
Un proyecto de integración de sistemas típico para nosotros se ve así: el cliente tiene un conjunto de sistemas para clientes de contabilidad, la tarea es recopilar las tarjetas de los clientes en una sola base de datos. Y no solo para recolectar, sino también para eliminar duplicados y basura. Para obtener tarjetas de clientes limpias, estructuradas y completas.
Para los principiantes, explicaré que la migración se realiza de acuerdo con este esquema:
fuentes → conversión de datos ( ETL o respuestas de bus ) → receptor .
En un proyecto, perdimos tres meses simplemente porque un equipo de integradores de terceros no estudió los datos en los sistemas fuente. Lo más molesto fue que esto podría haberse evitado.
Trabajaron así:
- Los integradores de sistemas personalizan el proceso ETL.
- ETL transforma los datos de origen y me los da.
- Estudio la descarga y envío errores a los integradores.
- Los integradores corrigen los ETL y comienzan la migración nuevamente.
En el artículo mostraré cómo analizar datos durante la integración del sistema. Estudié cargas ETL, fue muy útil. Pero en los datos de origen, las mismas técnicas acelerarían el trabajo dos veces.
Las sugerencias serán útiles para probadores, implementadores de productos empresariales, integradores de sistemas y analistas. Las recepciones son universales para las bases de datos relacionales, y se divulgan completamente en volúmenes de un millón de clientes.
Pero primero, sobre uno de los principales mitos de la integración de sistemas.
La documentación y el arquitecto ayudarán (en realidad no)
Los integradores a menudo no estudian los datos antes de la migración; ahorran tiempo. Leen la documentación, miran la estructura, hablan con el arquitecto, y eso es suficiente. Después de eso, ya están planeando la integración.
Resulta malo Solo el análisis mostrará lo que realmente está sucediendo en la base de datos. Si no ingresa a los datos con mangas enrolladas y una lupa, la migración saldrá mal.
La documentación está mintiendo. Un sistema empresarial típico funciona de 5 a 20 años. Todos estos años, los cambios han sido documentados por varios departamentos y contratistas. Cada uno con su propio campanario. Por lo tanto, no hay integridad en la documentación, nadie comprende completamente la lógica y la estructura del almacenamiento de datos. Sin mencionar que los plazos siempre están vigentes y no hay suficiente tiempo para la documentación.
Una historia común: en la tabla de clientes hay un campo "SNILS", en papel es muy importante. Pero cuando miro los datos, veo que el campo está vacío. Como resultado, el cliente acepta que la base objetivo no tendrá un campo para SNILS, ya que todavía no hay datos.
Un caso especial de documentación son las regulaciones y las descripciones de los procesos comerciales: cómo los datos ingresan a la base de datos, en qué circunstancias, en qué formato. Todo esto tampoco ayudará.
Los procesos comerciales son perfectos solo en papel. Temprano en la mañana, el somnoliento operador Anatoly entra a la oficina del banco en las afueras de Vyksa. Debajo de la ventana gritaron toda la noche, y por la mañana Anatoly tuvo una pelea con la niña. Odia al mundo entero.
Los nervios aún no se han puesto en orden, y Anatoly lleva completamente el nombre del nuevo cliente al campo de apellido. Se olvida por completo de su cumpleaños: el "01.01.1900 g" predeterminado permanece en el formulario. ¡¡¡No me importan las regulaciones cuando todo alrededor es tan enfurecedor !!!
El caos derrota los procesos comerciales que están muy bien formados en papel.
Un arquitecto de sistemas no lo sabe todo. Se trata nuevamente de la venerable vida útil de los sistemas empresariales. Con los años que trabajan, los arquitectos han cambiado. Incluso si habla con el actual, las decisiones de las anteriores serán sorpresas durante el proyecto.
Y asegúrese: incluso un arquitecto agradable en todos los aspectos mantendrá en secreto sus fakaps y muletas del sistema.
La integración "por instrumentos" sin análisis de datos es un error. Mostraré cómo en HFLabs aprendemos datos a través de la integración del sistema. En el último proyecto, solo analicé las cargas ETL. Pero cuando el cliente da acceso a los datos de origen, definitivamente lo verifico de acuerdo con los mismos principios.
Campos rellenos y valores nulos
Las comprobaciones más simples son la integridad de las tablas en general y la integridad de los campos individuales. Estoy empezando con ellos.
Cuántas filas totales hay en la tabla. La solicitud más simple posible.
SELECT COUNT(*) FROM <table_name>;
Obtengo el primer resultado.
Aquí miro la adecuación de los datos. Si solo dos millones de clientes llegaron a la descarga de un banco grande, entonces algo está claramente mal. Pero mientras todo se ve como se esperaba, sigue adelante.
Cuántas líneas se llenan para cada campo por separado. Reviso todas las columnas de la tabla.
SELECT <column_name>, COUNT(*) AS <column_name> cnt FROM <table_name> WHERE <column_name> IS NOT NULL;
El primero se encontró con un campo de feliz cumpleaños, e inmediatamente curioso: por alguna razón, los datos no llegaron en absoluto.
Si todos los valores en el campo son "NULL" en la carga, lo primero que veo es el sistema de origen. Quizás los datos se almacenan allí correctamente, pero se perdieron durante la migración.
Veo que en el sistema fuente los cumpleaños están en su lugar. Voy a los integradores: muchachos, error. Resultó que en el proceso ETL, la función de decodificación funcionaba incorrectamente. El código fue corregido, en la próxima carga revisaremos los cambios.
Voy más allá al campo con el TIN.
Hay 100 millones de personas en la base de datos, y solo 65 mil están llenos de TIN, esto es 0.07%. Una ocupación tan débil es una señal de que el campo en la base del receptor puede no ser necesario en absoluto.
Compruebo el sistema de origen, todo está correcto: los TIN son similares a los reales, pero casi no hay ninguno. Entonces, no se trata de migración. Queda por averiguar si el cliente necesita un campo casi vacío debajo del TIN en la base de datos de destino.
Llegué a la bandera de eliminación del cliente.
Las banderas están vacías. ¿Pero qué, la empresa no elimina clientes? Miro el sistema fuente, hablo con el cliente. Resulta que sí: la bandera es formal, en lugar de eliminar clientes, sus cuentas se eliminan. Sin cuentas, como si el cliente hubiera sido eliminado.
En el sistema de destino, se requiere el indicador de cliente remoto, esta es una característica de la arquitectura. Por lo tanto, si el cliente tiene cero cuentas en el sistema receptor, debe cerrarse mediante lógica adicional o no importarse en absoluto. Entonces, cómo decide el cliente.
El siguiente es la placa de dirección. Por lo general, algo está mal con tales tablas, porque las direcciones son algo complicado, se ingresan de diferentes maneras.
Verifico la integridad de los componentes de la dirección.
Las direcciones no están llenas de manera uniforme, pero es demasiado pronto para sacar conclusiones: primero le preguntaré al cliente para qué son. Si para la segmentación por país, todo está bien: hay suficientes datos. Si se trata de listas de correo, entonces el problema es: las casas están casi vacías, no hay apartamentos.
Como resultado, el cliente vio que el ETL estaba tomando direcciones de una tableta vieja e irrelevante. Ella está en la base como un monumento. Pero hay otra tabla, nueva y buena, los datos deben tomarse de ella.
Durante el análisis, completo los campos que enlazan a directorios con particularidad. La condición "NO ES NULL" no funciona con ellos: en lugar de "NULL", la celda suele ser "0". Por lo tanto, verifique los campos de referencia por separado.
Cambios en el relleno de campos. Entonces, verifiqué la ocupación general y la ocupación de cada campo. Problemas encontrados, los integradores arreglaron el proceso ETL y comenzaron la migración nuevamente.
Ejecuto la segunda descarga para todos los pasos enumerados anteriormente. Escribo estadísticas en el mismo archivo para ver los cambios.
Integridad de todos los campos.
Entre cargas, 5 millones de registros desaparecieron. Voy a los integradores, hago preguntas típicas:
- "¿Por qué se perdieron los registros?";
- "¿Qué datos se descartaron?";
- "¿Qué datos dejaste?"
Resulta que no hay problema: simplemente eliminaron a los clientes "técnicos" de la nueva descarga. Están en la base de datos para pruebas, no son personas vivas. Pero con la misma probabilidad, los datos podrían perderse por error, esto sucede.
Pero los cumpleaños en la nueva descarga aparecieron, como esperaba.
Pero! No necesariamente es bueno cuando los datos que faltaban anteriormente aparecieron repentinamente en una nueva carga. Por ejemplo, los cumpleaños se pueden completar con fechas predeterminadas; no hay nada de qué alegrarse. Por lo tanto, siempre verifico qué datos vinieron.
Qué comprobar, en pocas palabras.
- El número total de entradas en las tablas. ¿Es esta cantidad adecuada a las expectativas?
- El número de líneas rellenas en cada campo.
- La relación entre el número de filas llenas en cada campo y el número de filas en la tabla. Si es demasiado pequeño, esta es una ocasión para pensar si arrastrar el campo a la base objetivo.
Repita los primeros tres pasos para cada carga. Siga la dinámica: dónde y por qué ha aumentado o disminuido.Longitud de valores en campos de cadena
Sigo una de las reglas básicas de las pruebas: compruebo los valores límite.
Qué valores son demasiado cortos. Entre los valores más cortos está lleno de basura, por lo que es interesante excavar aquí.
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) < 3;
De esta manera, verifico el nombre, número de teléfono, TIN, OKVED, direcciones de sitios web. Las tonterías aparecen como "A * 1", "0", "11", "-" y "...".
¿Está todo bien con los valores máximos? Cerrar campo es un marcador del hecho de que los datos no se ajustaron durante la transferencia, y se cortaron automáticamente. MySQL resuelve esto famoso sin previo aviso. Al mismo tiempo, parece que la migración se realizó sin problemas.
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) = 65;
De esta manera, encontré en el campo con el tipo de documento la línea "Certificado de registro de la solicitud del inmigrante para su reconocimiento". Ella les dijo a los integradores que la longitud del campo fue corregida.
Cómo se distribuyen los valores a lo largo de la longitud. En HFLabs, llamamos a la tabla de distribución de longitud para las filas.
SELECT LENGTH(<column_name>), COUNT(<column_name>) FROM <table_name> GROUP BY LENGTH(<column_name>);
Aquí busco anomalías en la distribución a lo largo de la longitud. Por ejemplo, aquí hay una frecuencia para una tabla con direcciones de correo.
Los valores con una longitud de 125 son demasiados. Miro la base de datos de origen y encuentro que, por alguna razón, algunas de las direcciones se cortaron a 125 caracteres hace tres años. En otros años, todo está bien. Voy con este problema al cliente y a los integradores, entendemos.
Qué comprobar, en pocas palabras.
- Los valores más cortos en los campos de cadena. A menudo, las líneas de menos de tres caracteres son basura.
- Valores que "se apoyan" a lo largo del ancho del campo. A menudo están circuncidados.
- Anomalías en la distribución de filas a lo largo de la longitud.
Valores populares
Divido en tres categorías los valores que se encuentran entre los más populares:
- muy común , como el nombre "Tatyana" o el segundo nombre "Vladimirovich". Aquí debe recordarse que, en el caso general, Tatyana no debería ser 100 veces más popular que Anna, e Ismail difícilmente puede ser más popular que Egor;
- basura , como ".", "1", "-" y similares;
- Predeterminado en el formulario de entrada, como "01/01/1900" para fechas.
Dos de cada tres casos son marcadores del problema, es útil buscarlos.
Busco valores populares en tres tipos de campos:
- Campos de cadena ordinarios.
- Campos de cadena de referencia. Estos son campos de cadena ordinarios, pero el número de valores diferentes en ellos está, por supuesto, regulado. Estos campos almacenan países, ciudades, meses, tipos de teléfono.
- Campos de clasificador: contienen un enlace a una entrada en una tabla de clasificador de terceros.
Estudio los campos de cada uno de estos tipos un poco diferente.
Para los campos de cadena: ¿cuáles son los 100 valores más populares? Si lo desea, puede tomar más, pero en los primeros cien valores generalmente se colocan todas las anomalías.
SELECT * FROM (SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC) WHERE ROWNUM <= 100;
Compruebo los campos de esta manera:
- Nombre completo, así como apellidos, nombres y patronímicos por separado;
- fechas de nacimiento y generalmente cualquier fecha;
- direcciones Tanto la dirección completa como sus componentes individuales, si están almacenados en la base de datos;
- Teléfonos
- serie, número, tipo, lugar de emisión de documentos.
Casi siempre entre los valores populares: prueba y valores predeterminados, algunos trozos.

Sucede que el problema encontrado no es un problema en absoluto. Una vez encontré un número de teléfono sospechosamente popular en la base de datos. Resultó que los clientes indicaron este número como trabajadores, y en la base de datos simplemente había muchos empleados de una organización.
En el camino, dicho análisis mostrará campos de referencia ocultos. Lógicamente, se supone que estos campos no son directorios, pero de hecho están en la base de datos. Por ejemplo, selecciono valores populares del campo "Posición", y solo hay cinco de ellos.
Quizás la compañía solo sirve cinco profesiones. No es muy cierto, ¿verdad? Más bien, en la forma para los operadores, en lugar de una línea, hicieron un directorio y olvidaron volcar valores. La pregunta importante aquí es: ¿es aconsejable completar las publicaciones a través del directorio? Entonces, a través del análisis de datos, salgo a posibles problemas con el software del operador.
Para los campos de referencia y clasificadores, verifico la popularidad de todos los valores. Para empezar, descubro qué campos son directorios. No puedes seguir con los scripts, tomo la documentación y pretendo serlo. Por lo general, los directorios se crean para valores, cuyo número es, por supuesto, y relativamente pequeño:
- países
- idiomas
- monedas
- meses
- la ciudad
En un mundo ideal, los contenidos de los campos de referencia son claros y consistentes. Pero nuestro mundo no es así, así que verifico con una solicitud.
SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC;
Por lo general, en los campos de cadena de directorios se encuentra esto.
Problemas comunes:
- errores tipográficos
- espacios
- Caso diferente.
Habiendo encontrado un desastre, voy a los integradores con ejemplos a mano. Permítales dejar basura en la fuente y eliminar las discrepancias. Luego, en la base de datos de destino por rigor, será posible convertir las líneas de referencia en clasificadores.
Compruebo los valores populares en los campos del clasificador para detectar la falta de opciones. Ante tales casos.
Dichos clasificadores se ven muy extraños, deben mostrarse al cliente. Cada vez que tuve un error detrás de tales casos: o algo está mal en la base de datos, o los datos se descargaron del lugar equivocado.
Qué comprobar, en pocas palabras.
- Qué campos de cadena son de referencia y cuáles no.
- Para campos de cadena simples, los principales valores populares. Por lo general, en la basura superior y los datos predeterminados.
- Para los campos de referencia de cadena, la distribución de todos los valores por popularidad. La selección mostrará discrepancias en los valores de referencia.
- Para clasificadores: ¿hay suficientes opciones en la base de datos?
Consistencia y reconciliación cruzada
Desde el análisis de datos dentro de las tablas, paso al análisis de las relaciones.
Si los datos están destinados a estar relacionados. Llamamos a este parámetro "consistencia". Tomo la mesa subordinada, por ejemplo, con teléfonos. Para ello en una pareja: la tabla principal de clientes. Y veo cuántos clientes en la tabla subordinada son identificadores que no están en el padre.
SELECT COUNT(*) FROM ((SELECT <ID1> FROM <table_name_1>) MINUS (SELECT <ID2> FROM <table_name_2>));
Si la solicitud dio un delta, significa que no hubo suerte: hay datos no relacionados en la carga. Así que reviso las mesas con teléfonos, contratos, direcciones, facturas, etc. Una vez, durante un proyecto, encontró 23 millones de números que simplemente colgaban en el aire.
También funciona en la dirección opuesta: estoy buscando clientes que por alguna razón no tienen un solo contrato, dirección o número de teléfono. A veces está bien, bueno, el cliente no tiene una dirección. Aquí debe averiguarlo el cliente, la documentación engañará fácilmente.
¿Hay duplicaciones de claves primarias en diferentes tablas? A veces, las entidades idénticas se almacenan en tablas diferentes. Por ejemplo, clientes heterosexuales. (Nadie sabe por qué, porque Brezhnev todavía reclamó la estructura). Pero la tabla en el receptor es única, y al migrar, los identificadores del cliente entrarán en conflicto.
Giro la cabeza y miro la estructura de la base: donde es posible la fragmentación de entidades similares. Pueden ser tablas de clientes, teléfonos de contacto, pasaportes, etc.
Si hay varias tablas con entidades similares, hago una verificación cruzada: compruebo la intersección de los identificadores. Intersecar: pegue un parche. Por ejemplo, recopilamos identificadores para una sola tabla de acuerdo con el esquema "nombre de la tabla fuente + ID".
Qué comprobar, en pocas palabras.
- Cuántos datos no relacionados hay en tablas vinculadas.
- ¿Hay posibles conflictos clave primarios?
¿Qué más revisar?
¿Hay caracteres latinos a los que no pertenecen? Por ejemplo, en apellidos.
SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[AZ]', 'i');
Así que capto la maravillosa letra latina "C", que coincide con el cirílico. El error es desagradable, porque de acuerdo con el nombre con la "C" latina, el operador nunca encontrará un cliente.
¿Hay caracteres extraños en los campos de cadena destinados a números? SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[^0-9]');
Aparecen problemas en los campos con el número de pasaporte de la Federación de Rusia o TIN. Los teléfonos son iguales, pero allí permito más, corchetes y guiones. La solicitud también revelará la letra "O", que se estableció en lugar de cero.
Cuán adecuados son los datos. Nunca se sabe dónde surgirá el problema, así que siempre estoy en guardia. Conocí tales casos:
- ¿Es “Sofya Vladimirovna” un cliente de 50,000 teléfonos? ¿Es esto normal? Respuesta: no es normal. El cliente es técnico, le pusieron números de teléfono "sin dueño" para enviar correos electrónicos. No es necesario llevar al cliente a una nueva base;
- Los TIN se llenan, de hecho, la columna contiene "79853617764", "89109462345", "4956780966" y así sucesivamente. ¿Qué tipo de teléfonos, okuda? ¿Dónde está la posada? Respuesta: qué tipo de números, no se sabe quién lo puso, no está claro. Nadie los usa. El TIN actual se almacena en otro campo de otra tabla, tomado de allí;
- el campo "dirección en una línea" no corresponde a los campos en los que la dirección se almacena en partes. ¿Por qué son diferentes las direcciones? Respuesta: una vez que los operadores llenaron las direcciones con una línea, y el sistema externo clasificó las direcciones en campos separados. Para la segmentación A medida que pasó el tiempo, las personas cambiaron de dirección. Los operadores los actualizaban regularmente, pero solo como una cadena: la dirección seguía siendo antigua en algunas partes.
Todo lo que necesitas es SQL y Excel
Para analizar datos, no se necesita un software costoso. Suficiente Excel y conocimiento de SQL.
Excel uso para compilar una consulta larga. Por ejemplo, verifico si los campos están completos y hay 140 en la tabla. Escribiré con las manos antes de la conspiración de la zanahoria, así que recojo la solicitud con las fórmulas en la placa de Excel.
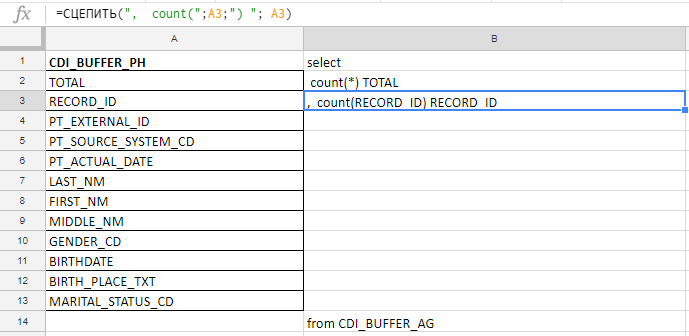 En la columna "A" inserto los nombres de los campos, los tomo en la documentación o en las tablas de servicio. En la columna "B": una fórmula para pegar una solicitud
En la columna "A" inserto los nombres de los campos, los tomo en la documentación o en las tablas de servicio. En la columna "B": una fórmula para pegar una solicitudInserto los nombres de los campos, escribo la primera fórmula en la columna "B", doblo la esquina y listo.
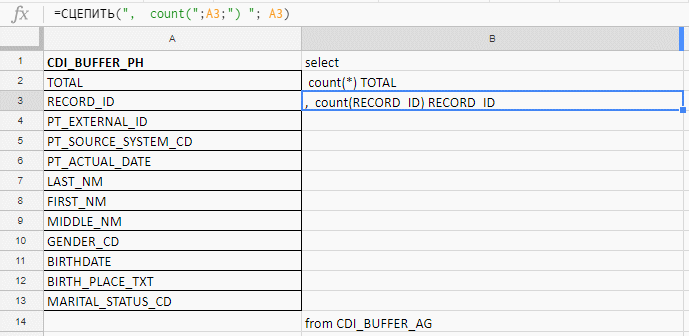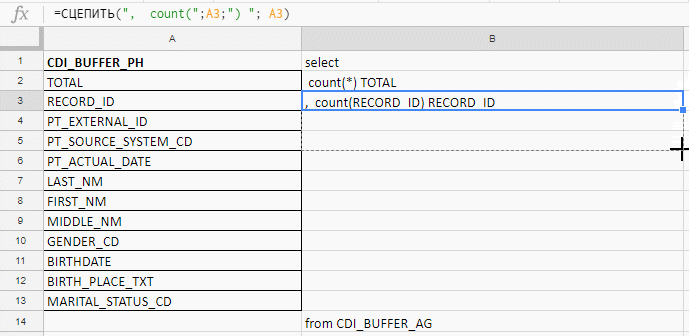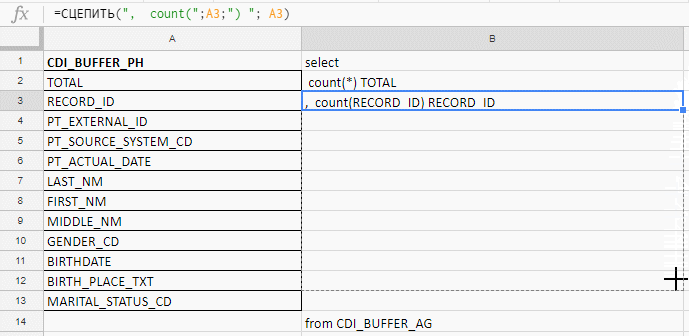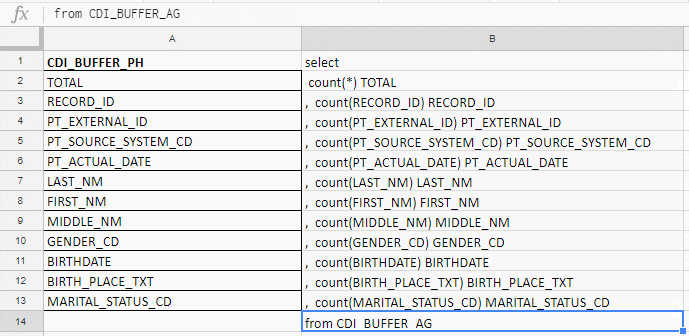 Funciona en Excel, y en Google Docs, y en Excel Online (disponible en Yandex.Disk)
Funciona en Excel, y en Google Docs, y en Excel Online (disponible en Yandex.Disk)El análisis de datos ahorra el automóvil del tiempo y los nervios de los gerentes. Con ella es más fácil cumplir con la fecha límite. Si el proyecto es grande, el análisis ahorrará millones de rublos y una reputación.
No números, sino conclusiones
Ella formuló una regla para sí misma: no mostrar números desnudos al cliente, todavía no obtendrá el efecto. Mi tarea es analizar los datos y sacar conclusiones, y adjuntar los números como evidencia. Las conclusiones son primarias, los números son secundarios.
Lo que recojo para el informe:
- La redacción de los problemas en forma de hipótesis o pregunta : “El TIN se llena en un 0.07%. ¿Cómo utiliza estos datos, qué tan relevante es, cómo interpretarlos? ¿Hay solo un INN en una mesa? No puede culpar: "Su TIN no está lleno en absoluto". En respuesta, recibirás solo agresión;
- ejemplos de problemas Estas son las tabletas de las cuales hay tantas en el artículo;
- opciones sobre cómo hacerlo: "Puede valer la pena eliminar el TIN de la base objetivo para no producir campos vacíos".
No tengo derecho a decidir qué elegir exactamente de la base de datos de origen y cómo cambiar los datos durante la migración. Por lo tanto, con el informe, voy al cliente o a los integradores, y descubrimos cómo proceder.
A veces, el cliente, al ver el problema, responde: “No se preocupe, no preste atención. Compraremos un terabyte extra de memoria, eso es todo. Es más barato que optimizar ". No puede aceptar esto: si toma todo en una fila, no habrá calidad en el receptor. Se están migrando los mismos datos redundantes basura.
Por lo tanto, le preguntamos de manera suave pero constante: "Díganos cómo utilizará estos datos en particular en el sistema de destino". No "por qué lo necesita", es decir, "cómo lo va a utilizar". Las respuestas "entonces se nos ocurrirán" o "por si acaso" no son adecuadas. Tarde o temprano, el cliente comprende qué datos se pueden prescindir.
Lo principal es encontrar y resolver todos los problemas hasta que el sistema se inicie en prod. Para cambiar la arquitectura y el modelo de datos con vida, perderá la cabeza.
Eso es todo con comprobaciones básicas, ¡estudia los datos!