
Recientemente, un cliente nos solicitó implementar un sistema de contabilidad de capacidad de disco. La tarea consistía en combinar información de más de setenta matrices de discos de diferentes proveedores, desde conmutadores SAN y hosts VMware ESX. Luego, los datos debían ser sistematizados, analizados y mostrados en un tablero de mandos y varios informes, por ejemplo, sobre el volumen libre y ocupado de espacio en disco en todas las matrices tomadas por separado.
Decidimos implementar el proyecto utilizando el sistema de análisis operativo: Splunk.
¿Por qué derramar?
Splunk es poderoso para visualizar los datos que recopila. Le permite crear informes interactivos (paneles) actualizados en tiempo real. Mostramos información sobre el espacio total en disco en ellos, mostramos de inmediato todas las matrices con la capacidad de ordenar por diferentes filtros, por ejemplo, por capacidad. Al hacer clic en la matriz, inmediatamente obtenemos información sobre todas las conexiones. En un panel separado, puede ingresar el nombre de la máquina virtual y ver en qué host ESX vive, de qué matrices recibe datos y otros parámetros.
En mi opinión, hasta ahora Splunk no tiene análogos que funcionen con cualquier sistema de almacenamiento fuera de la caja. Hace unos años, apareció el CommandCentral pagado, pero no tiene la flexibilidad necesaria, no sabe cómo generar informes arbitrarios (en las primeras versiones de los informes no había ninguno) y con una visualización poco convincente. En general, esta no es una herramienta para el inventario, sino para monitorear y controlar el estado de los sistemas. Para cumplir con la tarea establecida por el cliente, tendría que ser refinada durante mucho tiempo y costosa.
Al mismo tiempo, Splunk tiene impresionantes capacidades de visualización de información: los gráficos se pueden organizar libremente entre ellos, controlar el estado de todos los sistemas en un modo de ventana única y, por lo tanto, simplificar su mantenimiento. Para todo lo demás, para nuestra tarea utilizamos la versión gratuita.

Que hiciste
Hasta este momento, nuestro equipo no tenía experiencia con Splunk. Afortunadamente, el sistema resultó ser amigable e intuitivo, y las soluciones a problemas emergentes se encontraron fácilmente con ayuda regular o en un motor de búsqueda.
Splunk ha creado una serie de herramientas que necesitamos. Por ejemplo, el sistema le permite combinar datos de diferentes fuentes para cualquier campo a través de las llamadas búsquedas (directorios). Entonces, en una tabla, los hosts ESX se mostraban como IP, en otra, como nombres DNS. Al principio, queríamos crear una búsqueda casera y usar la utilidad nslookup para seleccionar registros DNS y recopilar tablas, pero resultó que Splunk tiene un directorio que compara DNS sobre IP y viceversa. Esta búsqueda incorporada no tiene que configurarse, extrae datos sobre los servidores DNS de la configuración del sistema, y no importa si es Windows o Linux, y los datos en los registros DNS siempre están actualizados.

Uno de los escenarios interesantes implementados con Splunk es el control de cambios (RFC) en el sistema. Por ejemplo, un administrador de RFC recibe una solicitud de un ingeniero para dar servicio a uno de los conmutadores SAN. Ingresa el nombre del conmutador en Splunk y ve qué almacenamientos están conectados a él y qué servidores reciben datos de estos almacenamientos. Al mismo tiempo, el gerente ve el plan de trabajo que escribió el ingeniero y puede evaluar cómo deshabilitar este interruptor durante el mantenimiento afectará el rendimiento de los arreglos y los servidores.
Configuramos la carga diaria de información sobre la conexión de todos los conmutadores y matrices a Splunk. El cliente está satisfecho con esta tasa de actualización. Él ya tenía una herramienta de monitoreo Stor2RRD, pero no sabe cómo combinar datos de diferentes fuentes y visualizarlos. Por lo tanto, configuramos el sistema de adquisición de datos en Splunk de la siguiente manera:
- Recibimos información sobre almacenamientos de Stor2RRD;
- De los conmutadores recibimos información sobre SAN;
- A través de vCenter usando scripts de PowerCLI, recopilamos datos de los hosts ESX.
Los datos recibidos se llevan automáticamente a un solo formulario, se procesan y se muestran en forma de los informes necesarios.
¿Con qué tuviste que pelear?
Splunk es un sistema poderoso, pero hay tareas que no se pueden resolver de inmediato, y para resolver algunos problemas, necesitamos un conocimiento profundo de VMware.
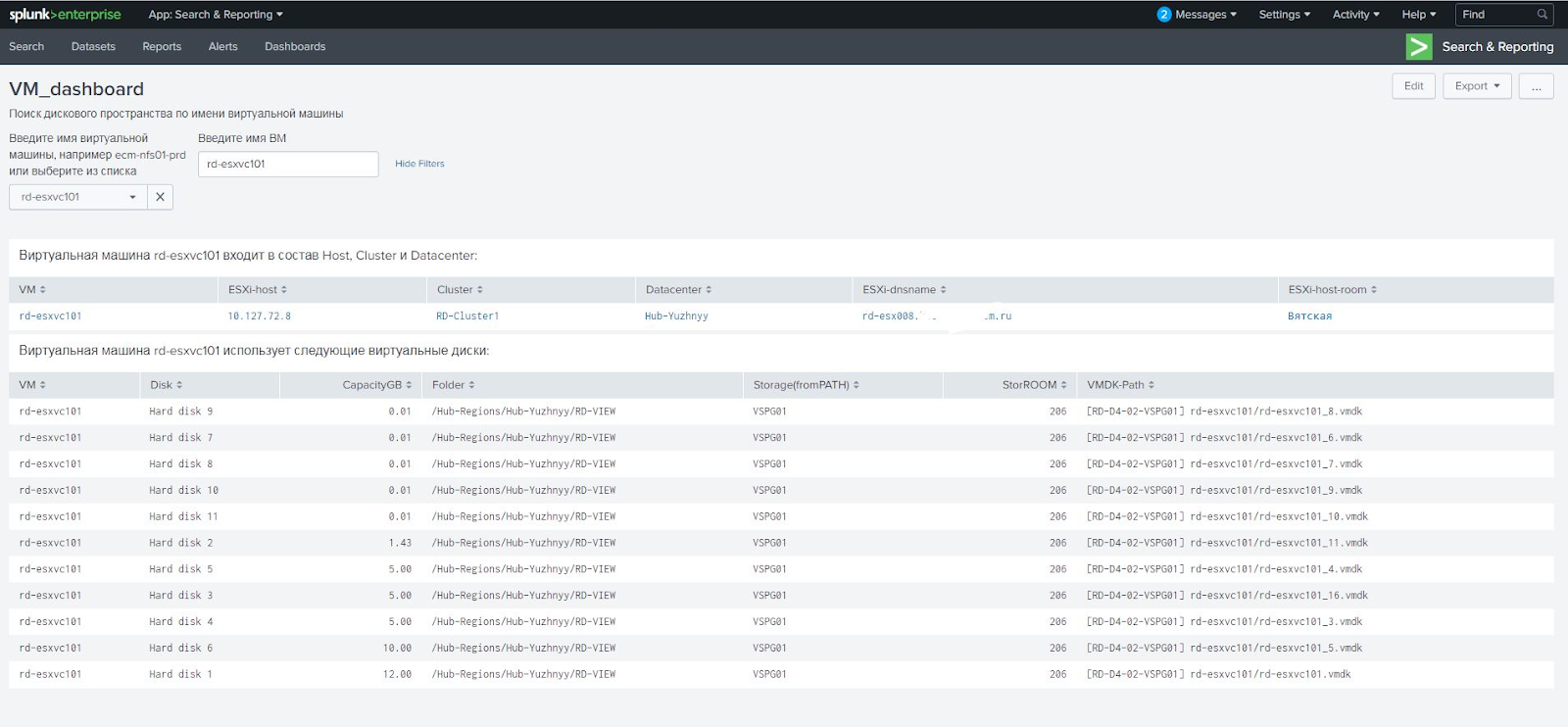
Por ejemplo, un cliente utiliza discos RDM asignados directamente y almacenes de datos virtuales virtuales para máquinas virtuales. Estos dos tipos de unidades deben manejarse de manera diferente. Al principio, resolvimos el problema por nuestra cuenta, pero luego nos enfrentamos a una situación en la que la máquina virtual recibió tanto discos RAW como discos virtuales. Resultó que recibíamos el campo Path incorrecto en el informe de vCenter y el enlace incorrecto a la matriz de discos RAW. El esquema funciona con almacenes de datos ordinarios, pero no funciona con discos RAW. Para ellos, debe usar la propiedad de disco RAW Disk ID, que contiene el atributo de disco. Tuve que recurrir a expertos de VMware que rehicieron el script para que calcule la matriz correcta a través de la ID de disco RAW.
Además, no aprendimos de inmediato cómo trabajar de manera óptima con los scripts de PowerCLI, luego los algoritmos tuvieron que desarrollarse más. Inicialmente, ¡los scripts procesaron datos de varios miles de máquinas virtuales durante un tiempo de hasta tres horas! Después del refinamiento, la duración de los guiones se redujo a cuarenta minutos.
Cual es el resultado?
Al no tener experiencia con Splunk, implementamos rápidamente un sistema para la contabilidad de las capacidades de los discos, que recibe información de numerosas fuentes, la consolida y proporciona una amplia gama de gráficos convenientes e intuitivos. Si no ha tenido que elegir o crear dicho sistema antes, Splunk es un buen candidato para este rol. Funciona rápidamente, se configura de manera fácil y flexible y no requiere ningún conocimiento especializado para resolver la gran mayoría de las tareas.
Vladislav Semenov, Jefe del Grupo de Arquitectura de Sistemas, Centro de Diseño de Complejos de Computación, Jet Infosystems