 datacenterknowledge.com
datacenterknowledge.comEl año pasado, se implementó la instalación de almacenamiento basada en RAIDIX más grande en este momento. Se implementó un sistema de 11 clústeres de conmutación por error en el Instituto RIKEN de Ciencias de la Computación (Japón). El objetivo principal del sistema es el HPC Infrastructure Storage (HPCI), que se implementa como parte del proyecto de intercambio de información de intercambio académico a gran escala Academic Cloud (basado en la red SINET).
Una característica importante de este proyecto es su volumen total de 65 PB, de los cuales el volumen utilizable del sistema es 51.4 PB. Para comprender mejor este valor, agregamos que se trata de 6512 discos de 10 TB cada uno (el más moderno en el momento de la instalación). Esto es mucho
El trabajo en el proyecto continuó durante todo el año, después de lo cual el monitoreo de la estabilidad del sistema continuó durante aproximadamente un año. Los indicadores obtenidos cumplieron con los requisitos establecidos, y ahora podemos hablar sobre el éxito de este registro y un proyecto significativo para nosotros.
Supercomputadora en el Centro de Computación del Instituto RIKEN
Para la industria de las TIC, el Instituto RIKEN es conocido principalmente por su legendaria "computadora K" (del japonés "kei", que significa 10 billones), que en el momento del lanzamiento (junio de 2011) era considerada la supercomputadora más poderosa del mundo.
Lea sobre la computadora K La supercomputadora ayuda al Centro de Ciencias Computacionales en la implementación de investigaciones complejas a gran escala: permite modelar el clima, las condiciones climáticas y el comportamiento molecular, calcular y analizar reacciones en física nuclear, predicción de terremotos y mucho más. Las capacidades de la supercomputadora también se utilizan para una investigación más "diaria" y aplicada, para buscar campos petroleros y pronosticar tendencias en los mercados bursátiles.
Dichos cálculos y experimentos generan una gran cantidad de datos, cuyo valor y significado no pueden ser sobreestimados. Para aprovechar al máximo esto, los científicos japoneses han desarrollado un concepto para un único espacio de información en el que los profesionales de HPC de diferentes centros de investigación tendrán acceso a los recursos de HPC recibidos.
Infraestructura informática de alto rendimiento (HPCI)
HPCI opera sobre la base de SINET (The Science Information Network), una red troncal para el intercambio de datos científicos entre universidades y centros de investigación japoneses. Actualmente, SINET reúne a unos 850 institutos y universidades, creando enormes oportunidades para el intercambio de información en investigaciones que afectan la física nuclear, la astronomía, la geodesia, la sismología y la informática.
HPCI es un proyecto de infraestructura único que forma un sistema unificado de intercambio de información en el campo de la informática de alto rendimiento entre universidades y centros de investigación en Japón.
Al combinar las capacidades de la supercomputadora "K" y otros centros de investigación en una forma accesible, la comunidad científica recibe beneficios obvios por trabajar con datos valiosos creados por la informática de la supercomputadora.
Con el fin de proporcionar un acceso efectivo de los usuarios conjuntos al entorno HPCI, se impusieron altos requisitos de almacenamiento para la velocidad de acceso. Y gracias a la "hiperproductividad" de la computadora K, se calculó que el clúster de almacenamiento en el Centro de Ciencias Computacionales del Instituto RIKEN se creó con un volumen de trabajo de al menos 50 PB.
La infraestructura del proyecto HPCI se construyó sobre la base del sistema de archivos Gfarm, que permitió proporcionar un alto nivel de rendimiento y combinar grupos de almacenamiento dispares en un solo espacio compartido.
Sistema de archivos Gfarm
Gfarm es un sistema de archivos distribuidos de código abierto desarrollado por ingenieros japoneses. Gfarm es el fruto del desarrollo del Instituto de Ciencia y Tecnología Industrial Avanzada (AIST), y el nombre del sistema se refiere a la arquitectura utilizada por Grid Data Farm.
Este sistema de archivos combina una serie de propiedades aparentemente incompatibles:
- Alta escalabilidad en volumen y rendimiento.
- Distribución de redes de larga distancia con soporte para un solo espacio de nombres para varios centros de investigación diversos.
- Soporte de API POSIX
- Alto rendimiento requerido para computación paralela
- Seguridad de almacenamiento de datos
Gfarm crea un sistema de archivos virtual utilizando recursos de almacenamiento de múltiples servidores. El servidor de metadatos distribuye los datos y el esquema de distribución en sí está oculto para los usuarios. Debo decir que Gfarm consiste no solo en un clúster de almacenamiento, sino también en una cuadrícula computacional que utiliza los recursos de los mismos servidores. El principio de funcionamiento del sistema se parece a Hadoop: el trabajo enviado se "baja" al nodo donde se encuentran los datos.
La arquitectura del sistema de archivos es asimétrica. Los roles están claramente asignados: Servidor de almacenamiento, Servidor de metadatos, Cliente. Pero al mismo tiempo, los tres roles pueden ser realizados por la misma máquina. Los servidores de almacenamiento almacenan muchas copias de archivos y los servidores de metadatos funcionan en modo maestro-esclavo.
Proyecto de trabajo
Core Micro Systems, un socio estratégico y proveedor exclusivo de RAIDIX en Japón, implementó la implementación en el Instituto RIKEN del Centro de Ciencias de la Computación. Para implementar el proyecto, se necesitaron unos 12 meses de trabajo minucioso, en el que no solo los empleados de Core Micro Systems, sino también los especialistas técnicos del equipo de Reydix tomaron parte activa.
Al mismo tiempo, la transición a otro sistema de almacenamiento parecía poco probable: el sistema existente tenía muchos enlaces técnicos que complicaban la transición a cualquier nueva marca.
Durante largas pruebas, comprobaciones y mejoras, RAIDIX ha demostrado un alto rendimiento y una eficiencia consistentes al trabajar con una cantidad de datos tan impresionante.
Sobre las mejoras vale la pena contar un poco más. Era necesario no solo crear la integración de los sistemas de almacenamiento con el sistema de archivos Gfarm, sino también expandir algunas características funcionales del software. Por ejemplo, para cumplir con los requisitos establecidos de las especificaciones técnicas, era necesario desarrollar e implementar la tecnología de escritura automática lo antes posible.
El despliegue del sistema en sí fue sistemático. Los ingenieros de Core Micro Systems realizaron con cuidado y precisión cada etapa de la prueba, aumentando gradualmente la escala del sistema.
En agosto de 2017, la primera fase de implementación se completó cuando el volumen del sistema alcanzó 18 PB. En octubre del mismo año, se implementó la segunda fase, en la cual el volumen aumentó a un récord de 51 PB.
Arquitectura de soluciones
La solución se creó a través de la integración de los sistemas de almacenamiento RAIDIX y el sistema de archivos distribuido Gfarm. En conjunto con Gfarm, la capacidad de crear almacenamiento escalable usando 11 sistemas RAIDIX de doble controlador.
La conexión a los servidores de Gfarm se realiza a través de 8 x SAS 12G.
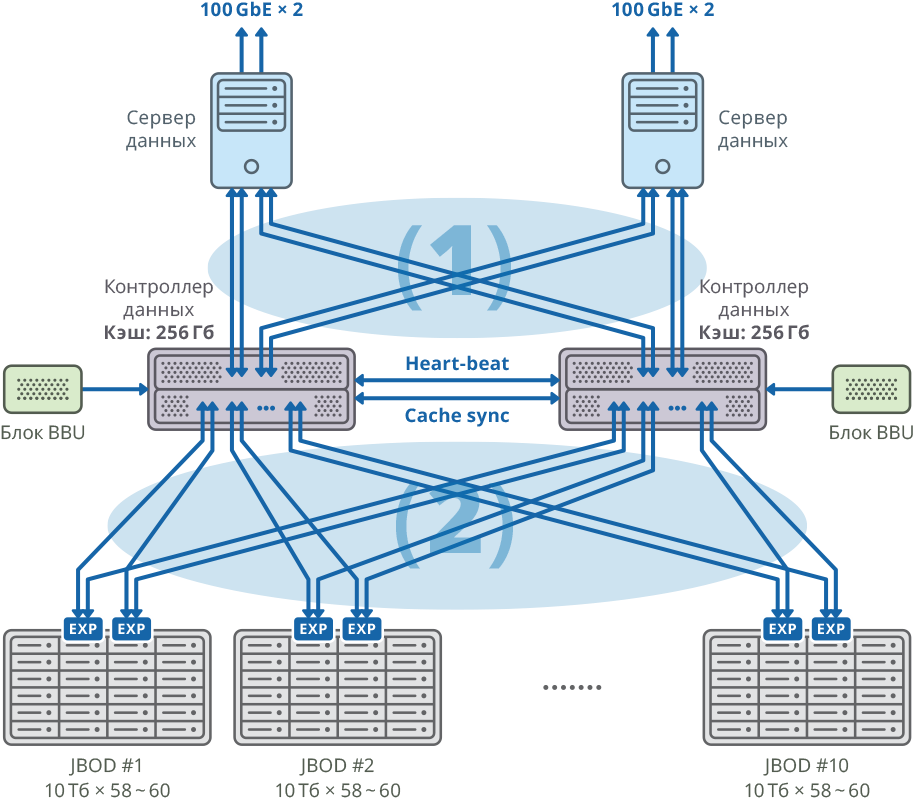 Fig. 1. Imagen de un clúster con un servidor de datos separado para cada nodo
Fig. 1. Imagen de un clúster con un servidor de datos separado para cada nodo(1) conexiones de malla SAN de 48 Gbps × 8; ancho de banda: 384 Gbps
(2) conexiones de TELA de malla de 48 Gbps × 40; ancho de banda: 1920Gbps
Configuración de plataforma de controlador dual
| CPU | Intel Xeon E5-2637 - 4 piezas |
| Placa base | Compatible con el modelo de procesador compatible con PCI Express 3.0 x8 / x16 |
| Caché interna | 256 GB para cada nodo |
| Chasis | 2U |
| Controladores SAS para conectar estanterías de discos, servidores y sincronización de caché de escritura | Broadcom 9305 16e, 9300 8e |
| HDD | HGST Helium 10TB SAS HDD |
| Sincronización de latidos | Ethernet 1 GbE |
| CacheSync Sync | 6 x SAS 12G |
Ambos nodos del clúster de conmutación por error están conectados a 10 JBOD (60 discos de 10 TB cada uno) a través de 20 puertos SAS 12G para cada nodo. En estos estantes de disco, se crearon 58 matrices RAID6 de 10 TB (8 discos de datos (D) + 2 discos de paridad (P)) y se asignaron 12 discos para “intercambio en caliente”.
10 JBOD => 58 × RAID6 (8 discos de datos (D) + 2 discos de paridad (P)), LUN de 580 HDD + 12 HDD para “intercambio en caliente” (2.06% del volumen total)
592 HDD (10TB SAS / 7.2k HDD) por cluster * HDD: HGST (MTBF: 2 500 000 horas)
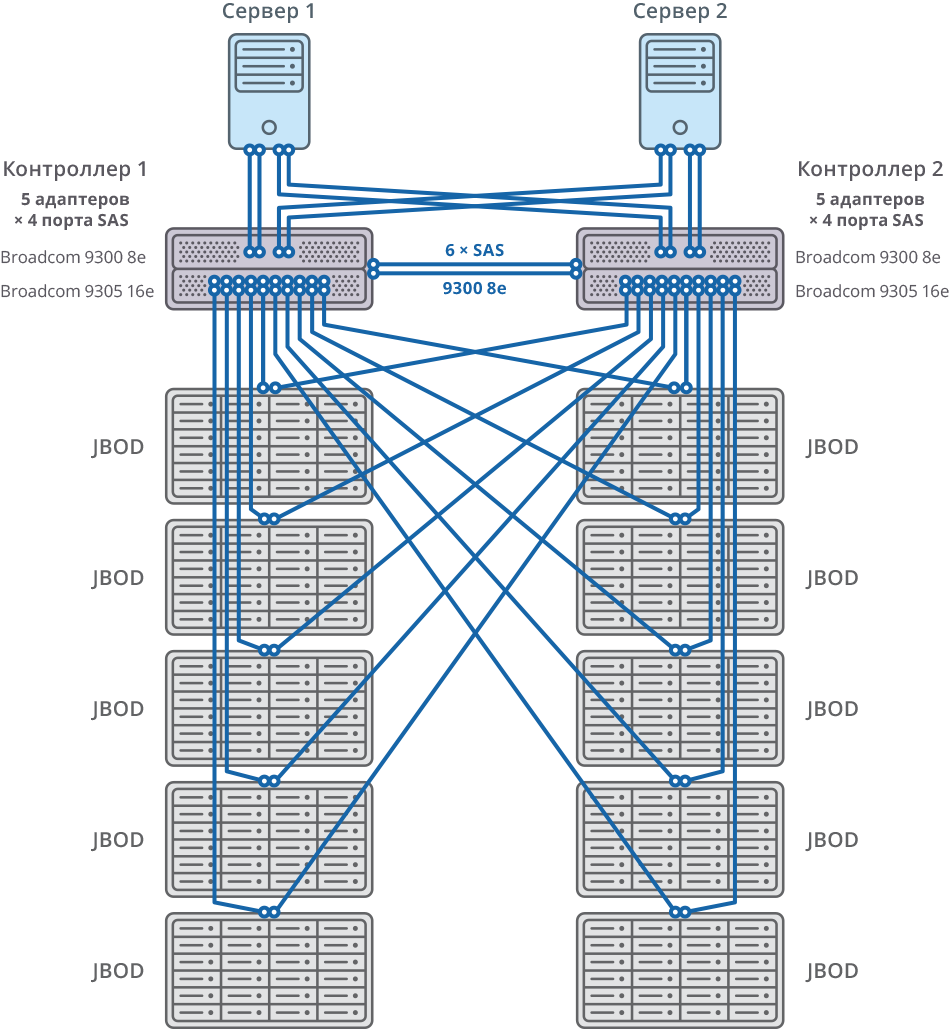 Fig. 2. Clúster de conmutación por error con diagrama de conexión 10 JBOD
Fig. 2. Clúster de conmutación por error con diagrama de conexión 10 JBODSistema general y diagrama de conexión
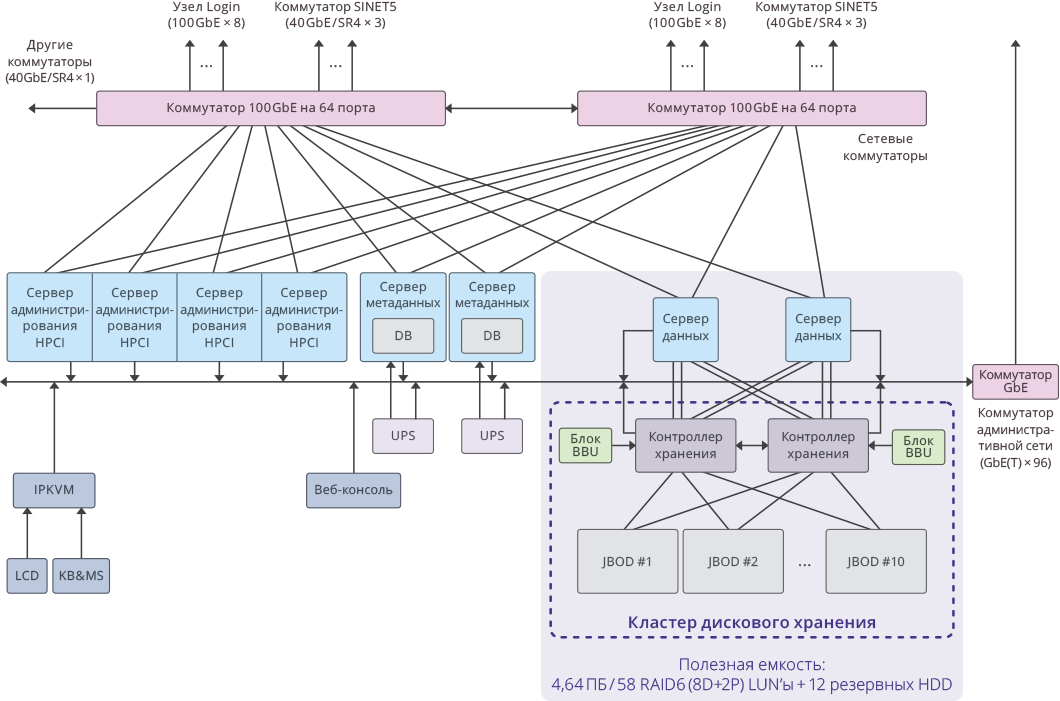 Fig. 3. Imagen de un solo clúster dentro del sistema HPCI
Fig. 3. Imagen de un solo clúster dentro del sistema HPCIIndicadores clave del proyecto
Capacidad utilizable por clúster: 4.64 PB ((RAID6 / 8D + 2P) LUN × 58)
La capacidad útil total de todo el sistema: 51.04 PB (4.64 PB × 11 grupos).
Capacidad total del sistema: 65 PB .
El rendimiento del sistema fue: 17 GB / s para escritura, 22 GB / s para lectura.
El rendimiento total del subsistema de disco del clúster en 11 sistemas de almacenamiento RAIDIX: 250 GB / s .