Los sistemas distribuidos se utilizan cuando existe una necesidad de escala horizontal para proporcionar indicadores de rendimiento incrementados de que un sistema de escala vertical no es capaz de proporcionar el dinero adecuado.
Al igual que la transición de un paradigma de un solo subproceso a un subproceso múltiple, la migración a un sistema distribuido requiere una especie de inmersión y comprensión de cómo funciona dentro, a lo que debe prestar atención.
Uno de los problemas que enfrenta una persona que quiere migrar un proyecto a un sistema distribuido o comenzar un proyecto en él es qué producto elegir.
Nosotros, como empresa que "se comió un perro" en el desarrollo de sistemas de este tipo, ayudamos a nuestros clientes a tomar decisiones informadas en relación con los sistemas de almacenamiento distribuido. También estamos lanzando una
serie de seminarios web para una audiencia más amplia que se centran en los principios básicos en un lenguaje simple, y cualesquiera preferencias alimentarias específicas ayudan a mapear características importantes para que sea más fácil elegir.
Este artículo se basa en nuestros materiales sobre consistencia y garantías de ACID en sistemas distribuidos.
¿Qué es y por qué se necesita?
"
La consistencia de los datos (a veces
la consistencia de los datos ) es
la consistencia de los datos entre sí, la integridad de los datos y la consistencia interna". (
Wikipedia )
La coherencia implica que, en cualquier momento, las aplicaciones pueden estar seguras de que están trabajando con la versión correcta y técnicamente relevante de los datos, y pueden confiar en ellas al tomar decisiones.
En los sistemas distribuidos, garantizar la coherencia es cada vez más difícil y costoso, porque surgen una serie de nuevos desafíos relacionados con el intercambio de red entre diferentes nodos, la posibilidad de falla de nodos individuales y, a menudo, la falta de una sola memoria que pueda servir para la verificación.
Por ejemplo, si tengo un sistema de 4 nodos: A, B, C y D, que sirve para transacciones bancarias, y los nodos C y D están separados de A y B (por ejemplo, debido a problemas de red), es muy posible que ahora no Tengo acceso a parte de la transacción. ¿Cómo actúo en esta situación? Diferentes sistemas toman diferentes enfoques.
En el nivel superior, hay 2 direcciones clave que se expresan en el teorema CAP.
"
El teorema CAP (también conocido como
teorema de Brewer ) es una declaración heurística de que en cualquier implementación de computación distribuida es posible proporcionar no más de dos de las siguientes tres propiedades:
- consistencia de datos (consistencia inglesa): en todos los nodos de computación en un punto en el tiempo, los datos no se contradicen entre sí;
- disponibilidad (disponibilidad ing.): cualquier solicitud a un sistema distribuido finaliza con una respuesta correcta, pero sin garantizar que las respuestas de todos los nodos del sistema coincidan;
- tolerancia de partición: dividir un sistema distribuido en varias secciones aisladas no genera una respuesta incorrecta de cada sección ".
(
Wikipedia )
Cuando el teorema CAP habla de consistencia, implica una definición bastante estricta, que incluye la linealización de registros y lecturas, y estipula solo consistencia al escribir valores individuales. (
Martin Kleppman )
El teorema de CAP dice que si queremos ser resistentes a los problemas de la red, en general debemos elegir sacrificar: consistencia o accesibilidad. También hay una versión extendida de este teorema: PACELC (
Wikipedia ), que además habla del hecho de que incluso en ausencia de problemas de red, debemos elegir entre velocidad de respuesta y consistencia.
Y aunque, a primera vista, nativo del mundo de los DBMS clásicos, parece que la elección es obvia y la consistencia es lo más importante que tenemos, esto está lejos de ser siempre el caso, lo que ilustra claramente el crecimiento explosivo de varios DBMS NoSQL que hicieron una elección diferente y A pesar de esto, obtuvieron una gran base de usuarios. Apache Cassandra con su famosa consistencia eventual es un buen ejemplo.
Todo esto se debe al hecho de que esta es una
opción que implica que sacrificamos algo, y no siempre estamos listos para sacrificarlo.
A menudo, el problema de consistencia en los sistemas distribuidos se resuelve simplemente abandonando esta consistencia.
Pero es necesario e importante comprender cuándo es aceptable el rechazo de esta coherencia y cuándo es un requisito comercial crítico.
Por ejemplo, si diseño un componente que es responsable del almacenamiento de sesiones de usuario, aquí, lo más probable, la consistencia no es tan importante para mí, y la pérdida de datos no es crítica si ocurre solo en casos problemáticos, muy raramente. Lo peor que sucederá es que el usuario necesitará iniciar sesión, y para muchas empresas esto tendrá poco efecto en su desempeño financiero.
Si analizo el flujo de datos de los sensores, en muchos casos no es crítico para mí perder parte de los datos y obtener un muestreo por un corto período de tiempo, especialmente si finalmente veo los datos.
Pero si hago un sistema bancario, la consistencia de las transacciones en efectivo es crítica para mi negocio. Si acumulé una multa en el préstamo de un cliente debido al hecho de que simplemente no vi el pago realizado a tiempo, aunque él estaba en el sistema, esto es muy, muy malo. Además, si el cliente puede retirar todo el dinero de mi tarjeta de crédito varias veces, porque tuve problemas de red en el momento de la transacción, y la información de retiro no llegó a parte de mi grupo.
Si realiza una compra costosa en una tienda en línea, no desea que se olvide su pedido, a pesar del informe de éxito en la página web.
Pero si opta por la coherencia, sacrifica la accesibilidad. Y a menudo esto se espera, lo más probable es que te hayas topado con esto personalmente más de una vez.
Es mejor si la cesta de la tienda en línea dice "intente más tarde, un DBMS distribuido no está disponible" que si informa sobre el éxito y olvida el pedido. Es mejor obtener un rechazo en una transacción debido a la falta de disponibilidad de los servicios del banco que un golpe al éxito y luego los procedimientos con el banco debido al hecho de que olvidó que usted pagó el préstamo.
Finalmente, si observamos el teorema PACELC extendido, entonces entendemos que incluso en el caso del funcionamiento regular del sistema, al elegir la consistencia, podemos sacrificar bajas latencias, obteniendo un nivel potencialmente más bajo de rendimiento máximo.
Por lo tanto, respondiendo a la pregunta "¿por qué es esto necesario?": Es necesario si es fundamental para su tarea tener datos actualizados y consistentes, y la alternativa le traerá pérdidas significativas mayores que la indisponibilidad temporal del servicio durante el período del incidente o su menor rendimiento.
¿Cómo proporcionar esto?
En consecuencia, la primera decisión que debe tomar es dónde se encuentra en el teorema CAP, si desea coherencia o disponibilidad en caso de un incidente.
A continuación, debe comprender en qué nivel desea realizar los cambios. Quizás solo tenga suficientes registros atómicos que afecten a un solo objeto, ya que MongoDB pudo y pudo (ahora lo extiende con soporte adicional para transacciones completas). Permítame recordarle que el teorema CAP no dice nada sobre la consistencia de las operaciones de escritura que involucran múltiples objetos: el sistema bien puede ser CP (es decir, prefiere la consistencia de accesibilidad) y al mismo tiempo proporcionar solo registros atómicos únicos.
Si esto no es suficiente para usted, comenzamos a abordar el concepto de transacciones ACID distribuidas completas.
Observo que incluso cuando nos mudamos al valiente y nuevo mundo de las transacciones de ACID distribuidas, a menudo tenemos que sacrificar algo. Por ejemplo, varios sistemas de almacenamiento distribuido tienen transacciones distribuidas, pero solo dentro de una única partición. O, por ejemplo, el sistema puede no admitir la parte "I" en el nivel que necesita, sin aislamiento o con un número insuficiente de niveles de aislamiento.
Estas restricciones a menudo se hicieron por alguna razón: ya sea para simplificar la implementación o, por ejemplo, para mejorar el rendimiento o por otra cosa. Son suficientes para una gran cantidad de casos, por lo que no debe considerarlos por sí solos.
Debe comprender si estas restricciones son un problema para su escenario específico. Si no, tiene más opciones y puede dar más peso, por ejemplo, a los indicadores de rendimiento o la capacidad del sistema para proporcionar tolerancia a desastres, etc. Finalmente, no debemos olvidar que en varios sistemas estos parámetros se pueden ajustar hasta el punto de que el sistema puede ser CP o AP dependiendo de la configuración.
Si nuestro producto pretende ser CP, entonces generalmente tiene un enfoque de quórum para la selección de datos o nodos dedicados que son los principales propietarios de los registros, todos los cambios de datos pasan a través de ellos y, en caso de problemas de red, si estos nodos maestros no pueden proporcionar respuesta, se cree que los datos, en principio, no pueden obtenerse, o arbitraje, cuando un componente externo altamente accesible (por ejemplo, el clúster ZooKeeper) puede decir cuál de los segmentos del clúster es el principal, contiene la versión actual de los datos y puede atender eficientemente la solicitud s.
Finalmente, si estamos interesados no solo en el CP, sino también en el soporte de transacciones ACID distribuidas completas, a menudo se usa una sola fuente de verdad, por ejemplo, el almacenamiento centralizado en disco, donde nuestros nodos, de hecho, actúan solo como cachés, que pueden desactivarse en tiempo de confirmación o se aplica el protocolo de confirmación multifase.
El primer enfoque de unidad única también simplifica la implementación, proporciona bajas latencias en las transacciones distribuidas, pero intercambia a cambio de una escalabilidad muy limitada en cargas con grandes volúmenes de grabación.
El segundo enfoque brinda mucha más libertad en el escalado y, a su vez, se divide en protocolos de confirmación de dos fases (
Wikipedia ) y trifásicos (
Wikipedia ).
Considere una confirmación de dos fases que usa, por ejemplo, Apache Ignite.
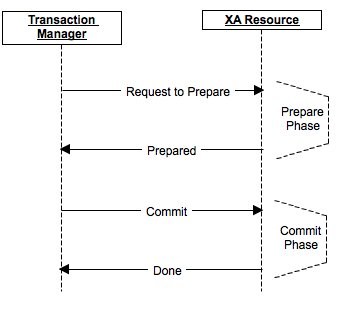

El procedimiento de compromiso se divide en 2 fases: preparación y compromiso.
En la fase de preparación, se prepara un mensaje sobre la preparación para el compromiso, y cada participante, si es necesario, realiza un bloqueo, realiza todas las operaciones hasta el compromiso real e incluye el envío, y envía la preparación a sus réplicas, si el producto lo asume. Si al menos uno de los participantes respondió con una negativa por algún motivo o resultó no estar disponible, los datos no cambiaron realmente, no hubo compromiso. Los participantes revierten los cambios, liberan bloqueos y vuelven a su estado original.
En la fase de confirmación, la ejecución real de la confirmación se envía a los nodos del clúster. Si por alguna razón algunos de los nodos no estaban disponibles o respondieron con un error, entonces para ese momento los datos se ingresaron en su redo-log (ya que la preparación fue exitosa), y la confirmación en cualquier caso puede completarse al menos en un estado pendiente.
Finalmente, si el coordinador falla, en la etapa de preparación se cancelará la confirmación, en la etapa de confirmación se puede seleccionar un nuevo coordinador, y si todos los nodos han completado la preparación, puede verificar y asegurarse de que la etapa de confirmación se haya completado.
Los diferentes productos tienen sus propias características de implementación y optimización. Entonces, por ejemplo, algunos productos pueden en algunos casos reducir un compromiso de 2 fases a un compromiso de 1 fase, ganando significativamente en rendimiento.
Conclusiones
Conclusión clave: los sistemas de almacenamiento distribuido son un mercado bastante desarrollado, y los productos en él pueden proporcionar una alta consistencia de datos.
Además, los productos de esta categoría se ubican en diferentes puntos de la escala de consistencia, desde productos totalmente AP sin ninguna transaccionalidad hasta productos CP que además proporcionan transacciones ACID completas. Algunos productos se pueden configurar de una forma u otra.
Cuando elige lo que necesita, debe tener en cuenta las necesidades de su caso y comprender bien qué sacrificios y compromisos está dispuesto a hacer, porque nada sucede de forma gratuita, y al elegir uno, lo más probable es que rechace otra cosa.
Al evaluar productos desde este lado, vale la pena prestar atención a lo siguiente:
- donde están en el teorema CAP;
- ¿Soportan transacciones distribuidas de ACID?
- qué restricciones imponen a las transacciones distribuidas (por ejemplo, solo dentro de una única partición, etc.);
- Conveniencia y eficiencia del uso de transacciones distribuidas, su integración en otros componentes del producto.