Descargo de responsabilidad: este artículo describe una solución no obvia a un problema no obvio. Antes de apresurarse huevos Para ponerlo en práctica, recomiendo leer el artículo hasta el final y pensarlo dos veces.

Hola a todos! Cuando trabajamos con código, a menudo tenemos que lidiar con el estado . Uno de esos casos es el ciclo de vida de los objetos. Administrar un objeto con varios estados posibles puede ser una tarea muy trivial. Agregue la ejecución asincrónica aquí y la tarea se complica por un orden de magnitud. Existe una solución efectiva y natural. En este artículo hablaré sobre la máquina de eventos y cómo implementarla en Go.
¿Por qué administrar el estado?
Para comenzar, definamos el concepto mismo. El ejemplo más simple de un estado: archivos y varias conexiones. No puedes simplemente tomar y leer un archivo. Primero debe abrirse, y al final preferiblemente asegúrese de cerrar Resulta que la acción actual depende del resultado de la acción anterior: la lectura depende de la apertura. El resultado guardado es el estado.
El principal problema con el estado es la complejidad. Cualquier estado complica automáticamente el código. Debe almacenar los resultados de las acciones en la memoria y agregar varias comprobaciones a la lógica. Es por eso que las arquitecturas sin estado son tan atractivas para los programadores: nadie quiere problemas dificultades Si los resultados de sus acciones no afectan la lógica de ejecución, no necesita un estado.
Sin embargo, hay una propiedad que te hace tener en cuenta las dificultades. Un estado requiere que sigas un orden específico de acciones. En general, tales situaciones deben evitarse, pero esto no siempre es posible. Un ejemplo es el ciclo de vida de los objetos del programa. Gracias a la buena gestión del estado, se puede obtener un comportamiento predecible de los objetos con un ciclo de vida complejo.
Ahora veamos cómo hacerlo bien .
Automático como una forma de resolver problemas

Cuando la gente habla de estados, las máquinas de estados finitos vienen inmediatamente a la mente. Es lógico, porque un autómata es la forma más natural de administrar un estado.
No profundizaré en la teoría de los autómatas ; hay información más que suficiente en Internet.
Si busca ejemplos de máquinas de estado finito para Go, definitivamente se encontrará con un lexer de Rob Pike . Un gran ejemplo de un autómata en el que los datos procesados son el alfabeto de entrada. Esto significa que las transiciones de estado son causadas por el texto que procesa el lexer. Solución elegante a un problema específico.
Lo principal a entender es que un autómata es una solución a un problema estrictamente específico. Por lo tanto, antes de considerarlo como un remedio para todos los problemas, debe comprender completamente la tarea. Específicamente, la entidad que desea controlar:
- estados - ciclo de vida;
- eventos: qué causa exactamente la transición a cada estado;
- resultado del trabajo - datos de salida;
- modo de ejecución (síncrono / asíncrono);
- Principales casos de uso.
El lexer es hermoso, pero solo cambia de estado debido a los datos que procesa. Pero, ¿qué pasa con la situación cuando el usuario invoca transiciones? Aquí es donde la máquina de eventos puede ayudar.
Ejemplo real
Para aclararlo, analizaré un ejemplo de la biblioteca de phono .
Para una inmersión completa en el contexto, puede leer el artículo introductorio . Esto no es necesario para este tema, pero ayudará a comprender mejor lo que estamos gestionando.
¿Y qué estamos gestionando?
phono se basa en la tubería DSP. Consiste en tres etapas de procesamiento. Cada etapa puede incluir de uno a varios componentes:
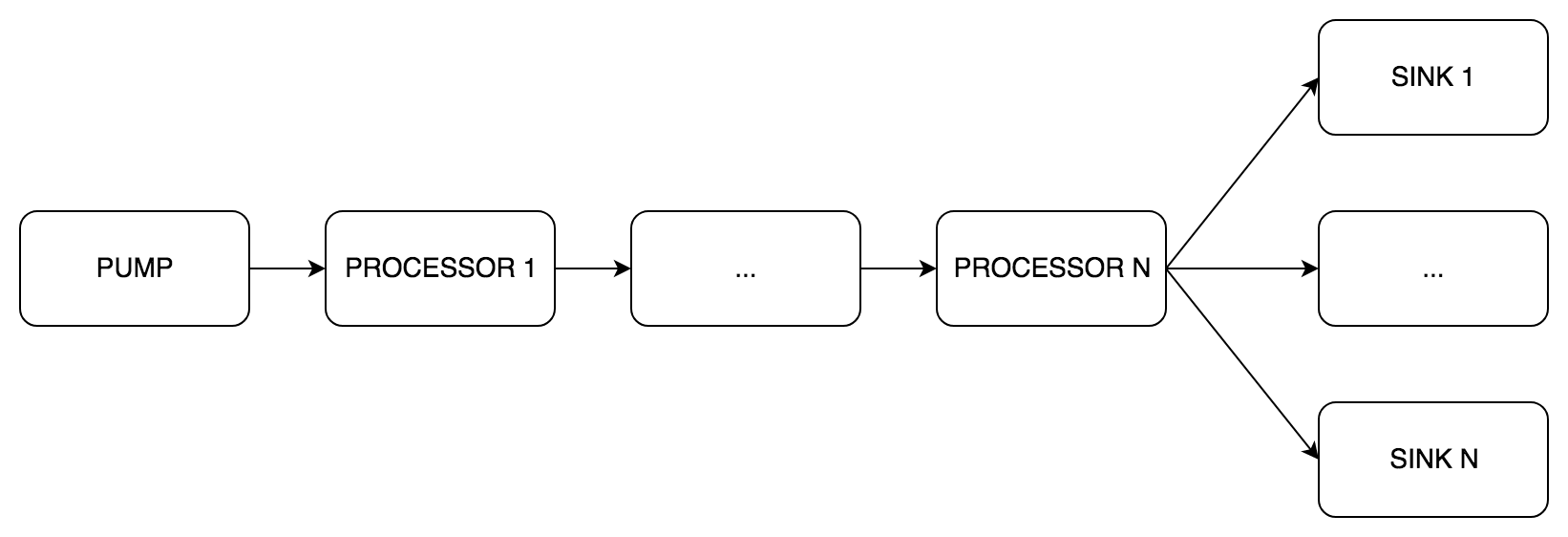
pipe.Pump (bomba inglesa) es una etapa obligatoria de recepción de sonido, siempre solo un componente.pipe.Processor (controlador en inglés): una etapa opcional de procesamiento de sonido, de 0 a N componentes.pipe.Sink (sumidero inglés): una etapa obligatoria de transmisión de sonido, de 1 a N componentes.
En realidad, gestionaremos el ciclo de vida del transportador.
Ciclo de vida
Así es como se ve el diagrama del estado de la pipe.Pipe .
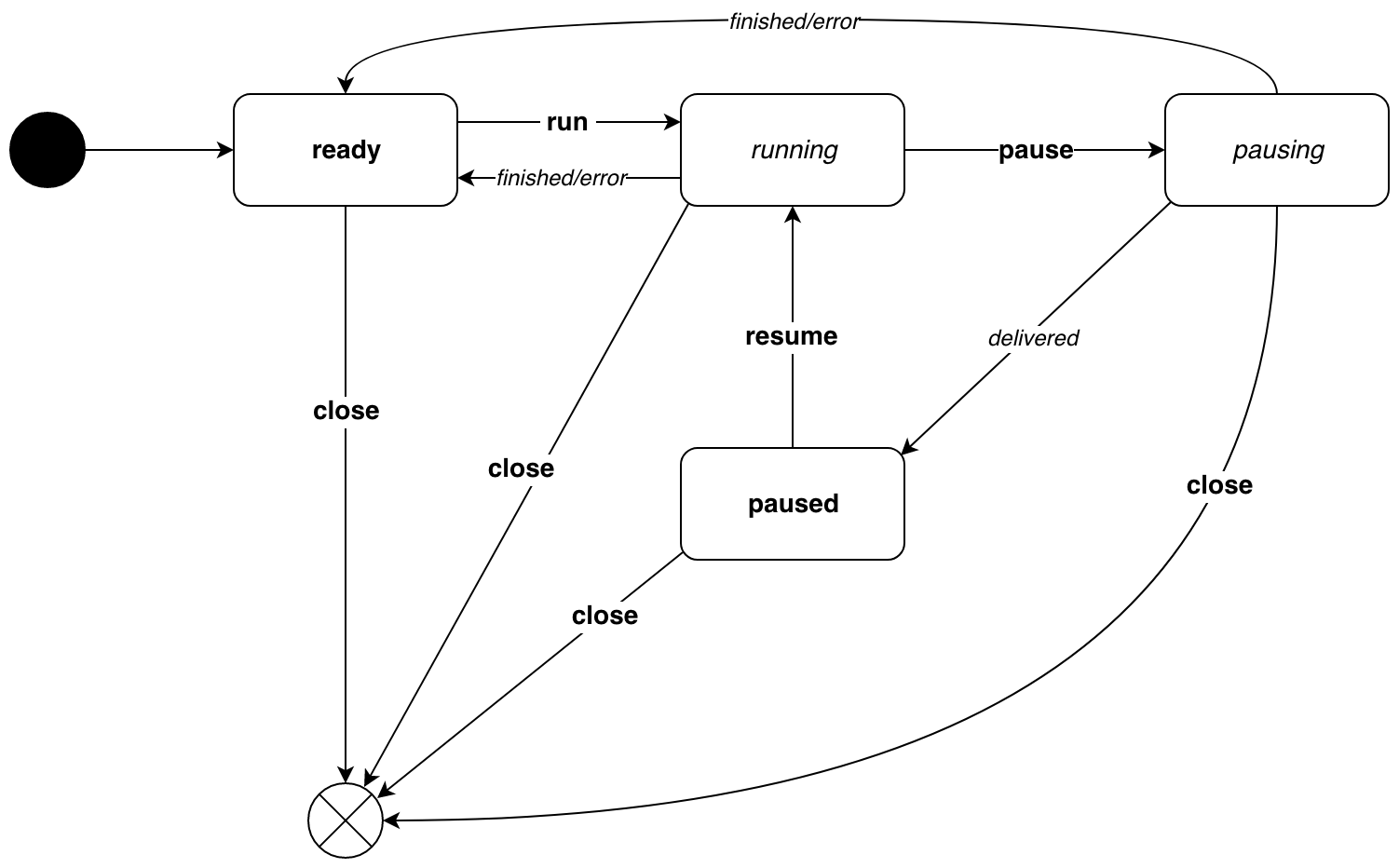
La cursiva indica transiciones causadas por la lógica de ejecución interna. Negrita : transiciones causadas por eventos. El diagrama muestra que los estados se dividen en 2 tipos:
- estados inactivos :
ready y en paused , solo puede saltar de ellos por evento - estados activos :
running y pausing , transiciones por evento y debido a la lógica de ejecución
Antes de un análisis detallado del código, un claro ejemplo del uso de todos los estados:
Ahora, lo primero es lo primero.
Todo el código fuente está disponible en el repositorio .
Estados y eventos
Comencemos con lo más importante.
Gracias a tipos separados, las transiciones también se declaran por separado para cada estado. Esto evita lo enorme salchichas funciones de transición con switch anidadas. Los estados en sí no contienen ningún dato o lógica. Para ellos, puede declarar variables a nivel de paquete para que no lo haga todo el tiempo. La interfaz de state es necesaria para el polimorfismo. activeState de activeState e idleState poco más tarde.
La segunda parte más importante de nuestra máquina son los eventos.
Para comprender por qué se necesita el tipo de target , considere un ejemplo simple. Hemos creado un nuevo transportador, está ready . Ahora ejecútelo con p.Run() . El evento de run se envía a la máquina, la tubería pasa al estado de running . ¿Cómo saber cuándo se termina el transportador? Aquí es donde el tipo de target nos ayudará. Indica qué estado de descanso esperar después del evento. En nuestro ejemplo, una vez completado el trabajo, la tubería volverá a entrar en el estado ready . Lo mismo en el diagrama:
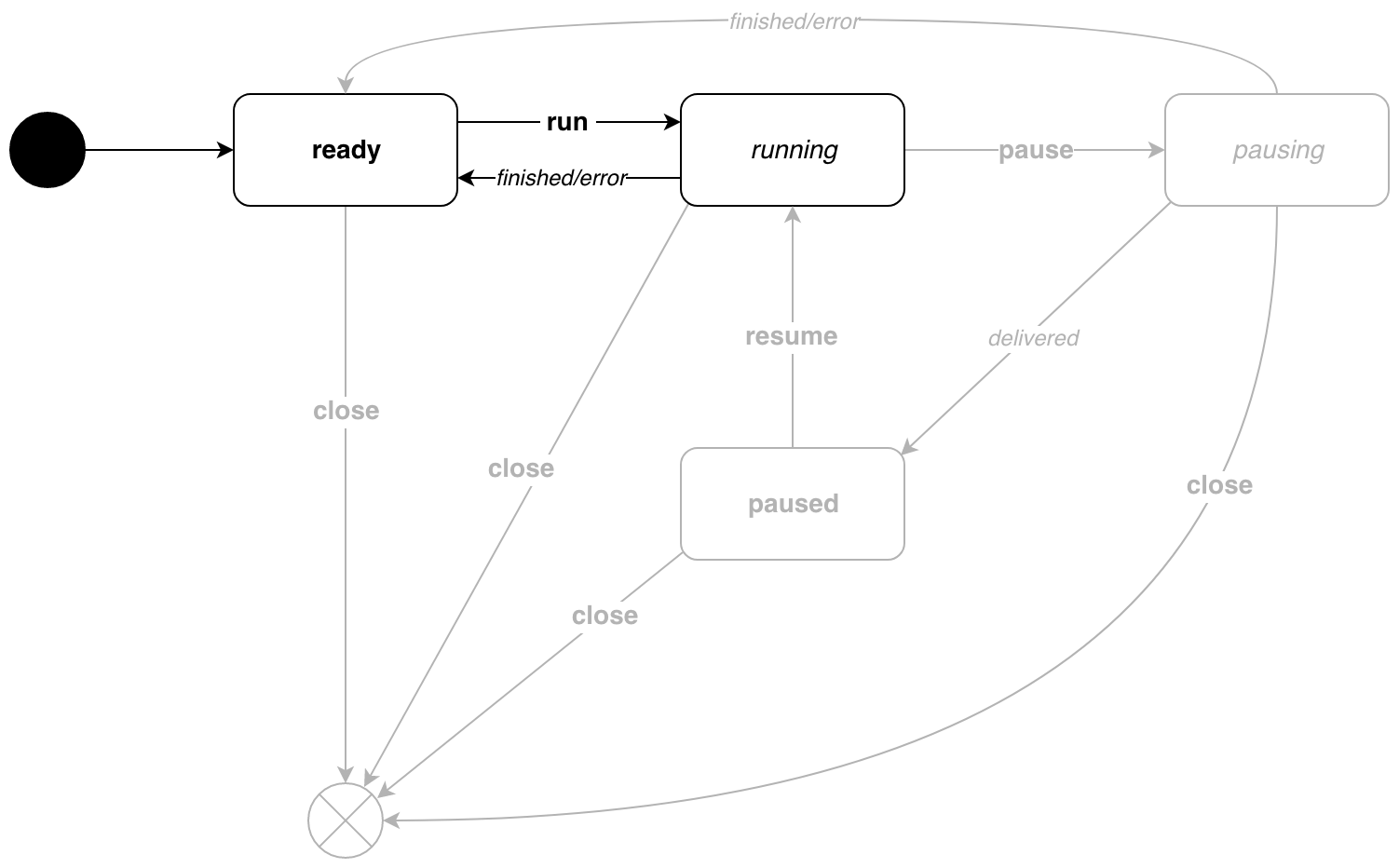
Ahora más sobre los tipos de estados. Más precisamente, sobre las activeState idleState y activeState . Veamos las funciones de listen(*Pipe, target) (state, target) para diferentes tipos de etapas:
pipe.Pipe tiene diferentes funciones para esperar una transición. Que hay
Por lo tanto, podemos escuchar diferentes canales en diferentes estados. Por ejemplo, esto le permite no enviar mensajes durante una pausa, simplemente no escuchamos el canal correspondiente.
Constructor y arranque de la máquina.
Además de la inicialización y las opciones funcionales , existe el inicio de una rutina de rutina separada con el ciclo principal. Bueno, míralo:
El transportador se crea y se congela en previsión de eventos.
Hora de trabajar
Llame a p.Run() !
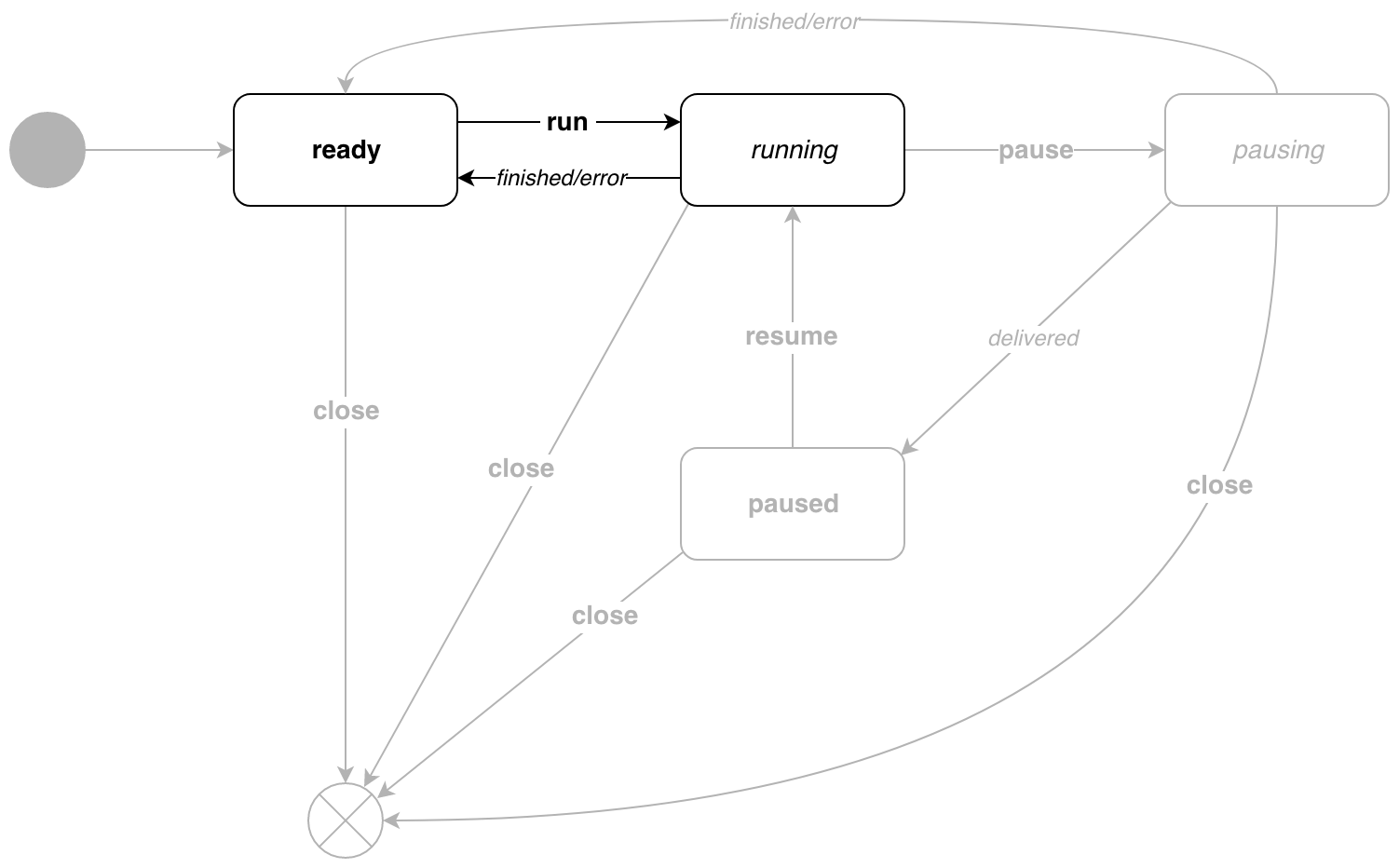
running genera mensajes y se ejecuta hasta que se complete la canalización.
Pausa
Durante la ejecución del transportador, podemos pausarlo. En este estado, la canalización no generará nuevos mensajes. Para hacer esto, llame al método p.Pause() .
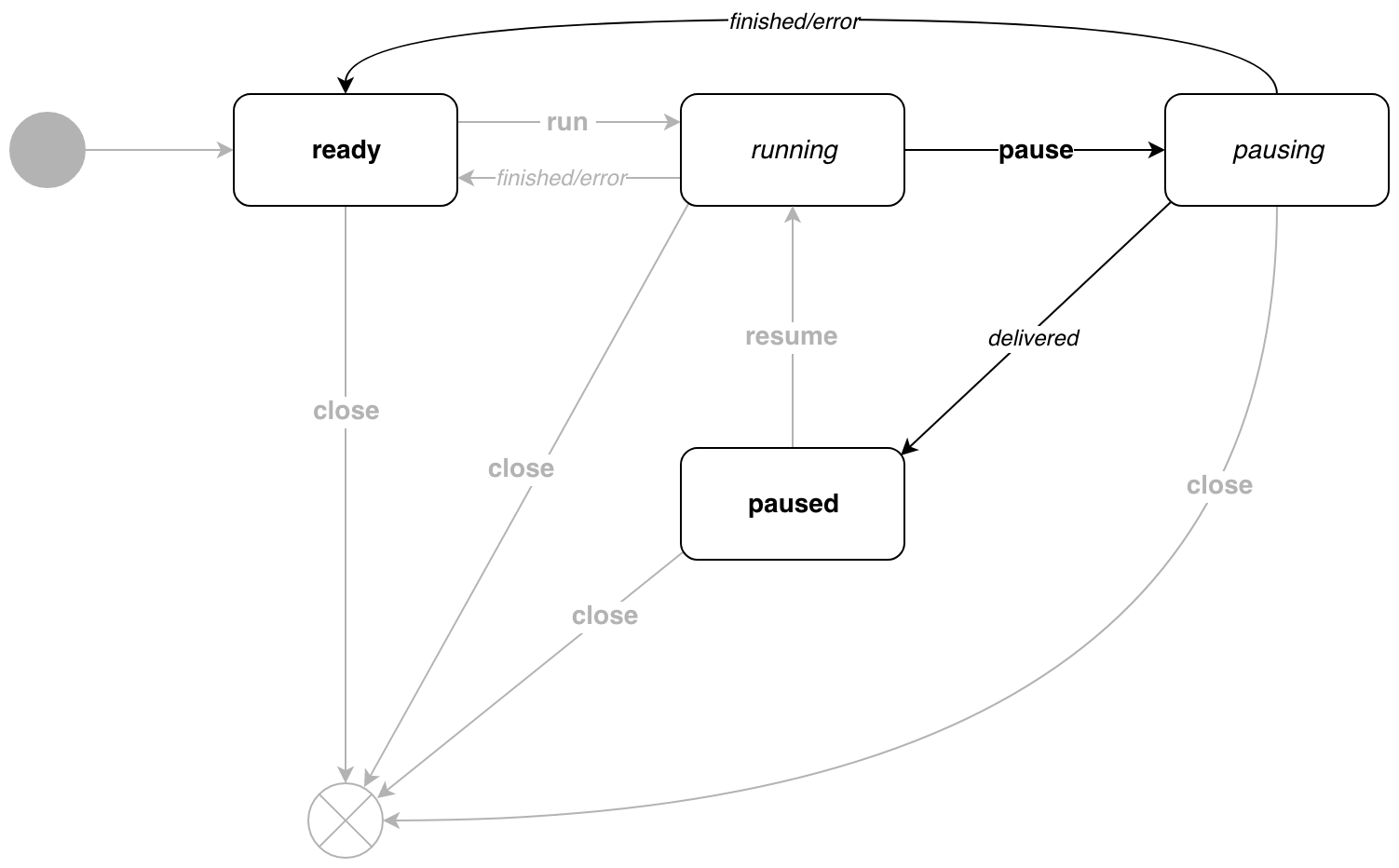
Tan pronto como todos los destinatarios reciban el mensaje, la canalización entrará paused estado de paused . Si el mensaje es el último, se producirá la transición al estado ready .
De vuelta al trabajo!
Para salir del estado en paused , llame a p.Resume() .
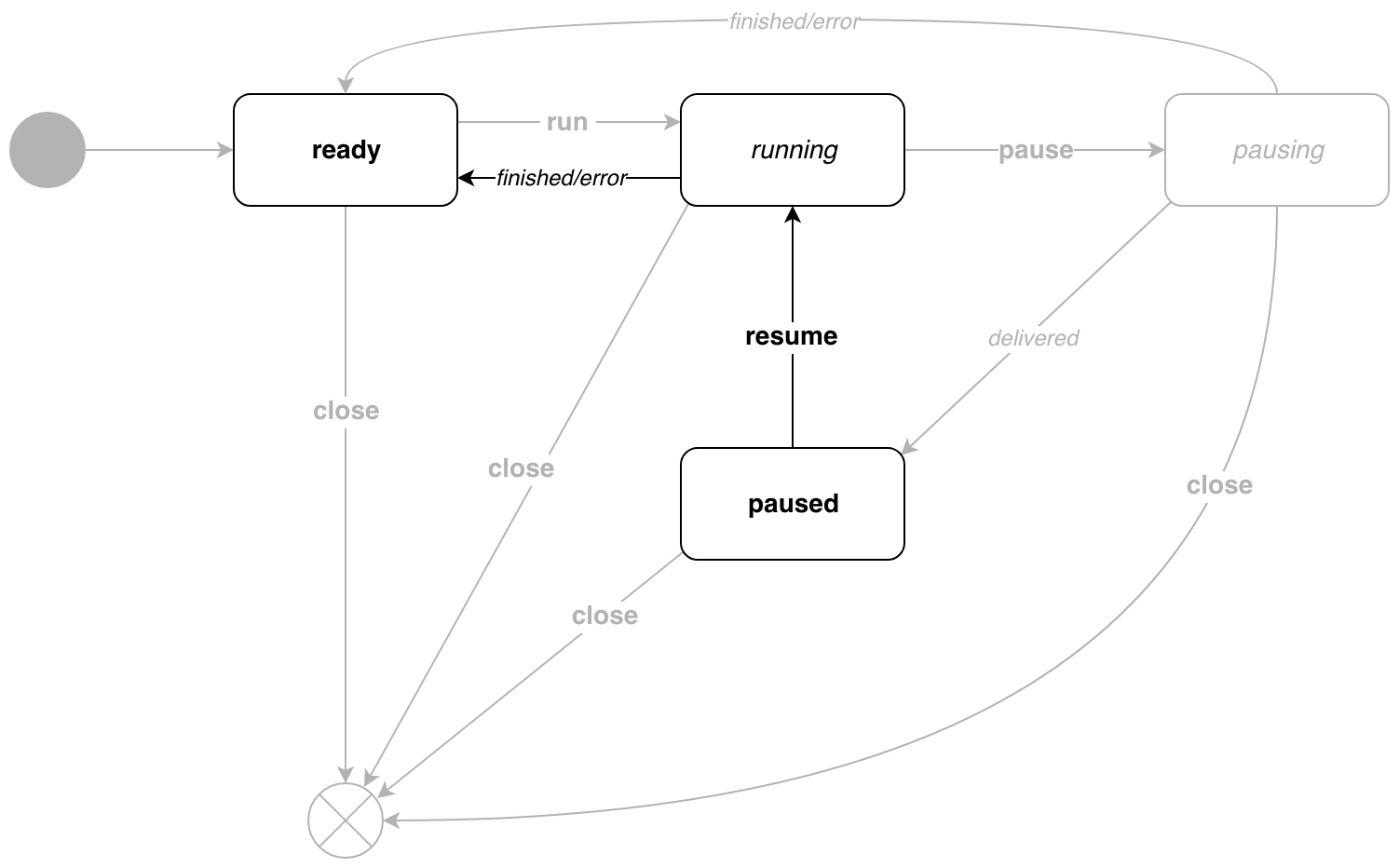
Aquí todo es trivial, la tubería vuelve a running .
Acurrucarse
El transportador se puede detener desde cualquier estado. Hay p.Close() .
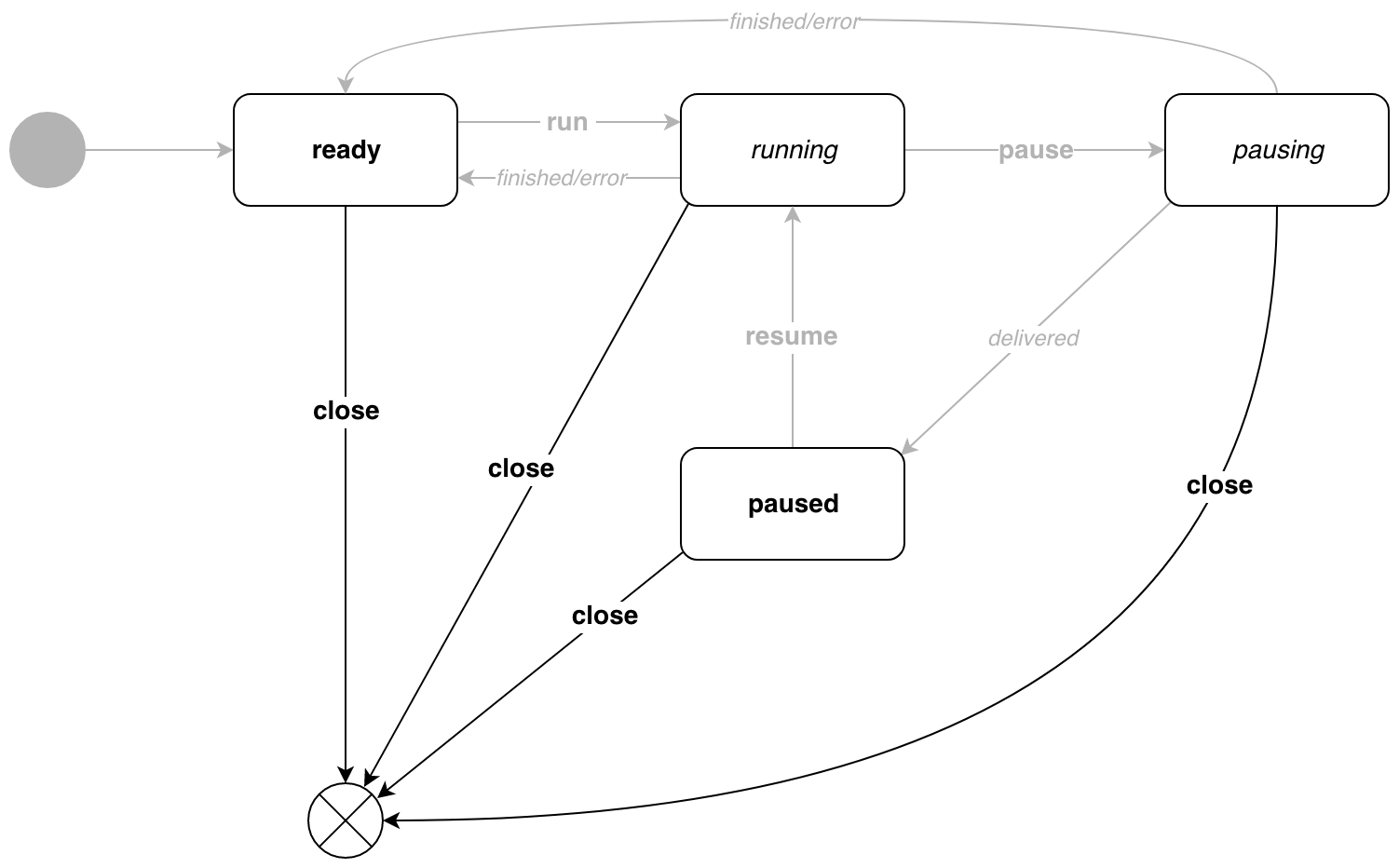
¿Quién necesita esto?
No es para todos. Para comprender exactamente cómo administrar el estado, debe comprender su tarea. Hay exactamente dos circunstancias en las que puede usar una máquina asincrónica basada en eventos:
- Ciclo de vida complejo: hay tres o más estados con transiciones no lineales.
- Se utiliza la ejecución asincrónica.
Aunque la máquina de eventos resuelve el problema, es un patrón bastante complicado. Por lo tanto, debe usarse con mucho cuidado y solo después de una comprensión completa de todos los pros y los contras.
Referencias