En uno de los artículos anteriores, hablé sobre cómo puede construir un ejecutor de programas para una máquina de pila virtual utilizando enfoques de programación funcionales y orientados al lenguaje. La estructura matemática del lenguaje sugirió la estructura básica para la implementación de su traductor, basada en el concepto de semigrupos y monoides. Este enfoque me permitió construir una implementación hermosa y ampliable y romper los aplausos, pero la primera pregunta de la audiencia me hizo bajar de la tribuna y volver a subir a Emacs.
Realicé una prueba simple y me aseguré de que en tareas simples que usan solo la pila, la máquina virtual funciona de manera inteligente, y cuando se usa la "memoria", una matriz con acceso aleatorio, comienzan grandes problemas. Acerca de cómo logramos resolverlos sin cambiar los principios básicos de la arquitectura del programa y lograr una aceleración mil veces mayor del programa, y será discutido en este artículo.
Haskell es un lenguaje peculiar con un nicho especial. El objetivo principal de su creación y desarrollo era la necesidad de que la lengua franca expresara y probara ideas de programación funcional. Esto justifica sus características más llamativas: pereza, pureza extrema, énfasis en los tipos y manipulaciones con ellos. No fue diseñado para el desarrollo diario, ni para la programación industrial, ni para el uso generalizado. El hecho de que realmente se use para crear proyectos a gran escala en la industria de redes y en el procesamiento de datos es la buena voluntad de los desarrolladores, prueba de concepto, si lo desea. Pero hasta ahora, el producto más importante, ampliamente utilizado y sorprendentemente poderoso escrito en Haskell es ... el compilador ghc. Y esto está completamente justificado desde el punto de vista de su propósito: ser una herramienta para la investigación en el campo de la informática. El principio proclamado por Simon Payton-Johnson: "Evitar el éxito a toda costa" es necesario para que el lenguaje siga siendo ese instrumento. Haskell es como una cámara estéril en el laboratorio de un centro de investigación que desarrolla tecnologías de semiconductores o nanomateriales. Es terriblemente inconveniente trabajar en él, y para la práctica diaria también restringe la libertad de acción, pero sin estos inconvenientes, sin una adhesión inflexible a las restricciones, no será posible observar y estudiar los sutiles efectos que luego se convertirán en la base de los desarrollos industriales. Al mismo tiempo, en la industria, la esterilidad será necesaria solo en el volumen más necesario, y los resultados de estos experimentos aparecerán en nuestros bolsillos en forma de dispositivos. Estudiamos estrellas y galaxias no porque esperemos recibir beneficios directos de ellas, sino porque, en la escala de estos objetos poco prácticos, los efectos cuánticos y relativistas se vuelven observables y estudiados, tanto que luego podemos usar este conocimiento para desarrollar algo muy utilitario. Por lo tanto, Haskell con sus líneas "incorrectas", la pereza poco práctica de los cálculos, la rigidez de algunos algoritmos de inferencia de tipos, con una curva de entrada extremadamente empinada, finalmente no le permite crear fácilmente una aplicación inteligente en la rodilla o un sistema operativo. Sin embargo, lentes, mónadas, análisis combinatorio, el uso generalizado de monoides, métodos de prueba automática de teoremas, gestores de paquetes funcionales declarativos, tipos lineales y dependientes se están acercando al mundo práctico. Esto encuentra aplicación en condiciones menos estériles en los lenguajes Python, Scala, Kotlin, F #, Rust y muchos otros. Pero no usaría ninguno de estos maravillosos lenguajes para enseñar los principios de la programación funcional: llevaría al estudiante al laboratorio, le mostraría cómo funciona en ejemplos claros y claros, y luego podrá ver estos principios en acción en la fábrica Una máquina grande e incomprensible, pero muy rápida. Evitar el éxito a toda costa es proteger contra los intentos de colocar una cafetera en un microscopio electrónico para popularizarla. Y en las competencias cuyo idioma es mejor, Haskell siempre estará fuera de las nominaciones habituales.
Sin embargo, la persona es débil y un demonio también vive en mí, lo que me hace querer comparar, evaluar y defender "mi idioma favorito" frente a los demás. Entonces, después de haber escrito una implementación elegante de una máquina apilada, basada en una composición monoidal, con el único propósito de ver si esta idea funciona para mí, inmediatamente me molestó que me di cuenta de que la implementación funcionó de manera brillante, ¡pero terriblemente ineficiente! Es como si realmente lo voy a usar para tareas serias, o para vender mi máquina apilada en el mismo mercado donde se ofrecen máquinas virtuales Python o Java. Pero maldita sea, el artículo sobre el lechón con el que comenzó toda esta conversación ofrece números tan sabrosos: cientos de milisegundos para el lechón, segundos para Python ... ¡y mi hermoso monoide no puede hacer la misma tarea en una hora! Tengo que tener éxito! ¡Mi microscopio preparará espresso no peor que una máquina de café en el pasillo del instituto! ¡Crystal Palace se puede dispersar y lanzar al espacio!
¿Pero a qué estás dispuesto a renunciar, me pregunta el ángel matemático? ¿La pureza y transparencia de la arquitectura del palacio? ¿La flexibilidad y extensibilidad que proporcionan los homomorfismos de los programas a otras soluciones? El demonio y el ángel son tercos, y el sabio taoísta, a quien también me permito vivir, propuso tomar el camino que mejor se adapte a ambos y seguirlo el mayor tiempo posible. Sin embargo, no con el objetivo de identificar al ganador, sino con el fin de conocer el camino en sí mismo, descubrir hasta dónde llega y obtener una nueva experiencia. Y entonces supe la vana tristeza y la alegría de la optimización.
Antes de comenzar, agregamos que las comparaciones de idiomas en términos de efectividad no tienen sentido. Necesita comparar traductores (intérpretes o compiladores), o el desempeño de un programador que usa el lenguaje. Al final, la afirmación de que los programas C son los más rápidos es fácil de refutar escribiendo un intérprete C completo en BASIC, por ejemplo. Entonces, no estamos comparando Haskell y JavaScript, sino el rendimiento de los programas ejecutados por un traductor compilado por ghc y los programas ejecutados, por ejemplo, en un navegador en particular. Toda la terminología porcina proviene de un artículo inspirador sobre máquinas apiladas. Todo el código Haskell que acompaña al artículo puede estudiarse en el repositorio .
Salimos de la zona de confort.
La posición inicial será la implementación de una máquina de pila monoidal en forma de EDSL , un pequeño lenguaje simple que permite combinar dos docenas de primitivas para representar programas para una máquina de pila virtual. Tan pronto como entró en el segundo artículo, le damos el nombre de monopig . Se basa en el hecho de que los lenguajes para máquinas apiladas forman un monoide con una operación de concatenación y una operación vacía como una unidad. En consecuencia, él mismo fue construido en forma de una transformación monoide del estado de la máquina. El estado incluye una pila, memoria en forma de un vector (una estructura que proporciona acceso aleatorio a los elementos), un indicador de parada de emergencia y una batería monoidal para acumular información de depuración. Toda esta estructura se transmite a lo largo de una cadena de endomorfismos de una operación a otra, llevando a cabo un proceso computacional. Se construyó una estructura isomórfica de códigos de programa a partir de la estructura que forman los programas y, a partir de ella, los homomorfismos en otras estructuras útiles que representan los requisitos del programa en términos de número de argumentos y memoria. La etapa final de la construcción fue la creación de monoides de transformación en la categoría Claysley, que le permiten sumergir los cálculos en una mónada arbitraria. Entonces la máquina obtuvo las capacidades de entrada-salida y cálculos ambiguos. Comenzaremos con esta implementación. Su código se puede encontrar aquí .
Pondremos a prueba la efectividad del programa en la implementación ingenua del tamiz de Eratóstenes, que llena la memoria (matriz) con ceros y unos, denotando primos por cero. Le damos el código de procedimiento del algoritmo en javascript :
var memSize = 65536; var arr = []; for (var i = 0; i < memSize; i++) arr.push(0); function sieve() { var n = 2; while (n*n < memSize) { if (!arr[n]) { var k = n; while (k < memSize) { k+=n; arr[k] = 1; } } n++; } }
El algoritmo está inmediatamente ligeramente optimizado. Elimina el mal caminar a través de las celdas de memoria ya llenas. Mi ángel matemático no estuvo de acuerdo con una versión realmente ingenua de un ejemplo en el proyecto PorosenokVM , ya que esta optimización cuesta solo cinco instrucciones del lenguaje de pila. Así es como el algoritmo se traduce a monopig :
sieve = push 2 <> while (dup <> dup <> mul <> push memSize <> lt) (dup <> get <> branch mempty fill <> inc) <> pop fill = dup <> dup <> add <> while (dup <> push memSize <> lt) (dup <> push 1 <> swap <> put <> exch <> add) <> pop
Y así es como puede escribir una implementación equivalente de este algoritmo en el idiomático Haskell, utilizando los mismos tipos que en monopig :
sieve' :: Int -> Vector Int -> Vector Int sieve' km | k*k < memSize = sieve' (k+1) $ if m ! k == 0 then fill' k (2*k) m else m | otherwise = m fill' :: Int -> Int -> Vector Int -> Vector Int fill' knm | n < memSize = fill' k (n+k) $ m // [(n,1)] | otherwise = m
Utiliza el tipo Data.Vector y las herramientas para trabajar con él, que no son demasiado comunes para el trabajo diario en Haskell. Expresión m ! k m ! k devuelve el k elemento del vector m , y m // [(n,1)] : establece el elemento con el número n en 1. Estoy escribiendo esto aquí porque tuve que acudir a ellos en busca de ayuda, a pesar de que trabajo en Haskell Casi todos los días. El hecho es que las estructuras con acceso aleatorio en una implementación funcional son ineficientes y, por esta razón, no son amadas.
De acuerdo con las condiciones de competencia especificadas en el artículo sobre el lechón, el algoritmo se ejecuta 100 veces. Y para deshacerse de una computadora específica, comparemos las velocidades de ejecución de estos tres programas, refiriéndolos al rendimiento del programa javascript que se ejecutó en Chrome.
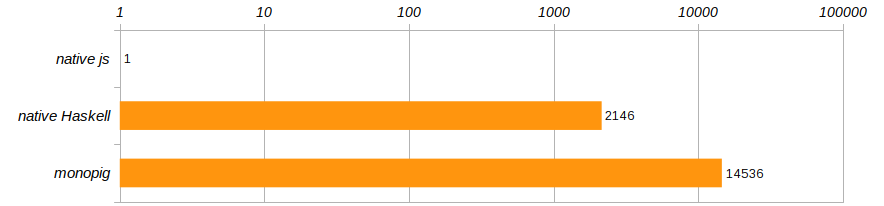
Horror horror !!! ¡ monopig no monopig ralentiza impíamente, sino que la versión nativa no es mucho mejor! ¿Haskell, por supuesto, es genial, pero no tanto como inferior a un programa que se ejecuta en un navegador? Como los entrenadores nos enseñan, no puedes vivir así, ¡es hora de abandonar la zona de confort que nos brinda Haskell!
Superar la pereza
Vamos a hacerlo bien. Para hacer esto, compile un programa en monopig con el indicador -rtsopts para realizar un -rtsopts estadísticas de tiempo de ejecución y vea lo que necesitamos para ejecutar el tamiz de Eratóstenes una vez:
$ ghc -O -rtsopts ./Monopig4.hs [1 of 1] Compiling Main ( Monopig4.hs, Monopig4.o ) Linking Monopig4 ... $ ./Monopig4 -RTS -sstderr "Ok" 68,243,040,608 bytes allocated in the heap 6,471,530,040 bytes copied during GC 2,950,952 bytes maximum residency (30667 sample(s)) 42,264 bytes maximum slop 15 MB total memory in use (7 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 99408 colls, 0 par 2.758s 2.718s 0.0000s 0.0015s Gen 1 30667 colls, 0 par 57.654s 57.777s 0.0019s 0.0133s INIT time 0.000s ( 0.000s elapsed) MUT time 29.008s ( 29.111s elapsed) GC time 60.411s ( 60.495s elapsed) <-- ! EXIT time 0.000s ( 0.000s elapsed) Total time 89.423s ( 89.607s elapsed) %GC time 67.6% (67.5% elapsed) Alloc rate 2,352,591,525 bytes per MUT second Productivity 32.4% of total user, 32.4% of total elapsed
La última línea nos dice que el programa se dedicaba a la computación productiva solo un tercio del tiempo. El resto del tiempo, el recolector de basura se escapó de la memoria y limpió para hacer cálculos flojos. ¡Cuántas veces nos han dicho en la infancia que la pereza no es buena! Aquí, la característica principal de Haskell nos perjudicó al intentar crear varios billones de transformaciones de pila y vectores diferidos.
Un ángel matemático en este lugar levanta un dedo y felizmente habla del hecho de que desde la época de Alonzo Church, hay un teorema que establece que la estrategia de cálculo no afecta su resultado, lo que significa que somos libres de elegirlo por razones de eficiencia. Cambiar los cálculos a estricto no es nada difícil: ¡ponga una señal ! en la declaración del tipo de pila y memoria y, por lo tanto, hace que estos campos sean estrictos.
data VM a = VM { stack :: !Stack , status :: Maybe String , memory :: !Memory , journal :: !a }
No cambiaremos nada más y verificaremos inmediatamente el resultado:
$ ./Monopig41 +RTS -sstderr "Ok" 68,244,819,008 bytes allocated in the heap 7,386,896 bytes copied during GC 528,088 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 16 MB total memory in use (14 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 129923 colls, 0 par 0.666s 0.654s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.001s 0.001s 0.0006s 0.0007s INIT time 0.000s ( 0.000s elapsed) MUT time 13.029s ( 13.048s elapsed) GC time 0.667s ( 0.655s elapsed) EXIT time 0.001s ( 0.001s elapsed) Total time 13.700s ( 13.704s elapsed) %GC time 4.9% (4.8% elapsed) Alloc rate 5,238,049,412 bytes per MUT second Productivity 95.1% of total user, 95.1% of total elapsed
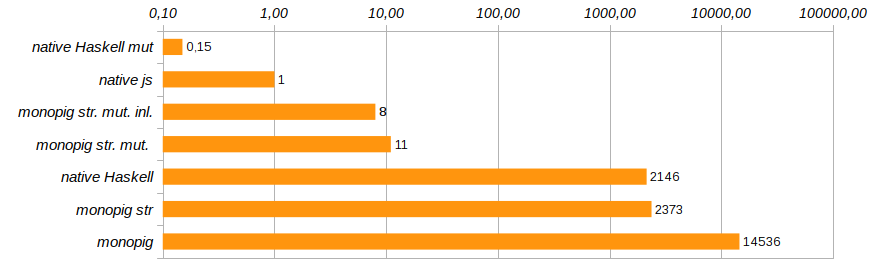
La productividad ha crecido significativamente. Los costos totales de memoria aún se mantuvieron impresionantes debido a la inmutabilidad de los datos, pero lo más importante, ahora que hemos limitado la pereza de los datos, el recolector de basura tiene la oportunidad de ser perezoso, solo queda el 5% del trabajo. Ingrese una nueva entrada en la calificación.

Bueno, los cálculos rigurosos nos han acercado a la velocidad del código nativo de Haskell, que vergonzosamente se ralentiza sin ninguna máquina virtual. Esto significa que la sobrecarga de usar un vector inmutable excede significativamente el costo de mantener una máquina apilada. Y esto significa que es hora de decir adiós a la inmutabilidad de la memoria.
Dejar cambios en la vida
El tipo Data.Vector bueno, pero al usarlo, pasamos mucho tiempo copiando, en nombre de preservar la pureza del proceso informático. Reemplazándolo con el tipo Data.Vector.Unpacked al menos ahorramos en el empaque de la estructura, pero esto no cambia fundamentalmente la imagen. La solución correcta sería eliminar la memoria del estado de la máquina y proporcionar acceso al vector externo utilizando la categoría Kleisley. Al mismo tiempo, junto con los vectores puros, puede usar los denominados vectores mutables (mutables) Data.Vector.Mutable .
Conectaremos los módulos apropiados y pensaremos cómo manejar datos mutables en un programa funcional limpio.
import Control.Monad.Primitive import qualified Data.Vector.Unboxed as V import qualified Data.Vector.Unboxed.Mutable as M
Se supone que estos tipos sucios están aislados del público puro. Están contenidos en las mónadas de la clase PrimMonad (estos incluyen ST o IO ), donde los programas limpios insertan cuidadosamente las instrucciones para las acciones escritas en un lenguaje funcional cristal en un pergamino precioso. Por lo tanto, el comportamiento de estos animales inmundos está determinado por escenarios estrictamente ortodoxos y no es peligroso. No todos los programas para nuestra máquina usan memoria, por lo que no es necesario condenar a toda la arquitectura a la inmersión en la mónada IO . Junto con un subconjunto limpio del lenguaje monopig crearemos cuatro instrucciones que brinden acceso a la memoria, y solo ellos tendrán acceso al territorio peligroso.
El tipo de máquina limpia se acorta:
data VM a = VM { stack :: !Stack , status :: Maybe String , journal :: !a }
Los diseñadores de programas y los propios programas apenas notarán este cambio, pero sus tipos cambiarán. Además, tiene sentido definir varios tipos de sinónimos para simplificar las firmas.
type Memory m = M.MVector (PrimState m) Int type Logger ma = Memory m -> Code -> VM a -> m (VM a) type Program' ma = Logger ma -> Memory m -> Program ma
Los constructores tendrán otro argumento que representa el acceso a la memoria. Los ejecutores cambiarán significativamente, especialmente aquellos que mantienen un registro de cálculo, porque ahora necesitan preguntar por el estado del vector variable. El código completo se puede ver y estudiar en el repositorio, pero aquí daré lo más interesante: la implementación de los componentes básicos para trabajar con memoria para mostrar cómo se hace esto.
geti :: PrimMonad m => Int -> Program' ma geti i = programM (GETI i) $ \mem -> \s -> if (0 <= i && i < memSize) then \vm -> do x <- M.unsafeRead mem i setStack (x:s) vm else err "index out of range" puti :: PrimMonad m => Int -> Program' ma puti i = programM (PUTI i) $ \mem -> \case (x:s) -> if (0 <= i && i < memSize) then \vm -> do M.unsafeWrite mem ix setStack s vm else err "index out of range" _ -> err "expected an element" get :: PrimMonad m => Program' ma get = programM (GET) $ \m -> \case (i:s) -> \vm -> do x <- M.read mi setStack (x:s) vm _ -> err "expected an element" put :: PrimMonad m => Program' ma put = programM (PUT) $ \m -> \case (i:x:s) -> \vm -> M.write mix >> setStack s vm _ -> err "expected two elemets"
El demonio optimizador se ofreció inmediatamente a ahorrar un poco más en verificar los valores de índice permitidos en la memoria, porque para los geti puti y geti índices son conocidos en la etapa de creación del programa y los valores incorrectos pueden eliminarse de antemano. Los índices definidos dinámicamente para los comandos put y get no garantizan la seguridad, y el ángel matemático no permitió que se les hicieran llamadas peligrosas.
Todo este alboroto con poner la memoria en un argumento separado parece complicado. Pero muestra muy claramente que los datos deben ser cambiados por su lugar: deberían estar afuera . Les recuerdo que estamos tratando de llevar a un repartidor de pizza a un laboratorio estéril. Las funciones puras saben qué hacer con ellas, pero estos objetos nunca se convertirán en ciudadanos de primera clase, y no vale la pena preparar pizza en el laboratorio.
Verifiquemos lo que compramos con estos cambios:
$ ./Monopig5 +RTS -sstderr "Ok" 9,169,192,928 bytes allocated in the heap 2,006,680 bytes copied during GC 529,608 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 2 MB total memory in use (0 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 17693 colls, 0 par 0.094s 0.093s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.000s 0.000s 0.0002s 0.0003s INIT time 0.000s ( 0.000s elapsed) MUT time 7.228s ( 7.232s elapsed) GC time 0.094s ( 0.093s elapsed) EXIT time 0.000s ( 0.000s elapsed) Total time 7.325s ( 7.326s elapsed) %GC time 1.3% (1.3% elapsed) Alloc rate 1,268,570,828 bytes per MUT second Productivity 98.7% of total user, 98.7% of total elapsed
Esto ya es progreso! El uso de la memoria se redujo ocho veces, la velocidad de ejecución del programa aumentó 180 veces y el recolector de basura permaneció casi sin trabajo.

La solución apareció monopig st. mut. , que es diez veces más lento que la solución nativa en js , pero aparte de eso, la solución nativa en Haskell, que usa vectores mutables. Aquí está su código:
fill' :: Int -> Int -> Memory IO -> IO (Memory IO) fill' knm | n > memSize-k = return m | otherwise = M.unsafeWrite mn 1 >> fill' k (n+k) m sieve' :: Int -> Memory IO -> IO (Memory IO) sieve' km | k*k < memSize = do x <- M.unsafeRead mk if x == 0 then fill' k (2*k) m >>= sieve' (k+1) else sieve' (k+1) m | otherwise = return m
Comienza de la siguiente manera
main = do m <- M.replicate memSize 0 stimes 100 (sieve' 2 m >> return ()) print "Ok"
Y ahora Haskell finalmente muestra que no es un lenguaje de juguete. Solo necesitas usarlo sabiamente. Por cierto, el código anterior utiliza el hecho de que el tipo IO () forma un semigrupo con la operación de ejecución secuencial de programas (>>) , y con la ayuda de stimes 100 veces el cálculo del problema de la prueba.
Ahora está claro por qué hay tanta aversión por los arreglos funcionales y por qué nadie recuerda cómo trabajar con ellos: tan pronto como un programador de Haskell realmente necesita estructuras de acceso aleatorio, se reenfoca en datos mutables y trabaja en mónadas ST o IO.
Sacar una parte de los comandos a una zona especial pone en duda la legalidad del isomorfismo. El programa . Después de todo, no podemos convertir simultáneamente el código en programas puros y monádicos, esto no permite que el sistema de tipos lo haga. Sin embargo, las clases de tipos son lo suficientemente flexibles como para que exista este isomorfismo. Código de homomorfismo El programa ahora se divide en varios homomorfismos para diferentes subconjuntos del lenguaje. Cómo exactamente se hace esto se puede ver en el [código] () completo del programa.
No te detengas ahí
Eliminar las llamadas innecesarias a funciones e incrustar su código directamente usando el pragma {-# INLINE #-} ayudará a cambiar ligeramente la productividad del programa. Este método no es adecuado para funciones recursivas, pero es ideal para componentes básicos y funciones de establecimiento. Reduce el tiempo de ejecución del programa de prueba en otro 25% (ver Monopig51.hs ).
El siguiente paso razonable será deshacerse de las herramientas de registro cuando no sean necesarias. En la etapa de formación del endomorfismo que representa el programa, utilizamos un argumento externo, que determinamos al inicio. El program constructores inteligentes y el programM pueden ser advertidos de que no puede haber ningún argumento-logger. En este caso, el código del convertidor no contiene nada superfluo: solo la funcionalidad y la comprobación del estado de la máquina.
program code f = programM code (const f) programM code f (Just logger) mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> logger mem code =<< f mem (stack vm) vm _ -> return vm programM code f _ mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> f mem (stack vm) vm _ -> return vm
Ahora, las funciones de ejecución deben indicar explícitamente la presencia o ausencia de registro que no utiliza el código auxiliar none , sino que usa el tipo Maybe (Logger ma) . ¿Por qué debería funcionar esto, porque si hay un registro o no, los componentes del programa lo descubrirán "en el último momento", antes de la ejecución? ¿No se cosería el código innecesario en la etapa de composición de la composición del programa? Haskell es un lenguaje vago y aquí juega en nuestras manos. Es antes de la ejecución que el código final se optimiza para una tarea específica. Esta optimización redujo el tiempo de ejecución del programa en otro 40% (ver Monopig52.hs ).
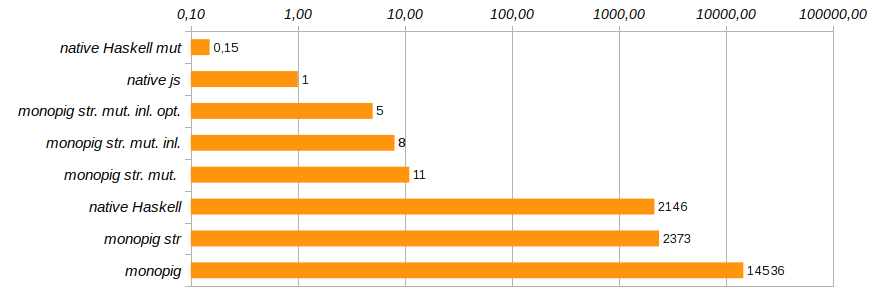
Con esto, completaremos el trabajo para acelerar el lechón monoidal. Él ya está corriendo lo suficientemente rápido para que tanto el ángel como el demonio puedan calmarse. Esto, por supuesto, no es C, todavía usamos una lista limpia como una pila, pero reemplazarla con una matriz conducirá a una excavación exhaustiva del código y al rechazo de usar plantillas elegantes en las definiciones de comandos básicos. Quería sobrevivir con cambios mínimos, y principalmente a nivel de tipos.
Algunos problemas persisten con el registro. Un recuento simple del número de pasos o el uso de la pila funciona bien (hicimos que el campo de registro sea estricto), pero emparejarlos ya comienza a comer memoria, tienes que meterte en patadas usando seq , lo cual ya es bastante molesto. Pero dime, ¿quién registrará los 14 mil millones de pasos, si puedes depurar la tarea en los primeros cientos? Entonces no pasaré mi tiempo acelerando para acelerar.
Solo queda agregar que en el artículo sobre el lechón, como uno de los métodos para optimizar los cálculos, se proporciona el seguimiento: la asignación de secciones lineales de código, los rastros dentro de los cuales se pueden realizar los cálculos sin pasar por el ciclo de envío del comando principal (bloque de switch ). En nuestro caso, la composición monoidal de los componentes del programa crea tales huellas, ya sea durante la formación del programa a partir de los componentes EDSL, o durante la operación del homomorfismo fromCode . Este método de optimización nos llega gratis, por así decirlo, por construcción.
Hay muchas soluciones Conduits y rápidas en el ecosistema de Haskell, como las transmisiones de Conduits o Pipes , hay excelentes reemplazos de String y creadores ágiles de XML como blaze-html, y el analizador attoparsec es un estándar para el análisis combinatorio de las gramáticas LL (∞). Todo esto es necesario para el funcionamiento normal. Pero aún más se necesita investigación que conduzca a estas decisiones. Haskell ha sido y sigue siendo una herramienta de investigación que cumple con los requisitos específicos que el público en general no necesita. Vi en Kamchatka cómo los ases en un helicóptero Mi-4 cerraron cajas de fósforos en una discusión, empujando el tren de aterrizaje con una rueda mientras colgaba en el aire. Esto se puede hacer, y es genial, pero no es necesario.
¡Pero, sin embargo, esto es genial!