Ejemplos de reconstrucción de un fragmento de video comprimido por diferentes códecs con aproximadamente el mismo valor de BPP (bits por píxel). Los resultados de las pruebas comparativas se encuentran en cat.Los investigadores de WaveOne
afirman estar cerca de una revolución en la compresión de video. Al procesar video de alta definición de 1080p, su
nuevo códec de aprendizaje automático comprime el video aproximadamente un 20% mejor que los códecs de video tradicionales más modernos como H.265 y VP9. Y en un video de “definición estándar” (SD / VGA, 640 × 480), la diferencia alcanza el 60%.
Los desarrolladores llaman a los métodos actuales de compresión de video, implementados en H.265 y VP9, "antiguos" según los estándares de las tecnologías modernas: "En los últimos 20 años, los fundamentos de los algoritmos de compresión de video existentes no han cambiado significativamente", escriben los autores del artículo científico en la introducción de su artículo. "Aunque están muy bien diseñados y cuidadosamente ajustados, permanecen codificados y, como tales, no se pueden adaptar a la creciente demanda y a una gama cada vez más versátil de aplicaciones para materiales de video, que incluyen el intercambio en las redes sociales, detección de objetos, transmisión de realidad virtual, etc."
El uso del aprendizaje automático finalmente debería llevar la tecnología de compresión de video al siglo XXI. El nuevo algoritmo de compresión es significativamente superior a los códecs de video existentes. "Hasta donde sabemos, este es el primer método de aprendizaje automático que ha mostrado tal resultado", dicen.
La idea principal de la compresión de video es eliminar los datos redundantes y reemplazarlos con una descripción más corta que le permita reproducir el video más tarde. La mayor parte de la compresión de video tiene lugar en dos etapas.
La primera etapa es la compresión de movimiento, cuando el códec busca objetos en movimiento e intenta predecir dónde estarán en el siguiente cuadro. Luego, en lugar de grabar los píxeles asociados con este objeto en movimiento, en cada cuadro, el algoritmo codifica solo la forma del objeto junto con la dirección del movimiento. De hecho, algunos algoritmos miran cuadros futuros para determinar el movimiento con mayor precisión, aunque esto obviamente no funcionará para transmisiones en vivo.
El segundo paso de compresión elimina otras redundancias entre un cuadro y el siguiente. Por lo tanto, en lugar de registrar el color de cada píxel en el cielo azul, el algoritmo de compresión puede determinar el área de este color e indicar que no cambia en los próximos fotogramas. Por lo tanto, estos píxeles permanecen del mismo color hasta que se les indique que cambien. Esto se llama compresión residual.
El nuevo enfoque que los científicos han introducido utiliza el aprendizaje automático por primera vez para mejorar ambos métodos de compresión. Entonces, al comprimir el movimiento, los métodos de aprendizaje automático del equipo encontraron nuevas redundancias basadas en el movimiento, que los códecs convencionales nunca han podido detectar, y mucho menos usar. Por ejemplo, girar la cabeza de una persona de una vista frontal a un perfil siempre da un resultado similar: "Los códecs tradicionales no pueden predecir el perfil de una persona basándose en una vista frontal", escriben los autores del artículo científico. Por el contrario, el nuevo códec estudia estos tipos de patrones espacio-temporales y los usa para predecir marcos futuros.
Otro problema es la asignación del ancho de banda disponible entre el movimiento y la compresión residual. En algunas escenas, la compresión de movimiento es más importante, mientras que en otras, la compresión residual proporciona la mayor ganancia. El compromiso óptimo entre ellos difiere de cuadro a cuadro.
Los algoritmos tradicionales procesan ambos procesos por separado uno del otro. Esto significa que no hay una manera fácil de dar una ventaja a uno u otro y encontrar un compromiso.
Los autores evitan esto al comprimir ambas señales al mismo tiempo y, en función de la complejidad de la trama, determinan cómo distribuir el ancho de banda entre las dos señales de la manera más eficiente.
Estas y otras mejoras han permitido a los investigadores crear un algoritmo de compresión que supera con creces los códecs tradicionales (ver los puntos de referencia a continuación).
 Los ejemplos de reconstrucción de un fragmento comprimido por diferentes códecs con aproximadamente el mismo valor de BPP muestran una ventaja significativa del códec WaveOne
Los ejemplos de reconstrucción de un fragmento comprimido por diferentes códecs con aproximadamente el mismo valor de BPP muestran una ventaja significativa del códec WaveOne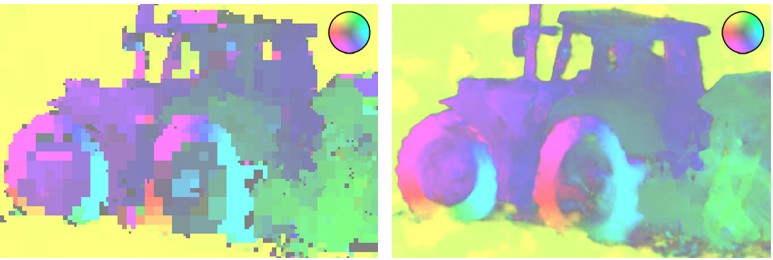 Tarjetas de flujo óptico H.265 (izquierda) y códec WaveOne (derecha) a la misma velocidad de bits
Tarjetas de flujo óptico H.265 (izquierda) y códec WaveOne (derecha) a la misma velocidad de bitsSin embargo, el nuevo enfoque no está exento de algunos inconvenientes,
señala el MIT Technology Review . Quizás el principal inconveniente es la baja eficiencia computacional, es decir, el tiempo requerido para codificar y decodificar el video. En la plataforma Nvidia Tesla V100 y en el video de tamaño VGA, el nuevo decodificador funciona a una velocidad promedio de aproximadamente 10 cuadros por segundo, y el codificador funciona a una velocidad de aproximadamente 2 cuadros por segundo. Tales velocidades son simplemente imposibles de usar en transmisiones de video en vivo, y con la codificación de materiales fuera de línea, el nuevo codificador tendrá un alcance muy limitado.
Además, la velocidad del decodificador no es suficiente incluso para
ver un video comprimido con este códec en una computadora personal normal. Es decir, para ver estos videos, incluso con una calidad SD mínima, actualmente se requiere un clúster informático completo con varios aceleradores gráficos. Y para ver videos en calidad HD (1080p), necesita una granja de computadoras completa.
Uno solo puede esperar un aumento en el poder de los procesadores gráficos en el futuro y mejorar la tecnología: "La velocidad actual no es suficiente para la implementación en tiempo real, pero debería mejorarse significativamente en el trabajo futuro", escriben.
Puntos de referencia
HEVC/H.265, AVC/H.264, VP9 HEVC HM 16.0 . Ffmpeg, — . , . , B- H.264/5
bframes=0,
-auto-alt-ref 0 -lag-in-frames 0 . MS-SSIM, ,
-ssim.
SD HD, . SD- VGA e Consumer Digital Video Library (CDVL). 34 15 650 . HD Xiph 1080p: 22 11 680 . 1080p 1024 ( , 32 ).
:
- MS-SSIM ;
- MS-SSIM ;
- WaveOne ( ).
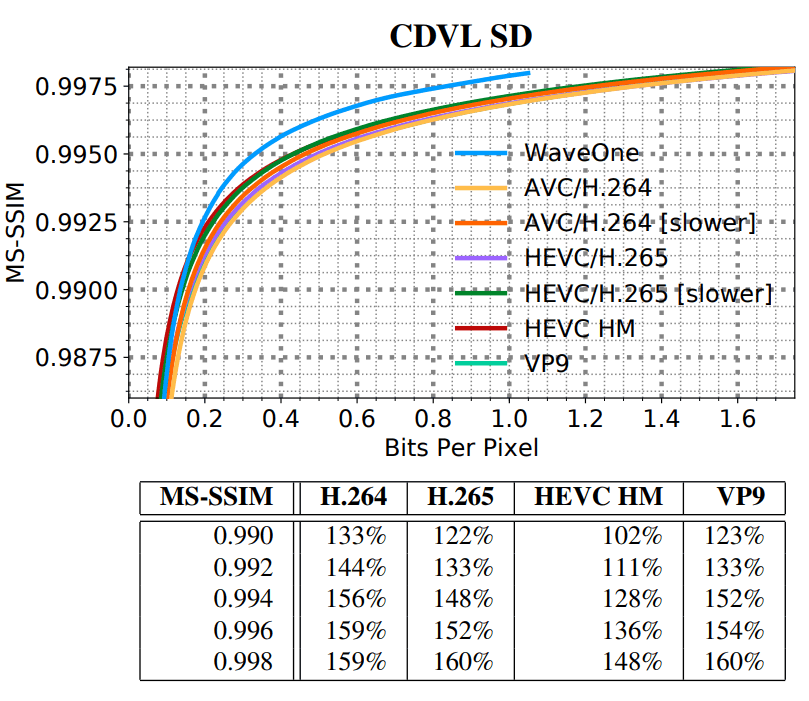 (SD)
(SD)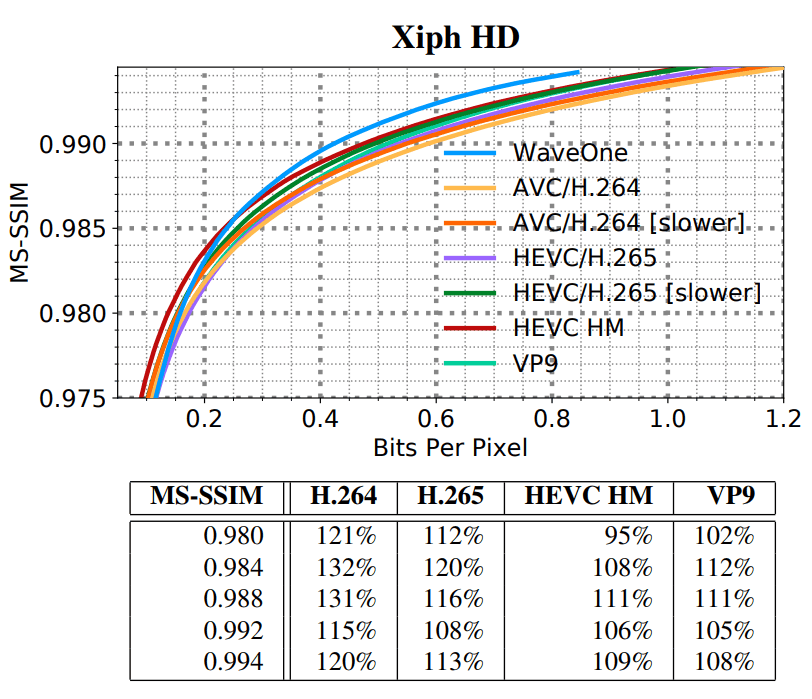 (HD)
(HD)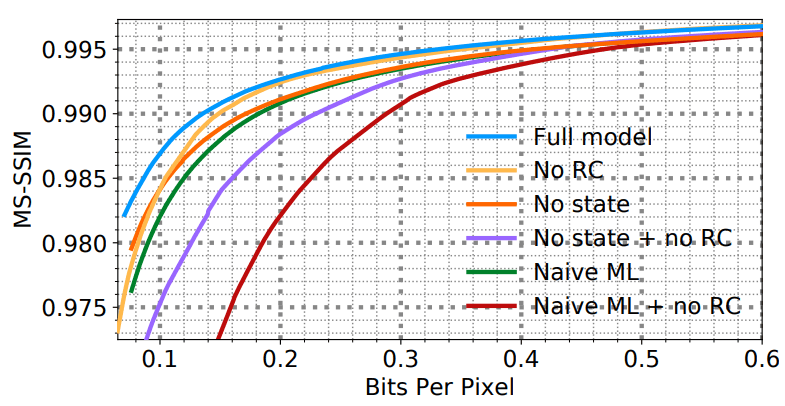 WaveOne
WaveOne. , . . , . G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, R. Sukthankar.
Variable rate image compression with recurrent neural networks, 2015; G. Toderici, D. Vincent, N. Johnston, S. J. Hwang, D. Minnen, J. Shor, M. Covell.
Full resolution image compression with recurrent neural networks, 2016; J. Balle, V. Laparra, E. P. Simoncelli.
End-to-end optimized image compression, 2016; N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, S. J. Hwang, J. Shor, G. Toderici.
Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks, 2017 . , , .
ML- , . . . C.-Y. Wu, N. Singhal, and P. Krahenbuhl.
Video compression through image interpolation, ECCV (2018). , . AVC/H.264. , .
« » 16 2018 arXiv.org (arXiv:1811.06981). — (Oren Rippel), (Sanjay Nair), (Carissa Lew), (Steve Branson), (Alexander G. Anderson), (Lubomir Bourdev).
Stas911:
Altaisky: . ?
Stas911: . .