[parte 2 de 2]
[parte 1 de 2]

Como lo hicimos
Decidimos cambiar a GCP para mejorar el rendimiento de la aplicación, al tiempo que aumentamos la escala, pero sin costos significativos. Todo el proceso tomó más de 2 meses. Para resolver este problema, hemos formado un grupo especial de ingenieros.
En esta publicación, hablaremos sobre el enfoque elegido y su implementación, así como sobre cómo logramos alcanzar el objetivo principal: llevar a cabo este proceso de la mejor manera posible y transferir toda la infraestructura a Google Cloud Platform, sin comprometer la calidad del servicio al usuario.
Planificacion
- Se ha preparado una lista de verificación detallada que identifica cada posible paso. Se ha creado un diagrama de flujo para describir la secuencia.
- Se ha desarrollado un plan de reinicio que nosotros, en todo caso, podríamos usar.
Algunas sesiones de lluvia de ideas, y hemos identificado el enfoque más comprensible y más simple para implementar el esquema activo-activo. Consiste en el hecho de que un pequeño conjunto de usuarios está alojado en una nube y el resto en otra. Sin embargo, este enfoque causó problemas, especialmente en el lado del cliente (relacionado con la administración de DNS) y provocó demoras en la replicación de la base de datos. Debido a esto, era casi imposible implementarlo de manera segura. El método obvio no proporcionó la solución necesaria, y tuvimos que desarrollar una estrategia especializada.
Con base en el diagrama de dependencia y los requisitos de seguridad operacional, dividimos los servicios de infraestructura en 9 módulos.
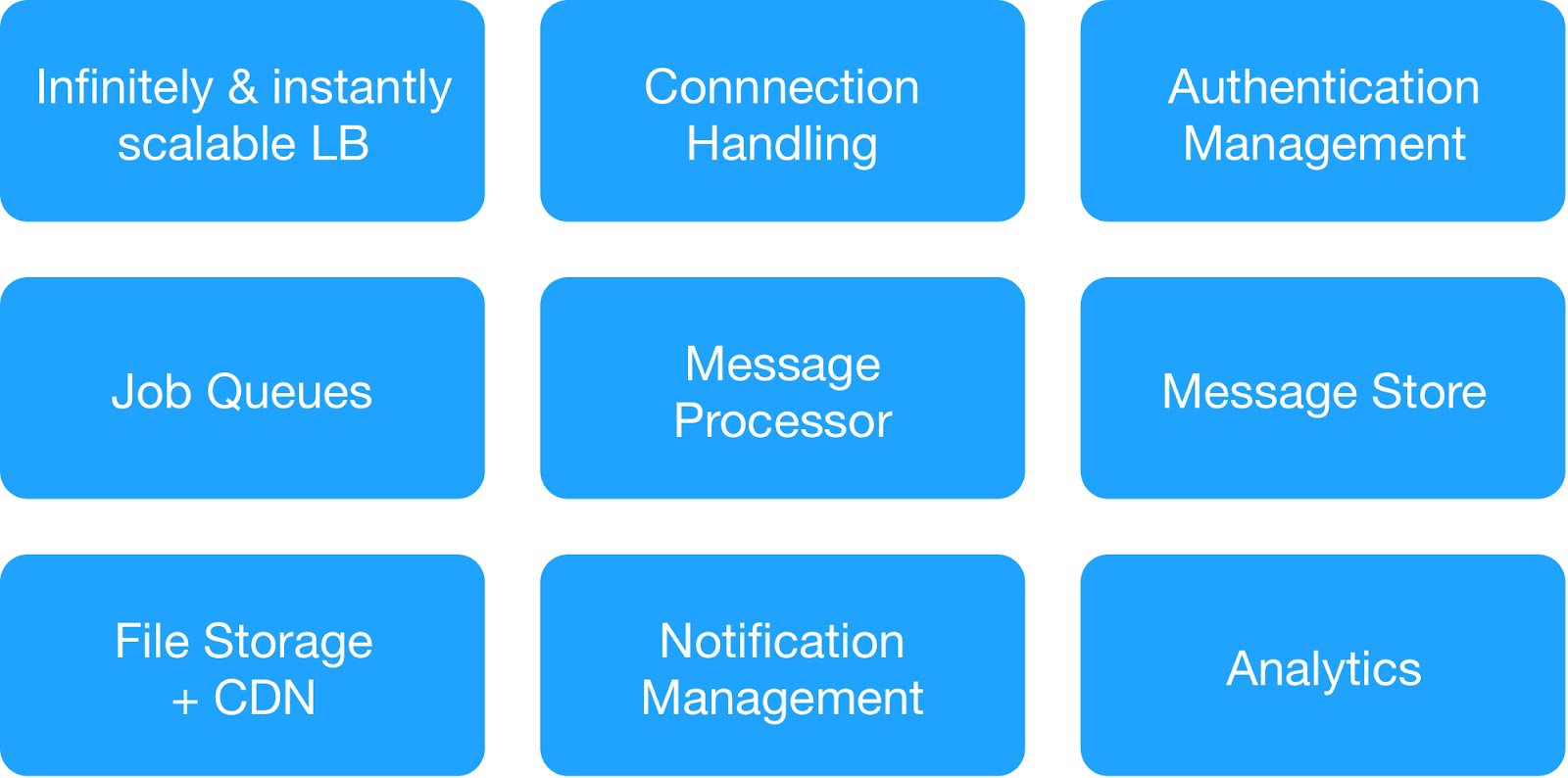
(Módulos básicos para desplegar infraestructura de alojamiento)
Cada grupo de infraestructura gestionó servicios internos y externos comunes.
Service Servicio de mensajería de infraestructura : MQTT, HTTPs, Thrift, servidor Gunicorn, módulo de colas, cliente Async, servidor Jetty, clúster Kafka.
Services Servicios de almacenamiento de datos : clúster distribuido MongoDB, Redis, Cassandra, Hbase, MySQL y MongoDB.
Service Servicio de análisis de infraestructura : clúster Kafka, clúster de almacén de datos (HDFS, HIVE).
Preparándose para un día significativo:
✓ Un plan detallado para cambiar a GCP para cada servicio: secuencia, almacén de datos, plan de reinicio.
✓ Redes de proyectos cruzados (VPC de nube privada virtual compartida [XPN]) en GCP para aislar varias partes de la infraestructura, optimizar la administración, mejorar la seguridad y la conectividad.
✓ Varios túneles VPN entre el GCP y la nube privada virtual (VPC) en ejecución para simplificar la transferencia de grandes cantidades de datos a través de la red durante el proceso de replicación, así como para el posible despliegue posterior de un sistema paralelo.
✓ Automatice la instalación y configuración de toda la pila utilizando el sistema Chef.
✓ Scripts y herramientas de automatización para implementación, monitoreo, registro, etc.
✓ Configure todas las subredes requeridas y las reglas de firewall administrado para la secuencia del sistema.
✓ Replicación en múltiples centros de datos (Multi-DC) para todos los sistemas de almacenamiento.
✓ Configurar equilibradores de carga (GLB / ILB) y grupos de instancias administradas (MIG).
✓ Scripts y código para transferir el contenedor de almacenamiento de objetos al GCP Cloud Storage con puntos de control.
Pronto, cumplimos con todos los requisitos previos necesarios y preparamos una lista de verificación de elementos para mover la infraestructura a la plataforma GCP. Después de numerosas discusiones, además de considerar la cantidad de servicios y sus diagramas de dependencia, decidimos transferir la infraestructura de la nube a GCP en tres noches para cubrir todos los servicios del lado del servidor y de almacenamiento de datos.
Transición
Estrategia de transferencia de equilibrador de carga:
Reemplazamos el clúster administrado HAProxy utilizado anteriormente con un equilibrador de carga global para procesar decenas de millones de conexiones de usuario activas diariamente.
⊹ Etapa 1:
- Los MIG se crean con reglas de reenvío de paquetes para reenviar todo el tráfico a las direcciones IP MQTT en la nube existente.
- Se ha creado un equilibrador de proxy SSL y TCP con MIG como parte del servidor.
- Para MIG, HAProxy se inicia con servidores MQTT como parte del servidor.
- En DNS, una política de enrutamiento basada en el peso ha agregado una dirección IP GLB externa.
Las conexiones de usuario se implementan gradualmente mientras se rastrea su rendimiento.
⊹ Paso 2: transición de hitos, comenzar a implementar servicios en GCP.
⊹ Etapa 3: la etapa final de la transición, todos los servicios se transfieren al GCP.
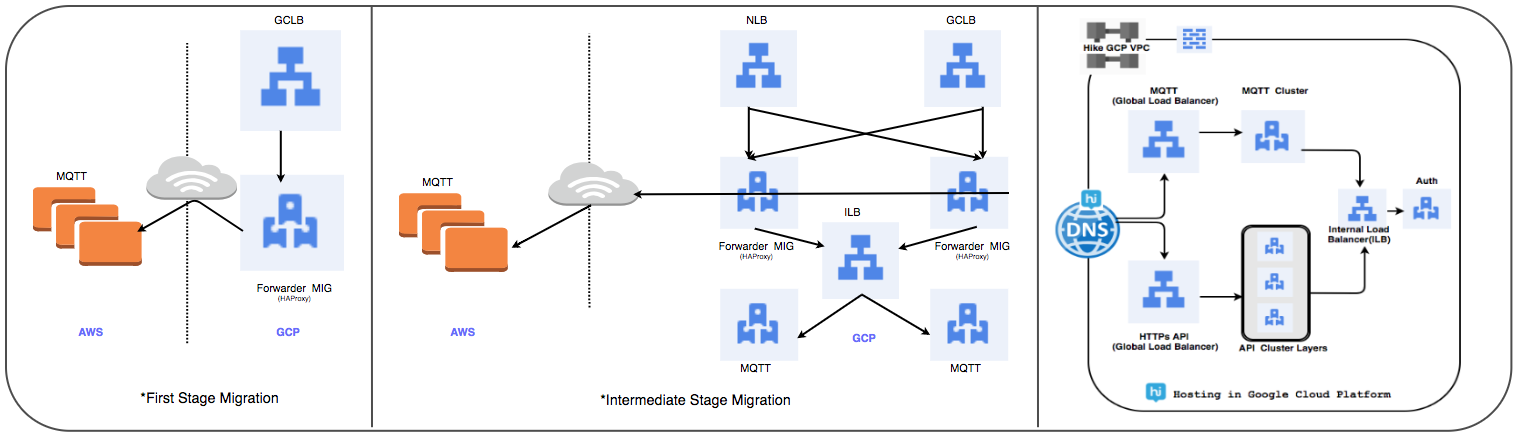
(Etapas de transferencia del equilibrador de carga)
En esta etapa, todo funcionó como se esperaba. Pronto, llegó el momento de implementar varios servicios HTTP internos en GCP con enrutamiento, dado el peso de los coeficientes. Seguimos de cerca todos los indicadores. Cuando comenzamos a aumentar gradualmente el tráfico, el día antes de la transición planificada, aumentaron los retrasos en la interacción VPC a través de VPN (se registraron retrasos de 40 ms - 100 ms, aunque antes eran menos de 10 ms).
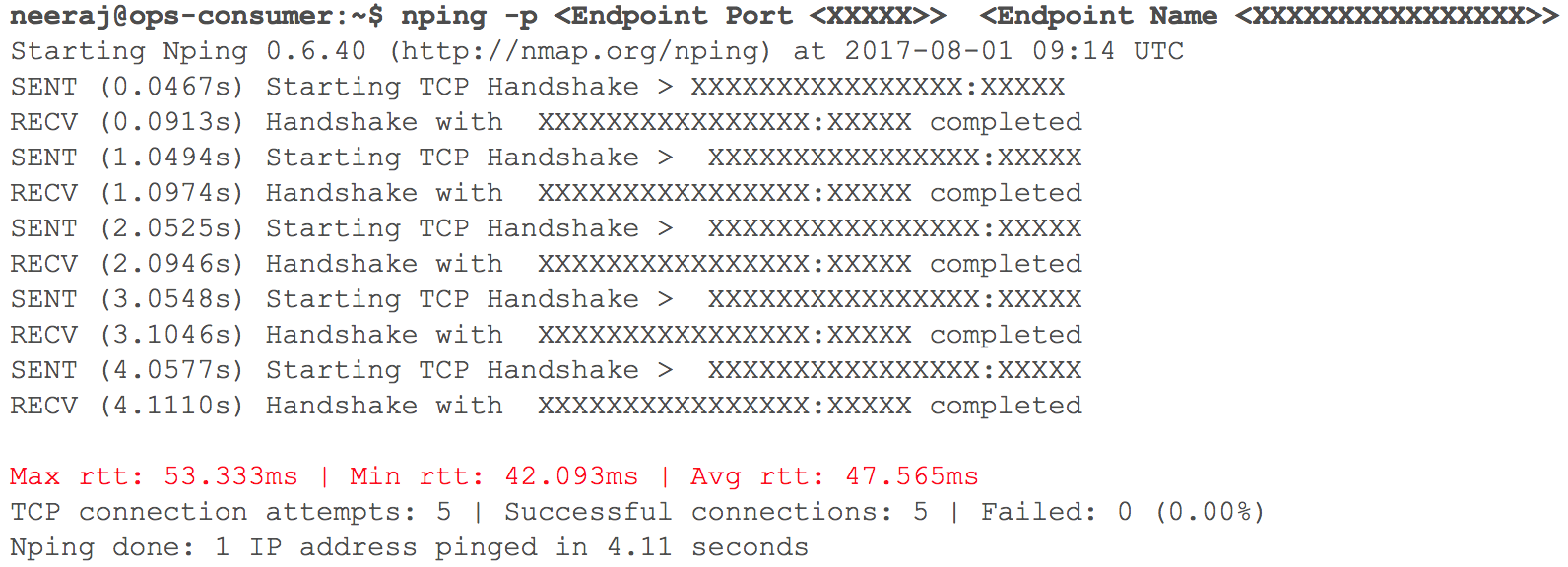
(Instantánea de la comprobación del retraso de la red cuando dos VPC interactúan)
El monitoreo mostró claramente: algo estaba mal con ambos canales de red en la nube que usaban túneles VPN. Incluso el rendimiento del túnel VPN no alcanzó la marca óptima. Esta situación ha comenzado a afectar negativamente a algunos de nuestros servicios de usuario. Inmediatamente devolvimos todos los servicios HTTP previamente migrados a su estado original. Nos contactamos con los equipos de soporte de TAM y servicios en la nube, proporcionamos los datos iniciales necesarios y comenzamos a entender por qué crecían las demoras. Los especialistas de soporte llegaron a la conclusión de que se logró el ancho de banda de red máximo en el canal de la nube entre dos proveedores de servicios en la nube. De ahí el crecimiento de los retrasos en la red durante la transferencia de sistemas internos.
Este incidente obligó a suspender la transición a la nube. Los proveedores de servicios en la nube no pudieron duplicar el ancho de banda lo suficientemente rápido. Por lo tanto, volvimos a la etapa de planificación y revisamos la estrategia. Decidimos transferir la infraestructura de la nube a GCP en una noche en lugar de tres e incluimos en el plan todos los servicios de la parte del servidor y el almacenamiento de datos. Cuando llegó la hora "X", todo transcurrió sin problemas: ¡las cargas de trabajo se transfirieron con éxito a Google Cloud sin ser notadas por nuestros usuarios!
Estrategia de migración de base de datos:
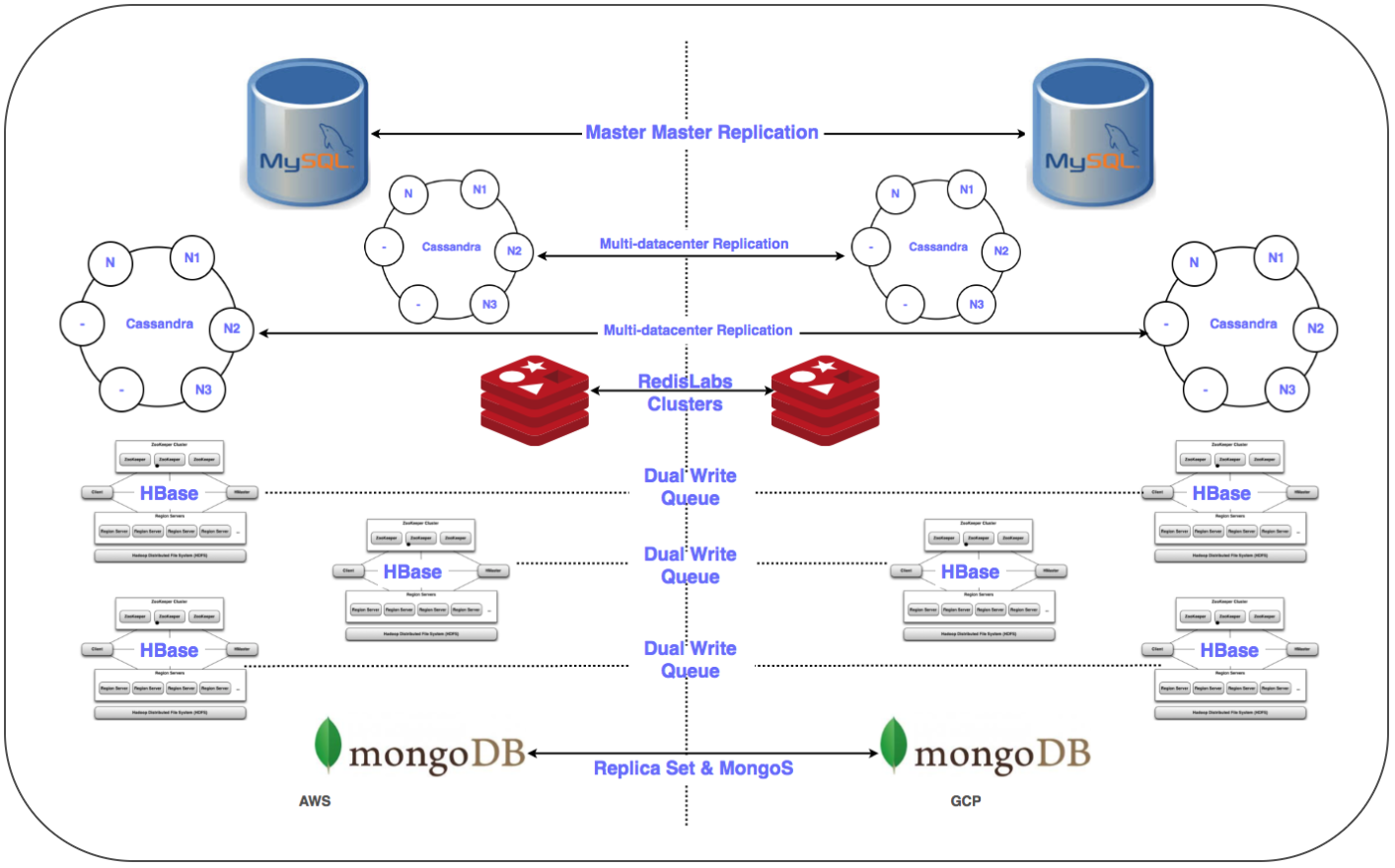
Fue necesario transferir más de 50 puntos finales de base de datos para un DBMS relacional, almacenamiento en memoria, así como NoSQL y clústeres distribuidos y escalables con baja latencia. Hemos colocado réplicas de todas las bases de datos en GCP. Esto se hizo para todas las implementaciones, excepto HBase.
Replica Replicación maestro-esclavo: implementado para MySQL, Redis, MongoDB y clusters MongoS.
Multi Multi-DC replication: implementado para clusters Cassandra.
⊹ Clústeres duales: se ha configurado un clúster paralelo para Gbase en GCP. Se migraron los datos existentes, se configuró la doble entrada de acuerdo con la estrategia de mantener la consistencia de los datos en ambos grupos.
En el caso de HBase, el problema fue establecer con Ambari. Encontramos algunas dificultades al colocar clústeres en varios centros de datos, por ejemplo, hubo problemas con DNS, un script de reconocimiento de rack, etc.
Los pasos finales (después de mover los servidores) incluyeron mover las réplicas a los servidores principales y cerrar las bases de datos antiguas. Según lo planeado, determinando la prioridad de la transferencia de la base de datos, utilizamos Zookeeper para la configuración necesaria de los clústeres de aplicaciones.
Estrategia de migración de servicios de aplicaciones
Para transferir las cargas de trabajo de los servicios de aplicaciones del alojamiento actual a la nube de GCP, utilizamos el enfoque de levantar y cambiar. Para cada servicio de aplicación, creamos un grupo de instancias administradas (MIG) con escala automática.
De acuerdo con un plan detallado, comenzamos a migrar servicios a GCP, teniendo en cuenta la secuencia y las dependencias de los almacenes de datos. Todos los servicios de pila de mensajes se migraron a GCP sin ningún tiempo de inactividad. Sí, hubo algunos problemas menores, pero los tratamos de inmediato.
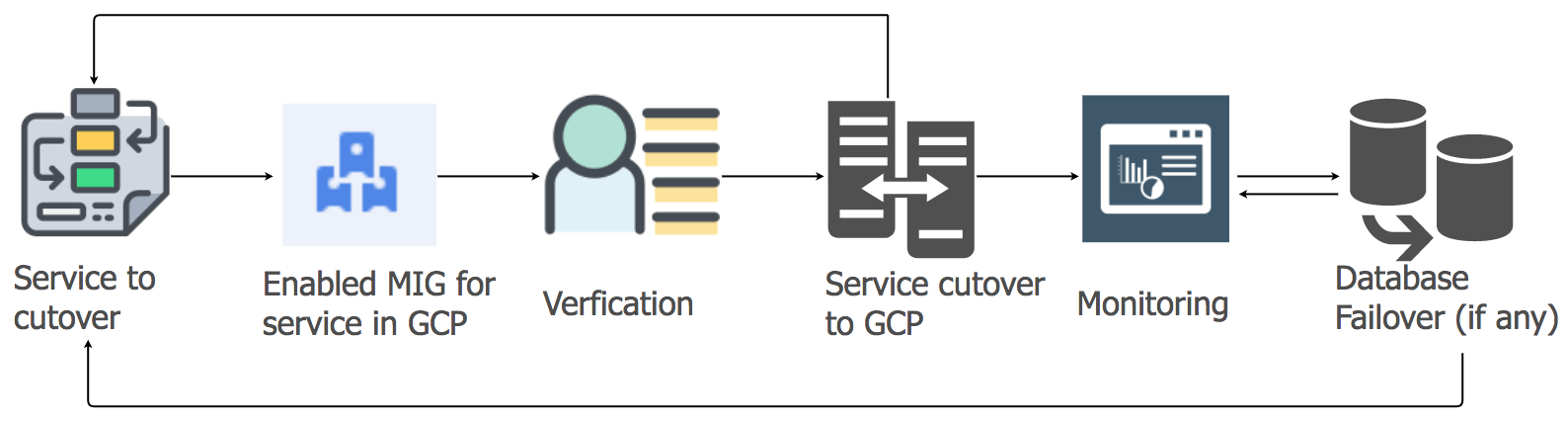
Por la mañana, a medida que aumentaba la actividad del usuario, seguimos cuidadosamente todos los paneles e indicadores para identificar rápidamente los problemas. Surgieron algunas dificultades, pero pudimos eliminarlas rápidamente. Uno de los problemas se debió a las limitaciones del equilibrador de carga interno (ILB), que no puede manejar más de 20,000 conexiones concurrentes. ¡Y necesitábamos 8 veces más! Por lo tanto, agregamos ILB adicionales a nuestra capa de administración de conexiones.
En las primeras horas de carga máxima después de la transición, controlamos todos los parámetros con especial cuidado, ya que toda la carga de la pila de mensajes se transfirió a GCP. Hubo algunos problemas menores que tratamos muy rápidamente. Al migrar otros servicios, tomamos el mismo enfoque.
Migración de almacenamiento de objetos:
Utilizamos el servicio de almacenamiento de objetos principalmente de tres maneras.
⊹ Almacenamiento de archivos multimedia enviados a un chat personal o grupal. El período de retención está determinado por la política de gestión del ciclo de vida.
⊹ Almacenamiento de imágenes y miniaturas del perfil de usuario.
⊹ Almacenamiento de archivos multimedia de las secciones "Historial" y "Línea de tiempo" y las miniaturas correspondientes.
Utilizamos la herramienta de transferencia de almacenamiento de Google para copiar objetos antiguos de S3 a GCS. También utilizamos un MIG personalizado basado en Kafka para transferir objetos de S3 a GCS cuando se requería una lógica especial.
La transición de S3 a GCS incluyó los siguientes pasos:
● Para el primer caso de uso del almacén de objetos, comenzamos a escribir nuevos datos tanto en S3 como en GCS, y después del vencimiento comenzamos a leer datos de GCS usando la lógica en el lado de la aplicación. La transferencia de datos antiguos no tiene sentido, y este enfoque es rentable.
● Para el segundo y tercer caso de uso, comenzamos a escribir nuevos objetos en GCS y cambiamos la ruta para leer los datos, de modo que la búsqueda se realiza primero en GCS y solo entonces, si no se encuentra el objeto, en S3.
Tomó meses planificar, verificar la exactitud del concepto, preparar y crear un prototipo, pero luego decidimos la transición y la implementamos muy rápidamente. Evaluamos los riesgos y nos dimos cuenta de que la migración rápida es preferible y casi imperceptible.
Este proyecto a gran escala nos ha ayudado a obtener una posición sólida y a aumentar la productividad del equipo en muchas áreas, ya que la mayoría de las operaciones manuales sobre la gestión de la infraestructura de la nube se han realizado en el pasado.
● En cuanto a los usuarios, ahora hemos recibido todo lo necesario para garantizar la más alta calidad de su servicio. El tiempo de inactividad casi ha desaparecido, y las nuevas características se están implementando más rápido.
● Nuestro equipo dedica menos tiempo a tareas de mantenimiento y puede centrarse en proyectos de automatización y crear nuevas herramientas.
● Obtuvimos acceso a un conjunto de herramientas sin precedentes para trabajar con grandes datos, así como a funcionalidades listas para el aprendizaje y análisis automático. Ver detalles aquí.
● El compromiso de Google Cloud de trabajar con el proyecto de código abierto Kubernetes también está en línea con nuestro plan de desarrollo para este año.