelerar. Que haremosDe hecho, la alquimia tiene dos partes. El primero es una abstracción sobre una base de datos sql llamada SQLAlchemy Core. El segundo es ORM, el mapeo real entre la base de datos relacional y la representación del objeto. En consecuencia, el núcleo de alquimia es uno a uno coincide con sql: si conoce el último, entonces no tendrá problemas con el núcleo. Si no conoce sql, aprenda sql.Además, el núcleo representa la sobrecarga más pequeña. Prácticamente no hay bombeo: las consultas se generan utilizando el generador de consultas y luego se ejecutan. Los gastos generales sobre dbapi son mínimos.Podemos crear solicitudes de cualquier complejidad, de cualquier tipo, podemos optimizarlas para la tarea. Es decir, si en el caso general a ORM no le importa cómo se construye el esquema de la base de datos: hay alguna descripción de las tablas, genera algunas consultas, sin saber que en este caso será, por ejemplo, óptimo seleccionar desde aquí, en otro, desde allí, tal aplique el filtro, y allí, otro, luego aquí podemos hacer solicitudes para la tarea.La desventaja es que volvimos a la sincronización manual. Todos los eventos, retransmisiones: todo esto en el núcleo no funciona. Hicimos una selección, los objetos vinieron a nosotros, hicimos algo con ellos, luego actualizamos, insertamos ... necesita incrementar la versión con sus manos, verifique las constantes usted mismo. Core no permite que todo esto se haga convenientemente, a un alto nivel.Bueno, no vivimos el primer día.
Por lo tanto, aún necesitamos acelerar. Que haremosDe hecho, la alquimia tiene dos partes. El primero es una abstracción sobre una base de datos sql llamada SQLAlchemy Core. El segundo es ORM, el mapeo real entre la base de datos relacional y la representación del objeto. En consecuencia, el núcleo de alquimia es uno a uno coincide con sql: si conoce el último, entonces no tendrá problemas con el núcleo. Si no conoce sql, aprenda sql.Además, el núcleo representa la sobrecarga más pequeña. Prácticamente no hay bombeo: las consultas se generan utilizando el generador de consultas y luego se ejecutan. Los gastos generales sobre dbapi son mínimos.Podemos crear solicitudes de cualquier complejidad, de cualquier tipo, podemos optimizarlas para la tarea. Es decir, si en el caso general a ORM no le importa cómo se construye el esquema de la base de datos: hay alguna descripción de las tablas, genera algunas consultas, sin saber que en este caso será, por ejemplo, óptimo seleccionar desde aquí, en otro, desde allí, tal aplique el filtro, y allí, otro, luego aquí podemos hacer solicitudes para la tarea.La desventaja es que volvimos a la sincronización manual. Todos los eventos, retransmisiones: todo esto en el núcleo no funciona. Hicimos una selección, los objetos vinieron a nosotros, hicimos algo con ellos, luego actualizamos, insertamos ... necesita incrementar la versión con sus manos, verifique las constantes usted mismo. Core no permite que todo esto se haga convenientemente, a un alto nivel.Bueno, no vivimos el primer día. Un caso de uso simple. Cada asignador contiene internamente un objeto __table__, que se utiliza en el núcleo. A continuación, verá: tomamos la selección habitual, enumeramos las columnas, unimos dos placas, indicamos la izquierda y la derecha, indicamos en qué condición la unimos, bueno, por el gusto agregamos una orden de compra. Además, alimentamos esta solicitud generada en la sesión y nos la devuelve iterable, en la que los objetos tipo tap se indexan tanto por el nombre de la columna como por el número. El número corresponde al orden en que se enumeran en la selección.
Un caso de uso simple. Cada asignador contiene internamente un objeto __table__, que se utiliza en el núcleo. A continuación, verá: tomamos la selección habitual, enumeramos las columnas, unimos dos placas, indicamos la izquierda y la derecha, indicamos en qué condición la unimos, bueno, por el gusto agregamos una orden de compra. Además, alimentamos esta solicitud generada en la sesión y nos la devuelve iterable, en la que los objetos tipo tap se indexan tanto por el nombre de la columna como por el número. El número corresponde al orden en que se enumeran en la selección. Se ha vuelto mucho mejor. El rendimiento en el peor de los casos cayó a 2-4 segundos, la solicitud más compleja y más larga contenía 14 comandos y RPS 10-15. Es solido.
Se ha vuelto mucho mejor. El rendimiento en el peor de los casos cayó a 2-4 segundos, la solicitud más compleja y más larga contenía 14 comandos y RPS 10-15. Es solido. Lo que me gustaría decir en conclusión.No produzca entidades donde no sean necesarias, no atornille las suyas donde estén listas.Use SQLA ORM: esta es una herramienta muy conveniente que le permite rastrear eventos a un alto nivel, responder a varios eventos asociados con la base de datos, ocultar todos los oídos de la alquimia.Si todo lo demás falla, el rendimiento no es suficiente: use SQLA Core. Esto es aún mejor que usar SQL puro puro porque proporciona una abstracción relacional sobre la base de datos. Se escapa automáticamente de los parámetros, hace las carpetas correctamente, no importa qué base de datos se encuentre debajo, se puede cambiar y Core admite diferentes dialectos.
Lo que me gustaría decir en conclusión.No produzca entidades donde no sean necesarias, no atornille las suyas donde estén listas.Use SQLA ORM: esta es una herramienta muy conveniente que le permite rastrear eventos a un alto nivel, responder a varios eventos asociados con la base de datos, ocultar todos los oídos de la alquimia.Si todo lo demás falla, el rendimiento no es suficiente: use SQLA Core. Esto es aún mejor que usar SQL puro puro porque proporciona una abstracción relacional sobre la base de datos. Se escapa automáticamente de los parámetros, hace las carpetas correctamente, no importa qué base de datos se encuentre debajo, se puede cambiar y Core admite diferentes dialectos. Es muy conveniente.
Eso es todo lo que quería decirte hoy.