



Este artículo analiza las conversiones más interesantes que realiza una cadena de dos
transpiladores (el primero traduce el código de Python en código en el
nuevo lenguaje de programación 11l , y el segundo traduce el código en 11l en C ++), y también compara el rendimiento con otras herramientas de aceleración / Ejecución de código Python (PyPy, Cython, Nuitka).
Reemplazar rebanadas \ rebanadas con rangos
La indicación explícita para indexar desde el final de la matriz
s[(len)-2] lugar de solo
s[-2] necesaria para eliminar los siguientes errores:
- Cuando, por ejemplo, se requiere obtener el carácter anterior por
s[i-1] , pero para i = 0 tal / este registro en lugar de un error devolverá silenciosamente el último carácter de la cadena [ y en la práctica encontré un error de este tipo: commit ] . - La expresión
s[i:] después de i = s.find(":") funcionará incorrectamente cuando el carácter no se encuentre en la cadena [en lugar de '' parte de la cadena a partir del primer carácter : y luego '' se tomará el último carácter de la cadena ] (y generalmente , Creo que devolver -1 con la función find() en Python también es incorrecto [ debería devolver nulo / Ninguno [ y si se requiere -1, debería escribirse explícitamente: i = s.find(":") ?? -1 ] ] ) - Escribir
s[-n:] para obtener los últimos n caracteres de una cadena no funcionará correctamente cuando n = 0.
Cadenas de operadores de comparación
A primera vista, es una característica sobresaliente del lenguaje Python, pero en la práctica se puede abandonar / dispensar fácilmente utilizando el operador
in y los rangos:
Lista de comprensión
Del mismo modo, resultó que puede rechazar otra característica interesante de Python: la lista de comprensiones.
Mientras que algunos
glorifican la comprensión de la lista e incluso sugieren abandonar `filter ()` y `map ()` , descubrí que:
En todos los lugares donde he visto la comprensión de la lista de Python, puede pasar fácilmente con las funciones `filter ()` y `map ()`. dirs[:] = [d for d in dirs if d[0] != '.' and d != exclude_dir] dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) '[' + ', '.join(python_types_to_11l[ty] for ty in self.type_args) + ']' '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']'
`filter ()` y `map ()` en 11l parecen más bonitos que en Python dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) dirs = dirs.filter(d -> d[0] != '.' & d != @exclude_dir) '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']' '['(.type_args.map(ty -> :python_types_to_11l[ty]).join(', '))']' outfile.write("\n".join(x[1] for x in fileslist if x[0])) outfile.write("\n".join(map(lambda x: x[1], filter(lambda x: x[0], fileslist)))) outfile.write(fileslist.filter(x -> x[0]).map(x -> x[1]).join("\n"))
y, en consecuencia, la necesidad de comprensión de la lista en 11l en realidad desaparece [el reemplazo de la comprensión de la lista con filter() y / o map() se realiza durante la conversión del código de Python en 11l automáticamente ] .
Convierta la cadena if-elif-else para cambiar
Si bien Python no contiene una declaración de cambio, esta es una de las construcciones más bellas de 11l, por lo que decidí insertar el cambio automáticamente:
Para completar, aquí está el código C ++ generado switch (instr[i]) { case u'[': nesting_level++; break; case u']': if (--nesting_level == 0) goto break_; break; case u''': ending_tags.append(u"'"_S); break; // '' case u''': assert(ending_tags.pop() == u'''); break; }
Convierta pequeños diccionarios a código nativo
Considere esta línea de código Python:
tag = {'*':'b', '_':'u', '-':'s', '~':'i'}[prev_char()]
Lo más probable es que esta forma de grabación no sea muy efectiva
[ en términos de rendimiento ] , pero es muy conveniente.
En 11l, la entrada correspondiente a esta línea
[ y recibida por el transportador Python → 11l ] no solo es conveniente
[ sin embargo, no es tan elegante como en Python ] , sino también rápida:
var tag = switch prev_char() {'*' {'b'}; '_' {'u'}; '-' {'s'}; '~' {'i'}}
La línea anterior se traduce en:
auto tag = [&](const auto &a){return a == u'*' ? u'b'_C : a == u'_' ? u'u'_C : a == u'-' ? u's'_C : a == u'~' ? u'i'_C : throw KeyError(a);}(prev_char());
[ La llamada a la función lambda será compilada por el compilador de C ++ \ en línea durante el proceso de optimización y solo permanecerá la cadena de operadores ?/: ]En el caso de que se asigne una variable, el diccionario se deja como está:
Capturar \ Capturar variables externas
En Python, para indicar que una variable no es local, sino que debe tomarse fuera
[ de la función actual ] , se usa la palabra clave no local
[de lo contrario, por ejemplo, found = True se tratará como la creación de una nueva variable local found , en lugar de asignar un valor ya variable externa existente ] .
En 11l, el prefijo @ se usa para esto:
C ++:
auto writepos = 0; auto write_to_pos = [..., &outfile, &writepos](const auto &pos, const auto &npos) { outfile.write(...); writepos = npos; };
Variables globales
Similar a las variables externas, si olvida declarar una variable global en Python
[ usando la palabra clave global ] , obtendrá un error invisible:
El código 11l
[ derecha ] , a diferencia de Python
[ izquierda ], break_label_index error 'variable no declarada
break_label_index ' en
break_label_index compilación.
Índice / número del artículo contenedor actual
Sigo olvidando el orden de las variables que devuelve la función
enumerate Python {el valor viene primero, luego el índice, o viceversa}. El comportamiento analógico en Ruby -
each.with_index - es mucho más fácil de recordar: con index significa que el índice viene después del valor, no antes. Pero en 11l, la lógica es aún más fácil de recordar:
Rendimiento
El
programa para convertir el marcado de PC a HTML se usa como un
programa de prueba, y el código fuente del
artículo sobre marcado de PC se usa como datos de origen
[ ya que este artículo es actualmente el más grande de los escritos en marcado de PC ] , y se repite 10 veces, es decir obtenido a partir de 48.8 kilobytes de tamaño de archivo de artículo 488Kb.
Aquí hay un diagrama que muestra cuántas veces la forma correspondiente de ejecutar el código Python es más rápida que la implementación original
[ CPython ] :
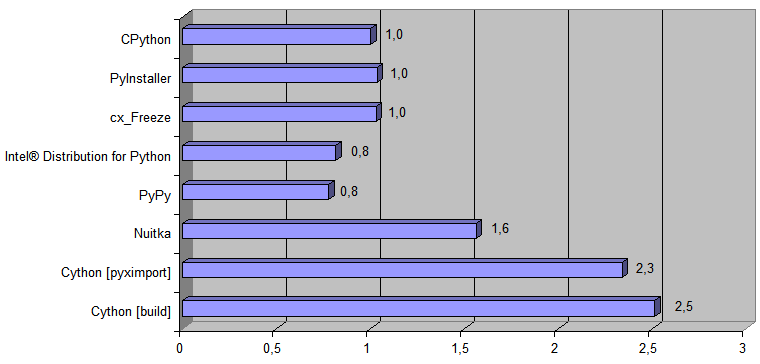
Y ahora agregue al diagrama la implementación generada por el transpilador Python → 11l → C ++: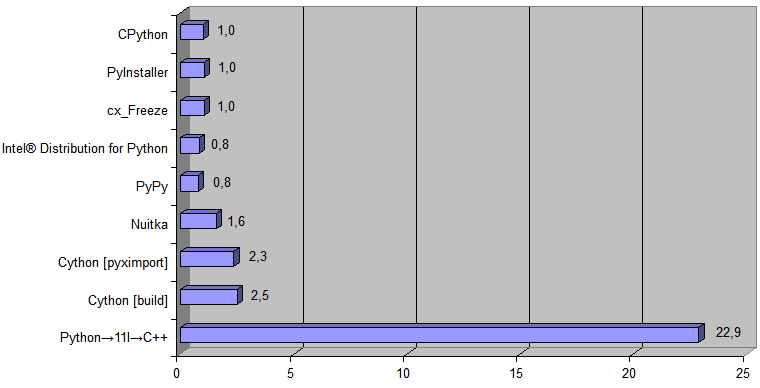
El tiempo de ejecución
[ tiempo de conversión de archivo de 488Kb ] fue de 868 ms para CPython y 38 ms para el código C ++ generado
[ esta vez incluye el pleno [ es decir no solo trabajando con datos en RAM ] ejecutando el programa por el sistema operativo y todas las entradas / salidas [ leyendo el archivo fuente [ .pq ] y guardando el nuevo archivo [ .html ] en el disco ] ] .
También quería probar
Shed Skin , pero no admite funciones locales.
Numba tampoco se pudo usar (arroja un error 'Uso de código de operación desconocido LOAD_BUILD_CLASS').
Aquí está el archivo con el programa utilizado para comparar el rendimiento
[ en Windows ] (requiere Python 3.6 o superior y los siguientes paquetes de Python: pywin32, cython).
Código fuente en Python y salida de transpiladores Python -> 11l y 11l -> C ++: